算法金 | Dask,一个超强的 python 库
本文来源公众号“算法金”,仅用于学术分享,侵权删,干货满满。
原文链接:Dask,一个超强的 python 库
1 Dask 概览
在数据科学和大数据处理的领域,高效处理海量数据一直是一项挑战。
为了应对这一挑战,我们需要强大而灵活的工具。今天,我将向大家介绍一款备受瞩目的 Python 库 —— Dask。

Dask 是一款用于并行计算的灵活、开源的库,它使得处理大规模数据变得更加容易。
Dask 提供了动态的并行计算工具,可以在单机或分布式系统上运行,让我们能够处理比内存更大的数据集。
https://github.com/dask/dask
1.1 Dask 的核心概念
Dask 的核心概念之一是分布式。它能够在集群上运行任务,通过分布式计算来加速处理。
此外,Dask 还支持延迟计算,这意味着它只在需要时才会计算结果,避免了不必要的计算开销。
1.2 Dask 的优势
-
可扩展性:Dask 可以轻松扩展到集群中的多台机器,处理比内存更大的数据集。
-
灵活性:Dask 与众多常用的 Python 数据科学库(如 NumPy、Pandas)兼容,使得迁移现有代码变得更加容易。
-
动态计算:Dask 采用延迟计算,只有在需要时才计算结果,提高了计算效率。
1.3 安装 Dask
首先,让我们来安装 Dask。打开你的终端并输入以下命令:
pip install dask1.4 使用 Dask 处理数据
让我们通过一个简单的例子来演示如何使用 Dask 处理数据。
假设我们有一个大型的CSV文件,我们想要计算某一列的平均值。
import dask.dataframe as dd# 读取大型CSV文件
df = dd.read_csv('large_dataset.csv')# 计算某一列的平均值
result = df['column_name'].mean()# 打印结果
print(result.compute())2 一个具体示例:传感器数据处理
案例:对比 Pandas 与 Dask 在大规模传感器数据处理上的性能,一起来看看吧。
创造一个大规模的传感器数据集,包含传感器ID、时间戳、测量值等信息。使用 Pandas 和 Dask 进行数据处理,如计算每个传感器的平均测量值。
-
首先,我们生成一个包含传感器ID、时间戳和测量值的大规模传感器数据集。
-
然后,我们使用 Pandas 和 Dask 分别进行数据处理,通过对比运行时间来展示 Dask 在大规模数据集上的性能优势。
import numpy as np
import pandas as pd
import dask.dataframe as dd
from datetime import datetime# 生成大规模传感器数据集
sensor_ids = np.random.randint(low=1, high=101, size=10**6)
timestamps = pd.date_range(start=datetime(year=2022, month=1, day=1), periods=10**6, freq='T')
measurements = np.random.random(size=10**6) * 100df_sensor = pd.DataFrame({'SensorID': sensor_ids,'Timestamp': timestamps,'Measurement': measurements
})df_sensor.to_csv('large_sensor_data.csv', index=False)# 使用 Pandas 进行数据处理并建立性能基线
def pandas_data_processing():df_pandas = pd.read_csv('large_sensor_data.csv')result = df_pandas.groupby('SensorID').agg({'Measurement': 'mean'})%timeit pandas_data_processing()输出:
2.48 s ± 814 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
可以观察到,使用Pandas进行groupby操作需要耗费2.48秒的时间。
现在,我们切换到Dask,运行相同的groupby查询。
# 使用 Dask 读取大型传感器数据 CSV 文件
ddf_sensor = dd.read_csv('large_sensor_data.csv')# 使用 Dask 进行相同的数据处理
def dask_data_processing():result_dask = ddf_sensor.groupby('SensorID').agg({'Measurement': 'mean'}).compute()%timeit dask_data_processing()输出:
5.48 ms ± 592 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
对于相似的任务,Dask的处理速度仅需5.48毫秒,这意味着性能有了明显的提升。
对比:
在Pandas执行groupby操作时,运算时间长达2.48秒。
而通过使用Dask进行相同的groupby查询,在相同的操作下,Dask仅需5.48毫秒,性能得到了显著的改善。
3 Dask 使用示例
Dask 团队贴心的提供了一系列的使用示例
Basic Examples
-
Dask数组
-
Dask Bags
-
Dask数据框
-
使用Dask Delayed进行自定义工作负载
-
自定义工作负载
-
Dask用于机器学习
-
在SQL上操作Dask数据框
-
Xarray与Dask数组
-
抵御硬件故障
Dataframes
-
数据框:读取和写入数据
-
数据框:按组操作
-
从Pandas到Dask的注意事项
-
创建两个进行比较的数据框:
-
Dask数据框 vs Pandas数据框
-
读取/保存文件
-
按组聚合 - 自定义聚合
-
数据框:读取混乱数据
-
制造一些混乱的数据
-
读取混乱的数据
-
构建延迟读取器
-
组装Dask数据框
Machine Learning
-
块状集成方法
-
将Scikit-Learn扩展到小数据问题
-
评分和预测大型数据集
-
使用PyTorch进行批处理预测
-
在大型数据集上训练模型
-
逐步训练大型数据集
-
文本矢量化管道
-
使用Dask进行超参数优化
-
扩展XGBoost
-
使用投票分类器
-
使用TPOT自动化机器学习
-
广义线性模型
-
奇异值分解
Applications
-
分析托管在Web上的JSON数据
-
异步/等待和非阻塞执行
-
异步计算:Web服务器 + Dask
-
尴尬的并行工作负载
-
处理不断变化的工作流程
-
图像处理
-
使用Prefect进行ETL流水线
-
使用Numba进行模板计算
-
时间序列预测
总结
Dask 是处理大规模数据的一项重要工具,它的灵活性和可扩展性使其在数据科学领域备受欢迎。
通过这篇简要介绍,相信你对 Dask 已经有了初步了解。
如果你处理的数据量较大,或者希望提高数据处理效率,不妨尝试在你的项目中引入 Dask,开启大数据处理的新境界。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
相关文章:

算法金 | Dask,一个超强的 python 库
本文来源公众号“算法金”,仅用于学术分享,侵权删,干货满满。 原文链接:Dask,一个超强的 python 库 1 Dask 概览 在数据科学和大数据处理的领域,高效处理海量数据一直是一项挑战。 为了应对这一挑战&am…...

Java 说唱歌手
Yo yo yo,欢迎来到Java地带,技术的盛宴开启, 从JDK到JVM,我们构建的是数字世界的奇迹。 Spring Boot启动,微服务架构轻盈起舞, IoC解耦依赖,AOP切面如丝般顺滑。 Maven管理依赖,Gra…...
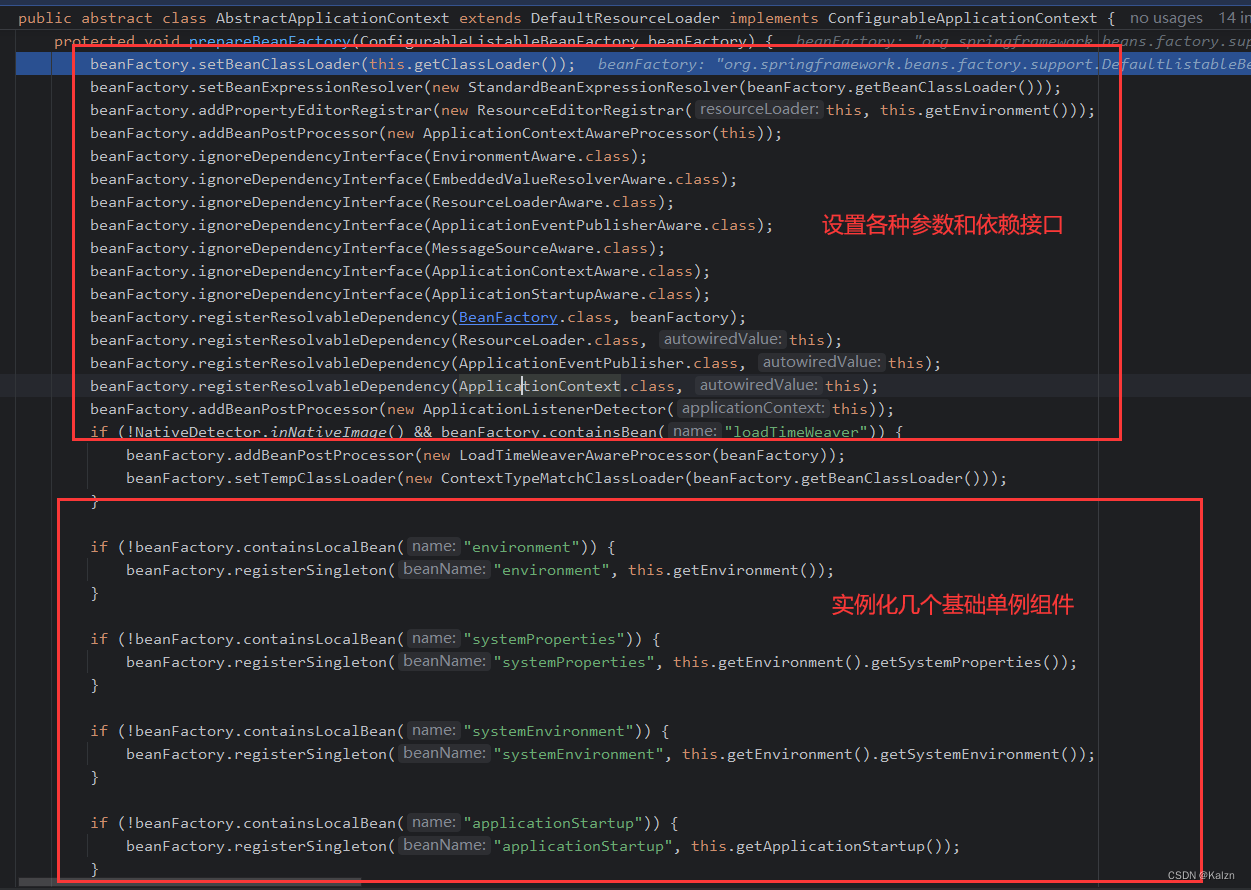
面试-软件工程与设计模式相关,Spring简介
