Langchain-Chatchat的markdownHeaderTextSplitter使用
文章目录
- 背景
- 排查步骤
- 官方issue排查
- 测试正常对话
- 测试官方默认知识库
- Debug排查
- vscode配置launch.json
- 命令行自动启动conda
- debug知识库搜索
- 测试更换ChineseRecursiveTextSplitter分词器
- 结论
- 关于markdownHeaderTextSplitter的探索
- 标准的markdown测试集
- Langchain区分head1和head2
- Langchain区分head1,head2,head3
- Langchain-Chatchat测试结果
- 分析Langchain-Chatchat的markdown文件加载
- 为什么Langchain-Chatchat会丢失标题
- 后记
背景
接上篇Langchain-Chatchat之pdf转markdown格式,pdf转markdown之后,使用官方的markdownHeaderTextSplitter分词器,创建完知识库之后进行问答,结果发现大模型无法正常返回,且日志报错如下:
File "/home/jfli/anaconda3/envs/py3.11/lib/python3.11/site-packages/langchain_community/chat_models/openai.py", line 493, in _astreamif len(chunk["choices"]) == 0:^^^^^^^^^^^^^^^^^^^^^
TypeError: Caught exception: object of type 'NoneType' has no len()
markdownHeaderTextSplitter这个分词器和markdown格式不是天生一对吗?为什么会出现这种报错?
排查步骤
官方issue排查
- https://github.com/chatchat-space/Langchain-Chatchat/issues/2062
- 重新install dashscope 无效
- 升级fschat 无效
- https://github.com/chatchat-space/Langchain-Chatchat/issues/3727
- 官方回答说这种类型的回答都代表大模型输出内容不对导致的。
- 所以就是要确认大模型是可用的,确认知识库的搜索结果是否符合预期。
测试正常对话
正常对话没问题,且大模型回复自己是千问,说明大模型也正常加载使用。
测试官方默认知识库
测试sample知识库的问题,结果是可以正常回复。说明大模型对于知识库的问答是生效的状态。
Debug排查
vscode配置launch.json
{// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Langchain-Chatchat","type": "debugpy","request": "launch","program": "${workspaceFolder}/startup.py","args": ["-a"],"console": "integratedTerminal","python": "/home/xxx/anaconda3/envs/py3.11/bin/python"}]
}
命令行自动启动conda
因为环境依赖都在conda下,如果不配置自动开启conda的话,服务会因为缺少依赖起不来。
配置launch.json的参数中没办法设置conda环境。有一种使用方法是先定义个task.json,在launch.json中定义preLaunchTask制定先运行task.json,在task.json中启动conda环境。
参考:利用launch.json和tasks.json 文件进行vscode 调试以及自动编译_tasks.json make编译-CSDN博客
经验证,没有成功。
第二种方法是直接修改zshrc文件,在文件下面新增:
conda activate py3.11
这样每次打开新的终端都会自动启动conda环境,缺点就是每次启动py3.11环境,如果需要切换环境的话需要自己手动切换。
debug知识库搜索
- 初始化模型
- 实例化模型的时候,api地址对应的端口是20000
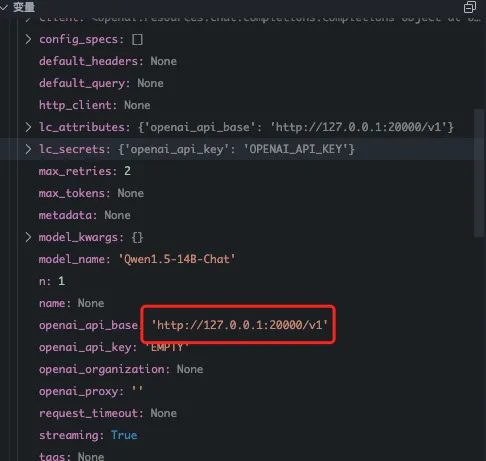
- 实例化模型的时候,api地址对应的端口是20000
- 查看知识库搜索结果
- 可以看到在向量库已经拿到数据了,根据向量返回的内容组装context,请求大模型出错。

