NLP(16)--生成式任务
前言
仅记录学习过程,有问题欢迎讨论
输入输出均为不定长序列(seq2seq)
自回归语言模型:
- x 为 str[start : end ]; y为 [start+1 : end +1] 同时训练多个字,逐字计算交叉熵
encode-decode结构:
- Encoder将输入转化为向量或矩阵,其中包含了输入中的信息
- Decoder将Encoder的输出转化为输出
attention机制
- 输入和输出应该和重点句子强相关,给输入加权(所以维度应该和输入的size一致)
Teacher forcing
- 使用真实标签作为下一个输入(自回归语言模型就是使用的teacher forcing)
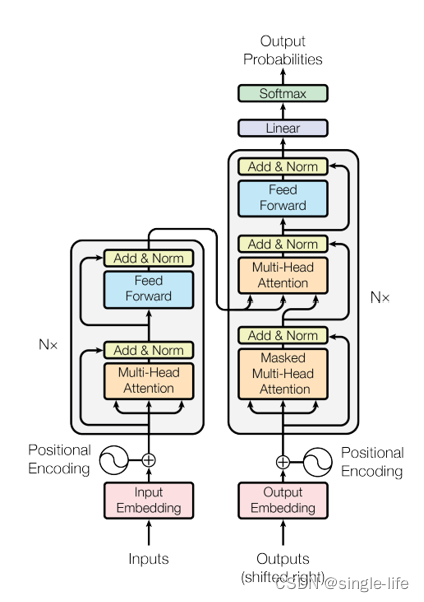
Transform结构
- Query来自Decode ,KV来自Encode
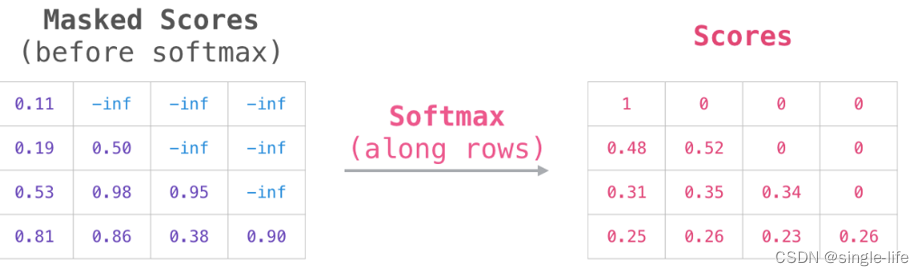
使用Mask Attation 来避免对output做计算时,获取了所有的信息。只使用当前的位置对应的output信息。(自回归模型,先mask,然后在softmax)
评价指标:
- BLEU:按照输出的字符计算一系列的数学(惩罚机制,Ngrim)计算来评价相似性
采样:
-
Beam size:
保留概率最大的n条路径 -
Temperature Sampling
根据概率分布生成下一个词,通过参数T,T越大,结果越随机,分布更均匀 -
TOP-P/K
采样先按概率从大到小排序,累加概率不超过P的范围中选
采样从TOP-K中采样下一个词
代码
使用bert实现自回归训练模型,
添加mask attention 来实现
# coding:utf8import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import refrom transformers import BertModel, BertTokenizer"""
基于pytorch的LSTM语言模型
"""class LanguageModel(nn.Module):def __init__(self, input_dim, vocab_size):super(LanguageModel, self).__init__()# self.embedding = nn.Embedding(len(vocab), input_dim)# self.layer = nn.LSTM(input_dim, input_dim, num_layers=1, batch_first=True)self.bert = BertModel.from_pretrained(r"D:\NLP\video\第六周\bert-base-chinese", return_dict=False)self.classify = nn.Linear(input_dim, vocab_size)# self.dropout = nn.Dropout(0.1)self.loss = nn.functional.cross_entropy# 当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):# x = self.embedding(x) # output shape:(batch_size, sen_len, input_dim)# 使用mask来防止提前预知结果if y is not None:# 构建一个下三角的mask# bert的mask attention 为(batch_size, vocab_size, vocab_size) L*Lmask = torch.tril(torch.ones(x.shape[0], x.shape[1], x.shape[1]))print(mask)x, _ = self.bert(x, attention_mask=mask)y_pred = self.classify(x)return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))else:x = self.bert(x)[0]y_pred = self.classify(x)return torch.softmax(y_pred, dim=-1)# 加载字表
def build_vocab(vocab_path):vocab = {"<pad>": 0}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):char = line[:-1] # 去掉结尾换行符vocab[char] = index + 1 # 留出0位给pad tokenreturn vocab# 加载语料
def load_corpus(path):corpus = ""with open(path, encoding="utf8") as f:for line in f:corpus += line.strip()return corpus# 随机生成一个样本
# 从文本中截取随机窗口,前n个字作为输入,最后一个字作为输出
def build_sample(tokenizer, window_size, corpus):start = random.randint(0, len(corpus) - 1 - window_size)end = start + window_sizewindow = corpus[start:end]target = corpus[start + 1:end + 1] # 输入输出错开一位# print(window, target)# 中文的文本转化为tokenizer的idinput_ids_x = tokenizer.encode(window, add_special_tokens=False, padding='max_length', truncation=True,max_length=10)input_ids_y = tokenizer.encode(target, add_special_tokens=False, padding='max_length', truncation=True,max_length=10)return input_ids_x, input_ids_y# 建立数据集
# sample_length 输入需要的样本数量。需要多少生成多少
# vocab 词表
# window_size 样本长度
# corpus 语料字符串
def build_dataset(sample_length, tokenizer, window_size, corpus):dataset_x = []dataset_y = []for i in range(sample_length):x, y = build_sample(tokenizer, window_size, corpus)dataset_x.append(x)dataset_y.append(y)return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)# 建立模型
