数据结构---树,二叉树的简单概念介绍、堆和堆排序
树
树的概念和结构
结构
在我们将堆之前,我们先来了解一下我们的树。
我们的堆是属于树里面的一种,
树是一种非线性结构,是一种一对多的一种结构,也就是我们的一个节点可能有多个后继节点,当然也可以只有一个或者没有。我们的这些有限结点组成一个具有层次关系的集合,我们把它叫做树是因为他的结构和一颗倒挂的数很像。
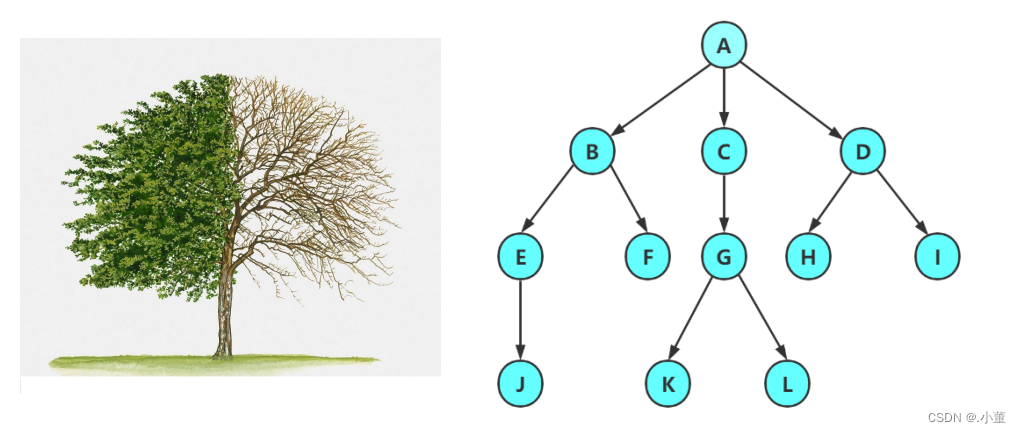
- 在我们的最上面的节点叫做根节点,他没有前驱。
- 我们树的其他节点具有0个或者多个后继节点。但是在只有一个前驱节点。
- 因此,树是递归定义的。
- 数的子树是不能相交的。相交的话就是不是我们的树了,是另外一种结构–图。
树的一些概念
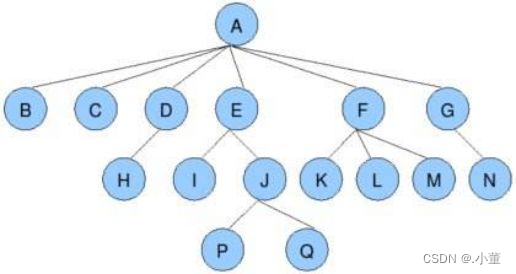
**结点的度:**一个结点含有的子树的个数称为该结点的度;
如上图:A的为6
叶结点或终端结点:度为0的结点称为叶结点; 如上图:B、C、H、I…等结点为叶结点
非终端结点或分支结点:度不为0的结点; 如上图:D、E、F、G…等结点为分支结点
**双亲结点或父结点:**若一个结点含有子结点,则这个结点称为其子结点的父结点; 如上图:A是B的父结点
**孩子结点或子结点:**一个结点含有的子树的根结点称为该结点的子结点; 如上图:B是A的孩子结点
**兄弟结点:**具有相同父结点的结点互称为兄弟结点; 如上图:B、C是兄弟结点
**树的度:**一棵树中,最大的结点的度称为树的度; 如上图:树的度为6
**结点的层次:**从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
**树的高度或深度:**树中结点的最大层次; 如上图:树的高度为4
堂兄弟结点:双亲在同一层的结点互为堂兄弟;如上图:H、I互为兄弟结点
**结点的祖先:**从根到该结点所经分支上的所有结点;如上图:A是所有结点的祖先
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。如上图:所有结点都是A的子孙
**森林:**由m(m>0)棵互不相交的树的集合称为森林;
树的表示
我们的树由于太过于有多个后继节点导致我们的树在构建的时候会比较麻烦,我们可以用我们的链表来表示,也可以用数组来表示。
链式
对与我们用链式来存储我们的树的话,就需要我们去去存储他的后继节点,但是我们这里的节点的每个后继节点数目不同,我们治理有一下个很好的方法-----孩子兄弟表示法。
就是我们只存下我们的第一个孩子节点,在定义一个兄弟节点,指向他的兄弟 节点,这样当我们的节点具有同一个节点时候我们第一个孩子节点就会是这个孩子链的头结点,我们沿着我们的兄弟指针就可以找到双亲的所有孩子节点。
typedef int DataType;
struct Node
{struct Node* firstChild1; // 第一个孩子结点struct Node* pNextBrother; // 指向其下一个兄弟结点DataType data; // 结点中的数据域
};
数组
我们这里用数组存储主要是利用了双亲和孩子节点的下标关系。主要是存储二叉树的。
二叉树的相关知识
一棵二叉树是结点的一个有限集合,该集合:
- 或者为空
- 由一个根结点加上两棵别称为左子树和右子树的二叉树组成

