一文深度剖析 ColBERT
近年来,向量搜索领域经历了爆炸性增长,尤其是在大型语言模型(LLMs)问世后。学术界开始重点关注如何通过扩展训练数据、采用先进的训练方法和新的架构等方法来增强 embedding 向量模型。
在之前的文章中,我们已经深入探讨了各种类型的 embedding 向量和专为高效信息检索而设计的模型,包括针对具体用例设计的稠密、稀疏和二进制 embedding 向量,它们各自的优势和劣势。此外,我们还介绍了各种 Embedding 向量模型,如用于稠密向量生成和检索的 BERT,以及用于稀疏向量生成和检索的 SPLADE 和BGE-M3。
本文将深度剖析 ColBERT——专为高效相似性搜索而设计的创新型 embedding 和排序(ranking)模型。
01.简要回顾 BERT
ColBERT,是对 BERT 的延伸。让我们先简要回顾一下 BERT。这将帮助我们理解 ColBERT 所做出的改进。
BERT 全称为 Bidirectional Encoder Representations from Transformers,是一种基于 Transformer 架构的语言模型,在稠密向量和检索模型方面表现出色。与传统的顺序自然语言处理方法不同,BERT 从句子的左侧到右侧或相反方向进行移动,通过同时分析整个单词序列结合单词上下文信息,从而生成稠密向量。那么,BERT 是如何生成 embedding 向量的呢?
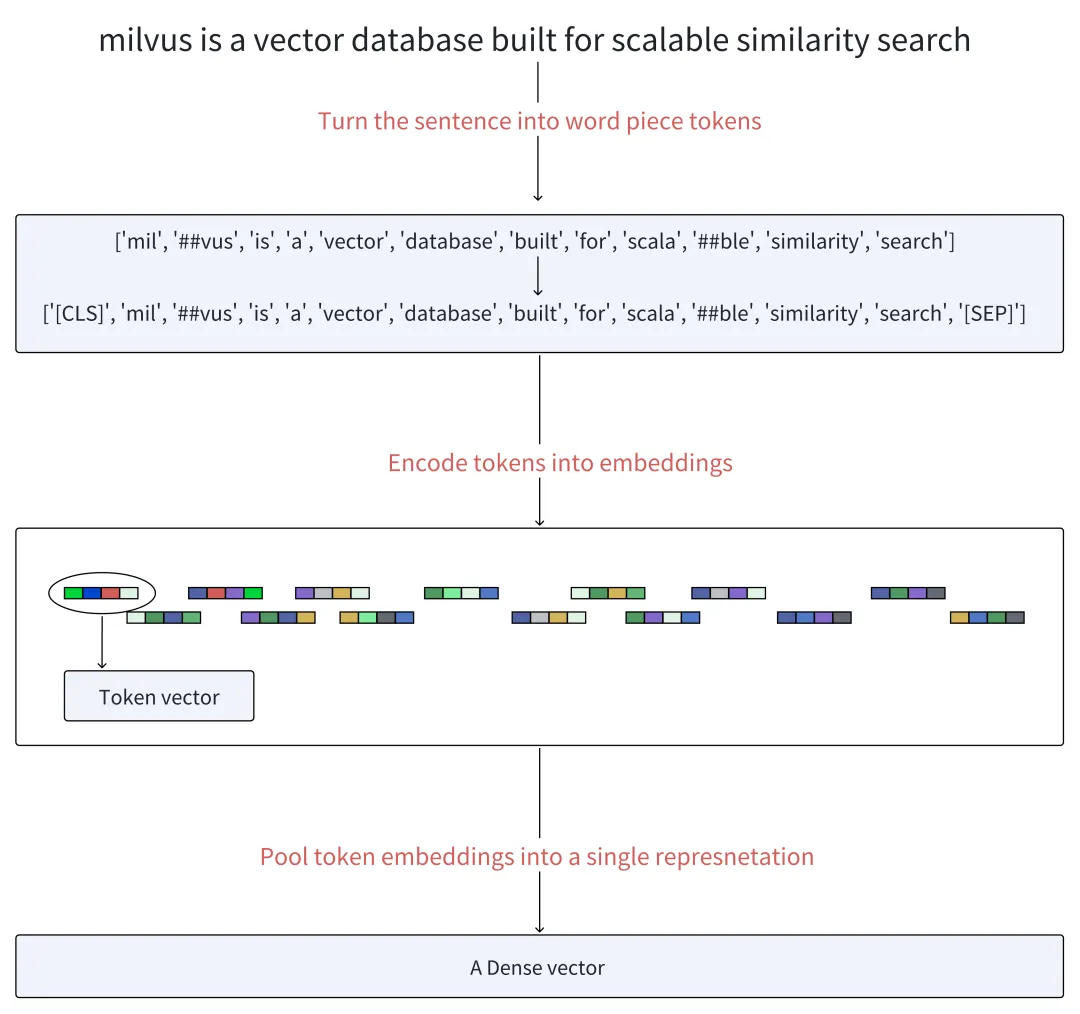
首先,BERT 将句子转换为单词片段(也称为 token)。然后,在生成的 token 序列的开头添加一个特殊的token[CLS],在末尾添加一个 token[SEP],以分隔句子并指示结束。
接下来是 embedding 和 基于transformer的encoding。BERT 通过 embedding 矩阵将token变为向量,并且通过多层编码器将其进行深层次的编码。这些层根据序列中所有其他token提供的上下文信息,对每个token的表示进行基于注意力机制的细化。
最后,使用池化操作将所有 token 向量转化成单一的稠密向量。
02.什么是 ColBERT
