C++vector的简单模拟实现

文章目录
目录
文章目录
前言
一、vector使用时的注意事项
1.typedef的类型
2.vector不是string
3.vector
4.算法sort
二、vector的实现
1.通过源码进行猜测vector的结构
2.初步vector的构建
2.1 成员变量
2.2成员函数
2.2.1尾插和扩容
2.2.2operator[]
2.2.3 迭代器
2.2.4尾删、指定位置删除和插入
3指定位置删除和插入和迭代器失效
3.1insert和迭代器野指针问题
3.2erase和迭代器失效
4.拷贝构造
5.operator=赋值
6.迭代器区间初始化
7.n个val初始化和编译器匹配问题
三、{}的使用
四、vector的问题
前言
vector的使用方法和string很类似,但是string设计的接口太多,而vector则较少所有我们直接开始模拟实现,如果你对vector的使用不太熟悉可以通过它的文档来了解:vector。我们实现vector的简单模板版本。
由于模板的小问题,我们在使用模板时最好声明和定义在同一个文件。
一、vector使用时的注意事项
1.typedef的类型
在看文档时有很多未见过的类型,实际上那是typedef的: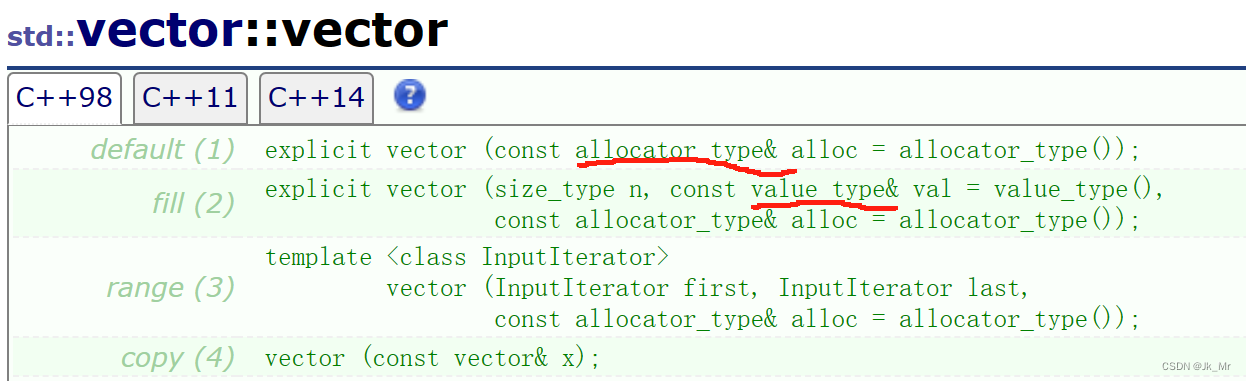

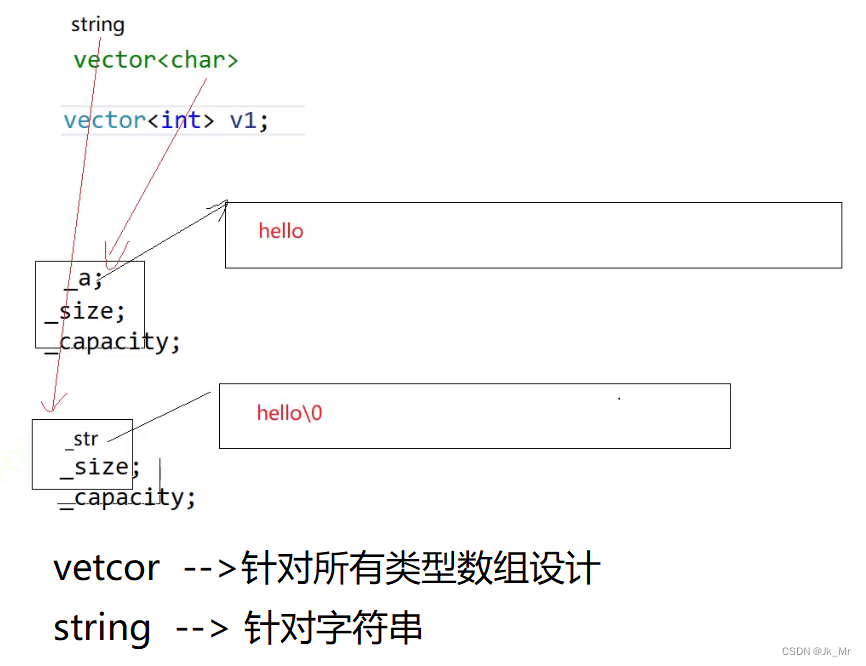
2.vector<char>不是string
不能把vector<char>和string等价,string是专门对待字符串和字符的自定义类型,而vector<char>是char类型的顺序表。
区别在于vector<char>后面要手动加'\0',而string会自动加'\0'.
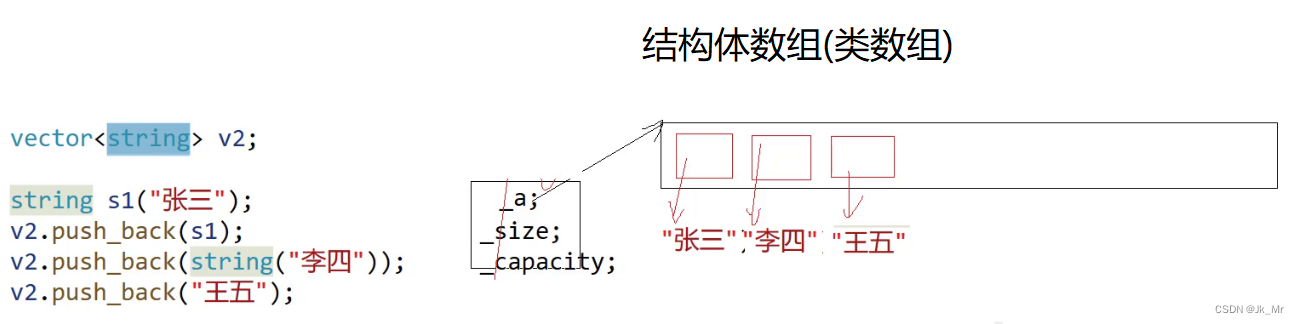
3.vector <string>
vector<string>是string 的顺序表,每个元素都是string,如果使用vector<const char*>则空间还需自己手动调整,使用string则不用。
4.算法sort
C++库函数中提供了一个包含算法的头文件<algorithm>,现在我们要学会使用sort来排序:
默认是升序。
vector<int> v1 = { 5,6,1,3,4,10 };for (const auto& e : v1){cout << e << ' ';}std::sort(v1.begin(), v1.end());cout << endl;for (const auto& e : v1){cout << e << ' ';} 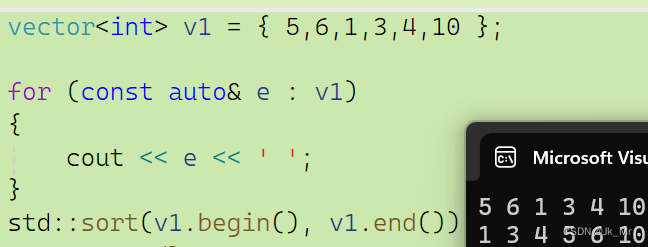
那么该如何降序?
可以使用反向迭代器:
std::sort(v1.rbegin(), v1.rend());使用反函数greater<>:
greater<int> gt;std::sort(v1.begin(), v1.end(),gt);//std::sort(v1.begin(),v1.end(),greater<int>());//匿名对象
greater是降序,升序是less.在C++中,我们<为升序,> 为降序,所有greater是降序,less是升序。
这里了解一下,后面会详细讲解。
二、vector的实现
1.通过源码进行猜测vector的结构
<vctor.h>中,我们先浅浅了解一下,具体实现我们使用我们的思路。

观察源码typedef:
观察源码的成员变量:
start是什么,finish是什么?end_of_storage?从名字上看再对比之前的顺序表结构,或许可以大胆猜测:start到finish是一对和size差不多,end_of_storage应该是capacity。
通过观察成员函数来进行猜测:

