大数据技术原理(二):搭建hadoop伪分布式集群这一篇就够了
(实验一 搭建hadoop伪分布式)
--------------------------------------------------------------------------------------------------------------------------------
一、实验目的
1.理解Hadoop伪分布式的安装过程
实验内容涉及Hadoop平台的搭建和配置,旨在提高对大数据处理框架的理解和实践能力。通过完成本实验,将能够独立完成Hadoop伪分布式环境的安装和配置。
2.学会JDK安装和编译hadoop源码包
同时,通过手动编译hadoop源码包,还将能够更深入地了解Hadoop的内部原理和工作机制,通过解决问题并不断思考,具备根据需求进行扩展和定制的能力。
3.学会Hadoop伪分布式安装和参数配置
修改Hadoop的配置文件,包括core-site.xml、hdfs-site.xml等,根据实际需求设置相应的参数,启动Hadoop集群服务,检查各个节点的运行状态是否正常。
二、实验环境
1.VMware WorkStation Pro 16
2.Jdk 1.8.0_241
3.hadoop2.7.5
三、实验原理
1.Hadoop架构概述
Hadoop是一个开源的分布式计算框架,主要用于存储和处理大规模数据集。它采用了分布式存储和计算的方式,将大型数据集分割成多个数据块,并将这些数据块分布式存储到多台计算机节点上。
2.伪分布式的安装
伪分布式实验是在单台计算机上模拟多个Hadoop节点的环境。通过在一台计算机上安装Hadoop软件并进行适当的配置,可以模拟一个包含多个节点的Hadoop集群,并让这些节点之间相互通信和协作。
四、实验步骤与实验结果
(一)服务器基础环境准备
1.修改好虚拟机主机名
| vi /etc/hostname,将其改为node1 |

2.查看虚拟机IP地址
| ifconfig,查看显示IP地址为192.168.88.100 |

3.修改主机名和IP的映射关系
| vim /etc/hosts,输入:192.168.88.100 node1 与此同时,同步修改windows的C:\Windows\System32\drivers\etc\hosts文件 |

4.用主机名ping通:宿主机IP和外网IP
| ping 192.168.88.100 |

5.关闭虚拟机防火墙和windows防火墙
(1)关闭虚拟机防火墙
| #查看防火墙状态 systemctl status firewalld.service #关闭防火墙 systemctl stop firewalld.service #关闭防火墙开机启动 systemctl disable firewalld.service |

(2)关闭windows防火墙

(二)在虚拟机上安装JDK
1.上传jdk
| rz jdk-8u65-linux-x64.tar.gz,需要安装rz命令(yum install -y lrzsz) |
2.解压jdk
| tar -zxvf jdk-8u65-linux-x64.tar.gz -C /export/server 其中,tar命令参数解释如下: -z:使用解压方式 -x:解压gz的文件 -v:显示解压信息 -f:带解压文件名 -C:指定解压路径 |
3.将java添加到环境变量中
| vim /etc/profile #在文件最后添加 export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/ |

