机器学习之常用算法与数据处理
一、机器学习概念:
机器学习是一门多领域交叉学科,涉及概率论、统计学、计算机科学等多门学科。它的核心概念是通过算法让计算机从数据中学习,改善自身性能。机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构来不断改善自身的性能。
机器学习就是数据通过算法构建出模型并对模型进行评估 ,评估的性能如果达到要求就拿这个模型来测试其他的数据,如果达不到要求就要调整算法来重新建立模型,再次进行评估如此循环往复,最终获得满意的经验来处理其他的数据。

机器学习:算法统称,其中包含很多算法,给算法划分类别,主要划分为2大类(3类或4类) 。
第一类、监督学习(Supervised Learning) 。从数据集来说,有y值的,有label和target 。数据集:特征features +标签label
标签监督学习算法中标签label值的类型,可以划分为两类:
标签label值类型:离散值,称为分类算法
- 比如鸢尾花数据集
- 离散值,个数是一定的,从几个值中获取的数据
标签label值类型:连续值,称为回归算法
- 比如天气预测
第二类、非监督学习(Unsupervised Learning) 。从数据集来说,没有y值,没有label或target 。数据集:特征features
可以细分为两类算法:
- 聚类算法:就是把相似的对象聚集在一起的过程。想象一下,你有一堆不同颜色、形状和大小的球,你想要将它们分成几组,使得每组内的球尽可能相似,而不同组之间的球则尽量不同。
- 降维算法:将特征值由高向低下降,比如将鸢尾花数据集中特征值features是4个维度(4列值)降低到三个维度(3列)
数据集:
在机器学习中,数据集的基本概念是指用于训练和评估机器学习模型的数据集合。这些数据集合通常是由真实世界中的数据收集而来,它们由一组样本组成,每个样本包含一个或多个特征和一个或多个标签(也称为目标变量)。
1.1机器学习核心:
机器学习核心:数据+算法

1.2机器学习库:
机器学习库:机器学习库是包含各种机器学习算法和工具的集合,其中包含分类算法、回归算法、聚类算法和降维算法、推荐算法。目前来说,使用比较广泛2个算法库(机器学习算法库:将算法实现出来,用户只需要调用API,带入数据,训练模型即可)
算法库一:scikit-learn
- 基于Python语言实现机器学习算法库,可以人工智能学习,必学库
算法库二:Spark MLlib
- 基于Spark之上实现机器学习算法库,目前在大数据领域中经常被使用
特点:将常用的算法实现出来,结合海量数据训练模型,RDD数据存储内容,迭代训练模型更加快速,实际项目中往往scikit-learn 和 Spark MLlib一起使用的,都使用Python语言

Spark模块中提供两个数据接口封装数据,导致SparkMLlib库中有两种实现API,两个数据接口分别是:
- RDD数据结构
- DataFrame数据结构
推荐使用基于DataFrame API库。
1.3机器学习三要素:
使用机器学习库时,三要素为:算法、模型、策略。
- 模型(model):模型在未进行训练前,其可能的参数是多个甚至无穷的,故可能的模型也是多个甚至无穷的,这些模型构成的集合就是假设空间。
- 策略(strategy):即从假设空间中挑选出参数最优的模型的准则。模型的分类或预测结果与实际情况的误差(损失函数)越小,模型就越好。那么策略就是误差最小。
- 算法(algorithm):即从假设空间中挑选模型的方法(等同于求解最佳的模型参数)。机器学习的参数求解通常都会转化为最优化问题,故学习算法通常是最优化算法,例如最速梯度下降法、牛顿法以及拟牛顿法等。
1.4机器学习术语
术语一:数据集

