机器学习 - 决策树
1. 决策树基础
定义与概念
决策树是一种监督学习算法,主要用于分类和回归任务。它通过学习从数据特征到输出标签的映射规则,构建一个树形结构。在分类问题中,决策树的每个叶节点代表一个类别。
案例分析
假设我们有一个关于天气和是否进行户外活动的数据集,其中特征包括“温度”、“风速”和“天气类型”,目标变量是“是否进行户外活动”。决策树将从这些特征中学习规则,以预测任何给定天气条件下的活动决定。
公式推导
最简单的决策树使用信息增益来选择每个节点的分裂特征。信息增益计算如下:
I G ( T , a ) = H ( T ) − ∑ v ∈ V a l u e s ( a ) ∣ T v ∣ ∣ T ∣ H ( T v ) IG(T, a) = H(T) - \sum_{v \in Values(a)} \frac{|T_v|}{|T|} H(T_v) IG(T,a)=H(T)−v∈Values(a)∑∣T∣∣Tv∣H(Tv)

常见问题及解决方案
-
问题:如何处理连续特征?
- 解决方案:将连续特征通过阈值划分为两个子集,选择最优阈值使信息增益最大化。
-
问题:决策树容易过拟合吗?
- 解决方案:是的,可以通过设置树的最大深度或使用剪枝技术来防止过拟合。
-
问题:如果数据集中有缺失值怎么办?
- 解决方案:可以用数据集中同一特征的非缺失值的平均值或众数替代缺失值。
-
问题:决策树在何种情况下表现不好?
- 解决方案:在特征间复杂的相互作用或分类边界非线性时,单一决策树效果不佳,此时可考虑使用随机森林等集成方法。
-
问题:如何选择最佳的分裂特征?
- 解决方案:通过计算每个特征的信息增益或基尼不纯度,并选择增益最大或不纯度降低最多的特征。
2. 关键概念
属性选择度量
在决策树构造中,选择正确的属性对于分裂每个节点至关重要。以下是几种常见的属性选择度量方法:
- 信息增益:如之前所述,信息增益衡量在给定属性的条件下,数据不确定性的减少。
- 增益比率:解决信息增益偏好选择取值较多的属性的问题,通过标准化信息增益来减少这种偏差。
- 基尼指数:常用于CART(分类与回归树)算法中,测量一个随机选择的样本被错误标记的概率。
案例分析:基尼指数
考虑一个数据集,我们需要根据“年龄”、“收入”和“学历”预测一个人是否会购买豪车。使用基尼指数,我们可以决定哪个特征在根节点分裂时使用。
计算方法如下:
G i n i ( T ) = 1 − ∑ i = 1 k p i 2 Gini(T) = 1 - \sum_{i=1}^k p_i^2 Gini(T)=1−i=1∑kpi2
其中 pi 是第 i 类的比例。
假设我们有100个样本,60个样本不买豪车,40个买豪车,则:
G i n i ( T ) = 1 − ( ( 0.6 ) 2 + ( 0.4 ) 2 ) = 0.48 Gini(T) = 1 - ((0.6)^2 + (0.4)^2) = 0.48 Gini(T)=1−((0.6)2+(0.4)2)=0.48
树的构造
构造决策树时,我们从根节点开始,使用所选的属性选择度量来递归地分裂每个节点,直到满足某些停止条件,如节点达到最小样本数、达到最大深度或纯度达到一定水平。
常见问题及解决方案
-
问题:如何处理非数值特征?
- 解决方案:将类别型特征进行独热编码或使用基于标签的编码方法。
-
问题:节点最优分裂点如何确定?
- 解决方案:对于每个属性,尝试所有可能的分裂点,选择使信息增益、增益比率或基尼指数最优的分裂点。
-
问题:如何处理训练数据中的噪声?
- 解决方案:使用预剪枝或后剪枝减少噪声带来的影响,或者使用交叉验证来确定最佳的剪枝策略。
-
问题:决策树构造算法运行时间过长怎么办?
- 解决方案:可以通过限制树的最大深度或节点最小样本数来减少构造时间,或使用更高效的数据结构如KD树。
-
问题:如果一个属性在训练集中重要但在验证集中无效怎么办?
- 解决方案:进行特征选择和特征重要性评估,以避免过度依赖训练数据中的特定特征。
3. 决策树算法
ID3算法
定义与概念:
ID3(Iterative Dichotomiser 3)算法是最早的决策树算法之一,主要用于处理分类问题。它使用信息增益作为属性选择的度量标准,从而选择最能提供最大信息增益的属性来进行节点的分裂。
案例应用:
考虑一个邮件系统需要根据邮件内容判断是否为垃圾邮件。特征可能包括关键词的出现频率、发件人信誉等。ID3算法会选择最能区分垃圾邮件和非垃圾邮件的特征来分裂节点。
