BERT ner 微调参数的选择
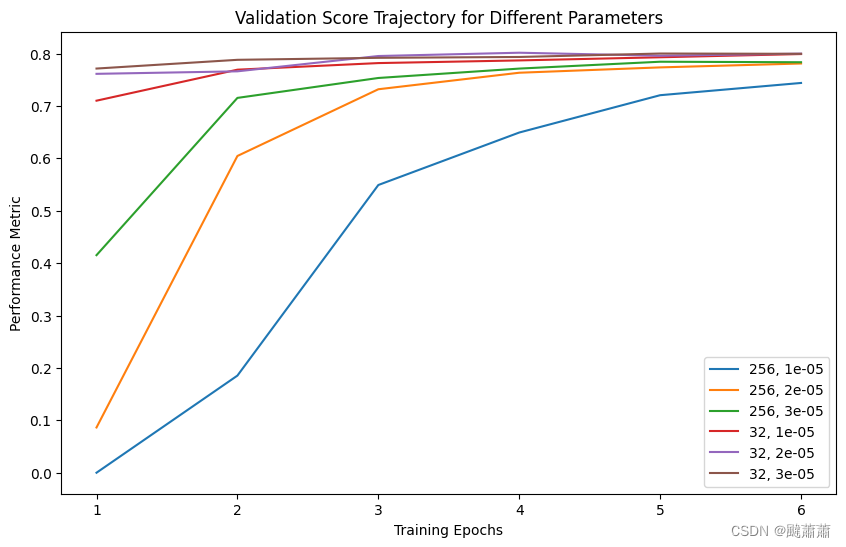
针对批大小和学习率的组合进行收敛速度测试,结论:
- 相同轮数的条件下,batchsize-32 相比 batchsize-256 的迭代步数越多,收敛更快
- 批越大的话,学习率可以相对设得大一点
画图代码(deepseek生成):
import matplotlib.pyplot as pltdic = {(256, 1e-5): [0, 0.185357, 0.549124, 0.649283, 0.720528, 0.743900],(256, 2e-5): [0.086368, 0.604535, 0.731870, 0.763409, 0.773608, 0.781042],(256, 3e-5): [0.415224, 0.715375, 0.753391, 0.771326, 0.784421, 0.783432],(32, 1e-5): [0.710058, 0.769245, 0.781832, 0.786909, 0.792920, 0.799076],(32, 2e-5): [0.761296, 0.766089, 0.795317, 0.801602, 0.795861, 0.799864],(32, 3e-5): [0.771385, 0.788055, 0.791863, 0.793491, 0.800057, 0.799527],
}# 提取参数和对应的训练轨迹
params = list(dic.keys())
trajectories = list(dic.values())# 绘制折线图
plt.figure(figsize=(10, 6))
for param, trajectory in zip(params, trajectories):plt.plot(range(1, len(trajectory) + 1), trajectory, label=f'{param[0]}, {param[1]}')# 设置图表标题和坐标轴标签
plt.title('Validation Score Trajectory for Different Parameters')
plt.xlabel('Training Epochs')
plt.ylabel('Performance Metric')# 添加图例
plt.legend()# 显示图表
plt.show()
附录
微调命令
!python ner_finetune.py \
--gpu_device 0 \
--train_batch_size 32 \
--valid_batch_size 32 \
--epochs 6 \
--learning_rate 3e-5 \
--train_file data/cluener2020/train.json \
--valid_file data/cluener2020/dev.json \
--allow_label "{'name': 'PER', 'organization': 'ORG', 'address': 'LOC', 'company': 'ORG', 'government': 'ORG'}" \
--pretrained_model models/bert-base-chinese \
--tokenizer models/bert-base-chinese \
--save_model_dir models/local/bert_tune_5
日志
Namespace(allow_label={'name': 'PER', 'organization': 'ORG', 'address': 'LOC', 'company': 'ORG', 'government': 'ORG'}, epochs=6, gpu_device='0', learning_rate=3e-05, max_grad_norm=10, max_len=128, pretrained_model='models/bert-base-chinese', save_model_dir='models/local/bert_tune_5', tokenizer='models/bert-base-chinese', train_batch_size=32, train_file='data/cluener2020/train.json', valid_batch_size=32, valid_file='data/cluener2020/dev.json')
CUDA is available!
Number of CUDA devices: 1
Device name: NVIDIA GeForce RTX 2080 Ti
Device capability: (7, 5)
标签映射: {'O': 0, 'B-PER': 1, 'B-ORG': 2, 'B-LOC': 3, 'I-PER': 4, 'I-ORG': 5, 'I-LOC': 6}
加载数据集:data/cluener2020/train.json0%| | 0/10748 [00:00<?, ?it/s]2024-05-21 14:05:00.121060: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-05-21 14:05:00.172448: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-05-21 14:05:00.914503: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
