【Pytorch】13.搭建完整的CIFAR10模型
项目源码
已上传至githubCIFAR10Model,如果有帮助可以点个star
简介
在前文【Pytorch】10.CIFAR10模型搭建我们学习了用Module来模拟搭建CIFAR10的训练流程
本节将会加入损失函数,梯度下降,TensorBoard来完整搭建一个训练的模型
基本步骤
搭建神经网络最主要的流程是
- 导入数据集(包括训练集和测试集)
- 创建
DataLoader - 创建自定义的神经网络
- 选择损失函数与梯度下降算法
- 进行n轮训练
- n轮训练完成后通过测试集进行验证
- 引入
TensorBoard进行可视化 - 保存每轮训练好的模型
接下来将逐步拆解这每一个步骤
1.导入数据集
因为我们本文是要训练CIFAR10的模型,所以我们导入CIFAR10的数据集
# 1.创建训练数据集
train_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=False, download=True,transform=torchvision.transforms.ToTensor())
# 记录数据集大小
train_size = len(train_dataset)
test_size = len(test_dataset)
分别导入训练集与测试集,并且分别记录训练集与测试集的大小
对参数的解释可以看【Pytorch】4.torchvision.datasets的使用这篇文章
2.创建DataLoader
DataLoader主要定义了如何在数据集中取数据的规则,具体讲解可以看【Pytorch】5.DataLoder的使用
# 2.创建dataloader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=True)
3.创建自定义的神经网络
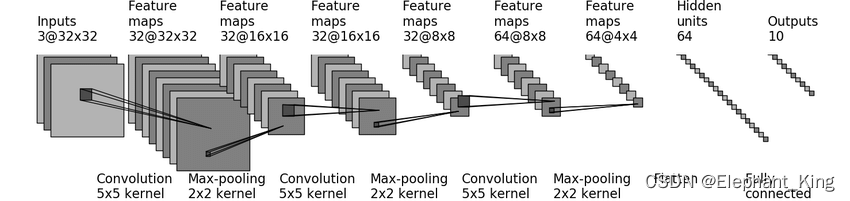
我们可以在网上搜到CIFAR10的网络模型,通过网络模型来搭建网络,具体可以看【Pytorch】10.CIFAR10模型搭建
import torch
from torch import nnclass CIFAR10Model(nn.Module):def __init__(self):super(CIFAR10Model, self).__init__()self.conv1 = nn.Conv2d(3, 32, 5, padding=2)self.maxpool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(32, 32, 5, padding=2)self.maxpool2 = nn.MaxPool2d(2, 2)self.conv3 = nn.Conv2d(32, 64, 5, padding=2)self.maxpool3 = nn.MaxPool2d(2, 2)self.flatten = nn.Flatten()self.fc1 = nn.Linear(1024, 64)self.fc2 = nn.Linear(64, 10)def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.fc1(x)x = self.fc2(x)return xif __name__ == '__main__':model = CIFAR10Model()input_test = torch.ones((64, 3, 32, 32))output_test = model(input_test)print(output_test.shape)