4.刷新配置文件
| source /etc/profile |

5.查看jdk安装情况
| java -version |

(三)重新编译hadoop
1.官方网站下载源码包
| Index of /dist |
2.下载对应版本编译包
| https://archive.apache.org/dist/hadoop/common/ hadoop-2.7.5-src.tar.gz //source 源码包 hadoop-2.7.5.tar.gz //官方编译后安装包 |
3.进行hadoop源码包编译
| 在源码的根目录下有编译相关的文件BUILDING.txt 指导如何编译。 使用maven进行编译 联网jar. |
4.编译环境进行目录创建
| mkdir -p /export/server |
5.安装编译相关的依赖
| yum install gcc gcc-c++ make autoconf automake libtool curl lzo-devel zlib-devel openssl openssl-devel ncurses-devel snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst zlib -y yum install -y doxygen cyrus-sasl* saslwrapper-devel* |
6.手动安装cmake
| #yum卸载已安装cmake 版本低 yum erase cmake #解压 tar zxvf CMake-3.19.4.tar.gz #编译安装 cd /export/server/CMake-3.19.4 ./configure make && make install #验证 [root@node1 ~]# cmake -version cmake version 3.19.4 #如果没有正确显示版本 请断开SSH连接 重写登录 |
7.手动安装snappy
| #卸载已经安装的 rm -rf /usr/local/lib/libsnappy* rm -rf /lib64/libsnappy* #上传解压 tar zxvf snappy-1.1.3.tar.gz #编译安装 cd /export/server/snappy-1.1.3 ./configure make && make install #验证是否安装 [root@node1 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy -rw-r--r-- 1 root root 511K Nov 4 17:13 libsnappy.a -rwxr-xr-x 1 root root 955 Nov 4 17:13 libsnappy.la lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x 1 root root 253K Nov 4 17:13 libsnappy.so.1.3.0 |
8.安装maven
| #解压安装包 tar zxvf apache-maven-3.5.4-bin.tar.gz #配置环境变量 vim /etc/profile export MAVEN_HOME=/export/server/apache-maven-3.5.4 export MAVEN_OPTS="-Xms4096m -Xmx4096m" export PATH=:$MAVEN_HOME/bin:$PATH source /etc/profile #验证是否安装成功 [root@node1 ~]# mvn -v Apache Maven 3.5.4 #添加maven 阿里云仓库地址 加快国内编译速度 vim /export/server/apache-maven-3.5.4/conf/settings.xml <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> |
9.安装ProtocolBuffer 3.7.1
| #卸载之前版本的protobuf #解压 tar zxvf protobuf-3.7.1.tar.gz #编译安装 cd /export/server/protobuf-3.7.1 ./autogen.sh ./configure make && make install #验证是否安装成功 [root@node1 protobuf-3.7.1]# protoc --version libprotoc 3.7.1 |
10.编译hadoop
| #上传解压源码包 tar zxvf hadoop-2.7.5-src.tar.gz #编译 cd /root/hadoop-2.7.5-src mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib #参数说明: Pdist,native :把重新编译生成的hadoop动态库; DskipTests :跳过测试 Dtar :最后把文件以tar打包 Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】 Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径 |
11.编译后安装包路径
| /root/hadoop-2.7.5-src/hadoop-dist/target |

(四)安装hadoop伪分布式
1.上传Hadoop安装包
| hadoop-2.7.5-Centos7-64-with-snappy.tar.gz tar zxvf hadoop-2.7.5-Centos7-64-with-snappy.tar.gz -C /export/server/ |

2.切换到配置文件目录
| cd /export/server/hadoop-2.7.5/etc/hadoop |

3.修改hadoop-env.sh
| export JAVA_HOME=/export/server/jdk1.8.0_241 #文件最后添加 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |

4.修改core-site.xml
| <!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-2.7.5</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |

5.修改hdfs-site.xml
| <configuration> <!-- 指定SecondaryNameNode的主机和端口 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node1:50090</value> </property> <!-- 指定namenode的页面访问地址和端口 --> <property> <name>dfs.namenode.http-address</name> <value>node1:50070</value> </property> <!-- 指定namenode元数据的存放位置 --> <property> <name>dfs.namenode.name.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas</value> </property> <!-- 定义datanode数据存储的节点位置 --> <property> <name>dfs.datanode.data.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas</value> </property> <!-- 定义namenode的edits文件存放路径 --> <property> <name>dfs.namenode.edits.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/nn/edits</value> </property> <!-- 配置检查点目录 --> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/snn/name</value> </property> <property> <name>dfs.namenode.checkpoint.edits.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value> </property> <!-- 文件切片的副本个数--> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 设置HDFS的文件权限--> <property> <name>dfs.permissions</name> <value>false</value> </property> <!-- 设置一个文件切片的大小:128M--> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> <!-- 指定DataNode的节点配置文件 --> <property> <name> dfs.hosts </name> <value>/export/server/hadoop-2.7.5/etc/hadoop/slaves </value> </property> </configuration> |

