深度学习面试问题总结(21)| 模型优化
本文给大家带来的百面算法工程师是深度学习模型优化面试总结,文章内总结了常见的提问问题,旨在为广大学子模拟出更贴合实际的面试问答场景。在这篇文章中,我们还将介绍一些常见的深度学习面试问题,并提供参考的回答及其理论基础,以帮助求职者更好地准备面试。通过对这些问题的理解和回答,求职者可以展现出自己的深度学习领域的专业知识、解决问题的能力以及对实际应用场景的理解。同时,这也是为了帮助求职者更好地应对深度学习目标检测岗位的面试挑战,提升面试的成功率和竞争力。
专栏地址:百面算法工程师——总结最新各种计算机视觉的相关算法面试问题
目录
21.1 你知道的模型压缩方法有哪些?
21.2 模型压缩的作用与意义
21.3 谈谈低秩近似
21.4 剪枝与稀疏约束
21.5 参数量化的优缺点
21.6 你了解知识蒸馏(Knowledge Distillation)吗
21.7 降低网络复杂度但不影响精度的方法有哪些
21.8 聊聊TensorRT加速原理
21.1 你知道的模型压缩方法有哪些?
模型压缩是一种减少深度学习模型大小和计算量的技术,旨在在减少模型存储和推理时的计算资源消耗的同时,尽量保持模型的性能。以下是一些常见的模型压缩方法:
- 参数剪枝(Parameter Pruning):通过移除模型中不重要的参数来减少模型的大小和计算量。这些不重要的参数可以是训练过程中稀疏的参数,也可以通过基于梯度或其他规则进行识别和剪枝。
- 网络剪枝(Network Pruning):与参数剪枝类似,但是网络剪枝通常涉及到整个神经网络结构的剪枝,包括层的剪枝、通道的剪枝等。
- 量化(Quantization):将模型中的参数和激活值从浮点数转换为低精度的表示形式,如8位整数或二值(1位)。这样可以减少模型的存储需求和计算量,并且可以加速推理过程。
- 知识蒸馏(Knowledge Distillation):通过使用一个大型的教师模型来指导一个小型的学生模型学习,从而传递教师模型的知识给学生模型。这样可以减少学生模型的大小和计算量,同时保持较高的性能。
- 参数量化(Parameter Quantization):通过将模型中的参数表示为更紧凑的形式来减少模型的大小,如使用低精度的浮点数或固定点数。
- 模型蒸馏(Model Distillation):与知识蒸馏类似,但是模型蒸馏不仅传递输出的概率分布,还可以传递其他中间层的信息。
这些方法通常可以单独应用,也可以结合使用以进一步减少模型的大小和计算量。不同的方法适用于不同的场景和需求,需要根据具体情况进行选择和调整。
21.2 模型压缩的作用与意义
模型压缩在深度学习领域中具有重要的作用和意义,主要体现在以下几个方面:
- 减少存储和传输成本: 深度学习模型通常包含大量参数,导致模型文件庞大,占用大量存储空间。在部署到移动设备、边缘设备或者在网络传输模型时,模型大小的压缩可以显著减少存储和传输成本,提高效率。
