MySQL之Schema与数据类型优化(三)
Schema与数据类型优化
BLOB和TEXT类型
BLOB和TEXT都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。
实际上它们分别属于两组不同的数据类型家族:字符类型是TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONGTEXT;对应的二进制类型是TINYBLOB,SMALLBLOB,BLOB,MEDIUMBLOB,LONGBLOB.BLOB是SMALLBLOB的同义词,TEXT是SMALLTEXT的同义词。
与其他类型不同,MySQL把每个BLOB和TEXT值当作一个独立的对象处理。存储引擎在存储时通常会做特殊处理。当BLOB和TEXT值太大时,InnoDB会使用专门的"外部"存储区域来进行存储,此时每个值在行内需要1~4个字节存储一个指针,然后再外部存储区域存储实际的值。
BLOB和TEXT家族之间仅有的不同时BLOB类型存储的是二进制数据,没有排序规则或字符集,而TEXT类型有字符集和排序规则。
MySQL对BLOB和TEXT列进行排序与其他类型是不同的:它只对每个列的最前max_sort_length字节而不是整个字符串做排序。如果只需要排序前面一小部分字符,则可以减小max_sort_length的配置,或者使用ORDER BY SUBSTRING(column, length).
MySQL不能将BLOB和TEXT列全部长度的字符串进行索引,也不能使用这些索引消除排序
磁盘临时表和文件排序
因为Memory引擎不支持BLOB和TEXT类型,所以,如果查询使用了BLOB或TEXT列并且需要使用隐式临时表,将不得不使用MyISAM磁盘临时表。即使只有几行数据也是如此(Percona Server的Memory引擎支持BLOB和TEXT类型,同样的场景下还是需要使用磁盘临时表)。这会导致严重的性能开销。即使配置MySQL将临时表存储再内存块设备上(RAM Disk),依然需要许多昂贵的系统调用。最好的解决方案是尽量避免使用BLOB和TEXT类型。如果实在无法避免,有一个技巧是在所有用到BLOB字段的地方都使用SUBSTRING(column, length)将列值转换为字符串(在ORDER BY 子句中也适用),这样就可以使用内存临时表了。但是要确保截取的子字符串足够短,不会使临时表的大小超过max_heap_table_size或tmp_table_size,超过以后MySQL会将内存临时表转换为MyISAM磁盘临时表。
最坏情况下的长度分配对于排序的时候也是一样的,所以这一招对于内存中创建大临时表和文件排序,以及在磁盘上创建大临时表和文件排序这两种情况都很有帮助。
例如,假设有一个1000万行的表,占用几个GB的磁盘空间。其中有一个uft8字符集的VARCHAR(1000)的列,每个字符最多使用3个字节,最坏情况下需要3000字节的空间。如果在ORDER BY 中用到这个列,并且查询扫描整个表,为了排序就需要超过30GB的临时表。
如果EXPLAIN执行计划的Extra列包含了"Using temporary",则说明这个查询使用了隐式临时表
使用枚举类型(ENUM)代替字符串类型
有时候可以使用枚举列代替常用的字符串类型。枚举列可以把一些不重复的字符串存储成一个预定义的集合。MySQL在存储枚举时非常紧凑,会根据列表值得数量压缩到一个或者两个字节中。MySQL会在内部将每个值在列表中得为止保存为整数,并且在表的.frm文件中保存"数字-字符串"映射关系的"查找表",
例如,
mysql> CREATE TABLE enum_test(e ENUM('fish', 'apple', 'dog') NOT NULL);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO enum_test(e) VALUES('fish'), ('dog'),('apple');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
这三行数据实际存储为整数,而不是字符串。可以通过在数字上下问环境检索看到这个双重属性:
mysql> SELECT e+0 FROM enum_test;
+-----+
| e+0 |
+-----+
| 1 |
| 3 |
| 2 |
+-----+
3 rows in set (0.05 sec)