术语二:样本

数据集中一条数据。
术语三:特征features
每个样本中特征feature组合

使用向量Vector表示,认为向量就是数组Array
向量分为两种:
- 稠密向量(Dense Vector):向量中特征值为非0的占比大于50%,称为稠密向量
- 稀疏向量(Sparse Vector):向量中特征值为0的占比大于50%,称为稀疏向量
术语四:矩阵
将多个特征(向量)放在一起就是矩阵Matrix,由于向量分为稠密跟系数,所以矩阵分两种:
- 稠密矩阵:矩阵每行数据为稠密向量,那么此矩阵为稠密矩阵
- 稀疏矩阵:矩阵每行数据为稀疏向量,那么此矩阵为稠密矩阵
术语五:标签label
针对监督学习算法来说,就相当于 y = kx + b 中y的值
ok,讲完基本概念,接下来提供三个案例来讲解数据如何处理以及常用算法。
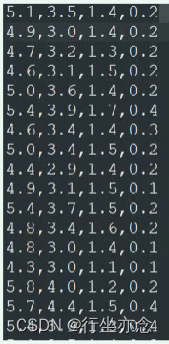
二、鸢尾花数据集:
鸢(yuan)尾花 lris Dataset 数据集是机器学习领域经典数据集,该数据集可以从加州大 学欧文分校(UCI)的机器学习库中得到。鸢尾花数据集包含了150条鸢尾花信息,每50 条取自三个鸢尾花中之一:Setosa、Versicolour和 Virginica,每个花的特征用下面5种属性 描述。 (1)萼片长度(厘米) (2)萼片宽度(厘米) (3)花瓣长度(厘米) (4)花瓣宽度(厘米) (5)类(Setosa、Versicolour、Virginica) 花的萼片是花的外部结构,保护花的更脆弱的部分(如花)。在许多花中,片是绿 的,只有花瓣是鲜艳多彩的,然而对与鸢尾花,片也是鲜艳多彩的。下图中的Virginica 鸢尾花的图片,鸢尾花的萼片比花瓣大并且下垂,而花向上。如下图:

在鸢尾花中花数据集中,包含 150个样本和4个特征,因此将其记作 150x4 维的矩阵。
接下来使用Scala语言来构建分类模型:
1.构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[4]").config("spark.sql.shuffle.partitions", 4).getOrCreate()import spark.implicits._
2.加载鸢尾花数据集iris.data,属于csv文件
val irisSchema: StructType = new StructType().add("sepal_length", DoubleType, nullable = true).add("sepal_width", DoubleType, nullable = true).add("petal_length", DoubleType, nullable = true).add("petal_width", DoubleType, nullable = true).add("class", StringType, nullable = true)val rawIrisDF: DataFrame = spark.read.option("sep", ",")// 当CSV文件首行不是列名称时,自定义Schema.option("header", "false").option("inferSchema", "false").schema(irisSchema).csv("datas/iris/iris.data")//rawIrisDF.printSchema()//rawIrisDF.show(10, truncate = false) 
3.将 萼片长度、宽度及花瓣长度、宽度 封装值 特征features向量中
val assembler = new VectorAssembler().setInputCols(rawIrisDF.columns.dropRight(1)).setOutputCol("features") // 添加一列,类型为向量val df1: DataFrame = assembler.transform(rawIrisDF)///df1.printSchema()//df1.show(10, truncate = false)4.转换类别字符串数据为数值数据
val indexer: StringIndexer = new StringIndexer().setInputCol("class") // 对哪列数据进行索引化.setOutputCol("label") // 数据索引化后列名val df2: DataFrame = indexer.fit(df1) // fit方法表示调用函数,传递DataFrame,获取模型.transform(df1)/*root|-- sepal_length: double (nullable = true)|-- sepal_width: double (nullable = true)|-- petal_length: double (nullable = true)|-- petal_width: double (nullable = true)|-- class: string (nullable = true)|-- features: vector (nullable = true) // 特征 x|-- label: double (nullable = false) // 标签 y算法:y = kx + b*/df2.printSchema()df2.show(150, truncate = false)5.将特征数据features进行标准化处理转换,使用StandardScaler
机器学习核心三要素: 数据(指的就是特征features) + 算法 = 模型(最佳)
调优中,最重要的就是特征数据features,如果特征数据比较好,处理恰当,可能得到较好模型
在实际开发中,特征数据features需要进行各个转换操作,比如正则化、归一化或标准化等等。
为什么需要对特征数据features进行归一化等操作呢???? 原因在于不同维度特征值,值的范围跨度不一样,导致模型异常
val scaler: StandardScaler = new StandardScaler().setInputCol("features").setOutputCol("scale_features").setWithStd(true) // 使用标准差缩放.setWithMean(false) // 不适用平均值缩放val irisDF: DataFrame = scaler.fit(df2).transform(df2)//irisDF.printSchema()//irisDF.show(10, truncate = false)
6.选择一个分类算法,构建分类模型
分类算法属于最多算法,比如如下分类算法:1. 决策树(DecisionTree)分类算法2. 朴素贝叶斯(Naive Bayes)分类算法,适合构建文本数据特征分类,比如垃圾邮件,情感分析3. 逻辑回归(Logistics Regression)分类算法4. 线性支持向量机(Linear SVM)分类算法5. 神经网络相关分类算法,比如多层感知机算法 -> 深度学习算法6. 集成融合算法:随机森林(RF)分类算法、梯度提升树(GBT)算法
7.将数据应用到算法中,训练模型以及对模型进行评估
//训练模型val lrModel: LogisticRegressionModel = lr.fit(irisDF)//评估模型到底如何val summary: LogisticRegressionSummary = lrModel.summary// 准确度:accuracy: 0.9733333333333334println(s"accuracy: ${summary.accuracy}")// 精确度:precision: 1.0, 0.96, 0.96, 针对每个类别数据预测准确度println(s"precision: ${summary.precisionByLabel.mkString(", ")}")// 应用结束,关闭资源spark.stop() 
总结:
总的来说,数据集训练模型的过程可以分为四个步骤:
- 特征提取(提取鸢尾花数据集)
- 类别标签label索引化
- label标签值,如果是离散值,算法是分类算法;如果是连续值,算法是回归
- 无论是 label还是features数据必须是数值类型(Double类型 )
- 特征features标准化
- 选择一个分类算法,构建分类模型
三、波士顿房价预测
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。波士顿的房价是由各方面影响而来的,所以要预测波士顿的房价必须从数据集属性来研究。接下来将使用线性回归算法对波士顿房价数据集构建回归模型并评估模型性能。

