掩码生成蒸馏——知识蒸馏
摘要
https://arxiv.org/pdf/2205.01529
知识蒸馏已成功应用于各种任务。当前的蒸馏算法通常通过模仿教师的输出来提高学生的性能。本文表明,教师还可以通过指导学生的特征恢复来提高学生的表示能力。从这一观点出发,我们提出了掩码生成蒸馏(Masked Generative Distillation,MGD),该方法很简单:我们随机掩码学生的特征像素,并通过一个简单的块强迫其生成教师的完整特征。MGD是一种真正通用的基于特征的蒸馏方法,可用于各种任务,包括图像分类、目标检测、语义分割和实例分割。我们在不同模型和广泛的数据集上进行了实验,结果表明所有学生都取得了显著的改进。特别地,我们将ResNet-18在ImageNet上的top-1准确率从69.90%提高到71.69%,将基于ResNet-50骨干的RetinaNet的Boundingbox mAP从37.4提高到41.0,将基于ResNet-50的SOLO的Mask mAP从33.1提高到36.2,以及将基于ResNet-18的DeepLabV3的mIoU从73.20提高到76.02。我们的代码已公开在https://github.com/yzd-v/MGD。
关键词:知识蒸馏,图像分类,目标检测,语义分割,实例分割
1、引言
深度卷积神经网络(CNNs)已被广泛应用于各种计算机视觉任务。通常,较大的模型具有更好的性能但推理速度较慢,这使得在资源有限的情况下难以部署。为了克服这一问题,提出了知识蒸馏技术[18]。根据蒸馏发生的位置,它可以分为两类。第一类是专门为不同任务设计的,例如,基于logits的蒸馏[18,40]用于分类任务和基于头部的蒸馏[10,39]用于检测任务。第二类是基于特征的蒸馏[28,17,4]。由于各种网络之间仅在特征之后的头部或投影器上存在差异,理论上,基于特征的蒸馏方法可以在各种任务中使用。然而,为特定任务设计的蒸馏方法通常在其他任务中不可用。例如,OFD[17]和KR[4]对检测器的改进有限。FKD[37]和FGD[35]是专门为检测器设计的,由于缺少颈部结构,无法在其他任务中使用。
先前的基于特征的蒸馏方法通常让学生尽可能地模仿教师的输出,因为教师的特征具有更强的表示能力。然而,我们认为,为了提高学生的特征表示能力,并不需要直接模仿教师。用于蒸馏的特征通常是通过深度网络提取的高阶语义信息。特征像素已经在一定程度上包含了相邻像素的信息。因此,如果我们能够通过一个简单的模块使用部分像素来恢复教师的完整特征,那么这些使用的像素的表示能力也会得到提高。从这一点出发,我们提出了掩码生成蒸馏(Masked Generative Distillation,MGD),这是一种简单且高效的基于特征的蒸馏方法。如图2所示,我们首先随机掩码学生的特征像素,然后通过一个简单的模块使用掩码后的特征来生成教师的完整特征。由于在每次迭代中都使用随机像素,训练过程中会用到所有像素,这意味着特征将更具鲁棒性,并且其表示能力也会得到提高。在我们的方法中,教师仅作为指导学生恢复特征的指南,并不要求学生直接模仿它。

为了验证我们的假设,即在不直接模仿教师的情况下,通过掩码特征生成可以提高学生的特征表示能力,我们对学生和教师颈部特征的注意力进行了可视化。如图1所示,学生和教师的特征差异很大。与教师相比,学生特征在背景区域的响应更高。教师的mAP也显著高于学生,为41.0%对37.4%。在使用最先进的蒸馏方法FGD[35]进行蒸馏后,该方法强制学生模仿教师特征的注意力,学生的特征变得更接近教师,mAP也大幅提高到40.7%。然而,在使用MGD进行训练后,尽管学生和教师的特征之间仍然存在显著差异,但学生对背景的响应大大降低。我们也惊讶地发现,学生的性能超过了FGD,甚至达到了与教师相同的mAP。这也表明使用MGD进行训练可以提高学生特征的表示能力。
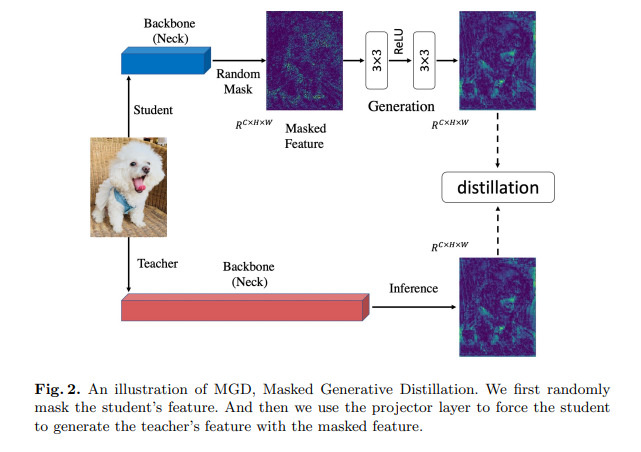
此外,我们还在图像分类和密集预测任务上进行了丰富的实验。结果显示,MGD可以为各种任务带来显著的改进,包括图像分类、目标检测、语义分割和实例分割。MGD还可以与其他基于logits或头部的蒸馏方法结合使用,以获得更大的性能提升。
综上所述,本文的贡献如下:
- 我们为基于特征的知识蒸馏引入了一种新方法,使学生通过其掩码特征生成教师的特征,而不是直接模仿。
- 我们提出了一种新颖的基于特征的蒸馏方法——掩码生成蒸馏(MGD),该方法简单易用,仅包含两个超参数。