100%|███████████████████████████████████| 10748/10748 [00:06<00:00, 1667.09it/s]
100%|█████████████████████████████████████| 1343/1343 [00:00<00:00, 2244.82it/s]
TRAIN Dataset: 7824
VALID Dataset: 971
加载模型:models/bert-base-chinese
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Some weights of the model checkpoint at models/bert-base-chinese were not used when initializing BertForTokenClassification: ['cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForTokenClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForTokenClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForTokenClassification were not initialized from the model checkpoint at models/bert-base-chinese and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Training epoch: 1
Training loss per 100 training steps: 2.108242988586426
Training loss per 100 training steps: 0.16535191606767108
Training loss per 100 training steps: 0.10506394136678521
Training loss epoch: 0.09411744458638892
Training accuracy epoch: 0.9225966380147197
Validation loss per 100 evaluation steps: 0.05695410072803497
Validation Loss: 0.03870751528489974
Validation Accuracy: 0.9578078217665675precision recall f1-score support
LOC 0.544872 0.683646 0.606421 373.0
ORG 0.750225 0.841734 0.793349 992.0
PER 0.806452 0.913978 0.856855 465.0
micro avg 0.718691 0.827869 0.769426 1830.0
macro avg 0.700516 0.813119 0.752208 1830.0
weighted avg 0.722656 0.827869 0.771385 1830.0
Training epoch: 2
Training loss per 100 training steps: 0.030774801969528198
Training loss per 100 training steps: 0.03080757723033133
Training loss per 100 training steps: 0.03123850032538917
Training loss epoch: 0.03104725396450685
Training accuracy epoch: 0.965836879311368
Validation loss per 100 evaluation steps: 0.07264477759599686
Validation Loss: 0.03662088588480988
Validation Accuracy: 0.961701479064846precision recall f1-score support
LOC 0.606635 0.686327 0.644025 373.0
ORG 0.776735 0.834677 0.804665 992.0
PER 0.821497 0.920430 0.868154 465.0
micro avg 0.752613 0.826230 0.787705 1830.0
macro avg 0.734956 0.813812 0.772281 1830.0
weighted avg 0.753439 0.826230 0.788055 1830.0
Training epoch: 3
Training loss per 100 training steps: 0.01707942970097065
Training loss per 100 training steps: 0.020070969108676555
Training loss per 100 training steps: 0.0214405001942717
Training loss epoch: 0.021760025719294744
Training accuracy epoch: 0.9760199331084162
Validation loss per 100 evaluation steps: 0.04943108558654785
Validation Loss: 0.03711987908689245
Validation Accuracy: 0.9608263101353024precision recall f1-score support
