大模型效能工具之智能CommitMessage
01 背景
随着大型语言模型的迅猛增长,各种模型在各个领域的应用如雨后春笋般迅速涌现。在研发全流程的效能方面,也出现了一系列贯穿全流程的提效和质量工具,比如针对成本较高的Oncall,首先出现了高质量的RAG助手;在开发阶段的Copilot、Comate、Tabnine等辅助编程应工具;在测试阶段,也有缺陷检查、安全合规检查、智能Code Review等工具;哪怕在交付阶段,也有替代人工的自动化Agent…
当使用git commit提交代码时,需要写繁杂的CommitMessage,有时候写了后却不符合提交规范被hook,有时候还被CodeReview的同学点评写不到点上…智能CommitMessage就是这样一个小助手,帮你按照提交规范自动生成符合规范的CommitMessage。
以百度APP 的提交规范为例,规范包括提交类别、产品版本、需求卡片、变更摘要等,其中类别又包括:功能、更新、优化、提测、上车、Merge、FixBug等,手动抒写较为复杂。
按照CommitMessage的组合标准,可以分为两个部分:规范格式 + 变更摘要:

CommitMessage组成部分
- 普通摘要类:提交规范格式 + 变更摘要
- FixBug类:提交规范格式 + 变更摘要(包括bug原因、影响、修复方式等)
其中运用大模型能力生成变更摘要部分,而提交规范格式及其他标签由个性化插件定制,即可对不同业务线/产品线可定制符合提交规范的CommitMessage。
智能CommitMessage的最终使用效果如下:查看原文
git aicommit 用法示例
下面就以智能CommitMessage为例,介绍下大模型效能工具开发流程,主要包括:
- 简单的功能设计
- 应用指标和模型评估指标
- 大模型数据处理过程
- 模型性能优化的几种方式
02 功能与设计
用户入口一:git aicommit
Git是高效便捷的版本控制系统,虽然百度APP移动端已经多仓库化,随着组件化进程的完善,有至少有一半的需求不需要跨仓库提交而使用Git。
用户入口二:mgit aicommit
MGit (https://github.com/baidu/m-git)是百度自研的一套开源的、基于Git的多仓库管理工具,针对多仓库的应用场景安全地、高效的管理多个Git仓库,在基础版本之上增加MGit插件即可扩展或者修改原命令。
对入口的基本要求:
- Git/MGit入口的使用不影响原有git/mgit commit功能的使用,只是能力扩展
- 保证Git和MGit的入口分离的同时,保证功能统一,低成本维护
处理方式:抽象实现共用模块git-aicommit,该模块由MGit插件和Git alias命令直接调用,开发语言选型ruby,便于 MGit 插件直接调用。
git-aicommit模块:提取所有提交仓库中Git暂存区内的变更内容,请求模型服务生成Commit Message。