- 我们通过在不同数据集上的大量实验验证了该方法在各种模型上的有效性。对于图像分类和密集预测任务,使用MGD的学生都取得了显著的改进。
2、相关工作
2.1、分类中的知识蒸馏
知识蒸馏最初由Hinton等人提出[18],其中学生模型不仅受到真实标签的监督,还受到教师模型最后线性层产生的软标签的监督。然而,除了基于logits的蒸馏方法外,更多蒸馏方法是基于特征图的。FitNet[28]从中间层提取语义信息进行蒸馏。AT[36]汇总通道维度上的值,并将注意力知识传递给学生模型。OFD[17]提出了边际ReLU,并设计了一种新的函数来衡量蒸馏中的距离。CRD[30]利用对比学习将知识传递给学生。最近,KR[4]建立了一个回顾机制,并利用多级信息进行蒸馏。SRRL[33]将表示学习和分类解耦,利用教师模型的分类器来训练学生模型的倒数第二层特征。WSLD[40]从偏差-方差权衡的角度提出了加权软标签用于蒸馏。
2.2、密集预测的知识蒸馏
分类与密集预测之间存在很大差异。许多针对分类的知识蒸馏方法在密集预测上失败了。理论上,基于特征的知识蒸馏方法应该对分类和密集预测任务都有帮助,这也是我们方法的目标。
对象检测的知识蒸馏。Chen等人[1]首先在检测器的颈部和头部计算蒸馏损失。对象检测中蒸馏的关键在于由于前景和背景之间的极端不平衡,应该在哪里进行蒸馏。为了避免从背景中引入噪声,FGFI[31]利用细粒度掩码来蒸馏物体附近的区域。然而,Defeat[13]指出前景和背景的信息都很重要。GID[10]选择学生和教师表现不同的区域进行蒸馏。FKD[37]使用教师和学生的注意力之和来使学生关注可变区域。FGD[35]提出了焦点蒸馏,迫使学生学习教师的关键部分,以及全局蒸馏,以弥补缺失的全局信息。
语义分割的知识蒸馏。Liu等人[23]提出了成对和整体蒸馏,强制学生和教师的输出之间保持成对和高阶一致性。He等人[16]将教师网络的输出重新解释为重新表示的潜在域,并从教师网络中捕获长期依赖关系。CWD[29]最小化了通过归一化每个通道的激活图计算得到的概率图之间的Kullback-Leibler(KL)散度。
3、方法
不同任务的模型架构差异很大。此外,大多数蒸馏方法都是为特定任务设计的。然而,基于特征的知识蒸馏可以应用于分类和密集预测。基于特征蒸馏的基本方法可以表示为:
L fea = ∑ k = 1 C ∑ i = 1 H ∑ j = 1 W ( F k , i , j T − f align ( F k , i , j S ) ) 2 L_{\text{fea}} = \sum_{k=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W}\left(F_{k, i, j}^{T} - f_{\text{align}}\left(F_{k, i, j}^{S}\right)\right)^{2} Lfea=∑k=1C∑i=1H∑j=1W(Fk,i,jT−falign(Fk,i,jS))2
其中, F T F^{T} FT 和 F S F^{S} FS 分别表示教师和学生的特征,而 f align f_{\text{align}} falign 是适配层,用于将学生特征 F S F^{S} FS 与教师特征 F T F^{T} FT 对齐。C、H、W 表示特征图的形状。
这种方法有助于学生直接模仿教师的特征。然而,我们提出了掩码生成蒸馏(MGD),其目标在于迫使学生生成教师的特征,而不是简单地模仿它,从而在分类和密集预测方面都为学生带来显著改进。MGD的架构如图2所示,我们将在本节中详细介绍它。
3.1、使用掩码特征的生成
对于基于CNN的模型,深层特征具有较大的感受野和更好的原始输入图像表示。换句话说,特征图像素已经在一定程度上包含了相邻像素的信息。因此,我们可以使用部分像素来恢复完整的特征图。我们的方法旨在通过学生的掩码特征生成教师的特征,这有助于学生实现更好的表示。
我们分别用 T l ∈ R C × H × W T^{l} \in R^{C \times H \times W} Tl∈RC×H×W 和 S l ∈ R C × H × W ( l = 1 , … , L ) S^{l} \in R^{C \times H \times W} (l=1, \ldots, L) Sl∈RC×H×W(l=1,…,L) 表示教师和学生的第 l l l 层特征图。首先,我们设置第 l l l 个随机掩码来覆盖学生的第 l l l 层特征,可以表示为:
M i , j l = { 0 , 如果 R i , j l < λ 1 , 其他情况 M_{i, j}^{l}=\left\{ \begin{array}{ll} 0, & \text{如果 } R_{i, j}^{l}<\lambda \\ 1, & \text{其他情况} \end{array} \right. Mi,jl={0,1,如果 Ri,jl<λ其他情况
其中 R i , j l R_{i, j}^{l} Ri,jl 是一个在 ( 0 , 1 ) (0,1) (0,1) 范围内的随机数, i , j i, j i,j 分别是特征图的横纵坐标。 λ \lambda λ 是一个超参数,表示掩码比例。第 l l l 层特征图被第 l l l 个随机掩码覆盖。
然后,我们使用相应的掩码来覆盖学生的特征图,并尝试用剩下的像素生成教师的特征图,可以表示为:
G ( f align ( S l ) ⋅ M l ) ⟶ T l G ( F ) = W l 2 ( ReLU ( W l 1 ( F ) ) ) \begin{array}{c} \mathcal{G}\left(f_{\text{align}}\left(S^{l}\right) \cdot M^{l}\right) \longrightarrow T^{l} \\ \mathcal{G}(F) = W_{l 2}\left(\text{ReLU}\left(W_{l 1}(F)\right)\right) \end{array} G(falign(Sl)⋅Ml)⟶TlG(F)=Wl2(ReLU(Wl1(F)))
G \mathcal{G} G 表示投影层,包括两个卷积层 W l 1 W_{l 1} Wl1 和 W l 2 W_{l 2} Wl2,以及一个激活层 ReLU。在本文中,我们为适配层 f align f_{\text{align}} falign 采用 1 × 1 1 \times 1 1×1 卷积层,为投影层 W l 1 W_{l 1} Wl1 和 W l 2 W_{l 2} Wl2 采用 3 × 3 3 \times 3 3×3 卷积层。
根据这种方法,我们为MGD设计了蒸馏损失 L dis L_{\text{dis}} Ldis:
L dis ( S , T ) = ∑ l = 1 L ∑ k = 1 C ∑ i = 1 H ∑ j = 1 W ( T k , i , j l − G ( f align ( S k , i , j l ) ⋅ M i , j l ) ) 2 L_{\text{dis}}(S, T) = \sum_{l=1}^{L} \sum_{k=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W}\left(T_{k, i, j}^{l} - \mathcal{G}\left(f_{\text{align}}\left(S_{k, i, j}^{l}\right) \cdot M_{i, j}^{l}\right)\right)^{2} Ldis(S,T)=l=1∑Lk=1∑Ci=1∑Hj=1∑W(Tk,i,jl−G(falign(Sk,i,jl)⋅Mi,jl))2
其中 L L L 是进行蒸馏的层数总和, C , H , W C, H, W C,H,W 表示特征图的形状。 S S S 和 T T T 分别表示学生和教师的特征。
3.2、总损失
在提出用于MGD的蒸馏损失 L dis L_{\text{dis}} Ldis 之后,我们使用总损失来训练所有模型,具体形式如下:
L all = L original + α ⋅ L dis L_{\text{all}} = L_{\text{original}} + \alpha \cdot L_{\text{dis}} Lall=Loriginal+α⋅Ldis
其中 L original L_{\text{original}} Loriginal 是所有任务中模型的原始损失,而 α \alpha α 是一个超参数,用于平衡两种损失。
MGD 是一种简单而有效的蒸馏方法,可以很容易地应用于各种任务。我们的方法流程在算法1中进行了总结。

4、主要实验