6.修改mapred-site.xml
| <!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> |

7.修改yarn-site.xml
| <!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 保存的时间7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |

8.修改slaves文件(3.0版本之后更名为works文件)
| cd /export/server/hadoop-2.7.5/etc/hadoop |

9.将hadoop添加到环境变量
| vim /etc/proflie export HADOOP_HOME=/export/server/hadoop-2.7.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile |

10.首次启动hadoop(格式化namenode)
| hdfs namenode -format |
(五)hadoop安装后初体验
1.启动hadoop软件
| # 切换到启动脚本文件目录 |

2.启动hdfs的UI界面
| # 在浏览器上输入 |

3.在hdfs上进行文件操作
| # linux终端上进行命令行 hadoop fs -ls / |


4.运行mapreduce程序
| # 准备wordcount.txt文件,文件内容如下: hello hello world world hadoop hadoop hello world hello flume hadoop hive hive kafka flume storm hive oozie # 在hdfs上创建文件目录 hadoop fs -mkdir -p /wordcount/input hadoop fs -put ./wordcount.txt /wordcount/input # 切换到hadoop自带的mapreduce的jar包目录 cd /export/server/hadoop-2.7.5/share/hadoop/mapreduce # 执行wordcount的mapreduce计算 hadoop jar hadoop-mapreduce-examples-2.7.5.jar wordcount /wordcount/input /wordcount/output 第一个参数:wordcount表示执行单词统计 第二个参数:指定输入文件的路径 第三个参数:指定输出结果的路径(该路径不能已存在) |