LOC 0.596847 0.710456 0.648715 373.0
ORG 0.776328 0.839718 0.806780 992.0
PER 0.855967 0.894624 0.874869 465.0
micro avg 0.755866 0.827322 0.789982 1830.0
macro avg 0.743047 0.814932 0.776788 1830.0
weighted avg 0.759981 0.827322 0.791863 1830.0
Training epoch: 4
Training loss per 100 training steps: 0.014015918597579002
Training loss per 100 training steps: 0.015494177154827826
Training loss per 100 training steps: 0.015997812416015278
Training loss epoch: 0.016311514128607756
Training accuracy epoch: 0.9820175765149567
Validation loss per 100 evaluation steps: 0.04825771600008011
Validation Loss: 0.04313824124514095
Validation Accuracy: 0.9585233633276977precision recall f1-score support
LOC 0.618037 0.624665 0.621333 373.0
ORG 0.794118 0.843750 0.818182 992.0
PER 0.853955 0.905376 0.878914 465.0
micro avg 0.774948 0.814754 0.794353 1830.0
macro avg 0.755370 0.791264 0.772810 1830.0
weighted avg 0.773433 0.814754 0.793491 1830.0
Training epoch: 5
Training loss per 100 training steps: 0.008429908193647861
Training loss per 100 training steps: 0.012711652241057098
Training loss per 100 training steps: 0.012486798004177747
Training loss epoch: 0.012644028145705862
Training accuracy epoch: 0.9862629694070859
Validation loss per 100 evaluation steps: 0.06491336971521378
Validation Loss: 0.049802260893967845
Validation Accuracy: 0.9582402189526026precision recall f1-score support
LOC 0.608899 0.697051 0.650000 373.0
ORG 0.795749 0.867944 0.830280 992.0
PER 0.831643 0.881720 0.855950 465.0
micro avg 0.764735 0.836612 0.799061 1830.0
macro avg 0.745430 0.815572 0.778743 1830.0
weighted avg 0.766785 0.836612 0.800057 1830.0
Training epoch: 6
Training loss per 100 training steps: 0.009717799723148346
Training loss per 100 training steps: 0.008476002312422093
Training loss per 100 training steps: 0.008608183584903456
Training loss epoch: 0.008819052852614194
Training accuracy epoch: 0.9903819524689835
Validation loss per 100 evaluation steps: 0.023518526926636696
Validation Loss: 0.049626993015408516
Validation Accuracy: 0.9602429496287505precision recall f1-score support
LOC 0.614251 0.670241 0.641026 373.0
ORG 0.806482 0.852823 0.829005 992.0
PER 0.848548 0.879570 0.863780 465.0
micro avg 0.776574 0.822404 0.798832 1830.0
macro avg 0.756427 0.800878 0.777937 1830.0
weighted avg 0.777989 0.822404 0.799527 1830.0
相关文章:
BERT ner 微调参数的选择
针对批大小和学习率的组合进行收敛速度测试,结论: 相同轮数的条件下,batchsize-32 相比 batchsize-256 的迭代步数越多,收敛更快批越大的话,学习率可以相对设得大一点 画图代码(deepseek生成)…...

