【有手就行】使用你自己的声音做语音合成,CPU都能跑,亲测有效
此文介绍在百度飞桨上一个公开的案例,亲测有效。
厌倦了前篇一律的TTS音色了吗?打开短视频听来听去就是那几个声音,快来试试使用你自己的声音来做语音合成吧!本教程非常简单,只需要你能够上传自己的音频数据就可以(建议10句以上,少于5句第一步会报错,句子越多,效果越好),剩下的就是等代码运行结束即可,一路运行到底!!选择CPU就行,推荐GPU32G或以上的环境运行!
1. 效果展示:
| Speaker | 数据量级 | 原始音频 | 微调效果 |
|---|---|---|---|
| 发音人A | 12句 | ||
| 发音人B | 12句 |
2. 使用说明
进入环境时,一定要选择 32G或以上的GPU环境运行,CPU环境无法运行

-
萌新玩家:如果你从来没有学习过编程,也不知道什么时深度学习,欢迎使用可视化界面进行操作。只需要准备好音频数据以后,按照网页说明一直向下点击运行即可。在【第三部分:安装试验所需环境】结束后,进入【第四部分:网页应用微调训练】
-
高端玩家:如果你有一定的Python基础并了解如何进行深度学习的训练,调参与模型微调,在【第三部分:安装试验所需环境】结束后,进入【第五部分:代码块微调训练】。
安装试验所需环境
执行下面这行代码块,安装全部所需实验环境。
无论什么时候,先等安装环境这行执行完毕!每一次重新打开项目的时候也是,重新把这行执行完毕!!!不然后面会有各种各样的报错
等这行出现。

In [ ]
# 安装实验所需环境
!bash env.sh
!pip install typeguard==2.13 --user4. 网页应用微调训练
在左侧找到文件 untitled.streamlit.py ,双击文件
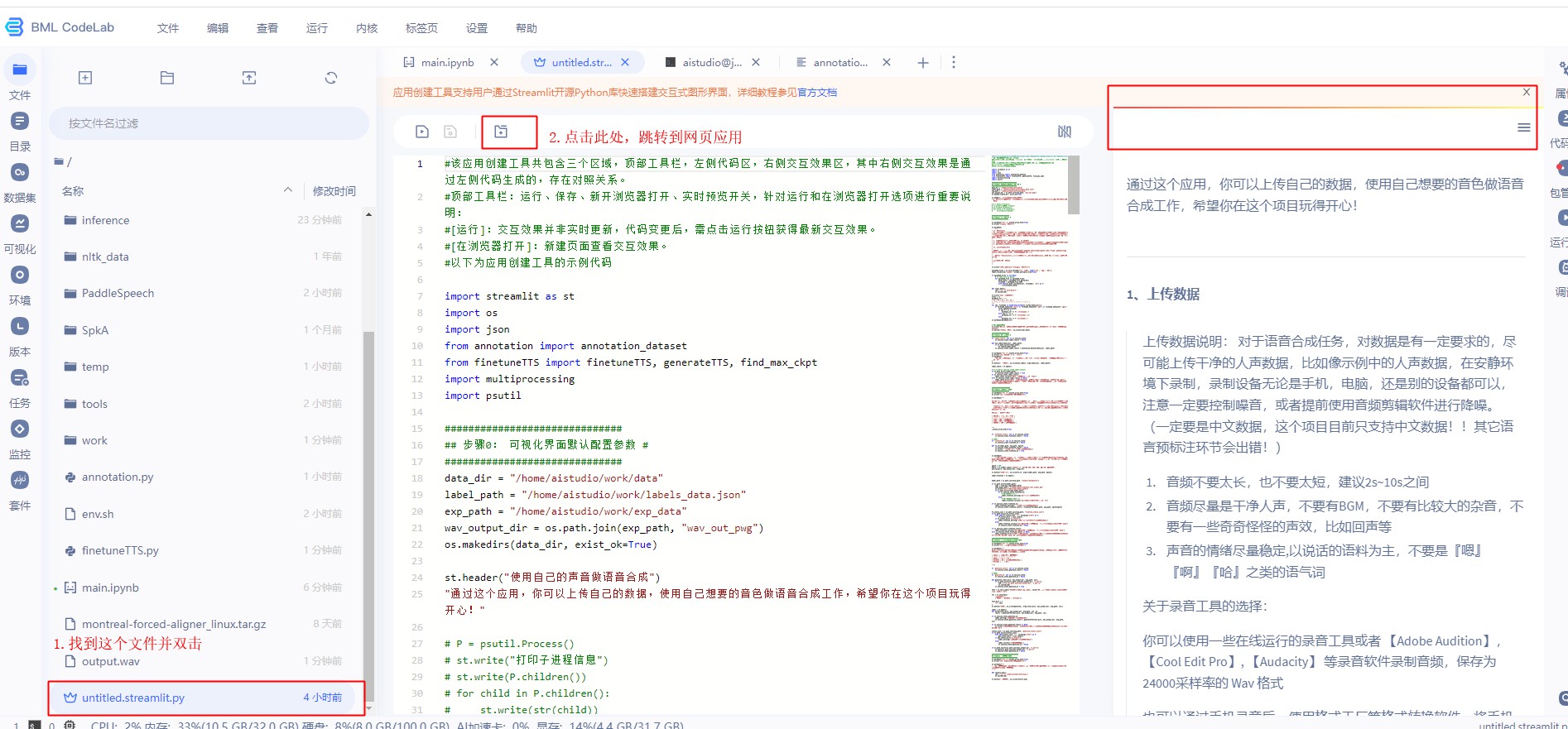
进入网页后,参照网页应用引导,上传文件 -> 标注数据 -> 微调模型 -> 合成文本
4.1 如何上传数据
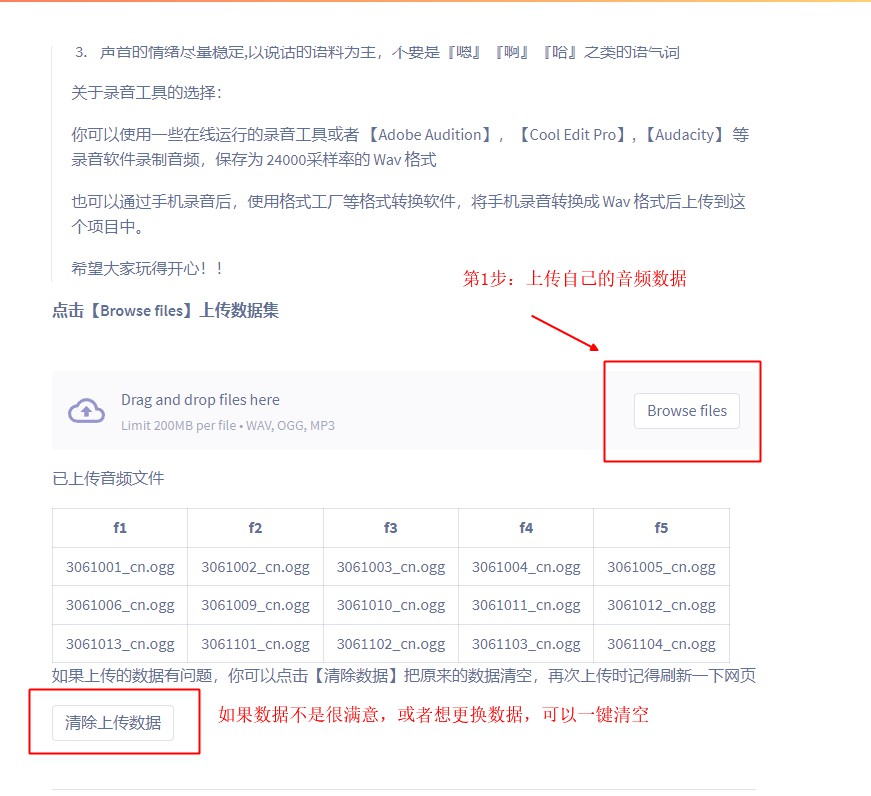
4.2 检查并标注数据