- 查看启动配置,发现model_worker已经正常启动了
- 可以看到在向量库已经拿到数据了,根据向量返回的内容组装context,请求大模型出错。
2024-05-11 17:52:50 | INFO | model_worker | Register to controller
INFO: Started server process [3818873]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:7861 (Press CTRL+C to quit)
- 为什么请求大模型是走的20000这个端口呢?而不是配置中的21012端口?
- langchain-chatchat中默认的openai 端口是20000,这个配置会作为api_base传递给ChatOpenAI类,最后组装langchain的LLMChain,发起大模型请求。
- 目前发现请求大模型的地址
http://127.0.0.1:20000/v1/chat/completions# 这个地址是初始化openai的时候,使用fastchat提供的fastapi路由,
# 文件在fastchat.serve.openai_api_server# qianwen 大模型实际部署的端口是21012,对不上,是否会是这个问题呢?
- 参考fastchat的文档:https://github.com/lm-sys/FastChat/blob/main/docs/openai_api.md
- http://127.0.0.1:20000是fastchat启动的restful的api地址,同时也要启动模型工作线程 fastchat.serve.model_worker
- 测试fastchat中是否可以调用本地的qianwen-14B的模型
# 查看当前启动的模型
curl "http://127.0.0.1:20000/v1/models"# 返回了qianwen-14B
{"object":"list","data":[
{"id":"Qwen1.5-14B-Chat","object":"model","created":1715421368,
"owned_by":"fastchat","root":"Qwen1.5-14B-Chat","parent":null,
"permission":[{"id":"modelperm-4dMH93oGAz7eFLMoAdKegr","object":"model_permission","created":1715421368,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":true,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}
]}]}# 查看启动的模型
curl -X POST "http://127.0.0.1:20001/list_models"
{"models":["Qwen1.5-14B-Chat"]}# 和模型交流
curl http://localhost:20000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen1.5-14B-Chat","messages": [{"role": "user", "content": "Hello! What is your name?"}]}'# 模型回答{"id":"chatcmpl-3ySLAgNaGJUqXcbu39cAmf","object":"chat.completion","created":1715421533,"model":"Qwen1.5-14B-Chat","choices":[{"index":0,"message":{"role":"assistant","content":"Hello! My name is Assistant. I'm here to help you with any questions or tasks you need assistance with. How can I help you today?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":25,"total_tokens":55,"completion_tokens":30}}
3. 结论是访问20000端口请求大模型没问题,fastchat可以找到启动的大模型实例。20000端口是fastchat的controller地址,实际的大模型由model_worker启动。
- 错误堆栈追踪
- 追踪堆栈发现是调用langchain的langchain_core/language_models/chat_models.py,调用了_agenerate_with_cache函数,但并没有命中cache,走了617行
- 命中langchain_community/chat_models/openai.py的_agenerate函数
- 最终报错是在langchain_community/chat_models/openai.py的_astream函数,代码如下:
async for chunk in await acompletion_with_retry(self, messages=message_dicts, run_manager=run_manager, **params):if not isinstance(chunk, dict):chunk = chunk.dict()if len(chunk["choices"]) == 0:continuechoice = chunk["choices"][0]# 错误代码
if len(chunk["choices"]) == 0:
- 拿到知识库返回的context,手动调用大模型查询试试?
- 知识库返回5w多个字符,不符合预期。
- 从返回内容上来看,充斥着大量的"##############" ,不符合我们的预期。使用MarkdownHeaderTextSplitter只是想保留标题,按照标题来分块,而不是污染原来的文档。
- 更改markdownHeaderTextSplitter的配置
- 默认的配置如下
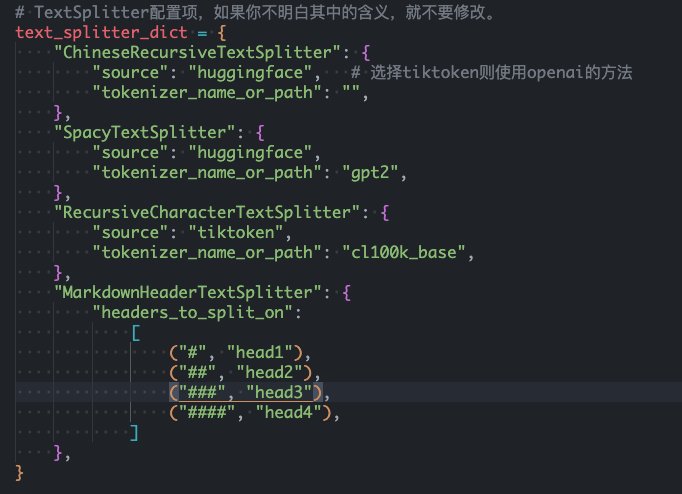
- 更改为只保留head1和head2看看
- 结果依然不行,文档含有大量的"##############",且分块只有2个。如果是textSplitter的话,分块有165个,比较正常。
- 猜测是markdownHeaderTextSplitter适合标准格式的markdown文件,我们这里把pdf转换成markdown并不标准,格式不统一。此时通过markdownHeaderTextSplitter分词识别到的head1和head2比较少,导致分块只有2个。
- langchain-chatchat中分词配置中的chunkSize和overlapSize对markdownHeaderTextSplitter不生效。如果markdown文件不标准的话,可能一个块有几w个字,会影响大模型的输出。
- 更改markdownHeaderTextSplitter的配置到head6
- 知识库分块明显多了,从2个块变成了35个块。
- 部分问答可以出来,部分问答依然返回错误。
- 默认的配置如下
测试更换ChineseRecursiveTextSplitter分词器
- 可以正常被搜索到,返回1216个字符
- 返回的内容依然是带有markdown格式的内容,保留了表格的关系
- 知识库查看数据可以正常分块,一共165个块。

