基于ChatGLM+Langchain离线搭建本地知识库(免费)
目录
简介
服务部署
实现本地知识库
测试
番外
简介
ChatGLM-6B是清华大学发布的一个开源的中英双语对话机器人。基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
LangChain提供了丰富的生态,可以非常方便的封装自己的工具,并接入到LangcChain的生态中,从而实现语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
服务部署
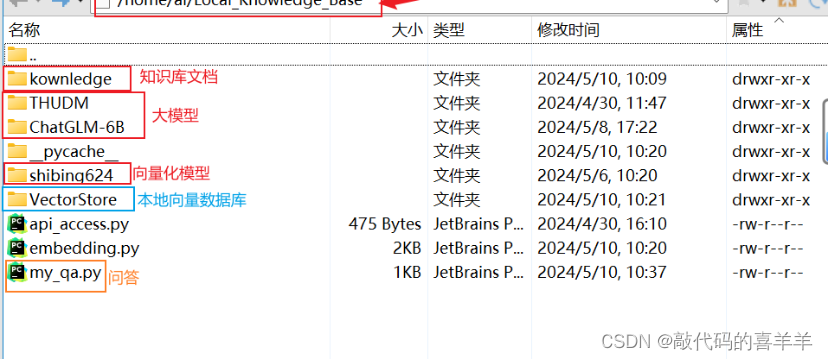
我是在一台离线服务器上,GPU内存16G,其中python3.10以上,torch1.10以上。首先github下载ChatGLM-6B(https://github.com/THUDM/ChatGLM-6B),方便调用接口,里面有一个 requirements.txt文件,直接安装里面环境即可,然后在Huggingface下载模型chatglm-6b(https://huggingface.co/THUDM/chatglm3-6b),最后将下载好的模型离线打包到离线服务器上。如下所示,其中kownledge文件夹里面包含了我要输入的知识文档(自己的一些文档、pdf、csv文件等)。
当环境搭建好之后,进入ChatGLm-6B文件夹下,打开api.py文件,将tokenizer和model的模型路径修改成从Huggingface下载下来的chatglm-6b模型路径,这里我用的是相对路径。

然后在服务器上运行api.py文件,服务在端口8000运行。

写一个测试代码api_access.py,看看服务是否能被正常使用。值得注意的是,如果你是在本地运行,这里的url写localhost:8000或者127.0.0.1:8000,如果是服务器运行,则写服务器的ip地址。
import requestsdef chat(prompt, history):resp = requests.post(#url = 'http://127.0.0.1:8000',url = 'http://172.27.171.194:8000',json = {"prompt": prompt, "history": history },headers = {"Content-Type": "application/json;charset=utf-8"})return resp.json()['response'], resp.json()['history']history = []
while True:response, history = chat(input("Question:"), history)print('Answer:',response)运行结果如下所示,说明该api服务能够正常使用。

