python 线性回归模型
教材链接-3.2. 线性回归的从零开始实现
c++实现
该博客仅用于记录一下自己的代码,可与c++实现作为对照
from d2l import torch as d2l
import torch
import random
# nn是神经网络的缩写
from torch import nn
from torch.utils import data# 加载训练数据
# 加载训练数据集
simples = torch.load('datas.pt')
# 这里是加载了训练和测试数据集的真实权重和偏差,仅作为最后训练结果的验证使用
tw, tb = torch.load('wb.pt')
# 加载测试数据集
tests = torch.load('test.pt')
# 获取训练数据集的样本数量
simple_num = simples.shape[0]# 获取数据读取迭代器
def data_iter(batch_size, features, labels):# 计算数据的总数量num_examples = len(features)# 创建一个包含数据索引的列表 indices = list(range(num_examples))# 随机打乱索引列表,以实现随机读取样本,对训练结果意义不明# random.shuffle(indices)# 遍历打乱后的indices,每次取出batch_size个索引,用于构建一个小批量数据 for i in range(0, num_examples, batch_size):# 获取当前批次的索引号并以张量形式存储batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])# 根据索引从特征和标签中提取数据 yield features[batch_indices], labels[batch_indices]
# 在Python中,yield 是一个关键字,用于定义一个生成器(generator)。生成器是一种特殊的迭代器,它允许你定义一个可以记住上一次返回时在函数体中的位置的函数。对生成器函数的第二次(或第n次)调用将恢复函数的执行,并继续从上次挂起的位置开始。# 定义一个函数来加载并批量处理数据,返回数据获取迭代器
def load_array(data_arrays, batch_size, is_train=True): #@save"""构造一个PyTorch数据迭代器"""# 使用TensorDataset将多个tensor组合成一个数据集 dataset = data.TensorDataset(*data_arrays)# 使用DataLoader加载数据集,并指定批量大小和是否打乱数据return data.DataLoader(dataset, batch_size, shuffle=is_train)# 定义线性回归模型
def linreg(X, w, b): #@save"""线性回归模型"""# 使用矩阵乘法计算预测值,并加上偏差 return torch.matmul(X, w) + b# 定义平方损失函数
def squared_loss(y_hat, y): #@save"""均方损失"""# 计算预测值与实际值之间的平方差,并除以2(方便梯度计算)return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2# 定义交叉熵损失函数,线性回归模型用不到
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])# 定义一个鲁棒的损失函数,结合了平方损失和绝对值损失
def robust_loss(y_hat, y, delta=1.0):residual = torch.abs(y_hat - y)return torch.where(residual<delta, 0.5* residual **2, delta*(residual-0.5*delta))# 绝对值损失函数
def abs_loss(y_hat, y):return torch.abs(y_hat - y.reshape(y_hat.shape))# 定义随机梯度下降函数
def sgd(params, lr, batch_size): #@save"""小批量随机梯度下降"""with torch.no_grad():# 遍历模型参数 for param in params:# 更新参数值,使用学习率lr乘以参数的梯度,并除以批量大小 param -= lr * param.grad / batch_size# 清除参数的梯度,为下一轮迭代做准备 param.grad.zero_()# 数据标准化处理
def standard(X):X_mean = torch.mean(X, dim=0)X_std = torch.std(X, dim=0)return (X-X_mean)/X_std# 数据最小最大归一化处理
def min_max(X):X_min = torch.min(X, dim=0)[0]X_max = torch.max(X, dim=0)[0]return (X-X_min)/(X_max-X_min)# 不进行任何处理,直接返回输入
def noProcess(X):return X
#Linear Regression Implementation from Scratch