def build_model(vocab_size, char_dim):model = LanguageModel(char_dim, vocab_size)return model# 文本生成测试代码
def generate_sentence(openings, model, tokenizer, window_size):# reverse_vocab = dict((y, x) for x, y in vocab.items())model.eval()with torch.no_grad():pred_char = ""# 生成文本超过30字终止while len(openings) <= 30:openings += pred_charx = tokenizer.encode(openings, add_special_tokens=False, padding='max_length', truncation=True,max_length=10)x = torch.LongTensor([x])if torch.cuda.is_available():x = x.cuda()# batch_size = 1 最后一个字符的概率y = model(x)[0][-1]index = sampling_strategy(y)# 转化为中文 只有一个字符pred_char = tokenizer.decode(index)return openings# 采样方式
def sampling_strategy(prob_distribution):if random.random() > 0.1:strategy = "greedy"else:strategy = "sampling"if strategy == "greedy":return int(torch.argmax(prob_distribution))elif strategy == "sampling":prob_distribution = prob_distribution.cpu().numpy()return np.random.choice(list(range(len(prob_distribution))), p=prob_distribution)# 计算文本ppl
def calc_perplexity(sentence, model, vocab, window_size):prob = 0model.eval()with torch.no_grad():for i in range(1, len(sentence)):start = max(0, i - window_size)window = sentence[start:i]x = [vocab.get(char, vocab["<UNK>"]) for char in window]x = torch.LongTensor([x])target = sentence[i]target_index = vocab.get(target, vocab["<UNK>"])if torch.cuda.is_available():x = x.cuda()pred_prob_distribute = model(x)[0][-1]target_prob = pred_prob_distribute[target_index]prob += math.log(target_prob, 10)return 2 ** (prob * (-1 / len(sentence)))def train(corpus_path, save_weight=True):epoch_num = 15 # 训练轮数batch_size = 64 # 每次训练样本个数train_sample = 10000 # 每轮训练总共训练的样本总数char_dim = 768 # 每个字的维度window_size = 10 # 样本文本长度# vocab = build_vocab(r"vocab.txt") # 建立字表tokenizer = BertTokenizer.from_pretrained(r"D:\NLP\video\第六周\bert-base-chinese")vocab_size = 21128corpus = load_corpus(corpus_path) # 加载语料model = build_model(vocab_size, char_dim) # 建立模型if torch.cuda.is_available():model = model.cuda()optim = torch.optim.Adam(model.parameters(), lr=0.001) # 建立优化器print("文本词表模型加载完毕,开始训练")for epoch in range(epoch_num):model.train()watch_loss = []for batch in range(int(train_sample / batch_size)):x, y = build_dataset(batch_size, tokenizer, window_size, corpus) # 构建一组训练样本if torch.cuda.is_available():x, y = x.cuda(), y.cuda()optim.zero_grad() # 梯度归零loss = model(x, y) # 计算lossloss.backward() # 计算梯度optim.step() # 更新权重watch_loss.append(loss.item())print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))print(generate_sentence("忽然一阵狂风吹过,他直接", model, tokenizer, window_size))print(generate_sentence("天青色等烟雨,而我在", model, tokenizer, window_size))if not save_weight:returnelse:base_name = os.path.basename(corpus_path).replace("txt", "pth")model_path = os.path.join("model", base_name)torch.save(model.state_dict(), model_path)returnif __name__ == "__main__":train("corpus.txt", False)# mask = torch.tril(torch.ones(4, 4)).unsqueeze(0).unsqueeze(0)# print(mask)相关文章:
NLP(16)--生成式任务
前言 仅记录学习过程,有问题欢迎讨论 输入输出均为不定长序列(seq2seq)自回归语言模型: x 为 str[start : end ]; y为 [start1 : end 1] 同时训练多个字,逐字计算交叉熵 encode-decode结构: Encoder将输…...