公式推导:
信息增益的计算已在前文中详细介绍。
C4.5算法
定义与概念:
C4.5算法是ID3算法的改进版本,能够处理连续属性和具有缺失值的数据。此外,C4.5使用增益比率来选择属性,减少了对多值属性的偏见。
案例应用:
在一个在线零售数据集中,我们可能需要根据客户的年龄、购买历史和页面浏览行为来预测他们是否会购买某个产品。C4.5算法能够有效地处理这些连续和离散的数据特征。
公式推导:
G a i n R a t i o ( S , A ) = I n f o r m a t i o n G a i n ( S , A ) S p l i t I n f o r m a t i o n ( S , A ) GainRatio(S, A) = \frac{InformationGain(S, A)}{SplitInformation(S, A)} GainRatio(S,A)=SplitInformation(S,A)InformationGain(S,A)
其中:
S p l i t I n f o r m a t i o n ( S , A ) = − ∑ i = 1 n ( ∣ S i ∣ ∣ S ∣ ) log 2 ( ∣ S i ∣ ∣ S ∣ ) SplitInformation(S, A) = -\sum_{i=1}^n \left(\frac{|S_i|}{|S|}\right) \log_2 \left(\frac{|S_i|}{|S|}\right) SplitInformation(S,A)=−i=1∑n(∣S∣∣Si∣)log2(∣S∣∣Si∣)
CART算法
定义与概念:
CART(Classification and Regression Trees)算法既可以用于分类问题也可以用于回归问题。这种算法使用基尼指数作为分类问题的度量,而对于回归问题,则使用最小二乘偏差。
案例应用:
在房价预测模型中,CART算法可以通过房屋的年龄、面积、地理位置等连续特征来预测房屋价格。
公式推导:
基尼指数计算已在前文介绍。对于回归问题,最小二乘偏差定义为:
L ( T ) = ∑ i ∈ T ( y i − y ^ T ) 2 L(T) = \sum_{i \in T} (y_i - \hat{y}_T)^2 L(T)=i∈T∑(yi−y^T)2
其中 y ^ T \hat{y}_T y^T 是节点 T 中所有样本 y 值的平均数。
常见问题及解决方案
-
问题:如何在ID3算法中处理连续特征?
- 解决方案:通过定义阈值将连续特征离散化,然后按照离散特征处理。
-
问题:C4.5算法在处理非常大的数据集时性能如何?
- 解决方案:由于计算增益比率较为复杂,对于非常大的数据集,C4.5的性能可能不如预期。可以考虑使用算法优化或者硬件加速。
-
问题:CART算法在分类问题中如何选择最佳分裂点?
- 解决方案:通过计算每个可能分裂点的基尼指数,选择基尼指数最低的点作为分裂点。
-
问题:如何处理决策树中的过拟合问题?
- 解决方案:通过剪枝技术,限制树的深度或者设置节点的最小样本大小等方法来控制树的复杂度。
-
问题:如果数据集中存在大量缺失值,决策树的性能如何?
- 解决方案:可以使用多种策略处理缺失值,如使用最常见的值填充,或者利用可用特征的信息推断缺失值。 C4.5算法原生支持处理缺失值。
4. 剪枝技术
定义与概念
剪枝是决策树学习算法中的一种技术,用于减少树的大小,从而控制模型的复杂度和过拟合现象。剪枝可以分为两种主要类型:预剪枝(Pre-pruning)和后剪枝(Post-pruning)。
预剪枝
定义:预剪枝是在决策树完全生成之前停止树的生长。这通常通过设置停止条件来实现,如达到最大深度、节点中的最小样本数或信息增益的最小阈值。
案例应用:
假设在一个贷款申请的决策树模型中,我们可以设置最大深度为5,以防止模型变得过于复杂并过拟合训练数据。
后剪枝
定义:后剪枝是在决策树构造完成后进行的。这种方法通常涉及使用验证数据集来评估是否剪去某些子树,从而改善模型在未见数据上的表现。
案例应用:
在同一个贷款申请模型中,我们可能会允许树完全生长,然后用一个独立的验证集来测试每一个子树的性能。如果剪除某个子树能够提高验证集上的准确率,则进行剪枝。
公式推导
对于后剪枝,其中一种常用方法是成本复杂度剪枝,其公式可以表示为:
R α ( T ) = R ( T ) + α × ∣ l e a v e s ∣ R_\alpha(T) = R(T) + \alpha \times |leaves| Rα(T)=R(T)+α×∣leaves∣
