jiebaNET中文分词器
最近我接手了一个有趣的需求,需要对用户评价进行分词,进行词频统计和情绪分析,并且根据词频权重制成词云图以供后台数据统计,于是我便引入了jieba分词器,但是我发现网上关于jiebaNET相关文档实在太少了,甚至连配置文件都很难搞清楚,所以我来大家介绍一下jiebaNET。
jiebaNET分词器介绍:
ieba.NET分词器是一款基于.NET平台的中文分词工具,它借鉴了jieba分词器的算法和思路,为.NET开发者提供了高效、准确的中文分词功能。jieba.NET分词器的主要功能和特点如下:
- 中文分词:jieba.NET分词器能够将中文文本按照词语进行切分,使得文本更易于被处理和分析。分词是中文文本处理的基础步骤,对于词频统计、文本分类、情感分析等任务具有重要意义。
- 多种分词模式:jieba.NET分词器支持多种分词模式,包括精确模式、全模式和搜索引擎模式。精确模式会将句子最精确地切分开,适合在文本分析时使用;全模式会将句子中所有成词的词语都扫描出来,速度非常快,但可能产生歧义;搜索引擎模式会在精确模式的基础上对长词再进行切分,提高召回率,适用于搜索引擎等场景。
- 自定义词典:jieba.NET分词器允许用户创建自定义词典,以确保特定词汇被正确切分。这对于处理特定行业或领域的文本非常有用,可以提高分词的准确性和效率。
- 高效快速:jieba.NET分词器采用了高效的分词算法和优化的数据结构,可以让分词速度非常快,能够满足大规模文本处理的需求。
- 接口友好:jieba.NET分词器提供了简洁易用的API接口,开发者可以方便地将其集成到自己的.NET项目中,进行中文文本处理和分析。
分词
字典文件存储在Resources中的dict.txt文件中,其中:
- “一个系列”是词条,也就是一个词语或者短语,是词典中存储的实际内容。
- “14”通常是这个词的词频,表示这个词在语料库中出现的次数或者重要程度。较高的词频意味着这个词在语料中较为常见。
- “m”代表词性标注,用来描述这个词的语法角色或词汇类别。在中文词性标注体系中,“m”通常代表“数词”,用于表示数量或序数的词语,比如“一个”、“两个”、“第一次”等
使用方法:
jieba.NET程序集中与分词相关的主要是JiebaSegmenter.Cut函数和JiebaSegmenter. CutForSearch函数,这两个函数都以字符串作为分词输入,不像之前盘古分词支持流式输入。
public IEnumerable<string> Cut(string text, bool cutAll = false, bool hmm = true)
public IEnumerable<string> CutForSearch(string text, bool hmm = true)
基于这两个函数,jieba.NET支持多种分词模式:全模式(把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义)、精确模式(试图将句子最精确地切开)、搜索引擎模式(在精确模式的基础上,对长词再次切分,提高召回率)。这三种方式的代码其实都比较简单,如下所示:
string textstr = txtContent.Text;txtResult.Text= textstr;var segmenter = new JiebaSegmenter();if (RadioButtonListType.SelectedValue == "jz"){var segments = segmenter.Cut(textstr,cutAll:false,hmm:false);txtResult.Text = "【精准模式】:" + string.Join("/ ", segments);//他/ 来到/ 上海交通大学}else if (RadioButtonListType.SelectedValue == "jzhmm"){var segments = segmenter.Cut(textstr, cutAll: false, hmm: false);txtResult.Text = "【精准模式、新词识别】:" + string.Join("/ ", segments);} //新词识别:"我/ 在/ 玩/ 某某/ 游戏/ 时/ 遇到/ 了/ 一个/ 名叫/ 小明/ 的/ 玩家/ 。"
//"某某"和"小明"可能是游戏中的特定角色或者玩家的ID,不在默认词典中。启用了新词识别功能后,结巴分词器可能会尝试将它们识别为新词,并进行分割else if (RadioButtonListType.SelectedValue == "cutAll"){var segments = segmenter.Cut(textstr, cutAll: true);txtResult.Text = "【全模式】:" + string.Join("/ ", segments);//【全模式】:他/ 来到/ 上海/ 上海交通大学/ 交通/ 大学}else if (RadioButtonListType.SelectedValue == "CutForSearch"){var segments = segmenter.CutForSearch(textstr, true);txtResult.Text = "【搜索引擎模式】:" + string.Join("/ ", segments);//他/ 毕业/ 于/ 上海/ 交通/ 大学/ 上海交通大学/ 机电/ 系/ ,/ 后来/ 在/ 一机部/ 上海/ 电器/ 科学/ 研究/ 研究所/ 工作}关键词提取
jieba.NET支持通过两种算法提取文本关键词:TF-IDF算法和TextRank算法,关于这两种算法的介绍详见参考文献10-11,在jieba.NET中对应的类为TfidfExtractor和TextRankExtractor,这两个分词都都支持调用ExtractTags和ExtractTagsWithWeight函数,前者默认返回前20个关键词,后者还附带每个关键词的权重。
权重逆文档频率存储在Resources/idf.txt文件中:如下图所示:

代码如下:
//不带权重txtResult.Text = String.Empty;using (TextReader tr = File.OpenText(txtPath.Text)){TfidfExtractor extractor = new TfidfExtractor();var keywords=extractor.ExtractTags(tr.ReadToEnd());txtResult.Text = string.Join("/ ", keywords);}//带权重txtResult.Text = String.Empty;using (TextReader tr = File.OpenText(txtPath.Text)){TfidfExtractor extractor = new TfidfExtractor();IEnumerable<WordWeightPair> results = extractor.ExtractTagsWithWeight(tr.ReadToEnd());foreach (WordWeightPair p in results){txtResult.Text += p.Word + "," + p.Weight.ToString()+ "\r\n";} }
TextRankExtractor类的示例代码及运行效果如下所示,对比可以看出这两种算法的返回结果还是存在差异:
//不带权重txtResult.Text = String.Empty;using (TextReader tr = File.OpenText(txtPath.Text)){TextRankExtractorextractor = new TextRankExtractor();var keywords=extractor.ExtractTags(tr.ReadToEnd());txtResult.Text = string.Join("/ ", keywords);}//带权重txtResult.Text = String.Empty;using (TextReader tr = File.OpenText(txtPath.Text)){TextRankExtractorextractor = new TextRankExtractor();IEnumerable<WordWeightPair> results = extractor.ExtractTagsWithWeight(tr.ReadToEnd());foreach (WordWeightPair p in results){txtResult.Text += p.Word + "," + p.Weight.ToString()+ "\r\n";} }
并行分词
"并行分词" 意味着可以同时处理多个文本或文本集合的分词任务,以提高分词速度和效率。在处理大量文本数据时特别有用,可以利用多核处理器的并行能力,加速分词过程。
JiebaSegmenter类的CutInParallel和CutForSearchInParallel函数支持并行分词
- CutInParallel: 这个函数用于普通的分词任务。它可以同时处理一个字符串集合或单个字符串,并将其分词后返回结果。如果输入是单个字符串,Jieba.NET 会自动将其按行转换为字符串集合,然后并行进行分词处理。
- CutForSearchInParallel: 这个函数用于搜索引擎模式的分词任务。类似于 CutInParallel,它也支持并行处理,但会采用搜索引擎模式进行分词,以适应搜索引擎等应用场景的需求。
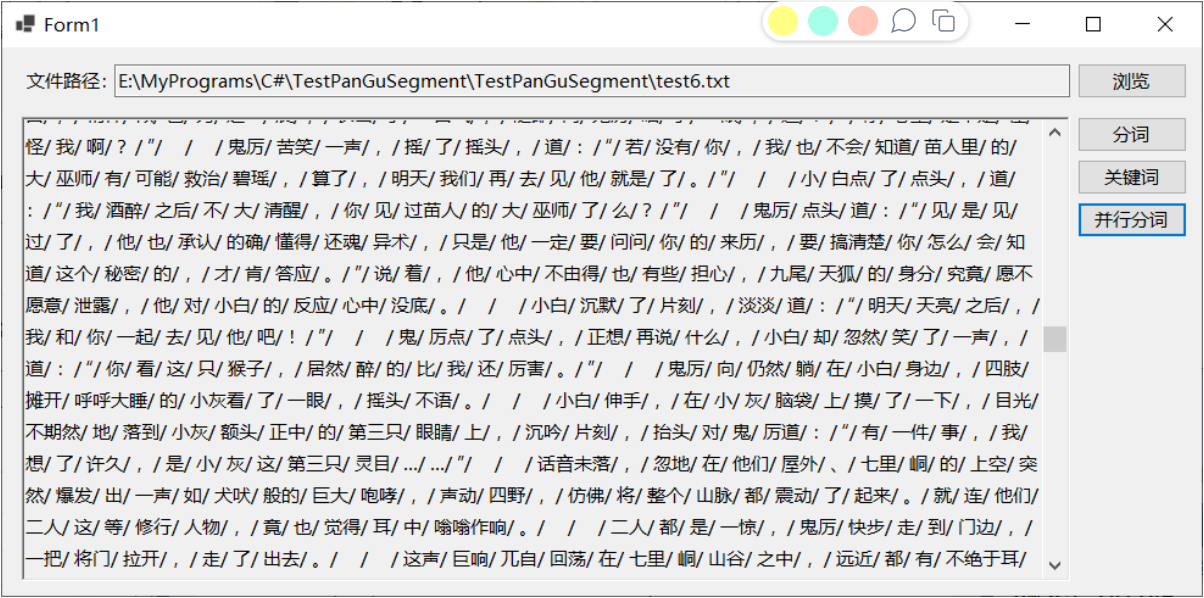
设置停用词
提取关键词时,部分词语可能不重要或者并非所需的词语,此时可以通过设置停用词,在提取关键词时过滤掉指定的停用词。jieba.NET的停用词词库放在Resources文件夹下的stopwords.txt,程序启动时会自动加载该文件。 以之前的测试文本为例,提取前20个关键词,将其中的“一声”、“一脉”两次设置停用词,即在stopwords.txt后追加这两词,再次运行程序提取关键词,可以看到这两个词已经消息
词性标注
jieba.NET中的PosSegmenter类支持在分词的同时,为每个词添加词性标注,词性标注的含义表如下所示:

- segmenter.Tokenize(text) 返回的是一个 IEnumerable<WordToken>,其中每个 WordToken 对象包含了词语、词性以及词语在原始文本中的起始位置。
1.在Resource的char_state_tab.json文件下存储了针对Unicode字符到其可能的词性的映射关系
2.在pos_prob_emit.json文件下存储了不同“词性”在遇到特定汉字时可能出现的概率大小,内容如图所示:

(这个指南不是直接给概率值,而是给了“负对数似然度”,你可以把它想象成衡量“不寻常程度”的一个指标——数值越小,表示这种情况越常见、越合理。)比如"E-e"下面"\u5440"的值是-0.65302718677052,意思是当某个词性是"E-e"时,汉字“\u5440”出现的概率相对较大,因为这个数字相比其他很多值是比较接近0的,也就是比较“不罕见”。
3.pos_prob_start.json /prob_emit.json 文件是用于存储词性标注模型中不同词性状态的先验概率或转移概率的数据。在自然语言处理任务,尤其是词性标注(Part-of-Speech Tagging)中,这样的文件起着至关重要的作用。(百度解释,不是太明白)
这个文件中的内容是每个词性对应的状态转移概率,以及每个状态的概率。每个词性都有一个对应的标识,比如 "E-e"、"E-d"、"S-rg" 等,这些标识可能是分别表示着不同的词性。而每个标识后面的数值则表示了该词性转移到下一个词性的概率,或者是该词性在句子中出现的概率。
4.pos_prob_trans/prob_trans.json 记录了不同词性之间的转移概率。其中,每个词性(比如 "E-e")后面跟着一个对象,对象的键是可能的下一个词性,而对应的值则是从当前词性转移到下一个词性的概率。例如,对于词性 "E-e",它可以转移到的词性有 "S-nr"、"S-ng"、"B-rz"、"B-mq" 等等,对应着不同的转移概率。这些值是负对数形式,数值越小代表从当前词性转移到目标词性的概率越高。
获取分词词语的起始位置
jieba.NET中的JiebaSegmenter类的Tokenize函数除了返回分词词语之外,还会返回每个分词词语的起止位置。该函数支持默认模式和搜索模式两种分词方式,根据官网说明及测试,默认模式类似于分词函数的精确模式分词,每个词语只会被分一次,而搜索模式类似于全模式及搜索引擎模式分词,把所有可能的分词形式都返回。代码使用如下所示
using JiebaNet.Segmenter;
using System;class Program
{static void Main(string[] args){var segmenter = new JiebaSegmenter();// 默认模式下的分词及位置信息var tokensDefaultMode = segmenter.Tokenize("我爱自然语言处理");foreach (var token in tokensDefaultMode){Console.WriteLine($"Word: {token.Word}, Start Index: {token.StartIndex}, End Index: {token.EndIndex}");}// 搜索模式下的分词及位置信息var tokensSearchMode = segmenter.Tokenize("我爱自然语言处理", TokenizerMode.Search);foreach (var token in tokensSearchMode){Console.WriteLine($"Word: {token.Word}, Start Index: {token.StartIndex}, End Index: {token.EndIndex}");}}