这里我们新创建了一个model.py用于专门存储网络结构,这样在我们的训练文件中,可以通过
from model import *# 3.创建神经网络
model = CIFAR10Model()
来导入我们自定义的神经网络
4.选择损失函数和梯度下降的方法
我们选择了交叉熵损失函数与SGD的梯度下降算法,具体讲解可以看【Pytorch】11.损失函数与梯度下降
# 4.设置损失函数与梯度下降算法
loss_fn = nn.CrossEntropyLoss()learn_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
5.开始进行训练
首先将模型设置为训练模式
model.train()
具体的训练流程分为以下几部
- 从DataLoader中获取图片以及对应的编号
- 将图片传入神经网络并获取输出
- 将优化器清零
- 计算损失函数
- 进行梯度下降
- 调用优化器进行更新
for data in train_loader:# 训练基本流程inputs, labels = dataoutputs = model(inputs)optimizer.zero_grad()loss = loss_fn(outputs, labels)loss.backward()optimizer.step()
在基础训练的基础上,还安排了每进行100次训练就将训练数据print出来,并且写入tensorboard
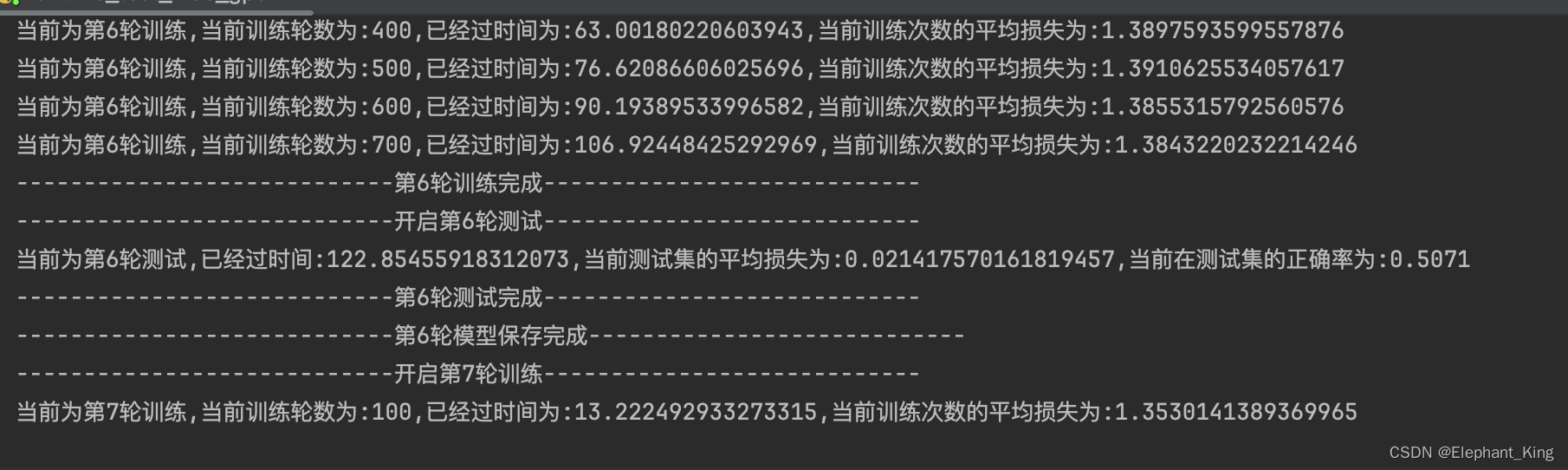
# 第i轮训练次数加一pre_train_step += 1pre_train_loss += loss.item()total_train_step += 1# 每100次输出一下if pre_train_step % 100 == 0:end_train_time = time.time()print(f'当前为第{i+1}轮训练,当前训练轮数为:{pre_train_step},已经过时间为:{end_train_time-start_time},当前训练次数的平均损失为:{pre_train_loss / pre_train_step}')# 添加可视化writer.add_scalar('train_loss', pre_train_loss / pre_train_step, total_train_step)print(f"----------------------------第{i + 1}轮训练完成----------------------------")
6.测试集验证
首先将模型设置为测试集模式
model.eval()
首先通过with关键字来创建一个没有梯度的上下文
验证方法与训练集类似,但是没有计算梯度与更新优化器的步骤
with torch.no_grad():for data in test_loader:# 测试集流程inputs, labels = dataoutputs = model(inputs)loss = loss_fn(outputs, labels)
然后通过torch.argmax用于计算所有标签的最大值
- 参数为1时代表横向判断
- 参数为0的代表纵向判断
计算当前模型在训练集中的正确次数
pre_accuracy += outputs.argmax(1).eq(labels).sum().item()
7.引入TensorBoard进行可视化
我们主要是通过Summary中的add_scalar来建立可视化函数来进行可视化的,具体可以看【Pytorch】2.TensorBoard的运用