MGD 是一种基于特征的蒸馏方法,可以轻松应用于不同模型和各种任务。在本文中,我们在包括分类、目标检测、语义分割和实例分割在内的各种任务上进行了实验。我们针对不同任务使用了不同的模型和数据集,并且所有模型在使用 MGD 后都取得了显著的改进。
4.1、分类
数据集。对于分类任务,我们在 ImageNet[11] 上评估了我们的知识蒸馏方法,它包含了 1000 个对象类别。我们使用 120 万张图像进行训练,并使用 50k 张图像进行所有分类实验的测试。我们使用准确率来评估模型。
实现细节。对于分类任务,我们在主干网络的最后一个特征图上计算蒸馏损失。关于这一点的消融研究将在第 5.5 节中展示。MGD 使用一个超参数 α \alpha α 来平衡方程 6 中的蒸馏损失。另一个超参数 λ \lambda λ 用于调整方程 2 中的掩码比例。我们在所有分类实验中都采用了超参数 { α = 7 × 1 0 − 5 , λ = 0.5 } \left\{\alpha=7 \times 10^{-5}, \lambda=0.5\right\} {α=7×10−5,λ=0.5}。我们使用 SGD 优化器对所有模型进行 100 个周期的训练,其中动量设置为 0.9,权重衰减为 0.0001。我们初始化学习率为 0.1,并在每 30 个周期后衰减。这一设置基于 8 个 GPU。实验是使用基于 Pytorch[26] 的 MMClassification[6] 和 MMRazor[7] 进行的。
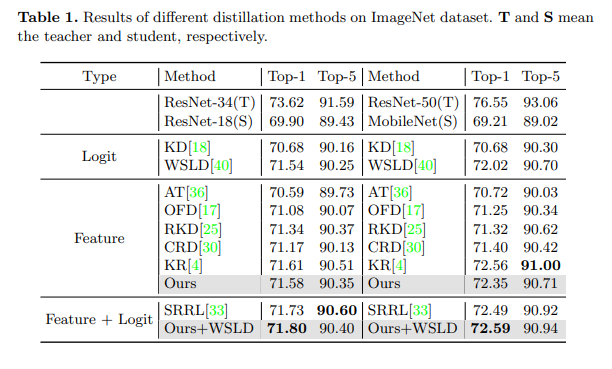
分类结果。我们针对分类任务进行了两种流行的蒸馏设置实验,包括同构蒸馏和异构蒸馏。第一种蒸馏设置是从 ResNet-34[15] 到 ResNet-18,另一种设置是从 ResNet-50 到 MobileNet[19]。如表 1 所示,我们将我们的方法与各种知识蒸馏方法[18, 36, 17, 25, 30, 4, 40, 33]进行了比较,这些方法包括基于特征的方法、基于逻辑的方法以及它们的组合。使用我们的方法,学生模型 ResNet-18 和 MobileNet 的 Top-1 准确率分别提高了 1.68 和 3.14。此外,如上所述,MGD 只需要在特征图上计算蒸馏损失,并且可以与基于逻辑的其他图像分类方法相结合。因此,我们尝试在 WSLD[40] 中添加基于逻辑的蒸馏损失。通过这种方式,两个学生模型分别达到了 71.80 和 72.59 的 Top-1 准确率,分别再提高了 0.22 和 0.24。
4.2、目标检测与实例分割
数据集。我们在 COCO2017 数据集[22]上进行了实验,该数据集包含 80 个对象类别。我们使用 120k 张训练图像进行训练,并使用 5k 张验证图像进行测试。模型的性能通过平均精度(Average Precision)进行评估。
实现细节。我们在颈部(neck)的所有特征图上计算蒸馏损失。对于所有单阶段模型,我们采用超参数 { α = 2 × 1 0 − 5 , λ = 0.65 } \left\{\alpha=2 \times 10^{-5}, \lambda=0.65\right\} {α=2×10−5,λ=0.65};对于所有两阶段模型,我们采用超参数 { α = 5 × 1 0 − 7 , λ = 0.45 } \left\{\alpha=5 \times 10^{-7}, \lambda=0.45\right\} {α=5×10−7,λ=0.45}。我们使用 SGD 优化器对所有模型进行训练,其中动量设置为 0.9,权重衰减为 0.0001。除非另有说明,我们训练模型 24 个周期。当师生具有相同的头结构时,我们使用继承策略[20, 35],即用教师的颈部和头部参数初始化学生的参数来训练学生。实验是基于 MMDetection[2] 进行的。
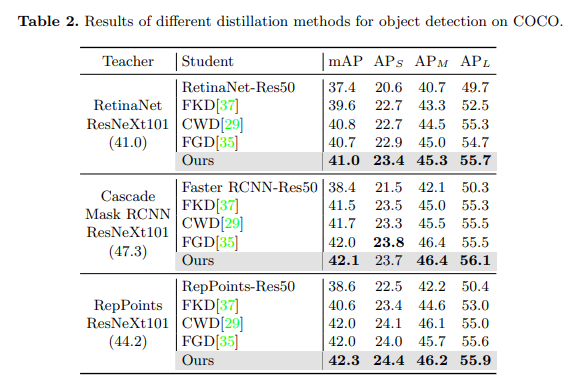
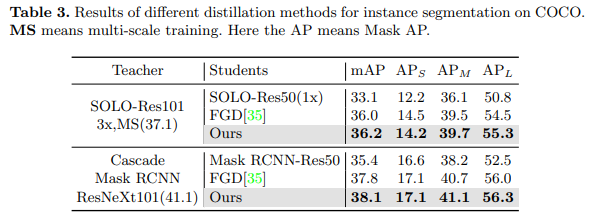
目标检测与实例分割结果。对于目标检测,我们在三种不同类型的检测器上进行了实验,包括两阶段检测器(Faster RCNN[27])、基于锚点的单阶段检测器(RetinaNet[21])和无锚点单阶段检测器(RepPoints[34])。我们将 MGD 与三种最新的检测器蒸馏方法[37, 29, 35]进行了比较。对于实例分割,我们在两个模型上进行了实验,即 SOLO[32] 和 Mask RCNN[14]。如表 2 和表 3 所示,我们的方法在目标检测和实例分割方面均超过了其他最先进的方法。使用 MGD 的学生模型获得了显著的 AP 改进,例如,基于 ResNet-50 的 RetinaNet 和 SOLO 在 COCO 数据集上分别获得了 3.6 的 Boundingbox mAP 和 3.1 的 Mask mAP 提升。