}
查找关键词
jieba.NET中的KeywordProcessor类预先指定的一组关键词,然后在指定的文本中查找存在哪些关键词,也即查找指定的关键词在文本中是否存在。
添加自定义词典
自定义词典,以便包含jeba词库里面没有的词,格式如下:
创新办 3 i
云计算 5
凱特琳 nz
载入词典
使用jieba,load_userdict(file_name)即可载入词典
动态调整词典
结巴分词器(Jieba)提供了 add_word(word, freq=None, tag=None) 和 del_word(word) 这两个方法,允许在程序运行过程中动态修改词典,以满足特定的需求。
- add_word(word, freq=None, tag=None): 这个方法用于向分词器的词典中添加新的词语。可以指定词语的频率(freq)和词性(tag),如果不指定频率和词性,则默认使用内部规则进行设置。这样一来,当分词器进行分词时,就可以识别和使用这些新增的词语了。
- del_word(word): 这个方法用于从分词器的词典中删除指定的词语。这在某些情况下可能很有用,比如当某些词语被错误地添加到词典中,或者需要动态地调整词典以适应不同的场景。
词频统计
词频统计功能可以计算文本中每个词语出现的频率以及统计词语的数量,这对文本分析、关键词提取、文本摘要等任务都非常有用。
Jieba 中的 cut 函数用于对文本进行分词,而分词后的结果可以通过 Counter 类进行词频统计。Counter 类可以统计一个可迭代对象中各个元素出现的次数。
using JiebaNet.Segmenter;
using System;
using System.Collections.Generic;
using System.Linq;class Program
{static void Main(string[] args){// 创建 JiebaSegmenter 实例var segmenter = new JiebaSegmenter();// 文本string text = "我爱自然语言处理,自然语言处理也很有趣。";// 分词var segments = segmenter.Cut(text);// 统计词频var wordCounts = segments.GroupBy(x => x).ToDictionary(g => g.Key, g => g.Count());// 输出词频统计结果foreach (var pair in wordCounts){Console.WriteLine($"词语: {pair.Key},频率: {pair.Value}");}}
}
那么如何按照词频绘制词云图呢?我们下章就为大家讲解!
相关文章:
jiebaNET中文分词器
最近我接手了一个有趣的需求,需要对用户评价进行分词,进行词频统计和情绪分析,并且根据词频权重制成词云图以供后台数据统计,于是我便引入了jieba分词器,但是我发现网上关于jiebaNET相关文档实在太少了,甚至连配置文件…...
springboot3项目练习详细步骤(第四部分:文件上传、登录优化、多环境开发)
目录 本地文件上传 接口文档 业务实现 登录优化 SpringBoot集成redis 实现令牌主动失效机制 多环境开发 本地文件上传 接口文档 业务实现 创建FileUploadController类并编写请求方法 RestController public class FileUploadController {PostMapping("/upload&…...