实现本地知识库
首先在Huggingface下载向量化模型,我选择了text2vec-base-chinese(https://huggingface.co/shibing624/text2vec-base-chinese/tree/main)
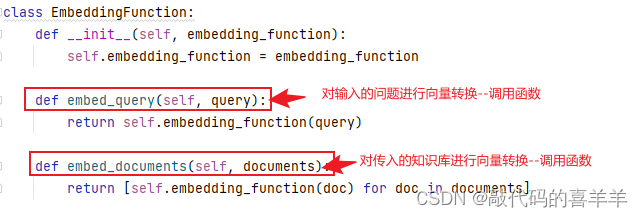
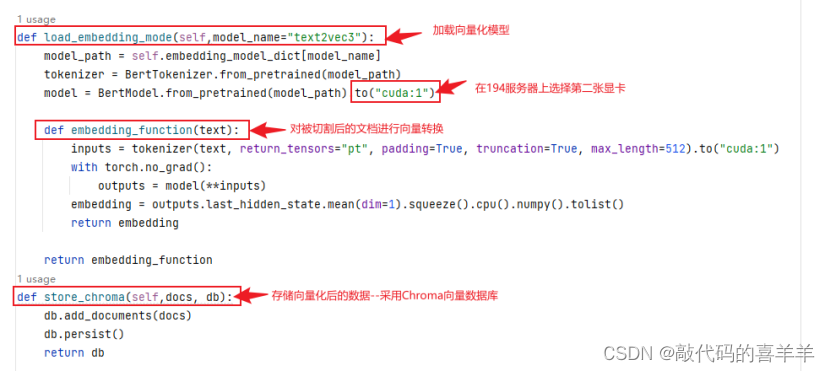
然后编写一个embedding.py文件,主要存放各种方法,完整代码如下所示。值得注意的是,由于我的服务器有多张显卡,因此我将cuda设置为1,你如果只有一张显卡,就直接是cuda:0。
from langchain_community.document_loaders import Docx2txtLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from transformers import BertModel, BertTokenizer
import torch
import os# -*- coding: utf-8 -*-class EmbeddingFunction:def __init__(self, embedding_function):self.embedding_function = embedding_functiondef embed_query(self, query):return self.embedding_function(query)def embed_documents(self, documents):return [self.embedding_function(doc) for doc in documents]class EmbeddingRetriever:def __init__(self):# 加载embeddingself.embedding_model_dict = {"text2vec3": "shibing624/text2vec-base-chinese","bert-base-chinese": "/home/ai/bert-base-chinese",}def load_documents(self,directory='kownledge'):documents = []for item in os.listdir(directory):if item.endswith("docx") or item.endswith("pdf"):split_docs = self.add_document(directory, item)documents.extend(split_docs)return documentsdef add_document(self, directory='kownledge', doc_name=''):file_path = os.path.join(directory, doc_name)if doc_name.endswith("docx"):loader = Docx2txtLoader(file_path=file_path)elif doc_name.endswith("pdf"):loader = PyPDFLoader(file_path=file_path)data = loader.load()text_spliter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)split_docs = text_spliter.split_documents(data)return split_docsdef load_embedding_mode(self,model_name="text2vec3"):model_path = self.embedding_model_dict[model_name]tokenizer = BertTokenizer.from_pretrained(model_path)model = BertModel.from_pretrained(model_path).to("cuda:1")def embedding_function(text):inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512).to("cuda:1")with torch.no_grad():outputs = model(**inputs)embedding = outputs.last_hidden_state.mean(dim=1).squeeze().cpu().numpy().tolist()return embeddingreturn embedding_functiondef store_chroma(self,docs, db):db.add_documents(docs)db.persist()return db简单解释如下,在load_documents和add_document方法中,由于我的知识文档是docx和pdf格式的,因此我就只写了两个类型,你如果有其他类型比如csv或者txt可以修改调用方式,如:
from langchain_community.document_loaders import TextLoader,CSVLoader