4.3、语义分割
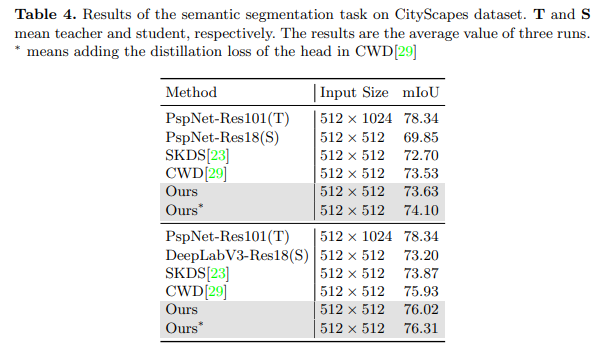
数据集。对于语义分割任务,我们在CityScapes数据集[9]上评估了我们的方法,该数据集包含5000张高质量图像(其中2975张用于训练,500张用于验证,1525张用于测试)。我们使用平均交并比(mIoU)来评估所有模型。
实现细节。对于所有模型,我们在骨干网络的最后一个特征图上计算蒸馏损失。我们在所有实验中都采用了超参数 { α = 2 × 1 0 − 5 , λ = 0.75 } \left\{\alpha=2 \times 10^{-5}, \lambda=0.75\right\} {α=2×10−5,λ=0.75}。我们使用SGD优化器训练所有模型,其中动量设置为0.9,权重衰减为0.0005。我们在8个GPU上运行所有模型。实验是使用MMSegmentation[8]框架进行的。
语义分割结果。在语义分割任务中,我们进行了两种设置的实验。在这两种设置中,我们都使用PspNet-Res101[38]作为教师模型,并使用 512 × 1024 512 \times 1024 512×1024的输入大小对其进行80k次迭代的训练。我们使用PspNet-Res18和DeepLabV3-Res18[3]作为学生模型,并使用 512 × 1024 512 \times 1024 512×1024的输入大小对它们进行40k次迭代的训练。如表4所示,我们的方法在语义分割任务上超越了最先进的蒸馏方法。无论是同构蒸馏还是异构蒸馏,都为学生模型带来了显著的改进,例如基于ResNet-18的PspNet获得了3.78 mIoU的改进。此外,MGD是一种基于特征的蒸馏方法,可以与其他基于逻辑(logits)的蒸馏方法相结合。如结果所示,通过在CWD[29]中添加头部的逻辑蒸馏损失,学生模型PspNet和DeepLabV3的mIoU分别再提高了0.47和0.29。
5、分析
5.1、MGD带来的更好表示
MGD迫使学生通过其掩码特征生成教师的完整特征图,而不是直接模仿它。这有助于学生获得输入图像的更好表示。在本小节中,我们通过使用学生自我教学来研究这一点。我们首先直接训练ResNet-18作为教师和基线。然后,我们使用训练好的ResNet-18用MGD蒸馏自己。为了比较,我们还通过强迫学生直接模仿教师来蒸馏学生。模仿的蒸馏损失是学生特征图与教师特征图之间的L2距离的平方。
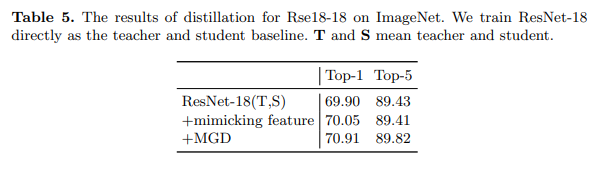
如表5所示,即使教师是它自己,学生也能通过MGD获得1.01的准确率提升。相比之下,当强迫学生直接模仿教师的特征图时,提升非常有限。比较表明,蒸馏后学生的特征图比教师的特征图获得了更好的表示。
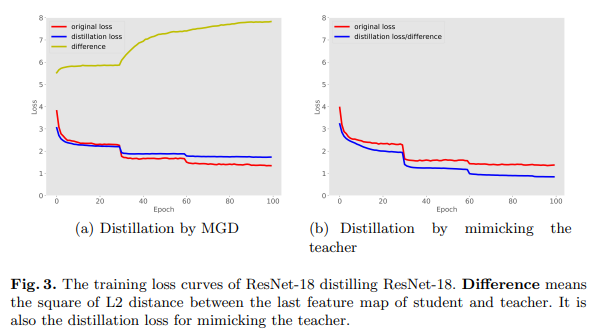
此外,我们可视化了使用MGD蒸馏和模仿教师的训练损失曲线,如图3所示。图中的差异表示学生与教师最后一个特征图之间的L2距离的平方,也是模仿教师的蒸馏损失。如图所示,在直接模仿教师的过程中,差异不断减小,最终学生得到了与教师相似的特征。然而,这种方法带来的改进很小。相比之下,在使用MGD训练后,差异变得更大。尽管学生得到了与教师不同的特征,但它获得了更高的准确率,这也表明学生的特征获得了更强的表示能力。
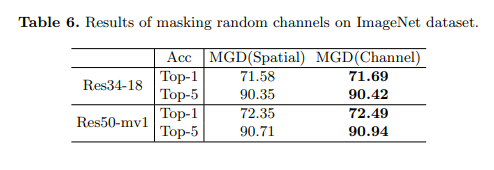
5.2、通过掩码随机通道进行蒸馏
对于图像分类,模型通常使用池化层来减少特征图的空间维度。这使得模型对通道比空间像素更敏感。因此,在本小节中,我们尝试通过掩码随机通道而不是空间像素来应用MGD进行分类。我们在实验中采用掩码比率 β = 0.15 \beta=0.15 β=0.15和超参数 α = 7 × 1 0 − 5 \alpha=7 \times 10^{-5} α=7×10−5。如表6所示,通过掩码随机通道而不是空间像素进行图像分类,学生可以获得更好的性能。学生ResNet-18和MobileNet分别获得了0.13和0.14的Top-1准确率提升。
