办公自动化-Python如何提取Word标题并保存到Excel中?
办公自动化-Python如何提取Word标题并保存到Excel中?
- 应用场景
- 需求分析
- 实现思路
- 实现过程
- 安装依赖库
- 打开需求文件
- 获取word中所有标题
- 去除不需要的标题
- 创建工作簿和工作表
- 分割标题
- 功能名称存入测试对象
- GN-TC+需求标识符存入测试项标识
- 存入需求标识符
- 完整源码
- 实现效果
- 学习总结
应用场景
-
为啥要提这个话题呢?测试小伙伴遇到一个问题,他的痛点是想把需求文档(word版)中的需求标识符、功能名称,挨个复制到测试计划中;
-
这对他来说是非常痛苦的,如果需求文档内容过于庞大,对他来说,需要好几天才能复制完这些标识符;
-
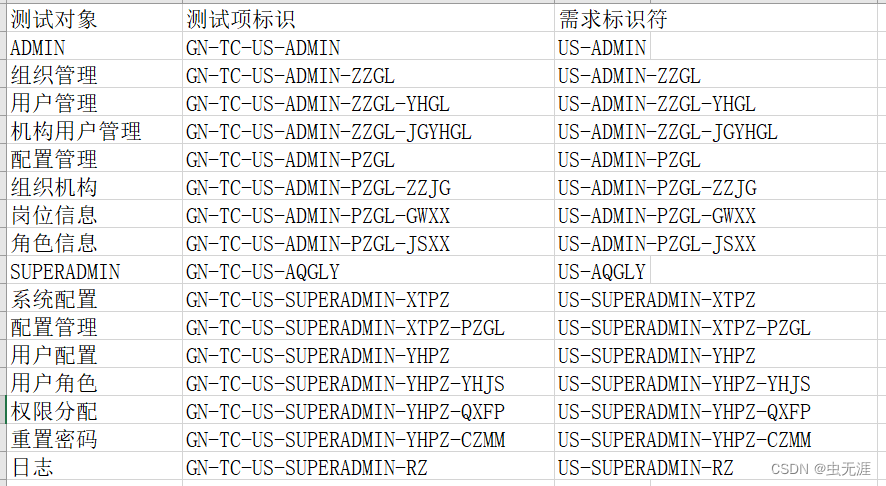
具体的比如以下word:

-
他想把以上word标题中的标识符和名称复制到如下表格中:
| 测试对象 | 测试项标识 | 需求标识 |
|---|---|---|
| 组织管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 组织管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 组织管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 组织管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
| 组织管理 | GN-TC-US-ADMIN-ZZGL | US-ADMIN-ZZGL |
- 针对这个简单的需求如何用python来实现呢?
需求分析
- 需求的标题为:序号+[标识符]+功能名称;
- 测试计划中表格内容:
| 字段 | 说明 |
|---|---|
| 测试对象 | 对应需求中的功能名称 |
| 测试项标识 | GN-TC+需求中的标识符 |
| 需求标识符 | 需求中的标识符 |
- 经过分析,其实就是把需求中的标题提取出来,然后进行分割,分别写入测试计划对应的表格中即可。
实现思路
- 打开指定目录下的需求文档;
- 获取需求文档中的所有标题;
- 当标题中只有符号“[” 和 "]"时列表;
- 创建excel工作簿;
- 新建工作表;
- 给工作标添加表头,比如测试对象、测试项标识、需求标识;
- 分割获取到的标题并存入excel对应的表头下。
实现过程
安装依赖库
- 我们使用Python的python-docx库和openpyxl库进行以上内容实现;
- 那么需要安装这两个库:
pip install python-docx
pip install openpyxl
- 如果没有网络,需要在本地单独安装,python-docx有以下两个依赖 lxml和typing-extensions:
C:\Users\Administrator>pip install python-docx
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: python-docx in d:\python37\lib\site-packages (1.1.0)
Requirement already satisfied: lxml>=3.1.0 in d:\python37\lib\site-packages (from python-docx) (4.6.3)
Requirement already satisfied: typing-extensions in d:\python37\lib\site-packages (from python-docx) (4.7.1)
- 如果没有网络,需要在本地单独安装,openpyxl有以下两个依赖 jdcal和 et-xmlfile:
C:\Users\Administrator>pip install openpyxl
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: openpyxl in d:\python37\lib\site-packages (3.0.5)
Requirement already satisfied: jdcal in d:\python37\lib\site-packages (from openpyxl) (1.4.1)
Requirement already satisfied: et-xmlfile in d:\python37\lib\site-packages (from openpyxl) (1.0.1)
打开需求文件
- 需要导入对应的库;
- 文件名称写自己的需求文件即可;
import docx
from openpyxl import Workbookdoc = docx.Document("./XX需求.docx")
获取word中所有标题
- 先创建和列表用于存放标题;
headings = []for para in doc.paragraphs:if para.style.name.startswith('Heading'):headings.append(para.text)
print(headings)
- 此时会输出所有的标题:
['XX管理系统', '[US-ADMIN]ADMIN', '[US-ADMIN-ZZGL]组织管理',
'[US-ADMIN-ZZGL-YHGL]用户管理', '功能描述', '输入输出',
'数据流向', '[US-ADMIN-ZZGL-JGYHGL]机构用户管理', '功能描述',
'输入输出', '数据流向', ' [US-ADMIN-PZGL]配置管理',
'[US-ADMIN-PZGL-ZZJG]组织机构', '功能描述', '输入输出',
'数据流向', '[US-ADMIN-PZGL-GWXX]岗位信息', '功能描述',
