Pandas高效数据清洗与转换技巧指南【数据预处理】
三、数据处理
1.合并数据(join、merge、concat函数,append函数)

Concat()函数使用
1.concat操作可以将两个pandas表在垂直方向上进行粘合或者堆叠。
join属性为outer,或默认时,返回列名并集,如:
df3 = pd.concat([df1,df2])
join属性为inner时,返回列名交集,如:
df4 = pd.concat([df1,df2],join=“inner”)
2.concat操作将两个pandas表在水平方向进行粘合或者堆叠。
df3 = pd.concat([df1,df2],axis = 1) #默认outer
join()函数使用
可用于简单的横向堆叠,直接用index来连接,语法格式如下:
pandas.DataFrame.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
当横向堆叠的两个表的列名有相同时,需设置lsuffix或rsuffix参数以示区别,否则会报错。
_append()函数使用
_append方法也可用于简单的纵向堆叠,这对列名完全相同的两张表特别有用,列名不同则会被空值替代。
和concat的axis = 0 的效果是一样的
pandas.DataFrame._append(self, other, ignore_index=False, verify_integrity=False)
Merge()函数使用
merge函数可以按照指定的列进行合并
实现sql数据库类似的各种join(连接)操作,例如内连接、外连接、左右连接等。
若没有指定列名,则自动寻找两个对象中同名的列进行连接运算,类似于数据库中的自然连接运算,这里类似于df_merge(df1,df2,on=‘key’,how=‘inner’)
2.清洗数据方法(重复值、缺失值判断和填充方法、异常值处理和判断方法)
重复数据处理
1.记录重复
drop_duplicates的去重方法。该方法只对DataFrame或者Series类型有效。这种方法不会改变数据原始排列,并且兼具代码简洁和运行稳定的特点。
该方法不仅支持单一特征的数据去重,还能够依据DataFrame的其中一个或者几个特征进行去重操作。 pandas.DataFrame(Series).drop_duplicates(self, subset=None, keep='first', inplace=False)
2. 特征重复
特征重复 : 存在一个或多个特征的名称不同,但是数据完全相同。
要去除特征之间的的重复,可以利用特征间的相似度将两个相似度为1的特征去掉一个。去除特征重复的方法主要有两个:corr()方法, DataFrame.equals()方法
在pandas中相似度的计算方法为corr,使用该方法计算相似度时,默认为“pearson”法 ,可以通过“method”参数调节,目前还支持“spearman”法和“kendall”法。
但是通过相似度矩阵去重存在一个弊端,该方法只能对数值型重复特征去重,类别型特征之间无法通过计算相似系数来衡量相似度。
除了使用相似度矩阵进行特征去重之外,可以通过DataFrame.equals的方法进行特征去重。
缺失值处理方法
利用isnull或notnull找到缺失值
缺失值:在Pandas中的缺失值有四种:np.nan (Not a Number) 、NA(not available)、 None 和 pd.NaT(时间格式的空值,注意大小写不能错)
空值:空值在Pandas中指的是空字符串"";
最后一类是导入的Excel等文件中,原本用于表示缺失值的字符“-”、“?”等。
isnull()/isna():对于缺失值,返回True;对于⾮缺失值,返回False。
Notnull/notna():对于⾮缺失值,返回True;对于缺失值,返回False。
any():⼀个序列中有⼀个True,则返回True,否则返回False。
sum():对序列进行求和计算。
1.删除法(dropna)
删除法分为删除观测记录和删除特征两种,它属于利用减少样本量来换取信息完整度的一种方法,是一种最简单的缺失值处理方法。
pandas中提供了简便的删除缺失值的方法dropna,该方法既可以删除观测记录,亦可以删除特征。
pandas.DataFrame.dropna(self, axis=0, how='any', thresh=None, subset=None, inplace=False)
2.替换法
替换法是指用一个特定的值替换缺失值。
特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的。
缺失值所在特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来代替缺失值。
缺失值所在特征为类别型时,则选择使用众数来替换缺失值。
pandas库中提供了缺失值替换的方法名为fillna,其基本语法如下。 pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
3.插值法
常用的插值法有线性插值、多项式插值和样条插值等:
线性插值是一种较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值。
多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式,再利用这个多项式求解缺失值,常见的多项式插值法有拉格朗日插值和牛顿插值等。
样条插值是以可变样条来作出一条经过一系列点的光滑曲线的插值方法,插值样条由一些多项式组成,每一个多项式都是由相邻两个数据点决定,这样可以保证两个相邻多项式及其导数在连接处连续。
线性插值
import numpy as np
from scipy.interpolate import interp1d
x=np.array([1,2,3,4,5,8,9,10])
y1=np.array([2,8,18,32,50,80,100,120])
linear_interp=interp1d(x,y1,kind='linear')
print(linear_interp([6,7]))多项式插值
from scipy.interpolate import lagrange
large_ins_value=lagrange(x,y1)
print(large_ins_value([6,7]))样条插值
spline_value=interp1d(x,y1,kind='cubic')
print(spline_value([6,7]))异常值检测方法
1. 3σ原则
数据的数值分布几乎全部集中在区间(μ-3σ,μ+3σ)内,超出这个范围的数据仅占不到0.3%。故根据小概率原理,可以认为超出3σ的部分数据为异常数据。
2.箱线图分析
箱型图提供了识别异常值的一个标准,即异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。
QL称为下四分位数,表示全部观察值中有四分之一的数据取值比它小。
QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大。
IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。
3.标准化数据常见方法(离差化,标准差标准化)
1. 离差标准化公式(Min-max归一化)