波士顿房价预测步骤:
1. 加载波士顿房价数据集 2. 获取特征features和标签label 3. 特征数据转换处理(归一化)等 4. 创建线性回归算法实例对象,设置相关参数,并且应用数据训练模型 5. 模型评估,查看模型如何 6. 模型预测
这里由于线性回归算法,默认情况下,对特征features数据进行标准化处理转换,所以此处不再进行处理,所以不需要进行步骤3,将特征数据转换处理。
其实会发现大部分模型训练的时间都会花在数据处理上面,大概会花费百分之八十的时间,而算法的使用与模型评估预测只占百分之二十,这也是由于本来就有机器学习库中封装的API.
代码如下:
import org.apache.spark.ml.linalg
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.ml.regression.{LinearRegression, LinearRegressionModel}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.storage.StorageLevel/*** 波士顿房价数据集,共506条数据,13个属性(特征值,features),1个房价(预测值,target)*/
object LrBostonRegression {def main(args: Array[String]): Unit = {// 构建SparkSession实例对象,通过建造者模式创建val spark: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[3]").config("spark.sql.shuffle.partitions", "3").getOrCreate()import spark.implicits._val bostonPriceDF: Dataset[String] = spark.read.textFile("datas/housing/housing.data").filter(line => null != line && line.trim.split("\\s+").length == 14)val bostonDF: DataFrame = bostonPriceDF.mapPartitions{iter =>iter.map{line =>val parts: Array[String] = line.trim.split("\\s+")// 获取标签labelval label: Double = parts(parts.length - 1).toDouble// 获取特征featuresval values: Array[Double] = parts.dropRight(1).map(_.toDouble)val features: linalg.Vector = Vectors.dense(values)// 返回二元组(features, label)}}// 调用toDF函数,指定列名称.toDF("features", "label")//bostonDF.printSchema()//bostonDF.show(20, truncate = false)// TODO: 需要将数据集划分为训练数据集和测试数据集val Array(trainingDF, testingDF) = bostonDF.randomSplit(Array(0.8, 0.2), seed = 123L)trainingDF.persist(StorageLevel.MEMORY_AND_DISK).count() // 触发缓存val lr: LinearRegression = new LinearRegression()// 设置特征列和标签列名称.setFeaturesCol("features").setLabelCol("label")// 是否对特征数据进行标准化转换处理.setStandardization(true)// 设置算法底层求解方式,要么是最小二乘法(正规方程normal),要么是拟牛顿法(l-bfgs).setSolver("auto")// 设置算法相关超参数的值.setMaxIter(20).setRegParam(1).setElasticNetParam(0.4)val lrModel: LinearRegressionModel = lr.fit(trainingDF)// Coefficients:斜率,就是k Intercept:截距,就是bprintln(s"Coefficients: ${lrModel.coefficients}, Intercept: ${lrModel.intercept}")val trainingSummary = lrModel.summaryprintln(s"RMSE: ${trainingSummary.rootMeanSquaredError}")lrModel.transform(testingDF).show(10, truncate = false)// 应用结束,关闭资源spark.stop()}}
运行结果如下:

四、泰坦尼克号生存预测
泰坦尼克号生存预测与第一个鸢尾花数据集一样,使用的算法是逻辑回归(Logistics Regression)分类算法
逻辑回归算法与线性回归算法类似:二分类

逻辑回归算法是分类算法的一种:
逻辑回归算法,充分利用sigmod函数和线性回归算法,综合起来,进行预测分类操作;如果要实现多分类,使用softmax函数(深度学习算法中函数)。
泰坦尼克号之中包含的变量有12个,其中要注意的是Age是有缺省值的。

缺省值的处理方法有很多,在这里我们选择对缺省值做填充:

将Age列的值挑选出来使用过滤器将不为空值过滤出来,计算平均值,然后使用Age平均值替代缺省的值。
模型预测步骤如下:
1. 加载数据、数据过滤与基本转换 2. 数据准备:特征工程(提取、转换与选择) 3. 使用算法和数据构建模型:算法参数 4. 模型评估
代码如下:
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer, VectorAssembler}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._/*** 基于泰塔尼克号数据集,使用逻辑回归构建分类模型,评估模型*/
object TitanicLrClassification {def main(args: Array[String]): Unit = {// 构建SparkSession实例对象,通过建造者模式创建val spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[3]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 导入隐式转换和函数库import spark.implicits._val rawTitanicDF: DataFrame = spark.read.option("header", "true").option("inferSchema", "true").csv("datas/titanic/train.csv")/*root|-- PassengerId: integer (nullable = true)|-- Survived: integer (nullable = true)|-- Pclass: integer (nullable = true)|-- Name: string (nullable = true)|-- Sex: string (nullable = true)|-- Age: double (nullable = true)|-- SibSp: integer (nullable = true)|-- Parch: integer (nullable = true)|-- Ticket: string (nullable = true)|-- Fare: double (nullable = true)|-- Cabin: string (nullable = true)|-- Embarked: string (nullable = true)*///rawTitanicDF.printSchema()//rawTitanicDF.show(10, truncate = false)// 2.1 Age年龄字段有缺省值,填充为年龄字段平均值val avgAge: Double = rawTitanicDF.select($"Age").filter($"Age".isNotNull).select(round(avg($"Age"), 2).as("avgAge")).first().getAs[Double](0)//println(s"Avg Age = $avgAge")val ageTitanicDF: DataFrame = rawTitanicDF.select(// 标签label$"Survived".as("label"),$"Pclass", $"Sex", $"SibSp", $"Parch", $"Fare", $"Age",// 当年龄为null时,使用平均年龄代替when($"Age".isNotNull, $"Age").otherwise(avgAge).as("defaultAge"))// 2.2 对Sex字段类别特征换换,使用StringIndexer和OneHotEncoder// male ->0 ,female -> 1val indexer: StringIndexer = new StringIndexer().setInputCol("Sex").setOutputCol("sexIndex")val indexerTitanicDF = indexer.fit(ageTitanicDF).transform(ageTitanicDF)// male -> [1.0, 0.0] female -> [0.0, 1.0]val encoder: OneHotEncoder = new OneHotEncoder().setInputCol("sexIndex").setOutputCol("sexVector").setDropLast(false)val sexTitanicDF: DataFrame = encoder.transform(indexerTitanicDF)// 2.3 将特征值组合, 使用VectorAssemblerval assembler: VectorAssembler = new VectorAssembler().setInputCols(Array("Pclass", "sexVector", "SibSp", "Parch", "Fare", "defaultAge")).setOutputCol("features")val titanicDF: DataFrame = assembler.transform(sexTitanicDF)//titanicDF.printSchema()//titanicDF.show(20, truncate = false)// 2.4 划分数据集为训练集和测试集val Array(trainingDF, testingDF) = titanicDF.randomSplit(Array(0.8, 0.2))trainingDF.cache().count()val logisticRegression: LogisticRegression = new LogisticRegression().setLabelCol("label").setFeaturesCol("features").setPredictionCol("prediction") // 使用模型预测时,预测值的列名称// 二分类.setFamily("binomial").setStandardization(true)// 超参数.setMaxIter(100).setRegParam(0.1).setElasticNetParam(0.8)val lrModel: LogisticRegressionModel = logisticRegression.fit(trainingDF)// y = θ0 + θ1x1+ θ2x2+ θ3x4+ θ4x4+ θ5x5+ θ6x6println(s"coefficients: ${lrModel.coefficientMatrix}") // 斜率, θ1 ~ θ6println(s"intercepts: ${lrModel.interceptVector}") // 截距, θ0val predictionDF: DataFrame = lrModel.transform(testingDF)//predictionDF.printSchema()predictionDF.select("label", "prediction", "probability", "features").show(40, truncate = false)// 分类中的ACCU、Precision、Recall、F-measure、Accuracyval accuracy = new MulticlassClassificationEvaluator().setLabelCol("label").setPredictionCol("prediction")// 四个指标名称:"f1", "weightedPrecision", "weightedRecall", "accuracy".setMetricName("accuracy").evaluate(predictionDF)println(s"accuracy = $accuracy")// 应用结束,关闭资源spark.stop()}}
1.获取特征值