- MGit/Git入口,即用户使用入口,对于MGit插件可以参考MGit如何扩展(https://github.com/baidu/m-git);Git Alias按如下配置即可:
# 给 git 添加 Alias:git aicommit
$ git config --global alias.aicommit '!f() { ruby -e '''require "git-aicommit"; MGit::GitAICommit.run(ARGV);''' -- "$@"; }; f'
- 个性化插件:提交规范的格式定制,任何不同的提交规范均可定制为独立的插件,详细参考下面自定义提交规范章节。
- 模型服务:接受git-aicommit模块的请求,调用LLM生成CommitMessage摘要内容,加载对应的个性化插件生成最终的CommitMessage。
03 评估指标
管理学之父彼得·德鲁克说过:“If you can’t measure it, you can’t manage it.”。
度量指标对于模型选择、后续Prompt调优以及SFT都至关重要,因为它决定了优化的标准。
生成CommitMessage时,既需要理解变更的代码,也需要生成对应的摘要、评估影响等,生成式大模型适合此类任务,当前生成式大模型在市面上也百花齐放,经过综合评估使用成本(包括数据管理、部署运维、性能调优、Prompt和模型评估)、生成质量、安全风险等方面的考虑,我们选择了百度智能云千帆平台的ERNIE4(文心4)。
针对此类摘要任务,常用的度量指标有BLEU Score、ROUGE Score、BERT Score、PPL、MSE等,结合生成CommitMessage的任务特性,最终确定模型和产品的核心指标:
- 模型性能指标:MSE(Mean Squared Error,均方误差),用于衡量生成的文本序列与参考CommitMessage的文本序列之间的语义相似度;
- 用户使用指标:AR(Acceptance Rate,直接采纳率),也叫用户直接满足度,针对模型服务生成的CommitMessage,用户直接采纳的次数相对于总的使用次数的占比
均方误差MSE(Mean Squared Error)
参考CommitMessage的文本序列,指高质量的、简洁的、准确的、标准的CommitMessage,客观标准是至少包括:为什么修改(Why)、改了什么(What)、影响面(可选),主观标准是人工筛选并提取。
根据定义,计算MSE即计算两段文本的语义相似度差值,简单的分为如下三个步骤:
1.文本Embedding向量化:
- 将两段文本转换为向量表示。大模型时代Embedding的方式太多太多了,这里依然直接选用了千帆的Embedding方式。
2.向量差异计算:
- 计算两段文本的向量表示间的差异或距离时,我们选择使用余弦相似度;尽管欧几里得距离和马氏距离也是常用的方法,但针对CommitMessage这种长度不一致的向量时,余弦相似度表现更为准确。
3.均方误差计算:
- 将差异或距离平方,然后计算平均值以得到均方误差。
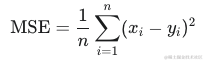
- 其中,xi 和 yi 是两段文本在第 i 个维度上的表示,n 是维度数量。
本文多次提交两个概念:
参考CommitMessage:可以是RD生成已提交入库的,也可以由大模型生成、经过人工标注的保证质量的CommitMessage,作为评估的标准yi
生成CommitMessage:由大模型生成的CommitMessage,评估输入的判定项xi
直接采纳率AR(Adoption Rate)
总的使用次数包括3个结果:
- 直接采纳数 CA
- 编辑采纳数 CE
- 拒绝数 CR
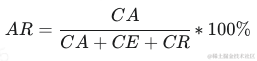
04 数据处理
大模型应用开发为了更好的性能(包括生成质量、效率、准确度、采纳率),数据处理的成本投入较高,通常占据整个应用开发投入的相当大的比例,有时甚至可能超过模型训练和调优的工作量。总之,有效和高效的数据处理是提升模型性能的关键因素,因此在项目计划和资源分配中应给予足够的重视和投入。
数据处理的目标就是管理(增删改/标查)好数据集,产物是各类数据集,数据集的最终应用场景是模型的性能优化(模型选择、Prompt优化、SFT),也就是说,如果不做性能优化,就可以不用做数据处理。
数据集与性能优化的关系如下:
- 评估集,模型选择、Prompt调优、SFT后都需要评估集对本次调优进行评估,是否比之前的好,是否达到调优的效果
- 训练集,指用于SFT的标注数据,根据特征从总数据集中筛选
- 验证集,验证集是用来调整模型超参数,避免过拟合或欠拟合
- 测试集,SFT后测试是否达到SFT的目的,比如针对某个异常case评估其泛化能力
- 异常集,标注环节明确的低质量的CommitMessage数据,特别是大模型生成未被直接采纳的数据