如果finish到了end_of_storage说明满了进行扩容。扩容操作是由insert_aux函数来完成的:
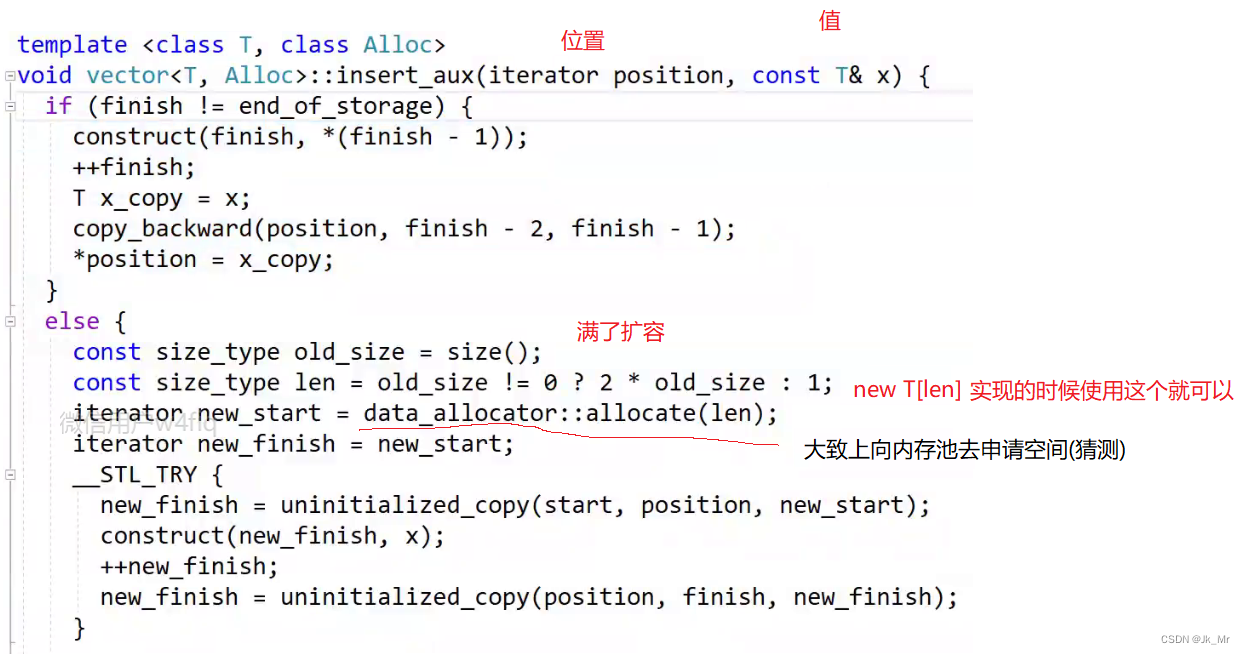
如果满了就进行扩容,大胆猜测扩容操作时进行三段操作: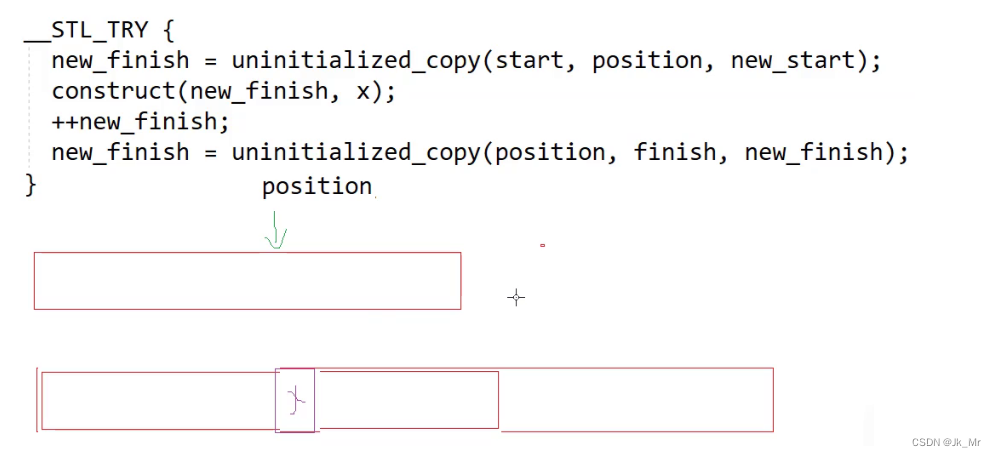
1.把position位置之前的数据拷贝到新空间,
2.把x插入到新的空间的尾部
3.再把position位置之后的数据拷贝到新的空间。
这些了解一下。
关于construc和destroy实际上和内存池有关:

由于内存池调用new和delete不会进行构造和初始化,所以construc和destroy是定位new的函数,用于对内存池的空间进行构造(这里是拷贝构造)和析构 。
2.初步vector的构建
使用声明和定义分离来进行模拟实现。在开始我们先不实现构造,使用给缺省值来解决五默认构造的问题。关于为什么给成员变量缺省值就可以进行插入可以查看这一片文章:类和对象(下)初始化列表
2.1 成员变量
#pragma once
#include <iostream>
using namespace std;
#include <vector>namespace vet
{template<class T>class vector{public:typedef T* iterator;private://T* _a;//size_t _size;//size_t _capacity;//俩者本质上是一样的iterator _start;iterator _finish;iterator _end_of_storage;};
}2.2成员函数
2.2.1尾插和扩容
尾插涉及扩容,这我们直接实现capacity和size函数。
vector.h中 void reserve(size_t n){if (n > capacity()){T* tmp = new T[n];if (_start)//如果为空不进行拷贝{memcpy(tmp, _start, sizeof(T) * size());delete _start;_start = tmp; }_finish = _start + size();_end_of_storage = _start + n;} }size_t capacity(){return _end_of_storage - start;}size_t size(){return _finish - _start;}void push_back(const T& x){if (_finish == _end_of_storage){//扩容size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);}*finish = x;++finish;}2.2.2operator[]
T& operator[](size_t pos){assert(pos < size());return _start[pos];}测试代码:
运行会发现,程序奔溃。
test.cpp中
void test_myvector1()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (int i = 0; i < v1.size(); i++){cout << v1[i] << ' ';}
}通过调试发现_finish = x是对空指针操作,实际上错误是在size()计算阶段:
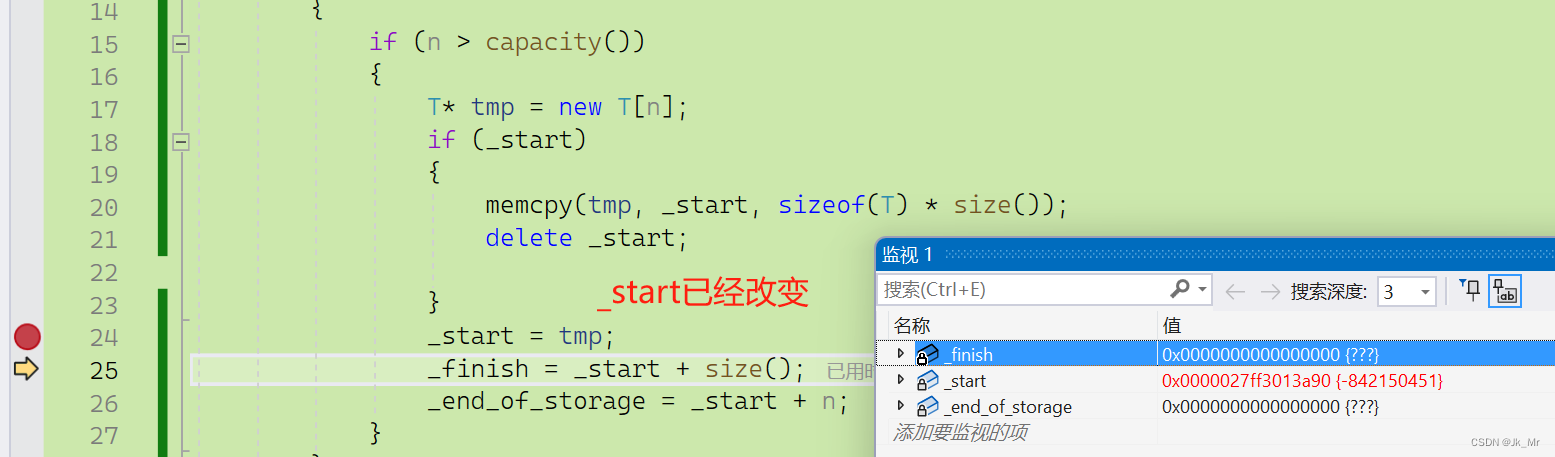
而size()是通过_finish - _start来计算的:

_start指向新的空间,而_finish是nullptr,使用空指针减去_start操作错误。size()不是我们想要的size().
俩种解决办法:
void reserve(size_t n)
{if (n > capacity()){T* tmp = new T[n];if (_start){memcpy(tmp, _start, sizeof(T) * size());delete _start;}_finish = tmp + size();_start = tmp; _end_of_storage = _start + n;}
}这样顺序不好,用户可能看不懂,所以可以记录一下size()然后进行更新:
void reserve(size_t n)
{size_t oldsize = size();if (n > capacity()){T* tmp = new T[n];if (_start){memcpy(tmp, _start, sizeof(T) * size());delete _start;}_start = tmp;_finish = _start + oldsize;_end_of_storage = _start + n;}
}结果: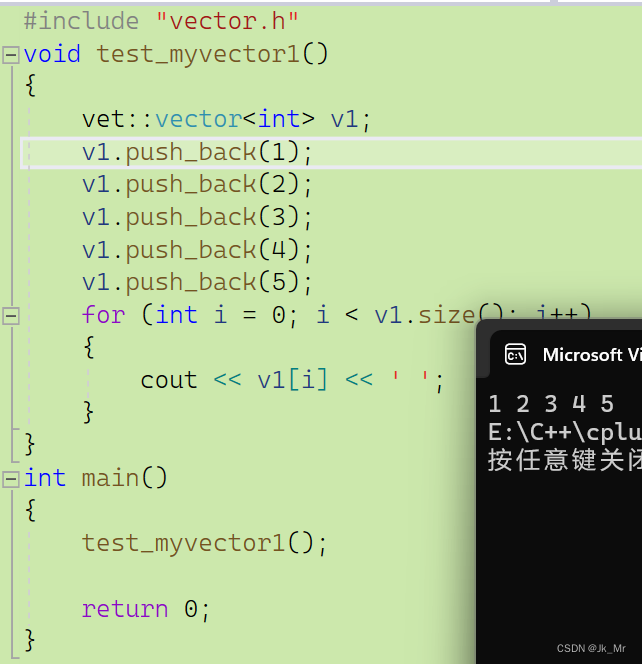
我们这里并未写析构和构造,系统是抽查的机制,动态开辟的一般在delete的时候进行检测,所以我们有时候可能在越界暴露不出来,推荐写上析构:
再测试有无问题。
~vector(){if (_start){delete[] _start;_finish = _end_of_storage = nullptr;}}
2.2.3 迭代器
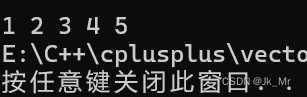
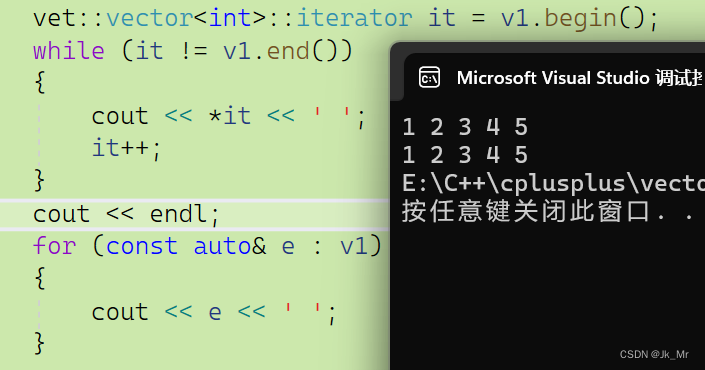
有了迭代器,那么就可以使用范围for了;
iterator begin()
{return _start;
}
iterator end()
{return _finish;
}测试代码:
vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);vet::vector<int>::iterator it = v1.begin();while (it != v1.end()){cout << *it << ' ';it++;}cout << endl;for (const auto& e : v1){cout << e << ' ';}结果:
2.2.4尾删、指定位置删除和插入
//尾删void pop_back(){assert(size() > 0);--_finish;}3指定位置删除和插入和迭代器失效
指定位置删除插入:
要实现指定位置删除或插入就要找到要删除或插入的值。
观察vector 的文档发现,vector没有find,是因为在算法<algorithm>中已经存在find的模板:体现了复用,vector,list都可以用。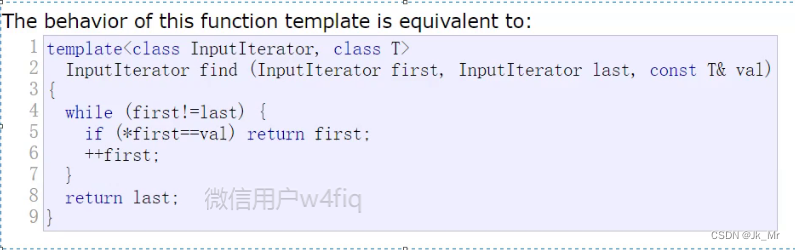
3.1insert和迭代器野指针问题
空间不够扩容,够了挪动数据。
void insert(iterator pos, const T& x){assert(pos >= _start && pos <= _finish);if (_finish == _end_of_storage){//扩容size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);}//挪动数据,从后往前挪iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;--end;}*pos = x;++_finish;}运行代码:
void test_myvector2()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (auto e : v1){cout << e << ' ';}cout << endl;v1.insert(v1.begin(), 0);for (auto e : v1){cout << e << ' ';}
