Python——IO编程
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。
比如你打开浏览器,访问新浪首页,浏览器这个程序就需要通过网络IO获取新浪的网页。浏览器首先会发送数据给新浪服务器,告诉它我想要首页的HTML,这个动作是往外发数据,叫Output,随后新浪服务器把网页发过来,这个动作是从外面接收数据,叫Input。所以,通常,程序完成IO操作会有Input和Output两个数据流。当然也有只用一个的情况,比如,从磁盘读取文件到内存,就只有Input操作,反过来,把数据写到磁盘文件里,就只是一个Output操作。
IO编程中,Stream(流)是一个很重要的概念,可以把流想象成一个水管,数据就是水管里的水,但是只能单向流动。Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去。对于浏览网页来说,浏览器和新浪服务器之间至少需要建立两根水管,才可以既能发数据,又能收数据。
由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题。举个例子来说,比如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可能需要10秒,怎么办呢?有两种办法:
第一种是CPU等着,也就是程序暂停执行后续代码,等100M的数据在10秒后写入磁盘,再接着往下执行,这种模式称为同步IO;
另一种方法是CPU不等待,只是告诉磁盘,“您老慢慢写,不着急,我接着干别的事去了”,于是,后续代码可以立刻接着执行,这种模式称为异步IO。
同步和异步的区别就在于是否等待IO执行的结果。好比你去麦当劳点餐,你说“来个汉堡”,服务员告诉你,对不起,汉堡要现做,需要等5分钟,于是你站在收银台前面等了5分钟,拿到汉堡再去逛商场,这是同步IO。
你说“来个汉堡”,服务员告诉你,汉堡需要等5分钟,你可以先去逛商场,等做好了,我们再通知你,这样你可以立刻去干别的事情(逛商场),这是异步IO。
很明显,使用异步IO来编写程序性能会远远高于同步IO,但是异步IO的缺点是编程模型复杂。想想看,你得知道什么时候通知你“汉堡做好了”,而通知你的方法也各不相同。如果是服务员跑过来找到你,这是回调模式,如果服务员发短信通知你,你就得不停地检查手机,这是轮询模式。总之,异步IO的复杂度远远高于同步IO。
操作IO的能力都是由操作系统提供的,每一种编程语言都会把操作系统提供的低级C接口封装起来方便使用,Python也不例外。我们后面会详细讨论Python的IO编程接口。
注意,本章的IO编程都是同步模式,异步IO由于复杂度太高,后续涉及到服务器端程序开发时我们再讨论。
文件读写
读写文件是最常见的IO操作。Python内置了读写文件的函数,用法和C是兼容的。
读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。
读文件
要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标示符:
>>> f = open('/Users/michael/test.txt', 'r')
标示符’r’表示读,这样,我们就成功地打开了一个文件。
如果文件不存在,open()函数就会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在:
>>> f=open('/Users/michael/notfound.txt', 'r')
Traceback (most recent call last):File "<stdin>", line 1, in <module>
FileNotFoundError: [Errno 2] No such file or directory: '/Users/michael/notfound.txt'
如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示:
>>> f.read()
'Hello, world!'
最后一步是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
>>> f.close()
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
try:f = open('/path/to/file', 'r')print(f.read())
finally:if f:f.close()
但是每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f:print(f.read())
这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便:
for line in f.readlines():print(line.strip()) # 把末尾的'\n'删掉
file-like Object
像open()函数返回的这种有个read()方法的对象,在Python中统称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义流等等。file-like Object不要求从特定类继承,只要写个read()方法就行。
StringIO就是在内存中创建的file-like Object,常用作临时缓冲。
二进制文件
前面讲的默认都是读取文本文件,并且是UTF-8编码的文本文件。要读取二进制文件,比如图片、视频等等,用'rb'模式打开文件即可:
>>> f = open('/Users/michael/test.jpg', 'rb')
>>> f.read()
b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节
字符编码
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
>>> f.read()
'测试'
遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore')
写文件
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
>>> f = open('/Users/michael/test.txt', 'w')
>>> f.write('Hello, world!')
>>> f.close()
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:f.write('Hello, world!')
要写入特定编码的文本文件,请给open()函数传入encoding参数,将字符串自动转换成指定编码。
细心的童鞋会发现,以'w'模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。如果我们希望追加到文件末尾怎么办?可以传入'a'以追加(append)模式写入。
所有模式的定义及含义可以参考Python的官方文档。
练习
请将本地一个文本文件读为一个str并打印出来:
fpath = '/etc/timezone'with open(fpath, 'r') as f:s = f.read()print(s)
小结
在Python中,文件读写是通过open()函数打开的文件对象完成的。使用with语句操作文件IO是个好习惯。
StringIO和BytesIO
StringIO
很多时候,数据读写不一定是文件,也可以在内存中读写。
StringIO顾名思义就是在内存中读写str。
要把str写入StringIO,我们需要先创建一个StringIO,然后,像文件一样写入即可:
>>> from io import StringIO
>>> f = StringIO()
>>> f.write('hello')
5
>>> f.write(' ')
1
>>> f.write('world!')
6
>>> print(f.getvalue())
hello world!
getvalue()方法用于获得写入后的str。
要读取StringIO,可以用一个str初始化StringIO,然后,像读文件一样读取:
>>> from io import StringIO
>>> f = StringIO('Hello!\nHi!\nGoodbye!')