2.特征值组合:

年龄有默认字段
性别先转换为索引,然后转换为向量
sexVector表示形式:(向量个数,索引下标,索引下标的值)
也就是说(2,[0],[1.0])这个数据表示为,这个向量里面有两个值,后面两个表示为0下标的值是1.0,其他为0,那么这个向量就是(1.0,0)。

准确率百分之83.
至此,三个案例都讲完啦。
总结:
使用数据集训练模型的步骤大差不差,都需要加载数据后对数据进行一系列处理(过滤与基本转换),然后构建特征工程,选择算法(有的算法要输入参数)得到模型,最后进行评估预测此模型是否可用(值得信任),可以的话就进行保存以便下次再用。
(以上部分资料来自黑马程序员,自用笔记,侵删。)
相关文章:
机器学习之常用算法与数据处理
一、机器学习概念: 机器学习是一门多领域交叉学科,涉及概率论、统计学、计算机科学等多门学科。它的核心概念是通过算法让计算机从数据中学习,改善自身性能。机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识…...

Git管理
git作用:代码回溯 版本切换 多人协作 远程备份 git仓库:本地仓库:开发人员自己电脑上的Git仓库 原程仓库:远程服务器上的Git仓库 commit:提交,将本地文件和版本信息保存到本地仓库 push:推送࿰…...
osgearth 3.5 vs 2019编译
下载源码 git clone --recurse-submodules https://github.com/gwaldron/osgearth.git 修改配置文件 主要是修改bootstrap_vcpkg.bat,一处是vs的版本,第二处是-DCMAKE_BUILD_TYPERELEASE 构建 执行bootstrap_vcpkg.bat vs中生成安装 vs2019打开bu…...

2024最新 Jenkins + Docker 实战教程(六)- Jenkins配置邮箱接收构建通知
😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~ 🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Mi…...
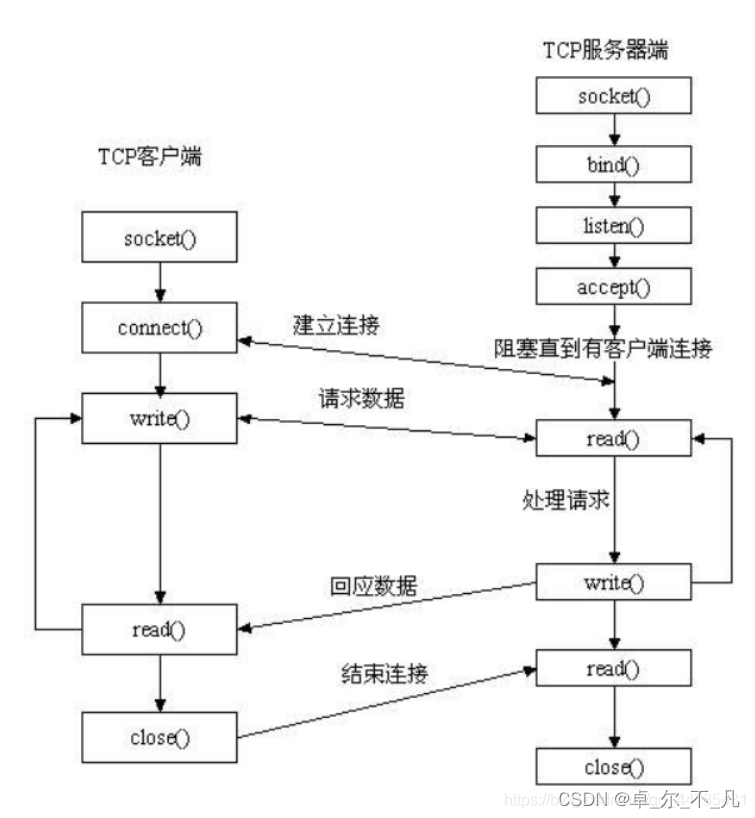
Python学习---基于TCP协议的网络通信程序案例
TCP简介: ●TCP 面向连接、可靠的、基于字节流的传输控制协议 ●TCP的特点 ○面向连接 ○可靠传输 ■应答机制 ■超时重传 ■错误校验 ■流量管控 ●TCP通信模型 TCP严格区分客户…...
正确可用--Notepad++批量转换文件编码为UTF8
参考了:Notepad批量转换文件编码为UTF8_怎么批量把ansi转成utf8-CSDN博客https://blog.csdn.net/wangmy1988/article/details/118698647我参考了它的教程,但是py脚本写的不对. 只能改一个.不能实现批量更改. 他的操作步骤没问题,就是把脚本代码换成我这个. #-*-…...

