Idea中flume的Interceptor的编写教程
1.新建-项目-新建项目

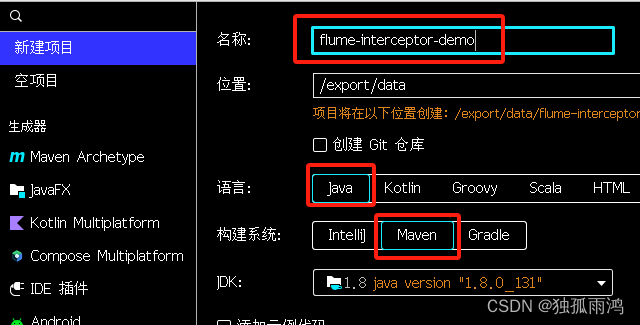
注意位置是将来打包文件存放的位置,即我们打包好的文件在这/export/data个目录下寻找
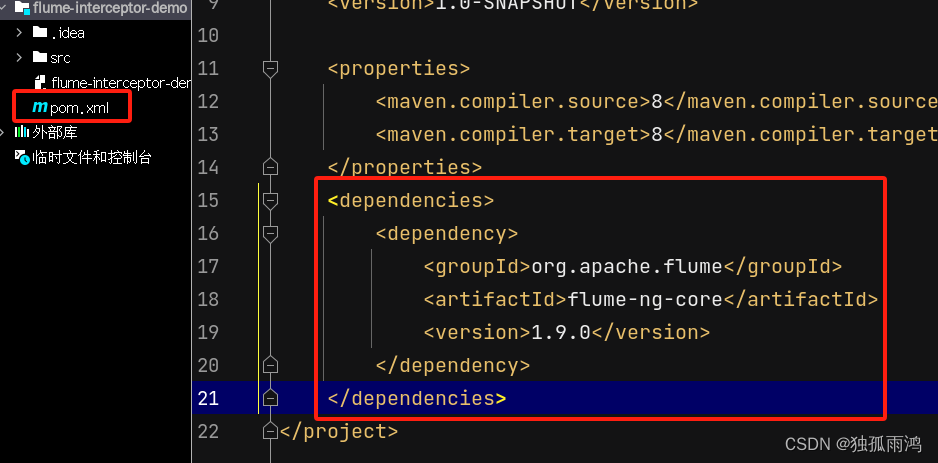
2. 在maven项目中导入依赖
Pom.xml文件中写入
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
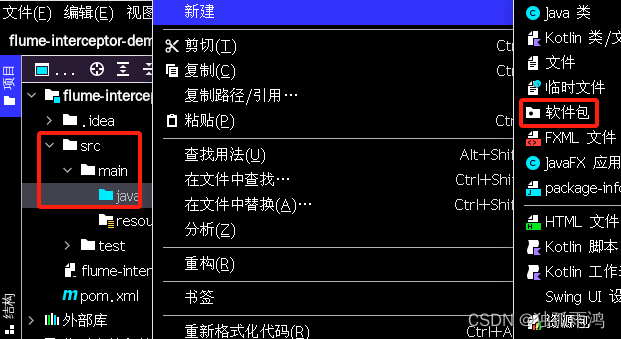
3.创建包(scr-main-java右键-新建-软件包)
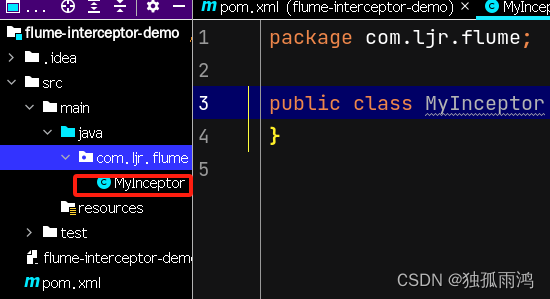
4.创建Java类(右键包名-新建-java类)
5. 继承(implements)flume 的拦截器接口
//键入implements Interceptor{} 光标定位到Interceptor alt + enter键选择导入类导入flume的Interceptor即可 import org.apache.flume.interceptor.Interceptor;
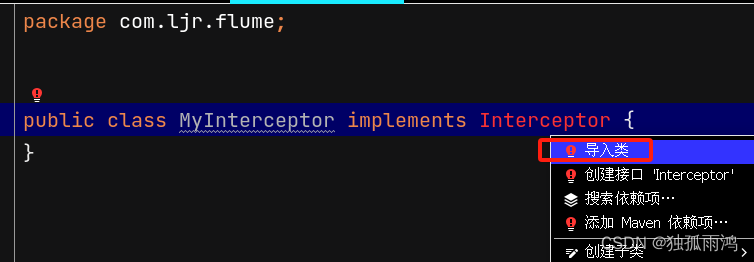
//此时会报错,点击红色灯泡,选择 实现方法 就会在下文写出需要Override的四个抽象类
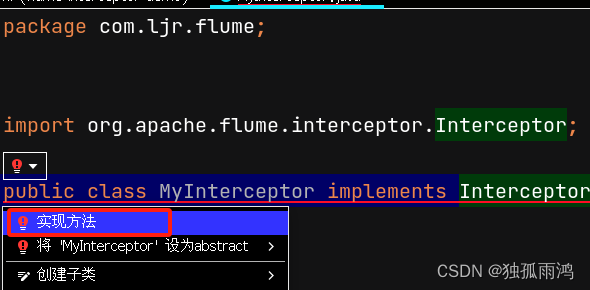
6.实现方法
public class MyInterceptor implements Interceptor {@Override//初始化方法public void initialize() {}//单个事件拦截//需求:在event的头部信息中添加标记//提供给channel selector 选择发送给不同的channel@Overridepublic Event intercept(Event event)//Map也需要alt + enter 导入Map<String, String> headers = event.getHeaders();//输入even.getHeaders().var回车即可自行填充等号前面的变量信息String log = new String(event.getBody());//envent.getBody().var自行判断变量类型为byte,为方便使用改为String类型// 键入new String(envent.getBody()).var回车,然后根据需要自行修改变量名//判断log开头的第一个字符,字母则发到channel1,数字则发到channel2char c = log.charAt(0);//log.charAt(0).var回车即可自行填充等号前面的变量信息if(c >= '0' && c <= '9'){headers.put("type","number");}else if ((c >= 'A' && c<= 'Z') || (c >= 'a' && c <= 'z')){// 注意字符串类型要使用>=需要用单引号而不能用双引号headers.put("type","letter");}//因为头部信息属性是一个引用数据类型 直接修改对象即可,也可以不调用以下的set方法 event.setHeaders(headers);//返回eventreturn event;}//批量事件拦截(处理多个event,系统调用这个方法)@Overridepublic List<Event> intercept(List<Event> list) {for (Event event : list){intercept(event);}return list;}//重写静态内部类Builder@Overridepublic void close() {}public static class Builder implements Interceptor.Builder{//创建一个拦截器对象@Overridepublic Interceptor build() {return new MyInterceptor();}//配置方法@Overridepublic void configure(Context context) {}}}7.打包(idea右侧菜单栏maven-生命周期-package)
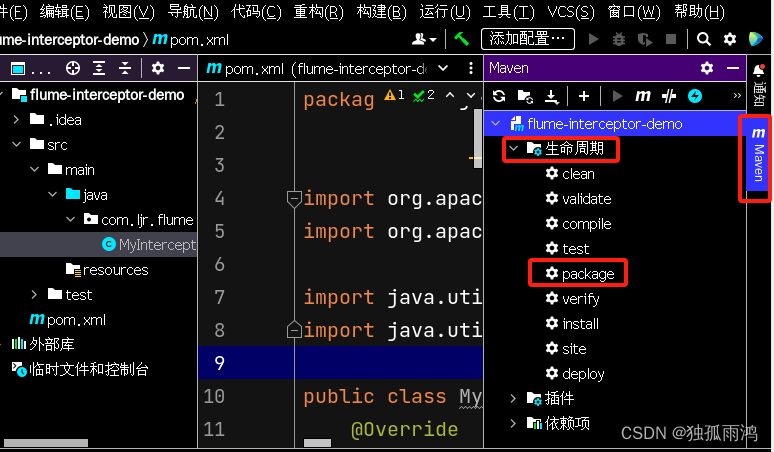
打包完成在idea左侧菜单栏 target 中可以看到我们的包
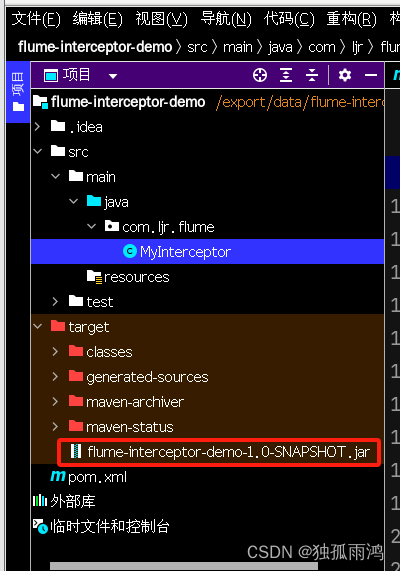
8.将建好的包复制到flume家目录下的lib中即可使用
cp /export/data/flume-interceptor-demo/target/flume-interceptor-demo-1.0-SNAPSHOT.jar $FLUME_HOME/lib
9.测试
9.1 编辑 flume 配置文件
vim flume1.conf
| # agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = node1 a1.sources.r1.port = 44444 # channel selector: multiplexing 多路复用 ;默认为replicating 复制 a1.sources.r1.selector.type = multiplexing # 填写相应inerceptor的header上的key a1.sources.r1.selector.header = type # 分配不同value发送到的channel,number到c2,letter到 c1 a1.sources.r1.selector.mapping.number = c2 a1.sources.r1.selector.mapping.letter = c1 #如果匹配不上默认选择的channel a1.sources.r1.selector.default = c2 #interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.ljr.flume.MyInterceptor$Builder # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = node1 a1.sinks.k1.port = 4545 a1.sinks.k2.type = avro a1.sinks.k2.hostname = node1 a1.sinks.k2.port = 4546 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 # 接收c1中的数据 a1.sinks.k1.channel = c1 # 接收c2中的数据 a1.sinks.k2.channel = c2 |
vim flume2.conf
| a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = avro a2.sources.r2.bind = node1 # flume1 中sink的输出端口 a2.sources.r2.port = 4545 # Describe the sink a2.sinks.k2.type = logger # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2 |
vim flume3.conf
| a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = avro a3.sources.r3.bind = node1 # flume1 中sink的输出端口 a3.sources.r3.port = 4546 # Describe the sink a3.sinks.k3.type = logger # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 |
9.2测试
打开四个窗口,前三个分别运行flume1.conf、flume2.conf、flume3.conf 配置的进程
第四个窗口启用necat,输入内容进行测试
flume-ng agent -c conf/ -f /export/server/flume/job/group2-multiplexing-test/flume1.conf -n a1
flume-ng agent -c conf/ -f /export/server/flume/job/group2-multiplexing-test/flume2.conf -n a2
flume-ng agent -c conf/ -f /export/server/flume/job/group2-multiplexing-test/flume3.conf -n a3
nc nc node1 44444 (flume1.conf中 source 填的主机名或IP地址 和端口号)
第一个窗口报错 ConnectException: 拒绝连接 可先忽略,运行二、三窗口后即可连接