if __name__ == '__main__':# 设置学习率和训练轮数 lr = 0.03num_epochs = 20# 这里其实net变量并没有定义为一个神经网络模型,而是一个函数 # 但为了与后续代码保持一致,我们仍然使用net来表示这个线性回归函数# loss同理net = linregloss = squared_loss# 使用不进行任何处理的数据处理方式 data_process = noProcess# 将数据分成50个批次,计算每批数据的数量 batch_size = simple_num // 50# 提取特征和标签 # 提取最后一列作为标签 label = simples[:,-1]# 提取除最后一列外的所有列作为特征,并使用data_process进行处理feature=data_process(simples[:, :-1])# 初始化权重和偏差,权重使用正态分布初始化,偏差初始化为0 w = torch.normal(0, 1, size=(feature.shape[1], 1), requires_grad=True)# w = torch.tensor([0.3], requires_grad=True)b = torch.tensor([0.0], requires_grad=True)timer = d2l.Timer()# 开始训练 for epoch in range(num_epochs):# 通过data_iter遍历数据进行一轮训练for X,y in data_iter(batch_size, feature, label):# 计算预测值y_hat = net(X, w, b)# 计算损失l = loss(y_hat, y)# 反向传播计算梯度 l.sum().backward()# 使用随机梯度下降更新参数sgd([w,b], lr, batch_size)# 一轮训练结束后,计算整个训练集上的损失,用以监控训练效果# with torch.no_grad(): 告诉 PyTorch 在这个上下文内不要计算梯度,从而节省内存并加速计算。with torch.no_grad():label_hat = net(feature, w, b)epoch_loss = loss(label_hat, label)if epoch%5 == 0:print(f'in epoch{epoch+1}, loss is {epoch_loss.sum()}')# 在训练完成后,计算测试集上的预测值和损失 # 提取测试集的特征和标签 test_feature = data_process(tests[:, :-1])test_label = tests[:, -1]# 计算测试集上的预测值和损失 test_label_hat = net(test_feature, w, b)label_loss = loss(test_label_hat, test_label)print(f'in test epoch, loss is {label_loss.mean()}')print(f'true_w={tw}, true_b={tb}, w={w}, b={b}')print(f' {num_epochs} epoch, time {timer.stop():.2f} sec')
#Concise Implementation of Linear Regression
#the concise implementation have lower accuracy than from scratch
if __name__ == '__main2__':# 设置学习率、训练轮数、数据处理方式和批量大小 lr = 0.03num_epochs = 15# 使用不进行任何处理的数据处理方式 data_process = noProcess# 将数据分成50个批次,计算每批数据的数量 batch_size = simple_num // 50# 提取特征和标签 label = simples[:,-1]feature=data_process(simples[:, :-1])# 加载数据并创建数据迭代器 data_iter = load_array((feature, label), batch_size)# 构建神经网络模型,这里是一个简单的线性回归模型 net = nn.Sequential(nn.Linear(feature.shape[1], 1))# 我们的模型只包含一个层,因此实际上不需要Sequential# 不使用Sequential时,后面的net[0]需要改为net# net = nn.Linear(feature.shape[1], 1)# 初始化网络权重和偏置 net[0].weight.data.normal_(0, 0.01)net[0].bias.data.fill_(0)# 使用均方误差损失函数loss = nn.MSELoss()# 使用随机梯度下降优化器 trainer = torch.optim.SGD(net.parameters(), lr=lr)# 开始训练 for epoch in range(num_epochs):# 通过data_iter遍历数据进行一轮训练for X, y in data_iter:# 前向传播计算预测值y_hat = net(X)# 计算损失 l = loss(y_hat, y.reshape(y_hat.shape))# 梯度清零,为下一轮迭代计算做准备trainer.zero_grad()# 反向传播计算梯度 l.backward()# 使用随机梯度下降更新参数trainer.step()# 在每个epoch结束后,对整个数据集进行前向传播并计算损失,用于监控训练过程 label_hat = net(feature)epoch_loss = loss(label_hat, label.reshape(label_hat.shape))if epoch%5 == 0:print(f'in epoch{epoch+1}, loss is {epoch_loss.mean()}')# 在训练完成后,计算测试集上的预测值和损失 # 提取测试集的特征和标签 test_feature = data_process(tests[:, :-1])test_label = tests[:, -1]# 计算测试集上的预测值和损失 test_label_hat = net(test_feature)label_loss = loss(test_label_hat, test_label.reshape(test_label_hat.shape))print(f'in test epoch, loss is {label_loss.mean():f}')print(f'tw={tw}, tb={tb}, w={net[0].weight.data}, b={net[0].bias.data}')相关文章:

python 线性回归模型
教材链接-3.2. 线性回归的从零开始实现 c实现 该博客仅用于记录一下自己的代码,可与c实现作为对照 from d2l import torch as d2l import torch import random # nn是神经网络的缩写 from torch import nn from torch.utils import data# 加载训练数据 # 加载训…...
pcl::transformPointCloud()用法及注意事项
函数用法 #include <pcl/common/transforms.h> pcl::transformPointCloud(const pcl::PointCloud<PointT> &cloud_in, pcl::PointCloud<PointT> &cloud_out, const Eigen::Matrix4f &transform) 其中cloud_in, cloud_out的类型为pcl::PointClo…...

图像超分辨率重建相关概念、评价指标、数据集、模型
1、图像超分辨率概念 1.1 基本定义 超分辨率(Super-Resolution),简称超分(SR)。是指利用光学及其相关光学知识,根据已知图像信息恢复图像细节和其他数据信息的过程,简单来说就是增大图像的分辨…...

中移物联OneMO Cat.1模组推动联网POS规模应用
在第三方支付蓬勃发展和消费模式不断革新的时代背景下,新型联网POS终端以其智能化、便捷化的特点丰富人们生活便利度。在这一变革浪潮中,中移物联OneMO Cat.1模组ML307R凭借其卓越的性能和成本效益,成为推动联网POS规模应用的重要力量。 性能…...
二.常见算法--贪心算法
(1)单源点最短路径问题 问题描述: 给定一个图,任取其中一个节点为固定的起点,求从起点到任意节点的最短路径距离。 例如: 思路与关键点: 以下代码中涉及到宏INT_MAX,存在于<limits.h>中…...
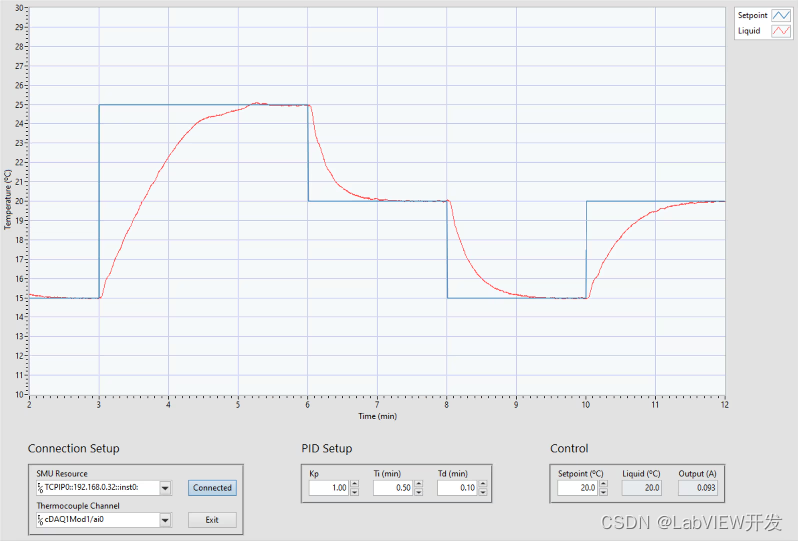
LabVIEW高温往复摩擦测试系统中PID控制
在LabVIEW开发高温往复摩擦测试系统中实现PID控制,需要注意以下几个方面: 1. 系统建模与参数确定 物理模型建立: 首先,需要了解被控对象的物理特性,包括热惯性、摩擦系数等。这些特性决定了系统的响应速度和稳定性。实验数据获取…...