- 降低计算资源需求: 大型深度学习模型需要昂贵的计算资源进行训练和推理,这对于一些资源受限的设备如移动端或嵌入式系统来说可能是不可行的。通过模型压缩可以降低模型的计算复杂度,使得它们能够在资源有限的环境下运行。
- 加速推理速度: 压缩后的模型通常具有更简洁的结构和更少的参数,这可以加速模型的推理速度,使得在实时应用中能够更快地处理数据。
- 提高隐私安全性: 在一些场景中,原始的大型深度学习模型可能存在隐私泄露的风险,因为它们可能包含了过多的个人数据。通过模型压缩,可以减少模型中包含的敏感信息,降低隐私泄露的风险。
- 支持部署到边缘设备: 边缘计算是一种将数据处理和分析推送到接近数据源的计算资源上的模式,可以减少数据传输的延迟和带宽消耗。通过模型压缩,可以使得深度学习模型能够更容易地部署到边缘设备,从而实现更快速的响应和更高效的资源利用。
总的来说,模型压缩可以在各种场景下发挥作用,包括移动端应用、边缘计算、大规模部署等,有助于提高模型的性能、降低成本、加强隐私保护等方面。
21.3 谈谈低秩近似
低秩近似是一种模型压缩的技术,通过将原始模型的参数矩阵近似为低秩矩阵来减少模型的参数数量和计算复杂度。在深度学习中,一个参数矩阵的秩(rank)表示该矩阵的线性独立维度的数量,而低秩矩阵则是指其秩远远小于原始参数矩阵的矩阵。
低秩近似的操作通常可以分为以下几个步骤:
- 计算原始模型的参数矩阵: 首先,需要确定要进行低秩近似的参数矩阵。这通常是在模型训练完成后得到的,例如全连接层或卷积层的权重矩阵。
- 计算参数矩阵的奇异值分解(Singular Value Decomposition, SVD): 对于一个给定的参数矩阵,可以使用SVD将其分解为三个矩阵的乘积:U、Σ和V^T。其中,U和V是正交矩阵,Σ是一个对角矩阵,对角线上的元素称为奇异值。
- 选择保留的奇异值数量: 选择一个合适的截断点,即保留SVD分解中的前k个最大的奇异值(k通常比原始矩阵的秩要小),将其他奇异值置零。
- 计算低秩近似矩阵: 利用保留的前k个奇异值和对应的U、Σ和V^T矩阵,可以重构近似的低秩参数矩阵。
- 更新模型: 将原始模型中的参数矩阵替换为低秩近似矩阵,然后可以重新训练模型以微调和优化。
低秩近似的操作可以降低模型的存储需求和计算量,同时在一定程度上保持模型的性能。这种技术通常用于对模型进行压缩以适应资源受限的环境,例如移动设备或嵌入式系统,或者用于提高大规模模型的训练和推理效率。
21.4 剪枝与稀疏约束
剪枝(Pruning)和稀疏约束(Sparse Constraint)都是模型压缩中常用的技术,它们的目标都是减少模型的参数量和计算量,但它们的实现方式有所不同。
- 剪枝(Pruning):
-
- 结构化剪枝:在结构化剪枝中,被剪枝的参数或连接是按照某种结构化的方式进行的,例如整个通道、整个层或者其他特定的结构。这样做的好处是可以保持模型的稀疏性,使得剪枝后的模型更容易优化和部署。
- 非结构化剪枝:在非结构化剪枝中,被剪枝的参数或连接是随机分布的,没有特定的结构。非结构化剪枝通常更灵活,但由于不保持模型的结构化特性,可能需要额外的技巧来重新组织和优化模型。