# 创建TensorBoard
writer = SummaryWriter('./CIFAR10_logs')# 在训练集中,输出每一百次训练的损失函数平均值# 每100次输出一下if pre_train_step % 100 == 0:end_train_time = time.time()print(f'当前为第{i+1}轮训练,当前训练轮数为:{pre_train_step},已经过时间为:{end_train_time-start_time},当前训练次数的平均损失为:{pre_train_loss / pre_train_step}')# 添加可视化writer.add_scalar('train_loss', pre_train_loss / pre_train_step, total_train_step)# 在测试集中,输出模型在测试集中的正确率
pre_accuracy += outputs.argmax(1).eq(labels).sum().item()writer.add_scalar('test_accuracy', pre_accuracy / test_size, i)8.保存模型
具体可以看【Pytorch】12.网络模型的加载、修改与保存
# 保存每轮的训练模型torch.save(CIFAR10Model, f'./CIFAR10TrainModel{i}.pth')
完整代码
import time
import torch
import torchvision.transforms
from torch.utils.tensorboard import SummaryWriterfrom model import *# 1.创建训练数据集
train_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=False, download=True,transform=torchvision.transforms.ToTensor())
# 记录数据集大小
train_size = len(train_dataset)
test_size = len(test_dataset)# 2.创建dataloader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=True)# 3.创建神经网络
model = CIFAR10Model()# 4.设置损失函数与梯度下降算法
loss_fn = nn.CrossEntropyLoss()learn_rate = 0.0001
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)# 训练轮数
total_train_step = 0
total_test_step = 0# 训练轮数
epoch = 20# 创建TensorBoard
writer = SummaryWriter('./CIFAR10_logs')
# 5.开始训练
for i in range(epoch):# 将模型设置为训练模式print(f"----------------------------开启第{i+1}轮训练----------------------------")model.train()# 第i轮训练的次数pre_train_step = 0# 第i轮训练的总损失pre_train_loss = 0# 第i轮训练的起始时间start_time = time.time()for data in train_loader:# 训练基本流程inputs, labels = dataoutputs = model(inputs)optimizer.zero_grad()loss = loss_fn(outputs, labels)loss.backward()optimizer.step()# 