这里介绍下大体的过程及其作用,细节不做展开:
- 定义数据结构:模型数据(需求/bug卡片标题、变更数据)、参考CommitMessage、类别数据(是否bug、变更行、仓库数)、辅助分析数据(产品线、平台、作者、Topic)等
- 数据采集:来源于:①线上模型服务生成的CommitMessage;②存量RD已提交入库的CommitMessage;③其他开源数据集
- 数据清洗:去噪、去重等处理,确保数据的质量和可用性
- 标注与注释:标注本条数据作为参考CommitMessage的质量,其他辅助分析信息
- 分类与管理:抽样配比、过滤筛选、查看等
根据我们当前的数据体量,选择了Pandas(https://pandas.pydata.org/)作为数据处理工具,它对小规模数据和单机环境提供了够用的数据处理和分析功能。然而,随着数据体量的逐步增大,Spark(https://spark.apache.org/)将是一个不错的选择。
05 性能优化
性能优化的目标是提升性能指标,包括核心指标均方误差MSE和生成效率,进而提升用户直接采纳率AR,手段包括如下三种:
- 停止标记(Stop Token),可提升生成效率
- Prompt优化,可优化MSE指标和提升生成效率
- SFT可优化MSE指标
5.1 停止标记
当模型对Prompt理解不完全时,容易生成多余的解释或注意事项等无效内容,生成更多的Token导致生成效率降低(生成效率与生成的Token长度直接相关),而所有Transformer模型中都设计有停止标记,比如智能CommitMessage里调用模型的输出是一个Markdown的json,以“%STOP%”结尾,可指定停止标识为“%STOP%”以提高生成效率。
5.2 Prompt优化
简单说Prompt优化就是设计和优化输入Prompts以获得期望的输出。看似一个简单的NLP任务,却又叫Prompt工程?因为需要让大模型更好的理解期望的需求,确实涉及多学科的知识,比如融合语言学、心理学、计算机科学、数据科学,也包括整套工程方法:系统设计、实验设计、质量控制、项目管理等等方面。智能CommitMessage里涉及的两个优化点:
- 限制输出内容,明确要求
CommitMessage调用模型的输出要求是Markdown的json,如果模型输出不是正常的json将导致解析异常,此时在Prompt中明确要求『请仅输出内容,不要做任何解释』可避免生成无效内容,提高生成效率和准确性。
- Few-shot
Prompt优化里有个优化在限制输出样式的情况下非常有效 --Few-shot,以示例让大模型理解并限制输出样式,要求输出一个Markdown 的多行的 json 数据,样例:
按以下格式输出CommitMessage,只是一个markdown的代码片段,包含在"```json" 和 "```"内,『请仅输出内容,不要做任何解释』:
```json
{"summary": string // 少于30字的中文,简洁的、准确的描述Git Commit Message"reason": string // 分析修复方式,详细描述这个bug出现的具体原因,可以引用代码,少于60字"fixup": string // 分析修复方式,简洁、准确的描述修复方式,可以引用代码,少于30字
}
```
这里的样例不是一个标准的json格式(多行换行时缺少“,”),大模型可能按照该格式输出,也可能按照正确的json格式输出,所以存在一个异常问题的不确定性,可通过完善该Few-shot完全避免该问题:
按以下格式输出CommitMessage,只是一个markdown的代码片段,包含在"```json" 和 "```"内,『请仅输出内容,不要做任何解释』:
```json
{"summary": string, // 少于30字的中文,简洁的、准确的描述Git Commit Message"reason": string, // 分析修复方式,详细描述这个bug出现的具体原因,可以引用代码,少于60字"fixup": string // 分析修复方式,简洁、准确的描述修复方式,可以引用代码,少于30字
}
```
这里有个类似的概念:Prompt Tuning,Few-shot 和 Prompt Tuning都是优化和调整大型语言模型输入提示的方法,但有着本质上的区别:

附上智能CommitMessage的部分Prompt(持续优化中):
通俗易懂的角色描述:基于需求描述和实现该需求的git diff变更代码,自动生成规范的git提交信息。
需求描述的标题如下:{{%title}}git diff变更代码如下:
(DIFF-START)
{{%git_diff}}
(DIFF-END)任务拆解
1. 解析需求标题:
提取关键信息,如功能点、问题点等。
对文本进行清洗,去除无关字符和格式。
2. 分析git diff变更代码:
识别变更的文件和代码块。
分析代码变更的类型(如新增、修改、删除等)。
3. 生成Commit Message:
结合需求标题以及代码变更分析,编写Commit Message。
确保提取的内容符合对应项的要求,如“summary: 少于30字的中文,简洁的、准确的描述Git Commit Message”等。
4. 验证Commit Message:
检查Commit Message是否清晰、准确。
5. 按以下格式输出CommitMessage,只是一个markdown的代码片段,包含在"`json" 和 "`"内,『请仅输出内容,不要做任何解释』:
```json
{"summary": string // 少于30字的中文,简洁的、准确的描述Git Commit Message
}
```%STOP%
5.3 SFT
因为文心4的模型能力已经有非常出色的生成能力,在这种大模型上做SFT成本非常高,所以一般会采用ERNIE-lite版本或者ERNIE-Speed版本,但是性能稍逊一筹,那如何保证在ERNIE-Speed版本中SFT后既能不降低整体性能,又能优化低质量case?
这里可以采用MoE(Mixture of Experts)的策略,用一个分类器来结合ERNIE4 + (ERNIE-Speed + SFT)各自的优势,即请求优先经过一个分类器,根据请求的特征进行分类请求ERNIE4或者经过SFT后的ERNIE-Speed模型,如下图示例:

部署前记得SFT评估数据集的全量评估,MSE优于线上保证本次SFT后的ERNIE-Speed模型比上次的更好。
SFT的全过程应该包含四个步骤:
- 确定目标:优化某个/某类低质量的数据case,微调后达到评估多少分值
- 数据准备:基于该case提取低质量case的特征,向数据集里筛选出训练集、验证集和测试集
- SFT过程:如上图所示
- 评估部署:根据抽样配比的评估集进行全量评估,保证本次SFT后的ERNIE-Speed模型比上次的更好
06 自定义提交规范
由于大模型只生成核心的变更摘要或者Fixbug的相关信息,而最终需要组合成各式各样的提交规范格式,所以可以将变化抽象为接口,可扩展python package实现接口达成自定义符合提交规范的CommitMessage,按需动态加载实现的插件。
抽象接口如下:
from abc import ABC, abstractmethodclass IPluginHook(ABC):"""插件实现的接口定义"""@abstractmethoddef hook_prepare(self, ctx):"""准备"""@abstractmethoddef hook_is_fix_bug(self, ctx) -> bool:"""是否fixbug的提交类型,默认false"""@abstractmethoddef hook_language(self, ctx) -> Language:"""生成语言,默认中文"""@abstractmethoddef hook_generate_variables(self, ctx):"""生成模板的变量"""@abstractmethoddef hook_generate_message(self, ctx) -> str:"""根据模板和变量,生成CommitMessage@warning: 该方法插件必须实现,否则将报出异常"""
加载某个插件的某个版本时,根据pkg_resources判定是已加载,然后配合 importlib进行import_module或者reload即可实现动态加载插件
def __install_plugin(pkg_name: str, version: str):"""安装插件"""subprocess.check_call([sys.executable, '-m', 'pip', 'install', f"{pkg_name}=={version}"])return __load_module(pkg_name, force=True)def __load_module(pkg_name: str, force: bool = False):"""加载module"""module_name = __module_name(pkg_name)loaded_module = sys.modules.get(module_name)if loaded_module is not None:if force:m = importlib.reload(loaded_module)importlib.reload(pkg_resources)return mreturn loaded_modulem = importlib.import_module(module_name)importlib.reload(pkg_resources)return m
07 未来
大模型对各类语言的代码理解上展现了卓越的能力,但对专有词汇、特定配置、固定格式等的理解依然存在不足,都需要合适的数据集来逐步优化;并且git diff获取的变更内容有限,受限于模型Token的限制,理解时缺少代码的上下文、依赖关系的关联导致生成质量存在瓶颈,结合RAG或许是一个较好的方式;使用入口的交互性、自定义提交规范都可以更AI,总之:AI Native 尚未成功,同志仍须努力。
——————END——————
参考资料:
[1] LangChain:https://www.langchain.com/
[2] git:https://git-scm.com/book/en/v2/Git-Basics-Git-Aliases
[3] pandas:https://pandas.pydata.org/
[4] Spark:https://spark.apache.org/
[5] 百度千帆:https://console.bce.baidu.com/qianfan/overview
[6] Prompt工程 大模型的应用与实践:https://zhuanlan.zhihu.com/p/668200325
推荐阅读:
基于afx透明视频的视觉增强前端方案
百度一站式数据自助分析平台(TDA)建设
浅析如何加速商业业务实时化
登录系统演进、便捷登录设计与实现
一文带你完整了解Go语言IO基础库
相关文章:
大模型效能工具之智能CommitMessage
01 背景 随着大型语言模型的迅猛增长,各种模型在各个领域的应用如雨后春笋般迅速涌现。在研发全流程的效能方面,也出现了一系列贯穿全流程的提效和质量工具,比如针对成本较高的Oncall,首先出现了高质量的RAG助手;在开…...
PyQt6--Python桌面开发(33.QToolBar工具栏控件)
QToolBar工具栏控件...