>>> while True:
... s = f.readline()
... if s == '':
... break
... print(s.strip())
...
Hello!
Hi!
Goodbye!
BytesIO
StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
>>> from io import BytesIO
>>> f = BytesIO()
>>> f.write('中文'.encode('utf-8'))
6
>>> print(f.getvalue())
b'\xe4\xb8\xad\xe6\x96\x87'
请注意,写入的不是str,而是经过UTF-8编码的bytes。
和StringIO类似,可以用一个bytes初始化BytesIO,然后,像读文件一样读取:
>>> from io import BytesIO
>>> f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
>>> f.read()
b'\xe4\xb8\xad\xe6\x96\x87'
小结
StringIO和BytesIO是在内存中操作str和bytes的方法,使得和读写文件具有一致的接口。
操作文件和目录
如果我们要操作文件、目录,可以在命令行下面输入操作系统提供的各种命令来完成。比如dir、cp等命令。
如果要在Python程序中执行这些目录和文件的操作怎么办?其实操作系统提供的命令只是简单地调用了操作系统提供的接口函数,Python内置的os模块也可以直接调用操作系统提供的接口函数。
打开Python交互式命令行,我们来看看如何使用os模块的基本功能:
>>> import os
>>> os.name # 操作系统类型
'posix'
如果是posix,说明系统是Linux、Unix或Mac OS X,如果是nt,就是Windows系统。
要获取详细的系统信息,可以调用uname()函数:
>>> os.uname()
posix.uname_result(sysname='Darwin', nodename='MichaelMacPro.local', release='14.3.0', version='Darwin Kernel Version 14.3.0: Mon Mar 23 11:59:05 PDT 2015; root:xnu-2782.20.48~5/RELEASE_X86_64', machine='x86_64')
注意uname()函数在Windows上不提供,也就是说,os模块的某些函数是跟操作系统相关的。
环境变量
在操作系统中定义的环境变量,全部保存在os.environ这个变量中,可以直接查看:
>>> os.environ
environ({'VERSIONER_PYTHON_PREFER_32_BIT': 'no', 'TERM_PROGRAM_VERSION': '326', 'LOGNAME': 'michael', 'USER': 'michael', 'PATH': '/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/mysql/bin', ...})
要获取某个环境变量的值,可以调用os.environ.get('key'):
>>> os.environ.get('PATH')
'/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/mysql/bin'
>>> os.environ.get('x', 'default')
'default'
操作文件和目录
操作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中,这一点要注意一下。查看、创建和删除目录可以这么调用:
# 查看当前目录的绝对路径:
>>> os.path.abspath('.')
'/Users/michael'
# 在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
>>> os.path.join('/Users/michael', 'testdir')
'/Users/michael/testdir'
# 然后创建一个目录:
>>> os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
>>> os.rmdir('/Users/michael/testdir')
把两个路径合成一个时,不要直接拼字符串,而要通过os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。在Linux/Unix/Mac下,os.path.join()返回这样的字符串:
part-1/part-2
而Windows下会返回这样的字符串:
part-1\part-2
同样的道理,要拆分路径时,也不要直接去拆字符串,而要通过os.path.split()函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名:
>>> os.path.split('/Users/michael/testdir/file.txt')
('/Users/michael/testdir', 'file.txt')
os.path.splitext()可以直接让你得到文件扩展名,很多时候非常方便:
>>> os.path.splitext('/path/to/file.txt')
('/path/to/file', '.txt')
这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
文件操作使用下面的函数。假定当前目录下有一个test.txt文件:
# 对文件重命名:
>>> os.rename('test.txt', 'test.py')
# 删掉文件:
>>> os.remove('test.py')
但是复制文件的函数居然在os模块中不存在!原因是复制文件并非由操作系统提供的系统调用。理论上讲,我们通过上一节的读写文件可以完成文件复制,只不过要多写很多代码。
幸运的是shutil模块提供了copyfile()的函数,你还可以在shutil模块中找到很多实用函数,它们可以看做是os模块的补充。
最后看看如何利用Python的特性来过滤文件。比如我们要列出当前目录下的所有目录,只需要一行代码:
>>> [x for x in os.listdir('.') if os.path.isdir(x)]
['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Applications', 'Desktop', ...]
要列出所有的.py文件,也只需一行代码:
>>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']
小结
Python的os模块封装了操作系统的目录和文件操作,要注意这些函数有的在os模块中,有的在os.path模块中。
练习
- 利用
os模块编写一个能实现dir -l输出的程序。
# -*- coding: utf-8 -*-import os
import stat
import timedef list_dir_long_format():# 获取当前目录下的所有文件和目录名entries = os.listdir('.')for entry in entries:# 获取文件详细信息full_path = os.path.join('.', entry)file_stat = os.stat(full_path)# 获取文件权限permissions = stat.filemode(file_stat.st_mode)# 获取文件所有者uid = file_stat.st_uiduser = os.path.basename(f'/proc/{uid}')# 获取文件大小size = file_stat.st_size# 获取文件最后修改时间mtime = file_stat.st_mtime# 格式化时间戳为可读的日期时间字符串time_str = time.ctime(mtime)# 打印文件信息print(f"{permissions} {user} {size} {time_str} {entry}")if __name__ == '__main__':list_dir_long_format()
- 编写一个程序,能在当前目录以及当前目录的所有子目录下查找文件名包含指定字符串的文件,并打印出相对路径。
# -*- coding: utf-8 -*-import osdef find_files_by_name(root_dir, search_name):for root, dirs, files in os.walk(root_dir):for file in files:if search_name in file:# 打印文件的相对路径print(os.path.relpath(os.path.join(root, file), root_dir))# 要搜索的目录(当前目录)
current_directory = '.'