其中 R(T) 是树 T 在训练数据上的误差, |leaves| 是树的叶节点数量,α 是复杂度参数。
常见问题及解决方案
-
问题:预剪枝和后剪枝哪个更好?
- 解决方案:预剪枝可以更快地构建模型,但可能因为过于保守而错过重要的模式;后剪枝通常更能提高模型的泛化能力,但计算成本更高。
-
问题:如何选择合适的 α 值进行成本复杂度剪枝?
- 解决方案:通过交叉验证来选取最佳的α 值,从而在模型简单性和准确性之间找到最佳平衡。
-
问题:如果剪枝过度会怎样?
- 解决方案:过度剪枝可能导致模型过于简单,不能捕捉数据中的重要模式。需要通过调整剪枝参数或减少剪枝程度来解决。
-
问题:预剪枝有哪些具体的停止条件?
- 解决方案:具体的停止条件包括但不限于达到最大树深、节点最小样本数、信息增益低于某个阈值等。
-
问题:后剪枝的流程是怎样的?
- 解决方案:后剪枝通常包括完全生成决策树,然后逐步测试每个节点(从叶节点开始)是否应该替换为更简单的决策过程或其父节点,通常借助独立的验证集来评估性能。
5. 决策树的应用
实际案例分析
决策树因其模型的解释性强,被广泛应用于各种行业和场景中。以下是几个示例:
-
医疗诊断:
- 场景:使用病人的历史医疗记录来预测某种疾病的发生。
- 数据:特征包括年龄、性别、体重、血压等。
- 应用:构建决策树来识别高风险病人,并进行早期干预。
-
客户分类:
- 场景:电商平台根据用户的购物行为和个人喜好进行市场细分。
- 数据:特征包括购买频率、平均消费金额、浏览历史等。
- 应用:决策树帮助确定哪些客户对特定产品类别感兴趣,以定向推送广告。
-
信用评分:
- 场景:金融机构需要评估贷款申请者的信用风险。
- 数据:特征包括信用历史、还款能力、已有负债等。
- 应用:通过决策树分析,银行可以决定是否批准贷款以及贷款条件。
特征重要性评估
在构建决策树模型时,了解哪些特征对预测结果影响最大是至关重要的。特征重要性评估可以帮助我们优化模型和理解数据背后的因果关系。
方法:
- 基于模型的特征重要性:大多数决策树算法(如CART和随机森林)都提供了一种计算特征重要性的内建方法。这通常基于每个特征在分裂节点时的效用(如基尼减少或信息增益)来评分。
案例应用:
在信用评分模型中,特征如“年收入”和“现有负债”可能显示为最重要的预测因素。通过分析这些特征的重要性,银行可以更准确地识别潜在的风险客户。
常见问题及解决方案
-
问题:决策树在哪些情况下可能不是最佳选择?
- 解决方案:对于具有复杂关系和大量非线性特征的数据集,单一决策树可能表现不佳。此时,可以考虑使用集成方法如随机森林或梯度提升树。
-
问题:如何处理大数据集上的决策树训练?
- 解决方案:可使用分布式计算框架如Apache Spark中的MLlib来处理大规模数据集上的决策树训练。
-
问题:如何解决决策树对于数据中小的变化过于敏感的问题?
- 解决方案:通过集成学习方法,如随机森林,可以降低模型对数据中小波动的敏感性。
-
问题:决策树如何应对非平衡数据集?
- 解决方案:通过调整类权重或对少数类进行过采样处理,以平衡各类的影响力。
-
问题:如何提高决策树的预测准确性?
- 解决方案:除了使用剪枝和特征选择技术,还可以通过调整模型参数如最大深度和最小分裂样本数来优化模型性能。
6. 集成方法
定义与概念
集成学习是一种强大的机器学习范式,它通过结合多个模型来提高预测性能,通常能够比任何一个单独的模型表现得更好。在决策树的上下文中,常见的集成方法包括随机森林和梯度提升树。
随机森林
定义:随机森林是由多个决策树组成的集成模型,每棵树都在数据集的一个随机子集上训练得到,用于增加模型的多样性。
案例应用:
在一个银行欺诈检测系统中,随机森林模型可以通过整合数百棵树的预测结果来提高识别欺诈行为的准确率。
梯度提升树
定义:梯度提升是一种提升技术,通过迭代地添加新模型来纠正前一轮模型的错误,通常使用决策树作为基学习器。
案例应用:
在房价预测模型中,梯度提升树可以逐步学习并改进预测,处理各种复杂的非线性关系,以更精确地预测各种因素影响下的房价。
比较决策树与其他模型
与支持向量机(SVM)
- 优点:决策树易于理解和解释,适合处理带有明确决策边界的问题。
- 缺点:SVM通常在高维空间和复杂决策边界的情况下表现更好,因为它侧重于最大化类之间的边界。
与神经网络