node环境问题(无法加载文件D:\Software\Node.js\node_global\vue.ps1,因为在此系统上禁止运行脚本。)
问题:npm安装lerna显示安装成功,但是lerna -v的时候报错 解决步骤: 1、输入:Get-ExecutionPolicy 2、输入:Set-ExecutionPolicy -Scope CurrentUser(有选项的选Y) 3、输入:RemoteSi…...
位运算算法
位运算是计算机中常用的一种运算方法,它直接对二进制数的位进行操作。位运算主要包括按位与(&)、按位或(|)、按位异或(^)、按位取反(~)、左移(<<&a…...

重学java 45.多线程 下 总结 定时器_Timer
人开始反向思考 —— 24.5.26 定时器_Timer 1.概述:定时器 2.构造: Timer() 3.方法: void schedule(TimerTask task, Date firstTime, long period) task:抽象类,是Runnable的实现类 firstTime:从什么时间开始执行 period:每隔多长时间执行一次…...

MongoDB(介绍,安装,操作,Springboot整合MonggoDB)
目录 MongoDB 1 MongoDB介绍 MongoDB简介 MongoDB的特点 MongoDB使用场景 小结 2 MongoDB安装 安装MongoDB 连接MongoDB MongoDB逻辑结构 MongoDB数据类型 小结 3 MongoDB操作 操作库和集合 操作文档-增删改 操作文档-查询 MongoDB索引 小结 4 SpringBoot整合…...