配置yum源
以下是在 Linux 系统中配置新的 yum 源的一般步骤和命令示例(以 CentOS 系统为例): 备份原有 yum 源配置文件:mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak 创建新的 yum 源配置文件(…...
数据技术篇之数据同步)
深入理解数仓开发(二)数据技术篇之数据同步
1、数据同步 数据同步我们之前在数仓当中使用了多种工具,比如使用 Flume 将日志文件从服务器采集到 Kafka,再通过 Flume 将 Kafka 中的数据采集到 HDFS。使用 MaxWell 实时监听 MySQL 的 binlog 日志,并将采集到的变更日志(json 格…...
—— 类与对象(二))
C++语言学习(六)—— 类与对象(二)
目录 一、对象数组 二、对象指针 三、this 指针 四、类类型作为参数类型的三种形式 4.1 对象本身作为参数 4.2 对象指针作为参数 4.3 对象引用作为参数 五、静态成员 5.1 静态数据成员 5.2 静态成员函数 六、友元机制 6.1 友元函数 6.2 友元类 七、类的组合 八、…...

3d选择模型后不能旋转什么原因?怎么解决?---模大狮模型网
在3D建模和渲染的过程中,旋转模型是常见的操作。然而,有时在选择了模型后,却发现无法进行旋转,这可能会让许多用户感到困扰。本文将探讨3D选择模型后不能旋转的可能原因,并提供相应的解决方法。 一、3D选择模型后不能旋…...

从入门到精通:详解Linux环境基础开发工具的使用
前言 在这篇文章中,我将深入学习和理解Linux环境基础开发工具的使用。无论你是初学者还是有一定经验的开发者,相信这篇文章都会对你有所帮助。我们将详细讲解软件包管理器、编辑器、编译器、调试器、自动化构建工具以及版本控制工具的使用。 Linux软件…...
安装 node)
linux(centos 7)安装 node
linux(centos 7)安装 node 下载对应版本&安装解压配置环境变量使配置文件生效验证是否安装成功附加 目前node最新版本是 node-v22.0.0 官网下载地址:https://registry.npmmirror.com/binary.html?pathnode/latest-v22.x/node-v22.0.0-li…...

C++之第九课
课程列表 今天,我们要学习一种结构:循环结构。 循环的方法有3种。 今天先将第1种for学了: int a;//循环变量 int b; for(a1;a<10;a){//像if那样“打包”cout<<a<<" ";b; } 当然,也可以这样写&#…...

618精选编程书单推荐:优质知识提升你的代码力
前言 在这个快速发展的技术时代,不断学习和提升自己的编程技能是每位程序员的必修课。今天,我为大家精心挑选了一系列编程技术书籍,它们将是你技术成长道路上的宝贵财富。 文章目录 前言编程之路:为何阅读书籍是不可或缺的书籍的…...

使用httpx异步获取高校招生信息:一步到位的代理配置教程
概述 随着2024年中国高考的临近,考生和家长对高校招生信息的需求日益增加。了解各高校的专业、课程设置和录取标准对于高考志愿填报至关重要。通过爬虫技术,可以高效地从各高校官网获取这些关键信息。然而,面对大量的请求和反爬机制的挑战&a…...

使用Java Stream API的map方法将包含Long类型ID的流转换为String数组
在这个例子中,idList是一个包含Long类型ID的列表。我们使用stream()方法创建一个流,然后应用map(String::valueOf)方法将Long类型的ID转换为String类型。最后,我们使用toArray(String[]::new)方法将流中的元素收集到一个新的String[]数组中。…...

centos 安装nginx 并配置https ssl
进入你要安装的目录 一般是/usr/local/ wget https://nginx.org/download/nginx-1.24.0.tar.gz解压安装包:使用以下命令解压下载的Nginx安装包: tar -zxvf nginx-1.24.0.tar.gz在编译和安装Nginx之前,确保您的系统上已安装了必要的编译工具和…...

Jenkins 自动化部署
Post Steps部分 Exec cmmand cd /data/build/test-admin/ rm -f app.jar rm -f Dockerfile cp target/app.jar ./ cp docker/Dockerfile ./docker build -t test-admin . docker tag test-admin 192.168.1.100/test/test-admin:1.2-SNAPSHOT docker push 192.168.1.100/test/…...