测试
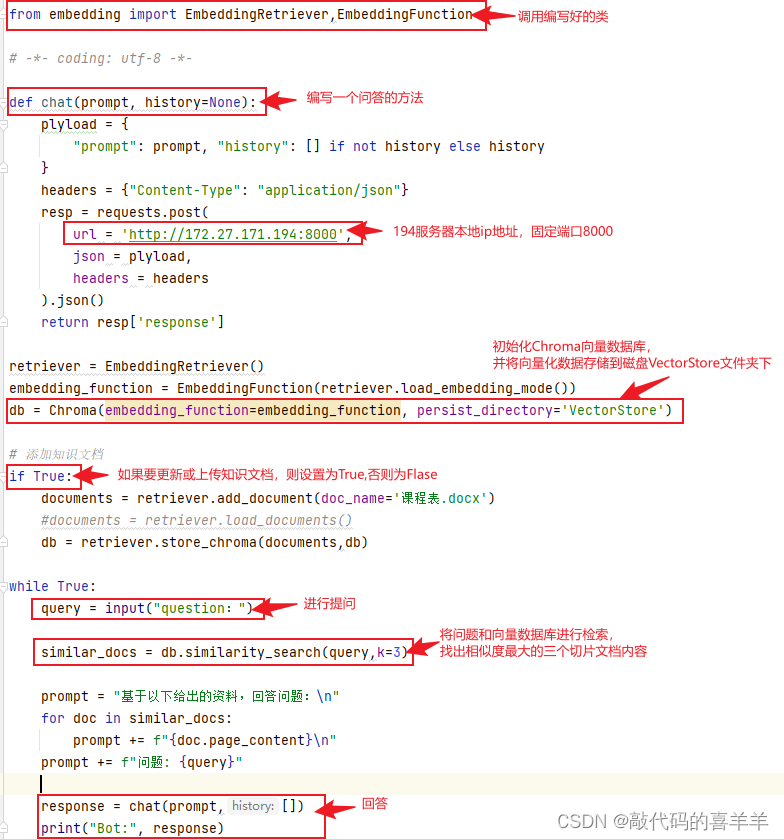
编写一个问答代码my_qa.py,完整代码如下所示,记得修改url地址。
from langchain_community.vectorstores import Chroma
import requests
from embedding import EmbeddingRetriever,EmbeddingFunction# -*- coding: utf-8 -*-def chat(prompt, history=None):plyload = {"prompt": prompt, "history": [] if not history else history}headers = {"Content-Type": "application/json"}resp = requests.post(url = 'http://172.27.171.194:8000',json = plyload,headers = headers).json()return resp['response']retriever = EmbeddingRetriever()
embedding_function = EmbeddingFunction(retriever.load_embedding_mode())
db = Chroma(embedding_function=embedding_function, persist_directory='VectorStore')# 添加知识文档
if True:documents = retriever.add_document(doc_name='课程表.docx')#documents = retriever.load_documents()db = retriever.store_chroma(documents,db)while True:query = input("question:")similar_docs = db.similarity_search(query,k=3)prompt = "基于以下给出的资料,回答问题:\n"for doc in similar_docs:prompt += f"{doc.page_content}\n"prompt += f"问题: {query}"response = chat(prompt,[])print("Bot:", response)简单解释如下:
在服务器上运行python my_qa.py,结果如下:

可以看到,准确度还是相当不错的。如果自己输入的知识库数量越多,回答越准确。
最后看看我的服务器上的文档位置。
可能出现的问题
1、解决transformers和sentence-transformers版本冲突问题
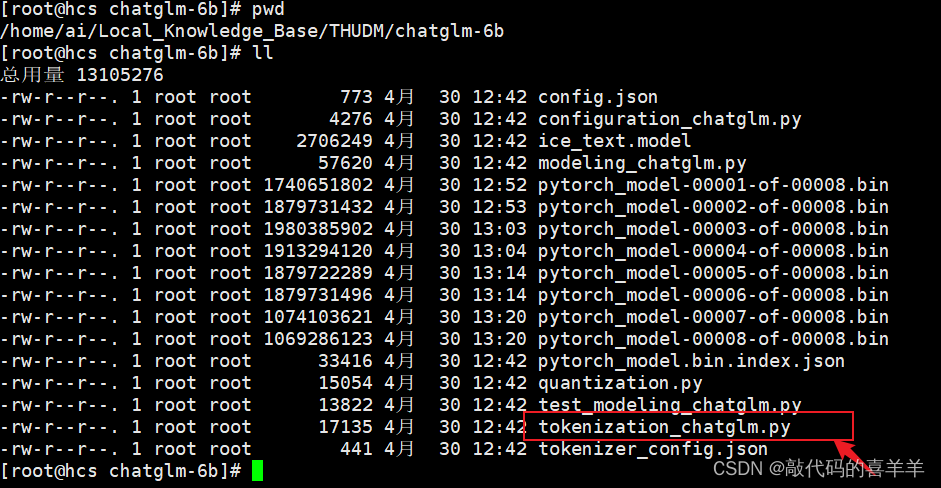
使用pip install -U sentence-transformers下载sentence-transformers时会下载最新版2.7.0并且把最新版的transformers4.39.3一起附带下载下来,但是在ChatGLM中要求的transformers版本是4.27.1,因此如果使用最新版的transformers在运行api.py接口时会报错提示没有xxxx属性。解决方式有两种,第一种就是手动降低版本(但可能会报出其他错误),第二种就是修改chatglm-6b的配置文件,如下所示:
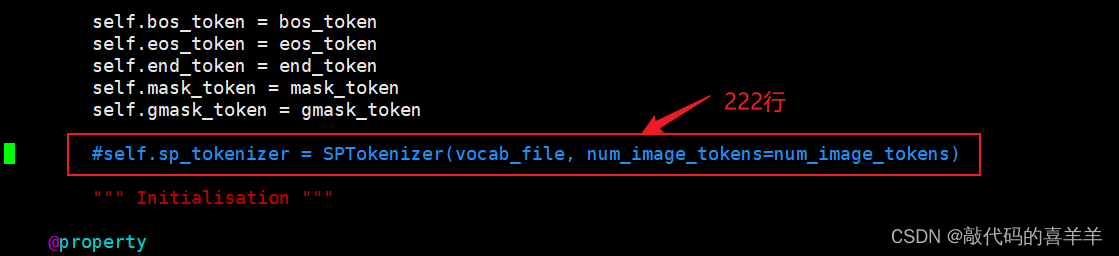
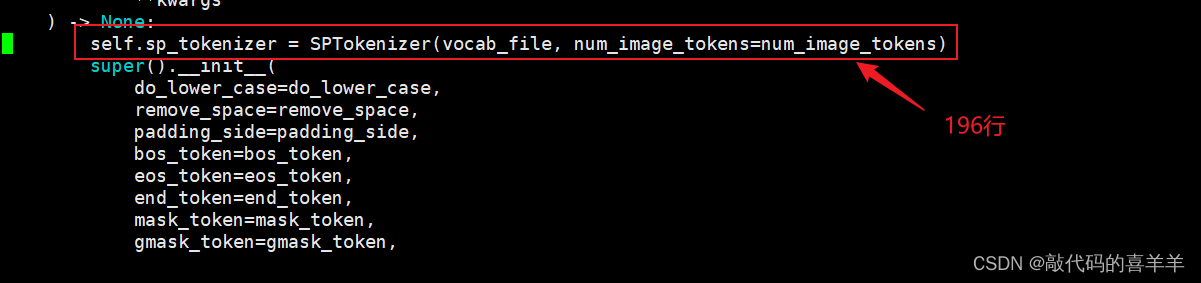
就是将从Huggingface下载的模型chatglm-6b下的tokenization_chatglm.py文件进行修改,将第222行的代码注释,放在第196行,也就是super().__init__上面。
相关文章:
基于ChatGLM+Langchain离线搭建本地知识库(免费)
目录 简介 服务部署 实现本地知识库 测试 番外 简介 ChatGLM-6B是清华大学发布的一个开源的中英双语对话机器人。基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT…...
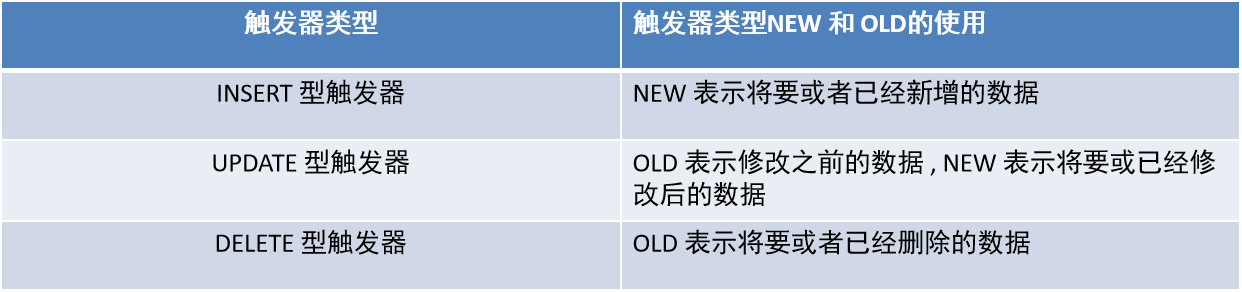
MySQL 进阶使用【函数、索引、视图、存储过程、存储函数、触发器】
前言 做数仓开发离不开 SQL ,写了很多 HQL 回头再看 MySQL 才发现,很多东西并不是 HQL 所独创的,而是几乎都来自于关系型数据库通用的 SQL;想到以后需要每天和数仓打交道,那么不管是 MySQL 还是 Oracle ,都…...

