2019年MathorCup数学建模C题汽配件制造业中的生产排程问题解题全过程文档及程序
2019年第九届MathorCup高校数学建模挑战赛
C题 汽配件制造业中的生产排程问题
原题再现:



整体求解过程概述(摘要)
随着市场竞争日趋激烈,企业开始更加注重低费高效,因此生产排程问题成为众多制造企业关注的热点之一。其中,制造行业的喷漆生产排程问题是长久以来的业界难题,本文欲解决之。
针对问题一,我们以最小化换色次数以及最小化未满足产品需求零件个数为目标,引入满足支架数量限制、滑橇数量限制、面漆换色限制、颜色前后摆放限制等约束,并将各变量、约束之间的隐形限制条件也引入约束中,建立了双目标非线性整数规划模型。在算法设计中,首先设计基于规则以及颜色优先级的基本算法求得初始解,得出平均每圈的换色次数为 4,未满足生产需求的零件个数为 71。接着基于此运用遗传算法求出一组基于初始解的双目标帕累托最优解。我们以较为平衡的一组为例展示,其平均每圈的换色次数(考虑了不同圈首尾衔接的换色情况)为 3.5,未满足生产需求的零件个数为40。
针对问题二,我们在问题一已有优化目标的基础上引入最小化更换滑撬次数这一目标。为了调节各目标关系,首先引入不同圈之间产品喷涂结构相似度指标,根据问题一的解,分析发现各圈产品之间喷涂结构相似度差异不大且大多在 50%左右,同时结合生产需求和换色次数在企业制造的重要性,将支架更换次数置于较低优先级。算法设计分为两部分,首先在尽量保证问题一最优解的情况下,以相似度和首尾颜色的可衔接性作为关键因素调整各圈之间的生产顺序。接着以调整后的第一圈为基准,依序调整此后各圈的产品喷涂结构,使之与其前一圈结构尽量相似。求得平均每圈的换色次数小幅增长为 3.6 以及未满足生产需求的零件个数不变为 40,平均每圈支架更换次数由 275 优化至180。观察结果发现,支架更换次数优化的情况受限于各圈生产顺序的选取策略,因此对于该策略的改进可作为后续研究的方向。
模型假设:
假设 1:不考虑设备的故障问题
假设 2:人工更换滑橇只是人力方面的影响,不对具体生产流程产生影响。
假设 3:企业不会因为更换次数频繁而增加对人员的雇佣
问题分析(部分):
支架的更换与不同圈之间的产品结构的情况息息相关,因此我们首先定义产品喷涂结构相似度。对与不同圈之间的产品喷涂相似性,我们以其共同生产的产品种类数为标准。具体表达如下:

第m圈和第n圈的相似度为他们相同的产品种类数与他们总共生产的产品种类数之比。越接近 1 则说明他们喷涂的产品结构越类似,进行适当的圈内调整之后,对更换支架次数的优化情况也会较好
模型的建立与求解整体论文缩略图




