C++ 数据结构算法 学习笔记(32) -五大排序算法
C++ 数据结构算法 学习笔记(32) -五大排序算法
选择算法
如下若有多个女生的身高需要做排序:

常规思维:
- 第一步先找出所有候选美女中身高最高的,与最后一个数交换

- 第二步再找出除最后一位美女外其它美女中的最高者,与倒数第二个美女交换位置

- 再找出除最后两位美女外其它美女中的最高者,与倒数第三个美女交换位置,因为倒数 第三个本身已是最大的,所以实际无需交换.

- 重复以上步骤,直到最后只剩下一人,此时,所有的美女均已按照身高由矮到高的 顺序排列

代码实现:
#include<stdio.h>
#include<stdlib.h>
void swap(int* num1, int* num2)//交换两个变量的值
{int temp = *num1;*num1 = *num2;*num2 = temp;
}void SelectSort1(int arr[], int len) {for (int i = 0; i < len - 1; i++) {int max = 0;for (int j = 1; j < len - i; j++) { //查找未排序的元素if (arr[j] > arr[max]) { //找到目前最小值max = j;}}//printf("max:%dbeauties%d\n",max,len-i-1);if (max != (len - i - 1)) {swap(&arr[max], &arr[len - i - 1]);}}
}
void SelectSort2(int arr[], int len) {int i, j;for (i = 0; i < len - 1; i++){int min = i;for (j = i + 1; j < len; j++) { //查找未排序的元素if (arr[j] < arr[min]) { //找到目前最小值min = j; //记录最小值}}swap(&arr[min], &arr[i]); //交换}
}
int main(void) {int beauties[] = { 163,161,158,165,171,170,163,159,162 };int len = sizeof(beauties) / sizeof(beauties[0]);SelectSort2(beauties, len);for (int i = 0; i < len; i++) {printf("%d ", beauties[i]);}system("pause");
}
冒泡算法
当我们采用前面的选择排序时,我们仍然要将候选者遍历5遍,才能完成最终的排序,但其 实,本身这些美女出了第一个外,已经很有序了,我们只需要把第一个和第二个交换,然后又和 第三个交换,如此循环,直到和最后一个交换后,整个数组基本就有序了!

当然,并不是每次都这么幸运,像下面的情况就会更复杂一些,一趟并不能完全解决问题, 我们需要多趟才能解决问题.

经过上述五步后,得到的结果:

此时,我们只保障了最后一个数是最大的,并不能保障前面的数一定会有序,所以,我们继续按 照上面五步对剩下的5个数继续进行一次排序,数组就变得有序了. 以上过程就是冒泡排序:通过重复地遍历未排序的数列,一次比较两个元素,如果它们的顺 序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列 已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢得像泡泡一样“浮”到数 列的顶端,故而得名
代码实现:
#include <iostream>
#include <string>using namespace std;void swap(int* tmp1, int* tmp2)
{int tmp3 = *tmp1;*tmp1 = *tmp2;*tmp2 = tmp3;
}int main()
{int height2[] = { 156,162,161,172,167,169,155 };int height[] = { 155,158,161,163,172,174 };int size = sizeof(height) / sizeof(height[0]);for (int i = 0; i < size-1; i++){bool sorted = true;for (int j = 0; j < size-i-1; j++){if (height[j] > height[j+1]){ sorted = false;swap(&height[j], &height[j + 1]);}}if (sorted == true) break;}for (int i = 0; i < size; i++){cout << height[i] << " ";}system("pause");return 0;
}
插入排序

- 首先,我们只考虑第一个元素,从第一个元素171开始,该元素可以认为已经被排序;

-
取下一个元素161并记录,并让161所在位置空出来,在已经排序的元素序列中从后向前扫 描;

-
该元素(171)大于新元素,将该元素移到下一位置;

-
171前已经没有最大的元素了,则将161插入到空出的位置

-
取下一个元素163,并让163所在位置空出来,在已经排序的元素序列中从后向前扫描;