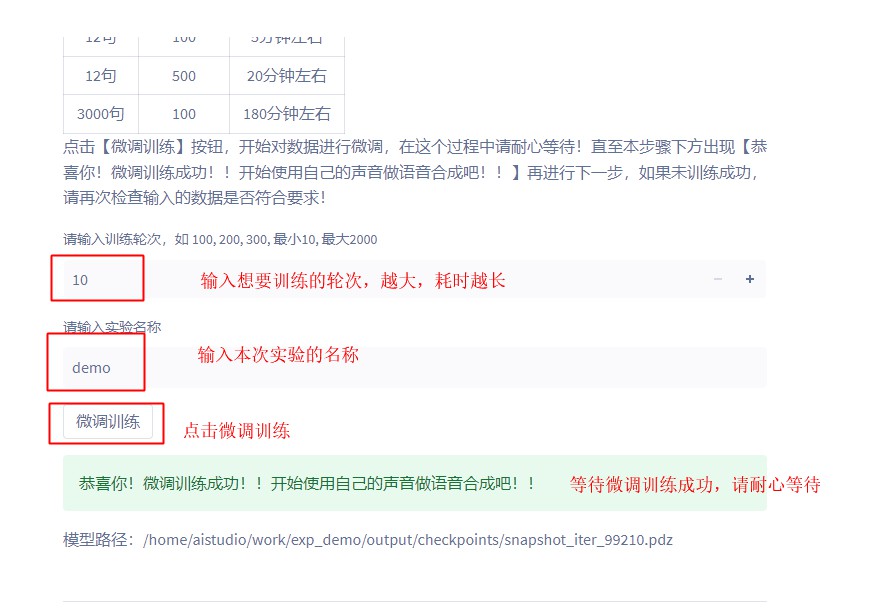
4.3 微调模型

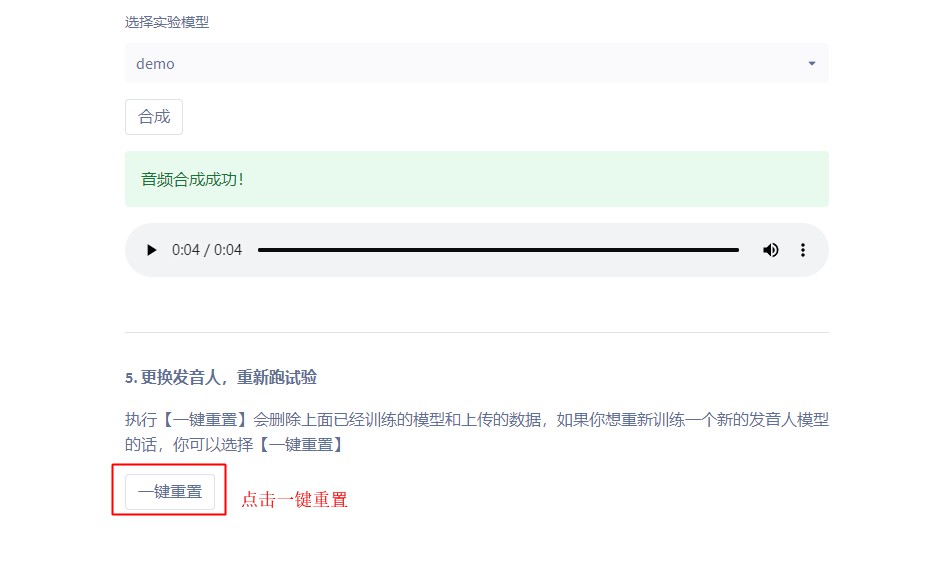
4.4 合成文本

4.5 想要跑新的实验
5. 代码块微调
5.1. 如何上传数据:
上传数据说明: 对于语音合成任务,对数据是有一定要求的,尽可能上传干净的人声数据,比如像示例中的人声数据,在安静环境下录制,录制设备无论是手机,电脑,还是别的设备都可以,注意一定要控制噪音,或者提前使用音频剪辑软件进行降噪。
- 音频不要太长,也不要太短,建议2s~10s之间
- 音频尽量是干净人声,不要有BGM,不要有比较大的杂音,不要有一些奇奇怪怪的声效,比如回声等
- 声音的情绪尽量稳定,以说话的语料为主,不要是『嗯』『啊』『哈』之类的语气词
关于录音工具的选择:
你可以使用一些在线运行的录音工具或者 【Adobe Audition】,【Cool Edit Pro】, 【Audacity】 等录音软件录制音频,保存为 24000采样率的 Wav 格式
也可以通过手机录音后,使用格式工厂等格式转换软件,将手机录音转换成 Wav 格式后上传到这个项目中。
希望大家玩得开心!!
这里给大家介绍两种把数据上传到 Aistudio 的方法
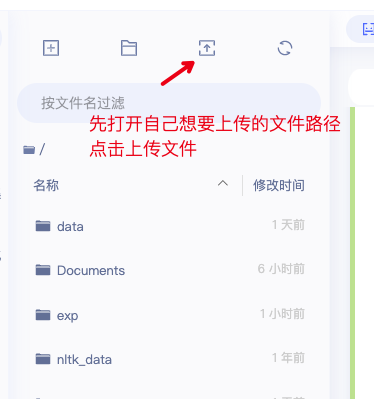
5.1.1 通过右侧菜单上传文件
点击 data,进入 data 目录上传音频数据(wav / mp3 / ogg 格式 ), 数据大小不超过 150M