2. 标准差标准化的公式及特点(Z-Score标准化)


离差标准化方法简单,便于理解,标准化后的数据限定在[0,1]区间内。
标准差标准化受到数据分布的影响较小。
归一化和标准化的区别和联系区别:
归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[a,b]区间内,仅由变量的极值决定,因此区间放缩法是归一化的一种。
标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。
归一化会改变数据的原始距离,分布,信息;标准化一般不会。
联系: 它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
4.数据变换方法(离散化连续型数据)
1.哑变量处理
Python中可以利用pandas库中的get_dummies函数对类别型特征进行哑变量处理。 pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
2.离散化
连续特征的离散化就是在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。
因此离散化涉及两个子任务,即确定分类数以及如何将连续型数据映射到这些类别型数据上。
1. 等宽法
将数据的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定或者用户指定,与制作频率分布表类似。pandas提供了cut函数,可以进行连续型数据的等宽离散化,其基础语法格式如下。
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
2. 等频法
cut函数虽然不能够直接实现等频离散化,但是可以通过定义将相同数量的记录放进每个区间。
等频法离散化的方法相比较于等宽法离散化而言,避免了类分布不均匀的问题,但同时却也有可能将数值非常接近的两个值分到不同的区间以满足每个区间中固定的数据个数。
3. 基于聚类分析的方法
一维聚类的方法包括两个步骤:
将连续型数据用聚类算法(如K-Means算法等)进行聚类。
处理聚类得到的簇,将合并到一个簇的连续型数据做同一标记。
聚类分析的离散化方法需要用户指定簇的个数,用来决定产生的区间数
相关文章:
Pandas高效数据清洗与转换技巧指南【数据预处理】
三、数据处理 1.合并数据(join、merge、concat函数,append函数) Concat()函数使用 1.concat操作可以将两个pandas表在垂直方向上进行粘合或者堆叠。 join属性为outer,或默认时,返回列名并集,如ÿ…...

kafka防止消息丢失配置
无消息丢失最佳实践配置: 不要使用 producer.send(msg),而要使用 producer.send(msg, callback) API。设置 acks all。是 Producer 参数。设置成 all,表明所有副本 Broker 都要接收到消息,g该消息才算是“已提交”。设置 retrie…...