- 优点:决策树不需要很多参数调整即可开始训练,而神经网络通常需要复杂的配置和更长的训练时间。
- 缺点:神经网络在处理大规模数据集和捕捉数据中复杂模式方面更有优势,尤其是在图像和语音识别等领域。
工具与库
- Scikit-learn:Python的一个主要机器学习库,提供了决策树和集成算法的实现,包括随机森林和梯度提升树。
- XGBoost:优化的分布式梯度提升库,非常适合在大规模数据集上进行高效的模型训练。
- Graphviz:用于决策树可视化的工具,可以帮助分析和解释模型的决策路径。
7.案例 - 鸢尾花分类
当然,这里我将给出一个使用Python中的scikit-learn库构建决策树分类器的详细案例。我们将使用经典的鸢尾花数据集(Iris dataset)来演示如何构建和评估一个决策树模型。
数据集
鸢尾花数据集包含150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)和3种不同类别的鸢尾花(Setosa, Versicolour, 和 Virginica)。
步骤
- 导入所需的库和数据集。
- 数据预处理。
- 分割数据集为训练集和测试集。
- 创建决策树模型。
- 训练模型。
- 预测测试数据。
- 评估模型性能。
- 可视化决策树。
代码实现
# 1. 导入库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, export_text, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt# 2. 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 3. 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 4. 创建决策树模型
tree_classifier = DecisionTreeClassifier(max_depth=3, random_state=42)# 5. 训练模型
tree_classifier.fit(X_train, y_train)# 6. 预测测试数据
y_pred = tree_classifier.predict(X_test)# 7. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:")
print(classification_report(y_test, y_pred))# 8. 可视化决策树
plt.figure(figsize=(12,8))
plot_tree(tree_classifier, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
说明
- 这段代码首先导入了必要的库,包括数据集加载、决策树构建、数据分割、模型评估和可视化所需的库。
- 使用
train_test_split函数将数据分为70%的训练集和30%的测试集。 - 使用
DecisionTreeClassifier创建一个决策树模型,设置max_depth=3来限制树的深度,以避免过拟合。 - 使用训练集训练模型,并在测试集上进行预测。
- 评估模型性能,输出准确率和分类报告。
- 使用
plot_tree函数可视化决策树,帮助理解模型是如何做出决策的。
更多问题咨询
Cos机器人
相关文章:
机器学习 - 决策树
1. 决策树基础 定义与概念 决策树是一种监督学习算法,主要用于分类和回归任务。它通过学习从数据特征到输出标签的映射规则,构建一个树形结构。在分类问题中,决策树的每个叶节点代表一个类别。 案例分析 假设我们有一个关于天气和是否进行…...
ML模型实战及经验总结(更新中))
【scikit-learn007】主成分分析(Principal Component Analysis, PCA)ML模型实战及经验总结(更新中)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架主成分分析(Principal C…...
还在花钱订购SSL证书吗?out啦!
SSL(Secure Sockets Layer)证书,以及其后续版本TLS(Transport Layer Security)证书,扮演了保护用户数据免遭窃听和篡改的核心角色。这些证书能够确保数据在客户端与服务器之间传输时的加密性与完整性&#…...