'输入输出', '数据流向', ' [US-ADMIN-PZGL-JSXX]角色信息','功能描述', '输入输出', '数据流向', ' [US-AQGLY]SUPERADMIN','[US-SUPERADMIN-XTPZ]系统配置', ' [US-SUPERADMIN-XTPZ-PZGL]配置管理','功能描述', '输入输出', '数据流向', '[US-SUPERADMIN-YHPZ]用户配置','[US-SUPERADMIN-YHPZ-YHJS]用户角色', '功能描述', '输入输出', '数据流向', '[ US-SUPERADMIN-YHPZ-QXFP]权限分配', '功能描述', '数据流向', '[US-SUPERADMIN-YHPZ-CZMM]重置密码', '功能描述', '输入输出', '数据流向', '[US-SUPERADMIN-RZ]日志', '功能描述', '输入输出', '数据流向']
去除不需要的标题
- 以上获取所有标题后,有的不是我们想要的;
- 比如功能描述、输入输出、数据流向等标题是不需要的;
- 我们需要的标题是比如[US-SUPERADMIN-RZ]日志;
- 标题获取后判断是否有符号“[” 和 “]”,如果有,再存入列表;
headings = []for para in doc.paragraphs:if para.style.name.startswith('Heading'):if '[' in para.text or ']' in para.text:headings.append(para.text)
print(headings)
- 此时就去掉了多余的标题内容:
['[US-ADMIN]ADMIN', '[US-ADMIN-ZZGL]组织管理',
'[US-ADMIN-ZZGL-YHGL]用户管理', '[US-ADMIN-ZZGL-JGYHGL]机构用户管理',
' [US-ADMIN-PZGL]配置管理', '[US-ADMIN-PZGL-ZZJG]组织机构','[US-ADMIN-PZGL-GWXX]岗位信息', ' [US-ADMIN-PZGL-JSXX]角色信息', ' [US-AQGLY]SUPERADMIN', '[US-SUPERADMIN-XTPZ]系统配置', ' [US-SUPERADMIN-XTPZ-PZGL]配置管理', '[US-SUPERADMIN-YHPZ]用户配置', '[US-SUPERADMIN-YHPZ-YHJS]用户角色', '[ US-SUPERADMIN-YHPZ-QXFP]权限分配', '[US-SUPERADMIN-YHPZ-CZMM]重置密码', '[US-SUPERADMIN-RZ]日志']
创建工作簿和工作表
- 创建一个工作簿;
- 然后在工作簿中创建一个工作表;
- 并在工作表中设置表头为测试对象、测试项标识、需求标识;
wb = Workbook()sheet = wb.create_sheet("data")# ws = wb.active
headers = ['测试对象', '测试项标识', '需求标识符']
for col_num, header in enumerate(headers, start=1):sheet.cell(row=1, column=col_num, value=header)
分割标题
- 去掉标题中的左书名号"[";
- 使用右书名号“]”进行分割,左边即为需求标识符,右边即为功能名称;
- 拼接测试项标题为GN-TC+需求标识符:
c3 = []
c5 = []
c7 = []
for content in headings:c1 = content.strip('[')c2 = c1.split(']')[0]c3.append(c2)c4 = c1.split(']')[1]c5.append(c4)c6 = 'GN-TC-' + c2c7.append(c6)print(c1)
print(c3)
print(c5)
print(c7)
- 其中c1为去掉所有左书名号:
US-ADMIN]ADMIN
US-ADMIN-ZZGL]组织管理
US-ADMIN-ZZGL-YHGL]用户管理
US-ADMIN-ZZGL-JGYHGL]机构用户管理[US-ADMIN-PZGL]配置管理
US-ADMIN-PZGL-ZZJG]组织机构
US-ADMIN-PZGL-GWXX]岗位信息[US-ADMIN-PZGL-JSXX]角色信息[US-AQGLY]SUPERADMIN
US-SUPERADMIN-XTPZ]系统配置[US-SUPERADMIN-XTPZ-PZGL]配置管理
US-SUPERADMIN-YHPZ]用户配置
US-SUPERADMIN-YHPZ-YHJS]用户角色US-SUPERADMIN-YHPZ-QXFP]权限分配
US-SUPERADMIN-YHPZ-CZMM]重置密码
US-SUPERADMIN-RZ]日志
- c3所有需求标识符:
['US-ADMIN', 'US-ADMIN-ZZGL', 'US-ADMIN-ZZGL-YHGL','US-ADMIN-ZZGL-JGYHGL', ' [US-ADMIN-PZGL', 'US-ADMIN-PZGL-ZZJG', 'US-ADMIN-PZGL-GWXX', ' [US-ADMIN-PZGL-JSXX', ' [US-AQGLY','US-SUPERADMIN-XTPZ', ' [US-SUPERADMIN-XTPZ-PZGL', 'US-SUPERADMIN-YHPZ','US-SUPERADMIN-YHPZ-YHJS', ' US-SUPERADMIN-YHPZ-QXFP', 'US-SUPERADMIN-YHPZ-CZMM', 'US-SUPERADMIN-RZ']
- c5功能名称:
['ADMIN', '组织管理', '用户管理', '机构用户管理',
'配置管理', '组织机构', '岗位信息', '角色信息',