【MySQL精通之路】系统变量-持久化系统变量
MySQL服务器维护用于配置其操作的系统变量。 系统变量可以具有影响整个服务器操作的全局值,也可以具有影响当前会话的会话值,或者两者兼而有之。 许多系统变量是动态的,可以在运行时使用SET语句进行更改,以影响当前服务器实例的…...

fdk-aac将aac格式转为pcm数据
int sampleRate 44100; // 采样率int sampleSizeInBits 16; // 采样位数,通常是16int channels 2; // 通道数,单声道为1,立体声为2FILE *m_fd NULL;FILE *m_fd2 NULL;HANDLE_AACDECODER decoder aacDecoder_Open(TT_MP4_ADTS, 1);if (!…...

【C语言深度解剖】(15):动态内存管理和柔性数组
🤡博客主页:醉竺 🥰本文专栏:《C语言深度解剖》 😻欢迎关注:感谢大家的点赞评论关注,祝您学有所成! ✨✨💜💛想要学习更多C语言深度解剖点击专栏链接查看&…...

力扣每日一题 5/25
题目: 给你一个下标从 0 开始、长度为 n 的整数数组 nums ,以及整数 indexDifference 和整数 valueDifference 。 你的任务是从范围 [0, n - 1] 内找出 2 个满足下述所有条件的下标 i 和 j : abs(i - j) > indexDifference 且abs(nums…...
无线电失控保护(一))
(1)无线电失控保护(一)
文章目录 前言 1 何时触发失控保护 2 将会发生什么 3 接收机配置...
基于51单片机的多功能万年历温度计—可显示农历
基于51单片机的万年历温度计 (仿真+程序+原理图+设计报告) 功能介绍 具体功能: 本设计基于STC89C52(与AT89S52、AT89C52通用,可任选)单片机以及DS1302时钟芯片、DS18B…...

【软件设计师】下午题总结-数据流图、数据库、统一建模语言
下午题总结 1 试题一1.1 结构化语言 2 试题二弱实体增加权限增加实体间联系和联系的类型 3 试题三3.1 UML关系例子 3.2 例子(2016上半年)3.3 设计类分类3.3.1 接口类3.3.2 控制类3.3.3 实体类 3.4 简答题3.4.1 简要说明选择候选类的原则3.4.2 某个类必须…...

CSDN 自动评论互动脚本
声明 该脚本的目的只是为了提升博客创作效率和博主互动效率,希望大家还是要尊重各位博主的劳动成果。 数据库设计 尽量我们要新建一个数据库csdn_article,再在其中建一个数据表article -- csdn_article-- article-- 需要进行自动评论的表格信息...CREATE TABLE `article`…...

Tomcat端口配置
Tomcat是开源免费的服务器,其默认的端口为8080,本文讲述一下如何配置端口。 最后在浏览器中输入localhost:8888即可打开Tomcat界面...