视觉里程计的融合方法及优缺点分析
视觉里程计是视觉slam的一部分,即前端部分,用于前端跟踪并建立局部地图。多用于重定位或辅助定位,常用的有特征点法,光流法和直接法,其区别和优缺点如下。 特征点法,需要计算特征点和描述子,计算…...
-- FGHIJ开头)
SQL常用基础语句(一)-- FGHIJ开头
GROUP BY GROUP BY语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。在GROUP BY子句后面包含了一个HAVING子句,HAVING类似于WHERE,(唯一的差别是WHERE过滤行,HAVING过滤组࿰…...
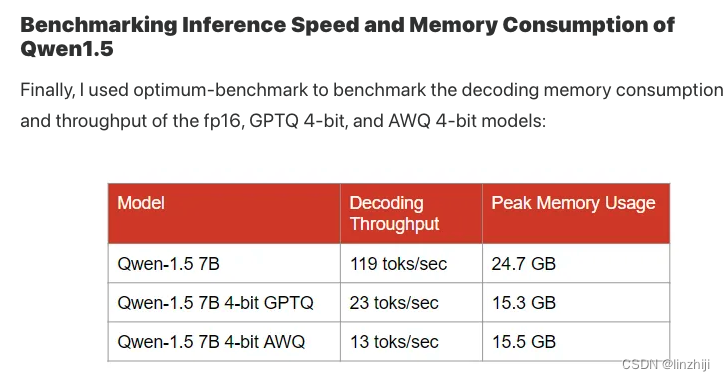
大语言模型量化方法对比:GPTQ、GGUF、AWQ 包括显存和速度
GPTQ: Post-Training Quantization for GPT Models GPTQ是一种4位量化的训练后量化(PTQ)方法,主要关注GPU推理和性能。 该方法背后的思想是,尝试通过最小化该权重的均方误差将所有权重压缩到4位。在推理过程中,它将动态地将其权重去量化为f…...
实现本地访问云主机,以及在云主机搭建FTP站点
前言 云计算是一种基于互联网的计算模式,通过网络提供按需访问的计算资源和服务。核心概念是把计算能力视作一种公共资源,用户可以根据自身需求动态分配和管理这些资源。 云主机 ECS (Elastic Compute Server)是一种按需获取的云端服务器,提…...

存储+调优:存储-Cloud
存储调优:存储-Cloud Master Server 配置: IP192.168.1.254 useradd mfs tar zxf mfs-1.6.11.tar.gz.gz cd mfs-1.6.11 ./configure --prefix/usr --sysconfdir/etc --localstatedir/var/lib --with-default-usermfs --with-default-groupmfs --disabl…...

海山数据库(He3DB)线程池方案详解
前言 对于应用开发人员来说肯定听说过连接池,却不一定听说过线程池,虽然二者都是池化的概念,但还是有所不同的: 连接池面向的是数据库连接,是针对数据库Client侧的优化。连接池可将数据库连接数固定在一定范围内&#…...

K8s 高级调度
文章目录 K8s 高级调度CronJobinitContainerTaint 和 Toleration污点(Taint)容忍(Toleration) AffinityNodeAffinityPodAnffinity 和 PodAntiAffinity 总结 K8s 高级调度 CronJob 在 k8s 中周期性运行计划任务,与 li…...