每天五分钟深度学习框架PyTorch:创建具有特殊值的tensor张量
本文重点 tensor张量是一个多维数组,本节课程我们将学习一些pytorch中已经封装好的方法,使用这些方法我们可以快速创建出具有特殊意义的tensor张量。 创建一个值为空的张量 import torch import numpy as np a=torch.empty(1) print(a) print(a.dim()) print(s.shape) 如图…...

2024电工杯数学建模B题Python代码+结果表数据教学
2024电工杯B题保姆级分析完整思路代码数据教学 B题题目:大学生平衡膳食食谱的优化设计及评价 以下仅展示部分,完整版看文末的文章 import pandas as pd df1 pd.read_excel(附件1:1名男大学生的一日食谱.xlsx) df1# 获取所有工作表名称 e…...
LabVIEW和ZigBee无线温湿度监测
LabVIEW和ZigBee无线温湿度监测 随着物联网技术的迅速发展,温湿度数据的远程无线监测在农业大棚、仓库和其他需环境控制的场所变得日益重要。开发了一种基于LabVIEW和ZigBee技术的多区域无线温湿度监测系统。系统通过DHT11传感器收集温湿度数据,利用Zig…...
FastCopy
目录 背景: 简介: 原理: 下载地址: 工具的使用: 背景: 简介: FastCopy是一款速度非常快的拷贝软件,软件版本为5.7.1 Fastcopy是日本的最快的文件拷贝工具,磁盘间相互拷贝文件是司空见惯的事情,通常情况…...