如果使用数字作为ENUM枚举常量,这种双重性很容易导致混乱,例如ENUM(‘1’,‘2’,‘3’).建议尽量避免这么做。另外一个让人吃惊的地方时,枚举字段是按照内部存储的整数而不是定义的字符串进行排序的:
mysql> SELECT e FROM enum_test ORDER BY e;
+-------+
| e |
+-------+
| fish |
| apple |
| dog |
+-------+
3 rows in set (0.05 sec)
一种绕过这种限制的方式是按照需要的顺序来定义枚举列。另外也可以在查询中使用FIELD()函数显式地指定排序顺序,但这会导致MySQL无法利用索引消除排序。
mysql> SELECT e FROM enum_test ORDER BY FIELD(e, 'apple', 'dog','fish');
+-------+
| e |
+-------+
| apple |
| dog |
| fish |
+-------+
3 rows in set (0.07 sec)
如果在定义时就是按照字母的顺序,就没有必要这么做了。枚举最不好的地方是,字符串列表是固定的,添加或删除字符串必须使用ALTER TABLE,因此,对于一系列未来可能会改变的字符串,使用枚举不是一个好主意,除非能接受只在列表末尾添加元素,这样在MySQL5.1中就可以不用重建整个表来完成修改。
由于MySQL把每个枚举值保存为整数,并且必须进行查找才能转换为字符串,所以枚举列有一些开销。通常枚举的列表都比较小,所以开销还可以控制,但也不能保证一直如此。在特定情况下,把CHAR/VARCHAR列与枚举列进行关联可能会比直接关联(CHAR/VARCHAR)列更慢。
为了说明这个情况,读一个应用中的一张表进行了基准测试,看看在MySQL中执行上面说的关联的速度如何。该表有一个很大的主键:
CREATE TABLE webservicecalls(
day date NOT NULL,
account smallint NOT NULL,
service varchar(10) NOT NULL,
method varchar(50) NOT NULL,
calls int NOT NULL,
items int NOT NULL,
time float NOT NULL,
cost decimal(9,5) NOT NULL,
updated datetime,
PRIMARY KEY(day,account, service, method)
) ENGINE=InnoDB;
这个表有11万行数据,只有10MB大小,所以可以完全载入内存。service列包含了5个不同的值,平均长度为4个字符,method列包含了71个值,平均产犊为20个字符。
复制一下这个表,但是把service和method字段换成枚举类型,表结构如下:
CREATE TABLE webservicecalls_enum(
...omitted...
service ENUM(... VALUES omitted ...) NOT NULL,
method ENUM(... VALUES omitted ...) NOT NULL,
...omitted...
) ENGINE=InnoDB;
然后我们用主键列关联这两个表,下面是所使用的查询语句:
mysql> SELECT SQL_NO_CACHE COUNT(*) FROM webservicecalls JOIN webservicecalls USING(day, account,service,method);
用VARCHAR和ENUM分别测试了这个语句,结果如表所示
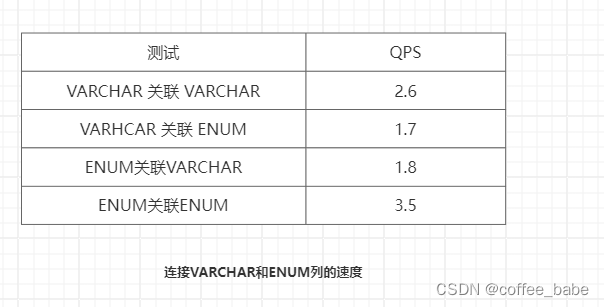
从上面的结果可以看到,当把列都转换成ENUM以后,关联变得很快。但是当VARCHAR列和ENUM列进行关联时则慢很多。在本例中,如果不是必须和VARCHAR列进行关联,那么转换这些列为ENUM就是个好主意。这是一个通用的设计时间,在"查找表"时采用整数主键而避免采用基于字符串的值进行关联。然而,转换列为枚举型还有另外一个好处。根据SHOW TABLE STATUS命令输出结果中Data_length列的值,把这两列转换为ENUM可以让表的大小缩小1/3.在某些情况下,即使可能出现ENUM和VARCHAR进行关联的情况,这也是值得的(这很可能可以节省IO)。同样,转换后主键也只有原来的一半大小了,因为这是InnoDB表,如果表上有其他索引,减小主键大小会使得非主键索引也变得更小。

