MySQL之性能剖析(三)
剖析MySQL查询
剖析单条查询
在定位到需要优化的单条查询后,可以针对查询"钻取"更多的信息,确认为什么会花费这么长的时间执行,以及需要如何去优化。不幸的是,MySQL目前大多数的测量点对于剖析查询都没有什么帮助。当然这种状况正在改善,大多数生产环境的服务器还没有使用包含最新剖析特性的版本。所以在实际应用中,除了SHOW STATUS、SHOW PROFILE、检查慢查询日志的条目(这还要求必须是Percona Server,官方MySQL版本的慢查询缺失了很多附加信息)这三种方法外就没有什么更好的办法了。
使用SHOW PROFILE
SHOW PROFILE命令是在MySQL 5.1以后的版本中引入的,来源于开源社区中的Jeremy Cole的贡献。这是唯一一个在GA版本中包含的真正的查询剖析工具。默认是禁用地,还可以通过服务器变量在会话(连接)级别动态地修改。
mysql> SELECT VERSION();
+------------+
| VERSION() |
+------------+
| 5.7.42-log |
+------------+
1 row in set (0.11 sec)mysql> SHOW VARIABLES LIKE 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | OFF |
+---------------+-------+
1 row in set (0.07 sec)mysql> SHOW PROFILE-> ;
Empty set
然后再服务器上执行的所有语句,都会测量其耗费的时间和其他一些查询执行状态变更相关的数据。这个功能有一定的作用,而且最初的设计功能更强大,但未来版本中可能会被Performance Schema所取代,尽管如此,这个工具最有用的作用还是在语句执行期间剖析服务器的具体工作。
当一条查询提交给服务器时,此工具会记录剖析信息到一张临时表,并且给查询赋予一个从1开始的整数标识符。
例子
- 举个例子
mysql> SELECT * FROM chat_room ORDER BY id DESC LIMIT 10;
10 rows in set (0.18 sec)
mysql> SHOW PROFILES;
+----------+------------+-------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------------------------+
| 1 | 0.00397750 | SHOW VARIABLES LIKE 'profiling' |
| 2 | 0.00010750 | SELECT * FROM chat ORDER BY id DESC LIMIT 100 |
| 3 | 0.00010100 | use chat |
| 4 | 0.00020625 | SELECT * FROM chat ORDER BY id DESC LIMIT 100 |
| 5 | 0.15971150 | SELECT * FROM chat_message ORDER BY id DESC LIMIT 100 |
| 6 | 0.00036200 | SELECT * FROM chat_message ORDER BY id DESC LIMIT 10 |
| 7 | 0.00037850 | SELECT * FROM chat_room ORDER BY id DESC LIMIT 10 |
+----------+------------+-------------------------------------------------------+
7 rows in set (0.17 sec)
该查询返回了10行记录,花费了0.18秒。接下来是SHOW PROFILES。
首先可以看到的是以很高的精度显示了查询的响应时间,这很好。MySQL客户端显示的时间只有两位小数,对于一些执行得很快的查询这样的精度是不够的。接下来继续看接下来的输出:
mysql> SHOW PROFILE FOR QUERY 7;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000077 |
| checking permissions | 0.000007 |
| Opening tables | 0.000071 |
| init | 0.000016 |
| System lock | 0.000006 |
| optimizing | 0.000003 |
| statistics | 0.000008 |
| preparing | 0.000009 |
| Sorting result | 0.000003 |
| executing | 0.000002 |
| Sending data | 0.000123 |
| end | 0.000004 |
| query end | 0.000005 |
| closing tables | 0.000005 |
| freeing items | 0.000024 |
| cleaning up | 0.000016 |
+----------------------+----------+
16 rows in set (0.17 sec)
剖析报告给出了查询执行的每个步骤及其花费的时间,看结果很难快速地确定哪个步骤花费地时间最多。因为输出是按照执行顺序排序,而不是按花费的时间排序的——而实际上我们更关心的是花费了多少多少时间,这样才能知道哪些开销比较打。但不幸的是无法通过诸如ORDER BY 之类的命令重新排序。假如不适用SHOW PROFILE命令而是这届查询INFORMATION_SHCEMA中对应的表,则可以按照需要格式化输出
如下方所示
mysql> SET @query_id = 7;
mysql>mysql> SELECT
STATE,
SUM( DURATION ) AS Total_R,
ROUND( 100 * SUM( DURATION ) / ( SELECT SUM( DURATION ) FROM INFORMATION_SCHEMA.PROFILING WHERE QUERY_ID = @query_id ), 2 ) AS Pct_R,
COUNT(*) AS Calls,
SUM( DURATION )/ COUNT(*) AS `R/Call`
FROM
INFORMATION_SCHEMA.PROFILING
WHERE
QUERY_ID = @query_id
GROUP BY
STATE
ORDER BY
Total_R DESC;
+----------------------+----------+-------+-------+--------------+
| STATE | Total_R | Pct_R | Calls | R/Call |
+----------------------+----------+-------+-------+--------------+
| Sending data | 0.000123 | 32.45 | 1 | 0.0001230000 |