Socket CAN中ctrlmode有哪些?
在Linux中,socketcan 的 ctrlmode 是一个用于配置CAN设备控制模式的标志字段。该字段的值由一组标志位组成,这些标志位控制CAN设备的各种操作模式。以下是一些常见的 ctrlmode 标志及其含义: CAN_CTRLMODE_LOOPBACK: 描述:启用回环模式。作用:设备在发送帧的同时会接收它…...
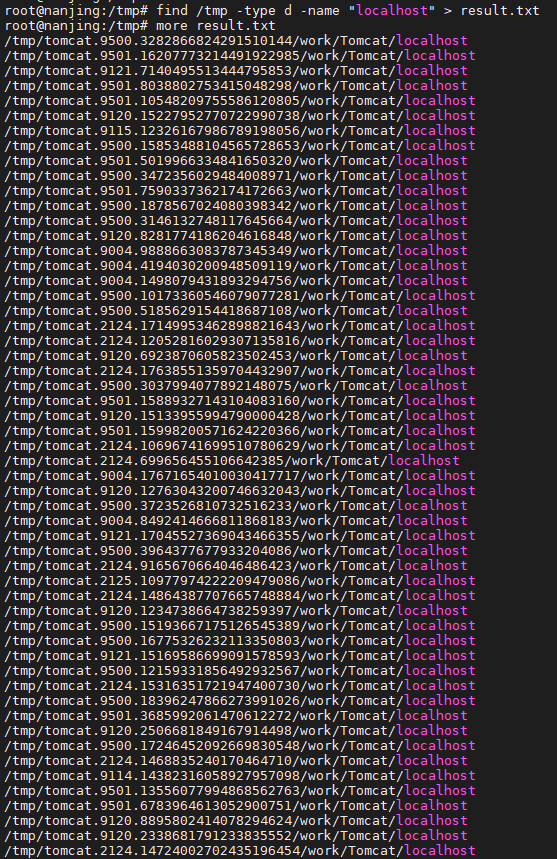
find 几招在 Linux 中高效地查找目录
1. 介绍 在 Linux 操作系统中,查找目录是一项常见的任务。无论是系统管理员还是普通用户,都可能需要查找特定的目录以执行各种操作,如导航文件系统、备份数据、删除文件等。