SCSS详解
SCSS(Sassy CSS)是Sass 3引入的新语法,完全兼容CSS3,并且继承了Sass的强大功能。与原始的Sass语法不同,SCSS语法使用了和CSS一样的块语法,即使用大括号“{}”将不同的规则分开,使用分号“;”将具…...

Vue 问题集
Q:MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 connection listeners added. Use emitter.setMaxListeners() to increase limit A: 可能由多个问题导致,我的是情况1 1. vue.config.js - devServer 代理设置只能添加10个&#…...

Elasticsearch 8.1官网文档梳理 -综述
积累 Elasticsearch 的常用知识,以及日常维护、学习用到的 API。因为相关内容太多,所以根据模块整理成了不同的文章,并在这里做汇总,整个系列的文章都会持续更新 目录 Elasticsearch 8.1官网文档梳理 - 四、Set up Elasticsearc…...

当自身需要使用的 gcc版本 和Linux 默认版本 存在大版本差异时怎样处理
前言 本文档意在说明 当使用者 gcc 版本 和 Linux系统默认的gcc版本 存在 大版本差异 时,怎样处理,能够兼用多个版本 并且对已有 程序影响最小。 问题描述 linux系统默认的gcc版本:7.5.0我们程序需要使用的gcc版本:8.4.0 安装…...
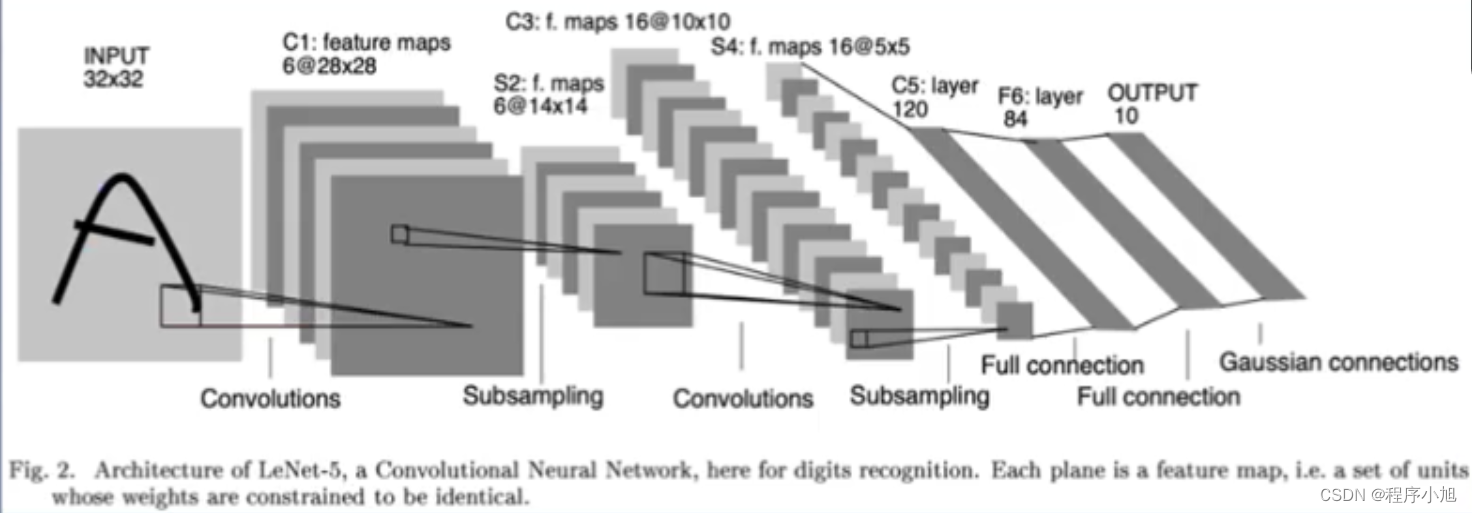
深度学习之卷积神经网络理论基础
深度学习之卷积神经网络理论基础 卷积层的操作(Convolutional layer) 在提出卷积层的概念之前首先引入图像识别的特点 图像识别的特点 特征具有局部性:老虎重要特征“王字”仅出现在头部区域特征可能出现在任何位置下采样图像,…...