第i轮训练次数加一pre_train_step += 1pre_train_loss += loss.item()total_train_step += 1# 每100次输出一下if pre_train_step % 100 == 0:end_train_time = time.time()print(f'当前为第{i+1}轮训练,当前训练轮数为:{pre_train_step},已经过时间为:{end_train_time-start_time},当前训练次数的平均损失为:{pre_train_loss / pre_train_step}')# 添加可视化writer.add_scalar('train_loss', pre_train_loss / pre_train_step, total_train_step)print(f"----------------------------第{i + 1}轮训练完成----------------------------")# 设置为测试模式model.eval()# 第i轮训练集的总损失pre_test_loss = 0# 第i轮训练集的总正确次数pre_accuracy = 0print(f"----------------------------开启第{i + 1}轮测试----------------------------")# 配置没有梯度下降的环境with torch.no_grad():for data in test_loader:# 测试集流程inputs, labels = dataoutputs = model(inputs)loss = loss_fn(outputs, labels)# 定义参数pre_test_loss += loss.item()# 记录训练集的总正确率# argmax(1)代表横向判断,argmax(0)代表纵向判断pre_accuracy += outputs.argmax(1).eq(labels).sum().item()# 记录测试集运行完后的事件end_test_time = time.time()print(f'当前为第{i + 1}轮测试,已经过时间:{end_test_time - start_time},当前测试集的平均损失为:{pre_test_loss / test_size},当前在测试集的正确率为:{pre_accuracy / test_size}')writer.add_scalar('test_accuracy', pre_accuracy / test_size, i)print(f"----------------------------第{i + 1}轮测试完成----------------------------")# 保存每轮的训练模型torch.save(CIFAR10Model, f'./CIFAR10TrainModel{i}.pth')print(f"----------------------------第{i + 1}轮模型保存完成----------------------------")writer.close()训练效果
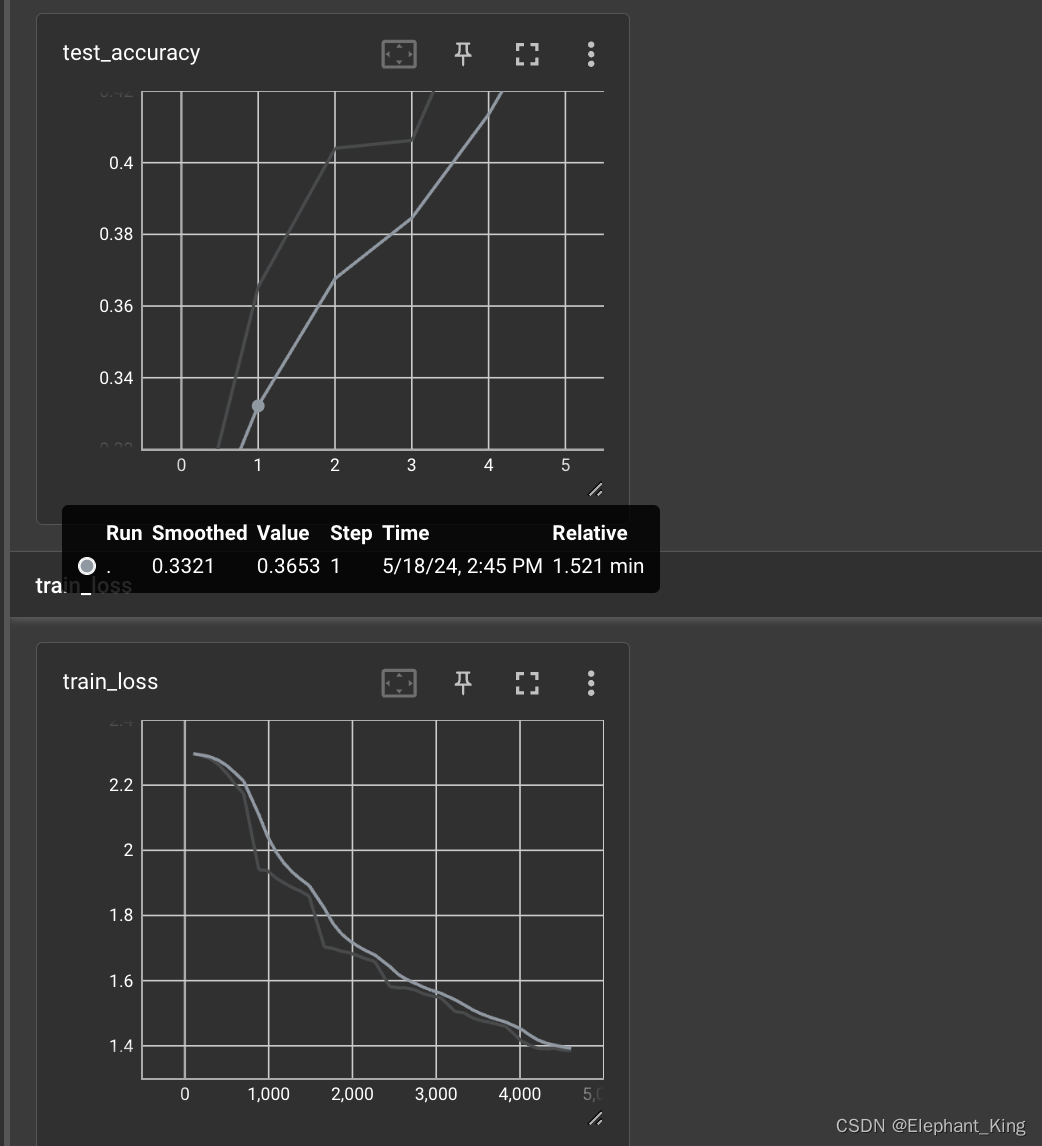
相关文章:
【Pytorch】13.搭建完整的CIFAR10模型
项目源码 已上传至githubCIFAR10Model,如果有帮助可以点个star 简介 在前文【Pytorch】10.CIFAR10模型搭建我们学习了用Module来模拟搭建CIFAR10的训练流程 本节将会加入损失函数,梯度下降,TensorBoard来完整搭建一个训练的模型 基本步骤 搭建…...