Linux 提供了多种命令和工具来帮助我们在文件系统中快速找到目标目…...
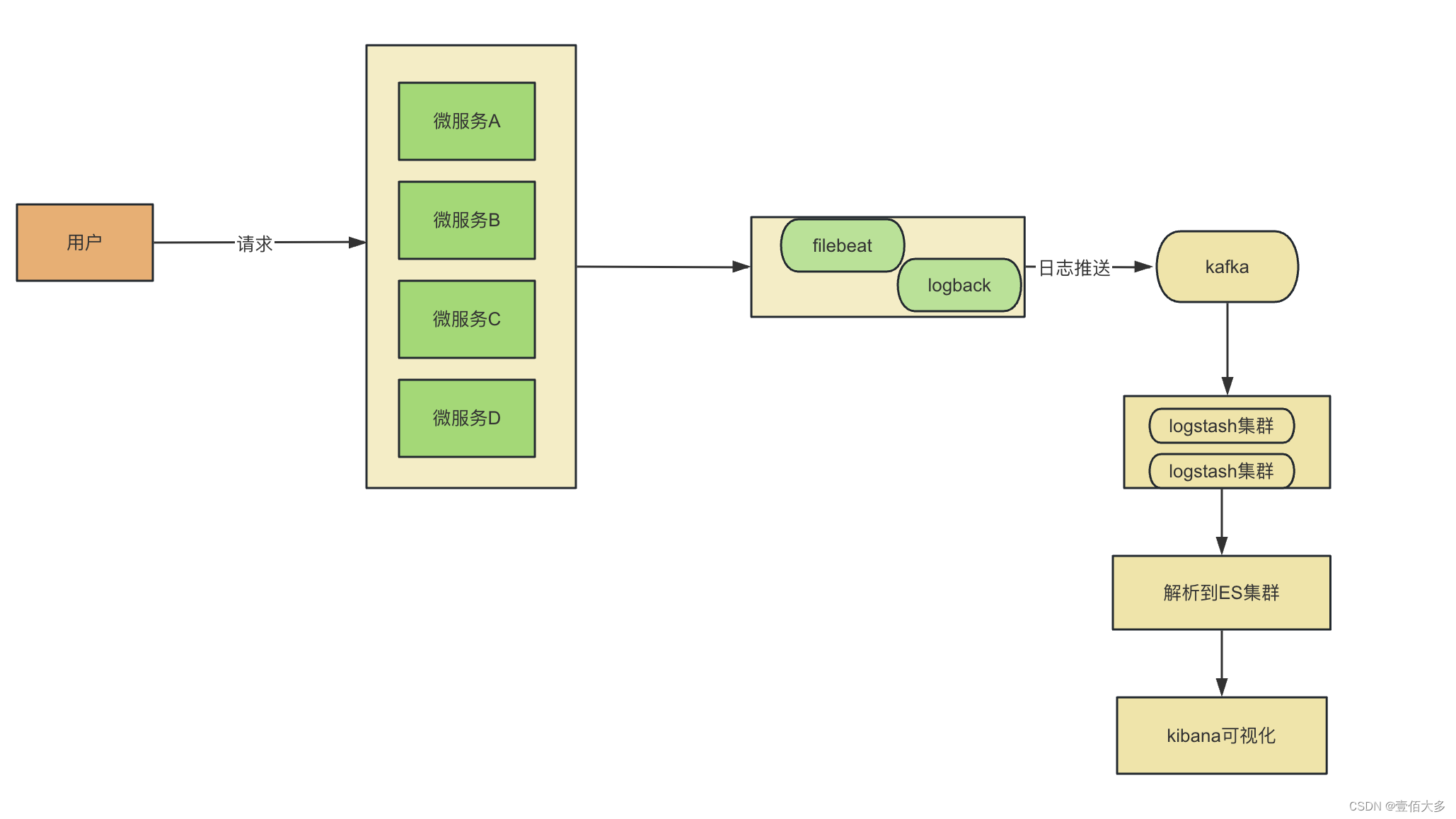
【ELK日志收集过程】
文章目录 为什么要使用ELK收集日志ELK具体应用场景ELK日志收集的流程 为什么要使用ELK收集日志 使用 ELK(Elasticsearch, Logstash, Kibana)进行日志收集和分析有多种原因。ELK 堆栈提供了强大、灵活且可扩展的工具集,能够满足现代 IT 系统对…...
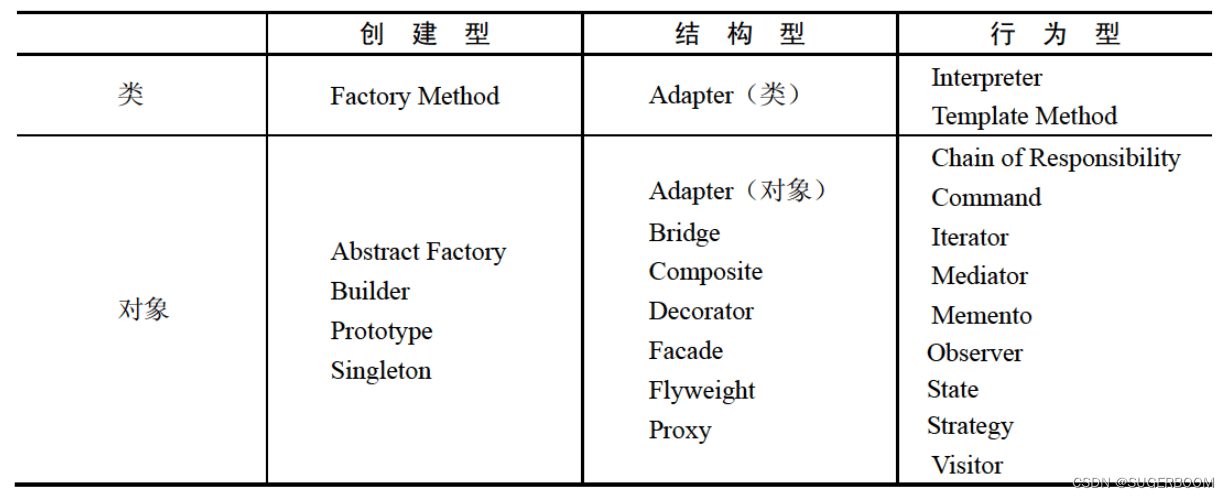
设计模式—23种设计模式重点 表格梳理