在窗口4中输入数字、字母、符号
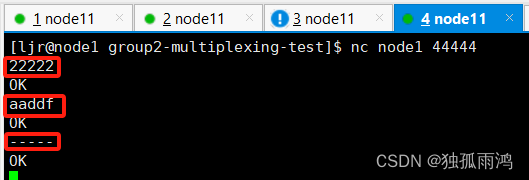
分别在窗口二看到输出字母,窗口三输出数字和符号


恭喜,Interceptor起作用!
相关文章:
Idea中flume的Interceptor的编写教程
1.新建-项目-新建项目 注意位置是将来打包文件存放的位置,即我们打包好的文件在这/export/data个目录下寻找 2. 在maven项目中导入依赖 Pom.xml文件中写入 <dependencies> <dependency> <groupId>org.apache.flume</groupId> <artifa…...

java单元测试:JUnit测试运行器
JUnit测试运行器(Test Runner)决定了JUnit如何执行测试。JUnit有多个测试运行器,每个运行器都有特定的功能和用途。 1. 默认运行器 当没有显式指定运行器时,JUnit会使用默认运行器,这在JUnit 4和JUnit 5之间有所不同…...
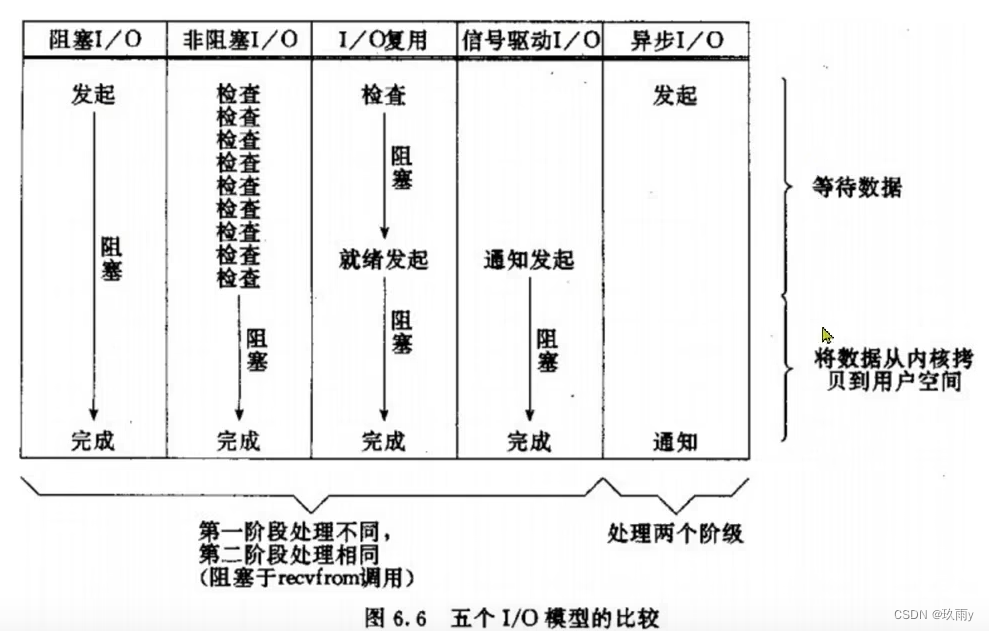
网络模型—BIO、NIO、IO多路复用、信号驱动IO、异步IO
一、用户空间和内核空间 以Linux系统为例,ubuntu和CentOS是Linux的两种比较常见的发行版,任何Linux发行版,其系统内核都是Linux。我们在发行版上操作应用,如Redis、Mysql等其实是无法直接执行访问计算机硬件(如cpu,内存…...
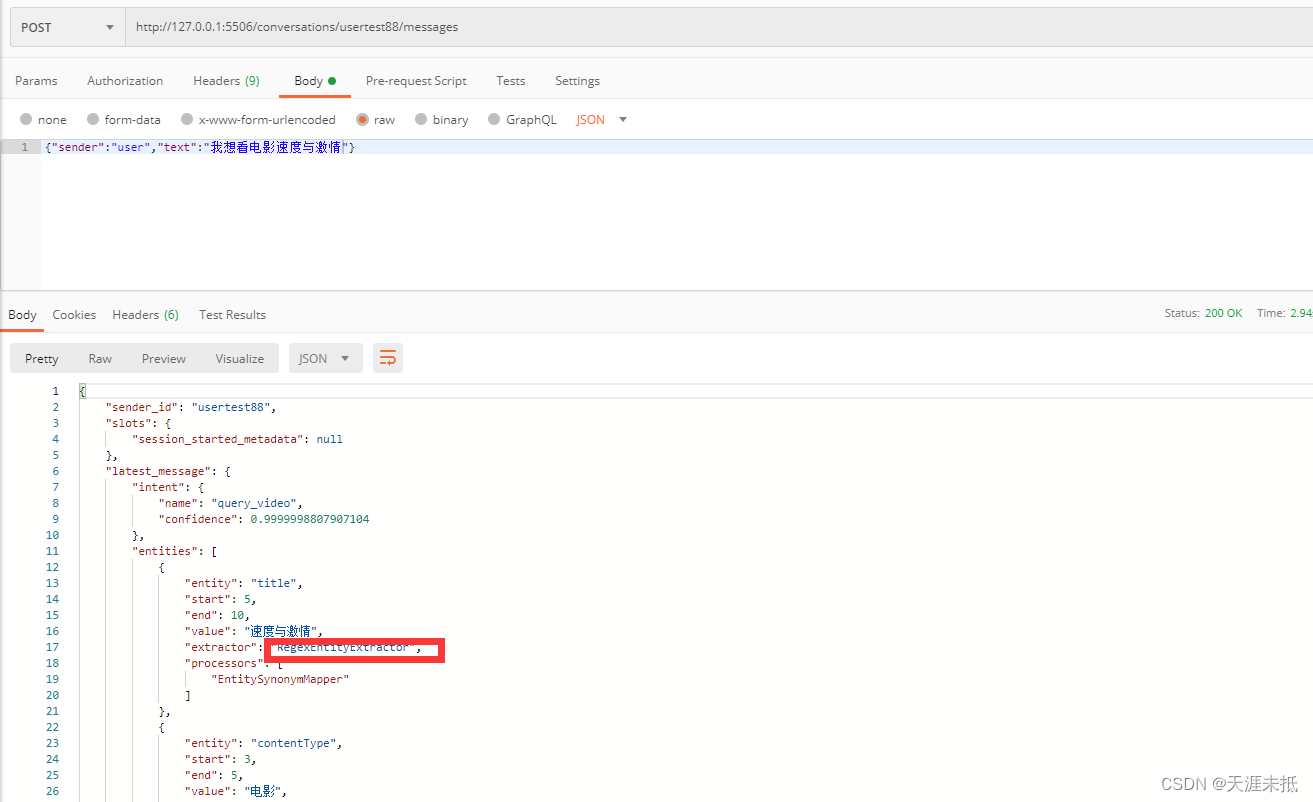
智能语义识别电影机器人的rasa实现
文章目录 0.前言1.项目整体框架2.rasa训练数据结构4.rasa启动命令及用到的API 0.前言 最近做了一个智能电影机器人的项目,我主要负责用户语义意图识别,用的框架是rasa,对应的版本为 3.6.15,对应的安装命令为: pip3 install rasa…...