护目镜佩戴自动识别预警摄像机
护目镜佩戴自动识别预警摄像机是一种智能监测设备,专门用于佩戴护目镜的工人进行作业时,能够自动识别有潜在风险的场景,并及时发出预警信号。该摄像机配备人脸识别和智能预警系统,可以检测危险情况并为工人提供实时安全保护&#…...

keep-alive的使用
Vue中的<keep-alive>组件是前端开发中的一个宝藏功能,它如同时光胶囊般保留组件的状态,让组件在切换时仿佛按下暂停键,再次回来时还能继续播放,极大地优化了用户体验和性能。🚀✨ 作用 状态保留:当包…...

【Linux】中的常见的重要指令(中)
目录 一、man指令 二、cp指令 三、cat指令 四、mv指令 五、more指令 六、less指令 七、head指令 八、tail指令 一、man指令 Linux的命令有很多参数,我们不可能全记住,我们可以通过查看联机手册获取帮助。访问Linux手册页的命令是 man 语法: m…...

营收净利双降、股东减持,大降价也救不了良品铺子
号称“高端零食第一股”的良品铺子(603719.SH),正遭遇部分股东的“用脚投票”。 5月17日晚间,良品铺子连发两份减持公告,其控股股东宁波汉意创业投资合伙企业、持股5%以上股东达永有限公司,两者均计划减持。 其中,宁…...

【设计模式】设计模式的分类
通常设计模式的分类有创建型、行为型和结构型。 创建型 常用的有:单例模式、工厂模式(工厂方法和抽象工厂)、建造者模式。 不常用的有:原型模式。 创建型模式涉及到将对象实例化,这类模式都提供一个方法,将…...

TCP/UDP的连接机制
TCP/UDP的连接机制 TCP的连接机制 TCP(Transmission Control Protocol)是一种面向连接的协议,提供可靠的、按顺序的数据传输服务。TCP的连接机制包括连接建立、数据传输和连接终止。 1. 连接建立(三次握手) TCP通过…...

供应链金融模式学习资料
目录 产生背景 供应链金融的诞生 供应链金额的六大特征...

代码随想录-算法训练营day50【动态规划12:最佳买卖股票时机含冷冻期、买卖股票的最佳时机含手续费、股票问题总结】
代码随想录-035期-算法训练营【博客笔记汇总表】-CSDN博客 第九章 动态规划part12● 309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费 ●总结309.最佳买卖股票时机含冷冻期 本题加了一个冷冻期,状态就多了,有点难度,大家要把各个状态分清,思路才能清晰…...
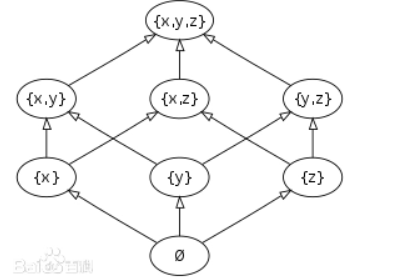
Dilworth 定理
这是一个关于偏序集的定理,事实上它也可以扩展到图论,dp等中,是一个很有意思的东西 偏序集 偏序集是由集合 S S S以及其上的一个偏序关系 R R R定义的,记为 ( S , R ) (S,R) (S,R) 偏序关系: 对于一个二元关系 R ⊂…...
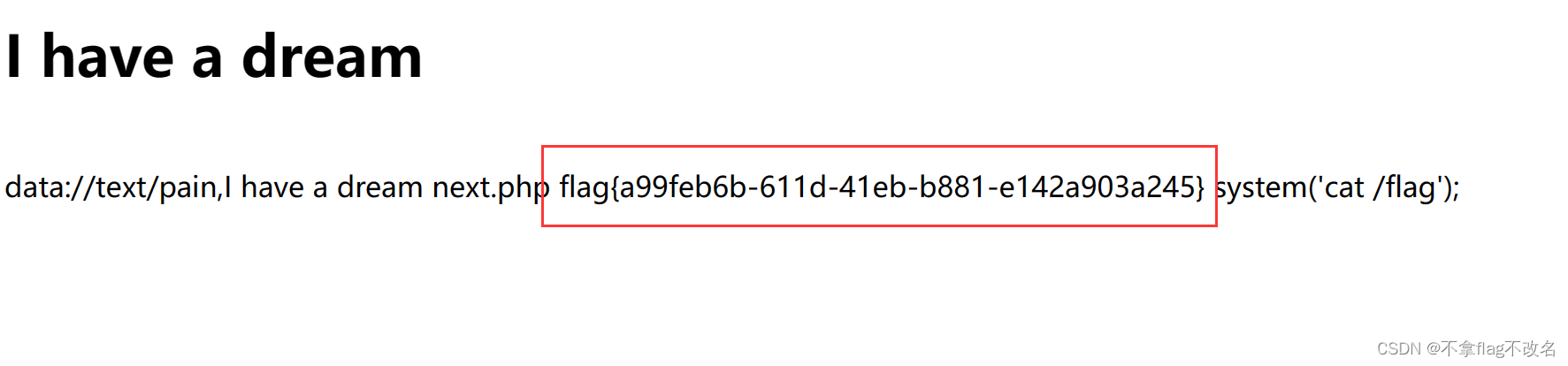
BUUCTF---web---[BJDCTF2020]ZJCTF,不过如此
1、点开连接,页面出现了提示 传入一个参数text,里面的内容要包括I have a dream。 构造:?/textI have a dream。发现页面没有显示。这里推测可能得使用伪协议 在文件包含那一行,我们看到了next.php的提示,我们尝试读取…...