}
结果: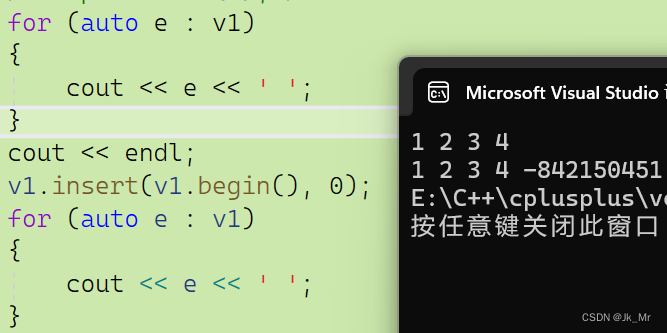
通过运行结果发现,程序崩溃了,这是为什么?
实际上这里是迭代器失效了,空间满了需要扩容操作,扩容造成了迭代器失效。如果空间足够则可以正常插入。
迭代器失效是指在使用迭代器遍历集合(如数组、列表、字典等)的过程中,对集合进行了修改(添加、删除操作)导致迭代器指向的元素位置发生变化,从而影响迭代器的正确性和结果不可预测的现象。
我们的代码实在扩容的时候发生了迭代器失效。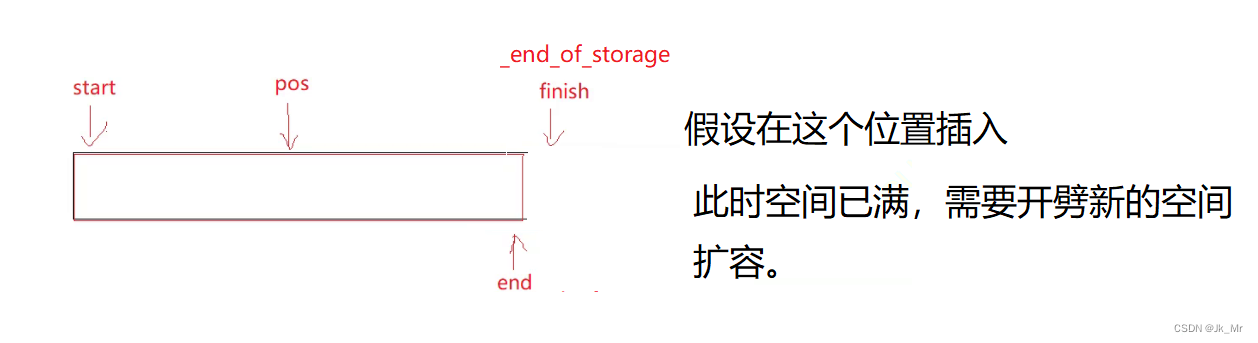
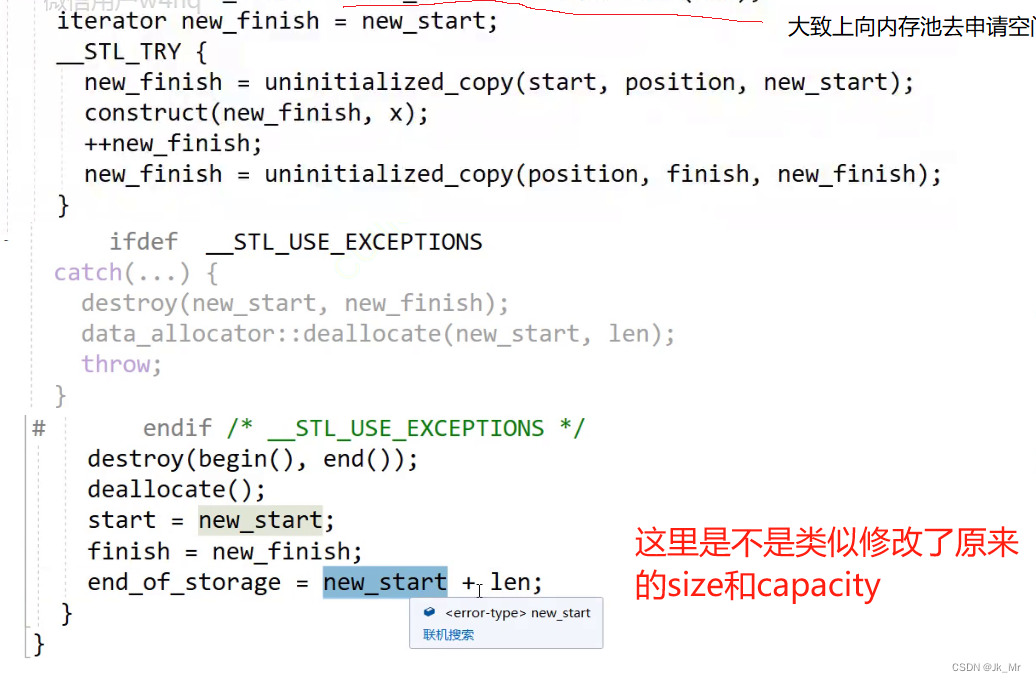
扩容操作改变的是_start和_finish以及_end_of_stroage: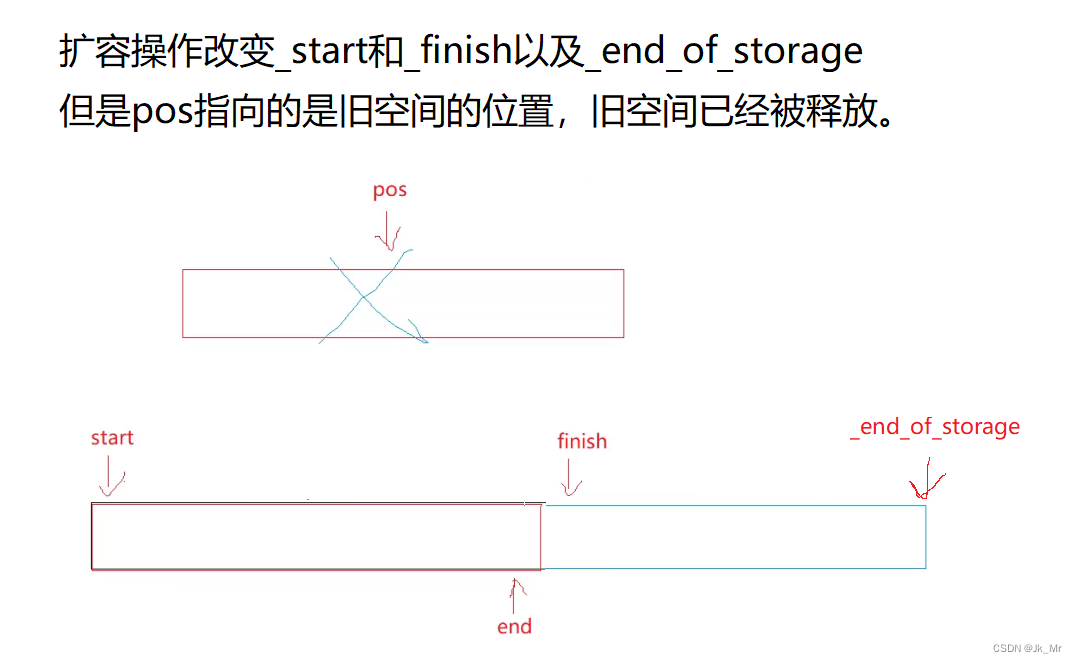
所以这里的迭代器失效本质是野指针问题。
既然pos迭代器失效,那我们就更新pos迭代器。pos要指向新空间的pos位置:
记录与_start的距离:size_t len = pos - _start;
void insert(iterator pos, const T& x)
{assert(pos >= _start && pos <= _finish);if (_finish == _end_of_storage){size_t len = pos - _start;//扩容size_t newcapacity = capacity() == 0 ? 4 : 2 * capacity();reserve(newcapacity);pos = _start + len;}//挪动数据,从后往前挪iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;--end;} *pos = x;++_finish;
}此时运行上面的测试代码: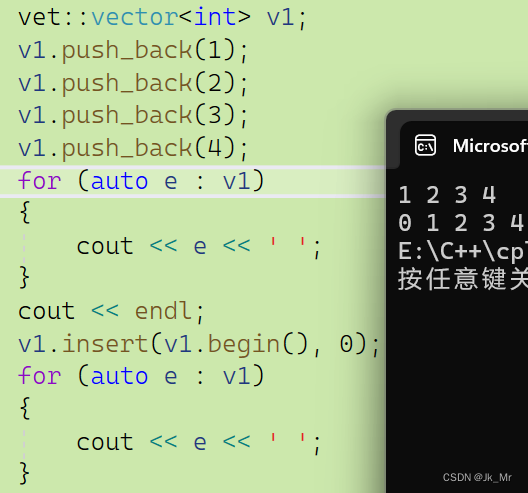 结果运行正常。
结果运行正常。
一般使用insert往往伴随着find,所以我们使用find再进行测试
vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (auto e : v1){cout << e << ' ';}cout << endl;vet::vector<int>::iterator vi = find(v1.begin(),v1.end(),3);v1.insert(vi, 10);for (auto e : v1){cout << e << ' ';}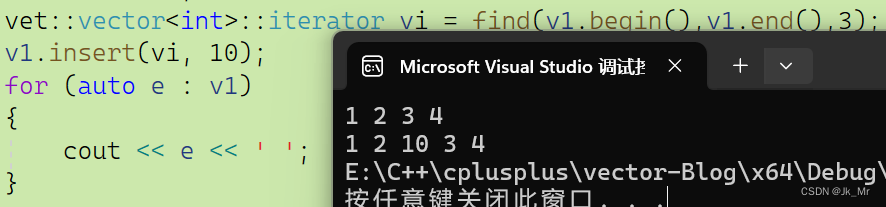
这样又有一个问题:发生扩容时insert以后vi个迭代器实参会不会失效?
仔细想想,空间不足时,需要扩容进行空间转移,而vi指向的是否是原来的空间?函数中的pos是否会改变vi?
答案是会失效,因为,vi是实参,而pos是形参,形参的改变不会影响实参的改变。
vet::vector<int>::iterator vi = find(v1.begin(),v1.end(),3);
if(vi != v1.end())
{ v1.insert(vi, 10);cout << *vi << endl;
}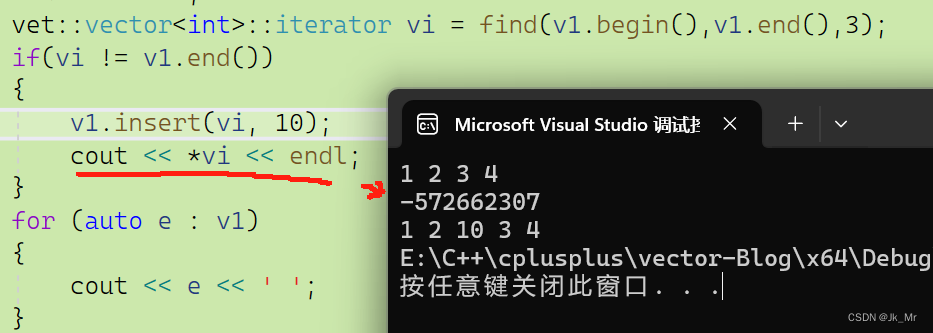
由于不知道什么时候扩容,所以一般认为这种情况是迭代器失效。这时候我们建议不要访问和修改vi指向的空间了(即不使用失效的迭代器)。
如果非要访问插入的位置呢?该怎么办?文档中insert提供了一种方法就是函数的返回值:
iterator insert(iterator pos, const T& x)
{//代码..return pos;
}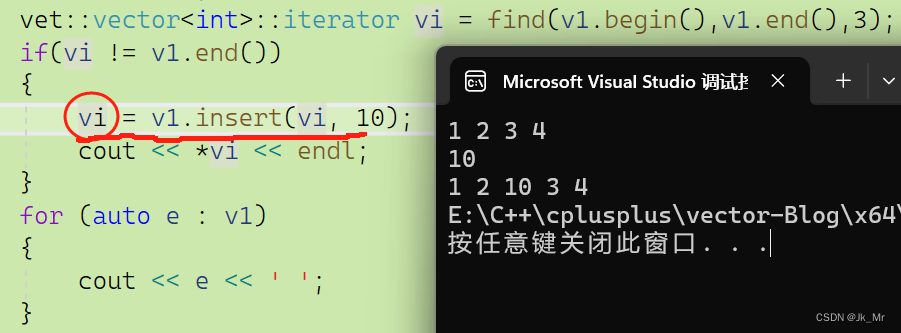
一般也不会这么做,所以一般认为失效了。string也有迭代器失效,其他也不例外。也是通过返回值。
3.2erase和迭代器失效
erase要将pos位置之后的数据前移:

void erase(iterator pos){assert(pos >= _start && pos < _finish);iterator it = pos + 1;//将后面的数据前移while (it != _finish){*(it - 1) = *it;++it;}--_finish;}测试代码:
void test_myvector03()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);for (auto e : v1){cout << e << ' ';}cout << endl;v1.erase(v1.begin());for (auto e : v1){cout << e << ' ';}
}测试结果:

erase也有迭代器失效,我们使用vector库里的删除进行测试看看: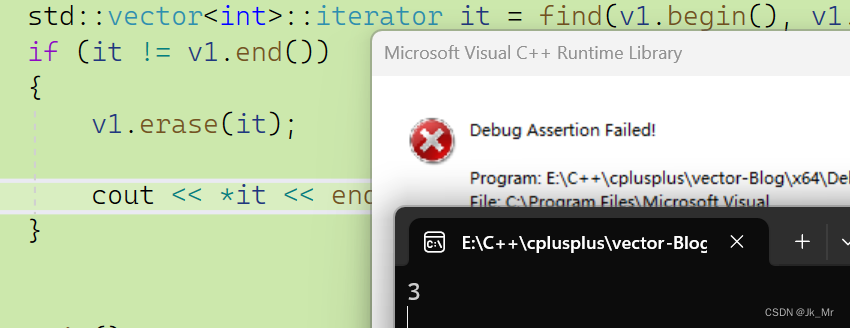
同样也不能访问,而且是断言错误。而使用返回值时则可以使用:
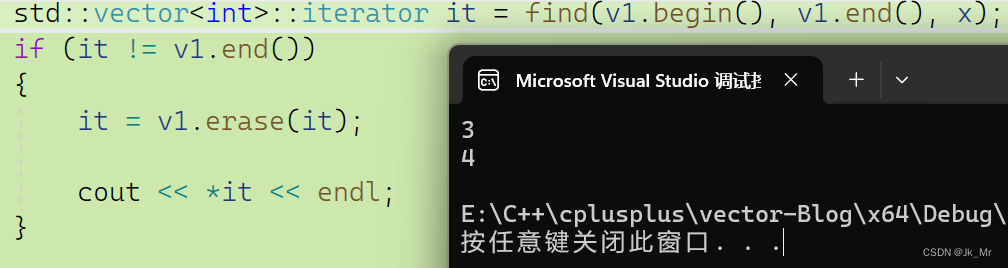
既然删除只涉及数据移动,那为什么删除也会是迭代器失效呢?
由于C++并未规定删除是否会缩容,所以删除时不同的平台可能不同:
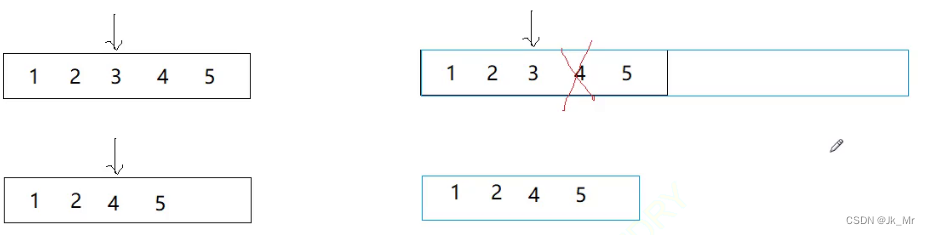
是有可能野指针的。
就算不缩容,那么在删5的时候呢?删除5的时候后面没有数据,如果要访问迭代器会造成越界访问。这里迭代器失效并不是野指针。
所以我们认为erase后,迭代器失效。
vs下要访问迭代器的话,同样是使用返回值,那我们实现也使用,但是在删除最后应一个有效元素时,不能进行访问: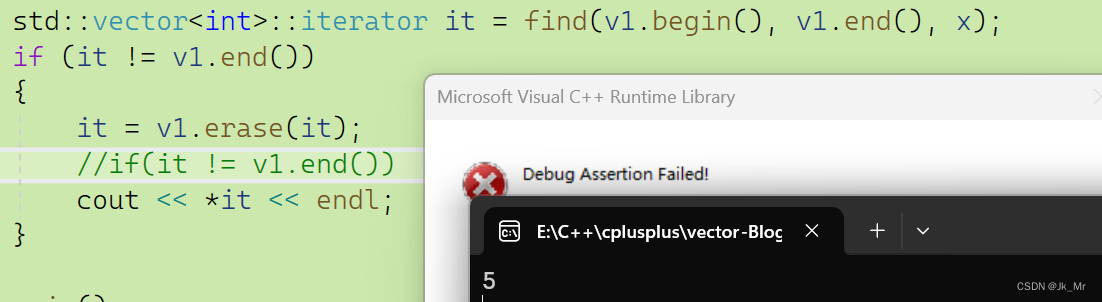
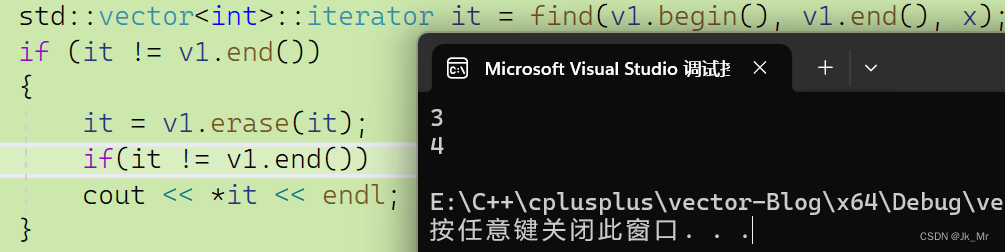
iterator erase(iterator pos)
{assert(pos >= _start && pos < _finish);iterator it = pos + 1;while (it != _finish){*(it - 1) = *it;++it;}--_finish;return pos;
}测试代码:
std::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);int x;cin >> x;std::vector<int>::iterator it = find(v1.begin(), v1.end(), x);if (it != v1.end()){it = v1.erase(it);if(it != v1.end())cout << *it << endl;}如下题,要删除所有偶数,使用失效的迭代器则会保存,所有应该使用返回值:
void test_myvector05()
{std::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (auto e : v1){cout << e << ' ';}//删除所有偶数std::vector<int>::iterator it = v1.begin();while (it != v1.end()){if (*it % 2 == 0)it = v1.erase(it);else++it;}for (auto e : v1){cout << e << ' ';}
}而在linux下不使用返回值则可以。但是不同平台不一样,使用最好使用函数返回值更新。
4.拷贝构造
在不写拷贝构造函数时,编译器会默认生成,该拷贝是浅拷贝。
void test_myvector06()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);//没有写拷贝构造//浅拷贝vet::vector<int> v2(v1);for (auto e : v2){cout << e << ' ';}
}结果肯定是报错,因为浅拷贝是值拷贝,成员变量的值是一样的,此时v1和v2指向同一块空间
,在出函数作用域时会调用析构函数,此时v1、v2都会析构,但是指向同一块空间,所以析构了俩次。
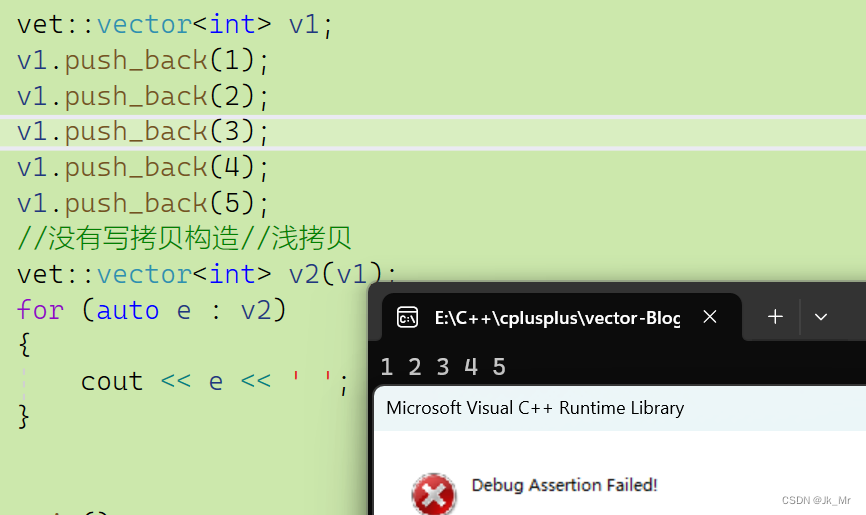
所有我们要写拷贝构造:
像这样写就可以开辟空防止指向同一块空间。
vector(const vector<T>& v)
{for (auto e : v){push_back(e);}
}但是由于我们没有写默认构造函数:

由于我们写了一个拷贝构造,编译器不会自动生成构造函数(类和对象中上)了。
我们可以通过写默认构造函数来解决也可以通过下面这种方法:
vector() = default;
vector(const vector<T>& v)
{for (auto e : v){push_back(e);}
}第一行代码使用于编译器强制生成默认构造函数。
我们在后面再添加上默认构造函数,这里我们先完成拷贝构造函数,由于拷贝构造我们使用的是尾插的方式,所以每次插入可能涉及很多扩容,所以我们可以提前开好空间:
vector(const vector<T>& v){reserve(v.capacity());for (auto e : v){push_back(e);}}
运行时发现不行:

是因为我们的capacity和size,迭代器不是const成员函数,所以我们加上const:

实现const迭代器:
typedef T* iterator;typedef const T* const_iterator;iterator begin(){return _start;}iterator end(){return _finish;}const_iterator begin() const{return _start;}const_iterator end() const{return _finish;}结果:
5.operator=赋值
我们使用现代写法:
//v1 = v2void swap(vector<T> v){std::swap(_start, v._start);std::swap(_finish,v._finish);std::swap(_end_of_storage,v._end_of_storage);}//现代写法:传值传参,v出函数作用域会调析构,//但是我们交换了this和v的成员变量,所以析构的是原来的空间而不是v的而是this的vector<T>& operator=(vector<T> v){swap(v);return this;}6.迭代器区间初始化
allocator是内存池,内存池是自己写的空间配置,我们使用new来开空间就好。

迭代器区间需要俩个迭代器first和last,我们写成函数模板,可以支持任意类型:
//支持任意容器的迭代器初始化
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{while (first != last){push_back(*first);++first;}
}测试代码:
void test_myvector07()
{vet::vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (auto e : v1){cout << e << ' ';}cout << endl;vet::vector<int> v2(v1.begin()+1,v1.end()-1);for (auto e : v2){cout << e << ' ';}
}结果: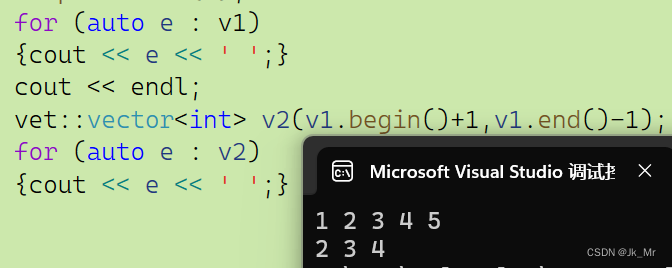
7.n个val初始化和编译器匹配问题
需要考虑缺省值。
![]()
缺省值能否是0?很明显不能,因为T的类型未知,如果是string、vector、list类型,给0肯定会有问题。所以该怎么办?
缺省参数一般给常量,但自定义类型怎么办,C++中自定义类型可以传T(),即匿名对象(调用默认构造)。内置类型是否可以这样?是可以的,C++对内置类型进行升级,可以进行构造: 值分别为0、1、0、2。
值分别为0、1、0、2。
测试代码:
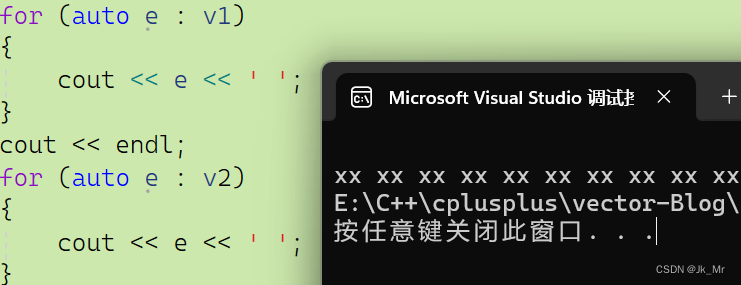
void test_myvector08()
{vet::vector<string> v1(10);vet::vector<string> v2(10, "xx");for (auto e : v1){cout << e << ' ';}cout << endl;for (auto e : v2){cout << e << ' ';}
}结果:
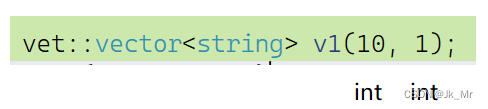
在使用实例化类模板时,如果对它构造n个1会有意想不到的错误:
void test_myvector09()
{vet::vector<string> v1(10, 1);for (auto e : v1){cout << e << ' ';}
} 报错到了这里?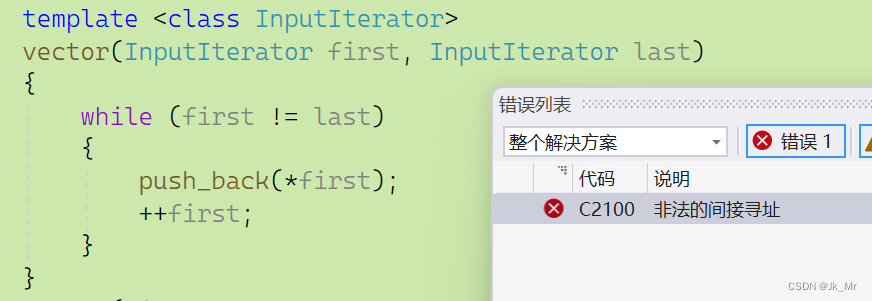
这里提一下调试技巧:目前我们知道时我们的测试代码上下都没有其他代码,
1.如果有其他代码,先通过屏蔽其他代码锁定时哪一段代码出来问题。
2.通过一步步调试进行观察。
这里实际上时参数的匹配问题,编译器的选择问题。
由于我们传参的都是int,所以模板实例化的也是int int。
编译器会匹配更好的,参数更匹配的。