控制台的高度可调有哪些重要意义解析
在现代办公环境中,控制台的高度可调性越来越受到重视。它不仅为员工提供了更加舒适的工作环境,还提高了工作效率和生产力。本文将详细探讨控制台高度可调的重要性,并解析其在实际应用中的优势。 个性化适应需求 对于长时间在控制台前工作的用…...

智能招聘?远在天边,近在眼前
2023年曾被称为“史上最卷毕业季”,当年应届高校毕业生高达1158万人。人力资源社会保障部公布的数据显示,即将到来的2024毕业季,全国普通高校毕业生规模预计将达1179万人,同比增加21万人,就业总量压力依然高企。看来&a…...

文字游侠AI丨简直是写作神器,头条爆文一键生成稳定赚米!附渠道和详细教程(只需四步)!
在数字时代的浪潮中,人们不断寻求网络空间中的商机,期望在互联网的浩瀚海洋里捕捉到稳定的财富。随着人工智能技术的突飞猛进,越来越多的AI工具被融入到各行各业,开辟了新天地,带来了创新的盈利模式。 其中,…...

【ES6】简单剖析一下展开运算符 “ ... “
基本用法 let row {id: 1,name: John Doe,age: 30 };let newRow { ...row };console.log(newRow); // 输出: { id: 1, name: John Doe, age: 30 }基本用法就是通过展开运算符,将某个对象中的元素依次展开,然后赋值给新的对象。 但是值得注意的是&…...

java StringUtils类常用方法
StringUtils类是Apache Commons Lang库中提供的一个工具类,用于处理字符串操作。它包含了许多常用的方法,以下是其中一部分常用方法: StringUtils.isEmpty(String str):判断字符串是否为空,如果字符串为null、空字符串…...
,汤臣倍健,中建三局,宁德时代,途游游戏,得物,蓝禾,顺丰,康冠科技24春招内推)
科锐国际(计算机类),汤臣倍健,中建三局,宁德时代,途游游戏,得物,蓝禾,顺丰,康冠科技24春招内推
科锐国际(计算机类),汤臣倍健,中建三局,宁德时代,途游游戏,得物,蓝禾,顺丰,康冠科技24春招内推 ①汤臣倍健 【内推岗位】:市场类、营销类、研发类…...

一些常见开发框架相关题目,RESTful是什么,Electron是什么,Express, Koa
RESTful架构 1. 什么是RESTful架构? REST(Representational State Transfer)是一种软件架构风格,它强调简单、无状态的接口,以资源为核心,使用统一的接口进行资源的访问。RESTful架构通常基于HTTP协议&am…...