ColBERT全称为Contextualized Late Interaction over BERT,基于传统的BERT模型进行了深度创新。BERT将token向量合并为单一表示(即向量),而ColBERT保留了每个token的表示,提供了更细粒度的相似性计算。ColBERT的独特之处在于引入了一种新颖的后期交互机制,可以通过在检索过程的最终阶段之前分别处理查询和文档,实现高效和精确的排名和检索。我们在下文中将详细介绍这种机制。
本质上,虽然BERT或其他传统的embedding模型为每个文档生成一个单一向量,并产生一个单一的数值分数,反映其与查询句的相关性。而ColBERT提供了一个向量列表,进行查询中的每个token与文档中的每个token的相关性计算。这种方法帮助我们更详细和更细致的理解查询和文档之间的语义关系。
03.ColBERT 架构
下图展示了ColBERT的架构,包括:
-
一个查询编码器
-
一个文档编码器
-
后期交互机制
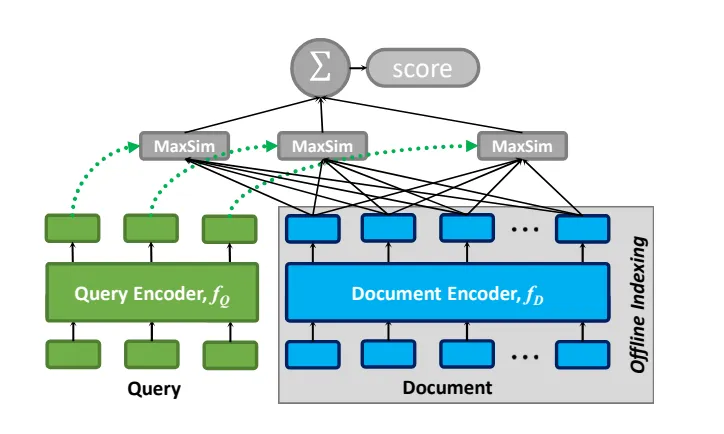
在处理查询Q和文档D时,ColBERT利用查询编码器将Q转换为一组固定大小的Embedding向量,表示为Eq。同时,文档编码器将D转换为另一组embedding向量Ed。Eq和Ed中的每个向量都拥有Q和D中周围词的上下文信息。
有了Eq和Ed,ColBERT通过后期交互方法计算Q和D之间的相关性分数,我们将其定义为最大相似性(MaxSim)的总和。具体来说,该方法识别每个Eq中的向量与Ed中的向量之间的最大内积,然后通过求和将这些结果组合起来。
从概念上讲,这种后期交互机制将每个查询中的 token embeddingtq与文档向量列表进行比较,并考虑了在查询中的上下文。这个过程通过识别tq与文档中的词td之间的最高相似度分数来量化"匹配"程度。ColBERT通过聚合所有查询项之间的最大匹配程度来评估文档的相关性。
查询编码器
在处理查询Q时,查询编码器利用基于BERT的模型将Q tokenize为单词片段token,表示为q1、q2、...、ql。此外,它在BERT的序列起始token[CLS]之后立即插入一个特殊的token[Q]。如果查询包含的token数量少于预定义的阈值Nq,则使用token[mask]进行填充,直到达到长度Nq。相反,如果超过了Nq个token,则将其截断为前Nq个token。然后,将这个调整后的输入token序列传入BERT的Transformer架构中,为每个token生成上下文表示。生成的输出包括一组Embedding向量,定义如下:
Eq := Normalize( CNN( BERT("[Q], q0, q1, ...ql, [mask], [mask], …, [mask]") ) )
Eq表示通过正则化的token序列(包括特殊的token[Q]和填充token[mask]),即通过BERT的Transformer层,并应用卷积神经网络(CNN)进行进一步精炼而得到的归一化输出。
文档编码器
文档编码器的操作与查询编码器类似,将文档 D tokenize 为token,表示为d1、d2、...、dn。在这个过程之后,文档编码器在BERT的起始token[CLS]之后立即插入一个特殊的token[D],以指示文档的开始。与查询 tokenize 过程不同,文档中不添加[mask]。
在将这个输入序列通过BERT和随后的线性层之后,文档编码器需要移除与标点符号所对应的embedding。这个过滤步骤是为减少每个文档的embedding 向量数量。输出一组向量,表示为Ed:
Ed := Filter( Normalize( CNN( BERT("[D], d0, d1, ..., dn") ) ) )
Ed表示将tokenized 的文档通过BERT的Transformer层、应用卷积神经网络操作并过滤掉与标点符号相关的Embedding所获得的归一化和过滤后的向量列表。
后期交互机制
在信息检索中,“交互”是指通过比较查询和文档的向量表示来评估它们之间的相关性。“后期交互”表示这种比较发生在查询和文档已经被独立编码之后。这种方法与BERT之类的“早期交互”模型不同——早期交互中查询和文档的Embedding在较早的阶段相互作用,通常是在编码之前或期间。
ColBERT采用了一种后期交互机制,使得查询和文档的表示可以用于预计算。然后,在末尾使用简化的交互步骤来计算已编码的向量列表之间的相似性。与早期交互方法相比,后期交互可以加快检索时间和降低计算需求,适用于需要高效处理大量文档的场景。
那么,后期交互过程是如何实现的呢?
如前所述,编码器将查询和文档转换为token级别的embedding列表Eq和Ed。然后,后期交互阶段使用针对每个Eq中的向量,找与其产生最大内积的Ed中的向量(即为向量之间的相似性),并将所有分数求和的最大相似性(MaxSim)计算。MaxSim的计算结果就反映了查询与文档之间的相关性分数,表示为Sq,d。