5.1.2 创建数据集并挂载到项目中
如果音频数据比较多,体积 > 150M 可以使用挂载数据集的方式上传,通过这种方式时注意项目启动时提前挂载好自己的数据集。
这部分可以参考 【Aistudio数据集挂载说明】
5.2. 微调模型
在上面的过程中,已经上传好了数据,大家只需要按步骤运行下面三步即可。
不同的数据量,微调所需的时间不同,比如使用示例音频,只需要5分钟左右就可以微调完成,你的数据越多,所需微调时间就越多, 剩下的只需要耐心等待就好了
如果你的数据量特别多,记得提前设置【页面关闭后环境终止时间】,选2h,以防因网络问题导致训练终端。
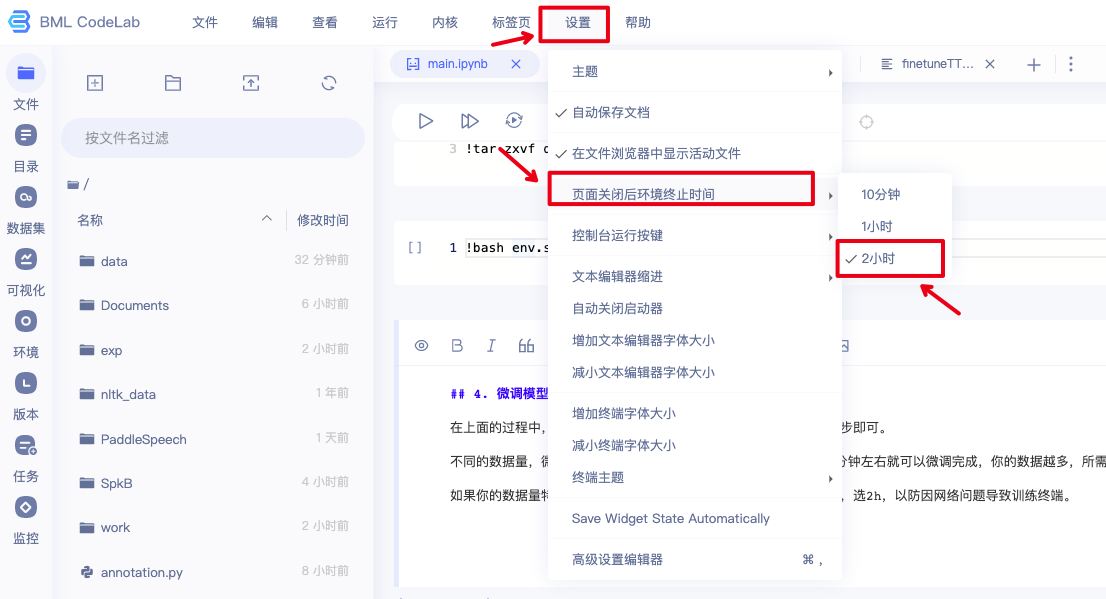
注意:当你想要做新一轮试验的时候!请一定要【重启内核】,重启内核后上面都不需要运行,直接从这里开始运行就可以
In [3]
###########
# 注意!!!
# 更换自己的数据集只需要替换这里的三个参数就可以了,为了防止出错,一律使用绝对路径!!不要使用相对路径!
# 1. data_dir:上传的数据路径
# 2. label_path:生成的标注文件,你也根据音频实际情况修改,注意:这里生成的是json文件,方便大家检查修改的!跟标注数据集标注有区别
# 3. exp_dir: 试验路径,建议不同的试验放在不同的试验路径,防止试验文件串了
########
import os# 示例1
data_dir = os.path.abspath("work/SpkA")
label_path = os.path.abspath("work/labels_spkA.json")
exp_name = "spka"# 示例2
# data_dir = os.path.abspath("work/SpkB")
# label_path = os.path.abspath("work/labels_speakB.json")
# exp_name = "spkb"# 示例3:上传自己的数据集到 data
# 如果你使用自己的数据集,并且已经把数据上传到了 data 目录,就把下面三行的 # 号去掉就好了
#data_dir = os.path.abspath("work/data")
#label_path = os.path.abspath("work/labels_data.json")
#exp_name = "demo"In [ ]
# 【有手就行】使用你自己的声音做语音合成厌倦了前篇一律的TTS音色了吗?打开短视频听来听去就是那几个声音,快来试试使用你自己的声音来做语音合成吧!本教程非常简单,只需要你能够上传自己的音频数据就可以(建议10句以上,少于5句第一步会报错,句子越多,效果越好),剩下的就是等代码运行结束即可,一路运行到底!!选择CPU环境也行,不过GPU32G或以上的环境运行!PaddleSpeech 是一个简单易用的all-in-one 的语音工具箱,支持语音识别,语音合成,声纹识别,声音分类,语音翻译,标点恢复,语音唤醒等多个方向的开发工作。如果你喜欢我们的工作,## 1. **效果展示**:<html><table><tr><th>Speaker</th><th>数据量级</th><th>原始音频</th><th>微调效果</th></tr><tr><td>发音人A</td><td>12句</td><td><audio controls><source src="https://paddlespeech.bj.bcebos.com/datasets/Aistudio/finetune/SpkA/data/000001.wav" type="audio/wav"></audio></td><td><audio controls><source src="https://paddlespeech.bj.bcebos.com/datasets/Aistudio/finetune/SpkA/finetune/1.wav" type="audio/wav"></audio></td></tr><tr><td>发音人B</td><td>12句</td><td><audio controls><source src="https://paddlespeech.bj.bcebos.com/datasets/Aistudio/finetune/SpkB/data/000002.wav" type="audio/wav"></audio></td><td><audio controls><source src="https://paddlespeech.bj.bcebos.com/datasets/Aistudio/finetune/SpkB/finetune/1.wav" type="audio/wav"></audio></td></tr>
</table></html>你可以在电脑或者手机提前录制好自己的声音,然后上传,注意音频不要太长,也不要太短,建议 2s ~ 10s 左右,音频太长训练时有可能会出错(GPU内存不足),建议按照一句话一个音频进行切分。In [4]
# 标注过一次之后就不需要在标注啦,只需要运行一次
# 将上传的数据转换成微调格式
# 第一次使用时会下载各种模型,请耐心等待,后面就不会再下载啦
# 如果感觉下方输出过多,可以右键点击【清除输出】
from util.annotation import annotation_dataset
