flink Data Source数据源
flink
Data Source数据源
Source
-
并行度
-
非并行:并行度只能为1
-
并行
-
-
基于集合的Source
-
fromElements
- package com.pxj.sx.flink;
-
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class FromElementDemo {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();configuration.setInteger(RestOptions.PORT, 8081);StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> daat = env.fromElements("flink", "spark", "hive");daat.print();Thread.sleep(2000000);}
}
- fromElements(T ...) 方法是一个非并行的Source,可以将一到多个数据作为可变参数传入到该方法中,返回DataStreamSource。该方法返回的DataStream是一个有限数据流,数据读完后,程序退出,通常用于开发测试。- fromCollection- fromCollection可以从一个结合读取数据,返回DataStream,该方法返回的DataStream是一个有限数据流,数据读完后,程序退出,通常用于开发测试。- package com.pxj.sx.flink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;
import java.util.List;public class FromCollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();List<String> wordList = Arrays.asList("flink", "spark", "hadoop", "flink");DataStreamSource<String> source = env.fromCollection(wordList);source.print();env.execute("pxj");}
}
- fromParallelCollection- fromParallelCollection(SplittableIterator, Class) 方法是一个并行的Source(并行度可以使用env的setParallelism来设置),该方法需要传入两个参数,第一个是继承SplittableIterator的实现类的迭代器,第二个是迭代器中数据的类型。该方法返回的DataStream是一个有限数据流,数据读完后,程序退出,通常用于开发测试。- package com.pxj.sx.flink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.types.LongValue;
import org.apache.flink.util.LongValueSequenceIterator;public class FromParallelCollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//Source是多个并行的DataStreamSource<LongValue> dataSource = env.fromParallelCollection(new LongValueSequenceIterator(1, 10), LongValue.class);dataSource.print();env.execute("pxj");}
}
- generateSequence- generateSequence(long from, long to) 方法是一个并行的Source(并行度也可以通过调用该方法后,再调用setParallelism来设置)该方法需要传入两个long类型的参数,第一个是起始值,第二个是结束值,返回一个DataStreamSource。该方法返回的DataStream是一个有限数据流,数据读完后,程序退出,通常用于开发测试。
-
基于Socket网络端口
-
socketTextStream(String hostname, int port) 方法是一个非并行的Source,该方法需要传入两个参数,第一个是指定的IP地址或主机名,第二个是端口号,即从指定的Socket读取数据创建DataStream。该方法还有多个重载的方法,其中一个是socketTextStream(String hostname, int port, String delimiter, long maxRetry),这个重载的方法可以指定行分隔符和最大重新连接次数。这两个参数,默认行分隔符是"\n",最大重新连接次数为0。
- package com.pxj.sx.flink;
-
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SocktDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.socketTextStream("pxj62", 8889);source.print();env.execute("pxj");}
}
-
基于文件
-
readFile
- package com.pxj.sx.flink;
-
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.FileProcessingMode;public class ReadFlie {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.readFile(new TextInputFormat(null), "data/a.txt",FileProcessingMode.PROCESS_CONTINUOUSLY, 2000).print();env.execute("pxj");}
}
- readTextFile- package com.pxj.sx.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class ReadFlieDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.readTextFile("data/a.txt");SingleOutputStreamOperator<Tuple2<String, Integer>> datas = source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {String[] strings = value.split(",");for (String s : strings) {out.collect(Tuple2.of(s, 1));}}});SingleOutputStreamOperator<Tuple2<String, Integer>> summed = datas.keyBy(0).sum(1);summed.print();env.execute("pxj");}
}
-
自定义Source
-
单并行度
-
可以实现 SourceFunction 或者 RichSourceFunction , 这两者都是非并行的source算子
- package com.pxj.sx.flink;
-
-
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;public class MySource2{public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.addSource(new MySource3());source.print();env.execute("pxj");}
}
class MySource3 extends RichSourceFunction<String> {private int i=0; //定义一个int类型的变量,从1开始private boolean flag=true; //定义一个flag标标志//run方法就是用来读取外部的数据或产生数据的逻辑@Overridepublic void run(SourceContext<String> ctx) throws Exception {while (i<=100 && flag){Thread.sleep(1000); //为避免太快,睡眠1秒ctx.collect("data:"+i++);}}@Overridepublic void cancel() {flag=false;}
}
- 多并行度- 也可继承 ParallelSourceFunction 或者 RichParallelSourceFunction , 这两者都是可并行的source算子- 带 Rich的,都拥有 open() ,close() ,getRuntimeContext() 方法
带 Parallel的,都可多实例并行执行source
- package com.pxj.sx.flink;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;public class MySource1{public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.addSource(new MySource());source.print();env.execute("pxj");}
}
class MySource extends RichParallelSourceFunction<String> {private int i=0; //定义一个int类型的变量,从1开始private boolean flag=true; //定义一个flag标标志//run方法就是用来读取外部的数据或产生数据的逻辑@Overridepublic void run(SourceContext<String> ctx) throws Exception {while (i<=100 && flag){Thread.sleep(1000); //为避免太快,睡眠1秒ctx.collect("data:"+i++);}}@Overridepublic void cancel() {flag=false;}
}
整理人:pxj_sx(潘陈)
日 期:2024-05-26 11:47:24
相关文章:

flink Data Source数据源
flink Data Source数据源 Source 并行度 非并行:并行度只能为1 并行 基于集合的Source fromElements package com.pxj.sx.flink; import org.apache.flink.configuration.Configuration; import org.apache.flink.configuration.RestOptions; import org.ap…...

网络七层模型与云计算中的网络服务
网络七层模型,也称为OSI(Open System Interconnection)模型,是由国际标准化组织(ISO)制定的一个概念性框架,用于描述网络通信过程中信息是如何被封装、传输和解封装的。这一模型将复杂的网络通信…...

word一按空格就换行怎么办?word文本之间添加空格就换行怎么办?
如上图,无法在Connection和con之间添加空格,一按空格就会自动换行。 第一步:选中文本,打开段落。 第二步:点击中文版式,勾选允许西文在单词中间换行。 确定之后就解决一按空格就自动换行啦!...

Python 遍历字典的方法,你都掌握了吗
Python中的字典是一种非常灵活的数据结构,它允许通过键来存储和访问值。在处理字典时,经常需要遍历字典中的元素,以下是几种常见的遍历字典的方法。 1. 使用 for 循环直接遍历字典的键 字典的键是唯一的,可以直接通过 for 循环来…...
MySQL 8.4.0 LTS 变更解析:I_S 表、权限、关键字和客户端
↑ 关注“少安事务所”公众号,欢迎⭐收藏,不错过精彩内容~ MySQL 8.4.0 LTS 已经发布 ,作为发版模型变更后的第一个长期支持版本,注定要承担未来生产环境的重任,那么这个版本都有哪些新特性、变更,接下来少…...
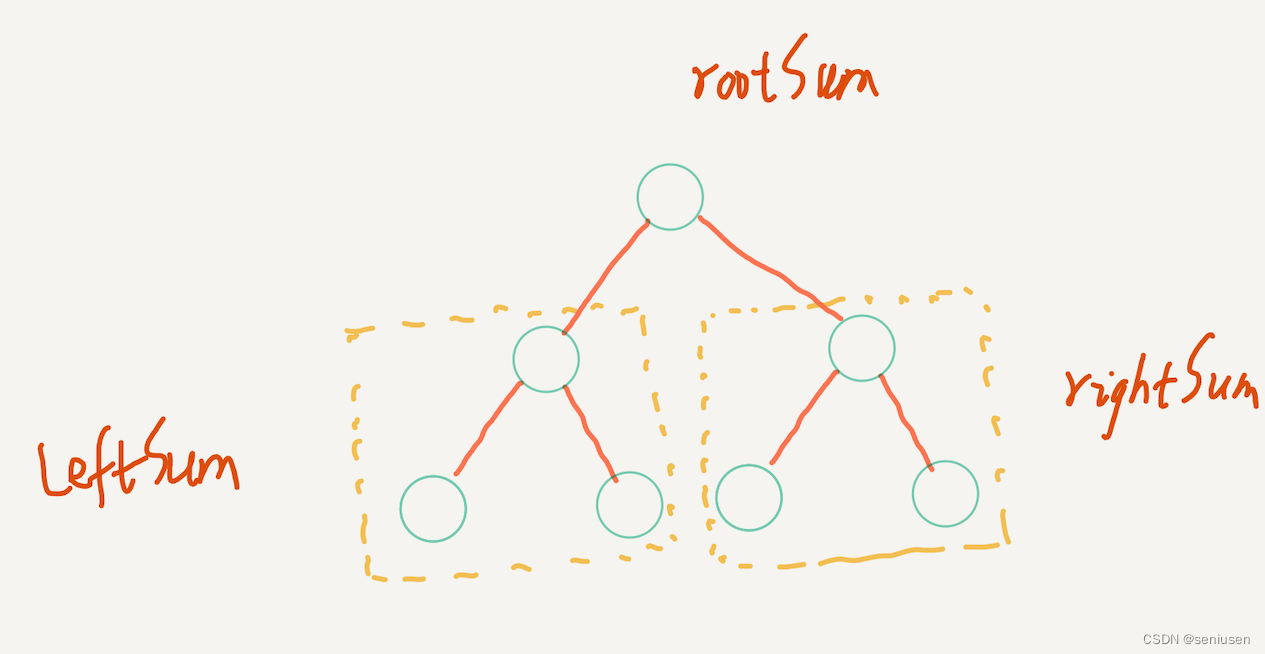
LeetCode 124 —— 二叉树中的最大路径和
阅读目录 1. 题目2. 解题思路3. 代码实现 1. 题目 2. 解题思路 二叉树的问题首先我们要想想是否能用递归来解决,本题也不例外,而递归的关键是找到子问题。 我们首先来看看一棵最简单的树,也就是示例 1。这样的一棵树总共有六条路径…...