全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
The actual procedure is shown in the screenshot
import numpy as np
import xlwt
import math
import copy
import xlrd
'''商品是商品大类根据颜色的细分''' #商品类,原始的不同类型不同颜色的商品为一个对象
class com:
name = None
color = None
num = 0
sled_num = 0 #商品需要的总的滑橇数
circle_num = 0 #商品需要生产的圈数
#如果圈数大于 1,假设生产圈数为 n,则保证前 n-1 生产量为 6 的倍数
pro_num = 0
def __init__(self, tname, tcolor,tnum):
self.name = tname
self.color = tcolor
self.num = tnum
#商品段类,排产圈中每个不同类型不同颜色的商品段为一个对象
class com_seg:
name = None
color = None
position = 0
num = 0
sled_num = 0
circle_balance = 0 #在加入该商品段前本圈的 balance
def __init__(self,tname,tcolor,tposition,tnum,sled_num,balance):
self.name = tname
self.color = tcolor
self.position = tposition
self.num = tnum
self.sled_num = sled_num
self.circle_balance = balance
com_info_list = [] #保存各个商品大类信息的列表
#示例:[name,color,num]
com_list = [] #保存所有商品对象
bracket_num = {} #支架数目字典,由商品大类名字为键
com_seg_list = [] #保存所有的商品段对象,由排产时生成
bracket_num_copy = {} #支架数目字典副本,排产时使用
''' 颜色序列与各颜色对应的数目
4068 曜岩黑 3854 极地白 1746 钻石白 1100 光耀蓝 935 宝石红 704 铱
银
551 米兰银 429 宝石蓝 43 宇宙黑 15 牛仔蓝
''' #颜色序列与颜色商品字典
color_series = ['曜岩黑','极地白','钻石白','光耀蓝','宝石红',
'铱银' ,'米兰银','宝石蓝', '宇宙黑','牛仔蓝']
color_com_dict = {'曜岩黑':[],'极地白':[],'钻石白':[],'光耀蓝':[],'宝石红':[],
'铱银':[],'米兰银':[],'宝石蓝':[], '宇宙黑':[],'牛仔蓝':[]}
def read_com_list(com_info_list):
workbook = xlrd.open_workbook("C 题附件.xlsx")
sheet1 = workbook.sheet_by_name("生产需求量表")
for i in range(1,84):
one_com_info = []
for j in range(3):
one_cell = sheet1.cell(i,j).value
one_com_info.append(one_cell)
#print(one_com_info)
com_info_list.append(one_com_info)
def read_brackrt_info(bracket_num):
workbook = xlrd.open_workbook("C 题附件.xlsx")
sheet1 = workbook.sheet_by_name("支架数量上限")
for i in range(1, 32):
one_cell = sheet1.cell(i,0).value
two_cell = sheet1.cell(i,1).value
bracket_num[one_cell] = int(two_cell)
#根据商品信息列表,生成商品对象列表
def cre_com_list(com_info_list,com_list):
for one_com_info in com_info_list:
temp = com(one_com_info[0],one_com_info[1],int(one_com_info[2]))
com_list.append(temp)
'''按照尽量多生产原则,计算各个商品需要的总滑撬数''' def cacu_sled(com_list):
for com in com_list:
if bracket_num[com.name] >= 6:
sleds = com.num // 6
if com.num % 6 > 0:
sleds += 1
com.sled_num = sleds
else:
sleds = com.num // bracket_num[com.name]
com.sled_num = sleds