SpringBoot中使用AOP实现日志记录功能
目录 一、SpringBoot框架介绍 二、什么是 AOP 三、日志记录的必要性 四、SpringBoot中如何使用AOP实现日志记录功能 一、SpringBoot框架介绍 SpringBoot是一个开源的Java开发框架,旨在简化基于Spring框架的应用程序的开发。它提供了一套开箱即用的工具…...
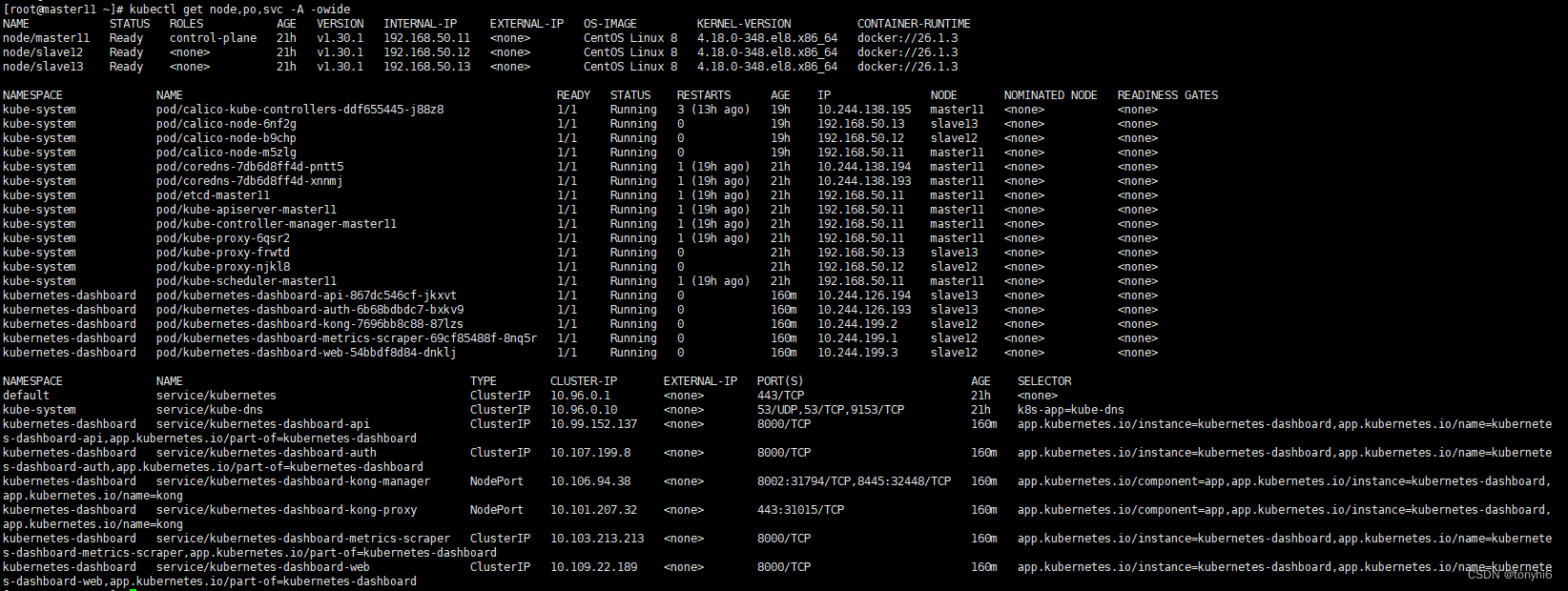
kubernetes(k8s) v1.30.1 helm 集群安装 Dashboard v7.4.0 可视化管理工具 图形化管理工具
本文 紧接上一篇:详细教程 Centos8.5 基于 k8s v1.30.1 部署高可用集群 kubeadm 安装 kubernetes v1.30.1 docker集群搭建 延长证书有效期-CSDN博客 1 Dashboard 从版本 7.0.0 开始,不再支持基于清单的安装。仅支持基于 Helm 的安装. #Helm 下载安装 …...
)
CS144(所有lab解析)
CS144 lab0-CSDN博客 (CS144 2024)Lab Checkpoint 1: stitching substrings into a byte stream (详细解析)-CSDN博客 CS144 Lab2 (2024)超详细解析-CSDN博客 Lab Checkpoint 3: the TCP sender-CSDN博客 CS144 Checkpoint 4: in…...

LeetCode 热题 100 介绍
"LeetCode热题100"通常是指LeetCode上被用户频繁练习和讨论的100道热门题目。这些题目往往对于面试准备和算法学习非常有帮助。 哈希 两数之和 难度:简单链接🔗: 这 字母异位词分组 难度:中等链接🔗&#x…...

Flutter 中的 AnimatedPhysicalModel 小部件:全面指南
Flutter 中的 AnimatedPhysicalModel 小部件:全面指南 Flutter 的 AnimatedPhysicalModel 是一个功能强大的小部件,它允许开发者创建具有物理效果的动画形状变换。这个小部件非常适合需要展示平滑过渡和动态交互的场景,如按钮按下效果、卡片…...

第二十届文博会沙井艺立方分会场启幕!大咖齐打卡!
2024年5月24日-27日,第二十届中国(深圳)国际文化产业博览交易会沙井艺立方分会场活动将在艺立方非遗(文旅)产业园盛大举办。 本届文博会艺立方分会场活动办展特色鲜明,亮彩纷呈,将以“种下梧桐树…...