C++进阶之路:何为默认构造函数与析构函数(类与对象_中篇)
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...
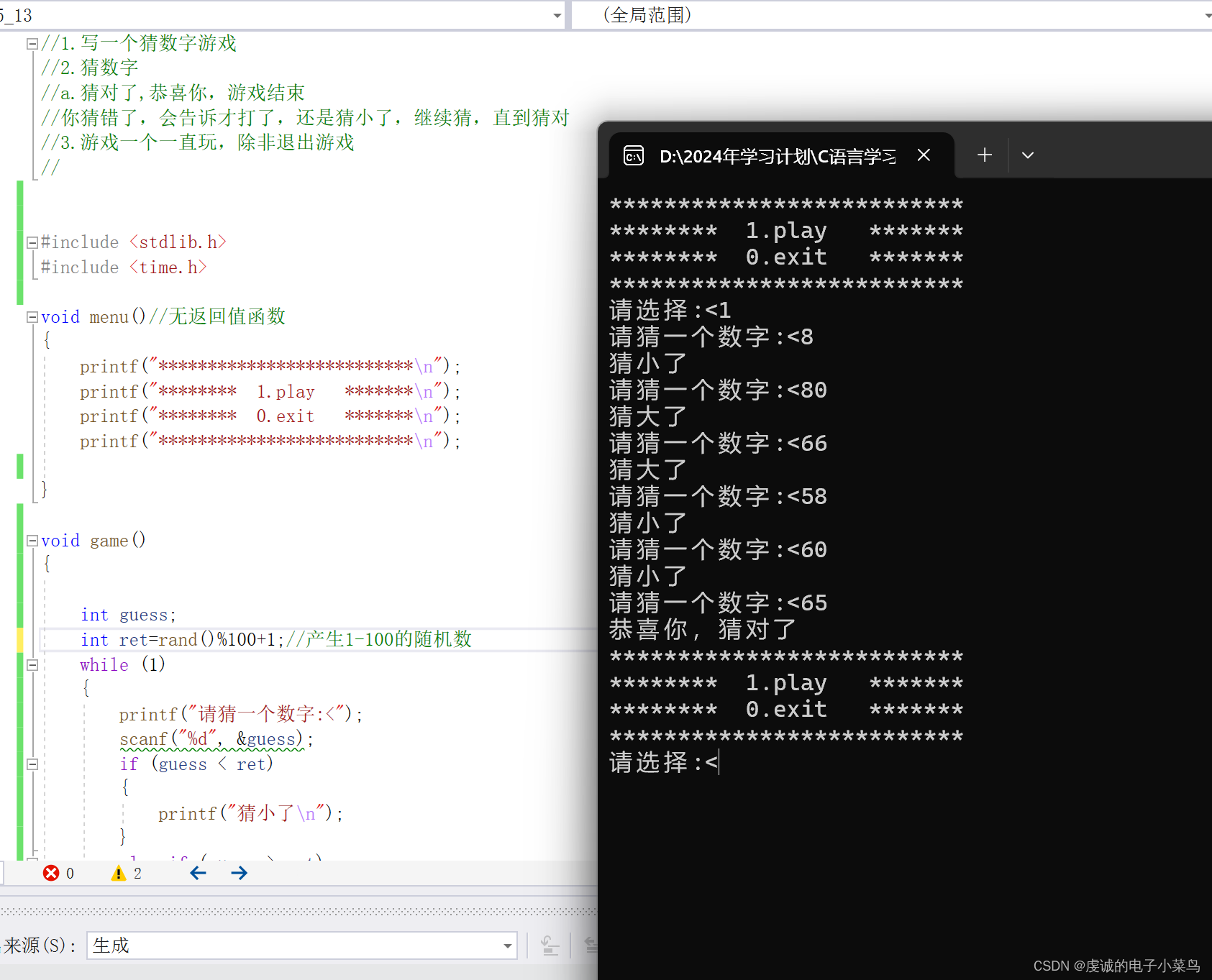
初识C语言——第二十一天
猜数字小游戏的实现: 学会了之后可以自己制作彩票抽奖,哈哈! 代码实现: #include <stdlib.h> #include <time.h>void menu()//无返回值函数 {printf("**************************\n");printf("****…...
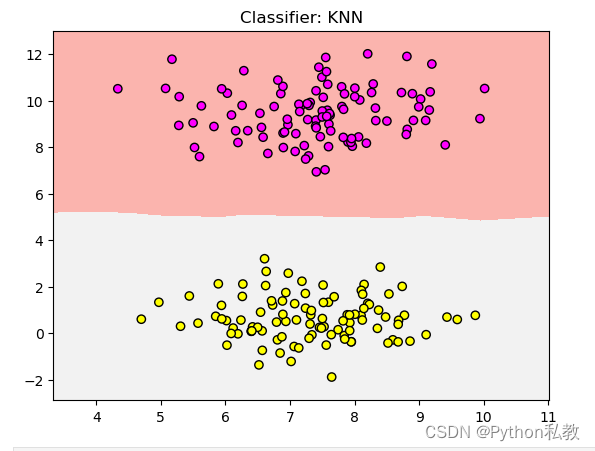
使用make_blobs生成数据并使用KNN机器学习算法进行分类和预测以及可视化
生成数据 使用make_blobs生成数据并使用matplotlib进行可视化 完整代码: from sklearn.datasets import make_blobs # KNN 分类器 from sklearn.neighbors import KNeighborsClassifier # 画图工具 import matplotlib.pyplot as plt # 数据集拆分工具 from sklea…...
WSL2-Ubuntu(深度学习环境搭建)
1.在Windows的WSL2上安装Ubuntu 流程可参考:https://www.bilibili.com/video/BV1mX4y177dJ 注意:中间可能需要使用命令wsl --update更新一下wsl。 2.WSL数据迁移 按照下面流程:开始菜单->设置->应用->安装的应用->搜索“ubun…...
政务服务电子文件归档和电子档案管理系统,帮助组织收、管、存、用一体化
作为数字政府建设的重要抓手,政务服务改革经过多年发展,截至 2022 年底,全国一体化在线政务服务平台实名用户超过10亿人,在政务服务、办件过程中出现了大量需要归档的电子文件,对于电子档案、电子证照的需求愈加强烈。…...
2024.05.15学习记录
1、完成Ts重构Axios项目中更多功能的开发 2、刷题:二叉树(代码回忆录) 3、复习diff算法源码解读...