#根据 com_list 中的商品对象,计算各个商品对象要排产的圈数
def cacu_circle(com_list):
for com in com_list:
circle_num = math.ceil(com.num / bracket_num[com.name])
if circle_num > 1:
if bracket_num[com.name] > 6:
com.pro_num = (bracket_num[com.name] // 6) * 6
com.circle_num = math.ceil(com.num / com.pro_num)
else:
com.pro_num = bracket_num[com.name]
com.circle_num = math.ceil(com.num /
bracket_num[com.name])
else:
com.circle_num = 1
#根据各个商品的颜色,生成以颜色划分的商品字典
def cre_color_dict(com_list):
for com in com_list:
color_com_dict[com.color].append(com)
#生成一个排产列表
pre_series = []
def cre_one_series(pre_series,color_series,bracket_num):
'''初始化总的滑橇数目,商品排产位置,要维护的每一圈滑橇数目,支架数目字典''' balance = 2250 #总的滑橇数目
position = 1 #记录商品排产的位置
one_balance = 303 #要维护的每一圈滑橇数目
bracket_num_copy = copy.deepcopy(bracket_num) #排产过程中用到的支架
数目字典
while(balance > 0):
for color in color_series:
for com in color_com_dict[color]:
#还剩一圈的产品与多余一圈的产品之间的差别是排产的数量
与排产的滑橇数量
#print(com.name,com.color,com.circle_num)
#print(balance)
if balance < 0:
return pre_series
if com.circle_num > 1:
once_sled = com.pro_num // 6
if once_sled <= 0:
once_sled += 1
append_num = com.pro_num
#print(com.name,com.color,com.circle_num,com.pro_num)
#print("append_num",append_num)
elif com.circle_num > 0:
once_sled = com.sled_num
append_num = com.num
#print(com.name, com.color, com.circle_num, com.num)
#print("append_num", append_num)
else:
continue
#判断是否加入本商品后就超出了本圈,若是则对支架数
字典
#滑橇数目的更新方式不同,如果加入后超出了本圈则
#print(one_balance)
#print(once_sled)
if one_balance - once_sled <= 0:
#print('是末尾')
#print(one_balance,once_sled)
# 这里要改,应该改成>,把下面的放在 else
#print('是末尾')
if bracket_num_copy[com.name] >= once_sled * 6:
a = com_seg(com.name, com.color, position, append_num,once_sled,one_balance)
com.num -= append_num #无论是否在末尾,
对该商品的更新方式相同
com.circle_num -= 1 #维护余下需要的圈数
com.sled_num -= once_sled #维护余下需要的滑橇
数
position += 1 #无论是否在末尾,对
位置的更新相同
pre_series.append(a)
#在末尾对滑橇数和支架数的更新不同
ex_sled = once_sled - one_balance
ex_bracket = bracket_num_copy[com.name] - one_balance * 6
bracket_num_copy = copy.deepcopy(bracket_num)
bracket_num_copy[com.name] -= ex_bracket
one_balance = 303 - ex_sled
balance -= once_sled
else:
continue
else:
#print('append_num',append_num)
#print(bracket_num_copy[com.name])
#print(one_balance, once_sled)
#print(com.name)
if append_num <= bracket_num_copy[com.name]:
#print('不是末尾')
a =
com_seg(com.name,com.color,position,append_num,once_sled,one_balance)
com.num -= append_num
com.circle_num -= 1
com.sled_num -= once_sled
position += 1
pre_series.append(a)
balance -= once_sled
one_balance -= once_sled
bracket_num_copy[com.name] -= append_num
#print(balance)
if balance < 0:
print(com.name,'balance < 0 ')
else:
continue
#pre_series.append("换色")
#one_balance -= 1
#balance -= 1
#print(balance)
read_com_list(com_info_list) #读入商品数据
cre_com_list(com_info_list,com_list) #创建商品列表
read_brackrt_info(bracket_num) #创建支架词典
cacu_sled(com_list) #按照多生产原则计算需要的滑橇
数量
cacu_circle(com_list) #计算各商品需要的生产圈数
cre_color_dict(com_list)
#for com in com_list:
#
print(com.name,com.color,com.sled_num,com.circle_num,com.num,com.pro_num)
pre_series = cre_one_series(pre_series,color_series,bracket_num)
count = 0
all = 0
for com_seg in pre_series:
if com_seg == '换色':
count += 1
print('换色')
else:
print(com_seg.name,com_seg.color,' 商 品 数 ',com_seg.num,' 滑 橇 数
',com_seg.sled_num,'加入之前本圈剩余滑橇数',com_seg.circle_balance)
all += com_seg.sled_num
def write_solution(pre_series):
f = xlwt.Workbook(encoding='utf-8')
sheet1 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) # 创建 sheet
# 将数据写入第 i 行,第 j 列
i = 0
for com_seg in pre_series:
sheet1.write(i, 1, com_seg.name)
sheet1.write(i, 2, com_seg.color)
sheet1.write(i, 3, com_seg.num)
sheet1.write(i, 4, com_seg.sled_num)
sheet1.write(i, 5, com_seg.circle_balance)
i = i + 1
f.save('初始解.xls') # 保存文件
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2019年MathorCup数学建模C题汽配件制造业中的生产排程问题解题全过程文档及程序
2019年第九届MathorCup高校数学建模挑战赛 C题 汽配件制造业中的生产排程问题 原题再现: 整体求解过程概述(摘要) 随着市场竞争日趋激烈,企业开始更加注重低费高效,因此生产排程问题成为众多制造企业关注的热点之一。其中,制造行…...
ARM uboot 的移植3 -从 uboot 官方标准uboot开始移植
一、选择合适的官方原版 uboot 1、官方原版 uboot 的版本 (1) 版本号。刚开始是 1.3.4 样式,后来变成 2009.08 样式。 (2) 新版和旧版的差别。uboot 的架构很早就定下来了,然后里面普遍公用的东西(common 目录下、drivers 目录下、fs 目录…...
【独家】)
华为OD机试 - 快递货车(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:快递货车…...
连接微信群、Slack 和 GitHub:社区开放沟通的基础设施搭建
NebulaGraph 社区如何构建工具让 Slack、WeChat 中宝贵的群聊讨论同步到公共领域。 要开放,不要封闭 在开源社区中,开放的一个重要意义是社区内的沟通、讨论应该是透明、包容并且方便所有成员访问的。这意味着社区中的任何人都应该能够参与讨论和决策过…...
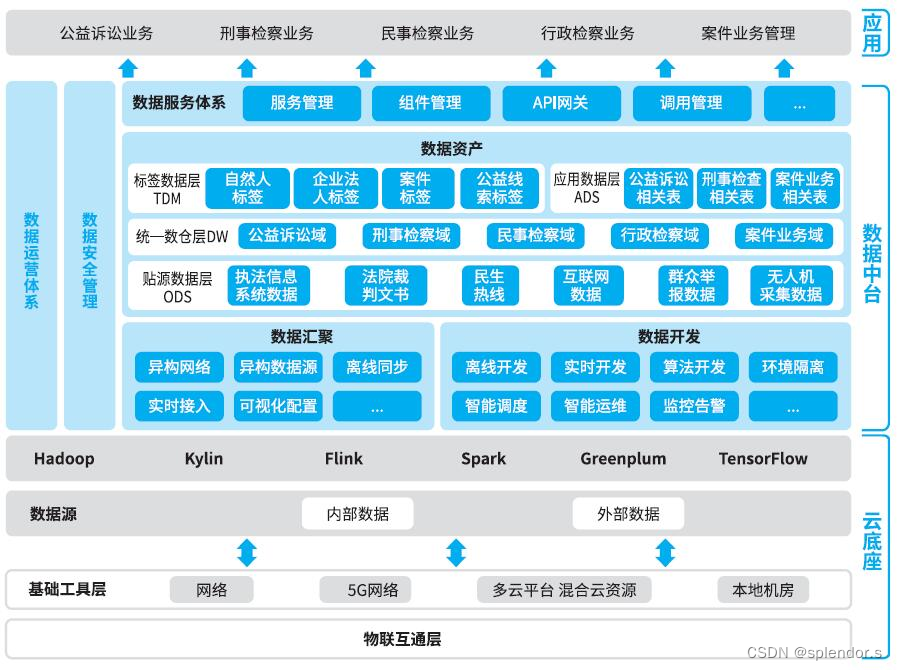
数据中台架构体系理解
目前,大部分企业更倾向于数据集中采集、存储,并应用分层建设。这种方式一方面有利于应用系统的快速部署,另一方面也保证了数据的集中管理与运营,体现数据的资产、资源属性。 数据中台的出现弥补了数据开发和应用开发之间由于开发…...