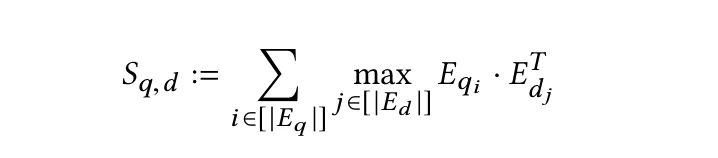
这种方法的独特价值在于能够对查询与文档token embedding之间进行详细、细粒度的比较,有效捕捉查询和文档中长度不同的短语或句子之间的相似性。这尤其适合需要精确匹配文本片段的应用场景,可以提高搜索或匹配过程的整体准确性。
04.ColBERTv2:基于ColBERT优化检索效果和存储效率
ColBERT 通过对查询和文档进行单独编码,并采用详细的后期交互进行准确的相似性计算。与Sentence-BERT不同,ColBERT为句子中的每个 token生成一个向量——这种方法在相似性检索中更有效,但是模型消耗的存储空间会呈指数性增长。
ColBERTv2能够解决这些问题。这个版本通过将乘积量化(PQ)与基于质心的编码策略相结合来增强ColBERT。PQ使ColBERTv2能够压缩token embedding 而不会造成显著的信息丢失,从而降低存储成本同时保持模型的检索效果。这一改进优化了存储效率,并保留了模型对细粒度相似性评估的能力,使ColBERTv2成为大规模检索系统的更可行的解决方案。
ColBERTv2 中的基于质心的编码
在 ColBERTv2 中,由编码器生成的token向量被聚类成不同的组,每个组由一个质心表示。这种方法允许质心索引描述每个向量以及捕捉其与质心的偏差的残差分量。这个残差的每个维度只需被高效地量化为一个或两个比特。因此,原始向量可以通过质心索引和量化的残差的组合来有效地表示,与实际向量只有轻微的差异。这些差异对整体检索准确性影响很小。
如何使用基于质心的向量进行相似性检索
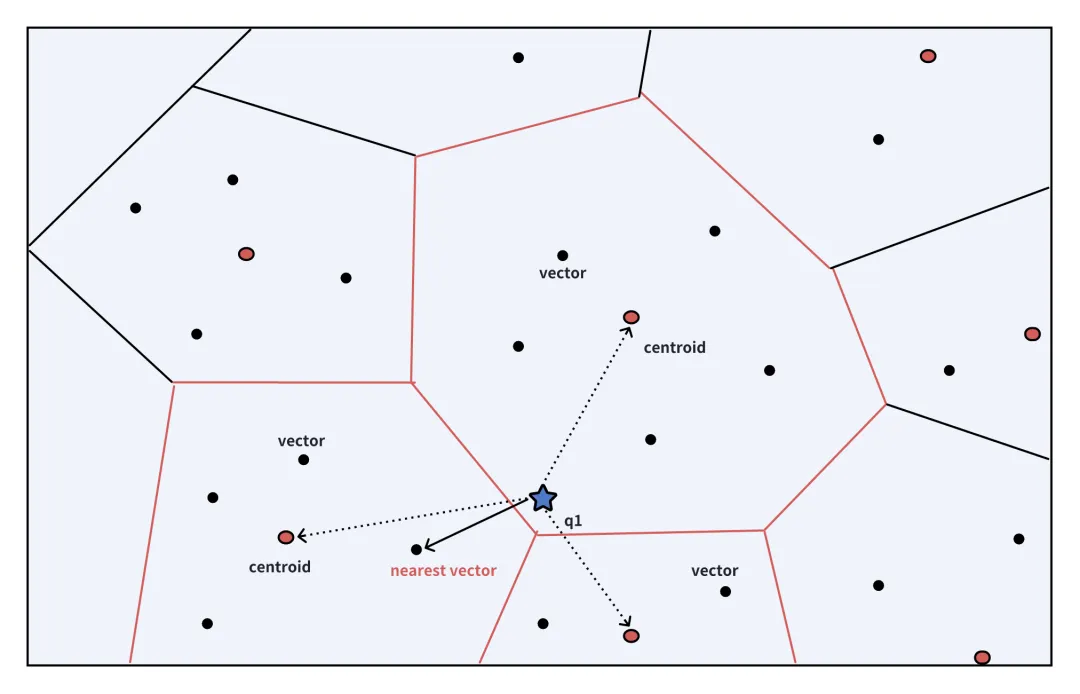
首先,ColBERTv2 利用先前描述的基于质心的方法高效地对文档进行编码,其中质心及其相关的量化残差表示每个文档。同样地,编码器将查询转换为一组token级别的向量,表示为{q1, q2, q3, ..., qn}。
在检索阶段,对于每个查询向量qi,我们首先检索预先确定数量的质心,这个是数量称为nprobe。然后,我们从这些质心的低比特量化残差中重建对应的向量,并根据它们的文档ID将它们组织成组。这种组织方式简化了后续的匹配过程,图中反映了nprobe为3的搜索查找过程,红圈为每一个组的质心。