结论
pdf转markdown之后生成的markdown格式不够标准,这种情况下使用markdownHeadertextSplitter进行分词的效果不符合预期。
且因为配置文件中的chunkSize和overlapSize对markdownHeaderTextSplitter不生效,导致分块结果很差,一个块几万个字。
大模型是拿到知识库查询的结果,作为"context"传过去的,几万个字传给大模型,直接导致大模型推理时间过久且没有返回结果。
关于markdownHeaderTextSplitter的探索
标准的markdown测试集
# 查特查特团队
荣获AGI Playground Hackathon黑客松“生产力工具的新想象”赛道季军。
## 报道简介
2023年10月16日, Founder Park在近日结束的AGI Playground Hackathon黑客松比赛中,查特查特团队展现出色的实力,荣获了“生产力工具的新想象”赛道季军。本次比赛由Founder Park主办,并由智谱、Dify、Zilliz、声网、AWS云服务等企业协办。
## 获奖队员简介
+ 小明,A大学+ 负责Agent旅游助手的开发、场地协调以及团队住宿和行程的安排+ 在保证团队完赛上做出了主要贡献。作为队长,栋宇坚持自信,创新,沉着的精神,不断提出改进方案并抓紧落实,遇到相关问题积极请教老师,提高了团队开发效率。
# 你好啊
## 世界你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 中国你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
# 中午吃什么
## 世纪难题
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 为什么选择吃什么这么难
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 现在的年轻人到底需要什么?
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
# 早睡早起
## 为什么晚睡
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 晚睡的危害是什么
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
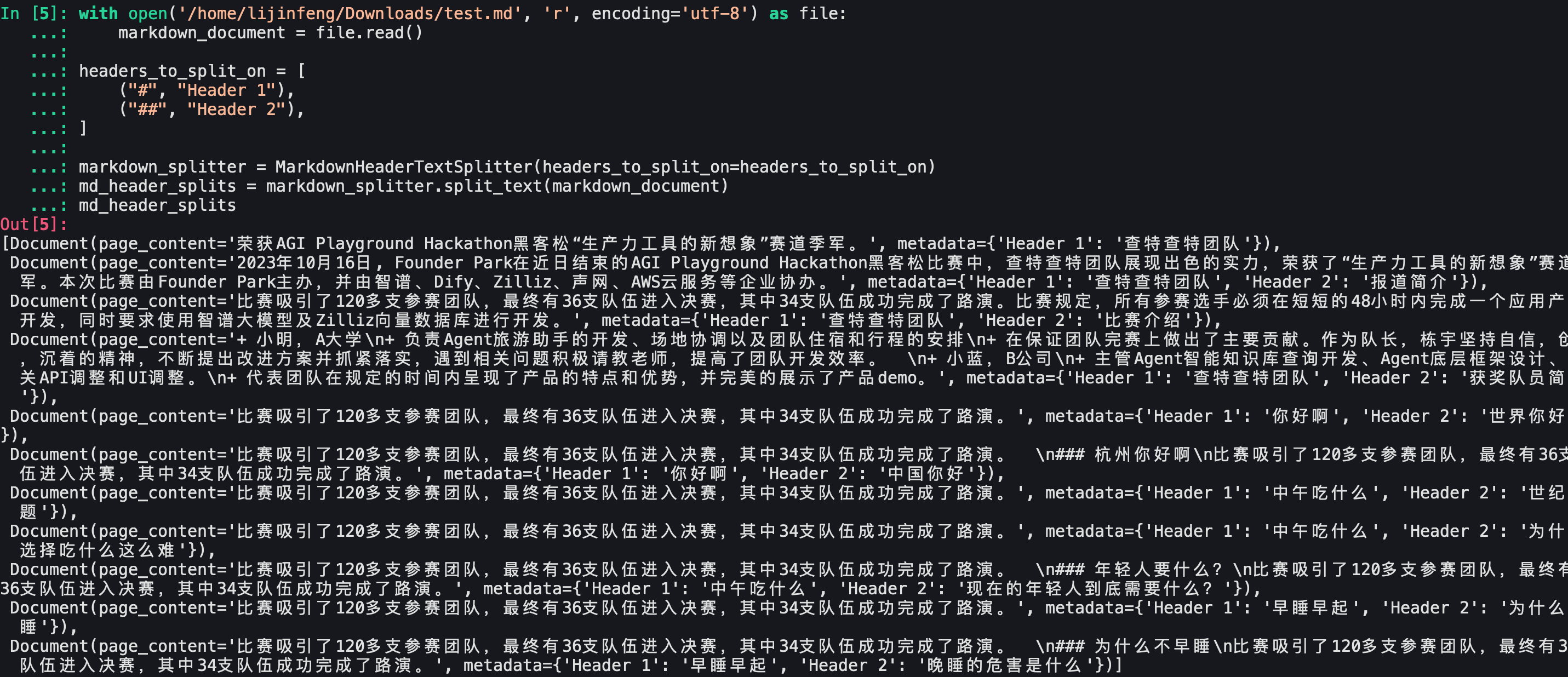
Langchain区分head1和head2
Langchain区分head1,head2,head3
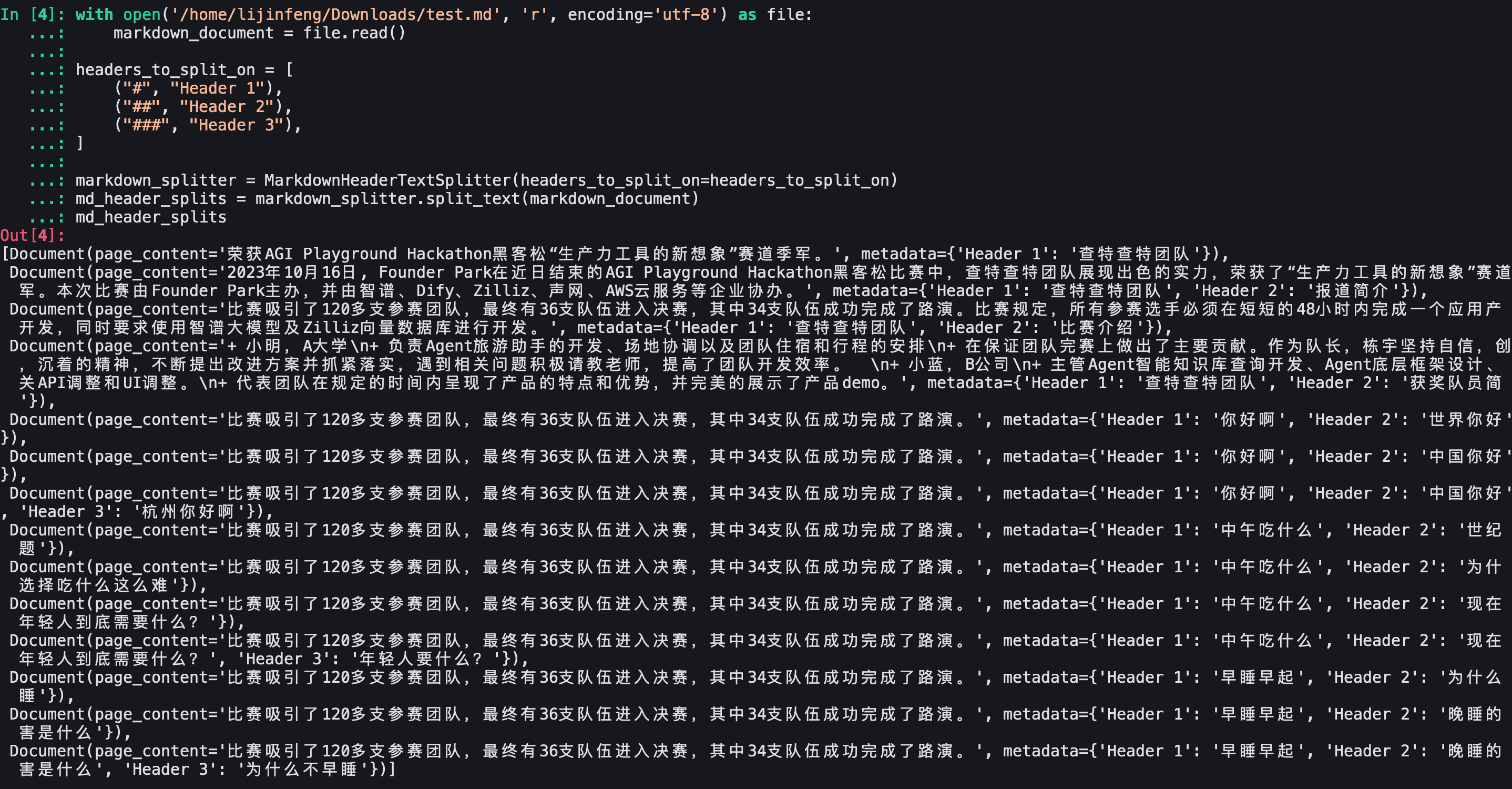
可以看到文档划分还是符合预期的。Langchain官方给出的测试demo没问题。
Langchain-Chatchat测试结果
更改markdown文件及分词器配置
- markdown文件包含一级,二级,三级标题
- 分词器只包含head1和head2
测试结果
- 依然只有一个文档
- 删除了md的分割标识符
- 保留了标题和内容的关系
- 没有保留标题的meta信息,不符合预期。
查特查特团队
荣获AGI Playground Hackathon黑客松“生产力工具的新想象”赛道季军。
报道简介
2023年10月16日, Founder Park在近日结束的AGI Playground Hackathon黑客松比赛中,查特查特团队展现出色的实力,荣获了“生产力工具的新想象”赛道季军。本次比赛由Founder Park主办,并由智谱、Dify、Zilliz、声网、AWS云服务等企业协办。
获奖队员简介
小明,A大学
负责Agent旅游助手的开发、场地协调以及团队住宿和行程的安排
在保证团队完赛上做出了主要贡献。作为队长,栋宇坚持自信,创新,沉着的精神,不断提出改进方案并抓紧落实,遇到相关问题积极请教老师,提高了团队开发效率。
你好啊
世界你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
中国你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
杭州你好啊
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
中午吃什么
世纪难题
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
为什么选择吃什么这么难
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
年轻人要什么?
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
早睡早起
为什么晚睡
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
为什么不早睡
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
分析Langchain-Chatchat的markdown文件加载
- 测试发现langchain-chatchat加载markdown文件使用的是langchain的markdown document loader
- 测试结果如下