高并发性能指标:QPS、TPS、RT、并发数、吞吐量
QPS(每秒查询) QPS:Queries Per Second意思是“每秒查询率”,一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准 互联网中,作为域名系统服务器的机器的性…...

【微信小程序】-- 案例 - 本地生活(列表页面)(三十)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

华为OD机试题,用 Java 解【一种字符串压缩表示的解压】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...

所有科研人警惕,掠夺型期刊和劫持型期刊的区别,千万别投错了
当今,新形式的学术出版物——例如数字式或开源式的学术期刊日益普及,热门期刊的数量逐年增长【1】。 人们获取学术出版物也越来越容易,使得更多的科研人员(特别是在低收入国家)能够及时了解各自研究领域的最新发展态势…...
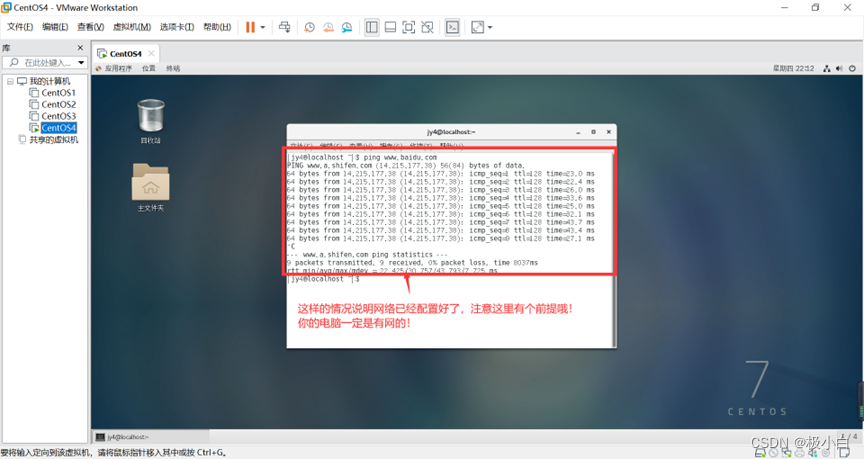
超详细CentOS7 NAT模式(有图形化界面)网络配置
在此附上CentOS7(有可视化界面版)安装教程 超详细VMware CentOS7(有可视化界面版)安装教程 打开VMware—>点击编辑---->选择虚拟网络编辑器 打开虚拟网络编辑器后如下图所示: 从下图中我们看到最下面子网IP为…...
华为OD机试题,用 Java 解【英文输入法】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...
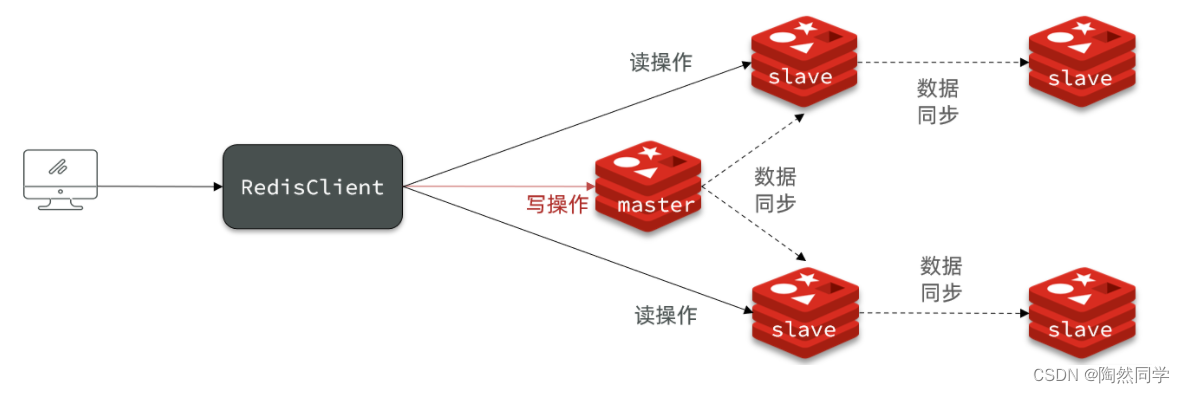
【Redis】主从集群 实现读写分离(二)
目录 2.Redis主从 2.1.搭建主从架构 2.2.主从数据同步原理 2.2.1.全量同步 2.2.2.增量同步 2.2.3.repl_backlog原理 2.3.主从同步优化 2.4.小结 2.Redis主从 2.1.搭建主从架构 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,…...

【JavaEE】前后端分离实现博客系统(页面构建)
文章目录1 效果展示1.1 博客登录页面1.2 博客列表页面1.3 博客详情页面1.4 博客编辑页面2 页面具体实现2.1 博客列表页的实现2.2 博客详情页的实现2.3 博客登录页面的实现2.4 博客编辑页面的实现写在最后1 效果展示 1.1 博客登录页面 用于实现用户的登录功能,并展…...
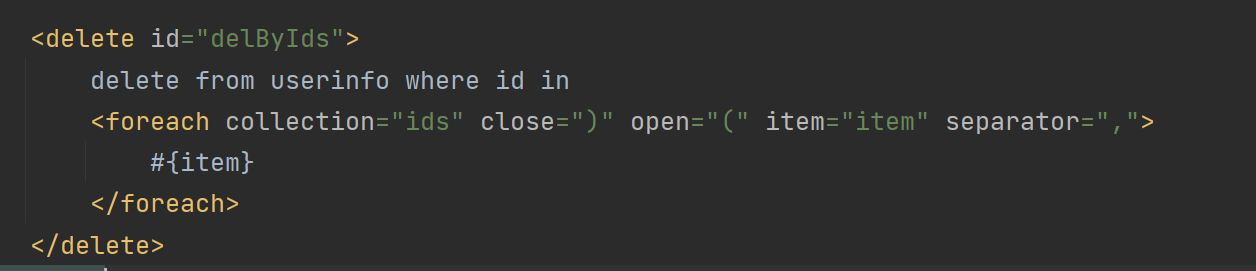
MyBatis的基本使用
MyBatis 为啥MyBatis会使用xml 在一个程序中,若需要操作数据表,那么 SQL 语句有两种存放方式:1. 放到 Java 类里面(这个就存在大量的字符串拼接,还有占位符需要处理-----JDBC);2:放…...