5.3、使用不同教师进行蒸馏
Cho等人[5]表明,对于图像分类的知识蒸馏,准确率更高的教师可能并不是更好的教师。这一结论基于基于逻辑(logits)的蒸馏方法。然而,我们的方法只需要在特征图上计算蒸馏损失。在本小节中,我们使用不同类型的教师来蒸馏相同的学生ResNet-18,如图4所示。
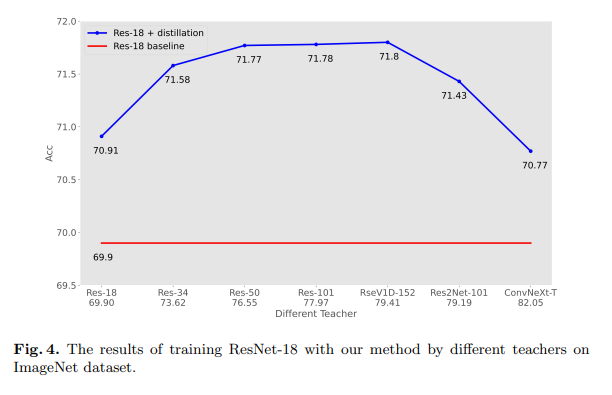
如图4所示,当教师和学生具有相似架构时,更好的教师更能使学生受益,例如ResNet-18分别使用ResNet-18和ResNetV1D-152作为教师时,准确率达到了70.91和71.8。然而,当教师和学生具有不同的架构时,学生很难生成教师的特征图,通过蒸馏获得的改进是有限的。此外,架构差异越大,蒸馏效果越差。例如,尽管Res2Net101[12]和ConvNeXt-T[24]的准确率分别为79.19和82.05,但它们仅为学生带来了1.53和0.88的准确率提升,甚至低于基于ResNet-34的教师(准确率为73.62)。
图4中的结果表明,当教师和学生具有相似架构时,更强的教师是特征基础蒸馏的更好选择。此外,具有相似架构的同构教师比准确率高但架构异构的教师更适合特征基础蒸馏。
5.4、生成块
MGD使用一个简单的块来恢复特征,称为生成块。在方程4中,我们使用两个 3 × 3 3 \times 3 3×3卷积层和一个ReLU激活层来完成这一点。在本小节中,我们探索了具有不同组合的生成块的效果,如表7所示。
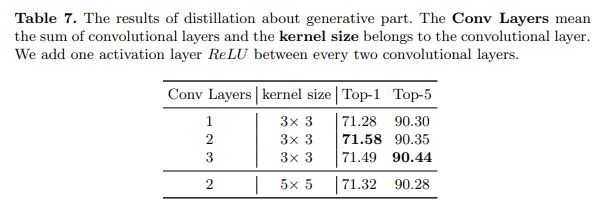
结果表明,当只有一个卷积层时,学生的提升最小。然而,当有三个卷积层时,学生的Top-1准确率较差但Top-5准确率更好。对于核大小, 5 × 5 5 \times 5 5×5卷积核需要更多的计算资源,但性能较差。基于这些结果,我们选择方程4中的架构作为MGD,它包括两个卷积层和一个激活层。
5.5、在不同阶段的蒸馏
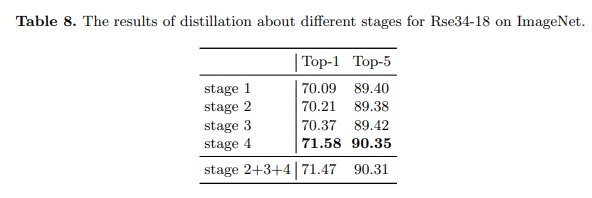
我们的方法也可以应用于模型的其他阶段。在本小节中,我们探索了在ImageNet上的不同阶段进行蒸馏。我们在教师和学生的相应层上计算蒸馏损失。如表8所示,蒸馏较浅的层也有助于学生,但非常有限。而蒸馏包含更多语义信息的较深阶段更能使学生受益。此外,早期阶段的特征不直接用于分类。因此,将这样的特征与最后一阶段的特征一起蒸馏可能会损害学生的准确率。
5.6、超参数的敏感性研究
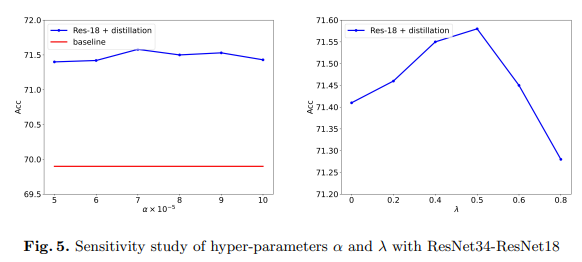
在本文中,我们使用方程6中的 α \alpha α和方程2中的 λ \lambda λ来平衡蒸馏损失和调整掩码比率。在本小节中,我们通过使用ResNet-34在ImageNet数据集上蒸馏ResNet-18来进行超参数的敏感性研究。结果如图5所示。
如图5所示,MGD对仅用于平衡损失的超参数 α \alpha α不敏感。对于掩码比率 λ \lambda λ,当其为0时,准确率为71.41,这意味着没有用于生成的掩码部分。当 λ < 0.5 \lambda<0.5 λ<0.5时,学生随着比率的增大而获得更高的性能。然而,当 λ \lambda λ过大时,例如0.8,剩余的语义信息太差,无法生成教师的完整特征图,性能提升也受到影响。
6、结论
在本文中,我们提出了一种新的知识蒸馏方法,它迫使学生通过其掩码特征生成教师的特征,而不是直接模仿它。基于这种方式,我们提出了一种新的知识蒸馏方法,即掩码生成蒸馏(MGD)。通过MGD,学生可以获得更强的表示能力。此外,我们的方法仅基于特征图,因此MGD可以轻松应用于各种任务,如图像分类、目标检测、语义分割和实例分割。在各种模型和不同数据集上的广泛实验证明,我们的方法简单且有效。
致谢。本研究得到了SZSTC项目资助号JCYJ20190809172201639和WDZC20200820200655001,以及深圳市重点实验室项目ZDSYS20210623092001004的支持。
相关文章:
掩码生成蒸馏——知识蒸馏
摘要 https://arxiv.org/pdf/2205.01529 知识蒸馏已成功应用于各种任务。当前的蒸馏算法通常通过模仿教师的输出来提高学生的性能。本文表明,教师还可以通过指导学生的特征恢复来提高学生的表示能力。从这一观点出发,我们提出了掩码生成蒸馏(…...