直播回放| 机器人任务挑战赛线上培训资料合集
大赛培训回顾 5月22日,卓翼飞思实验室为全国各赛区精心组织的机器人任务挑战赛(无人协同系统)线上培训第三期顺利落下帷幕,吸引300余人参与。本次培训主要针对仿真平台的基本使用,从仿真平台获取激光雷达/视觉数据&am…...

flask Web应用的接口调试
以上上一篇 Docker部署Azure chatgpt样例应用_群晖部署chatgpt-CSDN博客 xx为例 在app.py最下方有 /conversation 接口 在api.ts文件中可见调用了 /conversation 接口。 使用chrom浏览器F12查看 Networ- 本地运行后,使用postman调试。接口地址填写 http://127.0…...
简单易懂的 API 集成测试方法
简介:API 集成测试的重要性 API 集成测试是一类测试活动,用于验证 API 是否满足功能性、可靠性、性能和安全性等方面的预期要求。在多 API 协作的应用程序中,这种测试尤为紧要。 在这一阶段,我们不仅审视单个组件,还…...

leetcode 239. 滑动窗口最大值、347.前 K 个高频元素
leetcode 239. 滑动窗口最大值、347.前 K 个高频元素 leecode 239. 滑动窗口最大值 题目链接 :https://leetcode.cn/problems/sliding-window-maximum/description/ 题目 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的…...

npm常用指令
基础 命令:run 解释:运行脚本 示例:npm run dev 命令:list || ls 解释:查看依赖列表 示例:npm list || npm ls 命令:install || i 解释:安装依赖 示例:npm install ||…...

数字孪生技术在管理中有哪些实际应用?
随着科学技术的不断提高,数字孪生技术也在不断的从理论应用至现实,并且涉及领域较为广泛。 在生产运营管理层面,通过构建数字孪生模型,企业可以精准模拟和优化生产线,实现生产流程的智能化和高效化。比如,…...

LeetCode/NowCoder-链表经典算法OJ练习3
孜孜不倦:孜孜:勤勉,不懈怠。指工作或学习勤奋不知疲倦。💓💓💓 目录 说在前面 题目一:返回倒数第k个节点 题目二:链表的回文结构 题目三:相交链表 SUMUP结尾 说在前…...

如何理解HTML语义化
如何理解HTML语义化 HTML语义化,简单来说,就是使用HTML标签来清晰地表达页面内容的结构和意义,而不仅仅是作为布局的容器。它强调使用具有明确含义的HTML标签来描述页面元素,而不是仅仅依赖CSS来实现页面的外观和布局。 理解HTM…...

Solved problem: The number of elements in the character array
Problem: 未解决的问题:字符数组中元素的个数-CSDN博客 Solution: Add \0 at the end of the character array More detailed content can be found in the link below. Sizeof and Length of character array-CSDN博客...

Flume Channels简介及官方用例
通道是在代理上暂存事件的存储库。Source 添加事件,Sink 将其删除。 1、Memory Channel 事件存储在具有可配置最大大小的内存中队列中。它非常适合需要更高吞吐量的流,但在agent发生故障时会丢失暂存数据 Property Name Default Description type …...

【AI】如何用非Docker方法安装类GPT WebUI
【背景】 本地LLM通信的能力需要做成局域网SAAS服务才能方便所有人使用。所以需要安装WebUI,这样既有了用户界面,又做成了SAAS服务,很理想。 【问题】 文档基本首推都是Docker安装,虽然很多人都觉得容器多么多么方便࿰…...