- 稀疏约束(Sparse Constraint):
- L1正则化(Lasso regularization)会使得模型的参数更倾向于稀疏,因为L1正则化会促使部分参数变为零。
剪枝和稀疏约束都可以有效地减少模型的参数数量和计算量,从而提高模型的效率和推理速度。在实际应用中,常常会将剪枝和稀疏约束与其他模型压缩技术结合使用,以进一步提高模型的性能和压缩比例。
21.5 参数量化的优缺点
精简版
| 优点 | 缺点 |
| 减少模型存储需求 | 丢失一些模型精度 |
| 减少模型推理时的计算量 | 参数量化的过程可能引入额外的计算成本 |
| 提高模型在资源受限环境下的适用性 | 需要调整和优化量化参数的过程 |
| 减少模型推理时的内存占用 | 可能需要重新训练模型以适应量化后的参数 |
| 有助于加速推理速度 | 部分模型结构可能不适合进行参数量化 |
详细版
| 优点 | 缺点 |
| 减少模型存储需求:参数量化将模型中的浮点参数转换为紧凑表示形式,大大减少了模型在存储设备上的占用空间。 | 丢失一些模型精度:量化后的参数表示可能无法完美捕捉原始浮点参数的细微变化,导致模型精度略微下降。 |
| 减少模型推理时的计算量:量化后的参数通常需要更少的位数进行计算,从而减少了模型推理时的计算量,加快推理速度。 | 参数量化的过程可能引入额外的计算成本:确定量化参数的范围、量化参数的校准等操作可能会增加一些额外的计算成本。 |
| 提高模型在资源受限环境下的适用性:量化后的模型所需的存储空间和计算资源更少,更适合部署在资源受限的设备上。 | 需要调整和优化量化参数的过程:选择合适的量化参数对模型性能至关重要,需要进行仔细的调整和优化。 |
| 减少模型推理时的内存占用:量化后的模型需要更少的内存来存储参数和中间结果,对于内存受限的设备是非常有利的。 | 可能需要重新训练模型以适应量化后的参数:量化后的参数可能会导致模型行为的微妙变化,有时需要重新训练模型以适应量化后的参数。 |
| 有助于加速推理速度:减少了模型推理时的计算量和内存占用后,通常可以提高模型的推理速度,特别是在资源受限的环境下。 | 部分模型结构可能不适合进行参数量化:一些模型结构可能对参数量化更敏感,导致模型性能下降更为严重。 |
21.6 你了解知识蒸馏(Knowledge Distillation)吗
知识蒸馏是一种模型压缩的技术,旨在通过将一个大型的复杂模型(教师模型)的知识传递给一个小型的简化模型(学生模型),来训练出更加轻量级、高效的模型。这个过程通常包括以下几个步骤:
- 准备教师模型和学生模型: 首先,需要训练一个大型的复杂模型作为教师模型,通常是一个性能较好的深度神经网络模型。然后,准备一个小型的简化模型作为学生模型,该模型需要具有比教师模型更少的参数和计算复杂度。
- 知识提取: 使用教师模型对训练数据进行推理,获取教师模型在训练数据上的输出概率分布或者其他中间层的特征表示。这些输出可以包括分类概率、特征表示、模型输出等。