C# 实现腾讯云 IM 常用 REST API 之会话管理
目录 关于腾讯 IM REST API 开发前准备 范例运行环境 常用会话管理API 查询账号会话总未读数 查询单聊会话消息记录 下载最近会话记录 小结 关于腾讯 IM REST API REST API 是腾讯即时通信 IM 提供给服务端的一组 HTTP 后台管理接口,如消息管理、群组管理…...

MySQL之Schema与数据类型优化(三)
Schema与数据类型优化 BLOB和TEXT类型 BLOB和TEXT都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。 实际上它们分别属于两组不同的数据类型家族:字符类型是TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONG…...

大语言模型发展历史
大语言模型的发展历史可以追溯到自然语言处理(NLP)和机器学习早期的探索,但真正快速发展起来是在深度学习技术兴起之后。以下是大语言模型发展的一个简要历史概述: 早期阶段(20世纪50-90年代): …...

Nginx - 安全基线配置与操作指南
文章目录 概述中间件安全基线配置手册1. 概述1.1 目的1.2 适用范围 2. Nginx基线配置2.1 版本说明2.2 安装目录2.3 用户创建2.4 二进制文件权限2.5 关闭服务器标记2.6 设置 timeout2.7 设置 NGINX 缓冲区2.8 日志配置2.9 日志切割2.10 限制访问 IP2.11 限制仅允许域名访问2.12 …...