label_result = annotation_dataset(data_dir, label_path)---------------------------------------------------------------------------ModuleNotFoundError Traceback (most recent call last)/tmp/ipykernel_286/3639803463.py in <module> 3 # 第一次使用时会下载各种模型,请耐心等待,后面就不会再下载啦 4 # 如果感觉下方输出过多,可以右键点击【清除输出】 ----> 5 from util.annotation import annotation_dataset 6 label_result = annotation_dataset(data_dir, label_path) ~/util/annotation.py in <module> 7 import shutil 8 import uuid ----> 9 from paddlespeech.cli.asr.infer import ASRExecutor 10 from paddlespeech.cli.tts.infer import TTSExecutor 11 from paddlespeech.t2s.exps.syn_utils import get_frontend ModuleNotFoundError: No module named 'paddlespeech'
In [ ]
from util.finetuneTTS import finetuneTTS
# 训练参数配置# 如果你对深度学习训练不熟悉,就按照默认的方式训练就好啦,不需要过多关注其它参数
# 如果感觉下方输出过多,可以右键点击【清除输出】
finetuneTTS(label_path, exp_name, max_finetune_step=100, batch_size=32, learning_rate=0.001)# 如果你有一定深度学习的基础,欢迎通过这个部分来调整参数,接口中暴露的参数有 max_finetune_step, batch_size, learning_rate
# start_step 和 end_step 分别控制开始和结束,方便分步调试
# finetuneTTS(label_path, exp_name, start_step=1, end_step=8, max_finetune_step=100, batch_size=32, learning_rate=0.001)
In [ ]
# 模型导出成静态图
# 如果上面,跑到中途不想跑了,停掉以后可以用这行代码,将静态图转成动态图
# 上面如果正常结束的话会自动导出
# 第8步是动态图导出
# finetuneTTS(label_path, exp_name, start_step=8, end_step=8, max_finetune_step=100, batch_size=32, learning_rate=0.001)In [ ]
from util.finetuneTTS import generateTTS, generateTTS_inference_adjust_duration# 格式
# "文件名": "需要合成的文本"
# 新增 SSML 多音字处理(句子只支持中文)
# SSML使用说明:https://github.com/PaddlePaddle/PaddleSpeech/discussions/2538
text_dict = {"1": "欢迎使用 Paddle Speech 做智能语音开发工作。","2": "<speak>前浪<say-as pinyin='dao3'>倒</say-as>在沙滩上</speak>"
}# 生成想要合成的声音
# 声码器可选 【PWGan】【WaveRnn】【HifiGan】
# 动态图推理,可调节速度, alpha 为 float, 表示语速系数,可以按需求精细调整
# alpha 越小,速度越快,alpha 越大,速度越慢, eg, alpha = 0.5, 速度变为原来的一倍, alpha = 2.0, 速度变为一半
generateTTS_inference_adjust_duration(text_dict, exp_name, voc="PWGan", alpha=1.0)In [ ]
import os
import IPython.display as ipd
from util.finetuneTTS import exp_base# 测试第一句:中英文合成成功
exp_path = os.path.join(exp_base + exp_name)
wav_output_dir = os.path.join(exp_path, "wav_out")
ipd.Audio(os.path.join(wav_output_dir, "1.wav"))In [ ]
# 测试第2句,指定多音字的发音
ipd.Audio(os.path.join(wav_output_dir, "2.wav"))如何下载音频:上面代码块运行后,按下面的方式下载音频
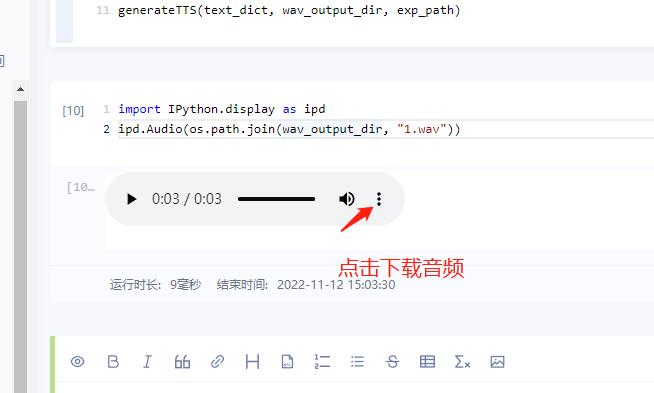
5.3 微调模型下载与使用
5.3.1 模型下载
上面 微调训练 结束后,会在 【inference】目录下生成对应 【exp_name】的模型文件夹,使用下面的代码块生成对应压缩文件,右键点击下载即可
进入 inference 目录
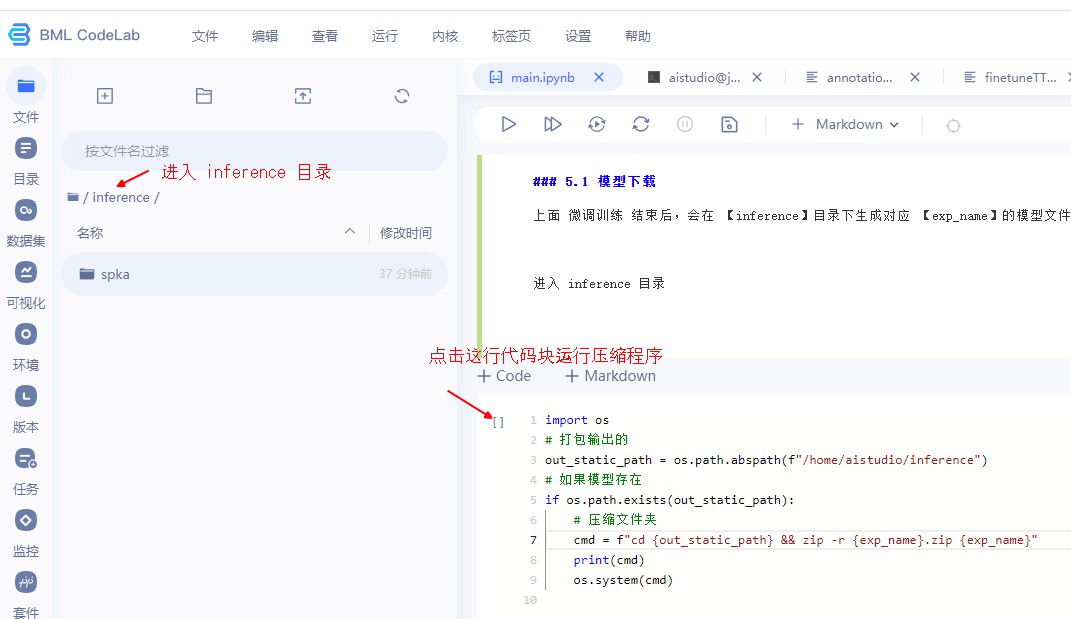
In [ ]
import os
# 打包输出的
out_static_path = os.path.abspath(f"/home/aistudio/inference")
exp_name = "spka"