力扣刷题---2206. 将数组划分成相等数对【简单】
题目描述🍗 给你一个整数数组 nums ,它包含 2 * n 个整数。 你需要将 nums 划分成 n 个数对,满足: 每个元素 只属于一个 数对。 同一数对中的元素 相等 。 如果可以将 nums 划分成 n 个数对,请你返回 true …...

2461. 长度为 K 子数组中的最大和(c++)
给你一个整数数组 nums 和一个整数 k 。请你从 nums 中满足下述条件的全部子数组中找出最大子数组和: 子数组的长度是 k,且子数组中的所有元素 各不相同 。 返回满足题面要求的最大子数组和。如果不存在子数组满足这些条件,返回 0 。 子数…...

range for
1. 基于范围的for循环语法 C11标准引入了基于范围的for循环特性,该特性隐藏了迭代器 的初始化和更新过程,让程序员只需要关心遍历对象本身,其语法也 比传统for循环简洁很多: for ( range_declaration : range_expression ) {loo…...

leetcode230 二叉搜索树中第K小的元素
题目 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。 示例 输入:root [5,3,6,2,4,null,null,1], k 3 输出:3 解析 这道题应该是能做出…...
)
.Net Core学习笔记 框架特性(注入、配置)
注:直接学习的.Net Core 6,此版本有没有startup.cs相关的内容 项目Program.cs文件中 是定义项目加载 启动的地方 //通过builder对项目进行配置、服务的加载 var builder WebApplication.CreateBuilder(args); builder.Services.AddControllers();//将…...

利用AI技术做电商网赚,这些百万级赛道流量,你还不知道?!
大家好,我是向阳 AI技术的飞速扩展已经势不可挡,不管你承不承认,AI 已经毫无争议的在互联网中占有一席之地了 无论你是做内容产业的,还是做电商的,你现在都躲不开 AI。 现在互联网行业的竞争就是这么残酷 互联网行业…...

leetcode-560 和为k的数组
一、题目描述 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 注意:nums中的元素可为负数 输入:nums [1,1,1], k 2 输出:2输入:num…...

Spring Boot实战指南:从入门到企业级应用构建
目录 一、引言 二、快速入门 1. 使用Spring Initializr创建项目 三、Spring Boot基础概念与自动配置 1. 理解SpringBootApplication注解 2. 自动配置原理 3. 查看自动配置报告 四、Spring Boot核心特性及实战 1. 外部化配置 2. Actuator端点 3. 集成第三方库 五、Sp…...
OneAPI接入本地大模型+FastGPT调用本地大模型
将Ollama下载的本地大模型配置到OneAPI中,并通过FastGPT调用本地大模型完成对话。 OneAPI配置 新建令牌 新建渠道 FastGPT配置 配置docker-compose 配置令牌和OneAPI部署地址 配置config.json 配置调用的渠道名称和大模型名称 {"systemEnv": {&qu…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...