【C#实战】Newtonsoft.Json基类子类解析
情景再现 假设你有如下类: public class Item {public int Id;public string Name; }public class Weapon: Item {public int CurrentAmmo; }public class Inventory {public List<Item> Items; } 其中你序列化的是Inventory类,Items列表里混杂着…...

表达式求值的相关语法知识(C语言)
目录 整型提升 整型提升的意义 整型提升规则 整型提升实例 算术转换 赋值转换 操作符的属性 C语言的语法并不能保证表达式的执行路径唯一!!! 问题表达式 整型提升 C的整型算术运算总是至少以缺省整型类型的精度来进行的。为了获得这…...

开发中遇到Electron自定义窗口的问题
开发中遇到Electron自定义窗口的问题 使用VUE3 Electron 开发一个音乐软件,自定义导航栏的放大、缩小和关闭。 其中使用ipcRenderer进行联系Electron,进行放大、缩小和关闭操作。 遇到问题 遇到__dirname is not defined in ES module scope //在V…...
c# sqlite使用
安装包 使用 const string strconn "Data Sourcedata.db"; using (SQLiteConnection conn new SQLiteConnection(strconn)) {conn.Open();var cmd conn.CreateCommand();cmd.CommandText "select 1";var obj cmd.ExecuteScalar();MessageBox.Show(ob…...
详解)
39、Flink 的窗口剔除器(Evictors)详解
Evictors Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor,通过 evictor(...) 方法传入 Evictor。 Evictor 可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素, Evictor 接口提供了两个方法实现此功能&#x…...

Flutter 中的 DefaultTabController 小部件:全面指南
Flutter 中的 DefaultTabController 小部件:全面指南 在Flutter中,DefaultTabController是一个用于管理Tab控制器的widget,它允许你控制Tab视图的初始索引和动态更新。这个组件在实现具有可滚动标签页的界面时非常有用,例如在设置…...
C++技能进阶指南——多态语法剖析
前言:多态是面向对象的三大特性之一。顾名思义, 多态就是多种状态。 那么是什么的多种状态呢? 这里的可能有很多。比如我们去买火车票, 有普通票, 学生票; 又比如我们去旅游, 有儿童票ÿ…...

Linux内存管理--系列文章肆
一、引子 上篇文章介绍了目标文件,也就是讲到编译过程中的汇编这个阶段。本篇要讲目标文件怎么变成一个可执行文件的,介绍编译过程中的链接。 链接主要分为两种,静态链接和动态链接。它们本质上的区别,是在程序的编译和运行过程中…...
kali下载zsteg和stegpy
1.kali下载zsteg 从 GitHub 上克隆zsteg到kali git clone https://github.com/zed-0xff/zsteg 切换目录 cd zsteg 用于安装名为 zsteg 的 Ruby Gem 包 gem install zsteg 2.kali下载stegpy 下载网站内的stegpy-master压缩包GitCode - 开发者的代码家园 并拉到kali中 切换到s…...

前端面试题日常练-day34 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末。 1. jQuery中,以下哪个选项用于筛选出第一个匹配的元素? a) first() b) get(0) c) eq(0) d) find(":first") 2. 在jQuery中,以下哪个选项用于在元素上…...