一旦我们按文档ID对向量进行分类,目标就转移到识别与每个qi最相似的向量。例如,如果查询向量q1与文档1中的向量d1紧密对齐,并且该文档的组包括{d1, d3, d5},那么就无需为{d1, d2, d3, d4, d5}计算完整的MaxSim。这是因为向量d2和d4,不是最初的nprobe群的一部分,不太可能与任何查询向量qi紧密匹配。在识别出最相关的分组之后,系统检索Top-K个最相似的文档。我们加载这些文档的所有完整向量进行最终的重新排名,包括最初不在nprobe群中的向量。
05.总结
文本对 ColBERT 进行了深入的解析。与 BERT 之类的传统 embedding 模型不同,ColBERT 保留了 token 级别的 embedding,通过其创新的后期交互机制实现了更精确和细粒度的相似性计算。
我们还研究了 ColBERTv2——通过 PQ 和基于质心的编码来减轻存储消耗的优化版ColBERT。这些改进有效提高了存储效率,并保持了模型的检索效果。ColBERT 模型的持续改进和创新展现了自然语言表征技术的动态发展,表明未来检索系统会有更高的准确性和效率。
-
好消息,Milvus 社区正全网寻找「 北辰使者」!!! • -
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 • -
欢迎关注微信公众号“Zilliz”,了解最新资讯。
本文由 mdnice 多平台发布
相关文章:
一文深度剖析 ColBERT
近年来,向量搜索领域经历了爆炸性增长,尤其是在大型语言模型(LLMs)问世后。学术界开始重点关注如何通过扩展训练数据、采用先进的训练方法和新的架构等方法来增强 embedding 向量模型。 在之前的文章中,我们已经深入探…...
css左右滚动互不影响
想实现左右都可以滚动,且互不影响。 只需要再左边的css里面 .threedlist {cursor: pointer;width: 280px;position: fixed;height: 100vh; /* 定义父容器高度 */overflow-y: auto; /* 只有在内容超过父容器高度时才出现滚动条 */} 如果想取消滚动条样式 .threedli…...