# 要搜索的文件名字符串
search_string = input("Enter the file name string to search for: ")# 调用函数进行搜索
find_files_by_name(current_directory, search_string)
序列化
在程序运行的过程中,所有的变量都是在内存中,比如,定义一个dict:
d = dict(name='Bob', age=20, score=88)
可以随时修改变量,比如把name改成'Bill',但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的'Bill'存储到磁盘上,下次重新运行程序,变量又被初始化为'Bob'。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Python提供了pickle模块来实现序列化。
首先,我们尝试把一个对象序列化并写入文件:
>>> import pickle
>>> d = dict(name='Bob', age=20, score=88)
>>> pickle.dumps(d)
b'\x80\x03}q\x00(X\x03\x00\x00\x00ageq\x01K\x14X\x05\x00\x00\x00scoreq\x02KXX\x04\x00\x00\x00nameq\x03X\x03\x00\x00\x00Bobq\x04u.'
pickle.dumps()方法把任意对象序列化成一个bytes,然后,就可以把这个bytes写入文件。或者用另一个方法pickle.dump()直接把对象序列化后写入一个file-like Object:
>>> f = open('dump.txt', 'wb')
>>> pickle.dump(d, f)
>>> f.close()
看看写入的dump.txt文件,一堆乱七八糟的内容,这些都是Python保存的对象内部信息。
当我们要把对象从磁盘读到内存时,可以先把内容读到一个bytes,然后用pickle.loads()方法反序列化出对象,也可以直接用pickle.load()方法从一个file-like Object中直接反序列化出对象。我们打开另一个Python命令行来反序列化刚才保存的对象:
>>> f = open('dump.txt', 'rb')
>>> d = pickle.load(f)
>>> f.close()
>>> d
{'age': 20, 'score': 88, 'name': 'Bob'}
变量的内容又回来了!
当然,这个变量和原来的变量是完全不相干的对象,它们只是内容相同而已。
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
JSON
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
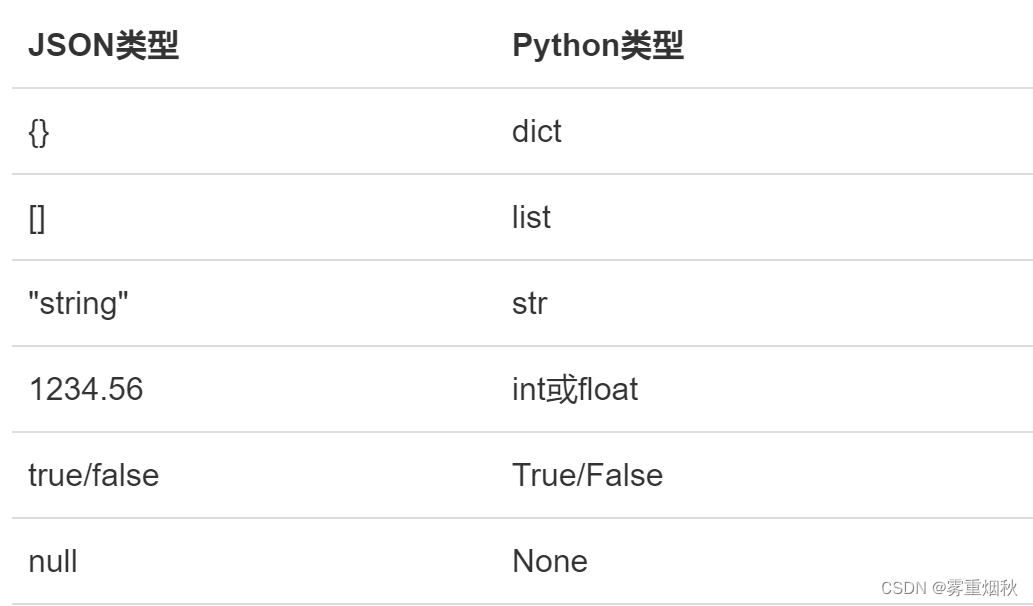
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换。我们先看看如何把Python对象变成一个JSON:
>>> import json
>>> d = dict(name='Bob', age=20, score=88)
>>> json.dumps(d)
'{"age": 20, "score": 88, "name": "Bob"}'
dumps()方法返回一个str,内容就是标准的JSON。类似的,dump()方法可以直接把JSON写入一个file-like Object。
要把JSON反序列化为Python对象,用loads()或者对应的load()方法,前者把JSON的字符串反序列化,后者从file-like Object中读取字符串并反序列化:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> json.loads(json_str)
{'age': 20, 'score': 88, 'name': 'Bob'}
由于JSON标准规定JSON编码是UTF-8,所以我们总是能正确地在Python的str与JSON的字符串之间转换。
JSON进阶
Python的dict对象可以直接序列化为JSON的{},不过,很多时候,我们更喜欢用class表示对象,比如定义Student类,然后序列化:
import jsonclass Student(object):def __init__(self, name, age, score):self.name = nameself.age = ageself.score = scores = Student('Bob', 20, 88)
print(json.dumps(s))
运行代码,毫不留情地得到一个TypeError:
Traceback (most recent call last):...