【GoLang基础】函数体的注意事项和细节讨论
在 Go 语言(Golang)中,函数是程序的基本构建块之一。理解函数的定义和使用是掌握 Go 语言的重要步骤。下面是关于 Go 语言中函数体的详细解释,包括函数的定义、参数传递、返回值以及闭包等方面。 1. 函数的定义 在 Go 语言中&am…...
YOLOv8训练流程-原理解析[目标检测理论篇]
关于YOLOv8的主干网络在YOLOv8网络结构介绍-CSDN博客介绍了,为了更好地学习本章内容,建议先去看预测流程的原理分析YOLOv8原理解析[目标检测理论篇]-CSDN博客,再次把YOLOv8网络结构图放在这里,方便随时查看。 1.前言 YOLOv8训练…...

实战使用Java代码操作Redis
实战使用Java代码操作Redis 1. 背景说明2. 单连接方式3. 连接池方式1. 背景说明 在工作中, 如果有一批数据需要初始化, 最方便的方法是使用代码操作Redis进行初始化。 Redis提供了多种语言的API交互方式, 这里以Java代码为例进行分析。 使用Java代码操作 Redis 需要借助…...

微信小程序之九宫格抽奖
1.实现效果 2. 实现步骤 话不多说,直接上代码 /**index.wxml*/ <view class"table-list flex fcc fwrap"><block wx:for"{{tableList}}" wx:key"id"><view class"table-item btn fcc {{isTurnOver?:grayscale…...
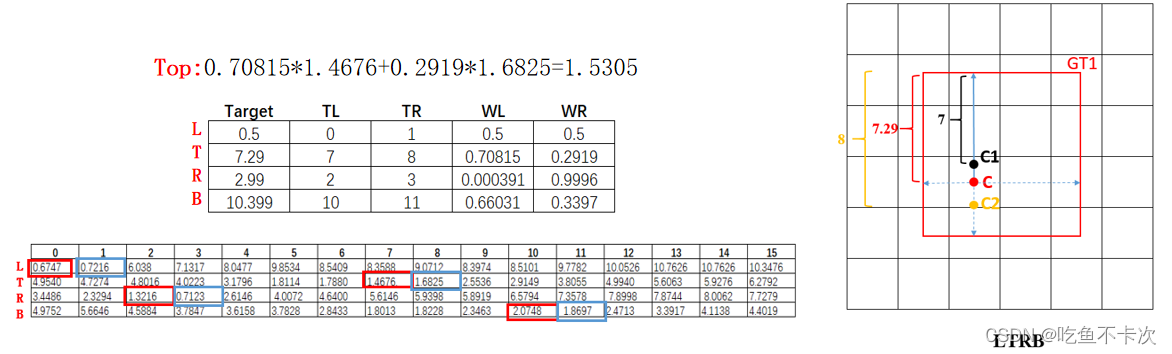
车牌检测识别功能实现(pyqt)
在本专题前面相关博客中已经讲述了 pyqt + yolo + lprnet 实现的车牌检测识别功能。带qt界面的。 本博文将结合前面训练好的模型来实现车牌的检测与识别。并用pyqt实现界面。最终通过检测车牌检测识别功能。 1)、通过pyqt5设计界面 ui文件如下: <?xml version="1…...
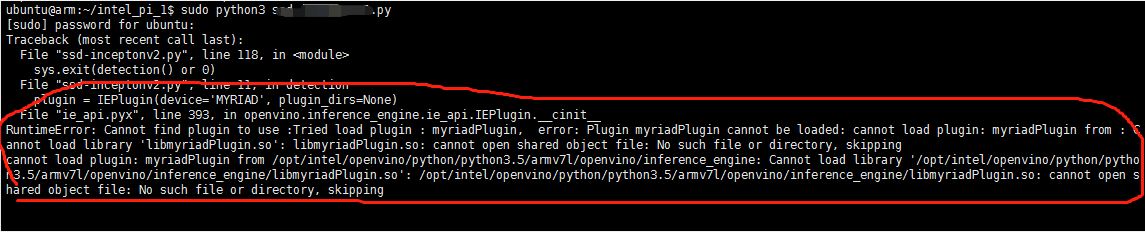
工业派-配置Intel神经计算棒二代(NCS2)
最近两天在工业派ubuntu16.04上配置了Intel神经计算棒二代——Intel Neural Compute Stick,配置过程之艰辛我都不想说了,实在是太折磨人。不过历尽千辛万苦,总算让计算棒可以在工业派ubuntu16.04系统上跑了,还是蛮欣慰的。 注&…...