-
该元素(171)大于新元素163,将该元素移到下一位置

-
继续取171前的元素新元素比较,直到找到已排序的元素小于或者等于新元素的位置;新 元素大于161,则直接插入空位中

-
重复步骤2~7,直到完成排序

插入排序:它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描, 找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间 的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供 插入空间。
具体算法描述如下:
-
从第一个元素开始,该元素可以认为已经被排序;
-
取出下一个元素,在已经排序的元素序列中从后向前扫描;
-
如果该元素(已排序)大于新元素,将该元素移到下一位置; 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
-
将新元素插入到该位置; 重复步骤2~5
代码实现::
#include <iostream>
#include <string>using namespace std;void InsertSort(int* height, int size)
{int current = 0;int preIndex = 0;for (int i = 1; i < size; i++){current = height[i];preIndex = i-1;while (preIndex >= 0 && height[preIndex] > current){height[preIndex + 1] = height[preIndex];preIndex--;}height[preIndex + 1] = current;}
}int main()
{int height[] = { 152,163,161,159,172,170,168,151 };int size = (sizeof(height) / sizeof(height[0]));InsertSort(height, size);cout << "The sorting result is" << endl;for (int i = 0; i < size; i++){cout << height[i] << " ";}system("pause");return 0;
}
希尔排序
插入排序虽好,但是某些特殊情况也有很多缺点,比如像下面这种情况

169前的元素基本不用插入操作就已经有序,元素1和2的排序几乎要移动数组前面的所有 元素!!!于是,有个老帅哥就提出了优化此问题的希尔排序!
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排 序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序。它与插入排序 的不同之处在于,它会优先比较距离较远的元素。
希尔排序是把记录按下表的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐 渐减少,每组包含的元素越来越多,当增量减至1时,所有元素被分成一组,实际上等同于执行一 次上面讲过的插入排序,算法便终止。
希尔排序的基本步骤:
选择增量:gap=length/2,缩小增量:gap=gap/2
增量序列:用序列表示增量选择,{n/2,(n/2)/2,…,1}
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
按增量序列个数k,对序列进行k趟排序;
每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m的子序列,分别对各子表进 行直接插入排序;
仅增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。

#include <iostream>
#include <string>
using namespace std;void InsertSort(int arr[], int len)
{int gap = len / 2;for (; gap > 0; gap = gap / 2) {for (int i = gap; i < len; i++) {int current = arr[i];int j = 0;for (j = i - gap; j >= 0 && arr[j] > current; j -= gap) {arr[j + gap] = arr[j];}arr[j + gap] = current;}}
}int main()
{int height[] = { 152,163,161,159,172,170,168,151 };int size = (sizeof(height) / sizeof(height[0]));InsertSort(height, size);cout << "The sorting result is" << endl;for (int i = 0; i < size; i++){cout << height[i] << " ";}system("pause");return 0;
}
归并排序
当两个组数据已经有序,我们可以通过如下方式(以下简称归并大法)让两组数据快速有序

我们可以依次从两组中取最前面的那个最小元素依次有序放到新的数组中,然后再把新数组 中有序的数据拷贝到原数组中,快速完成排序

具体步骤:
对于下面这一组待排序的数组

先以中间为界,把其均分为A和B两个数组(如果是奇数个,允许两组数相差一个)

如果A和B两组数据能够有序,则我们可以通过上面的方式让数组快速排好序。 此时,A组有4个成员,B组有5个成员,但两个数组都无序,然后我们可以采用分治法继 续对A组和B组进行均分,以A组为例,又可以均分A1和A2两个组如下:

均分后,A1组和A2组仍然无序,继续利用分治法细分,以A1组为例,A1又可分成如下 两组

数组细分到一个元素后,这时候,我们就可以采用归并法借助一个临时数组将数组A1有序化! A2同理!

依次类推,将A1组和A2组归并成有序的A组,B组同理!

最后,将A和B组使用归并大法合并,就得到了完整的有序的结果!