美甲店会员预约系统管理小程序的作用是什么
女性爱美体现在方方面面,美丽好看的指甲也不能少,市场中美甲店、小摊不少,也跑出了不少连锁品牌,70后到00后,每个层级都有不少潜在客户,商家需要获取和完善转化路径,不断提高品牌影响力与自身内…...

..堆..
堆 堆是完全二叉树,即除了最后一列之外,上面的每一层都是满的(左右严格对称且每个节点都满子节点) 最后一列从左向右排序。 默认大根堆:每一个节点都大于其左右儿子,根节点就是整个数据结构的最大值 pr…...
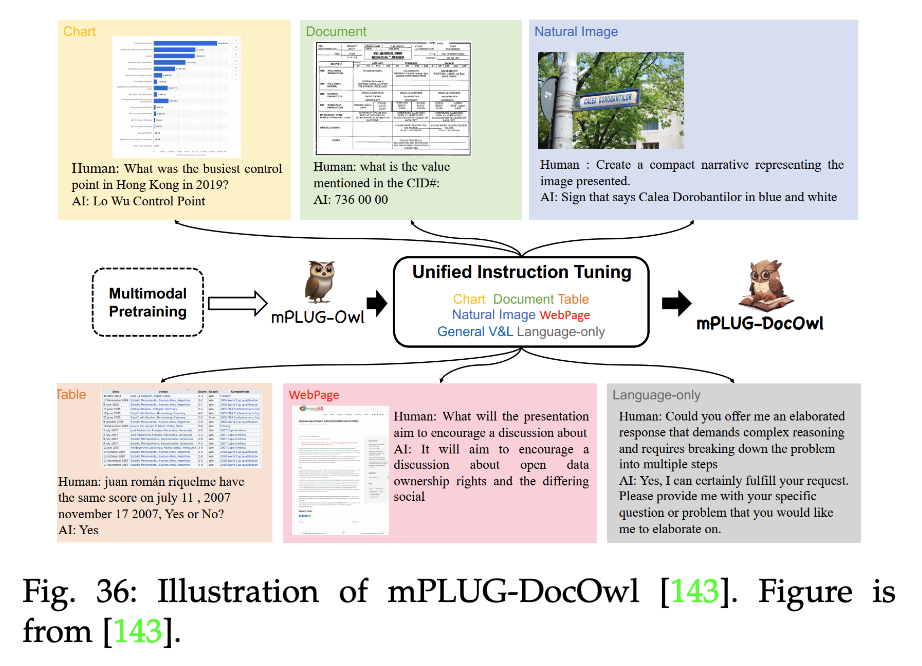
【LLM多模态】综述Visual Instruction Tuning towards General-Purpose Multimodal Model
note 文章目录 note论文1. 论文试图解决什么问题2. 这是否是一个新的问题3. 这篇文章要验证一个什么科学假设4. 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?5. 论文中提到的解决方案之关键是什么?6. 论文中的…...

探索Linux中的神奇工具:重定向符的妙用
探索Linux中的神奇工具:重定向符的妙用 在Linux系统中,重定向符是一个强大的工具,用于控制命令的输入和输出,实现数据流的定向。本文将详细介绍重定向符的基本用法和一些实用技巧,帮助读者更好地理解和运用这个功能。…...