深度学习中常见的九种交叉验证方法汇总
目录 1. K折交叉验证(K-fold cross-validation) 2. 分层K折交叉验证(Stratified K-fold cross-validation) 3. 时间序列交叉验证(Time Series Split) 4. 留一交叉验证(Leave-One-Out Cross-…...

企业建网站流程
企业建网站是一个复杂而繁琐的过程,需要根据企业的需求和目标进行规划、设计、开发和运营。以下是企业建网站的一般流程,主要包括以下几个步骤: 第一步:需求分析 企业建网站的第一步是进行需求分析。这个过程需要与企业负责人和相…...

Laravel通过phpSpreadsheet合并excel
背景 最近有一个需求,需要将所有excel文件的sheet合并到一个文件。 目前我们处理表格使用的是xlswriter这个插件,对于数据量比较大的话非常好用。...
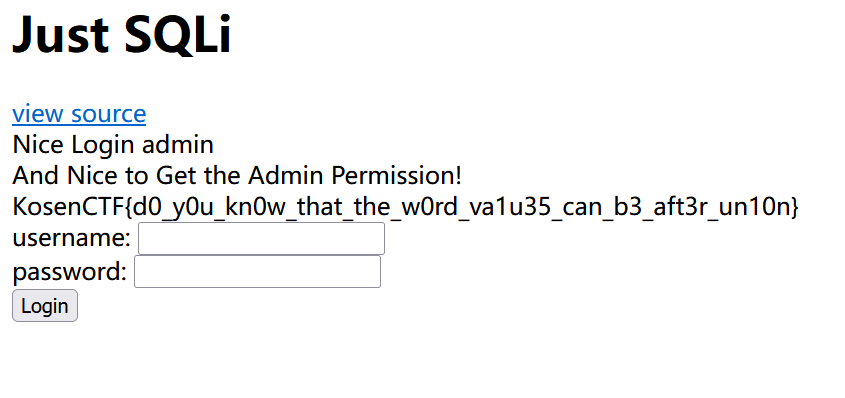
CTF网络安全大赛web题目:just_sqli
这道题目是bugku的web题目 题目的 描 述: KosenCTF{} 原文链接: CTF网络安全大赛web题目:just_sqli - 红客网-网络安全与渗透技术 题目Web源代码: <?php$user NULL; $is_admin 0;if (isset($_GET["source"])) {highlig…...