看完书上的链表还不会实现?不进来看看?
1.1链表的概念定义:链表是一种物理存储上非连续,数据元素的逻辑顺序通过链表中的指针链接次序,实现的一种线性存储结构。特点:链表由一系列节点组成,节点在运行时动态生成 (malloc),…...

【批处理脚本】-3.2-call命令详解
"><--点击返回「批处理BAT从入门到精通」总目录--> 共5页精讲(列举了所有call的用法,图文并茂,通俗易懂) 在从事“嵌入式软件开发”和“Autosar工具开发软件”过程中,经常会在其集成开发环境IDE(CodeWarrior,S32K DS,Davinci,EB Tresos,ETAS…)中,…...
华为OD机试题,用 Java 解【寻找相同子串】问题
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典使用说明 参加华为od机试,一定要注意不…...
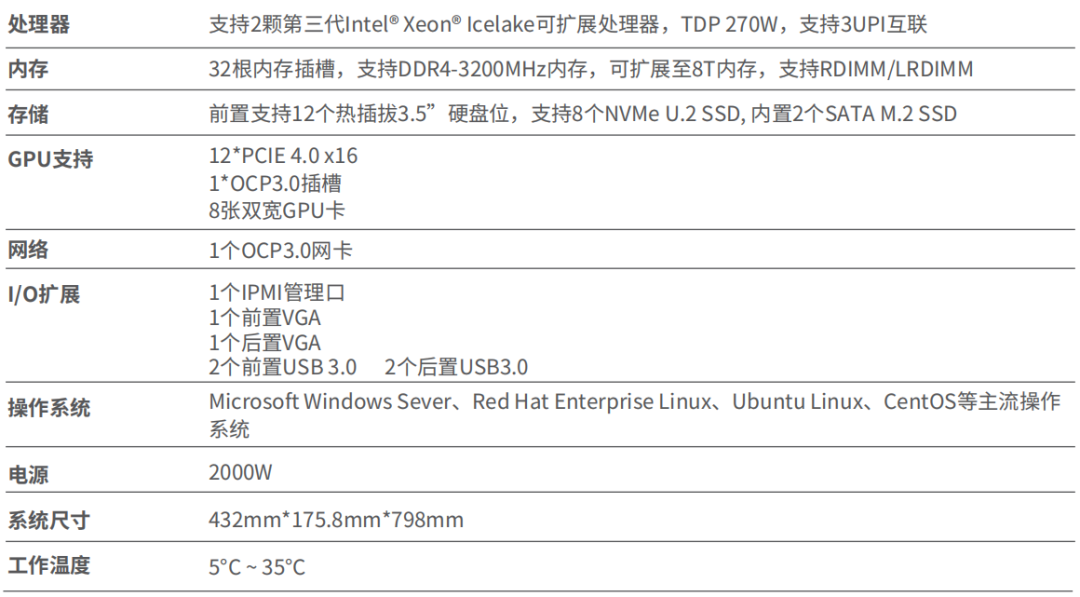
思腾合力深思系列 | 四款高性能 AI 服务器
深思系列 AI 服务器涵盖多种 CPU 平台,支持按客户需求预装 OS、驱动、DL 框架、常用 DL 库,节省您大量的前期调试时间,开机即用。 一个简单的任务,若想要在 AI 的脑中形成清晰的思路,需要大量的实验和练习。从 AI 训练…...
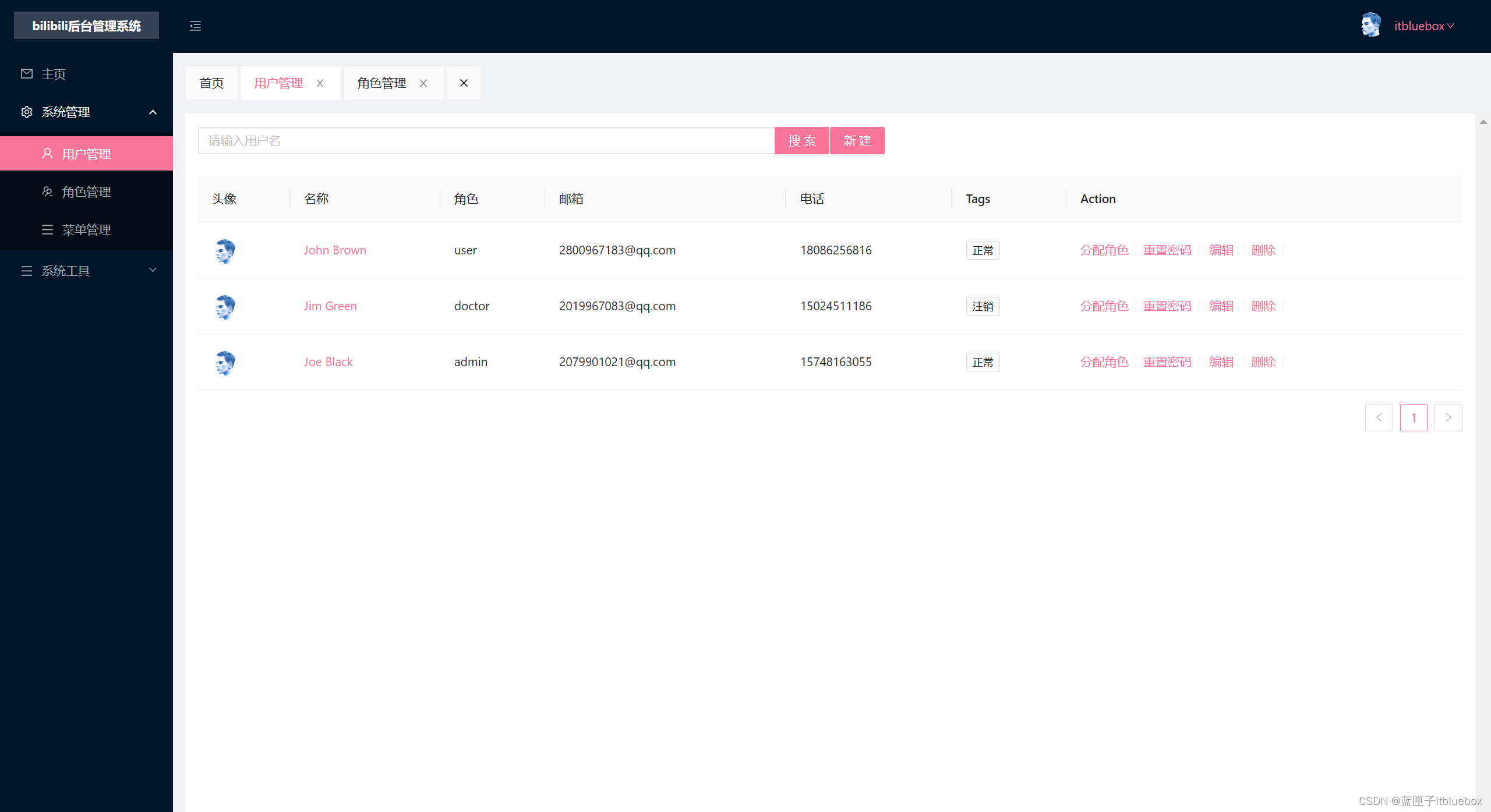
Vue3做出B站【bilibili】 Vue3+TypeScript+ant-design-vue【快速入门一篇文章精通系列(一)前端项目案例】
本项目分为二部分 1、后台管理系统(用户管理,角色管理,视频管理等) 2、客户端(登录注册、发布视频) Vue3做出B站【bilibili】 Vue3TypeScriptant-design-vue【快速入门一篇文章精通系列(一&…...