特点:
3. 二叉树不存在度大于2的结点
4. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
一张有意思的图:


**特殊的二叉树:
**
- **满二叉树:**一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是
说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。 - **完全二叉树:**完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对
应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。

二叉树的性质
- 若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有 个结点.
- 若规定根结点的层数为1,则深度为h的二叉树的最大结点数是 .2^(
- 对任何一棵二叉树, 如果度为0其叶结点个数为 n1, 度为2的分支结点个数为n2 ,则有 n2=n1 +1
- 对于孩子和双亲的关系,如果我们给每个节点都标都标上序号的话,如果为空我们也还是要为那个空节点保留下这个序号,我们就可以发现一个双亲和他们的孩子节点的下标关系**:左孩子=父亲+1;右孩子=父亲+2;**
由于我们整数激素那取整 的关系,我们利用孩子节点来求我们的父亲就可以写成:父亲=(孩子-1)/2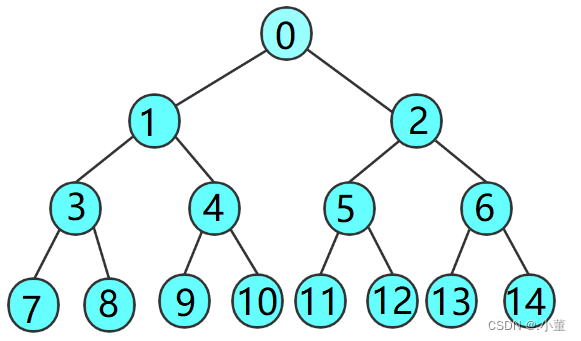
- 若规定根结点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2为底,n+1为对数)。
数组存储二叉树
我使用数组存储还是利用了二叉树的那条双亲和孩子的序号关系,我的通过计算下标就可以找到他们的双亲节点和孩子节点。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
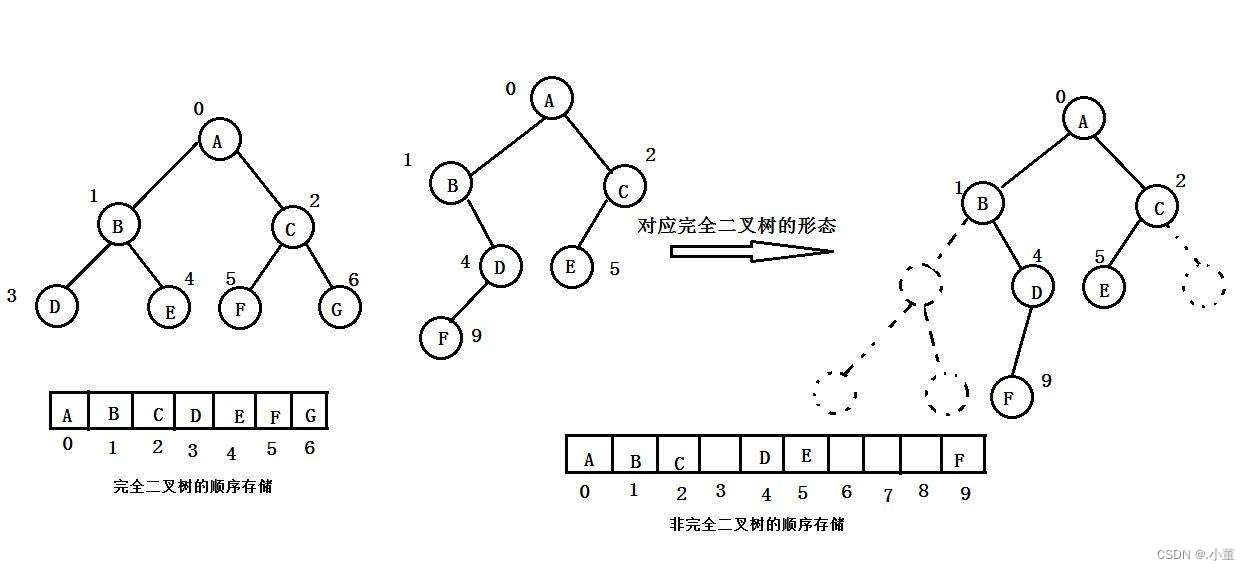
如果我们的二叉树是一颗完全二叉树的话我们可以考虑用数组去存储,这样操作起来会方便很多。
当然我们的树越接近满二叉树,我们的数组存储效率会很高,空间浪费的会很少。但是我们的二叉树的不是一个完全二叉树的话我们的存储效率会低很多,我峨嵋你要按照双亲的关系来存储。那么那些空姐带你的地方我们是不可以存储值的。
下面我们要讲的堆就是一颗完全二叉树,适合用我们的数组去存储。
堆
堆的概念及结构
如果有一个关键码的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储
在一个一维数组中,并满足: <= 且 <= ( >= 且 >= ) i = 0,1,2…,则称为小堆(或大堆)。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
总来说就是我们的双亲节点的值总是大于(小于)我们的孩子节点,