TypeError: <__main__.Student object at 0x10603cc50> is not JSON serializable
错误的原因是Student对象不是一个可序列化为JSON的对象。
如果连class的实例对象都无法序列化为JSON,这肯定不合理!
别急,我们仔细看看dumps()方法的参数列表,可以发现,除了第一个必须的obj参数外,dumps()方法还提供了一大堆的可选参数:
https://docs.python.org/3/library/json.html#json.dumps
这些可选参数就是让我们来定制JSON序列化。前面的代码之所以无法把Student类实例序列化为JSON,是因为默认情况下,dumps()方法不知道如何将Student实例变为一个JSON的{}对象。
可选参数default就是把任意一个对象变成一个可序列为JSON的对象,我们只需要为Student专门写一个转换函数,再把函数传进去即可:
def student2dict(std):return {'name': std.name,'age': std.age,'score': std.score}
这样,Student实例首先被student2dict()函数转换成dict,然后再被顺利序列化为JSON:
>>> print(json.dumps(s, default=student2dict))
{"age": 20, "name": "Bob", "score": 88}
不过,下次如果遇到一个Teacher类的实例,照样无法序列化为JSON。我们可以偷个懒,把任意class的实例变为dict:
print(json.dumps(s, default=lambda obj: obj.__dict__))
因为通常class的实例都有一个__dict__属性,它就是一个dict,用来存储实例变量。也有少数例外,比如定义了__slots__的class。
同样的道理,如果我们要把JSON反序列化为一个Student对象实例,loads()方法首先转换出一个dict对象,然后,我们传入的object_hook函数负责把dict转换为Student实例:
def dict2student(d):return Student(d['name'], d['age'], d['score'])
运行结果如下:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> print(json.loads(json_str, object_hook=dict2student))
<__main__.Student object at 0x10cd3c190>
打印出的是反序列化的Student实例对象。
练习
对中文进行JSON序列化时,json.dumps()提供了一个ensure_ascii参数,观察该参数对结果的影响:
根据官方文档:
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
这个ensure_ascii参数一直是True,If ensure_ascii is true (the default), the output is guaranteed to have all incoming non-ASCII characters escaped. If ensure_ascii is false, these characters will be output as-is.(ensure_ascii参数决定了序列化时是否将所有非ASCII字符转换为\uXXXX形式的Unicode转义序列。如果你将它设置为False,json.dumps()将尝试保留这些字符的原始编码,而不是将它们转换为Unicode转义序列。)
# -*- coding: utf-8 -*-import jsonobj = dict(name='小明', age=20)
# s = json.dumps(obj, ensure_ascii=True)
s = json.dumps(obj)print(s)s = json.dumps(obj, ensure_ascii=False)print(s)
结果:
{"name": "\u5c0f\u660e", "age": 20}
{"name": "小明", "age": 20}
小结
Python语言特定的序列化模块是pickle,但如果要把序列化搞得更通用、更符合Web标准,就可以使用json模块。
json模块的dumps()和loads()函数是定义得非常好的接口的典范。当我们使用时,只需要传入一个必须的参数。但是,当默认的序列化或反序列机制不满足我们的要求时,我们又可以传入更多的参数来定制序列化或反序列化的规则,既做到了接口简单易用,又做到了充分的扩展性和灵活性。
参考自https://www.liaoxuefeng.com/
相关文章:
Python——IO编程
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。 比如你打开浏览器,访问新浪…...
什么是网络端口?为什么会有高危端口?
一、什么是网络端口? 网络技术中的端口默认指的是TCP/IP协议中的服务端口,一共有0-65535个端口,比如我们最常见的端口是80端口默认访问网站的端口就是80,你直接在浏览器打开,会发现浏览器默认把80去掉,就是…...
CleanMyMac X v4.14.6中文破解版,让您的电脑像新的一样
小编给您带来CleanMyMac X v4.14.6中文破解版,CleanMyMac X破解版是应用在MacOS上的一款Mac系统清理优化工具,使用cleanmymac x 中文破解版只需两个简单步骤就可以把系统里那些乱七八糟的无用文件统统清理掉,节省宝贵的磁盘空间。 CleanMyMa…...
LeetCode 235. 二叉搜索树的最近公共祖先
LeetCode 235. 二叉搜索树的最近公共祖先 1、题目 题目链接:235. 二叉搜索树的最近公共祖先 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表…...