5.关闭hadoop软件
| # 切换到启动脚本文件目录 |

5.实验完毕,关闭虚拟机
|
shutdown -h now
|

五、实验总结
(一)发现问题与解决问题
1.编译hadoop出现警告消息

根据报错信息来看,编译hadoop过程中出现了找不到SASL库的错误。
解决方法如下:
|
|
2.本地上传文件到linux上出现乱码
根据网上资料显示,当使用rz命令上传文件出现乱码时,可以采取添加参数。
解决方法如下:
| 输入rz -be 即可解决 rz命令的参数说明: -a, –ascii -b, –binary 用binary的方式上传下载,不解释字符为 ascii -e, –escape 强制escape 所有控制字符,比如 Ctrl+x,DEL 等 -ary –o-sync -a 表示使用ascii码格式传输文件,如果是Dos格式的文件,会转换为unix格式 -r 使用 Crash recovery mode. 即文件传输中断会重传 -y 表示文件已存在的时候会覆盖 –o-sync 采用同步写模式,以处理从缓存写到磁盘时中断丢失的情况 |
3.使用vim编辑器编辑文件粘贴失效
当使用vim编辑器进行粘贴配置文件信息时,常常粘贴的内容变成注释且很难取消,原因是vim编辑器没有处于粘贴模式(paste)。
解决方法如下:
| 令vim编辑器处于命令模式(ESC键+冒号):set paste 当粘贴结束后,set nopaste即可退出该模式。 |
4.伪分布式的集群时间不统一
当出现时间不统一的情况下,需要与阿里云服务器统一时间。
解决方法如下:
| 集群同步时间命令:ntpdate ntp5.aliyun.com |
5.集群安全模式下不能修改删除
伪分布式集群误操作使得处于安全模式,需要退出安全模式才可以进行文件操作。
解决方法如下:
| hadoop dfsadmin -safemode leave |
6.hadoop中hdfs的9870端口用不了
通过查看版本差异,发现hadoop3.0以下的版本中默认端口号不是9870端口
解决方法如下:
| node1:50070 |
(二)总结实验与思考感悟
搭建Hadoop伪分布式集群是学习和理解Hadoop分布式计算框架的重要一步。
1.规划和准备
在开始搭建伪分布式集群之前,需要充分规划和准备工作。首先,了解Hadoop的基本概念和架构,对其运行原理有清晰的理解。然后,确定使用的操作系统、网络设置和硬件配置。确保操作系统满足Hadoop的最低要求,并且网络配置和硬件资源能够支持集群的需求。
2.安装和配置Hadoop
根据操作系统选择适当版本的Hadoop,下载并解压安装包。在安装过程中,需要进行一些关键配置,例如修改核心配置文件(如hadoop-env.sh、core-site.xml、hdfs-site.xml等),指定必要的路径、端口、日志目录等。此外,还要设置SSH免密登录,以便节点之间能够相互通信。在此过程中,需要仔细阅读官方文档,并参考示例配置进行调整。
3.单节点测试
在搭建伪分布式集群之前,可以先在单个节点上进行测试和调试。这样可以确保Hadoop的基本功能正常工作。在单节点测试中,需要验证HDFS文件系统的正常操作(如上传、下载、移动文件等),以及MapReduce任务的执行情况。通过这些测试可以熟悉Hadoop的命令和工作流程,并排查可能出现的问题。
4.集群部署
完成单节点测试后,可以将配置好的Hadoop复制到其他节点上,以搭建伪分布式集群。确保所有节点都有相同的软件版本和配置文件。在部署过程中,需要注意各个节点之间的通信,包括网络连接、防火墙设置、主机名解析等。确保集群节点之间能够互相访问,并且能够正常启动和停止Hadoop服务。
5.集群测试和优化
完成集群部署后,进行一系列的测试和性能优化工作。可以使用一些标准的Hadoop测试任务(如WordCount、Sort等)对集群进行压力测试。观察任务的执行时间、资源占用情况、数据分布等指标,根据结果进行性能调优,包括调整配置参数、增加节点、优化数据存储和计算等方面。此外,还应进行故障模拟和容错测试,确保集群在部分节点故障的情况下依然能够正常运行。
6.学习和扩展
搭建伪分布式集群不仅是为了实现一个运行的Hadoop环境,更重要的是学习和理解分布式计算的核心概念和机制。在搭建过程中,要积极探索和研究Hadoop的原理,理解其如何管理数据、调度任务、处理故障等。此外,还可以尝试扩展集群规模,增加节点数量,进行更大规模的数据处理和并行计算,以进一步提升对Hadoop的理解。
总结起来,搭建Hadoop伪分布式集群是一个学习和实践的过程。需要有足够的耐心和细心,仔细阅读官方文档和参考资料,并能够灵活应对可能出现的问题和挑战。通过这个过程,不仅可以构建一个可用的分布式计算环境,还能够深入理解Hadoop的工作原理和分布式系统的设计思想。
相关文章:
大数据技术原理(二):搭建hadoop伪分布式集群这一篇就够了
(实验一 搭建hadoop伪分布式) -------------------------------------------------------------------------------------------------------------------------------- 一、实验目的 1.理解Hadoop伪分布式的安装过程 实验内容涉及Hadoop平台的搭建和…...

中间件是什么?信创中间件有哪些牌子?哪家好用?
当今社会,中间件的重要性日益凸显,尤其是在信创背景下,选择适合的中间件产品对于推动企业数字化转型和升级具有重要意义。今天我们就来聊聊中间件是什么?信创中间件有哪些牌子?哪家好用?仅供参考哈…...