stm32常用编写C语言基础知识,条件编译,结构体等
位操作 宏定义#define 带参数的宏定义 条件编译 下面是头文件中常见的编译语句,其中_LED_H可以认为是一个编译段的名字。 下面代码表示满足某个条件,进行包含头文件的编译,SYSTEM_SUPPORT_OS可能是条件,当非0时,可以…...
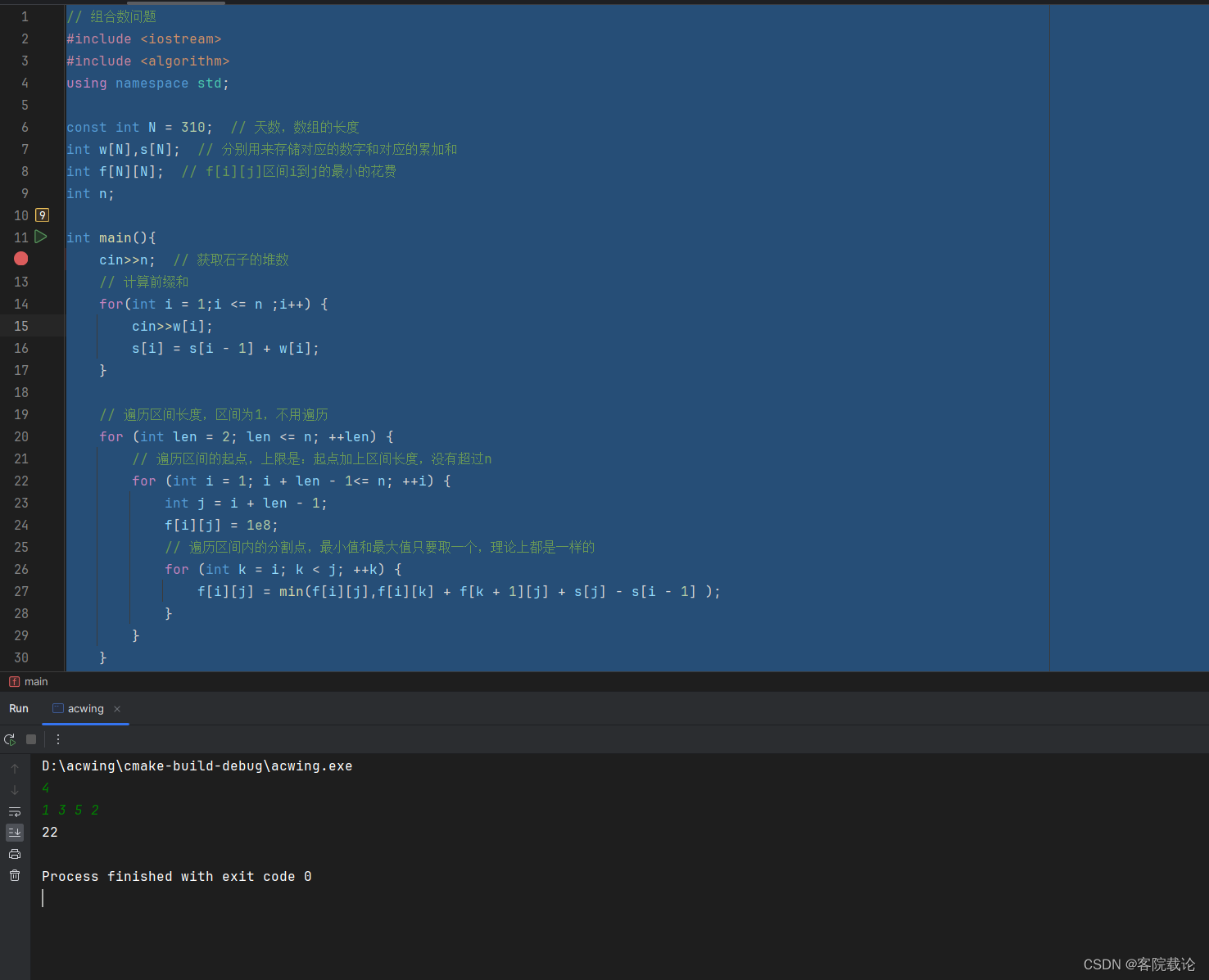
秋招突击——算法——模板题——区间DP——合并石子
文章目录 题目内容思路分析实现代码分析与总结 题目内容 思路分析 基本思路,先是遍历区间长度,然后再是遍历左端点,最后是遍历中间的划分点,将阶乘问题变成n三次方的问题 实现代码 // 组合数问题 #include <iostream> #in…...

数据库——实验12 数据库备份和还原
1. 备份设备的概念和方法 备份设备是指 SQL Server 中存储数据库和事务日志备份副本的载体,备份设备可以被定义成本地的磁盘文件、远程服务器上的磁盘文件、磁带。 在创建备份时,必须选择要将数据写入的备份设备。SQL Server 2005 可以将数据库、事务日…...
Node.js —— 前后端的身份认证 之用 express 实现 JWT 身份认证
JWT的认识 什么是 JWT JWT(英文全称:JSON Web Token)是目前最流行的跨域认证解决方案。 JWT 的工作原理 总结:用户的信息通过 Token 字符串的形式,保存在客户端浏览器中。服务器通过还原 Token 字符串的形式来认证用…...

文旅3d仿真数字人形象为游客提供全方位的便捷服务
在AI人工智能与VR虚拟现实技术的双重驱动下,文旅3D数字代言人正以其独特的魅力,频频亮相于各类文旅场景,为游客带来前所未有的个性化服务体验。他们不仅有趣有品,更能言善道,成为文旅业数字化发展的新亮点。 这些文旅3…...

