Hive语法学习总结
Hive SQL语法学习总结
- hive参数
- 库操作
- 1.创建库
- 2.具体案例
- 3.库的其他操作
- 表和库的路径演示
- 表的操作
- 创建表
- 插入数据
hive参数
一 hive常用交互命令hive -e 'sql语句'hive -f sql文件 //文件中是sql语句二 参数的设置方式一:在客户端中设置参数(当次有效)set 参数名=参数值;方式二:在启动客户端时设置参数(当次有效)hive -hiveconf 参数名=参数值beeline --hiveconf 参数名=参数值 -u jdbc:hive://hadoop102:10000 -n atguigu方式三:永久有效将参数设置在配置文件(hive-site.xml)hive客户端(不需要重启服务--因为hive客户端不需要连接hiveserver2服务)beeline客户端(需要重启服务-因为beeline客户端需要连接hiveserver2服务)
--开启自动转换为本地模式
set hive.exec.mode.local.auto=true;
库操作
1.创建库
CREATE DATABASE [IF NOT EXISTS] 库名
[COMMENT '库的描述信息-类似于注释']
[LOCATION '库在HDFS上对应的目录的所在路径']
[WITH DBPROPERTIES ('属性名'='属性值', ...)];
2.具体案例
create database db3;#if not exists : 如果库不存在则创建 存在则不创建。如果没有该字段库存在则报错
create database if not exists db3;create database db4
comment 'this is db4'
location '/db4'
with dbproperties('ver'='1.0');create database db5
comment 'this is db4'
location '/db55' #元数据中是对应的
with dbproperties('ver'='1.0');
3.库的其他操作
#查看库
#通配符可以是 *任意个数任意内容的字符 |表示或
#格式:SHOW DATABASES [LIKE '匹配规则-不是正则表达式'];
show databases;#查看库的信息 :
#extended :有了该字段才可以查看库的属性
#格式 :desc database [extended] 库名;
desc database db5;#选库:use 库名
use db1;#删除库 :
#[IF EXISTS] :如果库存在则删除不存在则不删。如果没有该字段库不存在则报错。
#[RESTRICT|CASCADE] :默认使用的是RESTRICT只能删除空库 cascade:可以删除非空的库
#格式:DROP DATABASE [IF EXISTS] 库名 [RESTRICT|CASCADE];
drop database db1;
drop database if exists db1;
drop database db2 cascade;#查看库的信息-建库语句
show create database 库名;#修改数据库
--修改dbproperties
#ALTER DATABASE 库名 SET DBPROPERTIES ('属性名'='属性值', ...);
alter database db3 set dbproperties('ver'='1.0');--修改location
#ALTER DATABASE 库名 SET LOCATION 'HDFS的路径';
alter database db3 set location 'hdfs://hadoop102:8020/demo/db33'--修改owner user
#ALTER DATABASE 库名 SET OWNER USER 用户名;
desc database extended db3;
表和库的路径演示
create database d1
location '/d1';create table stu(
id int
)
location '/d2';
表的操作
创建表
#[TEMPORARY] :创建一张临时表(当退出客户端时临时表被删除)#[EXTERNAL] :创建外部表 如果没有该字段创建的是管理表#[IF NOT EXISTS] :如果表不存在则创建存在则不创建 如果没有该字段表存在则报错CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [库名.]表名 [(字段名 字段类型 [COMMENT 字段的描述信息], 字段名2 字段类型 [COMMENT 字段的描述信息],...)][COMMENT 表的描述信息]#创建分区表 - 后面讲[PARTITIONED BY (字段名 字段类型 [COMMENT 字段的描述信息], ...)]#创建分桶表 - 后面讲[CLUSTERED BY (字段名1, 字段名2, ...)#对分桶字段中的内容排序 - 后面讲[SORTED BY (字段名 [ASC|DESC], ...)] INTO 桶的数量 BUCKETS][ROW FORMAT row_format] #存储格式 - 后面讲(默认是textfile)[STORED AS file_format]#一张表对应HDFS上的一个目录[LOCATION hdfs的路径]#表的属性[TBLPROPERTIES ('属性名'='属性值', ...)]2.创建表案例#案例一#[IF NOT EXISTS] :如果表不存在则创建存在则不创建 如果没有该字段表存在则报错create table if not exists emp(id int comment 'this is id',name string comment 'this is name')comment 'this is emp'location '/demo/emp'tblproperties('ver'='1.0');#案例二(创建临时表)#[TEMPORARY] :创建一张临时表(当退出客户端时临时表被删除)create TEMPORARY table emp2(id int,name string);#案例三 (基于现有的表创建一张新表)#create table 新表名 like 已经存在的表的表名;create table emp3 like emp;#案例四:将查询的结果创建成一张表create table 表名asselect查询语句;create table emp5