代码实现:
#include <iostream>
#include <string>using namespace std;//void mergeAdd_demo(int arr[], int left, int mid, int right)
//{
// int temp[64] = { 0 };
// int i = left;
// int j = mid;
// int k = 0;
//
// while (i < mid && j <= right)
// {
// if (arr[i] < arr[j])
// {
// temp[k++] = arr[i++];
// }
// else
// {
// temp[k++] = arr[j++];
// }
// }
// while (i < mid)
// {
// temp[k++] = arr[i++];
// }
//
// while (j <= right)
// {
// temp[k++] = arr[j++];
// }
//
// memcpy(arr + left, temp, sizeof(int) * (right - left + 1));
//}void mergeAdd(int arr[], int left, int mid, int right, int* temp)
{//int temp[64] = { 0 };int i = left;int j = mid;int k = left;while (i < mid && j <= right){if (arr[i] < arr[j]){temp[k++] = arr[i++];}else{temp[k++] = arr[j++];}}while (i < mid){temp[k++] = arr[i++];}while (j <= right){temp[k++] = arr[j++];}memcpy(arr + left, temp + left, sizeof(int) * (right - left + 1));
}void mergeSort(int arr[], int left, int right, int* temp)
{int mid = 0;if (left < right){mid = left+(right-left)/2;mergeSort(arr, left, mid, temp);mergeSort(arr, mid + 1, right, temp);mergeAdd(arr, left, mid+1, right, temp);}
}int main()
{int height[] = { 10,11,12,13,2,4,5,8 };int len = sizeof(height) / sizeof(height[0]);int* temp = new int[len];//int mid = len / 2;mergeSort(height, 0, len - 1, temp);//mergeAdd(height, 0, mid, len - 1,temp);for (int i = 0; i < len; i++){cout << height[i] << " ";}system("pause");return 0;
}
快速排序
具体做法为:
- 每次选取第一个数为基准数;
- 然后使用“乾坤挪移大法”将大于和小于基准的元素分别放置于基准数两边;
- 继续分别对基准数两侧未排序的数据使用分治法进行细分处理,直至整个序列有序。
对于下面待排序的数组:



代码实现:
#include <iostream>
#include <string>using namespace std;
int partition(int arr[], int low, int high)
{int i = low;int j = high;int base = arr[low];if (low < high){while (i < j){while (i < j && arr[j] >= base){j--;}if (i < j){arr[i++] = arr[j];}while (i < j && arr[i] < base){i++;}if (i < j){arr[j--] = arr[i];}}arr[i] = base;}return i;
}void QuickSort(int* arr, int low, int high)
{if (low < high){int index = partition(arr, low, high);QuickSort(arr, low, index - 1);QuickSort(arr, index + 1, high);}
}int main()
{int arr[] = { 163,161,158,165,171,170,163,159,162 };int len = sizeof(arr) / sizeof(arr[0]);//int index = partition(arr, 0, len - 1);QuickSort(arr, 0, len - 1);cout << "Executing the Quick Sort, result as" << endl;for (int i = 0; i < len; i++){cout << arr[i] << " ";}system("pause");return 0;
}
各大算法对比图

相关文章:
C++ 数据结构算法 学习笔记(32) -五大排序算法
C 数据结构算法 学习笔记(32) -五大排序算法 选择算法 如下若有多个女生的身高需要做排序: 常规思维: 第一步先找出所有候选美女中身高最高的,与最后一个数交换 第二步再找出除最后一位美女外其它美女中的最高者,与倒数第二个美女交换位置 再找出除最…...

从入门到精通:详解Linux进程管理
前言 在这篇文章中,我将带领大家深入学习和理解Linux系统中的进程管理。无论你是初学者还是有一定经验的开发者,相信这篇文章都会对你有所帮助。我们将详细讲解冯诺依曼体系结构、操作系统概念、进程管理、进程调度、进程状态、环境变量、内存管理以及其…...

【Linux】如何在 Linux 系统中使用 envsubst 来处理 Nginx 配置模板
一、创建 nginx.template 模板文件 vim nginx.template复制下面文件内容 server { listen ${BY_PORT}; server_name ${BY_HOST}; location /sys/ { proxy_pass http://${BY_GRAFANA_HOST}:${BY_GRAFANA_PORT}/; } # 其他配置... }这个模板中包含了几个环境变量&#…...