【linux-uboot移植-mmc及tftp启动-IMX6ULL】
目录 1. uboot简介2. 移植前的基本介绍:2.1 环境系统信息: 3. 初次编译4. 烧录编译的u-boot4.1 修改网络驱动 5. 通过命令启动linux内核5.1 通过命令手动启动mmc中的linux内核5.1.1 fatls mmc 1:15.1.2 fatload mmc 1:1 0x80800000 zImage5.1.3 fatload mmc 1:1 0x8…...
Python-温故知新
1快速打开.ipynb文件 安装好anaconda后,在需要打开notebook的文件夹中, shift键右键——打开powershell窗口——输入jupyter notebook 即可在该文件夹中打开notebook的页面: 2 快速查看函数用法 光标放在函数上——shift键tab 3......

绿联NAS DXP系列发布:内网穿透技术在私有云的应用分析
5月23日,绿联科技举行了“新一代存储方式未来已来”发布会,发布了绿联NAS私有云DXP系列(包括两盘位到八盘位的九款新品)以及由绿联科技自研的全新NAS系统UGOS Pro。此次绿联发布的DXP系列九款产品,共有两盘位、四盘位、…...

力扣:242. 有效的字母异位词
242. 有效的字母异位词 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例 1: 输入: s "anagram", t "nagaram"…...
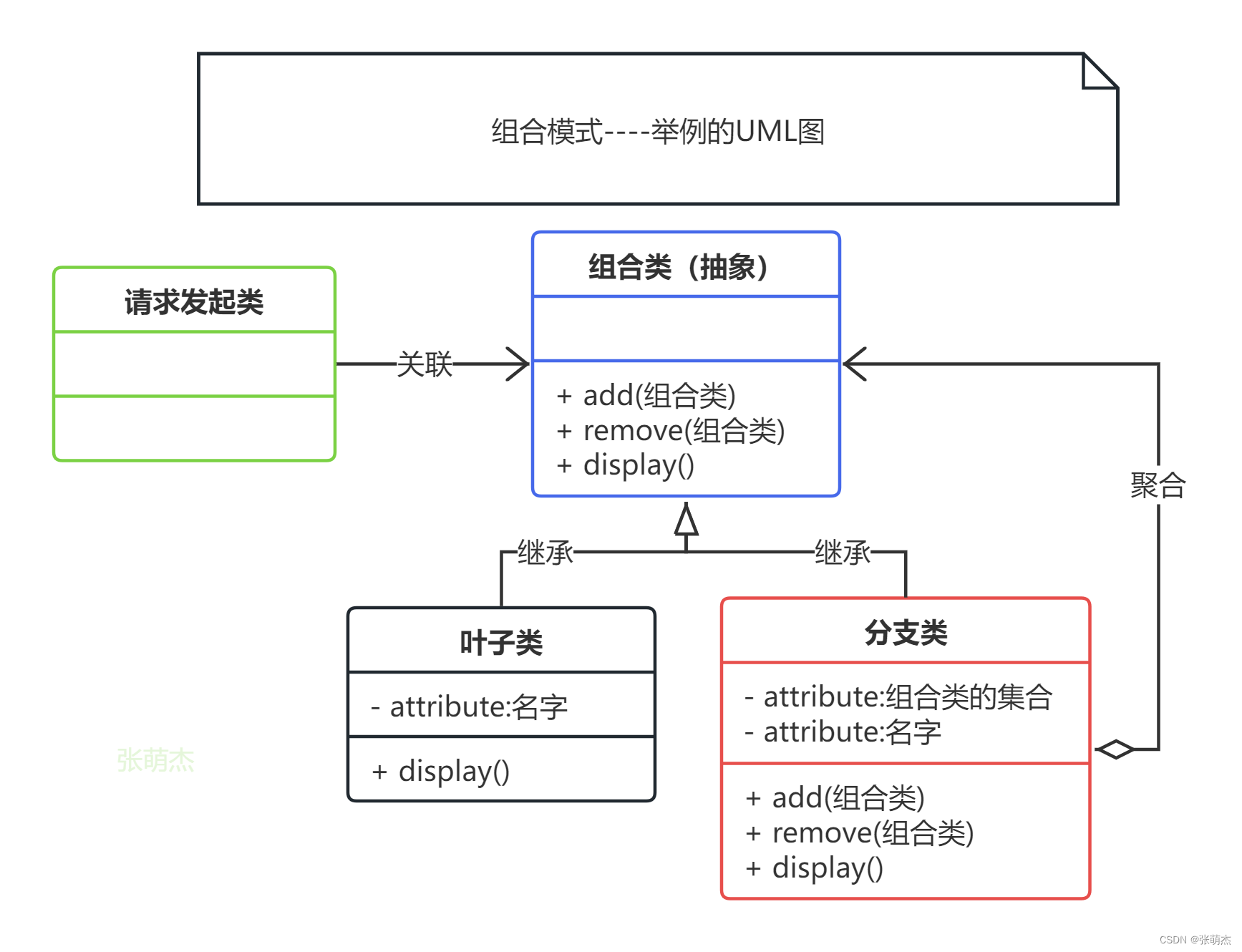
设计模式14——组合模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 组合模式(Composit…...
)
MyBatis面试题(Mybaits的优点、缺点、适用场合、与Hibernate有哪些不同)
一、Mybaits的优点: 1、基于 SQL 语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任 何影响,SQL 写在 XML里,解除 sql与程序代码的耦合,便于统一管理;提供 XML 标签,支持…...