- 也就是document loader的结果文件是没有markdown标识的,因此会导致进行markdownHeaderTextSplitter的时候,无法正确的按照标题来分割数据。
- document loader加上mode=“elements” 参数,发现可以区分标题了

- 测试markdownHeaderTextSplitter的效果
- 如果加上mode=“elements” 参数的话,markdown_splitter.split_text(markdown_document[0].page_content)的返回

- 如果不加 mode=“elements” 参数的话,结果是一整块
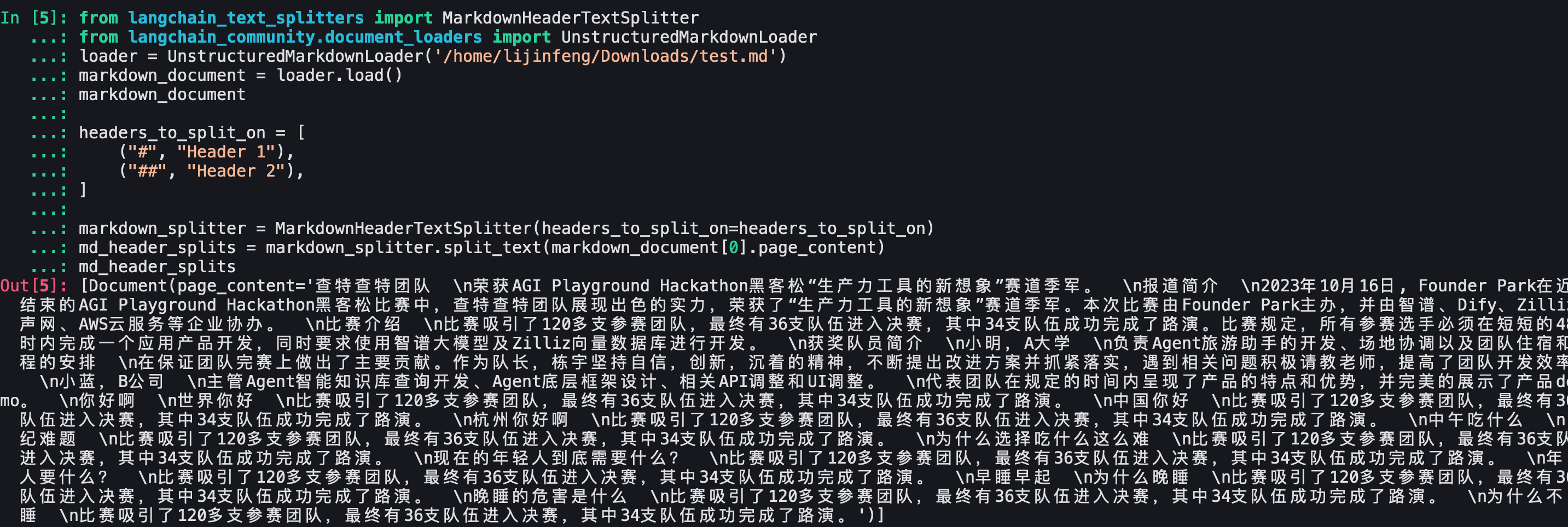
- 添加mode="elements"并且使用循环去进行split_text :

- 这个结果也不是符合预期的,只有文档内容page_content,没有meta信息,也没有标题信息。
- 如果加上mode=“elements” 参数的话,markdown_splitter.split_text(markdown_document[0].page_content)的返回
为什么Langchain-Chatchat会丢失标题
正如这篇文章所说: https://community.deeplearning.ai/t/loading-markdown-from-file-for-splitting/575875 langChain 中的 Markdown 加载器(UnstructedMarkdownLoader)删除了示例中分割文本所需的 Markdown 字符(例如:#、##、###)。所以按照标题分块是行不通的。
- 但是可以使用TextLoader来原样加载markdown文件,如下:

- 结合markdownHeaderTextSplitter
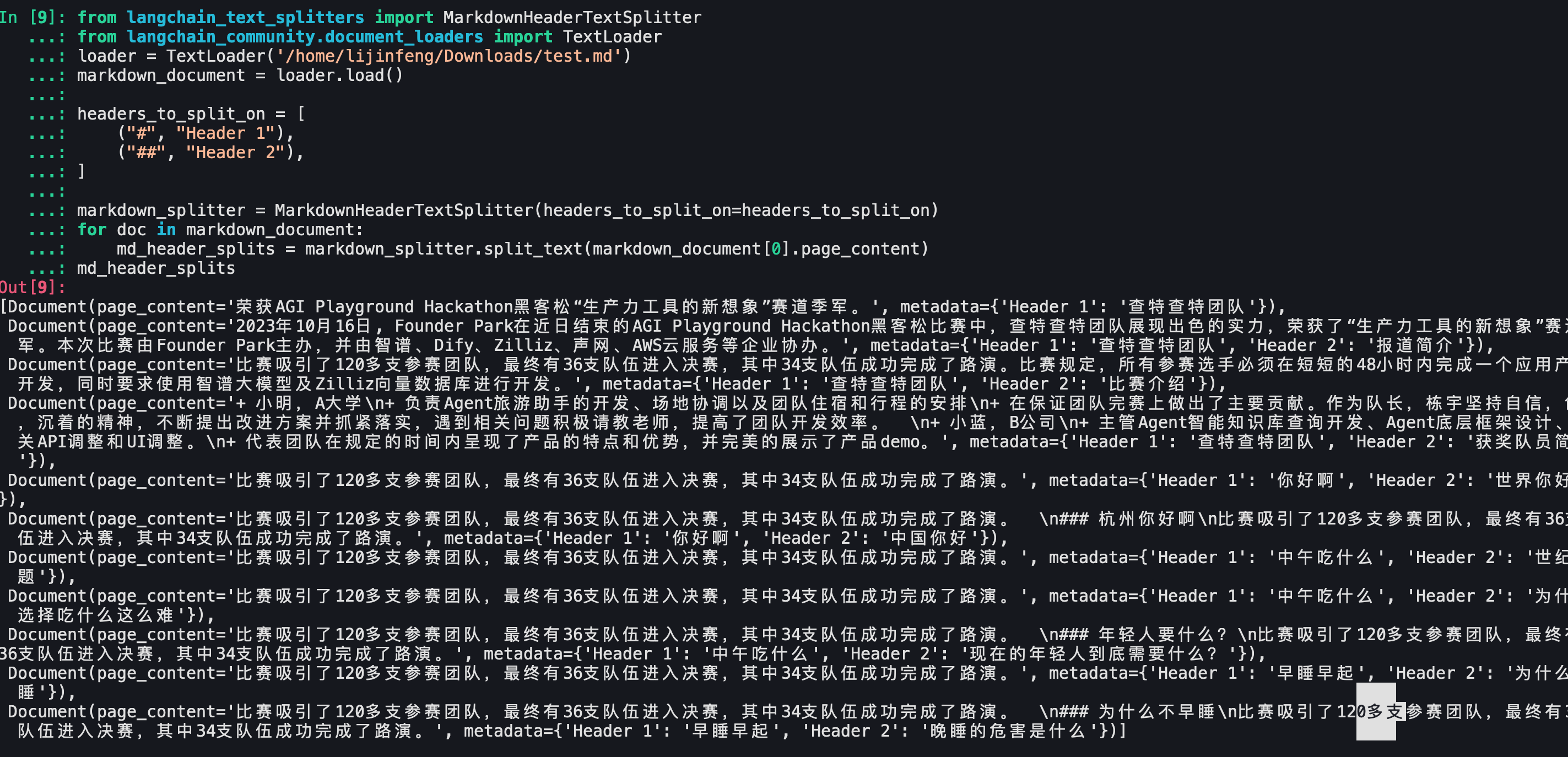
- 成功记录了标题信息,分块很成功!
后记
开源项目开箱即用是好事,但是直接拿来做产品还是欠佳的,怪不得大家最终都会走到自定义分词器的步骤,业务的需求千变万化,代码都掌握在自己手里才能以不变应万变啊。
就这样吧,还是挺有意思的。
end
相关文章:
Langchain-Chatchat的markdownHeaderTextSplitter使用
文章目录 背景排查步骤官方issue排查测试正常对话测试官方默认知识库Debug排查vscode配置launch.json命令行自动启动condadebug知识库搜索测试更换ChineseRecursiveTextSplitter分词器 结论 关于markdownHeaderTextSplitter的探索标准的markdown测试集Langchain区分head1和head…...
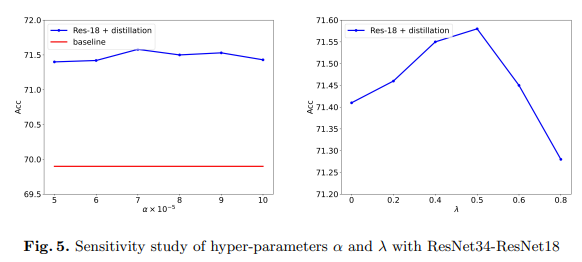
掩码生成蒸馏——知识蒸馏
摘要 https://arxiv.org/pdf/2205.01529 知识蒸馏已成功应用于各种任务。当前的蒸馏算法通常通过模仿教师的输出来提高学生的性能。本文表明,教师还可以通过指导学生的特征恢复来提高学生的表示能力。从这一观点出发,我们提出了掩码生成蒸馏(…...

【C#实战】Newtonsoft.Json基类子类解析
情景再现 假设你有如下类: public class Item {public int Id;public string Name; }public class Weapon: Item {public int CurrentAmmo; }public class Inventory {public List<Item> Items; } 其中你序列化的是Inventory类,Items列表里混杂着…...

表达式求值的相关语法知识(C语言)
目录 整型提升 整型提升的意义 整型提升规则 整型提升实例 算术转换 赋值转换 操作符的属性 C语言的语法并不能保证表达式的执行路径唯一!!! 问题表达式 整型提升 C的整型算术运算总是至少以缺省整型类型的精度来进行的。为了获得这…...

开发中遇到Electron自定义窗口的问题
开发中遇到Electron自定义窗口的问题 使用VUE3 Electron 开发一个音乐软件,自定义导航栏的放大、缩小和关闭。 其中使用ipcRenderer进行联系Electron,进行放大、缩小和关闭操作。 遇到问题 遇到__dirname is not defined in ES module scope //在V…...
c# sqlite使用
安装包 使用 const string strconn "Data Sourcedata.db"; using (SQLiteConnection conn new SQLiteConnection(strconn)) {conn.Open();var cmd conn.CreateCommand();cmd.CommandText "select 1";var obj cmd.ExecuteScalar();MessageBox.Show(ob…...
详解)
39、Flink 的窗口剔除器(Evictors)详解
Evictors Flink 的窗口模型允许在 WindowAssigner 和 Trigger 之外指定可选的 Evictor,通过 evictor(...) 方法传入 Evictor。 Evictor 可以在 trigger 触发后、调用窗口函数之前或之后从窗口中删除元素, Evictor 接口提供了两个方法实现此功能&#x…...