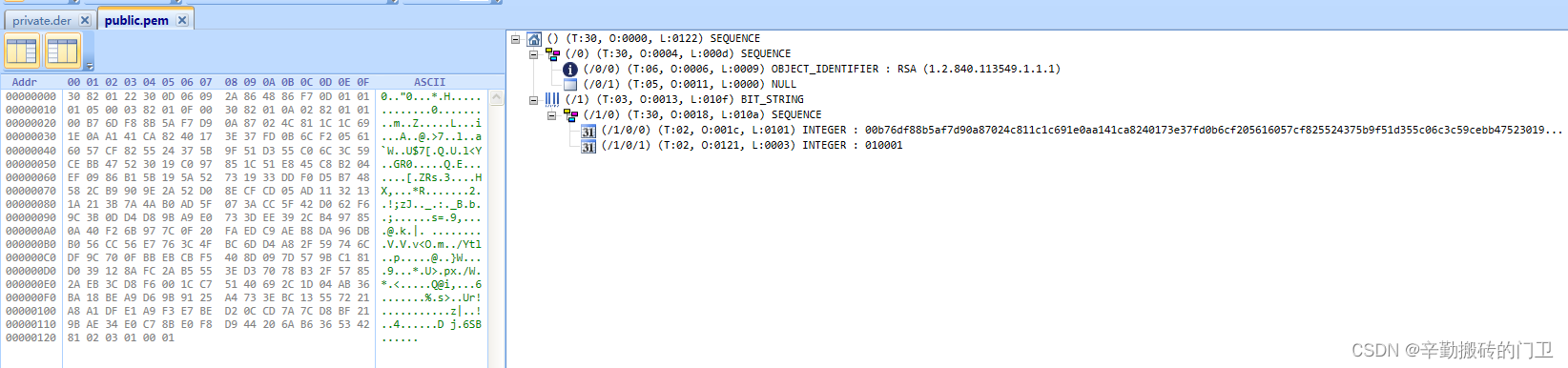
基于ASN.1的RSA算法公私钥存储格式解读
1.概述 RFC5958主要定义非对称密钥的封装语法,RFC5958用于替代RFC5208。非对称算法会涉及到1对公私钥,例如按照RSA算法,公钥是n和e,私钥是d和n。当需要将公私钥保存到文件时,需按照一定的格式保存。本文主要定义公私钥…...

RS2227XN功能和参数介绍及PDF资料
RS2227XN是一款模拟开关/多路复用器 品牌: RUNIC(润石) 封装: MSOP-10 描述: USB2.0高速模拟开关 开关电路: 双刀双掷(DPDT) 通道数: 2 工作电压: 1.8V~5.5V 导通电阻(RonVCC): 10Ω 功能:模拟开关/多路复用器 USB2.0高速模拟开关 工作电压范围:1.8V ~ 5…...

机器人非线性阻抗控制系统
机器人非线性控制系统本质上是一个复杂的控制系统,其状态变量和输出变量相对于输入变量的运动特性不能用线性关系来描述。这种系统的形成基于两类原因:一是被控系统中包含有不能忽略的非线性因素,二是为提高控制性能或简化控制系统结构而人为…...
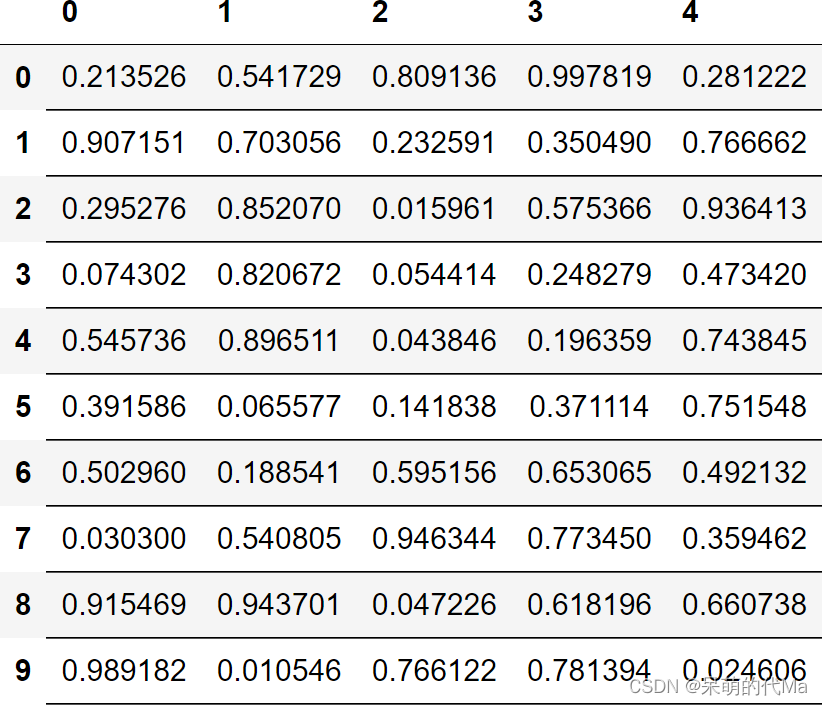
pandas style添加表格边框,或是只添加下边框等自定义边框样式设置
添加表格边框 可以使用如下程序添加表格: import dataframe_image as dfi import pandas as pd import numpy as npdf pd.DataFrame(np.random.random(size(10, 5))) df_style df.style.set_properties(**{text-align: center,border-color: black,border-width…...