如果双亲总是大于我们的孩子节点就是大堆;
双亲小于孩子节点的话就是小堆;
现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统
虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
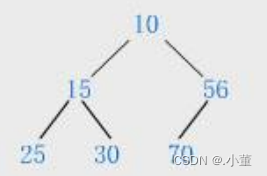
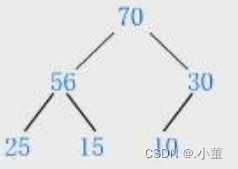
第一个是小堆,第二个是大堆。
堆的性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
堆的实现
我们实现我们的堆采用的是数组去存储的,维护我们堆的结构体:
typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;int _size;//数组里面有多少个有效数值int _capacity;//数组的空间大小
}Heap;我们下面将我们堆实现的一些接口:
void HeapInit(Heap* php);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
//进行调整(小堆),向上调整
void AdjustUp(HPDataType* data, int child);
//交换
void Swag(int* a, int* b);
//向下调整
void AdjustDown(HPDataType* data, int parents, int size);
初始化
我们的初始化就是给我们结构体中的数组开辟空间,不开也行,给我们的指针置空。
代码:
//堆的初始化
void HeapInit(Heap* php)
{assert(php);php->_a = (HPDataType*)malloc(sizeof(HPDataType) * 4);php->_capacity = 4;php->_size = 0;
}
堆的销毁
我们的销毁就是将我们的申请的空间还给我们的操作系统就行,我们这里主要申请的空间就是我们的数组,只需要将我们的数组释放就行。
代码:
// 堆的销毁
void HeapDestory(Heap* hp)
{assert(hp);free(hp->_a);hp->_capacity = 0;hp->_size = 0;
}
堆的向下调整算法
我们的向下调整算法,有一个前提是L他们需要左右子树必须是堆,才好去调整。
int array[] = {27,15,19,18,28,34,65,49,25,37};我们这里建小堆
当我们的左右子树不是堆的时候就会导致他们的父子关系变化。
我们向下建堆的思想是我们的根和他的孩子中较小的进行比较,如果他大于那个较小的孩子就进行交换,,交换后该节点再继续和他交换后的新的孩子进行比较,如此一直到我们的这个节点小于他的较小的孩子节点或者一直到超出我们的书的最后的一个节点的下标(就是在我们树的最后一层,他没有孩子节点了)。
例子:

我们的小堆有一个特点是:我们的根节点是堆中最小的数值,这是因为我们的父亲节点一定小于孩子节点。
我峨嵋你大堆就是根接待你是数值最大的。
代码:
//向下调整,小堆
void AdjustDown(HPDataType* data, int parents,int size)
{assert(data);int child = parents * 2 + 1;while (child <= size-1){if ( child + 1 <= size - 1 && data[child] > data[parents * 2 + 2])child = parents * 2 + 2;if (data[child] < data[parents]){//双亲比孩子大,交换Swag(&data[child], &data[parents]);}else {break;}parents = child;child = parents * 2 + 1;}
}
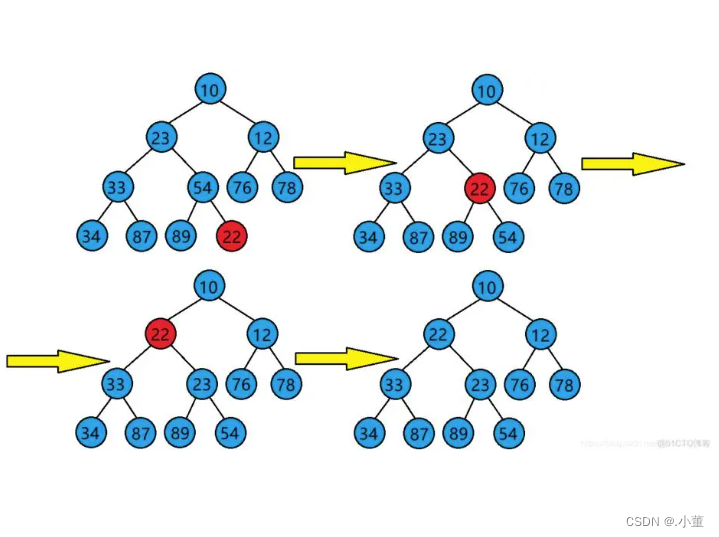
堆的向上调整算法
我们的向上调整算法是从我们的最后一个节点来进行的。 我们找到最后一个节点的父亲(通过他们的下标的关系),我们将该节点进行比较,如果我们的节点比他的父亲节点小就进行交换,我们再继续和他的新父亲节点进行比较,一直到他的父亲节点小于他,或者我们这个节点来到了我们根节点的位置。
这里需要注意的循环条件的判定,如果你是>=0的话就会导致死循环,当年我们该节点来到我们的根节点位置下标为0,南无我们用公式去算他的父亲节点:(0-1)/2,由于取整的特点,这个的值还会是0,并不会小于0;
代码:
//向上调整(小堆)
void AdjustUp(HPDataType* data,int child)
{int parents = (child - 1) / 2;while (child > 0){if (data[child] < data[parents]){//双亲大于孩子,要交换Swag(&data[child], &data[parents]);child = parents;parents = (parents - 1) / 2;}else {break;}}
}
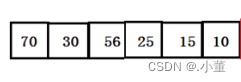
往堆中插入
我们往堆中插入是先将我们的插入的元素放在我们的数组的最后一个位置。我们插入了之后还要是我们的数组仍然是个堆,我们还要进行向上调整的操作,我们只需要调整刚进入的新的元素。形成一个新的堆。

代码:
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{assert(hp);int child = hp->_size;//判断空间是否充足if (hp->_capacity == hp->_size){hp->_capacity = hp->_capacity * 2;hp->_a = (HPDataType*)realloc(hp->_a, sizeof(HPDataType) * hp->_capacity);if (hp == NULL){perror("hp realloc!");return;}}//插入新的数据hp->_a[hp->_size] = x;hp->_size++;//小堆进行调整AdjustUp(hp->_a,child);}
堆中元素的删除
我们删除元素如果删除我们的叶子节点显然是很容易的,所以我们要删除的我们的根节点。
但是如果我们的将我们的根节点删除的话,父子关系也会变乱,出现了你的兄弟节点成为了你的父亲节点,所以我们要先将我们的根节点和我们最后一个节点进行交换,再将我们的数组的大小改变,并不需要我们将值进行改变。交换之后,我们的数组也不是一个堆了,但是他的左右子树仍旧是一个小堆,这是我们就可以进行向下调整,重新将我们的数组变成一个新的堆。
代码:
// 堆的删除
void HeapPop(Heap* hp)
{//将根上面的值与我们的最后一个节点交换,在进行调整assert(hp);Swag(&hp->_a[0], &hp->_a[hp->_size - 1]);hp->_size--;AdjustDown(hp->_a,0, hp->_size);}
取堆顶的数据
我们只需要将我们的数组中下标为0的元素返回就行
代码:
HPDataType HeapTop(Heap* hp)
{assert(hp);return hp->_a[0];
}
堆的判空和数据个数
我们结构体中定义了一个size变量来记录我们元素的个数,只需要对这个只进行判断是否为0,
// 堆的数据个数
int HeapSize(Heap* hp) {assert(hp);return hp->_size;
}
// 堆的判空
int HeapEmpty(Heap* hp)
{assert(hp);return hp->_size == 0 ? 1 : 0;
}
相关文章:
数据结构---树,二叉树的简单概念介绍、堆和堆排序
树 树的概念和结构 结构 在我们将堆之前,我们先来了解一下我们的树。 我们的堆是属于树里面的一种, 树是一种非线性结构,是一种一对多的一种结构,也就是我们的一个节点可能有多个后继节点,当然也可以只有一个或者没…...
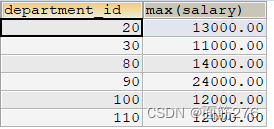
MySQL聚合函数(多行函数)
聚合函数(多行函数) 聚合函数作用于一组数据,并对一组数据返回一个值。 常见聚合函数 AVG和SUM函数 只作用于数值类型数据,不包含NULL 求工资平均值和总和 MIN和MAX函数 可以作用于任何数据类型(如字符串,…...