| starting | 0.000077 | 20.32 | 1 | 0.0000770000 |
| Opening tables | 0.000071 | 18.73 | 1 | 0.0000710000 |
| freeing items | 0.000024 | 6.33 | 1 | 0.0000240000 |
| init | 0.000016 | 4.22 | 1 | 0.0000160000 |
| cleaning up | 0.000016 | 4.22 | 1 | 0.0000160000 |
| preparing | 0.000009 | 2.37 | 1 | 0.0000090000 |
| statistics | 0.000008 | 2.11 | 1 | 0.0000080000 |
| checking permissions | 0.000007 | 1.85 | 1 | 0.0000070000 |
| System lock | 0.000006 | 1.58 | 1 | 0.0000060000 |
| closing tables | 0.000005 | 1.32 | 1 | 0.0000050000 |
| query end | 0.000005 | 1.32 | 1 | 0.0000050000 |
| end | 0.000004 | 1.06 | 1 | 0.0000040000 |
| Sorting result | 0.000003 | 0.79 | 1 | 0.0000030000 |
| optimizing | 0.000003 | 0.79 | 1 | 0.0000030000 |
| executing | 0.000002 | 0.53 | 1 | 0.0000020000 |
+----------------------+----------+-------+-------+--------------+
16 rows in set (0.17 sec)
效果好多了,通过这个结果可以很容易看到查询时间太长主要是因为花了一大半的时间是"发送数据(Sending data)“,这个状态代表的原因非常多,可能是各种不同的服务器活动,包括在关联时搜索匹配的行记录等,这部分很难说能优化节省多少消耗时间。还有一种可能导致查询时间太长的原因,是数据复制到临时表这一步。如果是这种情况,则就要考虑如何改写查询以避免使用临时表,或者提升临时表的使用效率,另外还有一种状态是"结果排序()Sorting result”,如果花费的时间占比非常低。那这部分是不值得去优化的。这是一个比较典型的问题,所以一般我们都不建议用户在"优化排序缓冲区(tunning sort buffer)"或者类似的活动上花时间。
尽管剖析报告帮助我们定位到哪些活动花费了最多的时间,但并不会告诉我们为什么会这样,要弄清除为什么状态花费这么多时间,就需要深入下去,继续剖析这一步的子任务。
使用SHOW STATUS
MySQL的SHOW STATUS命令返回了一些计数器。既有服务器级别的全局计数器,也有基于某个连接的会话级别的计数器。例如其中的Queries在会话开始时为0,每提交一条查询增加1.如果执行SHOW GLOBAL STATUS(注意到新加额GLOBAL关键字),则可以查看服务器级别的从服务器启动时开始计算的查询次数统计。不同计数器的可见范围不一样,不过全局的计数器也会出现SHOW STATUS的结果中,容易被误认为时会话级别的,千万不要搞迷糊了。在使用这个命令时要注意几点,就像前面所讨论的,收集合适级别的测量值是很关键的。如果打算优化从某些特定连接观察到的东西,测量的却是全局级别的数据,就会导致胡乱.MySQL官方手册中对所有变量是会话级还是全局级做了详细的说明。
SHOW STATUS是一个有用的工具,但并不是一款剖析工具。SHOW STATUS的大部分结果都只是一个计数器,可以显示某些互动如读索引的频繁程度,但无法给出消耗了多少时间。SHOW STATUS的结果中只有一条指的是操作时间(Innodb_row_lock_time),而且只能是全局级的,所以还是无法测量绘画级别的工作。尽管SHOW STATUS无法提供基于时间的统计,但对于在执行完查询后观察某些计数器的值还是有帮助的。有时候可以猜测哪些操作代价较高或者消耗的时间较多。最有用的计数器包括句柄计数器(handler counter)、临时文件和表计数器等。下面的例子演示了如何将会话级别的计数器重置为0,然后查询前面(SHOW PROFILE)提到的视图,再检查计数器的结果
例子
- 举个例子
mysql> FLUSH STATUS;
Query OK, 0 rows affected (0.09 sec)mysql> SELECT * FROM chat_room ORDER BY id DESC LIMIT 10;
10 rows in set (0.15 sec)
mysql> SHOW STATUS WHERE Variable_name LIKE '%Handler%' OR Variable_name LIKE 'Created%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 0 |
| Created_tmp_tables | 0 |
| Handler_commit | 1 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_external_lock | 2 |
| Handler_mrr_init | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 0 |
| Handler_read_key | 1 |
| Handler_read_last | 1 |
| Handler_read_next | 0 |
| Handler_read_prev | 9 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 0 |
+----------------------------+-------+
21 rows in set (0.19 sec)
从结果中可以看到Created_tmp_tables创建临时表的次数。以及读取记录的前一个指针Handler_read_prev的次数。仅从结果来推测,我们可以判断出,上面的SELECT查询在找到最新一条行记录时,通过读取前一个节点指针来获取记录的。
使用这个技术的时候,要注意SHOW STATUS本身也会创建一个临时表,而且也会通过句柄操作访问此临时表,这会影响到SHOW STATUS结果中对应的数字,而且不同的版本可能行为也不尽相同。
你可能会注意到通过EXPLAIN 查询查询的执行计划也可以获得大部分相同的信息,但EXPLAIN是通过估计得到的结果,而通过计数器则是实际的测量结果。例如EXPLAIN 无法告诉你临时表是否是磁盘表,这和内存临时表的性能差别是很大的。
相关文章:
)
MySQL之性能剖析(三)
剖析MySQL查询 剖析单条查询 在定位到需要优化的单条查询后,可以针对查询"钻取"更多的信息,确认为什么会花费这么长的时间执行,以及需要如何去优化。不幸的是,MySQL目前大多数的测量点对于剖析查询都没有什么帮助。当…...