OpenHarmony 3GPP协议开发深度剖析——一文读懂RIL
市面上关于终端(手机)操作系统在 3GPP 协议开发的内容太少了,即使 Android 相关的学习文档都很少,Android 协议开发书籍我是没有见过的。可能是市场需求的缘故吧,现在市场上还是前后端软件开发从业人员最多,…...
windows部署腾讯tmagic-editor02-Runtime
创建editor项目 将上一教程中的hello-world复制过来,改名hello-editor 创建runtime项目 和hello-editor同级 pnpm create vite删除src/components/HelloWorld.vue 按钮需要用的ts types依赖 pnpm add tmagic/schema tmagic/stage实现runtime 将hello-editor中…...
 函数的构建细节)
“分块”算法的基本要素及 build() 函数的构建细节
【“分块”算法知识点】 ● 分块是用线段树的分区思想改良的暴力法。代码比线段树简单。效率比普通暴力法高。分块适合求解 m=n=10^5 规模的问题,或 m*sqrt(n)≈10^7 的问题。其中,n 为元素个数,m 为操作次数。 ● “分块”算法的基本要素 (1)块的大小用 block 表示。通常…...
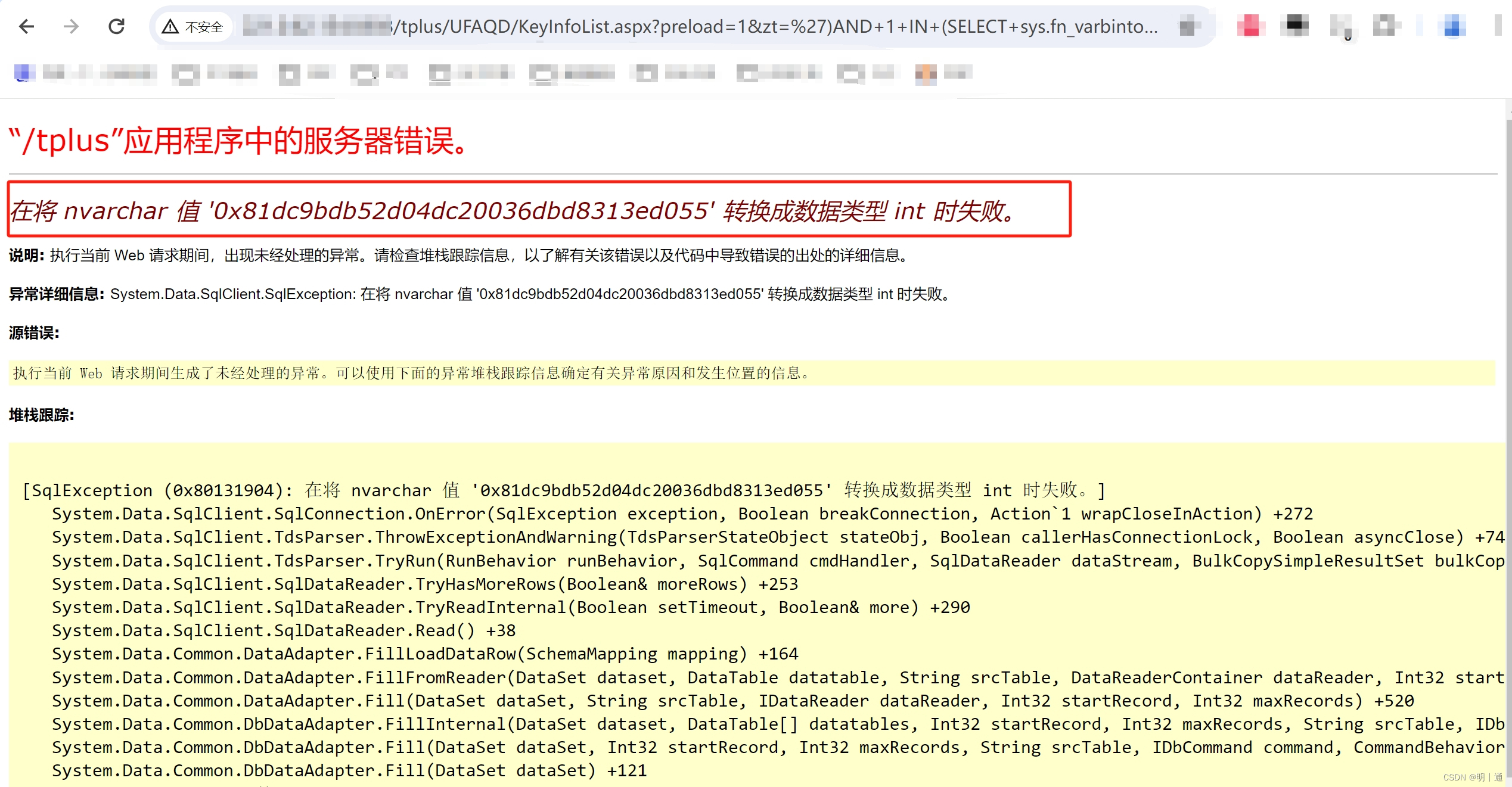
畅捷通TPlus keyEdit.aspx、KeyInfoList.aspx SQL注入漏洞复现
前言 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。 一、产…...