leetcode算法常用函数
文章目录 字符相关字符串相关数组和集合相关数值相关容器相关 核心关注算法逻辑,其他的常见操作用标准库里函数即可,不用浪费时间。 Java语言作为参考,记录刷题时常用的函数 字符相关 Character.isDigit(); //判断是否为数字Character.isLet…...
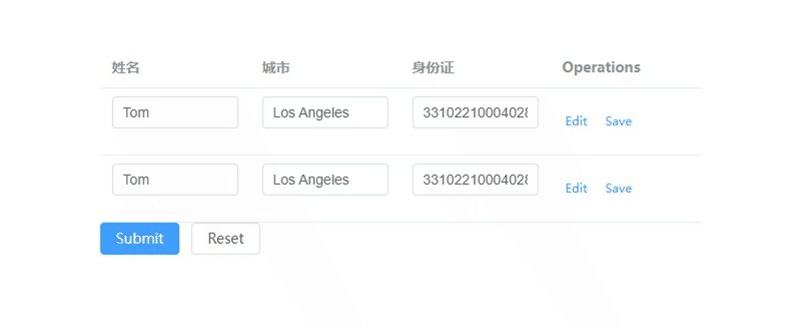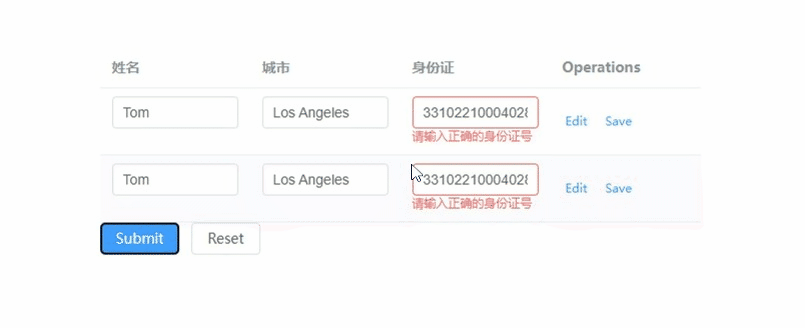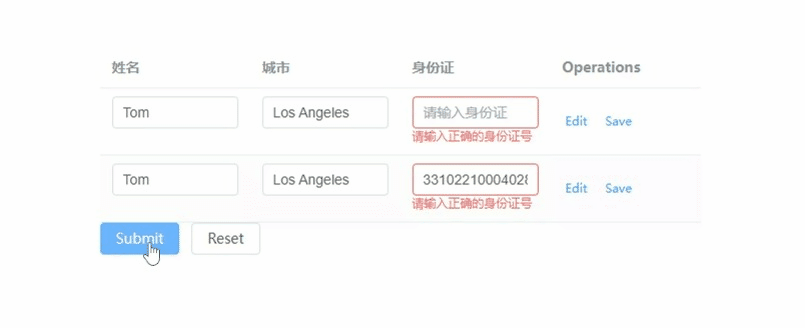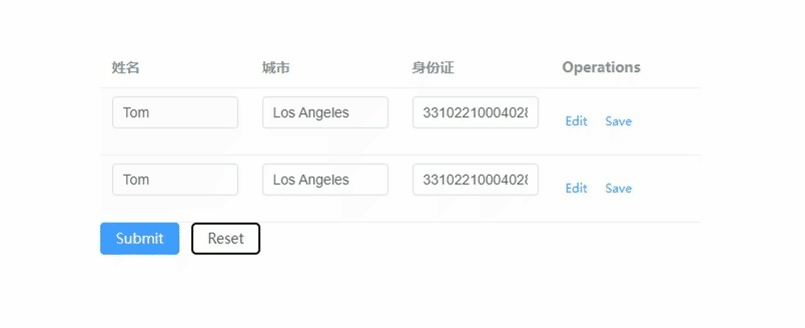
element-plus表格的表单校验如何实现,重点在model和prop
文章目录 vue:3.x element-plus:2.7.3 重点: 1) tableData放到form对象里 2) form-item的prop要写成tableData.序号.属性 <!--table-表单校验--> <template><el-form ref"forms" :model"form"><e…...

WPF密码输入框明文掩码切换
1,效果 2,代码: WPF的PasswordBox不能像Winform中的PasswordBox那样,通过PasswordBox.PasswordChar(char)0显示明文。所以这里使用无外观控件构筑掩码明文切换。 无外观控件遵守Themes/Generic.xaml文件配置. <ResourceDicti…...

SaaS架构详细介绍及一个具体实现的示例
SaaS架构详细介绍 软件即服务(SaaS,Software as a Service)是一种通过互联网交付软件应用程序的模式。 SaaS提供商托管应用程序,并通过网络将其提供给最终用户,用户无需安装和维护软件,只需通过浏览器或其他…...

四川音盛佳云电子商务有限公司正规吗?靠谱吗?
在数字化浪潮席卷全球的今天,电子商务已成为推动经济发展的重要引擎。四川音盛佳云电子商务有限公司,作为抖音电商服务的佼佼者,正以其独特的视角和创新的策略,引领着抖音电商的新潮流,开启着电商服务的新篇章。 四川…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...