- 学生模型训练: 使用教师模型的输出作为额外的监督信号,引导学生模型去学习教师模型的知识。通常,学生模型的损失函数包括两部分:一部分是基于学生模型自身输出和标签的损失函数,另一部分是基于教师模型输出和学生模型输出之间的距离的损失函数,通常使用交叉熵或均方误差等损失函数。
- 温度参数调节(可选): 在知识蒸馏中,通常会使用温度参数来调节教师模型输出的软化程度。通过增加温度参数,可以使得教师模型输出的概率分布更加平滑,有助于提高学生模型的泛化能力。
知识蒸馏的主要优势在于可以通过引入教师模型的知识,来提高学生模型的泛化能力和性能。此外,知识蒸馏还可以帮助加速模型的推理速度,减少模型的存储需求,从而更适合部署在资源受限的环境中。
21.7 降低网络复杂度但不影响精度的方法有哪些
- 参数剪枝(Parameter Pruning): 剪枝是一种通过移除模型中不重要的参数来减少模型大小和计算量的技术。这些不重要的参数可以通过基于梯度、敏感性分析、信息熵等方法来识别和剪枝。剪枝后的模型在移除了一部分参数的情况下仍然能够保持原始模型的精度。
- 网络剪枝(Network Pruning): 与参数剪枝类似,网络剪枝是指剪枝整个网络结构,包括剪枝层、通道、甚至整个模块。网络剪枝可以在保持模型性能的同时,减少模型的复杂度。
- 深度可分离卷积(Depthwise Separable Convolution): 深度可分离卷积是一种将传统卷积操作拆分成深度卷积和逐点卷积两个独立操作的技术。这种方式可以显著减少参数数量和计算量,同时保持模型性能。
- 通道剪枝(Channel Pruning): 通道剪枝是一种剪枝卷积层中的通道(channel)来减少模型复杂度的方法。通过移除不重要的通道,可以减少模型的计算量和存储需求,同时保持模型的性能。
这些方法可以单独应用,也可以组合使用,以进一步降低网络复杂度并保持模型的精度。选择合适的方法通常取决于具体的应用场景和需求。
21.8 聊聊TensorRT加速原理
在计算资源并不丰富的嵌入式设备上,TensorRT之所以能加速神经网络的的推断主要得益于两点。首先是TensorRT支持INT8和FP16的计算,通过在减少计算量和保持精度之间达到一个理想的trade-off,达到加速推断的目的。
更为重要的是TensorRT对于网络结构进行了重构和优化,主要体现在一下几个方面。
第一是tensorRT通过解析网络模型将网络中无用的输出层消除以减小计算。
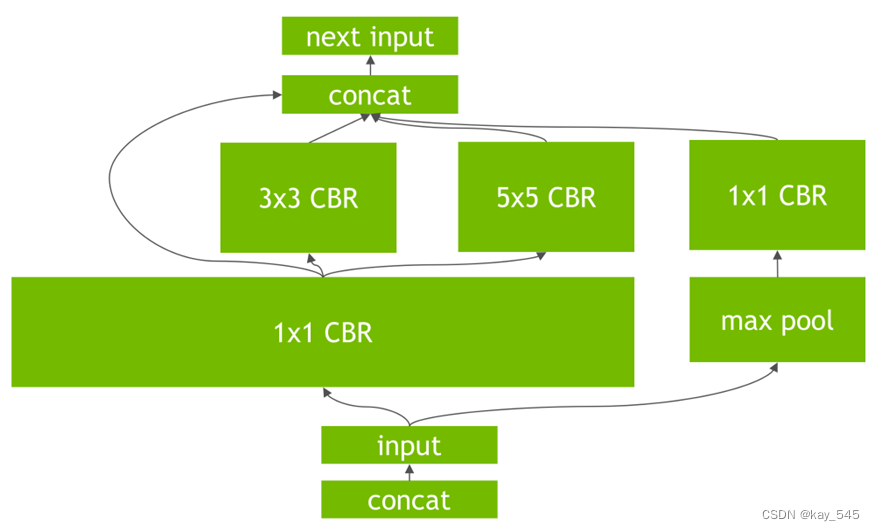
第二是对于网络结构的垂直整合,即将目前主流神经网络的conv、BN、Relu三个层融合为了一个层,例如将图1所示的常见的Inception结构重构为图2所示的网络结构。
第三是对于网络的水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,如图2向图3的转化。
第四是对于concat层,将contact层的输入直接送入下面的操作中,不用单独进行concat后在输入计算,相当于减少了一次传输吞吐。