智慧教室课堂-专注度及考试作弊系统、课堂动态点名,情绪识别、表情识别和人脸识别结合
课堂专注度分析: 课堂专注度表情识别 作弊检测: 关键点计算方法 转头(probe)低头(peep)传递物品(passing) 侧面的传递物品识别 逻辑回归关键点 使用: 运行setup.py安装必要内容 python setup.py build develop 运行demo_inference.py 将…...

单例模式简要介绍
学习目标: 单例模式 学习内容: 单例模式(Singleton Pattern)是一种设计模式,其主要目的是确保一个类只有一个实例,并且提供一个全局的访问点。它常用于需要全局唯一对象的场景,例如日志记录器、…...
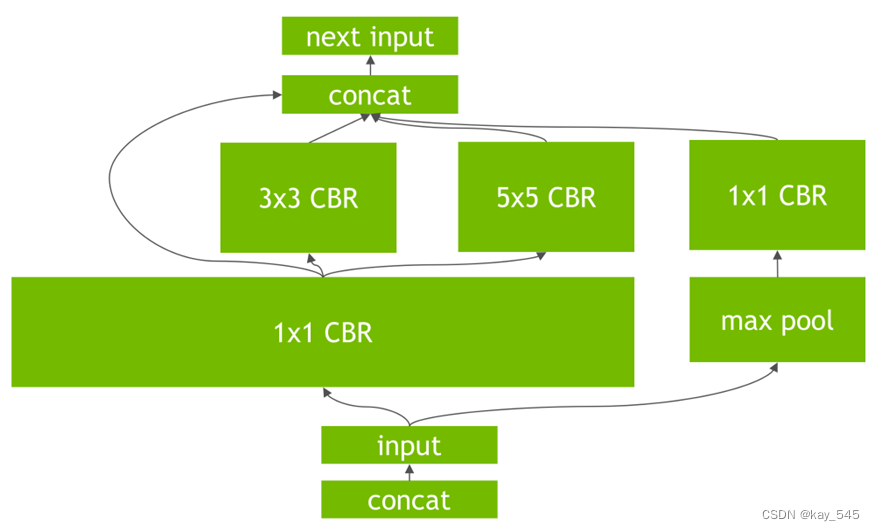
深度学习面试问题总结(21)| 模型优化
本文给大家带来的百面算法工程师是深度学习模型优化面试总结,文章内总结了常见的提问问题,旨在为广大学子模拟出更贴合实际的面试问答场景。在这篇文章中,我们还将介绍一些常见的深度学习面试问题,并提供参考的回答及其理论基础&a…...

4月手机行业线上市场销售数据分析
政府对智能手机行业的支持政策,如5G推广,以及相关的产业政策,都在一定程度上推动了智能手机市场的发展,再加上AI应用的推广和全球科技迅猛发展,中国手机市场在2024年迎来了恢复性增长。 据鲸参谋数据统计,…...

首都师范大学聘请旅美经济学家向凌云为客座教授
2024年4月17日,首都师范大学客座教授聘任仪式在首都师范大学资源环境与旅游学院举行。首都师范大学资源环境与旅游学院院长吕拉昌主持了仪式,并为旅美经济学家向凌云教授颁发了聘书。 吕拉昌院长指出,要贯彻教育部产学研一体化战略࿰…...