简述js的事件循环以及宏任务和微任务
前言 在JavaScript中,任务被分为同步任务和异步任务。 同步任务:这些任务在主线程上顺序执行,不会进入任务队列,而是直接在主线程上排队等待执行。每个同步任务都会阻塞后续任务的执行,直到它自身完成。常见的同步任…...

[力扣题解] 797. 所有可能的路径
题目:797. 所有可能的路径 思路 深度搜索 代码 // 图论哦!class Solution { private:vector<vector<int>> result;vector<int> path;// x : 当前节点void function(vector<vector<int>>& graph, int x){int i;// cout <&l…...

【QT八股文】系列之篇章3 | QT的多线程以及QThread与QObject
【QT八股文】系列之篇章3 | QT的多线程 前言4. 多线程为什么需要使用线程池线程池的基础知识python中创建线程池的方法使用threading库队列Queue来实现线程池使用threadpool模块,这是个python的第三方模块,支持python2和python3 QThread的定义QT多线程知…...

基于python flask的web服务
基本例子 from flask import Flask app Flask(__name__) app.route(/)#检查访问的网址,根路径走这里 def hello_world():return hello world#返回hello worldif __name__ __main__:# 绑定到指定的IP地址和端口app.run(host0.0.0.0, port1000, debugTrue)##绑定端…...

HTTP 响应分割漏洞
HTTP 响应分割漏洞 1.漏洞概述2.漏洞案例 1.漏洞概述 HTTP 响应拆分发生在以下情况: 数据通过不受信任的来源(最常见的是 HTTP 请求)进入 Web 应用程序。该数据包含在发送给 Web 用户的 HTTP 响应标头中,且未经过恶意字符验证。…...

Algoriddim djay Pro Ai for Mac:AI引领,混音新篇章
当AI遇上音乐,会碰撞出怎样的火花?Algoriddim djay Pro Ai for Mac给出了答案。这款专业的DJ混音软件,以AI为引擎,引领我们进入混音的新篇章。 djay Pro Ai for Mac的智能混音功能,让每一位DJ都能感受到前所未有的创作…...

常见算法(3)
1.Arrays 它是一个工具类,主要掌握的其中一个方法是srot(数组,排序规则)。 o1-o2是升序排列,o2-o1是降序排列。 package test02; import java.util.ArrayList; import java.util.Arrays; import java.util.Comparat…...

集中抄表电表是什么?
1.集中抄表电表:简述 集中抄表电表,又称为远程抄表系统,是一种现代化电力计量技术,为提升电力行业的经营效率和客户服务质量。它通过自动化的形式,取代了传统人工抄水表,完成了数据信息实时、精确、高效率…...