2024年ai知识库:特点、应用与搭建
随着科技的进步和企业的需要,ai知识库逐渐走进大众的视野并深受企业的青睐,掀起了搭建ai知识库的热潮。LookLook同学就来简单介绍一下关于ai知识库的特点、应用与发展趋势,带你了解2024年的ai知识库。 一、ai知识库的定义与特点 ai知识库是结…...
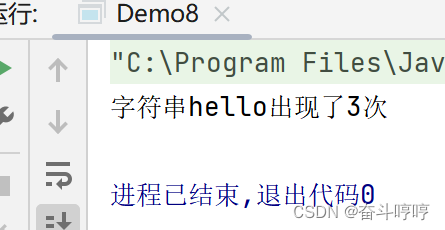
查询一个字符串在另一个字符串中出现的次数(java)
查询一个字符串在另一个字符串中出现的次数 例: String str1“helloworld,java,python,hellokafka,world big table helloteacher”; String str2“hello”; 字符串str2在str1中出现3次 代码 package exercise.test8;public class Demo8 {public static void mai…...

Docker in Docker 原理与实战
一、引言 随着容器化技术的普及,Docker 作为一种主流的容器管理工具,已被广泛应用于开发、测试及生产环境中。Docker 的灵活性和便捷性使得它成为 DevOps 流程中不可或缺的一部分。然而,在一些复杂的应用场景中,我们可能需要在一…...
Rust学习心得
我分享一下一年的Rust学习经历,从书到代码都一网打尽。 关于新手如何学习Rust,我之前在Hacker News上看到了这么一篇教程: 这篇教程与其他教程不同的时,他不是一个速成教程,而是通过自己的学习经历,向需要…...
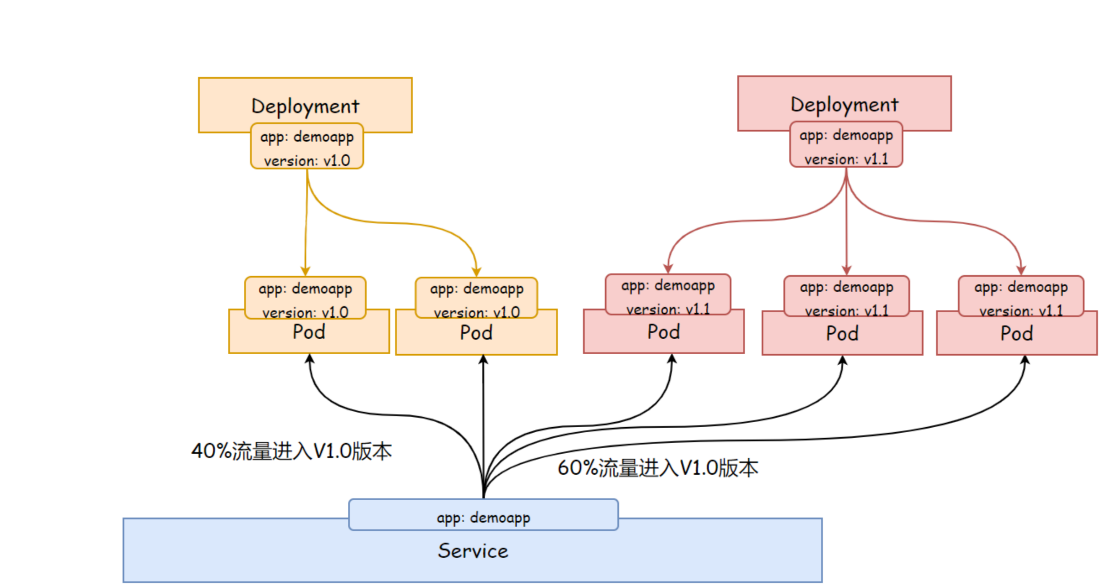
K8s deployment 进阶
文章目录 K8s deployment 进阶Deployment 更新策略RecreateRollingUpdatemaxSurge 和 maxUnavailable minReadySecondsprogressDeadlineSeconds Deployment 版本回滚Deployment 实现灰度发布 K8s deployment 进阶 Deployment 更新策略 Recreate 重建 (Recreate)&…...
简单样例)
python实现二叉搜索树(AVL树)简单样例
一、二叉搜索树 class TreeNode:def __init__(self, value):self.value valueself.left Noneself.right Noneclass BinarySearchTree:def __init__(self):self.root Nonedef insert(self, value):if self.root is None:self.root TreeNode(value)else:self._insert(self.…...