2.3操作系统-进程管理:死锁、死锁的产生条件、死锁资源数计算
2.3操作系统-进程管理:死锁、死锁的产生条件、死锁资源数计算死锁死锁的产生条件死锁资源数计算死锁 进程管理是操作系统的核心,如果设计不当,就会出现死锁的问题。如果一个进程在等待意见不可能发生的事,进程就会死锁。而如果一…...

自编码器在异常检测中的实战应用:以金融交易数据为例
自编码器在金融异常检测中的实战指南:从数据清洗到模型部署 金融交易数据中的异常行为检测一直是风险控制的核心环节。传统基于规则的系统难以应对日益复杂的欺诈模式,而自编码器这类无监督学习模型正在改变游戏规则。本文将带您从零构建一个完整的异常检…...

MusePublic Art Studio参数详解:随机种子锁定与艺术风格复现方法
MusePublic Art Studio参数详解:随机种子锁定与艺术风格复现方法 1. 理解随机种子:艺术创作的"基因密码" 在AI图像生成领域,随机种子就像是每幅作品的DNA序列。它决定了生成过程中的随机性因素,是控制输出结果一致性的…...

国产MCU实战:华大HC32F460串口DMA+超时中断,替代STM32空闲中断的完整配置流程
国产MCU实战:华大HC32F460串口DMA超时中断的工程化实现指南 在嵌入式开发领域,国产MCU的崛起为开发者提供了更多选择。华大半导体的HC32F460系列以其出色的性能和灵活的配置,成为许多项目中替代STM32的理想选择。本文将深入探讨如何在这款芯片…...

捉妖雷达Web版:如何解决游戏数据实时同步的技术挑战?
捉妖雷达Web版:如何解决游戏数据实时同步的技术挑战? 【免费下载链接】zhuoyao_radar 捉妖雷达 web版 项目地址: https://gitcode.com/gh_mirrors/zh/zhuoyao_radar 捉妖雷达Web版是一个开源的游戏辅助工具项目,旨在为捉妖游戏玩家提供…...

终极ESLyric歌词源配置指南:三步解锁酷狗QQ网易云逐字歌词
终极ESLyric歌词源配置指南:三步解锁酷狗QQ网易云逐字歌词 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource 想在Foobar2000中享受酷狗音乐、QQ…...

深度学习项目训练环境多场景落地:自动驾驶小车图像识别项目快速启动
深度学习项目训练环境多场景落地:自动驾驶小车图像识别项目快速启动 你是不是也遇到过这样的问题?想跑一个深度学习项目,光是配环境就花了大半天,各种版本冲突、依赖报错,好不容易装好了,一运行又提示缺这…...

Python自动化爬取企查查企业工商信息的实战技巧
1. Python爬取企查查数据的核心思路 企查查作为国内权威的企业信息查询平台,包含了大量有价值的工商注册信息。对于金融、证券行业的从业者来说,经常需要批量获取这些数据进行分析。手动一个个查询不仅效率低下,还容易出错。这时候Python自动…...

Node.js全栈项目集成Wan2.1-UMT5:实时视频生成进度推送
Node.js全栈项目集成Wan2.1-UMT5:实时视频生成进度推送 最近在做一个挺有意思的项目,需要把Wan2.1-UMT5这个视频生成模型集成到我们自己的系统里。用户上传一段文字描述,系统就能生成一段短视频。听起来挺酷,对吧?但问…...

Phi-3 Forest Laboratory 与SpringBoot微服务整合:打造企业级AI中台
Phi-3 Forest Laboratory 与SpringBoot微服务整合:打造企业级AI中台 最近和几个做企业级应用开发的朋友聊天,大家不约而同地提到了同一个痛点:公司内部有好几个业务团队都想用上最新的AI能力,比如用Phi-3这样的模型做智能客服、文…...

如何快速上手OneMore:OneNote插件的安装与基础设置教程
如何快速上手OneMore:OneNote插件的安装与基础设置教程 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 想要提升OneNote的使用效率吗?OneMore插…...