# 如果模型存在
if os.path.exists(out_static_path):# 压缩文件夹cmd = f"cd {out_static_path} && zip -r {exp_name}.zip {exp_name}"print(cmd)os.system(cmd)
生成压缩文件后,点击下载模型文件
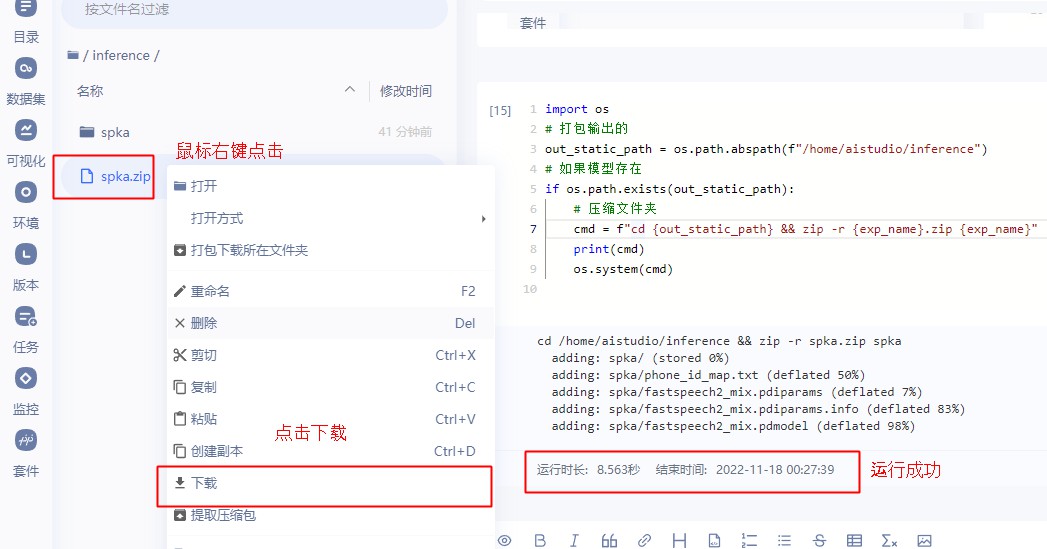
5.3.2 在其它的环境中使用微调后的模型
通过配置 CLI 来使用微调后的 TTS,可以参考下面的代码
在其他的环境中如何使用 导出 的静态图模型进行推理
提前下载好预训练声码器,不同的声码器名称不同, 提前下载好微调后的声学模型,并在对应的文件夹下解压
声码器下载地址:
【pwgan_aishell3_static】 【hifigan_aishell3】 【wavernn_csmsc】
本地运行详细流程,可以参考: 【有手就行】使用自己的声音做语音合成(二)本地部署
In [ ]
from pathlib import Path
import soundfile as sf
import os
from paddlespeech.t2s.exps.syn_utils import get_am_output
from paddlespeech.t2s.exps.syn_utils import get_frontend
from paddlespeech.t2s.exps.syn_utils import get_predictor
from paddlespeech.t2s.exps.syn_utils import get_voc_output# 在其他环境中,记得修改下面这两个变量的路径
am_inference_dir = os.path.join("/home/aistudio/inference", exp_name)
voc_inference_dir = "/home/aistudio/PaddleSpeech/examples/other/tts_finetune/tts3/models/pwgan_aishell3_static_1.1.0" # 这里以 pwgan_aishell3 为例子# 音频生成的路径,修改成你音频想要保存的路径
wav_output_dir = "work/inference_demo"# 选择设备[gpu / cpu],这里以GPU为例子,
device = "cpu"# 想要生成的文本和对应文件名text_dict = {"1": "今天天气真不错,欢迎和我一起玩。","2": "我认为跑步给我的身体带来了健康。",
}# frontend
frontend = get_frontend(lang="mix",phones_dict=os.path.join(am_inference_dir, "phone_id_map.txt"),tones_dict=None
)# am_predictor
am_predictor = get_predictor(model_dir=am_inference_dir,model_file="fastspeech2_mix" + ".pdmodel",params_file="fastspeech2_mix" + ".pdiparams",device=device)# voc_predictor
voc_predictor = get_predictor(model_dir=voc_inference_dir,model_file="pwgan_aishell3" + ".pdmodel", # 这里以 pwgan_aishell3 为例子,其它模型记得修改此处模型名称params_file="pwgan_aishell3" + ".pdiparams",device=device)output_dir = Path(wav_output_dir)
output_dir.mkdir(parents=True, exist_ok=True)sentences = list(text_dict.items())merge_sentences = True
fs = 24000
for utt_id, sentence in sentences:am_output_data = get_am_output(input=sentence,am_predictor=am_predictor,am="fastspeech2_mix",frontend=frontend,lang="mix",merge_sentences=merge_sentences,speaker_dict=os.path.join(am_inference_dir, "phone_id_map.txt"),spk_id=0, )wav = get_voc_output(voc_predictor=voc_predictor, input=am_output_data)# 保存文件sf.write(output_dir / (utt_id + ".wav"), wav, samplerate=fs)In [ ]
import IPython.display as ipd
ipd.Audio(os.path.join(wav_output_dir, "1.wav"))6. 趣味实验功能区
这个模块会开放一些有趣的TTS玩法,但是对开发者的技术能力有一定要求,大家根据自己的需要进行开发
6.1 帧级别调整音素长度进行语音合成
这部分将允许用户介入Duration的生成过程,通过编辑网页的方式改变音素的发音时长,duration 以整数为单位,一帧是12.5ms,欢迎大家体验, 音素 sp 代表静音帧。
比如想要得到一个 125 ms 的静音帧, 设置对应位置的 sp 为 10 即可
可视化使用方式:




具体大家可以到aistadio上去亲自体验一下哦!
【有手就行】使用你自己的声音做语音合成,CPU都能跑,亲测有效 - 飞桨AI Studio星河社区
相关文章:
【有手就行】使用你自己的声音做语音合成,CPU都能跑,亲测有效
此文介绍在百度飞桨上一个公开的案例,亲测有效。 厌倦了前篇一律的TTS音色了吗?打开短视频听来听去就是那几个声音,快来试试使用你自己的声音来做语音合成吧!本教程非常简单,只需要你能够上传自己的音频数据就可以(建议…...

《ESP8266通信指南》番外-(附完整代码)ESP8266获取DHT11接入(基于Lua)
前言 此篇为番外篇,是 ESP8266 入门的其他功能教程,包括但不限于 DHT11 驱动TCP 通信Thingsboard 平台的接入阿里云物联网云平台接入华为云平台接入 1. 小节目标 使用 Lua 驱动 DHT11 传感器,获取温湿度的值 2. 进入主题 NodeMCU 基于 LUA 相关资料 官方文档:…...
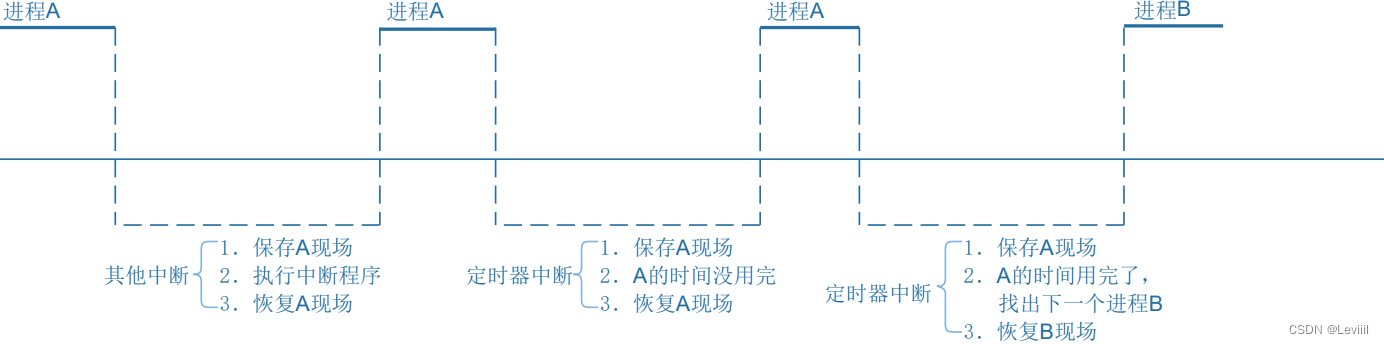
[IMX6ULL驱动开发]-Linux对中断的处理(一)
目录 中断概念的引入 ARM架构中断的流程 异常向量表 Linux系统对中断的处理 ARM对程序和中断的处理 Linux进程中断处理 中断概念的引入 如何理解中断,我们可以进行如下抽象。把CPU看做一个母亲,当它正在执行任务的时候,可以看为是一个母…...
)
PHP基础学习笔记(面向对象OOP)
类和对象 <?php //声明一个名为 Fruit 的类,它包含两个属性($name 和 $color)以及两个用于设置和获取 $name 属性的方法 set_name() 和 get_name(): class Fruit {// Propertiespublic $name;public $color;// Methodsfuncti…...
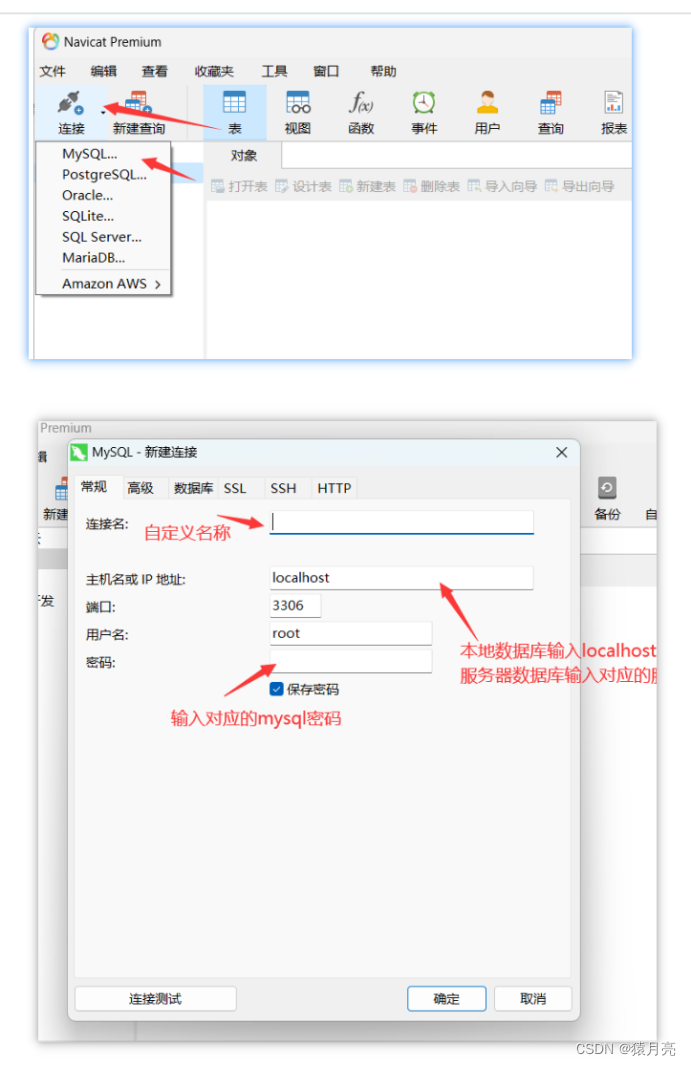
Mysql超详细安装配置教程(保姆级图文)
MySQL是一种流行的开源关系型数据库管理系统,它广泛用于网站和服务的数据存储和管理。MySQL以其高性能、可靠性和易用性而闻名,是许多Web应用程序的首选数据库解决方案之一。 一、下载安装包 (1)从网盘下载安装文件 点击此处直…...
HR招聘测评,如何判断候选人的团队协作能力?
什么是团队协作能力? 团队协作能力,说的是在集体环境中,能同他人协同工作,为追求共同的目标而努力,其中包括沟通,表达,协调,尊重,信任,责任共担等一系列综合…...
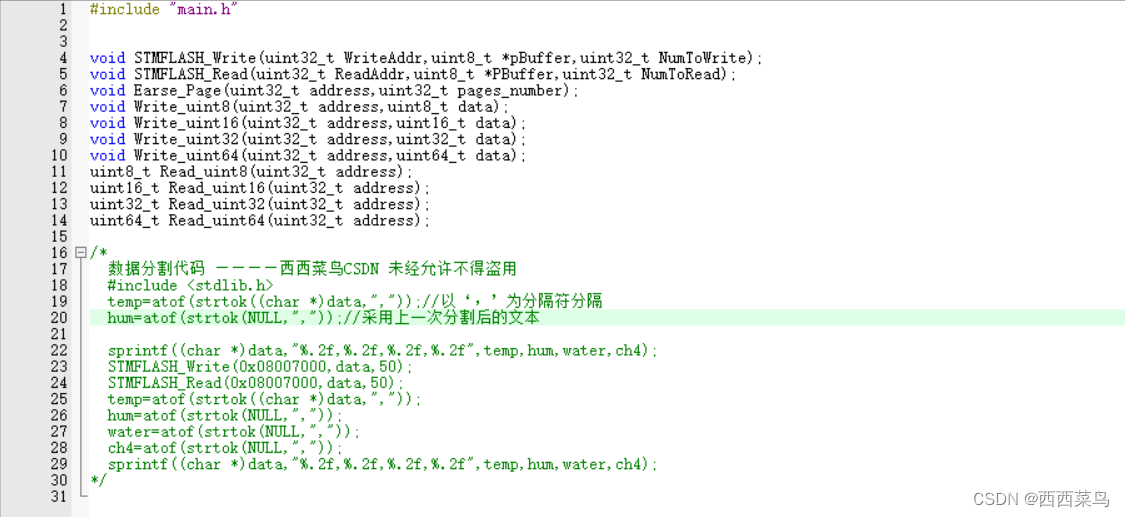
[STM32-HAL库]Flash库-HAL库-复杂数据读写-STM32CUBEMX开发-HAL库开发系列-主控STM32F103C6T6
目录 一、前言 二、实现步骤 1.STM32CUBEMX配置 2.导入Flash库 3.分析地址范围 4.找到可用的地址 5.写入读取普通数据 6.写入读取字符串 6.1 存储相关信息 6.2 存取多个参数 三、总结及源码 一、前言 在面对需要持久化存储的数据时,除了挂载TF卡,我们…...