相关文章:
深度学习面试问题总结(21)| 模型优化
本文给大家带来的百面算法工程师是深度学习模型优化面试总结,文章内总结了常见的提问问题,旨在为广大学子模拟出更贴合实际的面试问答场景。在这篇文章中,我们还将介绍一些常见的深度学习面试问题,并提供参考的回答及其理论基础&a…...

4月手机行业线上市场销售数据分析
政府对智能手机行业的支持政策,如5G推广,以及相关的产业政策,都在一定程度上推动了智能手机市场的发展,再加上AI应用的推广和全球科技迅猛发展,中国手机市场在2024年迎来了恢复性增长。 据鲸参谋数据统计,…...

首都师范大学聘请旅美经济学家向凌云为客座教授
2024年4月17日,首都师范大学客座教授聘任仪式在首都师范大学资源环境与旅游学院举行。首都师范大学资源环境与旅游学院院长吕拉昌主持了仪式,并为旅美经济学家向凌云教授颁发了聘书。 吕拉昌院长指出,要贯彻教育部产学研一体化战略࿰…...

多电脑共享鼠标键盘
由于要在两个电脑之间共用一套鼠标键盘,所以在此记录一下。 mouse without borders Mouse without Borders 是一款免费的 Windows 工具,允许你在多台电脑之间共享鼠标和键盘。 安装与配置步骤 下载和安装: 前往 Mouse without Borders 官…...

展厅设计对企业有哪些作用
1、增强品牌形象 企业展厅对于增强企业品牌形象、提升企业的知名度和市场竞争力具有显著作用和意义。展厅作为企业对外的窗口,是客户和访客了解企业的第一印象。通过独特的设计风格和精心的展示布局,企业可以将自身的核心价值和文化理念巧妙地融入到展厅…...

LeetCode-102. 二叉树的层序遍历【树 广度优先搜索 二叉树】
LeetCode-102. 二叉树的层序遍历【树 广度优先搜索 二叉树】 题目描述:解题思路一:一个全局队列queue,while queue:去搜集当前所有queue的level解题思路二:背诵版解题思路三: 题目描述: 给你二…...

基于时频模糊算子的数据增强方法
关键词:时频模糊,数据增强,机器学习,音频预处理 我们引入时频模糊算子,该算子将信号的短时傅里叶变换与指定的核进行卷积,在SpeechCommands V2数据集上训练了一个使用ResNet-34架构的卷积神经网络(CNN)和一…...

浅谈后端整合Springboot框架后操作基础配置
boot基础配置 现在不访问端口8080 可以吗 我们在默认启动的时候访问的是端口号8080 基于属性配置的 现在boot整合导致Tomcat服务器的配置文件没了 我们怎么去修改Tomcat服务器的配置信息呢 配置文件中的配置信息是很多很多的... 复制工程 保留工程的基础结构 抹掉原始…...

英码科技算能系列边缘计算盒子再添新成员!搭载TPU处理器BM1688CV186AH,功耗更低、接口更丰富
在数据呈现指数级增长的今天,越来越多的领域和细分场景对实时、高效的数据处理和分析的需求日益增长,对智能算力的需求也不断增强。为应对新的市场趋势,英码科技凭借自身的硬件研发优势,携手算能相继推出了基于BM1684的边缘计算盒…...
selenium 爬取今日头条
由于今日头条网页是动态渲染,再加上各种token再验证,因此直接通过API接口获取数据难度很大,本文使用selenium来实现新闻内容爬取。 selenium核心代码 知识点: 代码中加了很多的异常处理,保证错误后重试,…...

docker 安装 yapi
文章目录 docker 安装 yapi一、拉取镜像二、创建目录三、添加配置文件四、初始化数据库表五、启动 yapi六、测试以及修改默认密码 没有 MongDB 的可以先看这个教程:MongDB安装教程 docker 安装 yapi 版本: 1.9.5 一、拉取镜像 docker pull yapipro/y…...
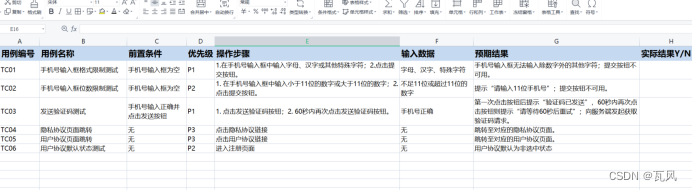
【AI如何帮你编写测试用例并输出表格格式】
1、工具:顺便使用一款生成式AI即可,此处用的是ChatGPT,Kimi这两个工具试验。 2、首先要拿到需求文档,根据需求文档向AI发出如下指令(Prompt) “请根据下面这段需求,编写测试用例: …...

九宫格转圈圈抽奖活动,有加速,减速效果
在线访问demo和代码在底部 代码,复制就可以跑 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><tit…...