as
select * from emp;
ROW FORAMT DELIMITED
[FIELDS TERMINATED BY char] -- 各字段之间用什么分隔
[COLLECTION ITEMS TERMINATED BY char] -- 复杂数据类型中各元素之间用什么分隔开
[MAP KEYS TERMINATED BY char] -- map的key和value用什么分隔开
[LINES TERMINATED BY char] -- 每条数据之间用什么分隔
[NULL DEFINED AS char] -- 数据中的null在文件中用什么字符表示=======================================================================建表语句格式一(数据不是json数据)
create table student(
name string,
friends array<string>,
students map<string,int>,
address struct<street:string,city:string,postal_code:int>
)
row format delimited
fields terminated by ',' -- 各字段之间用什么分隔
collection items terminated by '-' -- 复杂数据类型中各元素之间用什么分隔开
map keys terminated by ':'; -- map的key和value用什么分隔开=====================================================================建表语句格式一(数据是json数据)
create table student_json(
name string,
friends array<string>,
students map<string,int>,
address struct<street:string,city:string,postal_code:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'; -- 用来处理json数据=======================================================================复杂数据类型如何查里面的元素:
select friends[0],students['xiaoyangyang'],address.city from student_json;说明:
select 数组类型[索引值],map类型['key'],struct类型.属性名 from student_json;=======================================================================
1.表的操作#查看所有表show tables;#查看表信息#[formatted] :可以查看表的详细信息。没有该字段只能看字段信息desc [formatted] 表名;
创建外部表和内部表#创建外部表#[EXTERNAL] : 创建外部表 没有该字段就是内部表create external table external_table(id int,name string)row format delimited fields terminated by '\t';#创建内部表-管理表create table man_table(id int,name string)row format delimited fields terminated by '\t';二 外部表和管理表的区别1.删除外部表时只会删除元数据。删除管理表时会将元数据和HDFS上的数据全部删除。2.truncate table只能清空管理表。不能清空外部表。三 外部表和管理表相互转换#修改表的属性:alter table 表名 set tblproperties('属性名'='属性值');#FALSE是管理表 TRUE是外部表alter table external_table set tblproperties('EXTERNAL'='FALSE');
1.查看表#[IN 库名] :查看哪个库中的所有的表#LIKE ['identifier_with_wildcards']; 模糊查询#SHOW TABLES [IN 库名] LIKE ['identifier_with_wildcards'];2.修改表名ALTER TABLE 原表名 RENAME TO 新表名;3.