Flutter 中的 DefaultTabController 小部件:全面指南
Flutter 中的 DefaultTabController 小部件:全面指南 在Flutter中,DefaultTabController是一个用于管理Tab控制器的widget,它允许你控制Tab视图的初始索引和动态更新。这个组件在实现具有可滚动标签页的界面时非常有用,例如在设置…...
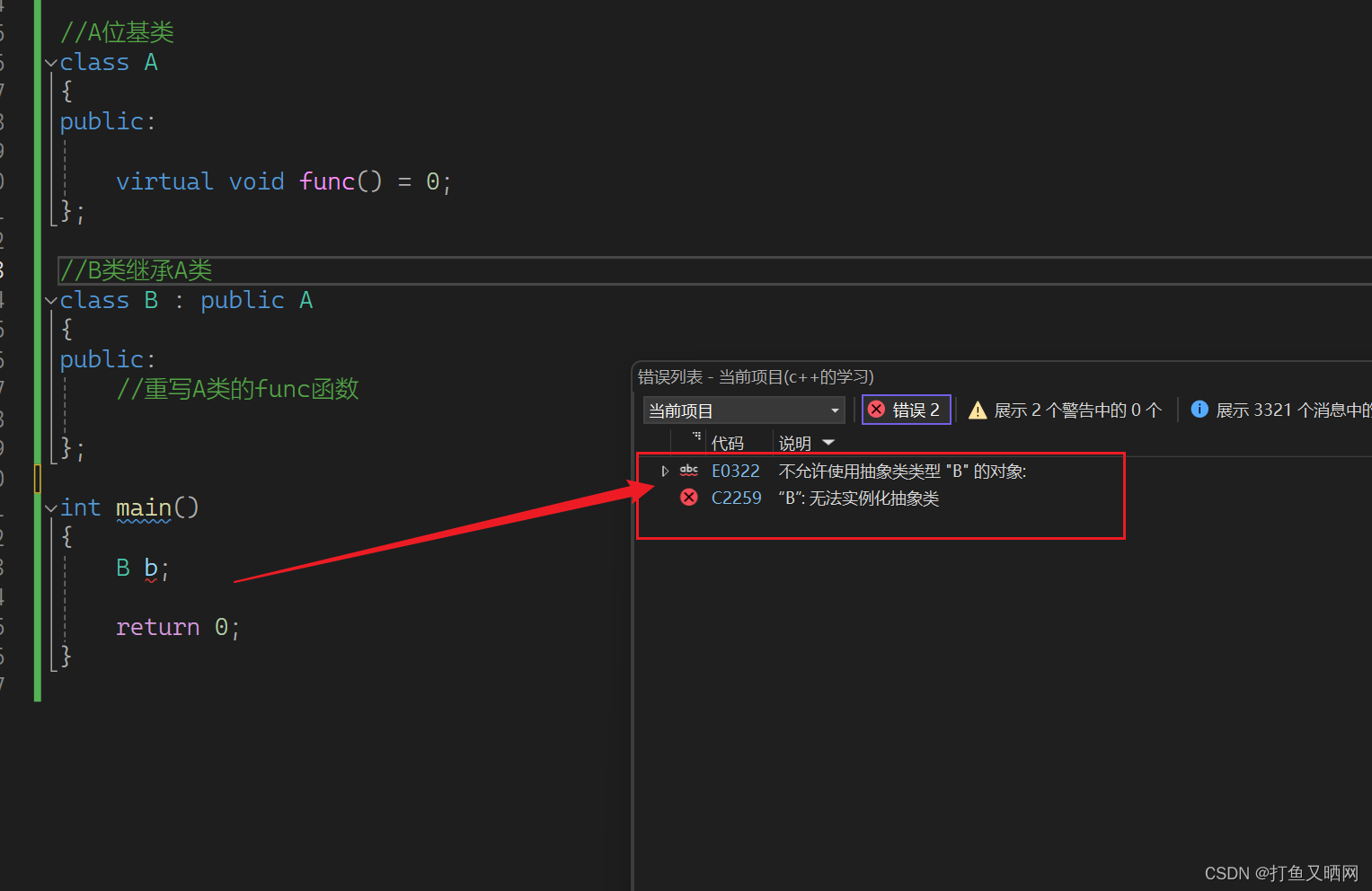
C++技能进阶指南——多态语法剖析
前言:多态是面向对象的三大特性之一。顾名思义, 多态就是多种状态。 那么是什么的多种状态呢? 这里的可能有很多。比如我们去买火车票, 有普通票, 学生票; 又比如我们去旅游, 有儿童票ÿ…...

Linux内存管理--系列文章肆
一、引子 上篇文章介绍了目标文件,也就是讲到编译过程中的汇编这个阶段。本篇要讲目标文件怎么变成一个可执行文件的,介绍编译过程中的链接。 链接主要分为两种,静态链接和动态链接。它们本质上的区别,是在程序的编译和运行过程中…...
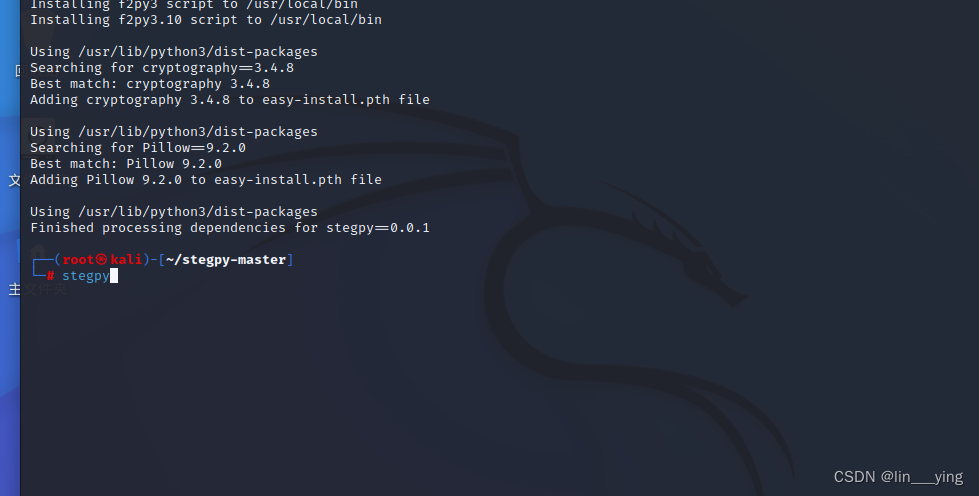
kali下载zsteg和stegpy
1.kali下载zsteg 从 GitHub 上克隆zsteg到kali git clone https://github.com/zed-0xff/zsteg 切换目录 cd zsteg 用于安装名为 zsteg 的 Ruby Gem 包 gem install zsteg 2.kali下载stegpy 下载网站内的stegpy-master压缩包GitCode - 开发者的代码家园 并拉到kali中 切换到s…...