Day47 打家劫舍123
198 打家劫舍 题目链接:198.打家劫舍 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,…...

OceanBase 开源社区新进展|obdiag SIG成立
为了构建完善的 OceanBase 诊断生态系统,汇聚各方力量,形成涵盖工具、知识在内的全方位诊断生态体系,助力开发者更高效地驾驭 OceanBase,OceanBase 社区宣布成立诊断 SIG,名称:obdiag SIG。 详情参加原文链…...

模块型OLT跟光模块有什么区别?
模块型OLT跟光模块有什么区别?明明是同一个 SFP 接口,插上去长得也差不多,为什么有的叫“光模块”,有的叫“模块型 OLT”? 它们到底有什么区别?能不能互换?选错了会怎样?同样是 SFP …...

嵌入式JavaScript混合开发:C与JS高效互调实践指南
1. 项目概述:当嵌入式遇上JavaScript最近几年,在嵌入式开发圈子里,一个老话题又有了新热度:用JavaScript来写嵌入式应用。这听起来有点“跨界”,毕竟传统印象里,嵌入式是C/C的天下,讲究的是对硬…...

Docker编译镜像实战:为嵌入式Linux开发打造标准化环境
1. 项目概述:为什么我们需要一个专属的Docker编译镜像?如果你是一名嵌入式Linux开发者,或者正在学习诸如全志Tina Linux这样的开源嵌入式系统,那么“编译环境”这个词对你来说一定不陌生。它就像是一个厨师的后厨,锅碗…...

两张图片拼接在一起中间有条白线
运行示例:给父元素设置font-size: 0;给图片设置display: block;都没用。 后面我换了一个图片就正常了。发现是图片本身的问题,单个看没任何问题,拼接后就会出现白线。 好像说是切的位置不是整数像素,出现 0.5 像素偏移就会出现。 …...

第一性原理计算在半导体缺陷研究中的应用:以氢掺杂氧化镓为例
1. 项目概述:从“掺杂”与“缺陷”说起在半导体材料的研究与开发中,我们常常听到“掺杂”这个词。简单来说,就像在炒菜时撒入不同的调料来改变风味,掺杂就是在纯净的半导体材料(本征材料)中,有目…...
)
手把手教你用N32G435的DMA‘传输过半中断’实现软件双缓冲(附2.5M波特率测试代码)
N32G435 DMA传输过半中断实现高负载串口通信的工程实践 在嵌入式系统开发中,高效处理高速串口数据流一直是工程师面临的挑战。当数据速率达到兆波特级别时,传统的中断驱动方式往往会导致CPU资源耗尽,系统响应迟缓。本文将深入探讨如何利用N32…...

AI生成论文的查重率区间是多少?目前控制AIGC疑似率最好用的软件有哪些?
毕业、投稿阶段难题频发,常规 AI 撰写论文,查重率普遍处在 35%-60% 区间,AIGC 疑似率更是达到 50%-70%,知网、维普检测极易不合格,进而引发答辩延后、错失评优资格等问题。下文实测四款热门工具,帮大家找准…...

HA高可用架构:数字化转型的“隐性及格线”,你达标了吗?
数字化转型的核心是“业务在线、数据可用”,而这一切的前提,是HA(High Availability)高可用架构的支撑。在企业数字化进程中,ERP选型、CRM部署、低代码平台搭建、BI工具落地、API集成打通等动作,都是可见的…...

植入式网络广告效果影响因素及投放决策优化【附代码】
✨ 长期致力于植入式网络广告效果、产品植入形态、广告呈现方式、载具属性、品牌知名度研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多因素交互实验…...

实时反欺诈Agent部署失败率高达68%?金融IT总监亲述4类典型故障链及容灾切换黄金12分钟法则
更多请点击: https://codechina.net 第一章:实时反欺诈Agent部署失败率高达68%?金融IT总监亲述4类典型故障链及容灾切换黄金12分钟法则 某头部城商行在2023年Q3上线新一代实时反欺诈Agent集群后,监控平台显示首次部署成功率仅32…...