多电脑共享鼠标键盘
由于要在两个电脑之间共用一套鼠标键盘,所以在此记录一下。 mouse without borders Mouse without Borders 是一款免费的 Windows 工具,允许你在多台电脑之间共享鼠标和键盘。 安装与配置步骤 下载和安装: 前往 Mouse without Borders 官…...

展厅设计对企业有哪些作用
1、增强品牌形象 企业展厅对于增强企业品牌形象、提升企业的知名度和市场竞争力具有显著作用和意义。展厅作为企业对外的窗口,是客户和访客了解企业的第一印象。通过独特的设计风格和精心的展示布局,企业可以将自身的核心价值和文化理念巧妙地融入到展厅…...

LeetCode-102. 二叉树的层序遍历【树 广度优先搜索 二叉树】
LeetCode-102. 二叉树的层序遍历【树 广度优先搜索 二叉树】 题目描述:解题思路一:一个全局队列queue,while queue:去搜集当前所有queue的level解题思路二:背诵版解题思路三: 题目描述: 给你二…...

基于时频模糊算子的数据增强方法
关键词:时频模糊,数据增强,机器学习,音频预处理 我们引入时频模糊算子,该算子将信号的短时傅里叶变换与指定的核进行卷积,在SpeechCommands V2数据集上训练了一个使用ResNet-34架构的卷积神经网络(CNN)和一…...

浅谈后端整合Springboot框架后操作基础配置
boot基础配置 现在不访问端口8080 可以吗 我们在默认启动的时候访问的是端口号8080 基于属性配置的 现在boot整合导致Tomcat服务器的配置文件没了 我们怎么去修改Tomcat服务器的配置信息呢 配置文件中的配置信息是很多很多的... 复制工程 保留工程的基础结构 抹掉原始…...

英码科技算能系列边缘计算盒子再添新成员!搭载TPU处理器BM1688CV186AH,功耗更低、接口更丰富
在数据呈现指数级增长的今天,越来越多的领域和细分场景对实时、高效的数据处理和分析的需求日益增长,对智能算力的需求也不断增强。为应对新的市场趋势,英码科技凭借自身的硬件研发优势,携手算能相继推出了基于BM1684的边缘计算盒…...
selenium 爬取今日头条
由于今日头条网页是动态渲染,再加上各种token再验证,因此直接通过API接口获取数据难度很大,本文使用selenium来实现新闻内容爬取。 selenium核心代码 知识点: 代码中加了很多的异常处理,保证错误后重试,…...

docker 安装 yapi
文章目录 docker 安装 yapi一、拉取镜像二、创建目录三、添加配置文件四、初始化数据库表五、启动 yapi六、测试以及修改默认密码 没有 MongDB 的可以先看这个教程:MongDB安装教程 docker 安装 yapi 版本: 1.9.5 一、拉取镜像 docker pull yapipro/y…...
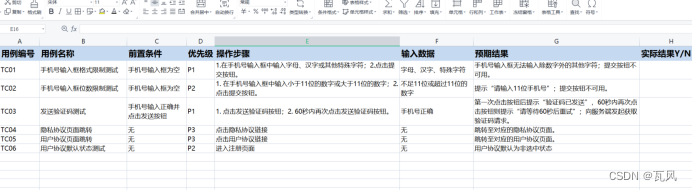
【AI如何帮你编写测试用例并输出表格格式】
1、工具:顺便使用一款生成式AI即可,此处用的是ChatGPT,Kimi这两个工具试验。 2、首先要拿到需求文档,根据需求文档向AI发出如下指令(Prompt) “请根据下面这段需求,编写测试用例: …...

九宫格转圈圈抽奖活动,有加速,减速效果
在线访问demo和代码在底部 代码,复制就可以跑 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><tit…...