Ubuntu22 下配置 Qt5 环境
1. Qt 简介 Qt5 中的新功能,可以看到各个版本的情况Whats New in Qt 5 | Qt 5.15 Qt 源文件网址Index of /archive/qt 2. 安装 Qt Creator cd 到安装包所在目录,进行软件安装。赋予可执行权限,加上 sudo 权限进入安装,这样会安…...

普通人也能创业!轻资产短视频带货项目,引领普通人实现创业梦想
在这个信息爆炸的时代,创业似乎成为了越来越多人的梦想。然而,传统的创业模式 keJ0277 往往伴随着高昂的资金投入和复杂的管理流程,让许多普通人望而却步。然而,现在有一种轻资产短视频带货项目正在悄然兴起,它以其低…...
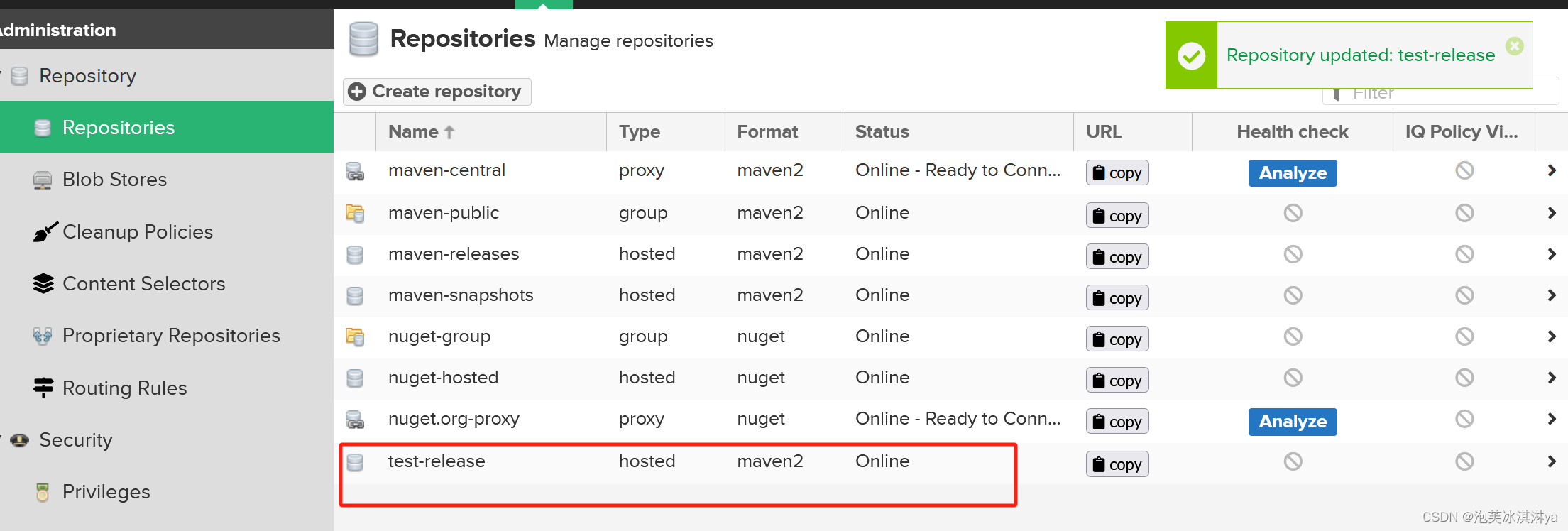
【Maven】Nexus简单使用
1、安装配置介绍Nexus私服: 安装配置指路上一篇详细教程博客 【Maven】Nexus私服简介_下载安装_登录-CSDN博客 简单介绍原有仓库类型: proxy代理仓库:代理远程仓库,访问全球中央仓库或其他公共仓库,将资源存储在私…...

winform嵌入excel 设置父窗体分辨率不是100% 嵌入excel分辨率变成双倍大小
在WinForms应用程序中嵌入Excel时,遇到分辨率问题可能是由于DPI缩放导致的。Windows 10及更高版本默认启用了DPI缩放,以便在高分辨率显示器上显示更清晰的内容。这可能会导致嵌入的应用程序(如Excel)看起来变大或变小。 解决方案 …...

前端系列-4 promise与async/await与fetch/axios使用方式
背景: 本文介绍promise使用方式,以及以Promise为基础的async/await用法和fetch/axios使用方式,主要以案例的方式进行。 1.promise 1.1 promise介绍 javascript是单线程执行的,异步编程的本质是事件机制和函数回调。当执行阻塞…...

微信公众号自定义分销商城小程序源码系统 带完整的安装代码吧以及系统部署搭建教程
系统概述 微信公众号自定义分销商城小程序源码系统是一款功能强大的电商解决方案,它集成了商品管理、订单处理、支付接口、分销管理等多种功能。该系统支持自定义界面设计,商家可根据自身需求调整商城的页面布局和风格,打造独特的品牌形象。…...