windows 下访问 csdn 异常问题
windows下访问csdn可能会出现什么 确认是真人 或着直接连接不上的情况, 需要在 C:\Windows\System32\drivers\etc 路径下 hosts文件中添加如下内容 1.180.18.85 blog.csdn.net 如果目录下没有hosts文件就自己建一个...
vue3结合element-plus之如何优雅的使用表格
背景 表格组件的使用在后台管理系统中是非常常见的,但是如果每次使用表格我们都去一次一次地从 element-plus 官网去 复制、粘贴和修改成自己想要的表格。 这样一来也说得过去,但是如果我们静下来细想不难发现,表格的使用都是大同小异的,每次都去复制粘贴,对于有很多表格…...

网络协议——Modbus-RTU
目录 1、简介 2、消息格式 3、Modbus寄存器种类说明 4、功能码01H 5、功能码02H 6、功能码03H 7、功能码04H 8、功能码05H 9、功能码06H 10、功能码0FH 11、功能码10H 1、简介 Modbus-RTU(Remote Terminal Unit)是一种串行通信协议࿰…...
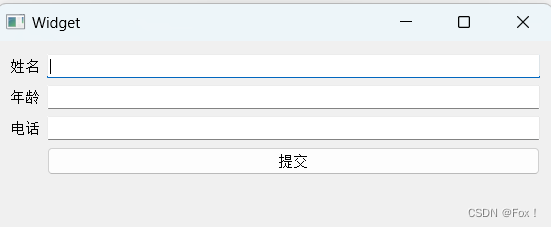
【Qt】如何优雅的进行界面布局
文章目录 1 :peach:写在前面:peach:2 :peach:垂直布局:peach:3 :peach:水平布局:peach:4 :peach:网格布局:peach:5 :peach:表单布局:peach: 1 🍑写在前面🍑 之前使⽤ Qt 在界⾯上创建的控件, 都是通过 “绝对定位” 的⽅式来设定的。也就是每个控件所在…...

【八股系列】分别说一下nodeJS和浏览器的事件循环机制?
文章目录 1. NodeJS1.1 Node.js 事件循环概念1.2 Node.js 事件循环工作流程1.3 Node.js 事件循环示例 2. 浏览器2.1 浏览器事件循环概念2.2 浏览器事件循环工作流程2.3 浏览器事件循环示例 1. NodeJS 1.1 Node.js 事件循环概念 在 Node.js 中,事件循环由 libuv 库…...
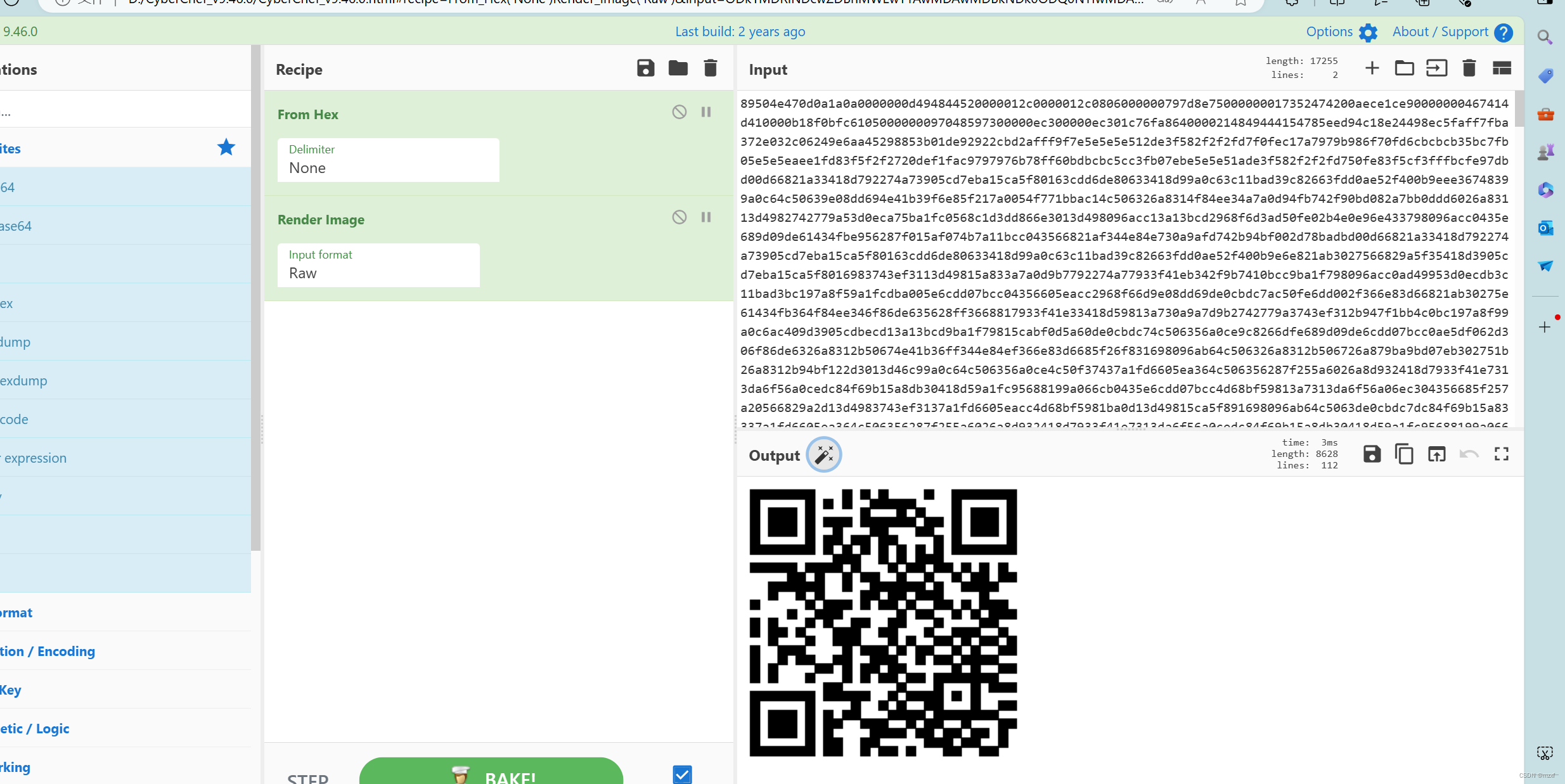
关于基础的流量分析(1)
1.对于流量分析基本认识 1)简介:网络流量分析是指捕捉网络中流动的数据包,并通过查看包内部数据以及进行相关的协议、流量分析、统计等来发现网络运行过程中出现的问题。 2)在我们平时的考核和CTF比赛中,基本每次都有…...