python实现520表白图案
今天是520哦,作为程序员有必要通过自己的专业知识来向你的爱人表达下你的爱意。那么python中怎么实现绘制520表白图案呢?这里给出方法: 1、使用图形库(如turtle) 使用turtle模块,你可以绘制各种形状和图案…...
【Linux】-Flink分布式内存计算集群部署[21]
注意: 本节的操作,需要前置准备好Hadoop生态集群,请先部署好Hadoop环境 简介 Flink同spark一样,是一款分布式内存计算引擎,可以支撑海量数据的分布式计算 Flink在大数据体系同样是明星产品,作为新一代的…...
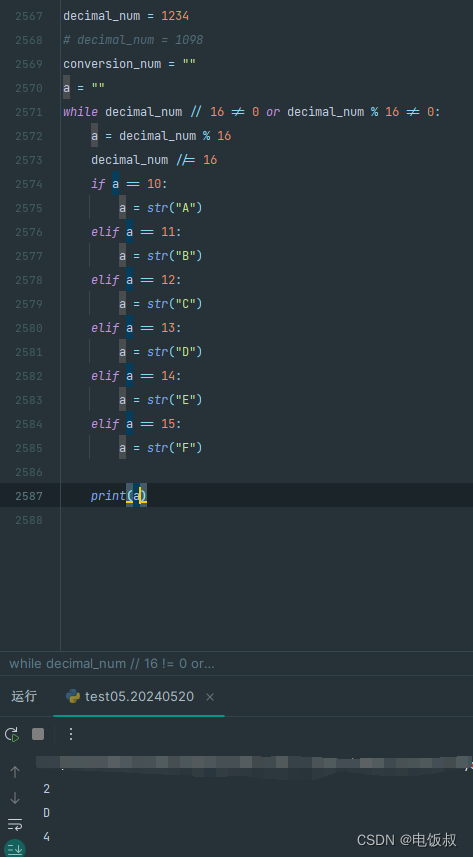
《python程序语言设计》2018版第5章第44题利用python循环进行十进制变十六进制,依然是44题的旧问题。倒着打出来的16进制
它似乎也有上一道题同样道问题。就是结果可能是倒着的。我还不能用超纲的办法。似乎上一个问题的难点又传到了下面 note: 我建立了一个method_a的变量干脆把整数除16的第一次放到循环外。 这样是不是可以解决呢? 我感觉还是在整除和除于的概念中,没有解脱…...

【HarmonyOS4学习笔记】《HarmonyOS4+NEXT星河版入门到企业级实战教程》课程学习笔记(九)
课程地址: 黑马程序员HarmonyOS4NEXT星河版入门到企业级实战教程,一套精通鸿蒙应用开发 (本篇笔记对应课程第 16 节) P16《15.ArkUI-状态管理-任务统计案例》 1、实现任务进度卡片 怎么让进度条和进度展示文本堆叠展示࿱…...

海山数据库(He3DB)数据仓库发展历史与架构演进:(一)传统数仓
从1990年代Bill Inmon提出数据仓库概念后经过四十多的发展,经历了早期的PC时代、互联网时代、移动互联网时代再到当前的云计算时代,但是数据仓库的构建目标基本没有变化,都是为了支持企业或者用户的决策分析,包括运营报表、企业营…...
简单快捷的图片格式转换工具:认识webp2jpg-online
经常写博客或记笔记的朋友们可能会碰到图床不支持的图片格式或图片太大需要压缩的情况。通常,我们会在浏览器中搜索在线图片格式转换器,但这些转换器往往伴有烦人的广告或要求登录,并且支持的转换格式有限。最近,我在浏览 GitHub …...
iptablese防火墙【SNAT和DNAT】
目录 1.SNAT策略及应用 1.1SNAT原理与应用 1.2 SNAT策略的工作原理 1.3 实验操练 2.DNAT策略 2.1 DNAT策略的概述 2.2 DNAT原理与应用 2.3 实验操练 1.SNAT策略及应用 1.1SNAT原理与应用 SNAT 应用环境:局域网主机共享单个公网IP地址接入Internet…...

IT行业现状与未来趋势
随着技术的不断进步,IT行业已成为推动全球经济和社会发展的关键力量。从云计算、大数据、人工智能到物联网、5G通信和区块链,这些技术正在重塑我们的生活和工作方式。你眼中IT行业的现状及未来发展趋势是怎么样的?无论您是行业领袖、技术专家…...