前端面试题日常练-day34 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末。 1. jQuery中,以下哪个选项用于筛选出第一个匹配的元素? a) first() b) get(0) c) eq(0) d) find(":first") 2. 在jQuery中,以下哪个选项用于在元素上…...
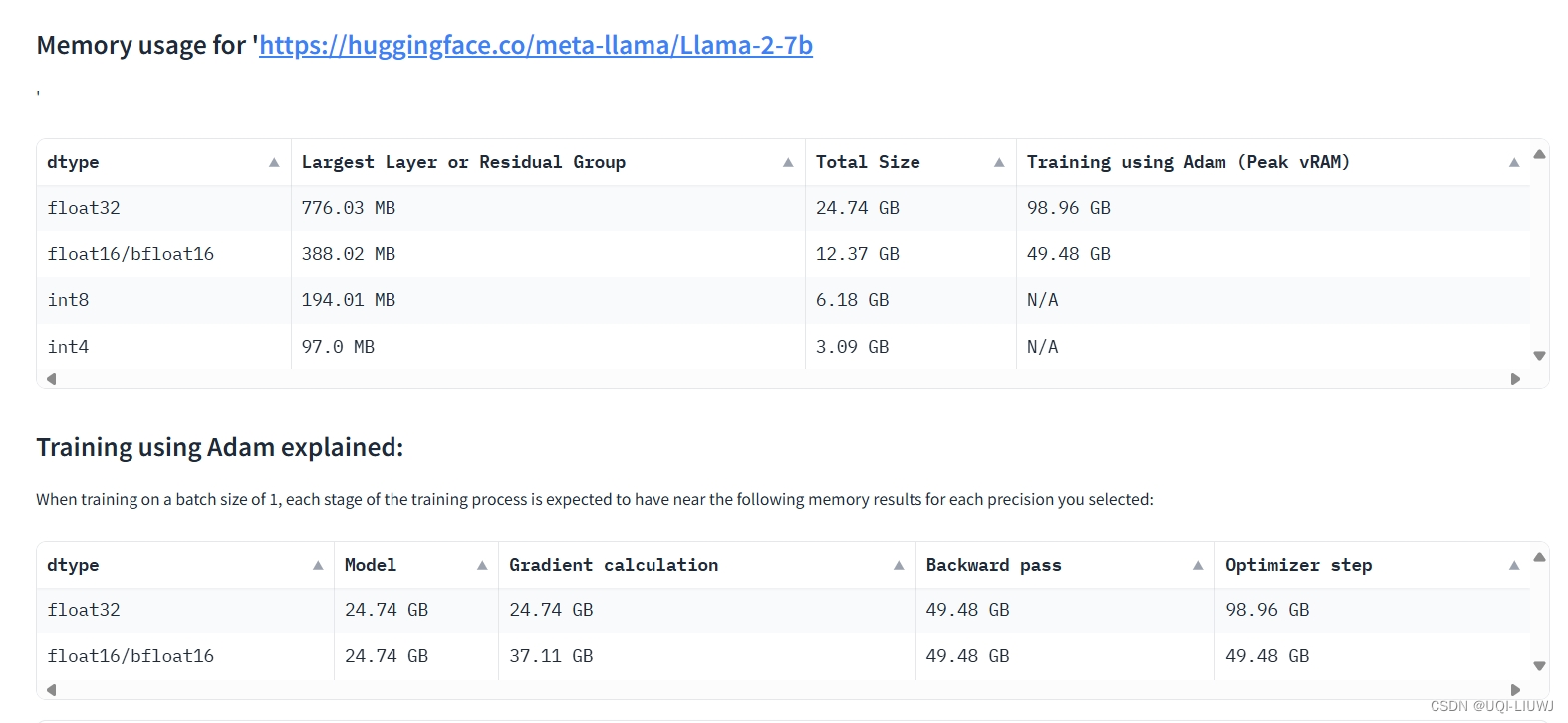
网站笔记:huggingface model memory calculator
Model Memory Utility - a Hugging Face Space by hf-accelerate 这个工具可以计算在 Hugging Face Hub上托管的大型模型训练和执行推理时所需的vRAM内存量。模型所需的最低推荐vRAM内存量表示为“最大层”的大小,模型的训练大约是其大小的4倍(针对Adam…...

SpringBoot2.0.x旧版集成Swagger UI报错Unable to infer base url...解决办法
一、问题描述 1.1项目背景 SpringBoot2.0.9的旧版项目维护开发,集成Swagger-ui2.9.2无法访问的问题。不用想啊,这种老项目是各种过滤器拦截器的配置,访问不到,肯定是它们在作妖。懂得都懂啊,这里交给大家一个排错的办…...

软件项目详细设计说明书实际项目参考(word原件下载及全套软件资料包)
系统详细设计说明书案例(直接套用) 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件开发全文档下载(下面链接或者本文末个人名片直接获取):软件开发全套资料-…...

电脑文件qt5core.dll如何修复?如何快速的解决qt5core.dll丢失问题
软件应用程序依赖于各种复杂的文件系统以保证其顺畅运行。这些文件中,动态链接库(Dynamic Link Library,简称DLL)是Windows操作系统中实现多种功能的关键组件之一。然而,DLL文件出现问题是Windows用户可能面临的常见挑…...
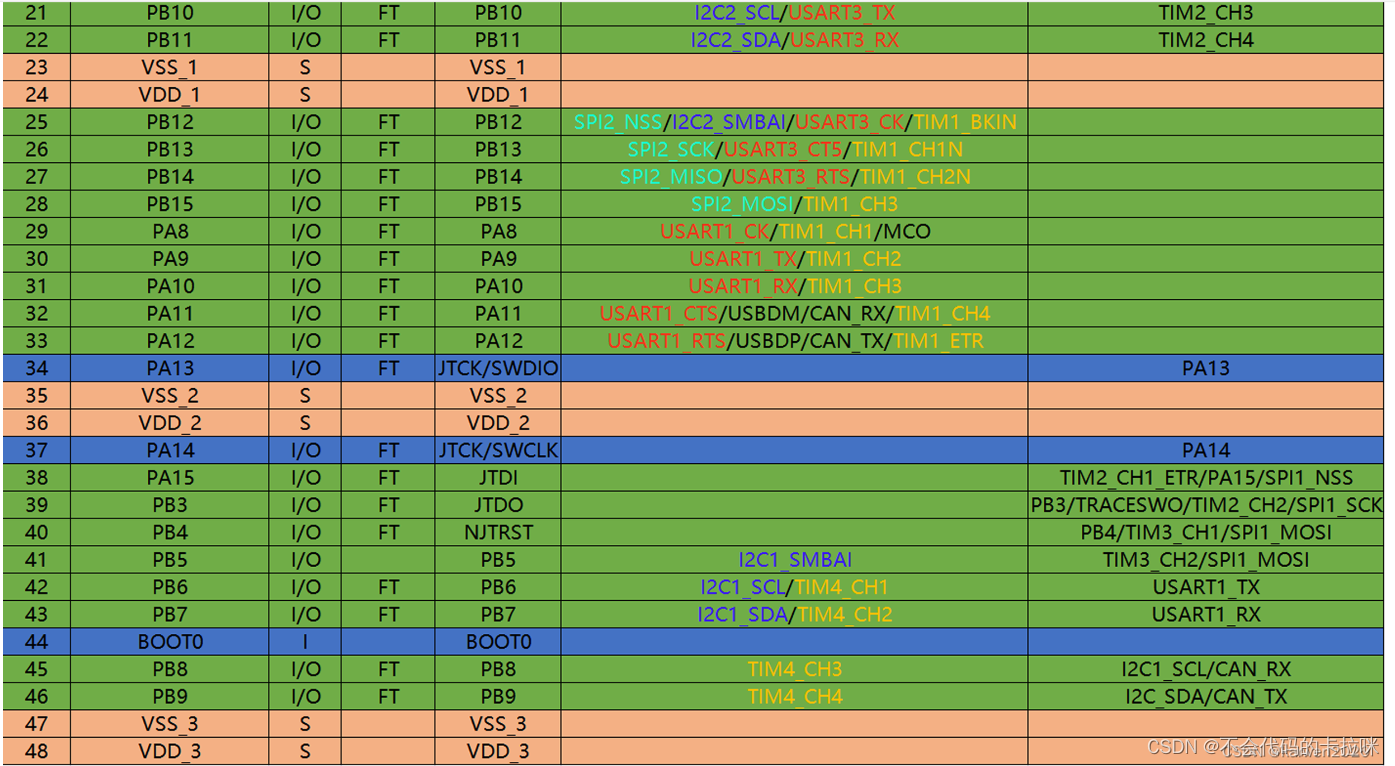
USART串口通信(stm32)
一、串口通信 通信的目的:将一个设备的数据传送到另一个设备,扩展硬件系统 通信协议:制定通信的规则,通信双方按照协议规则进行数据收发 STM32F103C8T6 USART资源: USART1、 USART2、 USART3 自带波特率发生器&…...