利用阿里OSS服务给文件设置过期删除--简单版
在云存储广泛应用的今天,阿里云的Object Storage Service(OSS)以其高度可扩展性、安全性和成本效益,成为了众多企业和开发者存储海量数据的首选方案。随着数据量的不断膨胀,高效的数据管理和成本控制变得尤为重要。其中…...
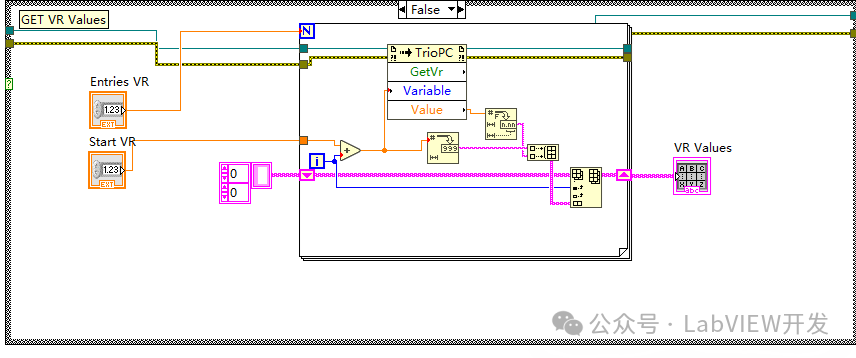
LabVIEW控制Trio控制器
将LabVIEW与Trio控制器结合,可以实现对复杂运动系统的控制和监测。以下是详细的方法和注意事项: 一、准备工作 软件安装: 安装LabVIEW开发环境,确保版本兼容性。 安装Trio控制器的相关驱动程序和软件,如Trio Motion …...
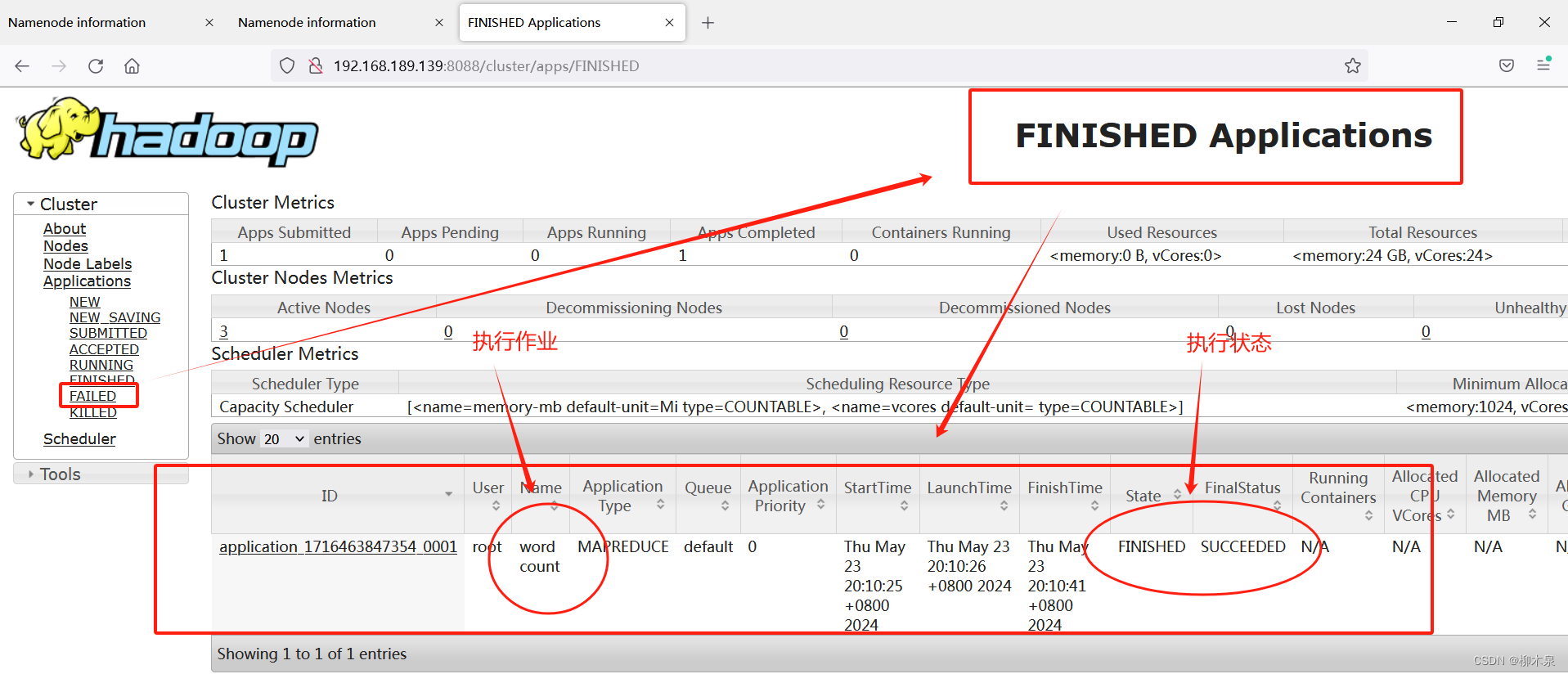
02--大数据Hadoop集群实战
前言: 前面整理了hadoop概念内容,写了一些概念和本地部署和伪分布式两种,比较偏向概念或实验,今天来整理一下在项目中实际使用的一些知识点。 1、基础概念 1.1、完全分布式 Hadoop是一个开源的分布式存储和计算框架࿰…...