Java入门基础学习笔记27——生成随机数
Random的使用:生成随机数。 随机数应用: 随机点名: 年会抽奖: 猜数字游戏: 密码学。 查看API文档: package cn.ensource.random;import java.util.Random;public class RandomDemo1 {public static voi…...
EasyImage2.0 图床源码
EasyImage2.0 是一个简单图床的源码,它支持以下功能: 1. API接口 2. 登录后才能上传图片 3. 设置图片质量 4. 压缩图片大小 5. 添加文字或图片水印 6. 设定图片的宽度和高度 7. 将上传的图片转换为指定的格式 8. 限制上传图片的最小宽度和高度 …...

人工智能创新领衔,Android系统如虎添翼:2024 Google I/O 大会深度解析
人工智能创新领衔,Android系统如虎添翼:2024 Google I/O 大会深度解析 2024年5月14日举行的Google I/O大会,犹如一场精彩的科技盛宴,吸引了全球的目光。大会上,谷歌发布了一系列重磅产品和技术更新,展现了…...

下单制造fpc的工艺参数
FPC工艺简介 - 百度文库 (baidu.com) FPC工艺参数 - 豆丁网 (docin.com) FPC柔性线路板的主要参数.ppt (book118.com) 捷多邦: 华秋: 背胶: FPC板背胶是可以粘接在光滑表面的一种薄型胶带,可以在狭小以及光滑的表面上用来提供高…...
位拆分与运算
描述 题目描述: 现在输入了一个压缩的16位数据,其实际上包含了四个数据[3:0][7:4][11:8][15:12], 现在请按照sel选择输出四个数据的相加结果,并输出valid_out信号(在不输出时候拉低) 0: 不输出且只有此时的输入有…...

windows11目标文件夹访问被拒绝-将安全信息应用到以下对象时发生错误
将安全性信息应用到以下对象时发生错误”解决办法 要夺取所有权时,点“安全”添加用户并允许所有权限后点击“应用”, 一直“无法保存对。。。(文件夹名)权限所在的更改。拒绝访问”啊 必须先点击“高级”,把“允许父项…...

C#thread线程传参数更新UI的文本框
C#线程的用法有几个不同的地方: 1、怎么启动线程? 2、是不是需要传入参数? 3、是不是要调用到UI中的控件,并对其进行更新? 关于启动线程,这里一个示例是在form中启动: 定义一个private:sta…...

终极Windows虚拟手柄驱动配置指南:5步快速上手ViGEmBus
终极Windows虚拟手柄驱动配置指南:5步快速上手ViGEmBus 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想在Windows系统中轻松实现游戏控制器模拟…...

如何通过DLSS版本管理工具提升30%游戏性能:实战指南
如何通过DLSS版本管理工具提升30%游戏性能:实战指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款开源游戏性能优化工具,专门用于管理DLSS、FSR和XeSS动态库版本。你是否曾…...

ESP32-S2物联网实战:IPv6配置与Adafruit IO双向通信
1. 项目概述与核心价值如果你手头有一块ESP32-S2开发板,并且已经厌倦了仅仅让它连上Wi-Fi、点个灯,想让它真正“活”起来,成为一个能融入现代互联网、能与云端自由对话的智能节点,那么这篇文章就是为你准备的。我们将深入两个在物…...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...
:提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制)
【独家首发】ElevenLabs乌尔都语语音SDK逆向分析(v2.4.1):提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音SDK逆向分析全景概览 ElevenLabs 官方未公开乌尔都语(ur-PK)的独立语音 SDK,但其 Web API 实际支持该语言的 TTS 合成。通过对官方 JS SDK&am…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

移动端Shell集成AI助手:ShellGPTMobile部署与实战指南
1. 项目概述:当ShellGPT遇见移动端如果你是一个重度命令行用户,同时又对AI助手(比如ChatGPT)的便利性爱不释手,那么你很可能面临一个尴尬的境地:在终端里敲命令时,突然需要AI帮忙解释一段日志、…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...