列的操作#添加列:ALTER TABLE 表名 ADD COLUMNS (字段名 字段类型 [COMMENT 字段描述信息], ...)alter table emp add columns(age int comment 'this is age');#更新列的名字#ALTER TABLE 表名 CHANGE [COLUMN] 原字段名 新字段名 字段的类型 [COMMENT 字段的描述信息] [FIRST | AFTER column_name]alter table emp change column age age2 int;#更新列的类型#注意类型 :比如int转bigint可以 但是string转int不可以#ALTER TABLE 表名 CHANGE [COLUMN] 字段名 字段名 字段的新类型 [COMMENT 字段的描述信息] [FIRST | AFTER column_name]alter table emp change age2 age2 string;#更新列的位置#注意:一定要注意字段的类型#ALTER TABLE 表名 CHANGE [COLUMN] 原字段名 原字段名 原字段类型 [COMMENT 字段的描述信息] [FIRST | AFTER column_name]#将name字段放在列的第一个位置alter table emp change column name name string first;#将name字段放在id的后面alter table emp change column name name string after id;#替换列#ALTER TABLE 表名 REPLACE COLUMNS (字段名 字段类型 [COMMENT 字段的描述信息], ...)#注意:①替换是依次替换 ②一定要注意替换的类型-int替换string肯定报错 # ③如果替换的列比被替换的列少-字段就会少。数据本身没有变化。alter table emp replace columns(id3 string,age3 string,name3 string);4.删除表#[if exists] : 如果表存在则删除不存在则不删除。如果没有该字段表不存在报错-但是没有报错drop table [if exists] 表名;5.清空表#注意:不能清空外部表TRUNCATE [TABLE] 表名;6.查看表信息#[formatted] : 可以查看表更详细的信息desc [formatted] 表名;7.查看建表语句show create table 表名;插入数据
一 Load格式#[LOCAL] :表示数据是在本地--从本地向表中导入数据。没有该字段表示从HDFS导数据到表中#[OVERWRITE] :表示覆盖。如果没有该字段是追加LOAD DATA [LOCAL] INPATH '文件路径' [OVERWRITE] INTO TABLE 表名 #等到分区表再说[PARTITION (partcol1=val1, partcol2=val2 ...)];案例1:从本地向表中导入数据-追加load data local inpath '/opt/module/hive/datas/student2.txt' into table student;案例2:从本地向表中导入数据-覆盖load data local inpath '/opt/module/hive/datas/student2.txt' overwrite into table student;案例3:从HDFS向表中导入数据 - 会将HDFS上的数据移动到表所对应的目录中load data inpath '/demo/datas/student2.txt' into table student2;=========================================================二 Insert2.1 将查询的结果插入到表中#into :追加 overwrite:覆盖INSERT (INTO | OVERWRITE) TABLE 表名#分区表再说[PARTITION (partcol1=val1, partcol2=val2 ...)] #查询语句select语句;案例1 - 追加:insert into table student3 select id,name from student where id < 1010;案例2 - 追加:insert into table student3(id) select id from student where id < 1010;案例3 - 覆盖:insert overwrite table student3 select id,name from student where id < 1005;案例4(错误的) - 覆盖(不能指定插入哪个字段):insert overwrite table student3(id) select id from student where id < 1003;2.2 插入给定数据INSERT INTO TABLE 表名(字段名1,字段名2,.......)#后面再说[PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES (值1,值2,值3,........),(值1,值2,值3,........),........;案例:insert into table student3(id,name) values(1,'a'),(2,'b');2.3 导出-将表中的数据导出#[LOCAL] :将表中的数据导出到本地。没有该字段导出到HDFS上INSERT OVERWRITE [LOCAL] DIRECTORY '导出的路径-导出到哪里'#可以指定导出的数据的各字段之间用什么分隔[ROW FORMAT row_format] #文件的存储格式-后面讲[STORED AS file_format] select语句;案例1:insert overwrite local directory '/home/atguigu/datas' select * from student;案例2:insert overwrite local directory '/home/atguigu/datas' row format delimited fields terminated by '\t' select * from student;
相关文章:

Hive语法学习总结
Hive SQL语法学习总结 hive参数库操作1.创建库2.具体案例3.库的其他操作 表和库的路径演示表的操作创建表插入数据 hive参数 一 hive常用交互命令hive -e sql语句hive -f sql文件 //文件中是sql语句二 参数的设置方式一:在客户端中设置参数(当次有效)set 参数名参…...

【Linux】TCP协议【中】{确认应答机制/超时重传机制/连接管理机制}
文章目录 1.确认应答机制2.超时重传机制:超时不一定是真超时了3.连接管理机制 1.确认应答机制 TCP协议中的确认应答机制是确保数据可靠传输的关键部分。以下是该机制的主要步骤和特点的详细解释: 数据分段与发送: 发送方将要发送的数据分成一…...

solidworks画螺母学习笔记
螺母 单位mm 六边形 直径16mm,水平约束,内圆直径10mm 拉伸 选择两侧对称,厚度7mm 拉伸切除 画相切圆 切除深度7mm,反向切除 拔模角度45 镜像切除 倒角 直径1mm 异形孔向导 螺纹线 偏移打勾,距离为2mm…...
WebGL的医学培训软件开发
开发基于WebGL的医学培训软件是一项复杂且技术性强的任务,需要结合医学专业知识和计算机图形学技术。以下是详细的开发流程和关键步骤。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1.需求分析与定义 目标用户…...

新时代AI浪潮下,程序员和产品经理如何入局AIGC领域?
当下,AI浪潮席卷全球,AIGC大模型技术已经成为当今技术领域的一个重要趋势,对于产品经理来说,掌握这项技术不仅能够增强他们的职业技能,还能在竞争激烈的职场中脱颖而出。 为什么呢? 把握AI时代的机遇 AI技…...
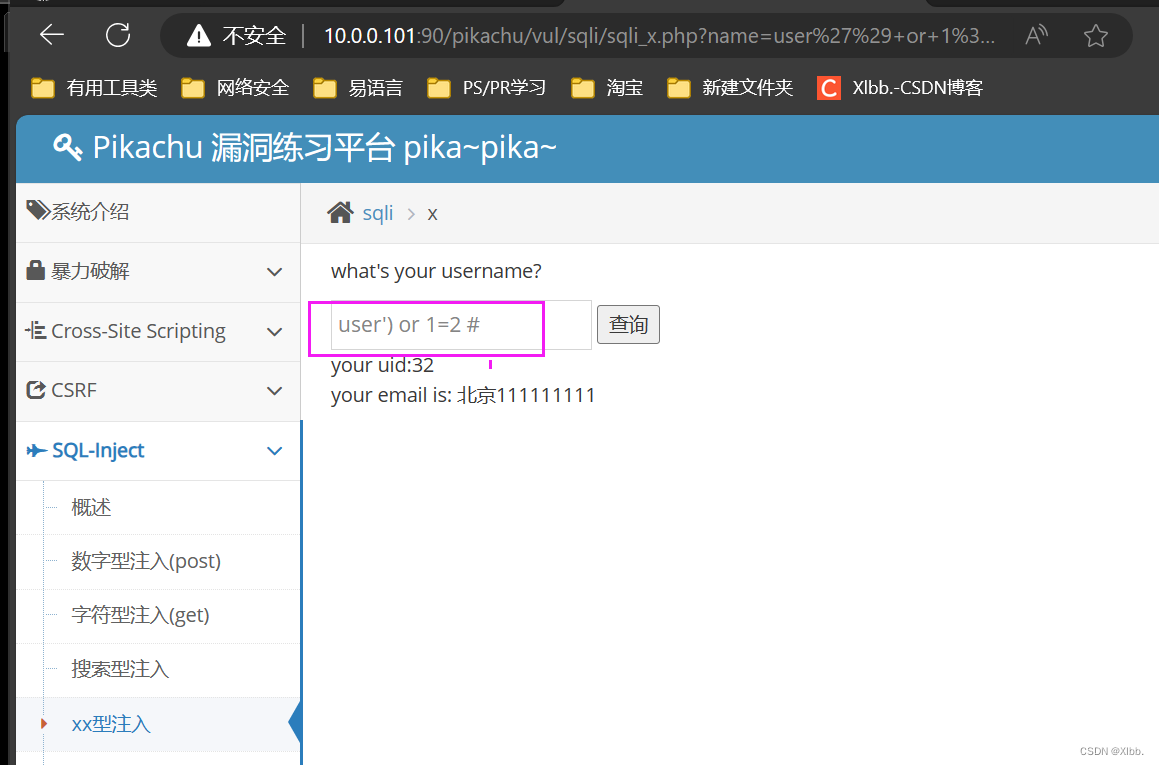
OWASP top10--SQL注入(一)
SQL注入式攻击技术,一般针对基于Web平台的应用程序.造成SQL注入攻击漏洞的原因,是由于程序员在编写Web程序时,没有对浏览器端提交的参数进行严格的过滤和判断。用户可以修改构造参数,提交SQL查询语句,并传递至服务器端…...