【LeetCode】438.找到字符串中所有字母异位词
找到字符串中所有字母异位词 题目描述: 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。 示…...

力扣96. 不同的二叉搜索树
Problem: 96. 不同的二叉搜索树 文章目录 题目描述思路复杂度Code 题目描述 思路 一个数字做根节点的话可能的结果为:其左边数字做子树的组合数字乘以其右边数字做子树的个数之积 1.创建备忘录memo; 2.递归分别求取当前数字左边和右边数字做子树的数量&…...

哈希表的用途
...

k8s笔记 | 高度调度
CronJob计划任务 简介:在k8s中周期性运行计划任务,与linux中的crontab相同;注意点 CornJob执行的时间是controller-manager的时间,所以一定要确保controller-manager的时间是准确的,另外cornjob cron表达式 文章参…...

Rom应用开发遇到得一些小bug
记录一些细碎得bug ROM时间类问题 问题描述: 设备拔电重启,ROM时间为默认时间如1970年1月1日,与某些业务场景互斥 问题原因: 后台接口校验https证书校验失败,要求是2年内得请求头校验了时间戳,时间戳过期…...

Python简介
Python简介 1. Python定义 Python 是一种简单易学并且结合了解释性、编译性、互动性和面向对象的脚本语言。Python提供了高级数据结构,它的语法和动态类型以及解释性使它成为广大开发者的首选编程语言。 Python 是解释型语言: 开发过程中没有了编译这个环…...
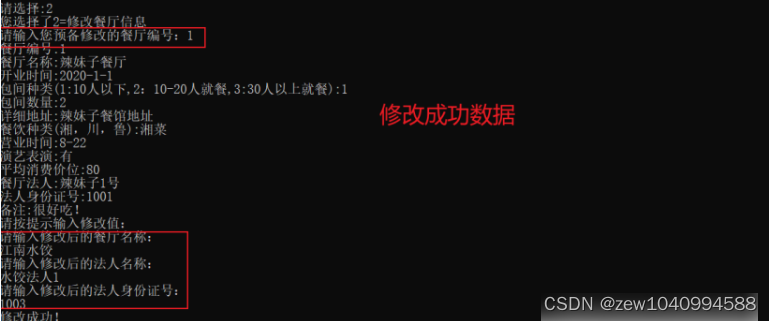
C++完成特色旅游管理信息系统
背景: 继C完成淄博烧烤节管理系统后,我们来到了特色旅游管理信息系统的代码编写,历史链接点下方。 C完成淄博烧烤节管理系统_淄博烧烤总账管理系统的-CSDN博客 问题描述: 为了更好的管理各个服务小组,开发相应的管…...
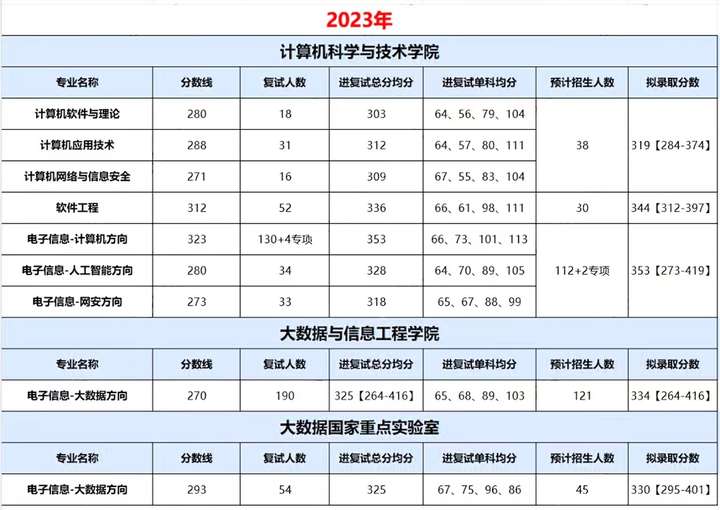
贵州大学24计算机考研数据速览,国家重点实验室22408复试线285分!贵州大学计算机考研考情分析!
贵州大学计算机科学与技术学院坐落在贵州大学北校区(贵阳花溪)。 学院现有教职工139人,其中专职教师126人,教授17人,副教授37人,讲师46人,高级实验师4人,实验师17人。具有博士学位的…...