设计模式的核心在于提供了相关的问题的解决方案,使得人们可以更加简单方便的复用成功的设计和体系结构。 按照设计模式的目的可以分为三大类。创建型模式与对象的创建有关;结构型模式处理类或对象的组合;行为型模式对类或对象怎样交互和怎样…...
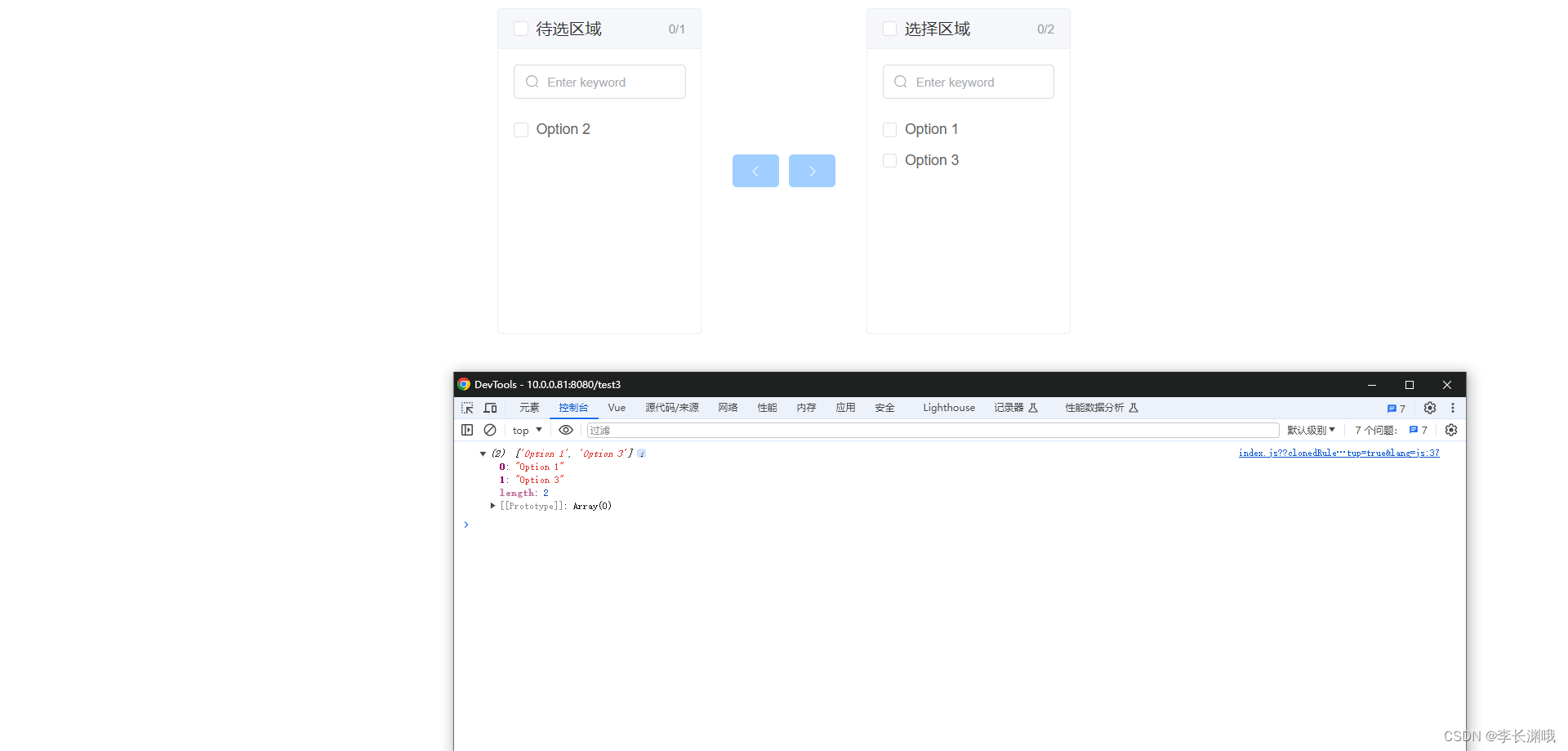
Vue学习穿梭框Transfer组件
Vue学习Transfer组件 一、前言1、案例一2、案例二 一、前言 在 Vue 3 中使用 el-transfer 组件可以帮助你实现数据的穿梭功能,让用户可以将数据从一个列表转移到另一个列表。下面是一个简单示例,演示如何在 Vue 3 中使用 el-transfer 组件: …...