利用阿里OSS服务给文件设置过期删除--简单版
在云存储广泛应用的今天,阿里云的Object Storage Service(OSS)以其高度可扩展性、安全性和成本效益,成为了众多企业和开发者存储海量数据的首选方案。随着数据量的不断膨胀,高效的数据管理和成本控制变得尤为重要。其中…...
LabVIEW控制Trio控制器
将LabVIEW与Trio控制器结合,可以实现对复杂运动系统的控制和监测。以下是详细的方法和注意事项: 一、准备工作 软件安装: 安装LabVIEW开发环境,确保版本兼容性。 安装Trio控制器的相关驱动程序和软件,如Trio Motion …...
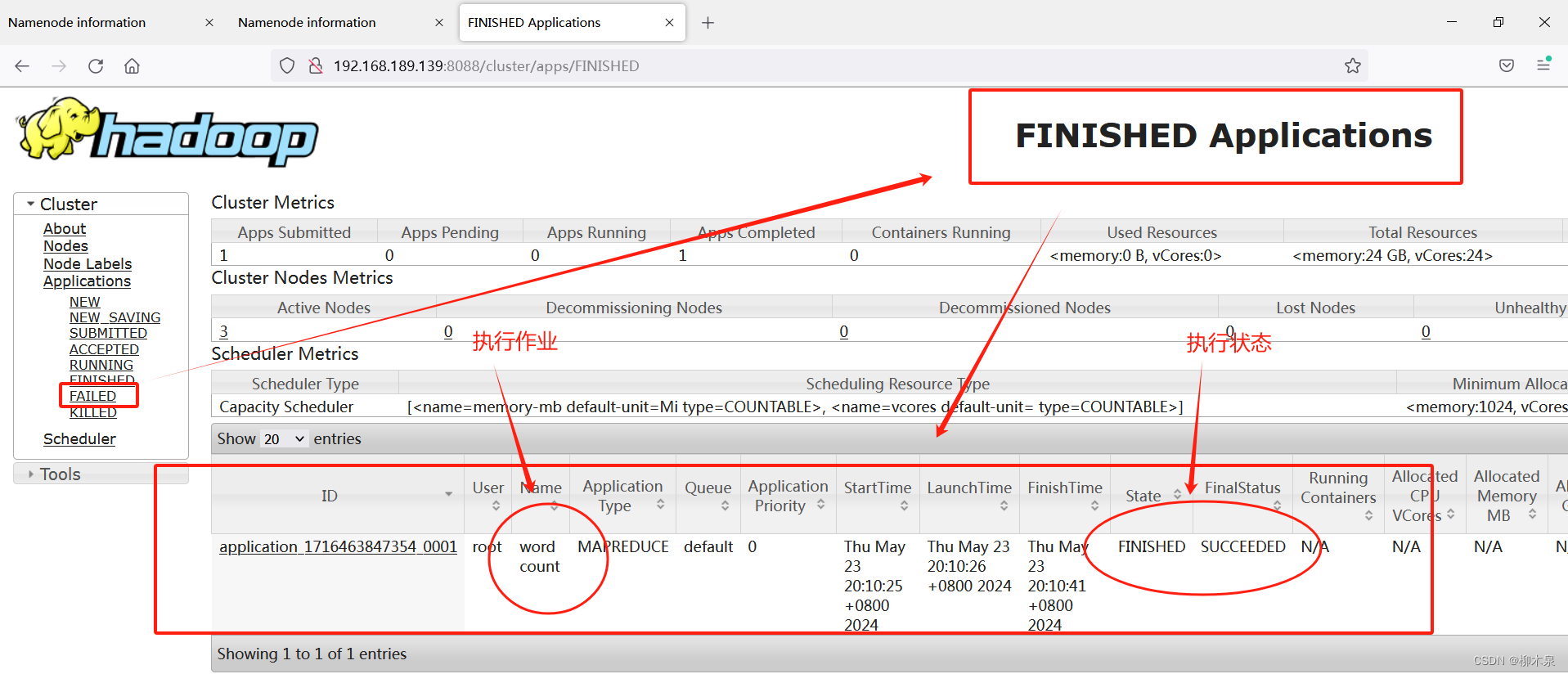
02--大数据Hadoop集群实战
前言: 前面整理了hadoop概念内容,写了一些概念和本地部署和伪分布式两种,比较偏向概念或实验,今天来整理一下在项目中实际使用的一些知识点。 1、基础概念 1.1、完全分布式 Hadoop是一个开源的分布式存储和计算框架࿰…...