快速分析变量间关系(Boruta+SHAP+RCS)的 APP(streamlit)
快速分析变量间关系(BorutaSHAPRCS)的 APP(streamlit) 以下情况下,你需要这个快速分析的APP: 正式分析之前的预分析,有助于确定分析的方向和重点变量;收集变量过程中,监测收集的变量…...
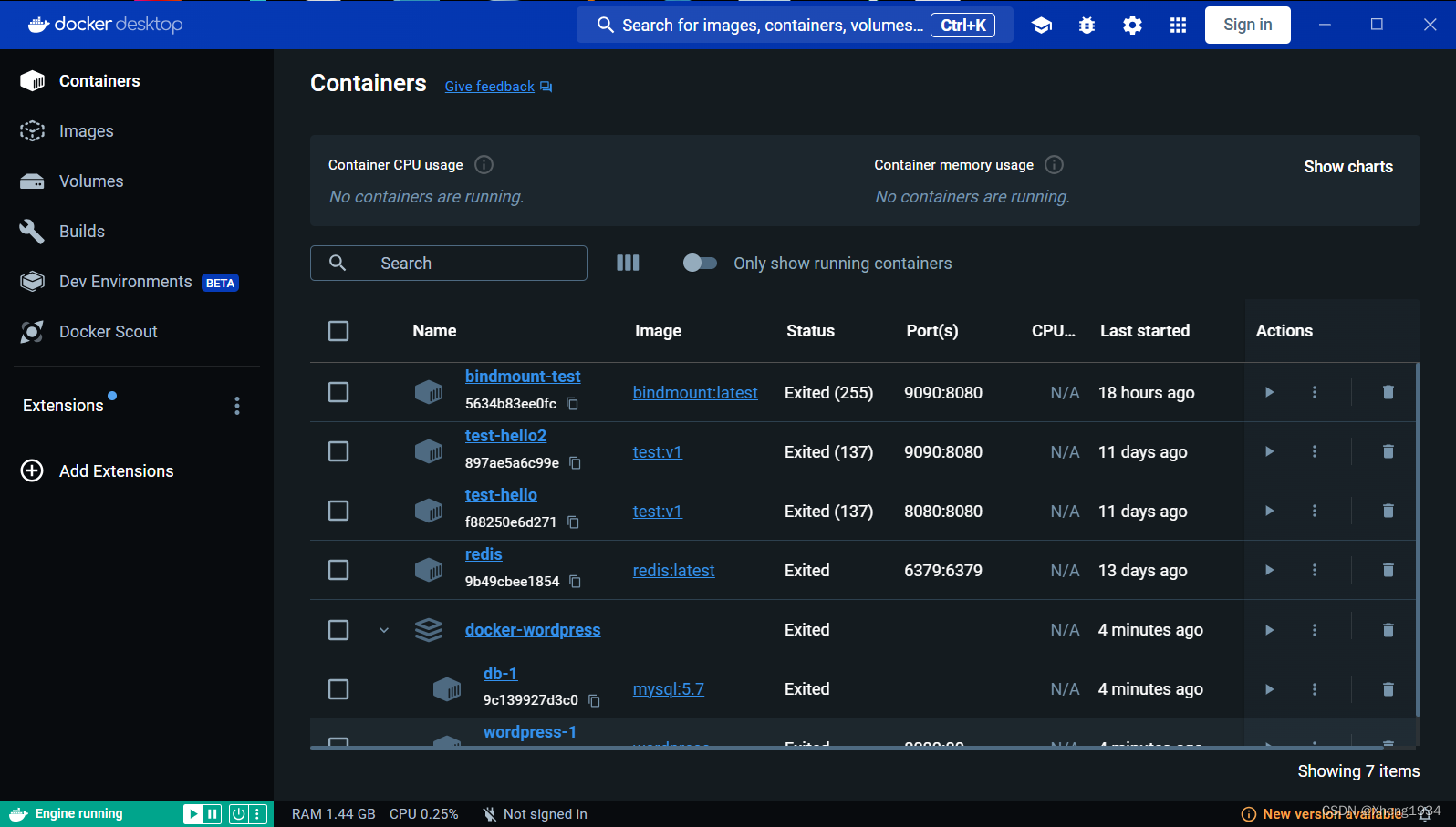
解决docker中container运行闪退终止的问题
在运行bindmount-test时,点击完运行按钮后闪退结束运行。 第一步查看log日志: 2024-05-18 23:46:18 Error: Cannot find module /app/nodemon 2024-05-18 23:46:18 at Function.Module._resolveFilename (internal/modules/cjs/loader.js:668:15) …...

Redis 性能管理
一、Redis 性能管理 #查看Redis内存使用 172.168.1.11:6379> info memory 1. 内存碎片率 操作系统分配的内存值 used_memory_rss 除以 Redis 使用的内存总量值 used_memory 计算得出。内存值 used_memory_rss 表示该进程所占物理内存的大小,即为操作系统分配给…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...