Android 项目中自定义多个 RadioButton 并排一列选择效果实现
文章目录 1、静态版实现1.1、实现要求1.2、实现步骤1.3、代码实现1.4、代码实现说明1.5、结论 2、项目版实现(动态)1、先看效果图2、main的布局文件3、定义RadioButton的属性4、最后在代码中生成我想要的东东5、说明 3、后续优化方向 1、静态版实现 1.1、实现要求 我们需要在…...

解决win系统msvcp140.dll丢失的多种常用方法,亲测有效!
msvcp140.dll 是一个重要的Windows系统文件,属于Microsoft Visual C Redistributable runtime components的一部分,特别与Visual Studio 2015及之后版本编译的C应用程序相关联。这个动态链接库(DLL)文件包含了一系列C标准库的功能…...

使用keepalived实现mysql主从复制的自动切换
使用Keepalived实现MySQL主从复制的自动切换通常涉及配置一个虚拟IP(VIP)作为MySQL服务器对客户端的访问点。Keepalived会监控MySQL主服务器的健康状况,如果主服务器宕机,Keepalived会自动将虚拟IP移至备用服务器,从而…...
数据库(4)——DDL数据库操作
SQL标准没有提供修改数据库模式定义的语句,用户想修改次对象只能将它删除后重建。 查询 查询所有数据库: SHOW DATABASES; 在安装完MySQL数据库之后,自带了4个数据库,如下图: 创建数据库 数据库的创建语言为 CREATE…...