Kubernetes 文档 / 概念 / 工作负载 / 工作负载管理 / Job
Kubernetes 文档 / 概念 / 工作负载 / 工作负载管理 / Job 此文档从 Kubernetes 官网摘录 中文地址 英文地址 Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的…...
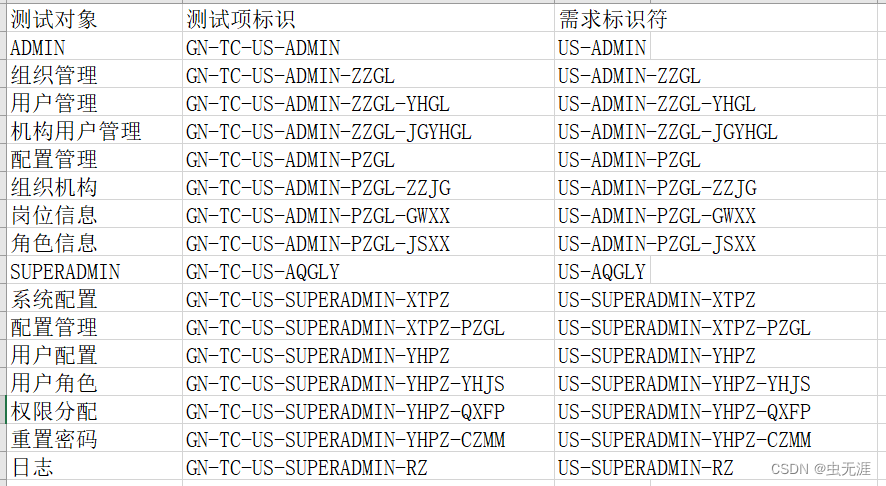
办公自动化-Python如何提取Word标题并保存到Excel中?
办公自动化-Python如何提取Word标题并保存到Excel中? 应用场景需求分析实现思路实现过程安装依赖库打开需求文件获取word中所有标题去除不需要的标题创建工作簿和工作表分割标题功能名称存入测试对象GN-TC需求标识符存入测试项标识存入需求标识符 完整源码实现效果学…...
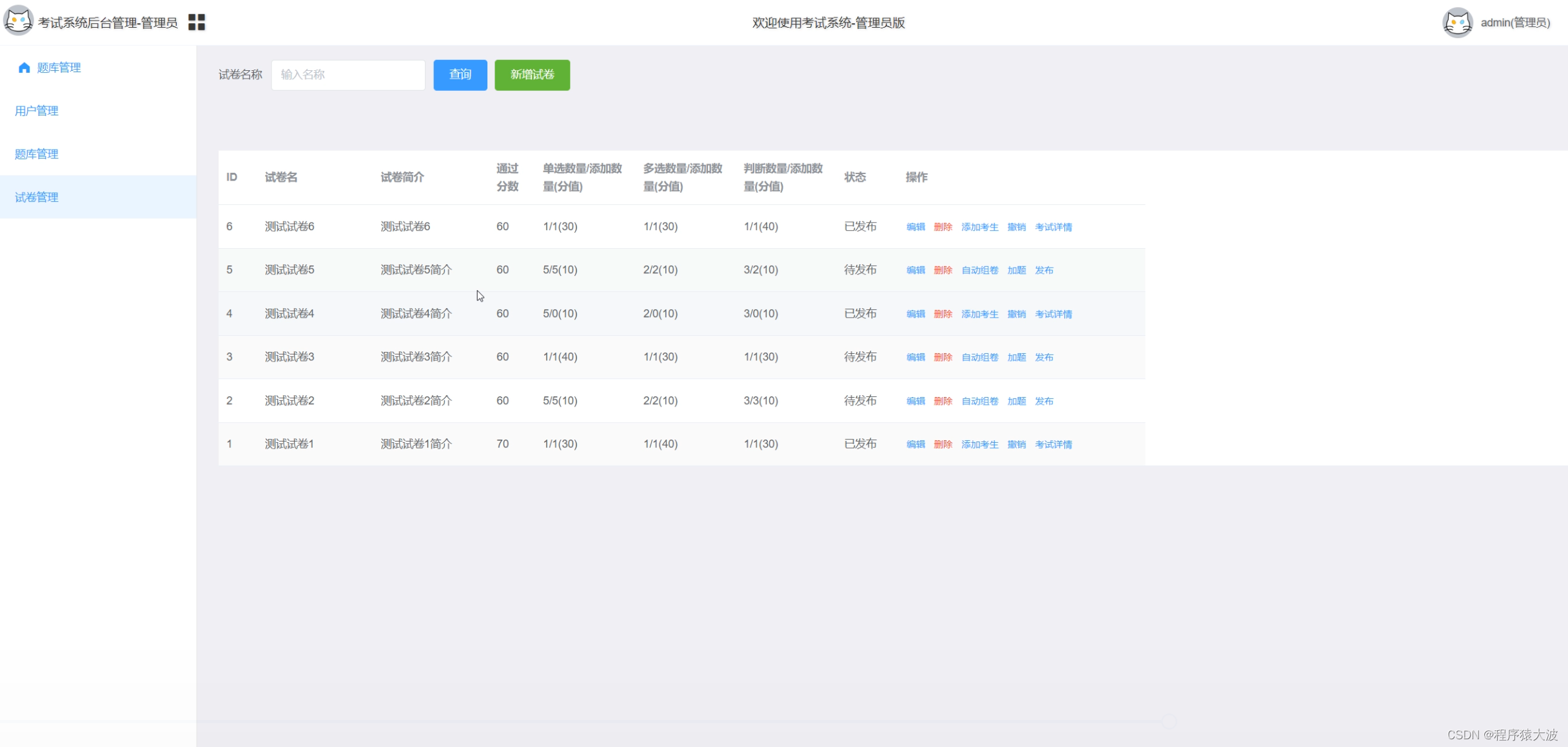
基于Java、SpringBoot和uniapp在线考试系统安卓APP和微信小程序
摘要 基于Java、SpringBoot和uniapp的在线考试系统安卓APP微信小程序是一种结合了现代Web开发技术和移动应用技术的解决方案,旨在为教育机构提供一个方便、高效和灵活的在线考试平台。该系统采用Java语言进行后端开发,使用SpringBoot框架简化企业级应用…...
)
抖音a-bogus加密解析(三)
要补的环境我给提示,大家自行操作,出了问题就是因为缺环境,没补好 window global; // reading _u未定义 window.requestAnimationFrame function () {} // XMLHttpRequest 未定义 window.XMLHttpRequest function () {} window.onwheelx …...