Snowy2.x 版本使用 Yaml
代码:https://gitee.com/xiaonuobase/snowy/tree/Snowy2.5.2/ 直接将 properties 转换成 yaml 那么你大概率会遇到下面报错: 然后你上网搜索,发现是 snakeyaml 版本的问题,1.x 版本的 snakeyaml 有安全隐患,要升级到…...
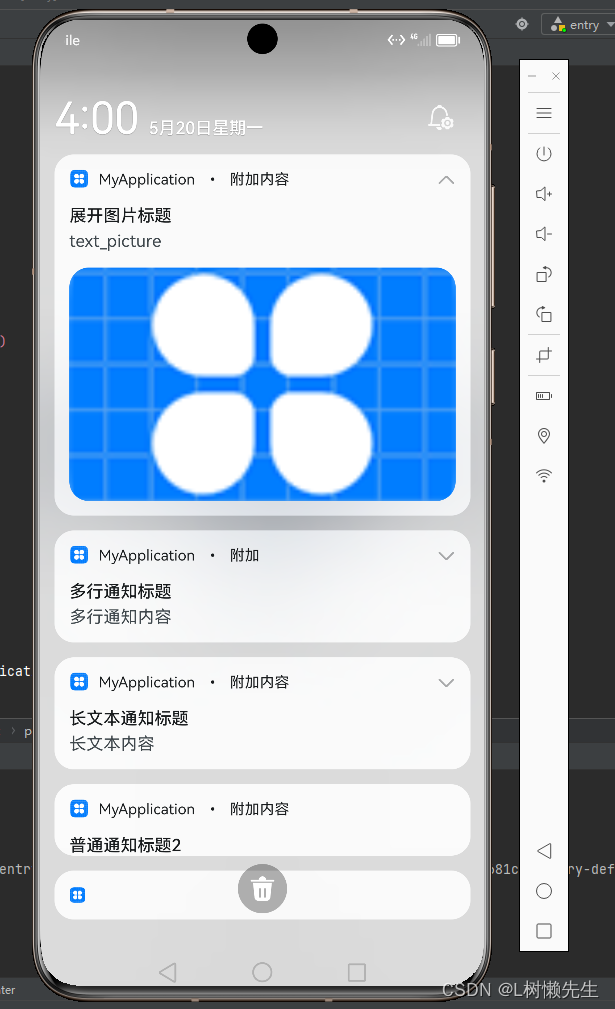
鸿蒙 DevEcoStudio:通知栏通知实现
【使用notificationManager实现通知栏功能】 【普通通知、长文本通知、多行通知、图片通知】 import notificationManager from ohos.notificationManager import image from ohos.multimedia.image Entry Component struct Index {State message: string Hello World// 将图…...

什么是网关鉴权及其在Spring Cloud Gateway中的实现
在现代微服务架构中,网关扮演着非常重要的角色,它是系统和外部世界之间的入口,负责路由请求、流量控制以及安全保护等任务。其中,网关鉴权是保障系统安全的重要环节之一。本文将深入介绍什么是网关鉴权,以及如何通过过…...

【机器学习与实现】支持向量机SVM
目录 一、SVM (Support Vector Machine) 概述(一)支持向量机SVM的主要特点(二)支持向量与间隔最大化(三)线性可分/不可分(四)软间隔 (soft margin) 与核技巧 (kernel trick)…...

当代人工智能三教父——深度学习三巨头
文章目录 引言 人物介绍 突出贡献 专业名词解释 引言 今天下午闲来无事翻阅了一下csdn首页的头条文章——《27 岁天才创始人 Joel Hellermark 分享了自己和“AI 教父” Geoffery Hinton 的最新采访》 感觉挺有意思,就从头到尾的看了一遍,里面有很多…...