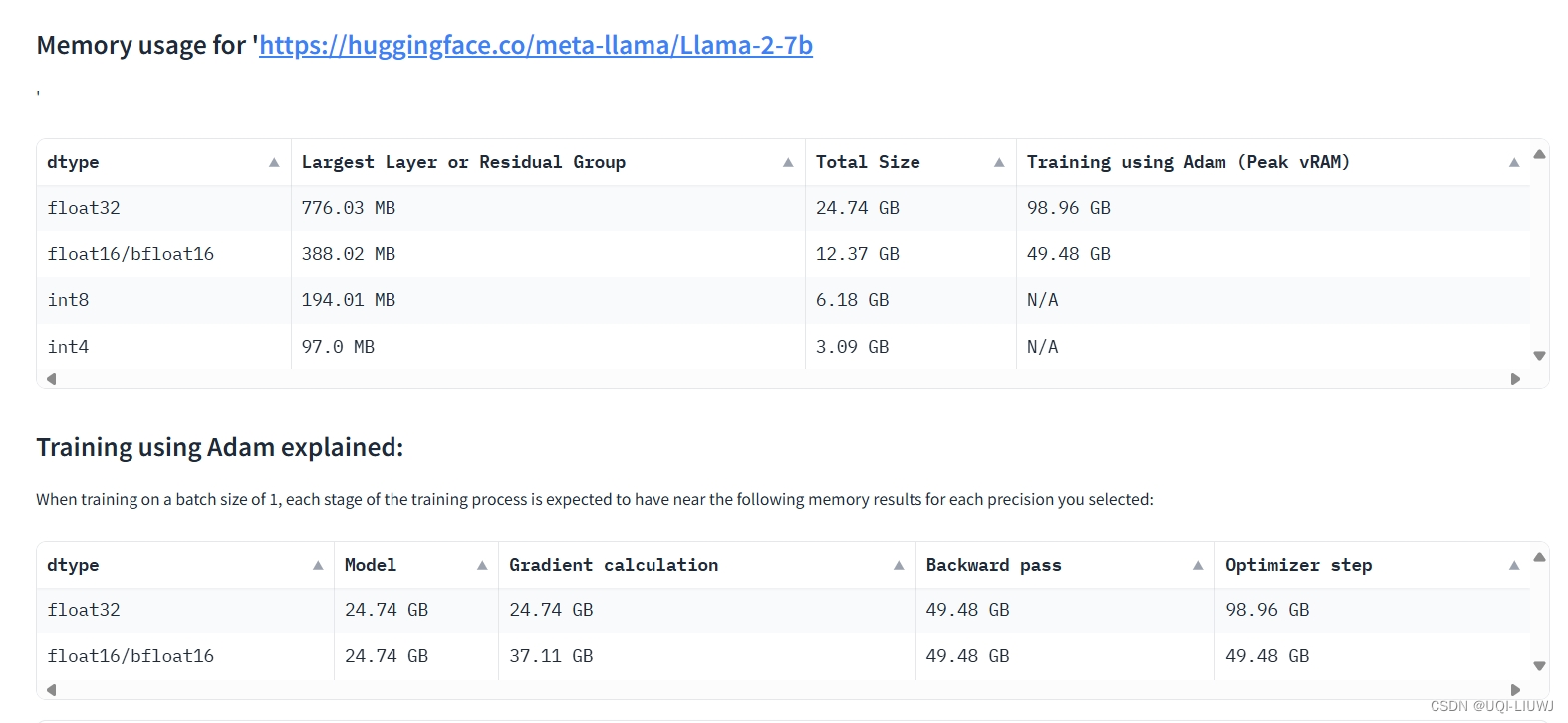
网站笔记:huggingface model memory calculator
Model Memory Utility - a Hugging Face Space by hf-accelerate 这个工具可以计算在 Hugging Face Hub上托管的大型模型训练和执行推理时所需的vRAM内存量。模型所需的最低推荐vRAM内存量表示为“最大层”的大小,模型的训练大约是其大小的4倍(针对Adam…...

SpringBoot2.0.x旧版集成Swagger UI报错Unable to infer base url...解决办法
一、问题描述 1.1项目背景 SpringBoot2.0.9的旧版项目维护开发,集成Swagger-ui2.9.2无法访问的问题。不用想啊,这种老项目是各种过滤器拦截器的配置,访问不到,肯定是它们在作妖。懂得都懂啊,这里交给大家一个排错的办…...

软件项目详细设计说明书实际项目参考(word原件下载及全套软件资料包)
系统详细设计说明书案例(直接套用) 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件开发全文档下载(下面链接或者本文末个人名片直接获取):软件开发全套资料-…...

电脑文件qt5core.dll如何修复?如何快速的解决qt5core.dll丢失问题
软件应用程序依赖于各种复杂的文件系统以保证其顺畅运行。这些文件中,动态链接库(Dynamic Link Library,简称DLL)是Windows操作系统中实现多种功能的关键组件之一。然而,DLL文件出现问题是Windows用户可能面临的常见挑…...
USART串口通信(stm32)
一、串口通信 通信的目的:将一个设备的数据传送到另一个设备,扩展硬件系统 通信协议:制定通信的规则,通信双方按照协议规则进行数据收发 STM32F103C8T6 USART资源: USART1、 USART2、 USART3 自带波特率发生器&…...

快速分析变量间关系(Boruta+SHAP+RCS)的 APP(streamlit)
快速分析变量间关系(BorutaSHAPRCS)的 APP(streamlit) 以下情况下,你需要这个快速分析的APP: 正式分析之前的预分析,有助于确定分析的方向和重点变量;收集变量过程中,监测收集的变量…...
解决docker中container运行闪退终止的问题
在运行bindmount-test时,点击完运行按钮后闪退结束运行。 第一步查看log日志: 2024-05-18 23:46:18 Error: Cannot find module /app/nodemon 2024-05-18 23:46:18 at Function.Module._resolveFilename (internal/modules/cjs/loader.js:668:15) …...

Redis 性能管理
一、Redis 性能管理 #查看Redis内存使用 172.168.1.11:6379> info memory 1. 内存碎片率 操作系统分配的内存值 used_memory_rss 除以 Redis 使用的内存总量值 used_memory 计算得出。内存值 used_memory_rss 表示该进程所占物理内存的大小,即为操作系统分配给…...
节水“云”科普丨北京昌平VR节水云展馆精彩上线
2024年5月15日上午,由北京昌平区水务局主办的“推进城市节水,建设美丽昌平——2024年全国城市节约用水宣传周暨‘坚持节水优先 树立节水标杆’昌平节水在行动主题实践活动”隆重举办,活动期间,昌平区水务局应用VR虚拟现实技术创新…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...

C语言预处理指令全解析
第六章 预处理命令在c语言中,所有# 开头的指令,被称为预处理指令。gcc 编译预处理 所有的预处理指令,都要在这步处理完汇编编译连接#include包含头文件。 全局变量的声明,函数的声明, 自定义构造类型声明, …...