C#基础一
使用Visual Studio 2022(VS2022)编写C#控制台程序 1. 安装Visual Studio 2022 确保已安装Visual Studio 2022。如果未安装,请从Visual Studio官网下载并安装。 另一篇文章中已经有详细描述,这里就不在细说了。 VisualStudio2022…...
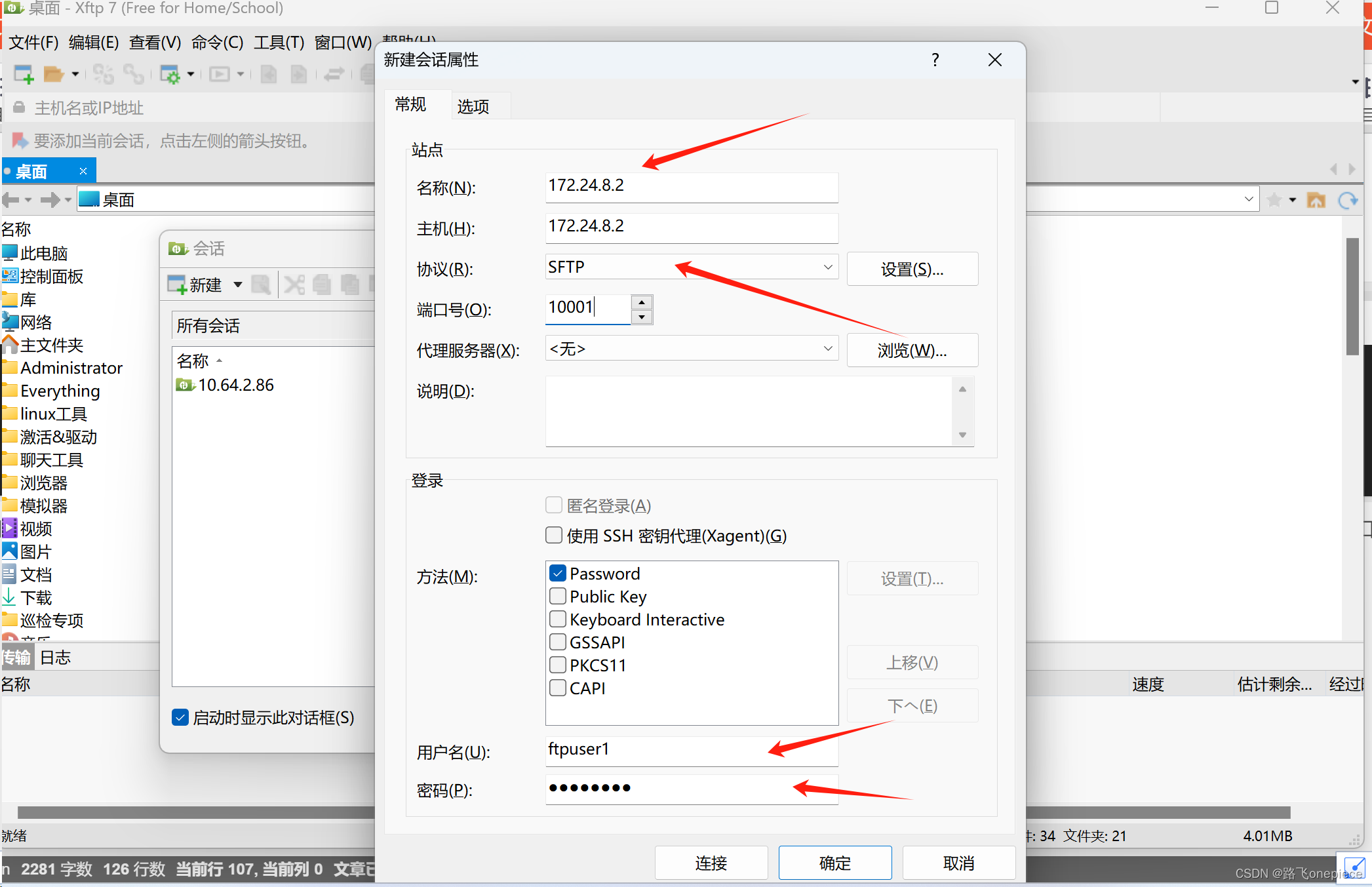
UOS1060e分离ssh与sftp服务
文章目录 原理一、sftp 用户与目录二、ssh 和 sftp 服务分离三、启动与停止四、验证 原理 SFTP是SSH的一部分,SFTP没有单独的守护进程,它必须使用SSHD守护进程(端口号默认是22)来完成相应的连接操作。 通过新建另一个‘sshd’进程…...

LeetCode刷题之HOT100之多数元素
2024/5/21 起床走到阳台,外面绵柔细雨,手探出去,似乎感受不到。刚到实验室,窗外声音放大,雨大了。昨天的两题任务中断了,由于下雨加晚上有课。这样似乎也好,不让我有一种被强迫的感觉࿰…...
)
回溯算法06(总结+leetcode332,51,37)
参考资料: https://programmercarl.com/%E5%9B%9E%E6%BA%AF%E6%80%BB%E7%BB%93.html 力扣这三题暂时不在本篇笔记中贴代码了,有兴趣的可参考332.重新安排形成、N皇后、解数独 总结: 画树形图分析题目 用途:回溯算法是用 递归实现…...