VUE3好看的酒网站模板源码
文章目录 1.设计来源1.1 首页界面1.2 十大名酒界面1.3 名酒新闻界面1.4 联系我们界面1.5 在线留言界面 2.效果和结构2.1 动态效果2.2 代码结构 3.VUE框架系列源码4.源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/detai…...

索引压缩技术详解
在现代搜索引擎和信息检索系统中,索引压缩技术是提高存储效率和检索速度的关键手段。本文将深入探讨几种常见的索引压缩技术,包括词典压缩、倒排列表压缩算法、文档编号重排序以及静态索引裁剪。 词典压缩 1.1 基础概念 词典(Dictionary&am…...

OAuthlib错误排查实战:从invalid_grant到server_error的根因定位
1. 为什么OAuthlib的错误信息总让你一头雾水?刚接手一个老项目,登录流程突然崩了,控制台只甩出一行红字:invalid_grant。我下意识去翻OAuthlib文档,结果发现它压根不解释这个错误到底意味着什么——它只告诉你“授权无…...

AI如何重塑移动App开发:从功能交付到智能服务的范式跃迁
1. 项目概述:当手机App开发不再只是“写代码”,而变成一场数据驱动的智能进化“How AI and ML are Turning the Mobile App Development Industry into a Smart Industry?”——这个标题不是一句空泛的行业口号,而是我过去三年深度参与17个中…...

紧急提醒!项目管理人员不要乱签字,否则真会坐牢!
在工程项目里,人证不合一早已不是新鲜事,项目经理、安全员、资料员之间“代签”几乎成了一种心照不宣的默契。忙起来的时候,一张签到表、一份验收单传过来,顺手帮不在场的同事填上名字,很多人觉得这不过是抬抬手的事&a…...

Gemini3.1Pro编程项目什么时候该用什么时候不该用
概要Gemini 3.1 Pro是Google DeepMind于2026年2月推出的旗舰级多模态大语言模型。在编程和项目管理场景中,它最核心的价值不是"替代程序员写代码",而是在特定环节——需求分析、架构设计初稿、代码审查、Bug定位、技术文档生成、项目进度整理—…...

图片去水印怎么做?2026年最全图片去水印工具推荐与方法盘点
在日常工作和生活中,我们常常会遇到带有水印的图片——无论是社交平台的截图、素材库的图片,还是从各类网站下载的资源。水印虽然保护了原作者的权益,但有时也会影响我们对内容本身的使用。那么,图片去水印有哪些实用方法…...

【Typescript】12-模块声明文件与第三方库
模块、声明文件与第三方库 当你开始把 TypeScript 真正放进项目里,就会很快遇到一些不再是语法层面的现实问题: 代码和类型应该如何跨文件组织第三方库没有类型时怎么办为什么有些包能直接提示类型,有些却报“找不到声明文件”.d.ts 到底是什…...

【ChatGPT】锂电卷绕机深度拆解、信息图、爆炸图、C++代码框架
深度拆解信息图...

嵌套式学习:构建AI持续记忆与知识演化的认知架构
1. 项目概述:什么是“嵌套式学习”?它真能解决AI的健忘症吗? “Nested Learning: The Future of AI That Never Forgets”——这个标题一出现,我就在实验室白板上画了三遍草图。不是因为它多炫酷,而是因为它精准戳中了…...

【设计模式 13】命令:覆水能收
这一课讲命令模式。什么在变:决策需要记录、排队、撤销。怎么挡:把决策封装成命令对象,可执行可回滚。林衍那次决策失误,后来集团内部管它叫"黑色十月"。 起因是赵闯带回来一条消息:一家新晋竞争对手拿到了十…...

NotebookLM视频处理突然变慢?紧急排查清单:GPU卸载阈值、音频采样率陷阱、语言模型缓存泄漏
更多请点击: https://codechina.net 第一章:NotebookLM视频转文字 NotebookLM 原生不支持直接上传视频文件进行转录,但可通过将视频中的音频提取为标准格式(如 WAV 或 MP3),再借助 Google 的 Speech-to-Te…...