数据猿携手IDC Directions 2024:探索中国ICT市场新趋势
大数据产业创新服务媒体 ——聚焦数据 改变商业 近日,ICT业界人士、行业数字化专家,以及来自投资机构、协会、智库的近500位嘉宾聚首北京,参加了IDC Directions 2024:中国ICT市场趋势论坛(北京站)活动。活…...
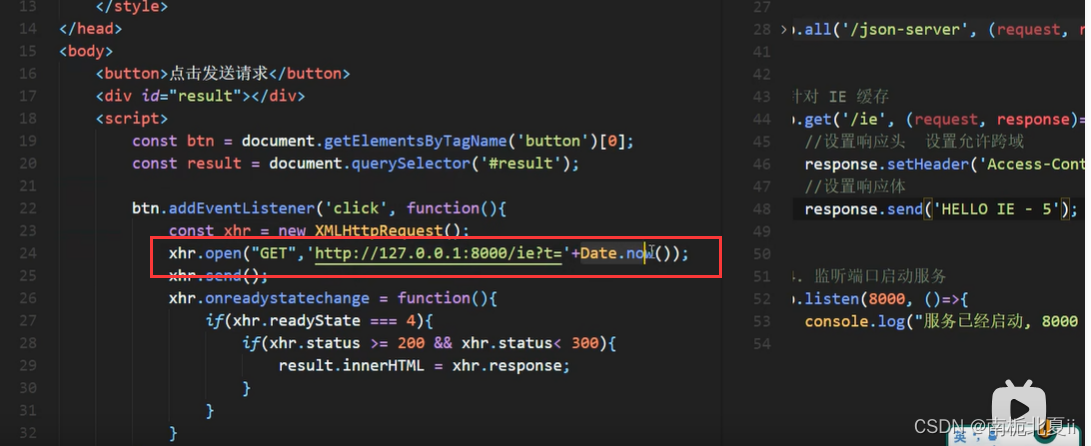
前端开发工程师——ajax
express框架 终端输入 npm init --yes npm i express 请求报文/响应报文 // 1.引入express const express require(express);// 2.创建应用对象 const app express();// 3.创建路由规则 // request:是对请求报文的封装 // response:是对响应报文的封装 app.get(…...

uni-app项目在微信开发者工具打开时报错[ app.json 文件内容错误] app.json: 在项目根目录未找到 app.json
uni-app项目在微信开发者工具打开时报错[ app.json 文件内容错误] app.json: 在项目根目录未找到 app.json 出现这个问题是因为打开的文件地址不对,解决这个问题首先我们要查看是否有unpackage文件夹,如果有,项目直接指向unpackage\dist\dev\…...

最大连续1的个数(滑动窗口)
算法原理: 这道题大眼一看是关于翻转多少个0的问题,但是,如果你按照这种思维去做题,肯定不容易。所以我们要换一种思维去做,这种思维不是一下就能想到的,所以想不到也情有可原。 题目是:给定一…...

Spring Cloud 框架的应用详解
Spring Cloud 框架的应用详解 Spring Cloud 是一个基于 Spring Boot 的微服务架构开发工具,它提供了一系列工具用于快速构建分布式系统中的常见模式,如配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、选举、分布式会话和集群状态管理…...

C语言 数组——向函数传递数组
目录 把数组传给函数(Passing Arrays to Functions) 向函数传递一维数组 向函数传递二维数组 数组在学生成绩管理中的应用 例:计算每个学生的平均分 把数组传给函数(Passing Arrays to Functions) 向函数传递一维…...
数据链路层简单介绍
mac地址(物理地址) mac地址和ip地址,目的都是为了区分网络上的不同设备的,在最开始的时候,mac地址和ip地址是两伙人,独立各自提出的,ip地址是4个字节(早都不够用了)&…...