分区4K对齐那些事,你想知道的都在这里
在对磁盘进行分区时,有一个很重要的注意事项,就是要将分区对齐,不对齐可能会造成磁盘性能的下降。尤其是固态硬盘SSD,基本上都要求4K对齐。磁盘读写速度慢还找不到原因?可能就是4K对齐的锅。那么分区对齐究竟是怎么回事?为什么要对齐?如何才能对齐?如何检测是否对齐呢?…...

达梦数据库学习笔记
架构、特点和基本概念 达梦数据库(DM Database)是中国达梦数据库有限公司自主研发的关系型数据库管理系统。它广泛应用于政府、金融、电信、能源等行业,具备高性能、高可靠性和高安全性的特点。 架构 达梦数据库的架构设计注重高性能和高可…...

安卓绕过限制直接使用Android/data无需授权,支持安卓14(部分)
大家都知道,安卓每次更新都会给权限划分的更细、收的更紧。 早在安卓11的时候还可以直接通过授权Android/data来实现操作其他软件的目录,没有之前安卓11授权的图了,反正都长一个样,就直接贴新图了。 后面到了安卓12~13的…...

【知识蒸馏】多任务模型 logit-based 知识蒸馏实战
一、什么是逻辑(logit)知识蒸馏 Feature-based蒸馏原理是知识蒸馏中的一种重要方法,其关键在于利用教师模型的隐藏层特征来指导学生模型的学习过程。这种蒸馏方式旨在使学生模型能够学习到教师模型在特征提取和表示方面的能力,从…...

C:技术面试总结
1 变量的声明和定义: 定义:为变量分配地址和存储空间 声明:不分配地址。一个变量可以在多个地方声明,但只能在一个地方定义。extern修饰的变量声明,说明此变量将在文件以外或文件后面部分定义。 2 局部变量是否能与全局变量重名: 可以,局部变量会屏蔽全局变量 局部…...

OpenHarmony 实战开发——一文总结ACE代码框架
一、前言 ACE_Engine框架是OpenAtom OpenHarmony(简称“OpenHarmony”)的UI开发框架,为开发者提供在进行应用UI开发时所必需的各种组件,以及定义这些组件的属性、样式、事件及方法,通过这些组件可以方便进行OpenHarmo…...

【数据结构与算法】之堆的应用——堆排序及Top_K问题!
目录 1、堆排序 2、Top_K问题 3、完结散花 个人主页:秋风起,再归来~ 数据结构与算法 个人格言:悟已往之不谏,知来者犹可追 克心守己,律己则安! 1、堆排序 对一个无序的数组…...
啊哈!算法-第2章-栈、队列、链表
啊哈!算法-第2章-栈、队列、链表 第1节 解密qq号——队列第2节 解密回文——栈第3节 纸牌游戏——小猫钓鱼第4节 链表第5节 模拟链表 第1节 解密qq号——队列 新学期开始了,小哈是小哼的新同桌(小哈是个大帅哥哦~),小哼向小哈询问 QQ 号, 小…...

简述 v-if 和 v-show 的区别
v-if 和 v-show 都是 Vue.js 中用于控制元素显示与隐藏的指令,但它们的工作方式有显著的差异。以下是它们之间的主要区别: 渲染方式: v-if:v-if 是“真正”的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...

自然语言处理的实战项目:从0到1搭建属于自己的文本分类系统
对于软件测试从业者而言,日常工作中我们每天都会接触大量的文本数据:缺陷管理系统中的bug描述、测试用例的步骤说明、用户反馈的问题报告、需求文档的规格描述,甚至是接口返回的异常信息文本。这些非结构化文本往往隐含着关键业务信息&#x…...