java —— 类与方法
一、访问修饰符 在类和方法中,均可使用访问修饰符以锁定该类或方法的被访问权限。访问修饰符有四种: (一)public 同一个项目中,对所有的类可见。 (二)protected 同一个项目中,对…...

【MySQL精通之路】InnoDB-启动选项和系统变量
系统变量可以在服务器启动时设置TRUE或FALSE启用禁用,也可以通过使用--skip前缀来禁用 例如: 要启用或禁用InnoDB自适应哈希索引,可以在命令行中使用--skip-innodb-adaptive-hash-index或--innodb-adaptive-hash-index,或者在配置…...

嵌入式linux系统中文件系统制作方法详解
第一:制作目的 1、掌握嵌入式Ubuntu系统的构建方法 2、熟悉嵌入式Ubuntu文件系统映射压缩打包方法 3、掌握RK3399linux系统单文件系统更新方法 Ubuntu根文件系统制作完成之后,把制作好的ubuntu文件系统映射文件在出厂系统的基础上替换原有的ubuntu根文件系统,即对 Linux 系统…...

AI爆文写作:要写文章爆,这47个爆文前缀少不了!
47个爆文前缀:很震惊很好用 这些前缀,虽然被用了无数次,但每个人看到还是会忍不住点进去。 可以借鉴这样强情绪的句式。 序号前缀1就在刚刚…2真相曝光…3震惊国人…4惊天秘密…5疯狂转发…6删前速看…7千万别吃…8还敢喝吗…9癌症前兆…10赶快扔了…11太可怕了…12大事不…...
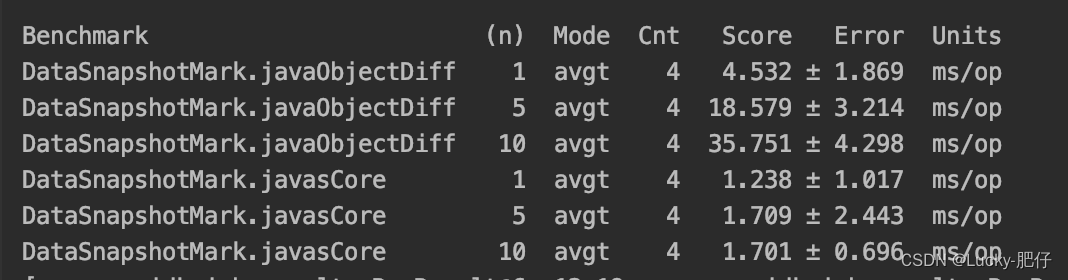
javas-core VS java-object-diff
对照工具选择 javas-core 和 java-object-diff ,对比demo https://github.com/kofgame/objectdiff-vs-javers,都为同源对比,都支持嵌套对象。 使用JMH测试方法进行性能测试,使用题库的QuestionResponseVO对象来进行对照对比,进行…...

dirsearch指令大全
文章目录 基本用法主要参数和选项目标和URL设置--url URL--url-list FILE 扩展名--extensions EXTENSIONS 字典文件--wordlists WORDLIST 线程和性能--threads THREADS--timeout SECONDS--delay MILLISECONDS 忽略状态码代理和请求设置--proxy PROXY--headers HEADERS 保存结果…...

C++基础:构建者设计模式
#include <iostream> #include <string> using namespace std; //构建者设计模式-一种工厂只生产一种复杂的产品 class robot {public:string head;string upbody;string downbody; };class robotBuilder {private:robot *myRobot;public:robotBuilder() //构造函…...