【Vue】computed 和 methods 的区别
概述 在使用时,computed 当做属性使用,而 methods 则当做方法调用computed 可以具有 getter 和 setter,因此可以赋值,而 methods 不行computed 无法接收多个参数,而 methods 可以computed 具有缓存,而 met…...
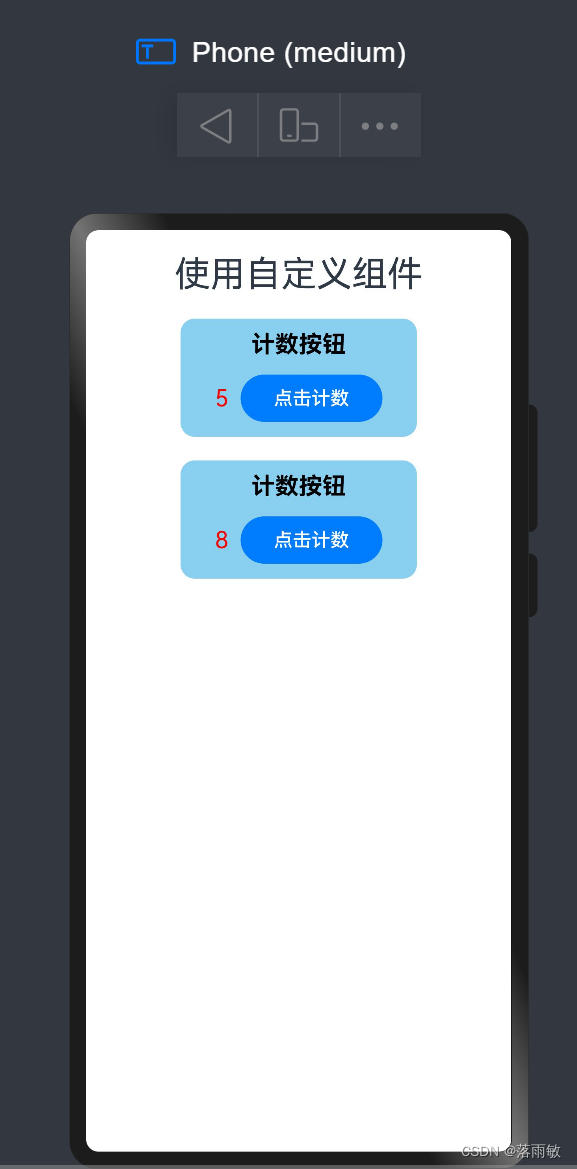
HarmonyOS 鸿蒙应用开发 - 创建自定义组件
开发者定义的称为自定义组件。在进行 UI 界面开发时,通常不是简单的将系统组件进行组合使用,而是需要考虑代码可复用性、业务逻辑与UI分离,后续版本演进等因素。因此,将UI和部分业务逻辑封装成自定义组件是不可或缺的能力。 1、创…...
【Vue3】封装axios请求(cli和vite)
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 Vue 【Vue3】env环境变量的配置和使用(区分cli和vite) 文章目录 Vue前言一、常见用法二、vue3cli封装接口1..env配置2..dev(开…...

Java8 Optional常用方法使用场景
前言: Optional 是 Java 8 的新特性,专治空指针异常(NullPointerException, 简称 NPE)问题,它是一个容器类,里面只存储一个元素(这点不同于 Conllection)。 为方便用户通过 Lambda 表…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

基于窗口比较器与晶体管逻辑的可编程非线性电压指示器设计
1. 项目概述:打造一个可编程的“移动光点”电压指示器在电子制作和仪器仪表领域,我们经常需要一个直观的电压指示器。经典的LM3914点/条图显示驱动芯片大家都很熟悉,它能把一个模拟电压信号转换成10个LED的点亮状态,形成移动的光点…...

XZ9971,60V,5A,NMOS 封装:SOT223
封装:SOT223类型:NVDS:60V VGS: 20V ID:5ARDS(ON):10V <50mΩRDS(ON):4.5V <60mΩ型号: XZ9971 封装:SOT223类型&…...

量子机器学习多编码框架MEDQ:提升模型泛化能力与参数效率
1. 项目概述:为什么量子机器学习需要“多编码”?量子机器学习(QML)这几年火得不行,但真正上手做过的人都知道,它有个挺让人头疼的“怪病”:模型在某些数据集上表现神勇,换到另一个看…...