实际上vector<int>(10,1)也会出错: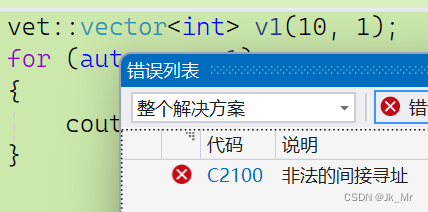
解决办法:要使得匹配到正确的函数我们就要给出一个重载的函数:
 、
、
这样就可以匹配到合适的函数。vector库内也面临这样的问题。
三、{}的使用
在类和对象(下)中我们提到了多参数和单参数的隐式类型转换。使用到了{},这时C++11的特性:一切皆可用{}进行初始化。

class A
{
public:A(int a):_a1(a),_a2(a){}A(int a1, int a2):_a1(a1), _a2(a2){}
private:int _a1;int _a2;
};
int main()
{//单参数隐式类型转换 1-> 构造临时对象A(1) -> 拷贝构造给 a1 => 优化为直接构造A a1(1);A a2 = 1;A a3{ 1 };A a4 = { 1 };//多参数隐式类型转换 1,2-> 构造临时对象A(1,2) -> 拷贝构造给 aa1 => 优化为直接构造A aa1(1, 2);A aa2 = { 1,2 };A aa3{ 1,2 };return 0;
}所以在平常使用中可以使用{}.
再来看下面代码:
我们使用库中的vector。
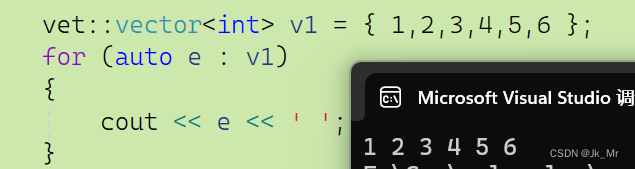
void test_vector1()
{std::vector<int> v1 = { 1,2,3,4,5,6 };for (auto e : v1){cout << e << ' ';}
}这里是隐式类型转换,但不是转化为vector<int>而是initializer list,然后再进隐式类型转化,是C++11的一种构造:

initializer list是C++11新增的类型

它是一个自定义类型:

il1和il2是等价的。由于{}内是常量数组。内部实际上是俩个指针,分别指向常量数组的开始和末尾:

它也有迭代器和size,所以支持范围for:
所以在我们自己实现的vector中要使用{1,2,3,4,5}这样的形式我们要支持initializer_list的构造:
vector(initializer_list<T>il){reserve(il.size());//initializer_list支持迭代器for (auto e : il){push_back(e);}}结果:
有了这个特性我们就可以像下面这样:
class A
{
public:A(int a = 0):_a1(a),_a2(a){}A(int a1, int a2):_a1(a1), _a2(a2){}
private:int _a1;int _a2;
};
int main()
{vet::vector<A> v1 = { 1,{1},A(1),A(1,2),A{1},A{1,2},{1,2} };return 0;
}{}的用法很杂,使用再使用{}进行初始化时,尽量不要写的太奇怪。
四、vector<string>的问题
观察下面的程序:
void test_myvector11()
{vet::vector<string> v1;v1.push_back("1111111111111111");v1.push_back("1111111111111111");v1.push_back("1111111111111111");v1.push_back("1111111111111111");for (auto e : v1){cout << e << endl;}cout << endl;
}
插入4个string,结果没有问题:
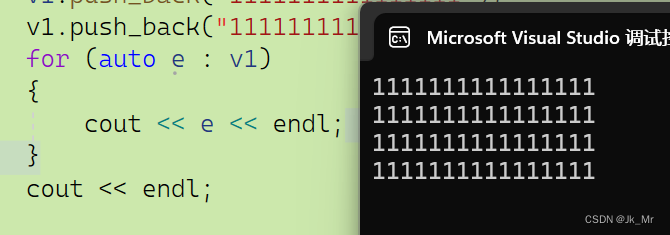
而再插入一个string会发生意料之外的结果: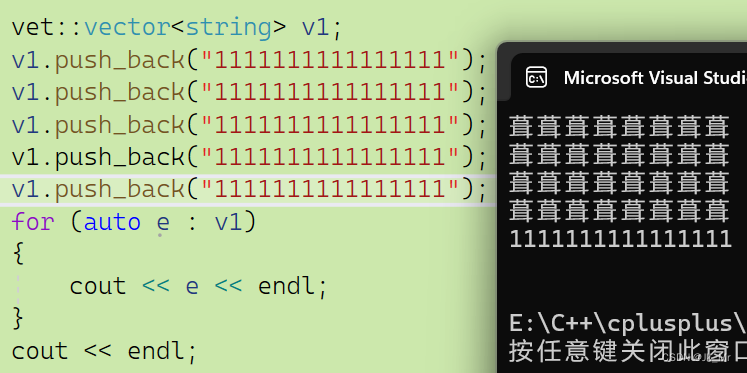
程序崩溃了。这是为什么?关键就在我们多插入的一次,通过调试观察:
到这没有什么问题,然后进memcpy,释放就释放旧空间。
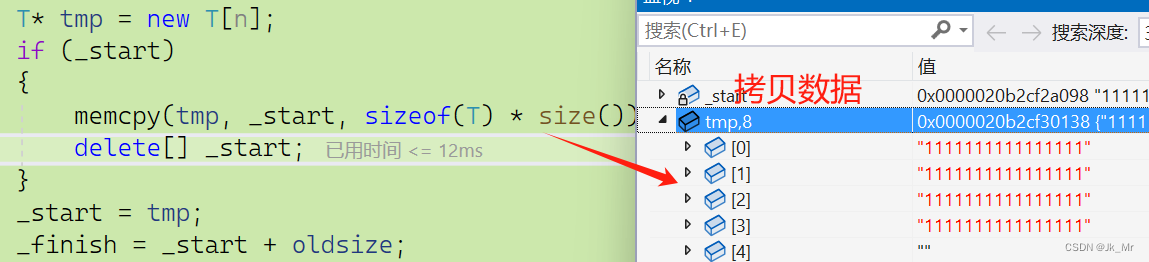
释放旧空间:

走早这里已经知晓了为什么会改变了,释放的空间是我们拷贝的空间,这样的情况就是浅拷贝。
画图进行分析:
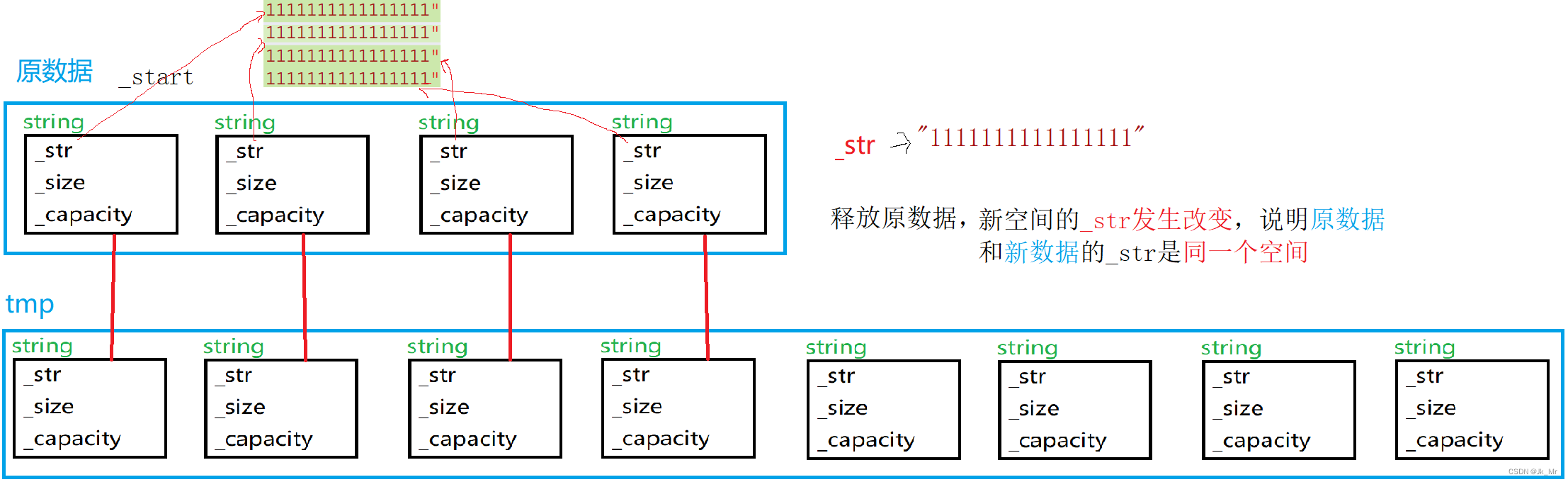
memcpy对任意类型数据拷贝是浅拷贝。memcpy对数据一个字节一个字节拷贝。在对_start进行释放时,string会调用析构函数,对其中的_str进行释放。
解决方案:进行深拷贝:
void reserve(size_t n){size_t oldsize = size();if (n > capacity()){T* tmp = new T[n];if (_start){//memcpy(tmp, _start, sizeof(T) * size());for (size_t i = 0; i < oldsize; i++){//进行赋值//内置类型进行赋值,自定义类型调用它的赋值操作tmp[i] = _start[i];}delete[] _start;}_start = tmp;_finish = _start + oldsize;_end_of_storage = _start + n;}}进行赋值,内置类型进行赋值,自定义类型调用它的赋值操作。在这里tmp[i]和_start[i]相当于是
string对象进行赋值。
如果你有所收获,可以留下你的点赞和关注,谢谢你的观看!
相关文章:
C++vector的简单模拟实现
文章目录 目录 文章目录 前言 一、vector使用时的注意事项 1.typedef的类型 2.vector不是string 3.vector 4.算法sort 二、vector的实现 1.通过源码进行猜测vector的结构 2.初步vector的构建 2.1 成员变量 2.2成员函数 2.2.1尾插和扩容 2.2.2operator[] 2.2.3 迭代器 2…...
AWTK实现汽车仪表Cluster/DashBoard嵌入式GUI开发(七):快启
前言: 汽车仪表是人们了解汽车状况的窗口,而仪表中的大部分信息都是以指示灯形式显示给驾驶者。仪表指示灯图案都较为抽象,对驾驶不熟悉的人在理解仪表指示灯含义方面存在不同程度的困难,尤其对于驾驶新手,如果对指示灯的含义不求甚解,有可能影响驾驶的安全性。即使是对…...
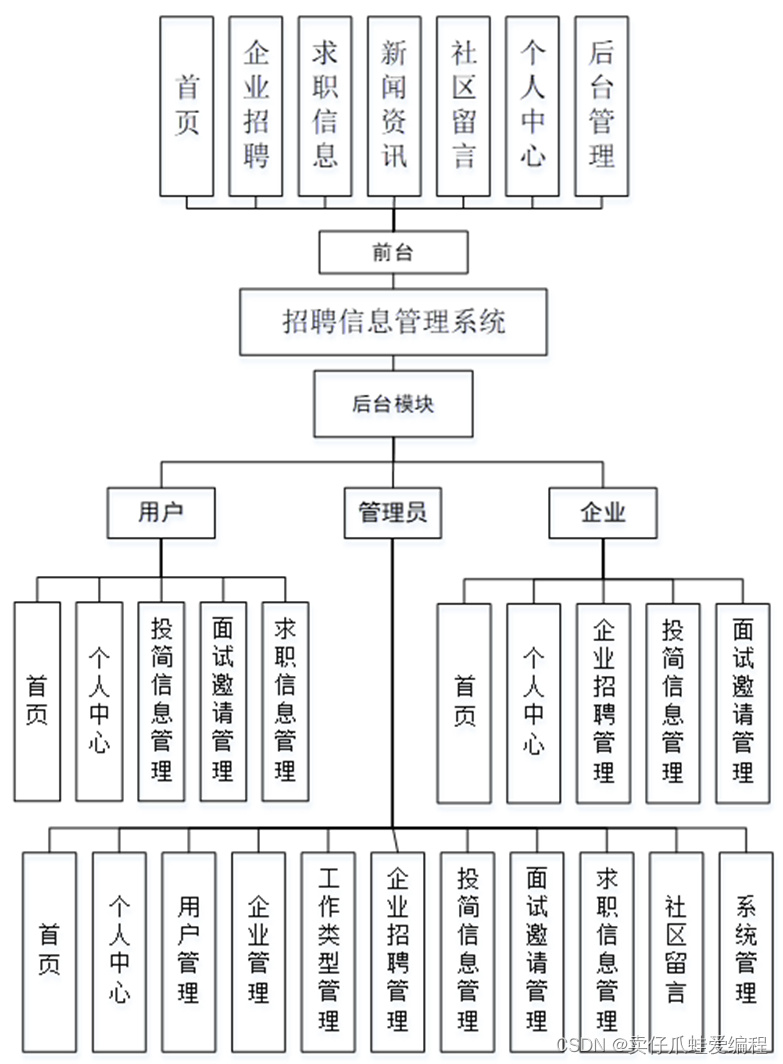
基于springboot+vue的招聘信息管理系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

使用STM32F103标准库实现自定义键盘
使用STM32F103标准库实现自定义键盘 在嵌入式系统中,自定义键盘的实现是一个经典的项目,能够帮助我们深入理解GPIO配置、按键扫描和中断处理等知识。本文将详细介绍如何使用STM32F103标准库来实现一个简单的自定义键盘。 1. 准备工作 1.1 硬件准备 S…...
面试八股之JVM篇3.5——垃圾回收——G1垃圾回收器
🌈hello,你好鸭,我是Ethan,一名不断学习的码农,很高兴你能来阅读。 ✔️目前博客主要更新Java系列、项目案例、计算机必学四件套等。 🏃人生之义,在于追求,不在成败,勤通…...
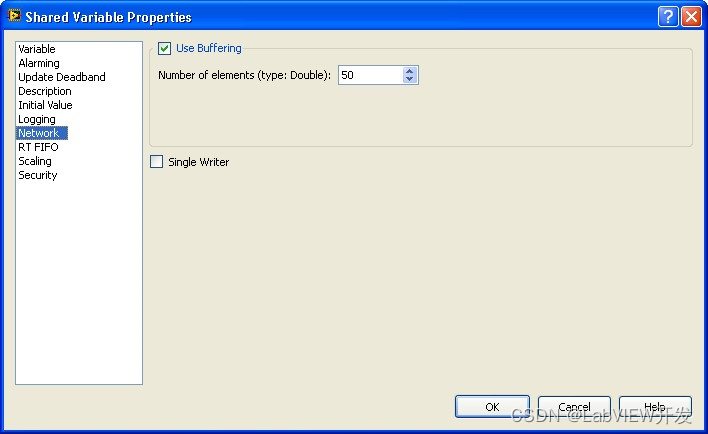
解决LabVIEW通过OPC Server读取PLC地址时的错误180121602
在使用LabVIEW通过OPC Server读取PLC地址时,若遇到错误代码180121602,建议检查网络连接、OPC Server和PLC配置、用户权限及LabVIEW设置。确保网络畅通,正确配置OPC变量,取消缓冲设置以实时读取数据,并使用诊断工具验证…...

npm,yarn,cnpm,tyarn,pnpm 安使用装配置镜像
npm 安装 安装node后就可以使用了 官方默认地址 npm config set registry https://registry.npmjs.org 镜像 npm config set registry https://registry.npm.taobao.org npm config set registry http://registry.npmmirror.org全局安装依赖 npm install -g <包名&g…...

使用python将一段文本写入一个txt文件中且先格式化文件名
有一段文本内容,有“标题”和“内容”组成。 任务:要将这段文本,存放到一个txt文件中,文件名为当天的日期加上“标题”内容。因为“标题”内可能有/<>之类的,还需要格式化一下。 已经将上述功能都写成了函数&a…...

前端 CSS 经典:元素倒影
前言:好看的元素倒影,可以通过-webkit-box-reflect 实现。但有兼容问题,必须是 webkit 内核的浏览器,不然没效果。但是好看啊。 效果图: 代码实现: <!DOCTYPE html> <html lang"en"&g…...

ROS学习记录:用C++实现IMU航向锁定
前言 获取IMU数据的C节点 在了解了如何获取到IMU的姿态信息(链接在上面)后,接下来尝试实现让一个节点在订阅IMU数据的时候,还能发布运动控制指令,使机器人能对姿态变化做出反应,达到一个航向锁定的效果。 …...

设计模式-策略模式-使用
设计模式-策略模式-CSDN博客 系统中有很多类,它们之间的区别仅在于它们的行为。策略模式可以定义一系列的算法,并将它们一个个封装起来,使它们可以相互替换。这样,算法就可以独立于使用它的客户而变化。需要使用算法的不同变体。…...