Agent Runtime 重构:Session 作为事件日志的工程实践
1. 这不是新赛道,而是 runtime 层的“操作系统时刻”正在重演你有没有试过让一个 AI 代理连续工作四十分钟?不是闲聊,而是真干活:查数据库、调 API、读文档、写代码、改配置、再验证——一环扣一环。去年我带团队跑一个客户的数据…...

UE5下载安装避坑指南:硬件驱动、VS环境与版本管理实战
1. 这不是“点几下就能好”的安装,而是UE5项目生命周期的第一次关键决策很多人点开Epic Games Launcher,看到那个醒目的“Install”按钮,下意识就点了下去——结果十分钟后卡在98%,或者装完打开编辑器直接报错“Failed to load mo…...

基于i.MX8M Plus与5G的高性能AI边缘计算网关设计与实践
1. 项目概述:为什么我们需要一个“会思考”的边缘网关?在工业现场待久了,你一定会对几个场景深有感触:产线上几十台PLC和传感器,协议五花八门,Modbus、Profibus、CANopen,想统一采集数据得接一堆…...

消费电子贴膜的光学技术革新:圆偏振光与磁控溅射AR的原理解析
摘要随着用户对屏幕使用健康关注的提升,消费电子贴膜行业正在经历从“物理防护”到“光学级视觉守护”的技术升级。本文从光学原理出发,解析圆偏振光柔光标准与磁控溅射AR抗眩镀膜两项核心技术的工作机制,并分析其在屏幕保护场景中的应用逻辑…...

ViMax 为什么会冲上 GitHub Trending:AI 视频生成开始从“出片”转向“制片”
今天刷 GitHub Trending 时,ViMax 这项目很难不注意到。它挂着 674 stars today 的当日热度,标题写得也很直接:Agentic Video Generation,导演、编剧、制片、视频生成一体化。真正让我觉得它值得写,不只是因为它又是一…...

【项目实训】法律文书智能摘要系统6
本开发周期内,团队围绕系统的核心业务能力与底层技术架构取得了重大进展。我们不仅完成了面向用户的批量处理、法规知识库等关键功能模块,还从底层重构了AI助手的长程记忆机制,并夯实了文本处理管线与用户认证体系。各项开发工作均按计划推进…...
第3小节:超高纯氟化钙材料难点)
0603光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第3小节:超高纯氟化钙材料难点
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第3小节:超高纯氟化钙材料难点(深紫外配套核心,全维度死磕解析) 前置硬核声明 氟化钙单晶(CaF₂)是DUV深紫外光刻核心光学基…...

Python初学者项目练习23--计算圆的面积
一、练习题目 定义一个函数,这个函数用于计算并返回给定半径的圆的面积(要求结果保留两位小数) 二、代码 1.初始版本 代码如下: def area(r):"""作用:用于计算并返回给定半径的圆的面积(要求…...

学习大模型RAG与Agent智能体基础知识day1
开头 各位好啊! 如你所见博主是个新手,新到这是我第一次发博客。 现在是2026.5.20的凌晨(哦情人节到了…),前几周刚刚学完langchain的基础知识,跟着教程做了个前后端(前端因为没学所以代码直接搬…...

英伟达市值“富可敌国”,AI基建核心地位稳固但仍有隐忧
英伟达市值惊人,超多数国家经济体截至2026年5月21日,英伟达的市值大约在5.5万亿美元。据悉,按IMF 2026年4月版《世界经济展望》的名义GDP预测,美国约32.38万亿美元,中国约20.85万亿美元,德国约5.45万亿美元…...