spark 之数据湖
delta lake 基本使用 可参见: https://docs.delta.io/2.3.0/quick-start.html#language-scala bin/spark-shell --packages io.delta:delta-core_2.12:2.3.0 --conf "spark.sql.extensionsio.delta.sql.DeltaSparkSessionExtension" --conf "spark…...

记录Hbase出现HMaster一直初始化,日志打印hbase:meta,,1.1588230740 is NOT online问题的解决
具体错误 hbase:meta,,1.1588230740 is NOT online; state{1588230740 stateOPEN, ...... 使用 hbase 2.5.5 ,hdfs和hbase分离两台服务器。 总过程 1. 问题发现 在使用HBase的程序发出无法进行插入到HBase操作日志后检查HBase状况。发现master节点和r…...
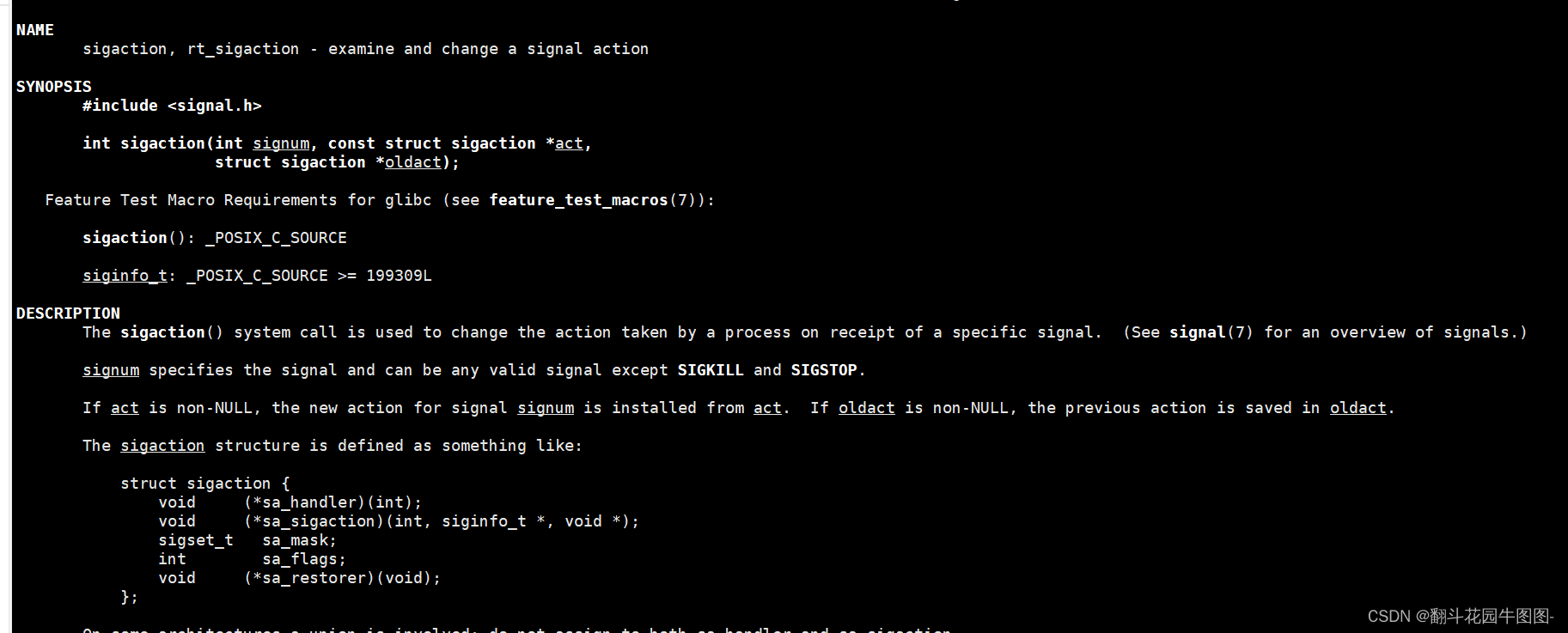
Linux——进程信号(二)
引言 在进程信号(一)中我们已经讲到了信号的保存,那么接下来要讲信号的处理了。 信号的处理主要要回答3个问题: 1.信号什么时候被处理的? 2.信号如何被处理的? 3.捕捉信号还有其他方式吗? 首先回答问题一࿱…...