WebSocket——相关介绍以及后端配置
一、WebSocket介绍: WebSocket是一种在单个TCP连接上进行全双工通信的协议,旨在改进客户端和服务器之间的实时通信。以下是关于WebSocket的详细介绍: 1、定义与标准 WebSocket是独立的、创建在TCP上的协议,通过HTTP/1.1协议的10…...
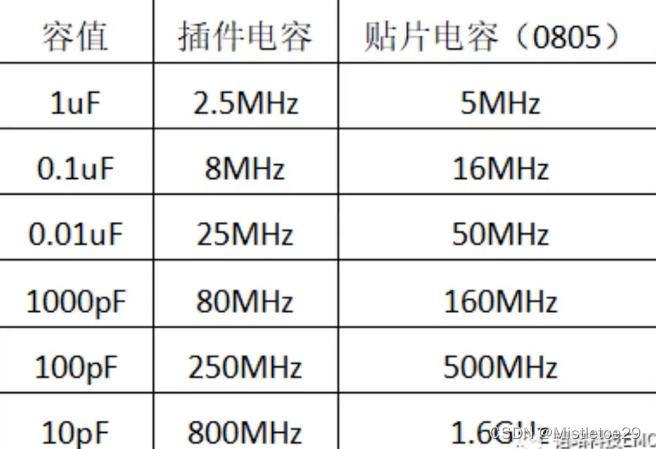
单片机设计注意事项
1.电源线可以30mil走线,信号线可以6mil走线 2.LDO推荐 SGM2019-3.3,RT9013,RT9193,1117-3.3V。 3.单片机VCC要充分滤波后再供电,可以接0.1uf的电容 4.晶振附件不要走其他元件,且放置完单片机后就放置晶振,晶振靠近X1,X2。...

Ubuntu 如何根据NVIDIA显卡型号确定对应的显卡驱动版本并安装
目录 一、查询推荐安装的驱动版本 二、安装推荐版本的驱动 1. 通过终端安装,只安装 nvidia 驱动(亲测可用!) 2. 通过 software & Updates 安装,安装 nvidia 驱动。 三、查询能安装的最新的显卡驱动版本 1. 方…...

如何选择一款安全高效的数据自动同步工具?
随着科技的不断发展,企业处理的数据量愈发庞大。数字化浪潮的涌现使得数据在业务活动和决策中的角色变得日益重要,然而这些数据往往分布在不同的位置,需要进行同步和分类,以便更有效地利用。以下是一些常见的数据自动同步场景&…...
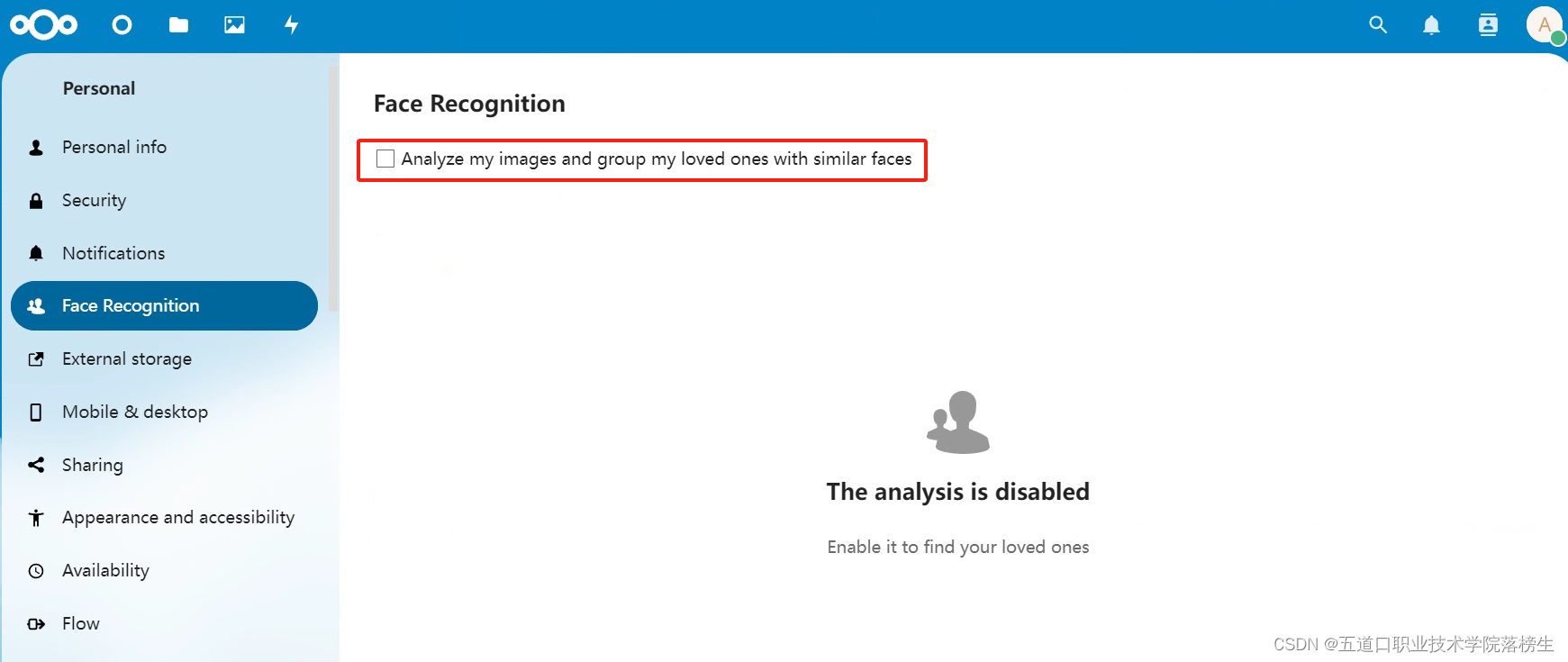
【linux】docker下nextcloud安装人脸识别插件
一、插件源码地址: GitCode - 开发者的代码家园 二、插件官网地址: Releases - Face Recognition - Apps - App Store - Nextcloud 三、插件安装教程: 1、查看本地nextcloud版本号 http://ipAddress:8080/settings/admin/overview 2、找…...

2. C++服务器编程-信号
什么是信号 其实信号就是一个中断。就是在执行程序的时候突然来了一个信号,然后我们去执行这个新来的程序了,这就是中断。 处理方法 信号的处理方式∶忽略、捕获、默认处理 linux中都有那些信号 man7 signal 比如说kill -9 安装man中文手册 自己百…...
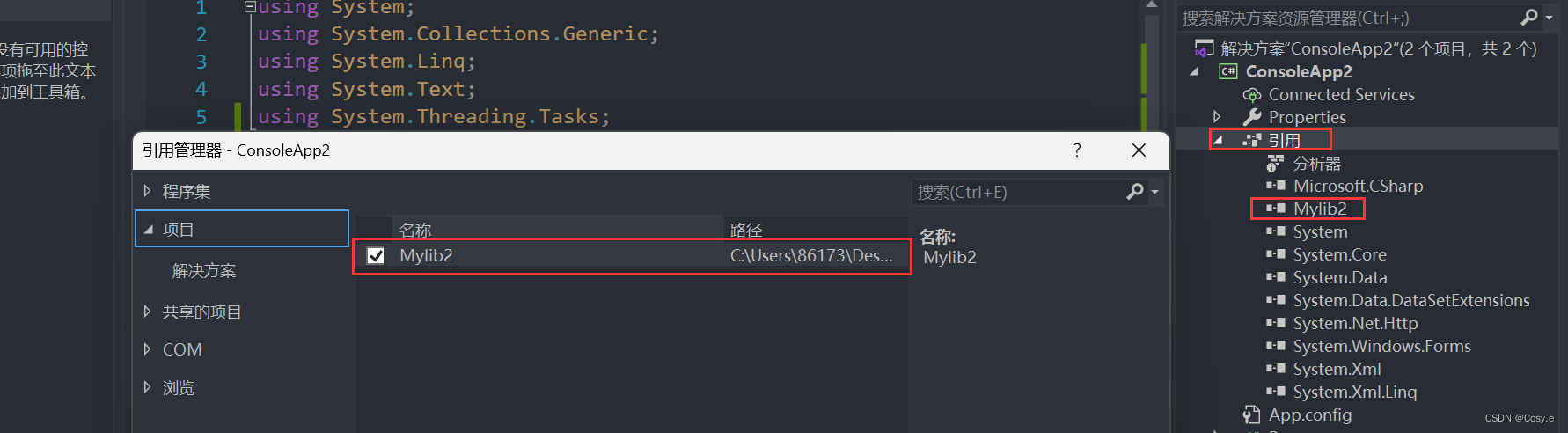
C#_库的引用
类库的引用 还可以自己引用类库:解决方案-添加-新建项目 主程序 using System; using System.Windows.Forms; using Tools;namespace ConsoleApp2 {class Program{static void Main(string[] args){//Console.WriteLine("helloword");// Form form ne…...

C++:STL—算法
C:STL—算法 算法 算法 STL(Standard Template Library)中的算法是为了操作数据集合(如容器)而设计的函数模板集合,它们提供了丰富的功能和灵活的接口,可以用于对数据进行排序、查找、遍历等操作。STL中的…...
深入探索:移动云服务器的强大之处
文章目录 一 什么是移动云二 移动云服务器的使用三 移动云服务器的优点四 在移动云上部署node.js项目五 移动云服务器的应用场景六 移动云服务器的使用体验总结 一 什么是移动云 移动云是指用户可以通过移动设备访问云端的数据和应用,无需在本地设备上进行存储和处…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...