【ARMv8/v9 异常模型入门及渐进 10 -- WFI 与 WFE 使用详细介绍 1】
请阅读【ARMv8/v9 ARM64 System Exception】 文章目录 WFI 与 WFE等待事件(WFE)发送事件(SEV)本地发送事件(SEVL)WFE 唤醒事件 WFE 使用场景举例与代码实现wfe睡眠函数sev 事件唤醒函数全局监视器和自旋锁 …...

@DateTimeFormat 和 @JsonFormat 的区别和使用方式
一. DateTimeFormat 详细用例 DateTimeFormat 是 Spring Framework 的一部分,它用于绑定 Web 请求中的字符串到 Java 的日期和时间类型。这种转换常常在 Spring MVC 控制器中处理 HTTP 请求参数或路径变量时使用。 使用场景: 将 HTTP 请求中的日期(也就是网络传输…...

C++—结构体
结构体(struct),是一种用户自定义复合数据类型,可以包含不同类型的不同成员。 结构体的声明定义和使用的基本语法: // 声明结构体struct 结构体类型 { 成员1类型 成员1名称; ...成员N类型 成员N名称; };除声明…...
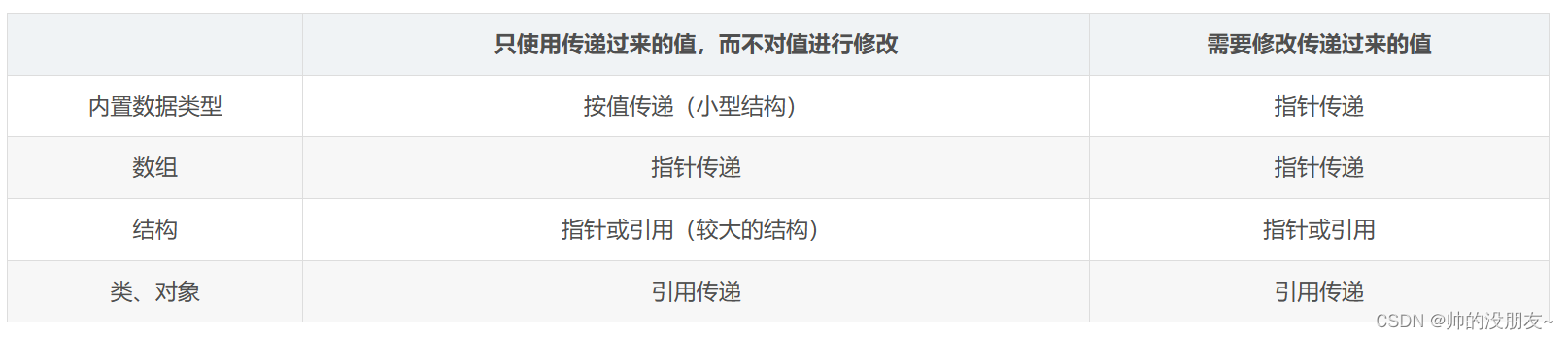
指针与引用
指针与引用 一:指针与引用场景二级目录三级目录 一:指针与引用场景 二级目录 三级目录...