2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(下):多智能体开发
传送门: 《2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(上):MetaGPT安装、单智能体开发》《2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(中)&…...
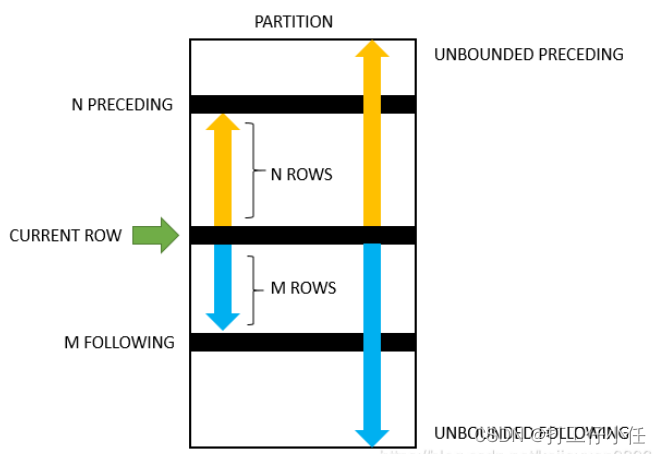
SQL开窗函数
文章目录 概念:语法:常用的窗口函数及示例:求平均值:AVG() :求和:SUM():求排名:移动平均计数COUNT():求最大MXA()/小MIN()值求分区内的最大/最小值求当前行的前/后一个值 概念: 开窗…...