面试-软件工程与设计模式相关,Spring简介 1.编程思想1.1 面向过程编程1.2 面向对象编程1.2.1 面向对象编程三大特征 1.3 面向切面编程1.3.1 原理1.3.2 大白话?1.3.3 名词解释1.3.4 实现 2. 耦合与内聚2.1 耦合性2.2 内聚性 3. 设计模式3.1 设计模型七大原…...
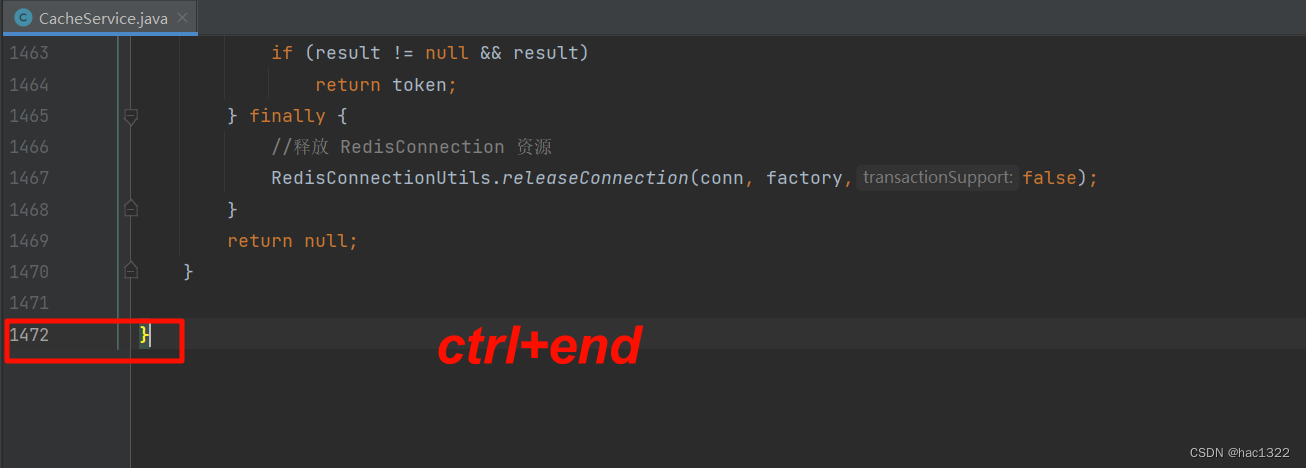
IDEA中一些常见操作【持续更新】
文章目录 前言善用debugidea中debug按钮不显示自动定位文件【始终选择打开的文件】idea注释不顶格【不在行首】快速定位类的位置【找文件非常快】创建文件添加作者及时间信息快速跳转到文件顶端 底端 前言 因为这些操作偶尔操作一次,不用刻意记忆,有个印…...