Seraphine:5大核心技术构建的智能英雄联盟战绩查询与决策系统
Seraphine:5大核心技术构建的智能英雄联盟战绩查询与决策系统 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于Python和PyQt5开发的高效智能开源英雄联盟战绩查询工具ÿ…...

AI写专著全攻略:从选题到完稿,AI工具帮你快速完成20万字专著!
学术专著的严谨性必须依靠大量的数据和资料,但资料的搜集和数据的整合却是写作中最为繁琐且耗时的部分。研究人员需要全面地收集国内外的前沿文献,这不仅包括确认文献的权威性和相关性,还有追溯原始出处,避免二次引用时的错误&…...

如何在5分钟内搭建免费PUBG游戏雷达:终极战场可视化指南
如何在5分钟内搭建免费PUBG游戏雷达:终极战场可视化指南 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-maph…...

Python自动化资源管理工具closeclaw:智能清理闲置窗口与进程
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫closeclaw,作者是krishpranav。乍一看这个仓库名,你可能会有点摸不着头脑——“关闭爪子”?这到底是干嘛的?点进去研究了一番,发现这是一个用…...

Photoshop快速导出图层终极指南:如何高效批量处理设计文件
Photoshop快速导出图层终极指南:如何高效批量处理设计文件 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址:…...

NotebookLM协作效能临界点预警:当团队超8人时,必须立即启用的3项动态共享策略
更多请点击: https://intelliparadigm.com 第一章:NotebookLM协作效能临界点的本质洞察 NotebookLM 的协作效能并非随用户数量线性增长,而是在特定交互密度与知识对齐度交汇时触发跃迁式提升——这一拐点即为“协作效能临界点”。其本质并非…...

从混乱到掌控:FastbootEnhance如何重塑安卓设备管理体验
从混乱到掌控:FastbootEnhance如何重塑安卓设备管理体验 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾面对黑底白字的Fastb…...

保障企业级应用安全,如何利用 Taotoken 管理 API 密钥与审计日志
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 保障企业级应用安全,如何利用 Taotoken 管理 API 密钥与审计日志 在中大型企业的开发实践中,将大模型能力集…...

AI驱动博客平台CodeBlog-app:开发者技术分享的智能解决方案
1. 项目概述:一个为开发者而生的AI驱动博客平台最近在GitHub上看到一个挺有意思的开源项目,叫CodeBlog-ai/codeblog-app。光看名字,你可能会觉得这又是一个普通的博客系统,或者是一个AI写作工具。但当我深入去研究它的代码和设计理…...

Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南
Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...