[xx点评完结]——白马点评完整代码+rabbitmq实现异步下单+资料,免费
项目所有功能已测,均可以跑通,Jmeter和RabbitMQ也都测了。 项目源码:dianpinghui: 仿黑马点评项目 资料: https://pan.baidu.com/s/1kTCn9PxgeIey90WgM4KRqA?pwdn66b 对佬有帮助可以给个star哈,感谢🌹🌹dz…...
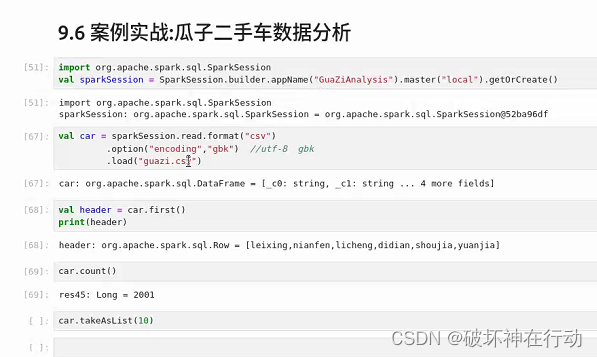
Hadoop+Spark大数据技术 实验8 Spark SQL结构化
9.2 创建DataFrame对象的方式 val dfUsers spark.read.load("/usr/local/spark/examples/src/main/resources/users.parquet") dfUsers: org.apache.spark.sql.DataFrame [name: string, favorite_color: string ... 1 more field] dfUsers.show() -----------…...

认知V2X的技术列一个学习大纲
为了深入学习和理解V2X(Vehicle to Everything)技术,以下是一个学习大纲的概述,结合了参考文章中的相关数字和信息: 一、V2X技术基础 V2X概述 定义:V2X是车用无线通信技术,将车辆与一切事物相连…...