第八届能源、环境与材料科学国际学术会议(EEMS 2024)
文章目录 一、重要信息二、大会简介三、委员会四、征稿主题五、论文出版六、会议议程七、出版信息八、征稿编辑 一、重要信息 会议官网:http://ic-eems.com主办方:常州大学大会时间:2024年06月7-9日大会地点:新加坡 Holiday Inn …...
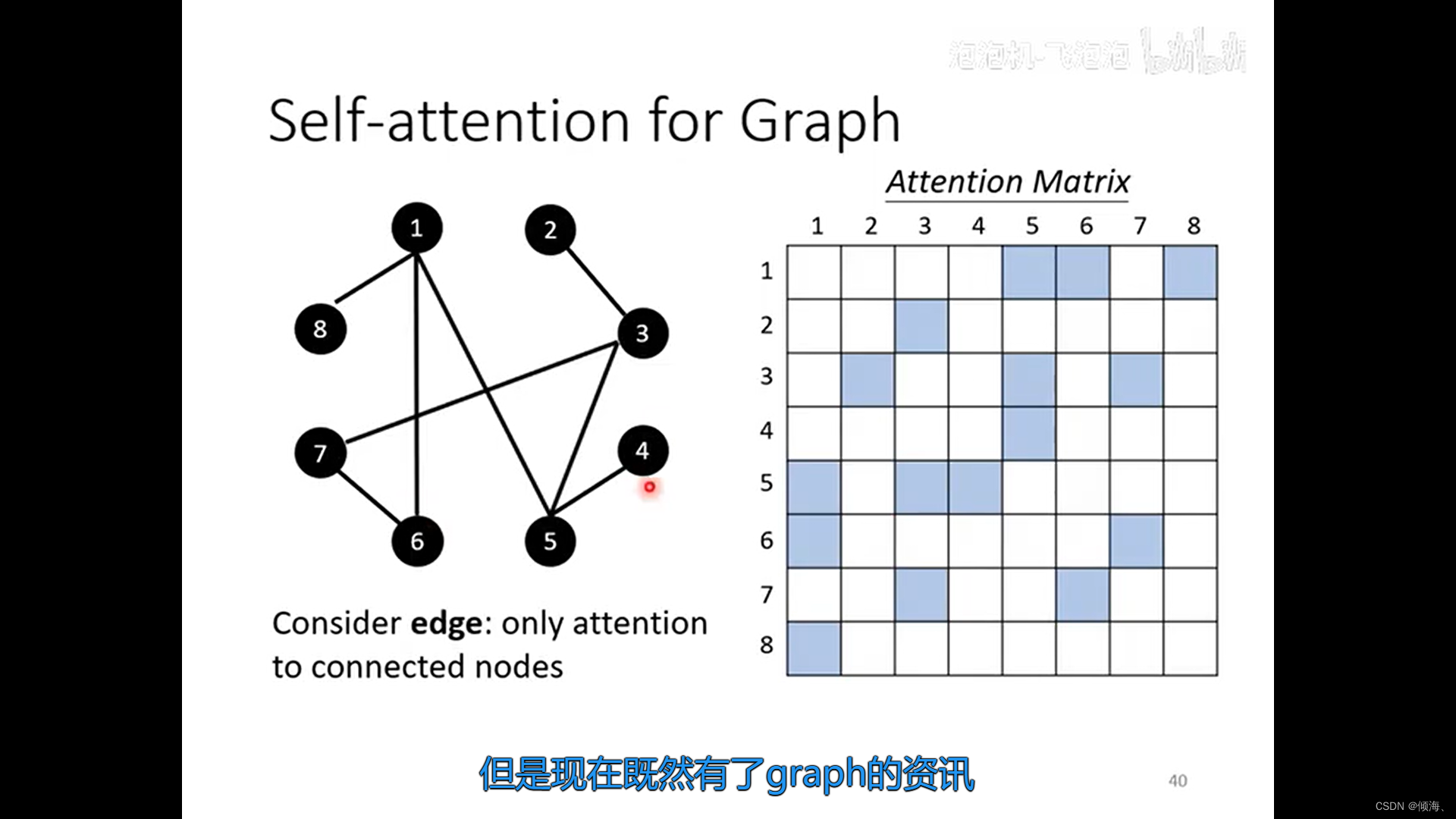
09.自注意力机制
文章目录 输入输出运行如何运行解决关联性attention score额外的Q K V Multi-head self-attentionPositional EncodingTruncated Self-attention影像处理vs CNNvs RNN图上的应用 输入 输出 运行 链接(Attention Is All You Need) 如何运行 解决关联性 a…...

时政|杂粮产业
政策支持 《新一轮千亿斤粮食产能提升行动方案(2024—2030年)》明确,按照“巩固提升口粮、主攻玉米大豆、兼顾薯类杂粮”的思路,因地制宜发展马铃薯、杂粮杂豆等品种,根据市场需求优产稳供。 产地发展 河北省石家庄…...

docker 安装 私有云盘 nextcloud
拉取镜像 # 拉取镜像 sudo docker pull nextcloud运行nextcloud 容器 # 内存足够可以不进行内存 --memory512m --memory-swap6g # 桥接网络 --network suixinnet --network-alias nextcloud \ sudo docker run -itd --name nextcloud --restartalways \ -p 9999:80 \ -v /m…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...