java继承使用细节二
构造器 主类是无参构造器时会默认调用 public graduate() {// TODO Auto-generated constructor stub也就是说我这里要用构造器会直接调用父类。它是默认看不到的 ,System.out.println("graduate");} 但当主类是有参构造器如 public father_(int s,doubl…...
本地化库 - 平面类别(std::numpunct_byname) 表示系统提供的具名本地环境的 std::numpunct)
c++11 标准模板(STL)本地化库 - 平面类别(std::numpunct_byname) 表示系统提供的具名本地环境的 std::numpunct
本地化库 本地环境设施包含字符分类和字符串校对、数值、货币及日期/时间格式化和分析,以及消息取得的国际化支持。本地环境设置控制流 I/O 、正则表达式库和 C 标准库的其他组件的行为。 平面类别 表示系统提供的具名本地环境的 std::numpunct std::numpunct_byn…...
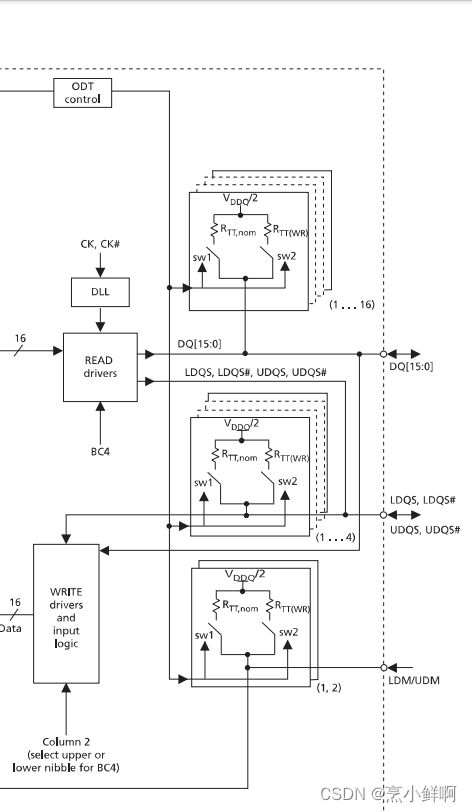
XILINX FPGA DDR 学习笔记(一)
DDR 内存的本质是数据的存储器,首先回到数据的存储上,数据在最底层的表现是地址。为了给每个数据进行存放并且在需要的时候读取这个数据,需要对数据在哪这个抽象的概念进行表述,我们科技树发展过程中把数据在哪用地址表示。一个数…...

vue源码2
vue之mustache库的机理其实是将模板字符串转化为tokens 然后再将 tokens 转化为 dom字符串,如下图 对于一般的将模板字符串转化为dom字符串,这样不能实现复杂的功能 let data {name:小王,age:18 } let templateStr <h1>我叫{{name}},我今年{{ag…...

Android四大组件 Broadcast广播机制
一 概述 广播 (Broadcast) 机制用于进程或线程间通信,广播分为广播发送和广播接收两个过程,其中广播接收者 BroadcastReceiver 是 Android 四大组件之一。BroadcastReceiver 分为两类: 静态广播接收者:通过 AndroidManifest.xm…...
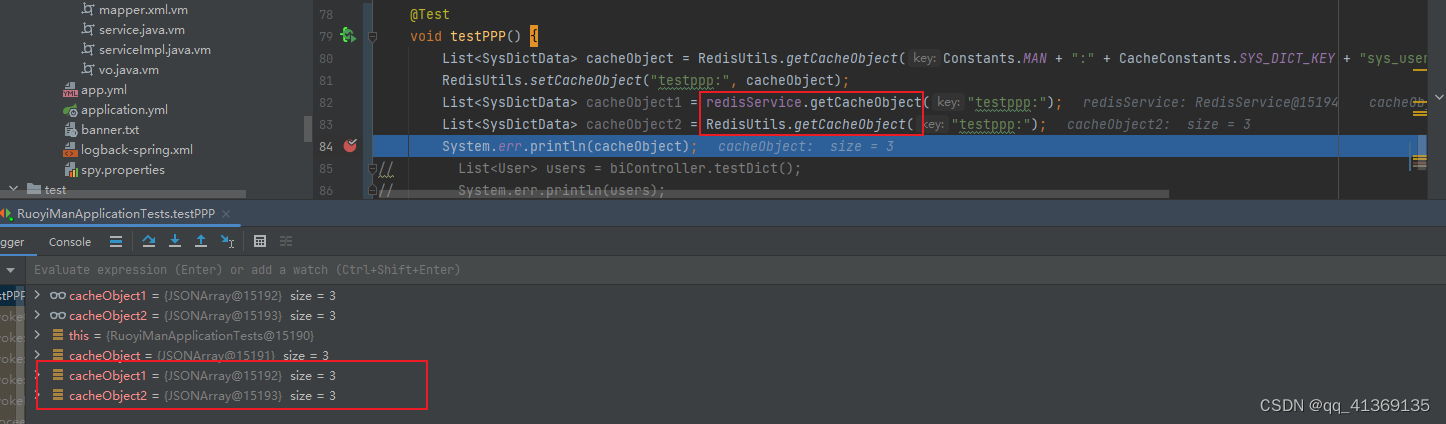
redisson 使用fastJson2序列化
前因:一个项目:有人用redisTemplete存数据(使用了fastjson2),使用redisson取的时候就会报错。要让redisTemplete与redisson序列化一致 一、自定义序列化器 import com.alibaba.fastjson2.JSON; import com.alibaba.fa…...