揭秘齿轮加工工艺的选用原则:精准打造高效传动的秘密武器
在机械制造领域,齿轮作为传动系统中的重要组成部分,其加工工艺的选择至关重要。不同的齿轮加工工艺会影响齿轮的精度、耐用性和效率。本文将通过递进式结构,深入探讨齿轮加工工艺的选用原则,带您了解如何精准打造高效传动的秘密武…...
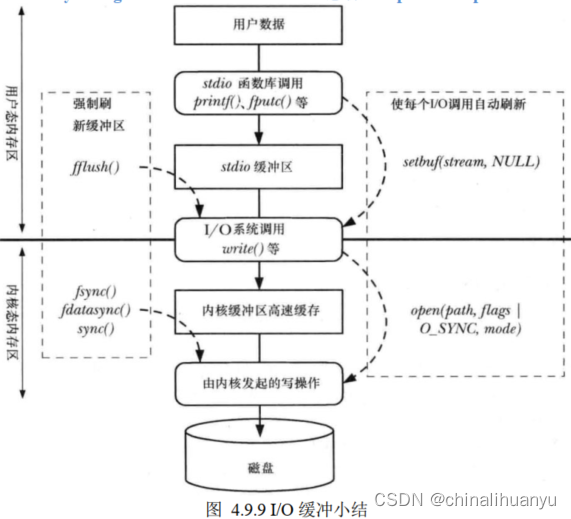
Linux-应用编程学习笔记(二、文件I/O、标准I/O)
一、文件I/O基础 文件 I/O 指的是对文件的输入/输出操作,就是对文件的读写操作。Linux 下一切皆文件。 1.1 文件描述符 在 open函数执行成功的情况下, 会返回一个非负整数, 该返回值就是一个文件描述符(file descriptor&#x…...

AI爆文写作:根据别人的爆款标题,如何通过名词替换改成自己的爆款标题?
在日常刷到爆文的时候,就可以培养自己的网感,为啥这篇文章会爆? 这篇爆文的标题有啥诀窍呢? 比如下面这一篇:《极简生活:变富就是每天循环5个动作》 我们可以发现,每天循环5个动作 这几个词语…...

Mybatis源码剖析---第二讲
Mybatis源码剖析—第二讲 那我们在讲完了mappedstatement这个类,它的一个核心作用之后呢?那下面我有一个问题想问问各位。作为mappedstatement来讲,它封装的是一个select标签或者insert标签。但是呢,我们需要大家注意的是什么&am…...

SpringMvc-restful设计风格
Restful 1、入门1.1 简介1.2 实例 1、入门 1.1 简介 RESTFul是什么 RESTFul是WEB服务接口的一种设计风格。 RESTFul定义了一组约束条件和规范,可以让WEB服务接口更加简洁、易于理解、易于扩展、安全可靠。 1.2 实例 web.xml <?xml version"1.0"…...

在未来你将何去何从?
在数字化的浪潮中,信息技术行业无疑是推动全球经济和社会发展的重要动力。随着科技的不断迭代与进步,云计算、大数据、人工智能(AI)、物联网(IoT)、5G通信和区块链等技术已经深入到我们生活的每一个角落&am…...

Vue.js组件设计模式:构建可复用组件库
在Vue.js中,构建可复用的组件库是提高代码复用性和维护性的关键。下面是一些设计模式,说明如何创建可复用的Vue组件: 1. 单文件组件(Single File Component, SFC) Vue.js组件通常是单文件组件,包含HTML、…...
【C语言】指针运算
前言 前面在“走进指针世界”中我已经讲解过指针相关的很多前置知识,其实还有一个很重要的部分就是指针的运算。这篇博客,就让我们一起了解一下指针的运算吧! 指针作为变量,是可以进行算术运算的,只不过情况会和整型…...
 函数)
Python学习(3) 函数
定义 定义一个函数的格式: def 函数名(参数):执行代码如果没有参数,则称为无参函数。 定义时小括号中写的是形参(形式参数),调用时写的是实参(实际参数)。 调用 调用格式: def…...

计算机网络安全控制技术
1.防火墙技术 防火墙技术是近年来维护网络安全最重要的手段,但是防火墙不是万能的,需要配合其他安全措施来协同 2.加密技术 目前加密技术主要有两大类:对称加密和非对称加密 3.用户识别技术 核心是识别网络者是否是属于系统的合法用户 …...
WordPress插件Disable WP REST API,可根据是否登录来禁用REST API
前面跟大家分享了代码版禁用WordPress REST API的方法(详见『WordPress4.7以上版本如何禁用JSON REST API?』),不过有些站长不太敢折腾自己的网站代码,那么建议试试这款Disable WP REST API,它可以…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...