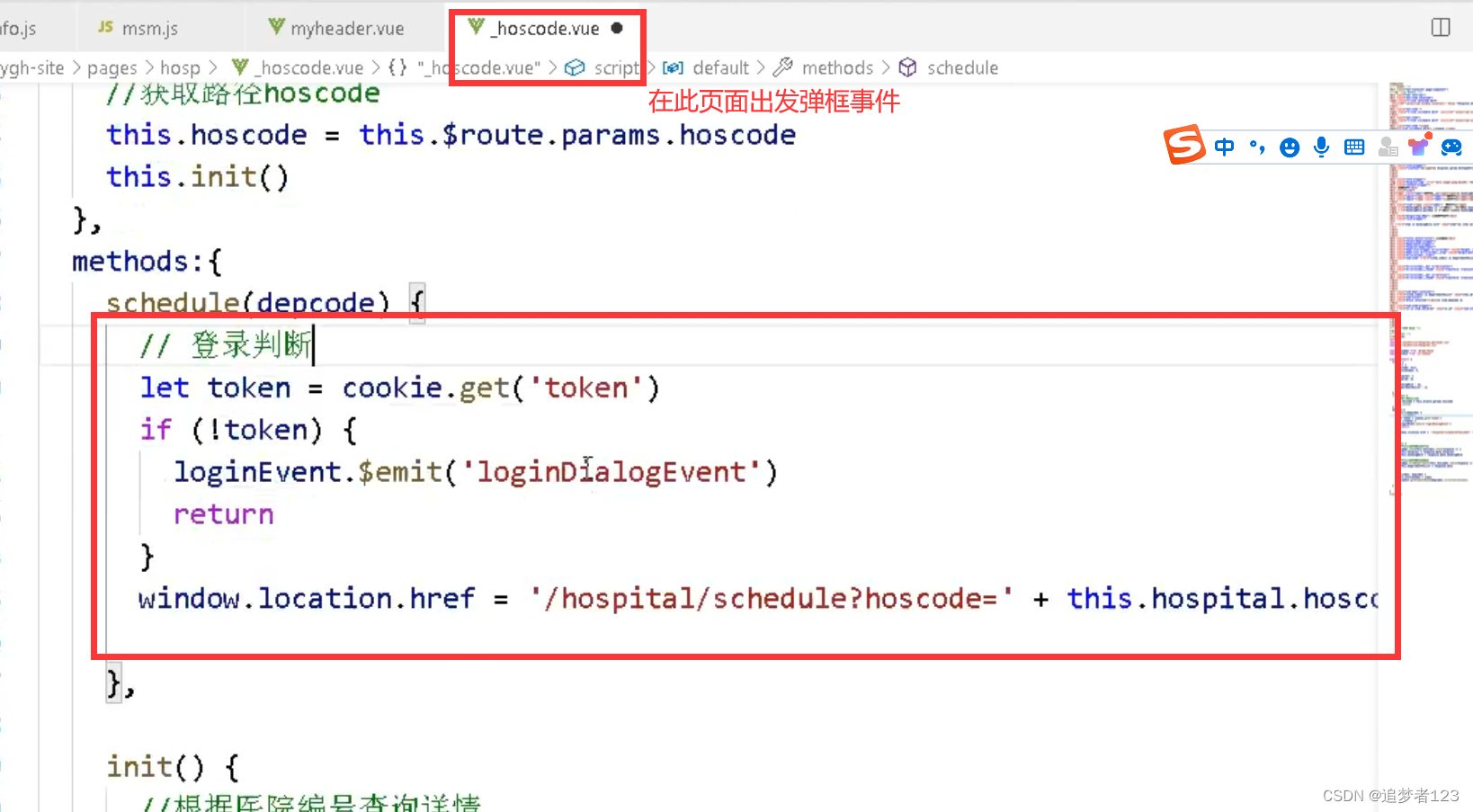
在另外一个页面,让另外一个页面弹框显示操作(调佣公共的弹框)vue
大概意思是,登录弹框在另外一个页面中,而当前页面不存在,在当前页面中判断如果token不存在,就弹框出登录的弹框 最后一行 window.location.href … 如果当前用户已登录,则执行后续操作(注意此处,可不要)...
羊毛-百度Comate领50京东E卡
给你分享一个AI编码助手——百度Comate!扫码参与抽红包活动,520宠粉!送京东卡!https://comate.baidu.com/?inviteCodeyysudp63 流程如下 点击:https://comate.baidu.com/?inviteCodeyysudp63添加链接描述 验证码…...

制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践
制造业数字鸿沟的终结者:零依赖STL到STEP转换引擎的技术突破与应用实践 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造与工业4.0的浪潮中,制造业企业面临着…...

从零到一:在个人PC上部署并集成ChatGLM-6B到Unity应用
1. 环境准备与模型下载 在个人PC上部署ChatGLM-6B需要先搞定三件事:硬件检查、软件环境搭建和模型文件获取。我的老款游戏本(i7-9750H RTX2060 6GB显存)实测可以流畅运行,关键在于正确的量化配置。 硬件检查要点: 显存…...

从8K游戏到HDR电影:拆解Xilinx HDMI 2.1 IP如何支持VRR、ALLM和动态HDR这些炫酷特性
从8K游戏到HDR电影:Xilinx HDMI 2.1 IP如何重塑视听体验 当PS5玩家在《战神:诸神黄昏》中感受到无撕裂的流畅战斗画面,或是家庭影院爱好者在《沙丘》中看到沙漠场景的每一粒沙粒都呈现出惊人的动态范围时,背后都离不开HDMI 2.1的关…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率
Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,错过对局接受、BP阶段犹豫不决、缺乏队友对手信息&a…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...