Python数据分析常用函数
Python基础 数字处理函数 Python提供了用于数字处理的内置函数和内置模块(math),使用内置模块,需要先导入 import math。 内置函数math模块abs(-5)返回绝对值math.ceil(2.3)返回不小于x的最小整数divmod(9,4)返回商和余数math.floor(2.3)返回不大于x的…...

C++ 数据结构算法 学习笔记(32) -五大排序算法
C 数据结构算法 学习笔记(32) -五大排序算法 选择算法 如下若有多个女生的身高需要做排序: 常规思维: 第一步先找出所有候选美女中身高最高的,与最后一个数交换 第二步再找出除最后一位美女外其它美女中的最高者,与倒数第二个美女交换位置 再找出除最…...

从入门到精通:详解Linux进程管理
前言 在这篇文章中,我将带领大家深入学习和理解Linux系统中的进程管理。无论你是初学者还是有一定经验的开发者,相信这篇文章都会对你有所帮助。我们将详细讲解冯诺依曼体系结构、操作系统概念、进程管理、进程调度、进程状态、环境变量、内存管理以及其…...

【Linux】如何在 Linux 系统中使用 envsubst 来处理 Nginx 配置模板
一、创建 nginx.template 模板文件 vim nginx.template复制下面文件内容 server { listen ${BY_PORT}; server_name ${BY_HOST}; location /sys/ { proxy_pass http://${BY_GRAFANA_HOST}:${BY_GRAFANA_PORT}/; } # 其他配置... }这个模板中包含了几个环境变量&#…...

【LeetCode】438.找到字符串中所有字母异位词
找到字符串中所有字母异位词 题目描述: 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。 示…...

力扣96. 不同的二叉搜索树
Problem: 96. 不同的二叉搜索树 文章目录 题目描述思路复杂度Code 题目描述 思路 一个数字做根节点的话可能的结果为:其左边数字做子树的组合数字乘以其右边数字做子树的个数之积 1.创建备忘录memo; 2.递归分别求取当前数字左边和右边数字做子树的数量&…...

哈希表的用途
...

k8s笔记 | 高度调度
CronJob计划任务 简介:在k8s中周期性运行计划任务,与linux中的crontab相同;注意点 CornJob执行的时间是controller-manager的时间,所以一定要确保controller-manager的时间是准确的,另外cornjob cron表达式 文章参…...

Rom应用开发遇到得一些小bug
记录一些细碎得bug ROM时间类问题 问题描述: 设备拔电重启,ROM时间为默认时间如1970年1月1日,与某些业务场景互斥 问题原因: 后台接口校验https证书校验失败,要求是2年内得请求头校验了时间戳,时间戳过期…...

Python简介
Python简介 1. Python定义 Python 是一种简单易学并且结合了解释性、编译性、互动性和面向对象的脚本语言。Python提供了高级数据结构,它的语法和动态类型以及解释性使它成为广大开发者的首选编程语言。 Python 是解释型语言: 开发过程中没有了编译这个环…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...

基于MAX78000的边缘AI语音识别:从模型训练到嵌入式部署实战
1. 项目概述与核心思路最近在捣鼓一个挺有意思的小项目,我把它叫做“声控转向控制器”。简单来说,这玩意儿能听懂你说的几个特定单词,比如“左转”、“右转”、“前进”、“后退”,然后控制对应的LED灯亮起。你可能会想࿰…...

还在古法编程?OpenAI Codex 全自动编程!稳定中转 Token 保姆级教程
OpenAI Codex 从安装到进阶实战|终端 AI 编程完全指南(2026 最新) 摘要:OpenAI Codex 是目前最强大的终端 AI 编程工具,支持代码生成、项目重构、Bug 修复、脚本自动化、批量代码优化等全场景能力。本文从零起步&…...