IS-IS DIS
原理概述 OSPF 协议支持4种网络类型, IS-IS 协议只支持两种网络类型,即广播网络和点到点网络。与 OSPF 协议相同, IS-IS 协议在广播网络中会将网络视为一个伪节点( Pseudonode ,简称 PSN ),并选举出一台 DIS ( Designa…...

random和range
含义: random(1,10) 不包含10,用于生成随机数。它可以生成浮点数或整数,取决于具体的使用方式。 range(0,1) 不包含1,用于生成一个整数序列。它可以生成一个指定范围内的连续整数序列。 区别在于&#x…...

研二学妹面试字节,竟倒在了ThreadLocal上,这是不要应届生还是不要女生啊?
一、写在开头 今天和一个之前研二的学妹聊天,聊及她上周面试字节的情况,着实感受到了Java后端现在找工作的压力啊,记得在18,19年的时候,研究生计算机专业的学生,背背八股文找个Java开发工作毫无问题&#x…...
实现)
Golang:gammazero/deque是一个快速环形缓冲区deque(双端队列)实现
gammazero/deque是一个快速环形缓冲区deque(双端队列)实现。 文档 https://github.com/gammazero/deque 安装 go get github.com/gammazero/deque代码示例 先入先出队列 package mainimport ("fmt""github.com/gammazero/deque&quo…...

C++ 时间处理-统计函数运行时间
1. 关键词2. 问题3. 解决思路4. 代码实现 4.1. timecount.h4.2. timecount.cpp 5. 测试代码6. 运行结果7. 源码地址 1. 关键词 C 时间处理 统计函数运行时间 跨平台 2. 问题 C如何简单便捷地实现“函数运行时间的统计”功能? 3. 解决思路 类的构造函数&#x…...
)
JAVA面试题大全(十五)
1、Zookeeper 是什么? zookper是一个分布式的,开放源码的分布式应用程序协调服务。是 google chubby 的开源实现,是 hadoop 和 hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

Lovable电商网站搭建,为什么92%的初创团队在第3周就遭遇性能雪崩?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署。其核心基于 Vue 3(Composition API&a…...

用Arduino改造TDA7010T FM收音机:数字调谐与自动搜台实战
1. 项目概述:当复古芯片遇上现代微控制器翻出抽屉角落里那个积灰的Kemo B156N套件时,我压根没想到它会变成一个如此有趣的周末项目。这个套件的核心,是一颗来自上世纪八十年代的FM收音机芯片——TDA7010T。当年,它和它的前身TDA70…...