(该图只是查询Data_length,与上面的例子无关)
相关文章:
MySQL之Schema与数据类型优化(三)
Schema与数据类型优化 BLOB和TEXT类型 BLOB和TEXT都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。 实际上它们分别属于两组不同的数据类型家族:字符类型是TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONG…...

大语言模型发展历史
大语言模型的发展历史可以追溯到自然语言处理(NLP)和机器学习早期的探索,但真正快速发展起来是在深度学习技术兴起之后。以下是大语言模型发展的一个简要历史概述: 早期阶段(20世纪50-90年代): …...

Nginx - 安全基线配置与操作指南
文章目录 概述中间件安全基线配置手册1. 概述1.1 目的1.2 适用范围 2. Nginx基线配置2.1 版本说明2.2 安装目录2.3 用户创建2.4 二进制文件权限2.5 关闭服务器标记2.6 设置 timeout2.7 设置 NGINX 缓冲区2.8 日志配置2.9 日志切割2.10 限制访问 IP2.11 限制仅允许域名访问2.12 …...

简述js的事件循环以及宏任务和微任务
前言 在JavaScript中,任务被分为同步任务和异步任务。 同步任务:这些任务在主线程上顺序执行,不会进入任务队列,而是直接在主线程上排队等待执行。每个同步任务都会阻塞后续任务的执行,直到它自身完成。常见的同步任…...

[力扣题解] 797. 所有可能的路径
题目:797. 所有可能的路径 思路 深度搜索 代码 // 图论哦!class Solution { private:vector<vector<int>> result;vector<int> path;// x : 当前节点void function(vector<vector<int>>& graph, int x){int i;// cout <&l…...

【QT八股文】系列之篇章3 | QT的多线程以及QThread与QObject
【QT八股文】系列之篇章3 | QT的多线程 前言4. 多线程为什么需要使用线程池线程池的基础知识python中创建线程池的方法使用threading库队列Queue来实现线程池使用threadpool模块,这是个python的第三方模块,支持python2和python3 QThread的定义QT多线程知…...

基于python flask的web服务
基本例子 from flask import Flask app Flask(__name__) app.route(/)#检查访问的网址,根路径走这里 def hello_world():return hello world#返回hello worldif __name__ __main__:# 绑定到指定的IP地址和端口app.run(host0.0.0.0, port1000, debugTrue)##绑定端…...

HTTP 响应分割漏洞
HTTP 响应分割漏洞 1.漏洞概述2.漏洞案例 1.漏洞概述 HTTP 响应拆分发生在以下情况: 数据通过不受信任的来源(最常见的是 HTTP 请求)进入 Web 应用程序。该数据包含在发送给 Web 用户的 HTTP 响应标头中,且未经过恶意字符验证。…...

Algoriddim djay Pro Ai for Mac:AI引领,混音新篇章
当AI遇上音乐,会碰撞出怎样的火花?Algoriddim djay Pro Ai for Mac给出了答案。这款专业的DJ混音软件,以AI为引擎,引领我们进入混音的新篇章。 djay Pro Ai for Mac的智能混音功能,让每一位DJ都能感受到前所未有的创作…...

常见算法(3)
1.Arrays 它是一个工具类,主要掌握的其中一个方法是srot(数组,排序规则)。 o1-o2是升序排列,o2-o1是降序排列。 package test02; import java.util.ArrayList; import java.util.Arrays; import java.util.Comparat…...

集中抄表电表是什么?
1.集中抄表电表:简述 集中抄表电表,又称为远程抄表系统,是一种现代化电力计量技术,为提升电力行业的经营效率和客户服务质量。它通过自动化的形式,取代了传统人工抄水表,完成了数据信息实时、精确、高效率…...