Django项目从创建到开发以及数据库连接的主要步骤,精简实用
1、项目创建 安装命令:pip install django3 -i <https://pypi.tuna.tsinghua.edu.cn/simple>上述命令是使用清华镜像,安装django3在项目的创建目录执行命令:django-admin startproject 项目名称(英文)就可以在指…...

linux 命令 grep 排除 No such file or directory
du -sh * 2>&1 | grep -v "proc" command 2>&1 | grep -v "No such file or directory" 这里的 2>&1 是将错误输出重定向到标准输出,然后 grep -v "No such file or directory" 会过滤掉包含 &qu…...
Unity 滑动条(Slider)拖拽开始和结束、点击等事件的拓展功能
目录 前言 一、关于slider的监听事件 二、方案一 (无脚本版) 三、方案二 (继承slider脚本进行拓展) 四、方案三(外部脚本添加) 前言 前一段时间在使用这个功能,发现搜索出来的文章和脚本&…...
持续更新 Linux输出重定向 Linux通配符 Linux正则表达式 持续更新....)
Linux 学习知识 (简单易懂 )持续更新 Linux输出重定向 Linux通配符 Linux正则表达式 持续更新....
一.输出重定向 标准输出:是将信息输出在终端 标准错误输出:在执行命令的过程中所产生错误信息也是输出在终端标准输入:从键盘输入 1.1标准输出重定向 作用:将本来要显示在终端上的信息重定向到一个文件中 实现方法:…...
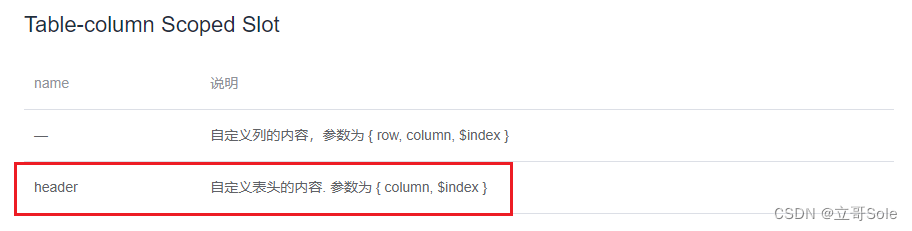
前端vue用el-table如何实现表头内容过长换行处理,实现换行效果
前端vue用el-table如何实现表头内容过长换行处理,实现换行效果 这是效果图 有两种方法,一种简易版本,一种万能方法,都是el-table,先看文档 表头标题是可以自定义的 方法一 label的解释写在代码里面了,这里会自动形成换…...

Purpur性能调优实战指南:7大核心优化方案深度解析
Purpur性能调优实战指南:7大核心优化方案深度解析 【免费下载链接】Purpur Purpur is a drop-in replacement for Paper servers designed for configurability, and new fun and exciting gameplay features. 项目地址: https://gitcode.com/gh_mirrors/pu/Purpu…...

AI智能体编排平台:从任务自动化到生态协作的架构与实践
1. 项目概述:一个面向AI编排与技能提升的生态协作平台最近在和一些做AI应用开发的朋友聊天,大家普遍有个痛点:现在AI工具和模型太多了,从大语言模型到图像生成,再到各种自动化脚本,每个都很强大,…...

解锁端侧智能:基于BigDL-LLM与Qwen-1.8B-Chat的CPU高效推理实践
1. 为什么要在CPU上部署大模型? 最近两年大模型技术发展迅猛,但大多数应用都依赖昂贵的GPU服务器。我在实际项目中发现,很多中小企业和个人开发者其实更需要能在普通电脑上运行的轻量化方案。这就是为什么基于CPU的大模型部署方案变得越来越…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

【低功耗蓝牙】④ 蓝牙MIDI协议:从ESP32 MicroPython代码到智能乐器DIY
1. 蓝牙MIDI协议入门:从音乐小白到智能乐器开发者 第一次听说蓝牙MIDI协议时,我正盯着桌上的ESP32开发板发呆。作为一个只会弹几个和弦的编程爱好者,完全没想到自己能用代码"演奏"音乐。蓝牙MIDI就像音乐世界的通用语言,…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

Java 大厂面试 200 题完整版含答案解析
前言本文整理了近两年从阿里、腾讯、字节、美团、京东、拼多多等大厂面试中高频出现的 200 道 Java 面试题,覆盖 Java 基础、集合、并发、JVM、Spring、MySQL、Redis、消息队列、分布式、场景设计 等核心模块,每题都附有简明扼要的答案解析,助…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...