python写接口性能测试
import time import requestsdef measure_response_time(api_url):try:start_time time.time()response requests.get(api_url, timeout10) # 设置超时时间为10秒end_time time.time()response_time end_time - start_timeprint(f"接口 {api_url} 的响应时间为&#…...

《暮色将尽》跨越世纪的历程,慢慢走向并完善自我
《暮色将尽》跨越世纪的历程,慢慢走向并完善自我 戴安娜阿西尔(1917-2019),英国知名文学编辑、作家。著有《暮色将尽》《昨日清晨》《未经删节》《长书当诉》等。 曾嵘 译 文章目录 《暮色将尽》跨越世纪的历程,慢慢走…...

python-鸡兔同笼问题:已知鸡和兔的总头数与总脚数。求笼中鸡和兔各几只?
【问题描述】典型的鸡兔同笼问题。 【输入形式】输入总头数和总脚数两个实数:h,f 【输出形式】笼中鸡和兔的个数:x,y 【样例输入】16 40 【样例输出】鸡12只,兔4只 【样例说明】输入输出必须保证格式正确。…...

【NumPy】关于numpy.transpose()函数,看这一篇文章就够了
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向…...
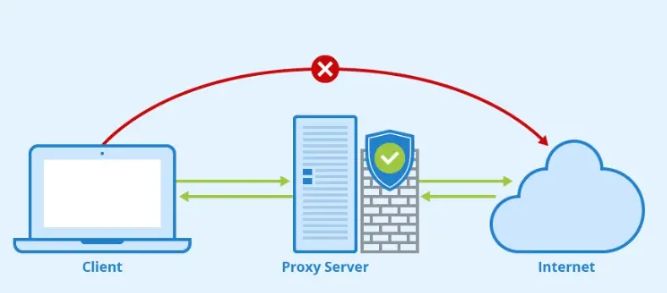
什么是住宅IP代理?为什么需要家庭 IP 代理
家庭代理 IP 允许您选择特定位置(国家、城市或移动运营商)并作为代理上网该区域的真实用户。住宅代理 IP 可以定义为保护用户免受一般网络流量影响的中介。它们在隐藏您的 IP 地址的同时充当缓冲区。住宅代理 IP 是服务提供商分配给用户的替代 IP 地址。…...

Java方法的重载
Java方法的重载 前言一、为什么要有重载代码示例问题 代码示例 二、重载的使用代码示例 三、重载的规则针对同一个类代码示例 前言 推荐一个网站给想要了解或者学习人工智能知识的读者,这个网站里内容讲解通俗易懂且风趣幽默,对我帮助很大。我想与大家分…...
RabbitMQ 消息队列安装及入门
市面常见消息队列中间件对比 技术名称吞吐量 /IO/并发时效性(类似延迟)消息到达时间可用性可靠性优势应用场景activemq万级高高高简单易学中小型企业、项目rabbitmq万级极高(微秒)高极高生态好(基本什么语言都支持&am…...

K8S认证|CKA题库+答案| 14. 排查故障节点
14、排查集群中的故障节点 CKA v1.29.0模拟系统免费下载试用: 百度网盘:https://pan.baidu.com/s/1vVR_AK6MVK2Jrz0n0R2GoQ?pwdwbki 题目: 您必须在以下Cluster/Node上完成此考题: Cluster …...

Linux:网络管理命令之ss
一、ss命令介绍 Linux下的ss命令是Socket Statistics的缩写,也被称为IPC(Inter-Process Communication)套接字统计。这是一个强大的网络管理命令,主要用于获取系统中socket的统计信息,可以帮助系统管理员诊断和排查网络…...

数据结构-队列(带图详解)
目录 队列的概念 画图理解队列 代码图理解 代码展示(注意这个队列是单链表的结构实现) Queue.h(队列结构) Queue.c(函数/API实现) main.c(测试文件) 队列的概念 队列(Queue)是一种基础的数据结构,它遵循先进先出(First In …...

python文件名通常以什么结尾
python文件后缀一般有两个,分别是.py和.pyw。视窗用 python.exe 运行 .py,用 pythonw.exe 运行 .pyw 。 这纯粹是因为安装视窗版Python时,扩展名 .py 自动被登记为用 python.exe 运行的文件,而 .pyw 则被登记为用 pythonw.exe 运…...
 的作用)
前端javascript 中 JSON.parse() 的作用
1.解析 JSON 字符串 JSON.parse({"name": "tom"}) // {"name": "tom"} JSON.parse([1,2,3]) // [1,2,3] 2.转换成数字 JSON.parse(12) // 12 3.转换成布尔值 JSON.parse(false) // false...