Swift 请求用户授权以跟踪其跨应用或网站的活动
步骤1:导入框架 首先,需要在Swift文件中导入AppTrackingTransparency框架。 import AppTrackingTransparency import AdSupport步骤2:请求跟踪许可 在适当的地方请求用户的跟踪许可。通常,这个请求会在应用启动时或者在用户执行…...

最新版npm详解
如:npm中搜索 jQuery image.png image.png 接地气的描述:npm 类似于如下各大手机应用市场 image.png image.png 查看本地 node 和 npm 是否安装成功 image.png image.png 或 npm install -g npm image.png image.png image.png image.png image.…...

超值分享50个DFM模型格式的素人直播资源,适用于DeepFaceLive的DFM合集
50直播模型:点击下载 作为直播达人,我在网上购买了大量直播用的模型资源,包含男模女模、明星脸、大众脸、网红脸及各种稀缺的路人素人模型。现在,我将这些宝贵的资源整理成合集分享给大家,需要的朋友们可以直接点击下…...

Python——一维二维字典数据转化为DataFrame的方法
import pands as pddf pd.DataFrame(dict)...

unity中如何插入网页
在Unity中插入自己的网页通常是通过使用Unity的WebGL构建目标和HTML页面来实现的。以下是一些步骤: 构建你的Unity项目为WebGL:在Unity中,选择Build Settings(构建设置),将Platform(平台&#x…...

【负载均衡在线OJ项目日记】引入网络库和客户端用户路由功能
目录 引入cpp-httplib库 将编译与运行服务打包 代码 客户端用户路由功能 采用MVC结构进行设计 用户路由功能 路由功能代码 引入cpp-httplib库 对于后端编译与运行模块基本已经设计完成,最后用户是通过网络传递代码等信息;我们就要将这个模块引入…...
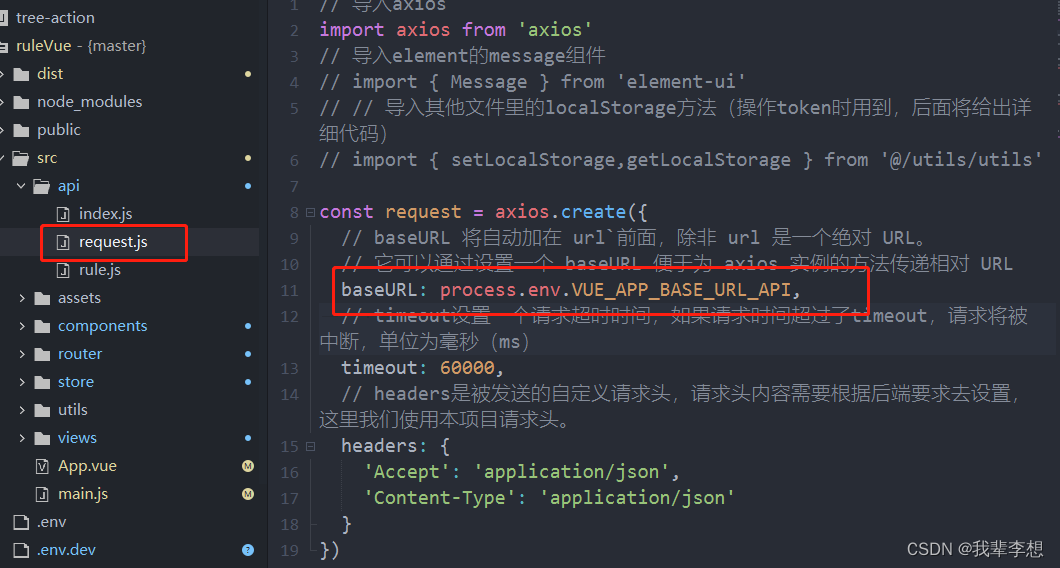
【Vue3】env环境变量的配置和使用(区分cli和vite)
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、env文件二、vue3cli加载env1..env配置2..dev配置(其他环境参考)3.package.json文件4.使用 三、vue3vite加载e…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...