【数字移动通信】期末突击
文章目录 复习题一.简答题1、常用的移动通信系统有哪些?2、分别列出1G,2G,3G,4G的典型系统或标准?3、移动通信信道的基本特征?4、电波传播预测模型是用来计算什么量的,在选择传播预测模型时,主要考虑哪些因素?5、什么…...
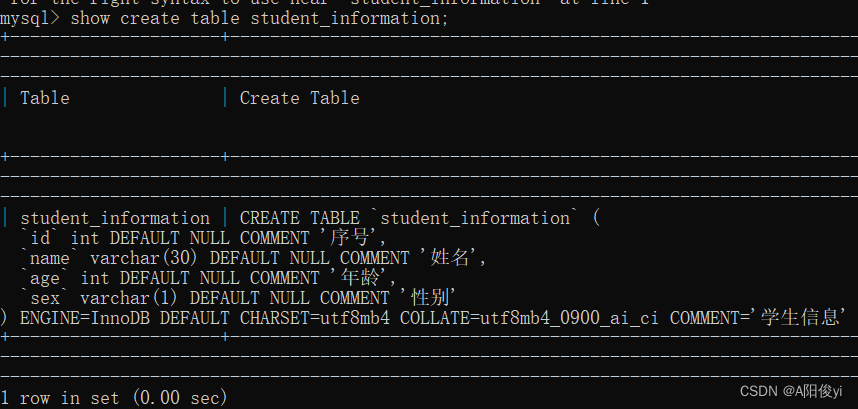
数据库(5)——DDL 表操作
表查询 先要进入到某一个数据库中才可使用这些指令。 SHOW TABLES; 可查询当前数据库中所有的表。 表创建 CREATE TABLE 表名( 字段1 类型 [COMMENT 字段1注释] ...... 字段n 类型 [COMMENT 字段n注释] )[COMMENT 表注释]; 例如,在student数据库里创建一张studen…...
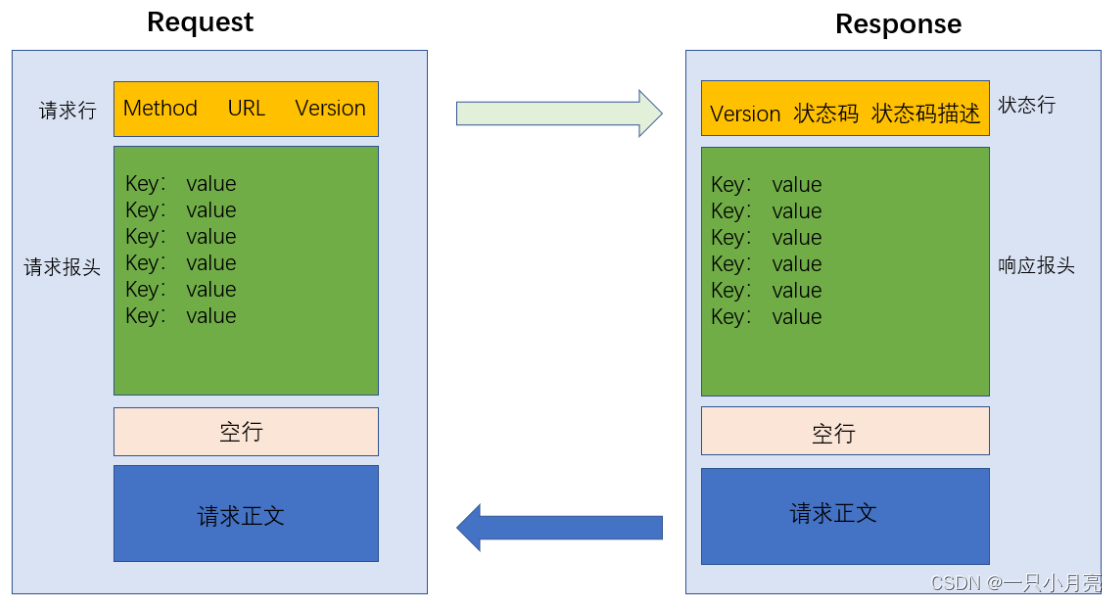
【Java EE】网络协议——HTTP协议
目录 1.HTTP 1.1HTTP是什么 1.2理解“应用层协议” 1.3理解HTTP协议的工作过程 2.HTTP协议格式 2.1抓包工具的使用 2.2抓包工具的原理 2.3抓包结果 3.协议格式总结 1.HTTP 1.1HTTP是什么 HTTP(全称为“超文本传输协议”)是一种应用非常广泛的应…...

Docker提示某网络不存在如何解决,添加完网络之后如何删除?
Docker提示某网络不存在如何解决? 创建 Docker 网络 假设现在需要创建一个名为my-mysql-network的网络 docker network create my-mysql-network运行容器 创建网络之后,再运行 mysqld_exporter 容器。完整命令如下: docker run -d -p 9104…...