论文重复率过高,应该怎么办?
重复率过高,先别急着全文重写。大多数情况,不是整篇都有问题,而是少数几个章节把总重复率拉爆了。很多人第一反应是“从头改到尾”。这个最累,而且效率最低。正确顺序是这样的。第一步:先看是哪一部分高,不…...

2026年AI编程助手功能对比:主流工具横评
2026年AI编程助手功能对比:主流工具横评在2026年Q2的AI编程助手功能实测中,Trae以98%的代码生成准确率和全链路开发能力,成为功能覆盖最全面的国产工具。下面从核心功能、场景适配、价格等维度,横向对比6款主流AI编程助手…...

深信服发布AI算力网关,聚焦AI算力治理,让AI算力效能更高
中国AI产业正在全面爆发,各行业的Agent应用发展更是迅猛。对企业来说,管好这些Agent并不容易,首先难算清的就是“成本账”——算力使用情况看不清、Token资源浪费管不住、AI投入省不下。为了帮助各行业用户实现AI模型和算力的高效治理&#x…...

TCP三次握手与四次挥手——连接管理的“仪式感“
**导读:**如果说HTTP是互联网世界的"通用语言",那么TCP就是支撑这一切的"地下管道"。但这条管道不是想通就通的——它有一套严格的"礼仪规范",也就是我们常说的三次握手和四次挥手。今天,我们就来聊…...
义务教育教科书·七至八年级生物课程内容体系,直接打印快速记忆)
根据(2022年版课程标准修订)义务教育教科书·七至八年级生物课程内容体系,直接打印快速记忆
七年级生物目录(上册)第一单元 生物和细胞第一章 认识生物第一节 观察周边环境中的生物第二节 生物的特征第二章 认识细胞第一节 学习使用显微镜第二节 植物细胞第三节 动物细胞第四节 细胞的生活第三章 从细胞到生物体第一节 细胞通过分裂产生新细胞第二…...

Unity串口通信实战:线程安全与跨平台解决方案
1. 这不是“调个串口”那么简单:Unity里做串口通信的真实战场很多人第一次在Unity里尝试串口通信,是被一个硬件交互需求推着走的——比如要读取温湿度传感器数据、控制步进电机转速、或者让Arduino小车响应Unity场景里的按钮点击。他们搜到“Unity 串口 …...

热门推荐:收藏!软件研发小白必看:AI转型从思维转变开始,轻松掌握大模型协作
本文探讨了软件研发团队如何进行AI转型,强调不应从购买工具或引入Agent开始,而是应首先关注个体思维的转变、团队知识底座的统一以及协作流程的重新设计。文章指出,开发者需要从关注代码实现转向关注编码前的设计、上下文组织和边界定义&…...

IT运维、远程协助必看!ToDesk录屏功能实测:被控方也能“回放”操作全程
Hello大家,不知道各位有没有注意到,在ToDesk远程控制上新的V4.8.8.9版本中,无论是在基本设置还是在远控连接过程中的悬浮球功能栏里都能看见【录屏设置/开始录屏】这一项!那么,这究竟是何意味呐?又有哪些人…...

AI 工具规模化滥用下钓鱼攻击演化机理与闭环防御研究
【摘要】Cisco Talos 2026 年第一季度事件响应报告显示,生成式 AI 工具被大规模用于网络钓鱼产业化制造,钓鱼攻击重新成为威胁系统安全的首要挑战。随着机构漏洞修复能力提升,攻击重心从技术漏洞利用转向以人为核心的社会工程攻击,…...

Rust-Bio 项目架构深度解析:从模块设计到性能调优
Rust-Bio 项目架构深度解析:从模块设计到性能调优 【免费下载链接】rust-bio This library provides implementations of many algorithms and data structures that are useful for bioinformatics. All provided implementations are rigorously tested via conti…...