数据结构---树,二叉树的简单概念介绍、堆和堆排序
树 树的概念和结构 结构 在我们将堆之前,我们先来了解一下我们的树。 我们的堆是属于树里面的一种, 树是一种非线性结构,是一种一对多的一种结构,也就是我们的一个节点可能有多个后继节点,当然也可以只有一个或者没…...
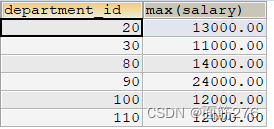
MySQL聚合函数(多行函数)
聚合函数(多行函数) 聚合函数作用于一组数据,并对一组数据返回一个值。 常见聚合函数 AVG和SUM函数 只作用于数值类型数据,不包含NULL 求工资平均值和总和 MIN和MAX函数 可以作用于任何数据类型(如字符串,…...

智慧教室课堂-专注度及考试作弊系统、课堂动态点名,情绪识别、表情识别和人脸识别结合
课堂专注度分析: 课堂专注度表情识别 作弊检测: 关键点计算方法 转头(probe)低头(peep)传递物品(passing) 侧面的传递物品识别 逻辑回归关键点 使用: 运行setup.py安装必要内容 python setup.py build develop 运行demo_inference.py 将…...

单例模式简要介绍
学习目标: 单例模式 学习内容: 单例模式(Singleton Pattern)是一种设计模式,其主要目的是确保一个类只有一个实例,并且提供一个全局的访问点。它常用于需要全局唯一对象的场景,例如日志记录器、…...
深度学习面试问题总结(21)| 模型优化
本文给大家带来的百面算法工程师是深度学习模型优化面试总结,文章内总结了常见的提问问题,旨在为广大学子模拟出更贴合实际的面试问答场景。在这篇文章中,我们还将介绍一些常见的深度学习面试问题,并提供参考的回答及其理论基础&a…...

4月手机行业线上市场销售数据分析
政府对智能手机行业的支持政策,如5G推广,以及相关的产业政策,都在一定程度上推动了智能手机市场的发展,再加上AI应用的推广和全球科技迅猛发展,中国手机市场在2024年迎来了恢复性增长。 据鲸参谋数据统计,…...

首都师范大学聘请旅美经济学家向凌云为客座教授
2024年4月17日,首都师范大学客座教授聘任仪式在首都师范大学资源环境与旅游学院举行。首都师范大学资源环境与旅游学院院长吕拉昌主持了仪式,并为旅美经济学家向凌云教授颁发了聘书。 吕拉昌院长指出,要贯彻教育部产学研一体化战略࿰…...

Sunshine自托管游戏串流终极指南:打造跨平台家庭游戏云的完整解决方案
Sunshine自托管游戏串流终极指南:打造跨平台家庭游戏云的完整解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下这样的场景:您坐在客厅沙发上…...

Midjourney中画幅风格不生效?5个致命配置错误正在 silently 毁掉你的成片率
更多请点击: https://kaifayun.com 第一章:Midjourney中画幅风格失效的真相与底层机制 Midjourney 中的中画幅(Medium Format)风格常被用户以 --style medium-format 或关键词 medium format film 调用,但大量实测表…...

利用python计算
#题1:11/21/31/4...1/100sum1 0for i in range(1, 101):sum1 1 / iprint("题1结果:", sum1)# 题2:计算1 - 1/2 1/3 - 1/4 ... 1/nn 100 sum2 0for i in range(1, n1):# 奇数项加,偶数项减if i % 2 1:sum2 1 / ielse:sum2…...

NY382固态MT29F32T08GSLBHL8-24QM:B
NY382固态MT29F32T08GSLBHL8-24QM:B当工业设备在极端环境下稳定运行,其核心存储的每一次数据读写,都决定着生产线的效率与安全。一颗看似平凡的存储芯片,背后是无数工程师在稳定性、耐久性与环境适应性之间的精妙权衡。今天,我们聚…...

CANN/asc-devkit SIMT数学函数文档
lrintf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

2026年10款降AI率网站横评:最高AI率100%直降至0.12%
2026年全球学术界对AIGC内容的监管持续收紧,论文查重与AI痕迹检测标准迎来全面升级,高校及科研机构纷纷引入更精准的检测系统,导致学术不端行为面临更严苛的审查。在此背景下,论文降AI工具市场需求激增,用户规模在半年…...

如何快速掌握DeepL翻译插件:浏览器跨语言阅读的终极解决方案
如何快速掌握DeepL翻译插件:浏览器跨语言阅读的终极解决方案 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension DeepL翻译插件是一款基于DeepL API的高质量…...

FreeRTOS队列深度剖析:从环形缓冲区到任务阻塞,你的消息真的发对了吗?
FreeRTOS队列深度剖析:从环形缓冲区到任务阻塞,你的消息真的发对了吗? 在嵌入式实时系统中,任务间的通信机制如同城市中的交通网络,而FreeRTOS队列则是这条网络中最核心的高速公路。当你的系统从简单的单任务演变为多任…...

【Spring】 AOP 核心原理,与声明式事务传播机制
一、什么是 AOPAOP(Aspect Oriented Programming,面向切面编程)核心思想在不修改原有业务代码的情况下,对方法进行统一增强。例如:日志记录;权限校验;事务管理;性能统计;…...

论完善代码版本信息构建AI在精工产业与智能设备短板—东方仙盟
出众的现代 AI时至今日,人工智能发展日新月异。在 UI 设计、网页开发、纯软件系统搭建等不依托实体硬件的领域,AI 表现已然成熟。常规信息化工作,AI 皆可独立完成,效率出众,为日常开发与设计减负良多。精工硬件领域 AI…...