LabVIEW图像识别的技术手段有什么?
LabVIEW在图像识别领域采用了多种技术手段,以实现对图像的采集、处理、分析和识别。以下是一些主要的技术手段: 1. 图像采集 工业相机:使用高分辨率相机捕捉图像,确保图像质量和细节。接口支持:支持多种相机接口&…...

Vulhub——adminer
文章目录 一、CVE-2021-21311(SSRF)二、CVE-2021-43008(远程文件读取) 一、CVE-2021-21311(SSRF) Adminer是一个PHP编写的开源数据库管理工具,支持MySQL、MariaDB、PostgreSQL、SQLite、MS SQL…...
)
MySQL之性能剖析(三)
剖析MySQL查询 剖析单条查询 在定位到需要优化的单条查询后,可以针对查询"钻取"更多的信息,确认为什么会花费这么长的时间执行,以及需要如何去优化。不幸的是,MySQL目前大多数的测量点对于剖析查询都没有什么帮助。当…...

spark 之数据湖
delta lake 基本使用 可参见: https://docs.delta.io/2.3.0/quick-start.html#language-scala bin/spark-shell --packages io.delta:delta-core_2.12:2.3.0 --conf "spark.sql.extensionsio.delta.sql.DeltaSparkSessionExtension" --conf "spark…...

记录Hbase出现HMaster一直初始化,日志打印hbase:meta,,1.1588230740 is NOT online问题的解决
具体错误 hbase:meta,,1.1588230740 is NOT online; state{1588230740 stateOPEN, ...... 使用 hbase 2.5.5 ,hdfs和hbase分离两台服务器。 总过程 1. 问题发现 在使用HBase的程序发出无法进行插入到HBase操作日志后检查HBase状况。发现master节点和r…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...

从XAI到HXAI:构建以人为中心的可解释AI框架与实践
1. 项目概述:从“黑箱”到“白盒”,构建可信AI的演进之路在机器学习项目里摸爬滚打了十几年,我见过太多因为模型“说不清道不明”而引发的信任危机。一个在测试集上表现完美的信用评分模型,可能因为无法向风控专家解释“为什么拒绝…...

告别烧录烦恼:用Etcher三步打造完美启动盘的终极指南
告别烧录烦恼:用Etcher三步打造完美启动盘的终极指南 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾因烧录系统镜像而误删硬盘数据…...
)
告别手动映射!用AD域控组策略批量给员工电脑挂载共享盘(Windows Server 2016实战)
企业级共享存储自动化部署指南:基于AD域控的组策略实战每当新员工入职或部门调整时,IT管理员最头疼的莫过于重复配置几十台电脑的共享盘映射。财务部需要访问M盘的报表目录,市场部要连接N盘的设计素材,而手动设置不仅效率低下&…...

Awoo Installer:如何用这个免费工具快速安装Switch游戏
Awoo Installer:如何用这个免费工具快速安装Switch游戏 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为Ninte…...

三招识别“纪律高危”学生?K-Means聚类助你构建精准考勤画像
助睿实验3 - 学生用户画像 - 考勤主题扩展标签构建第一部分:实验背景1.1实验目的本实验旨在基于已完成的学生考勤主题标签表,掌握使用K-Means聚类算法对学生考勤行为进行自动分群的核心技能。具体任务包括:通过迟到、早退、请假、校服违规次数…...

idea安装ccgui的插件后调用模型出现了Operation aborted的问题
这个问题也是最近在自己电脑上调试claude code出现的问题,问题就是我搭建好本地的claude后再ccgui页面使用大模型就出现了这个问题如图所示:我使用的环境(node -18)idea2026版本 ,ccswitch,claude code&…...

Wand-Enhancer终极指南:三步免费解锁WeMod专业版所有功能
Wand-Enhancer终极指南:三步免费解锁WeMod专业版所有功能 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的限制而烦恼吗&…...