ARMv8-A架构VDISR_EL3与VSESR_EL2寄存器解析
1. AArch64系统寄存器概述在ARMv8-A架构中,系统寄存器是处理器状态和功能控制的核心组件。它们分布在不同的异常级别(EL0-EL3),每个级别都有特定的访问权限和功能定位。作为芯片级开发者,理解这些寄存器的细节对构建稳定可靠的系统至关重要。…...
)
人教版高中英语选择性必修四单词音频+单词表+单词默写表(2026年最新)
2026年最新人教版高中英语选择性必修四课本单词表、单词默写表和听力音频,PDF高清电子版,可下载打印!单词音频下载链接:https://pan.quark.cn/s/c757d00cb27d人教版高中英语选修四单词高频30个1、literature /ˈlɪtrətʃə(r)/ …...

Unity编辑器性能优化:工作流、场景与预制体三大资源创建瓶颈
1. 为什么编辑器资源创建环节是Unity性能优化的“隐形地雷区”很多人一提Unity性能优化,第一反应就是Profiler里看Draw Call、GC Alloc、CPU耗时,或者去改Shader、压贴图、拆合批。这没错,但90%的团队在项目中后期卡顿频发、打包失败、CI构建…...

Heavy Fighter动画包:Unity战斗系统根运动与状态机深度解析
1. 这套动画包不是“拿来就能用”的资源,而是需要你亲手校准的战斗系统骨架我在2021年接手一个横版ARPG项目时,美术总监甩给我三套Mecanim动画包,其中一套就是Heavy Fighter Mecanim Animation Pack。当时我第一反应是“终于不用手调IK了”&a…...

VHS Pro深度解析:Unity中模拟真实录像机信号链的原理与实践
1. 这不是“加个滤镜”那么简单:VHS Pro 的真实定位与行业缺口你打开 Unity Asset Store,搜“vhs”,会跳出二十多个插件。有的叫 VHS Effect,有的叫 Retro Tape,还有的直接叫 “80s Glitch”。点开预览图,全…...

Unity IL2CPP逆向实战:用frida-il2cpp-bridge穿透三重运行时屏障
1. 这不是“又一个 Frida 教程”,而是 Unity 逆向现场的生存手册 你刚在某款热门 Unity 游戏里发现一个可疑的加密逻辑,想确认它是否调用了 UnityEngine.PlayerPrefs.SetString 存储敏感 token;或者你在调试一款国产工具类 App,…...

HDRP光照性能优化:探针体内存、阴影贴图与反射烘焙的底层控制
1. 这不是又一个“灯光插件”,而是HDRP光照工作流的手术刀我第一次在客户项目里看到UPGEN Lighting HDRP,是在一个实时虚拟制片场景的紧急优化现场。美术总监指着渲染帧率从28fps掉到14fps的监控面板说:“灯光一开,GPU就喘不上气—…...

WT32-S3-DK开发板全解析:从硬件设计到物联网项目实战
1. 项目概述:一块“小而全”的物联网开发板最近在捣鼓一个智能家居的传感器节点项目,需要一块性能足够、接口丰富、最好还带屏幕的开发板。市面上ESP32-S3的方案很多,但要么是核心板,需要自己配底板和屏幕,要么就是功能…...

从扁平到触手可及,Midjourney拟物化全流程拆解,含12组高复用材质参数模板与避坑清单
更多请点击: https://kaifayun.com 第一章:从扁平到触手可及:Midjourney拟物化设计范式跃迁 当UI设计从iOS 7的极简扁平风席卷全球,我们曾笃信“去装饰即高级”。而Midjourney V6起悄然掀起一场静默革命——它不再满足于生成“看…...
)
为什么你的ElevenLabs四川话输出总像“普通话+口音”?3步声学特征解耦法让韵律自然度提升2.8倍(附Python声谱可视化代码)
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs四川话输出总像“普通话口音”? ElevenLabs 当前并未提供原生四川话(西南官话成渝片)语音模型,其所谓“方言支持”实为在标准普通话…...