【软考】设计模式之装饰器模式
目录 1. 说明2. 应用场景3. 结构图4. 构成5. 适用性6. 优点7. 缺点8. java示例 1. 说明 1.动态地给一个对象添加一些额外的职责。2.Decorator Pattern。3.就增加功能而言,装饰器模式比生成子类更加灵活。4.一种在不改变现有对象结构的情况下,动态地给对…...
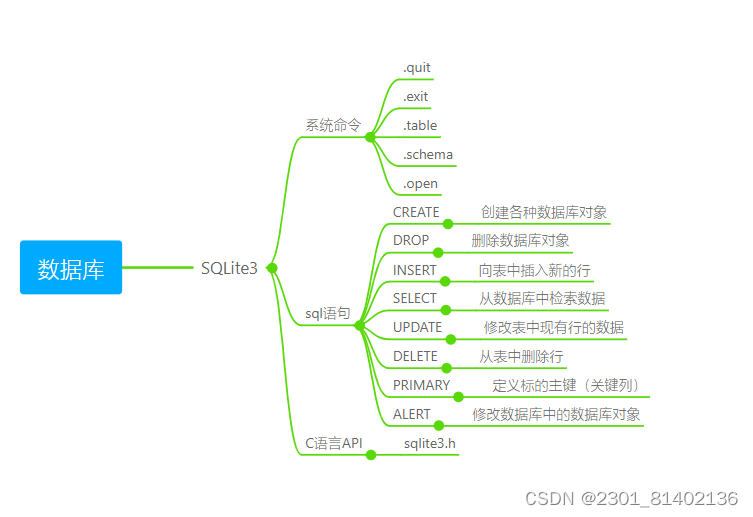
网络编程day6
IO多路复用的原理 IO多路复用是一种通过同时监视多个文件描述符(通常是套接字)来处理多个I/O操作的机制。它的原理可以简单概括为: 单线程处理多个I/O操作:传统的I/O模型中,每个I/O操作都需要一个线程或进程来处理。而…...

5.23总结
新增功能点 讨论 学生和老师均可发布话题,话题发布后,在该课程的用户可以在发布话题的课程中点击讨论参与课程的讨论,并可以进行评论,回复评论,点赞操作。每个话题发布时可添加多个图片文件,参加讨论的话…...

SQL Server基础学习笔记
一. 什么是SQL Server? SQL Server是由微软公司开发的关系型数据库管理系统(RDBMS),它提供了存储、检索、处理和分析数据的功能。作为一种强大的数据库解决方案,SQL Server被广泛应用于企业级应用程序、Web应用程序、…...

STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题
STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题 在嵌入式开发中,状态机是一种极其重要的编程范式,它能有效管理复杂系统的行为逻辑。QP(Quantum Platform)作为一款轻量级的状…...

解锁端侧智能:基于BigDL-LLM与Qwen-1.8B-Chat的CPU高效推理实践
1. 为什么要在CPU上部署大模型? 最近两年大模型技术发展迅猛,但大多数应用都依赖昂贵的GPU服务器。我在实际项目中发现,很多中小企业和个人开发者其实更需要能在普通电脑上运行的轻量化方案。这就是为什么基于CPU的大模型部署方案变得越来越…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案
Free-NTFS-for-Mac深度剖析:打破macOS与Windows文件系统壁垒的完整解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mountin…...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

从零构建现代化工作流引擎:架构、实战与生产级部署指南
1. 项目概述:一个为专业开发者打造的现代化工作流引擎最近在GitHub上看到一个挺有意思的项目,叫rohitg00/pro-workflow。光看名字,你可能觉得这又是一个“工作流”工具,市面上这类工具已经多如牛毛了。但当我深入去研究它的源码、…...

基于BLE信号强度的寻物游戏:用CircuitPython实现无线接近探测
1. 项目概述:一个用蓝牙信号“捉迷藏”的硬件游戏几年前我第一次接触Adafruit的Circuit Playground系列开发板时,就被它那种“开箱即玩”的理念吸引了。它把LED、按钮、传感器都集成在一块板子上,让你不用焊接就能快速验证想法。后来出的Circ…...