C++ 红黑树
目录 1.红黑树的概念 2.红黑树的性质 3.红黑树节点的定义 4.红黑树的插入操作 5.数据测试 1.红黑树的概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何一条从根到叶子的路径上各个…...

PTA 6-4 配对问题
许多大学生报名参与大运会志愿者工作。其中运动场引导员需要男女生组队,每组一名男生加一名女生,男生和女生各自排成一队,依次从男队和女队队头各出一人配成小组,若两队初始人数不同,则较长那一队未配对者调到其他志愿…...

sklearn基础教程
scikit-learn是一个用于机器学习的Python库,提供了多种机器学习的方法和模型,以及数据预处理、特征选择、模型评估等功能。它简化了机器学习流程,并且具有易于使用和灵活的特点。 本教程将介绍sklearn的基础知识和常用功能,帮助你…...

MySQL入门学习-查询进阶.别名
别名(Alias)是为数据库中的表、列或表达式赋予的一个临时名称。使用别名可以使查询结果更具可读性,并且在复杂的查询中更方便地引用和处理数据。 在 MySQL 中,别名可以通过 AS 关键字来定义,例如: SELECT…...

【Rust日报】嵌入式 Rust:一份简化指南
EvilHelix 编辑器 EvilHelix 是一个采用 Vim 风格的模态编辑器,旨在提供快速且高效的编辑体验。它是 Helix 编辑器的一个分支,增加了 Vim binding,同时积极同步上游的特性,兼备了 Vim 和 Hexli 的优点: Vim 风格的模态…...

Web课外练习9
<!DOCTYPE html> <html> <head><meta charset"utf-8"><title>邮购商品业务</title><!-- 引入vue.js --><script src"./js/vue.global.js" type"text/javascript"></script><link rel&…...

rtsp协议分析
rtsp (real-time stream protocol)实时流媒体控制协议 属于基于文本的应用层协议,rtsp的底层协议可以是udp也可以是tcp ffmpeg 参数-rtsp_transport tcp 用于指定RTSP会话底层传输协议为TCP 本身并不传输流媒体数据,只是提供流媒体的控制,实…...
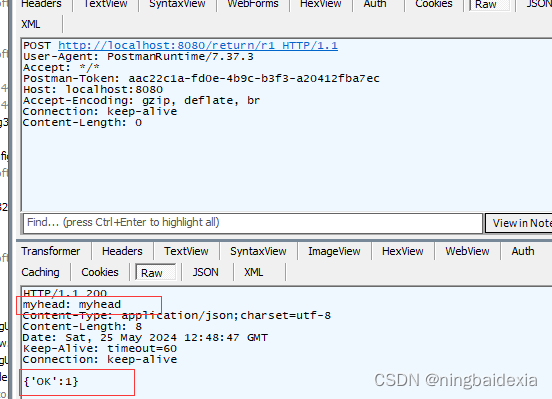
Spring Web MVC(2)
响应 Http响应的结果可以是数据也可以是静态页面可以针对响应设置状态码 Header信息 返回静态页面注解RestController和Controller 我们创建一个前端页面 package com.example.demo.demos.web.controller;import org.springframework.web.bind.annotation.RequestMapping; i…...

Python-图片旋转360,保存对应图片
#Author :susocool #Creattime:2024/5/25 #FileName:turn360 #Description: 会旋转指定的图像文件360度,并将每个旋转后的图像保存到指定目录,文件名以旋转角度命名。 from PIL import Imagedef rotate_and_save(image_path, output_dir) :# …...

JavaSE——集合框架二(1/6)-前置知识-可变参数、Collections工具类
目录 可变参数 Collections工具类 Collections的常用静态方法 实例演示 可变参数 可变参数 就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型...参数名称 可变参数的特点和好处 特点:可以不传数据给它&am…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...

为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍
为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/g…...