第八届能源、环境与材料科学国际学术会议(EEMS 2024)
文章目录 一、重要信息二、大会简介三、委员会四、征稿主题五、论文出版六、会议议程七、出版信息八、征稿编辑 一、重要信息 会议官网:http://ic-eems.com主办方:常州大学大会时间:2024年06月7-9日大会地点:新加坡 Holiday Inn …...
09.自注意力机制
文章目录 输入输出运行如何运行解决关联性attention score额外的Q K V Multi-head self-attentionPositional EncodingTruncated Self-attention影像处理vs CNNvs RNN图上的应用 输入 输出 运行 链接(Attention Is All You Need) 如何运行 解决关联性 a…...

时政|杂粮产业
政策支持 《新一轮千亿斤粮食产能提升行动方案(2024—2030年)》明确,按照“巩固提升口粮、主攻玉米大豆、兼顾薯类杂粮”的思路,因地制宜发展马铃薯、杂粮杂豆等品种,根据市场需求优产稳供。 产地发展 河北省石家庄…...

docker 安装 私有云盘 nextcloud
拉取镜像 # 拉取镜像 sudo docker pull nextcloud运行nextcloud 容器 # 内存足够可以不进行内存 --memory512m --memory-swap6g # 桥接网络 --network suixinnet --network-alias nextcloud \ sudo docker run -itd --name nextcloud --restartalways \ -p 9999:80 \ -v /m…...

第十一届蓝桥杯物联网试题(国赛)
国赛题目看着简单其实还是挺复杂的,所以说不能掉以轻心,目前遇到的问日主要有以下几点: 本次题主要注重的是信息交互,与A板通信的有电脑主机和B板,所以处理好这里面的交互过程很重要 国赛中避免不了会收到其他选手的…...

算法金 | Dask,一个超强的 python 库
本文来源公众号“算法金”,仅用于学术分享,侵权删,干货满满。 原文链接:Dask,一个超强的 python 库 1 Dask 概览 在数据科学和大数据处理的领域,高效处理海量数据一直是一项挑战。 为了应对这一挑战&am…...

Java 说唱歌手
Yo yo yo,欢迎来到Java地带,技术的盛宴开启, 从JDK到JVM,我们构建的是数字世界的奇迹。 Spring Boot启动,微服务架构轻盈起舞, IoC解耦依赖,AOP切面如丝般顺滑。 Maven管理依赖,Gra…...
面试-软件工程与设计模式相关,Spring简介
面试-软件工程与设计模式相关,Spring简介 1.编程思想1.1 面向过程编程1.2 面向对象编程1.2.1 面向对象编程三大特征 1.3 面向切面编程1.3.1 原理1.3.2 大白话?1.3.3 名词解释1.3.4 实现 2. 耦合与内聚2.1 耦合性2.2 内聚性 3. 设计模式3.1 设计模型七大原…...
IDEA中一些常见操作【持续更新】
文章目录 前言善用debugidea中debug按钮不显示自动定位文件【始终选择打开的文件】idea注释不顶格【不在行首】快速定位类的位置【找文件非常快】创建文件添加作者及时间信息快速跳转到文件顶端 底端 前言 因为这些操作偶尔操作一次,不用刻意记忆,有个印…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...

如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程 第一次用降AI工具有很多不确定——传什么格式、选哪个模式、怎么验收。 这篇教程把金融学论文降AI教程的常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&#x…...

10.刷机变砖、IMEI 丢失、基带未知、触控失灵?一站式终极修复方案
摘要 本文面向具备基础计算机操作能力的维修从业者与高级用户,系统讲解当前主流品牌手机(华为、小米、OPPO、vivo、一加、苹果)的刷机与维修核心流程。内容涵盖底层引导架构差异、Fastboot/Recovery/DFU模式操作规范、分区表保护策略、驱动兼容性处理以及常见硬件故障的软件…...