'SUPERADMIN', '系统配置', '配置管理', '用户配置',
'用户角色', '权限分配', '重置密码', '日志']
- c7测试项名称:
[
'GN-TC-US-ADMIN',
'GN-TC-US-ADMIN-ZZGL',
'GN-TC-US-ADMIN-ZZGL-YHGL',
'GN-TC-US-ADMIN-ZZGL-JGYHGL',
'GN-TC-US-ADMIN-PZGL',
'GN-TC-US-ADMIN-PZGL-ZZJG',
'GN-TC-US-ADMIN-PZGL-GWXX',
'GN-TC-US-ADMIN-PZGL-JSXX',
'GN-TC-US-AQGLY',
'GN-TC-US-SUPERADMIN-XTPZ',
'GN-TC-US-SUPERADMIN-XTPZ-PZGL',
'GN-TC-US-SUPERADMIN-YHPZ',
'GN-TC-US-SUPERADMIN-YHPZ-YHJS',
'GN-TC-US-SUPERADMIN-YHPZ-QXFP',
'GN-TC-US-SUPERADMIN-YHPZ-CZMM',
'GN-TC-US-SUPERADMIN-RZ']
功能名称存入测试对象
for i, heading in enumerate(c5):sheet.cell(row=i+2, column=1, value=heading)
GN-TC+需求标识符存入测试项标识
for i, heading in enumerate(c7):sheet.cell(row=i+2, column=2, value=heading)
存入需求标识符
for i, heading in enumerate(c3):sheet.cell(row=i+2, column=3, value=heading)
完整源码
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2024/5/23
# 文件名称:test_word.pyimport docx
from openpyxl import Workbookdoc = docx.Document("./XX需求.docx")headings = []for para in doc.paragraphs:if para.style.name.startswith('Heading'):if '[' in para.text or ']' in para.text:headings.append(para.text)
# print(headings)wb = Workbook()sheet = wb.create_sheet("data")# ws = wb.active
headers = ['测试对象', '测试项标识', '需求标识符']
for col_num, header in enumerate(headers, start=1):sheet.cell(row=1, column=col_num, value=header)# print(headings)c3 = []
c5 = []
c7 = []
for content in headings:c1 = content.strip('[')c2 = c1.split(']')[0]c3.append(c2)c4 = c1.split(']')[1]c5.append(c4)c6 = 'GN-TC-' + c2c7.append(c6)
# print(c1)
# print(c3)
# print(c5)
# print(c7)for i, heading in enumerate(c5):sheet.cell(row=i+2, column=1, value=heading)for i, heading in enumerate(c7):sheet.cell(row=i+2, column=2, value=heading)for i, heading in enumerate(c3):sheet.cell(row=i+2, column=3, value=heading)wb.save('./data.xlsx')
实现效果
学习总结
以上还有优化的空间,比如:
- 字符串中间有空格或者其他多余的内容如何处理?
- 新建的excel如何对表头进行字体、颜色等设置?
- 表格列宽如何调整?
- 整个表格字体如何设置?
等等。
相关文章:
办公自动化-Python如何提取Word标题并保存到Excel中?
办公自动化-Python如何提取Word标题并保存到Excel中? 应用场景需求分析实现思路实现过程安装依赖库打开需求文件获取word中所有标题去除不需要的标题创建工作簿和工作表分割标题功能名称存入测试对象GN-TC需求标识符存入测试项标识存入需求标识符 完整源码实现效果学…...
基于Java、SpringBoot和uniapp在线考试系统安卓APP和微信小程序
摘要 基于Java、SpringBoot和uniapp的在线考试系统安卓APP微信小程序是一种结合了现代Web开发技术和移动应用技术的解决方案,旨在为教育机构提供一个方便、高效和灵活的在线考试平台。该系统采用Java语言进行后端开发,使用SpringBoot框架简化企业级应用…...
)
抖音a-bogus加密解析(三)
要补的环境我给提示,大家自行操作,出了问题就是因为缺环境,没补好 window global; // reading _u未定义 window.requestAnimationFrame function () {} // XMLHttpRequest 未定义 window.XMLHttpRequest function () {} window.onwheelx …...

IS-IS DIS
原理概述 OSPF 协议支持4种网络类型, IS-IS 协议只支持两种网络类型,即广播网络和点到点网络。与 OSPF 协议相同, IS-IS 协议在广播网络中会将网络视为一个伪节点( Pseudonode ,简称 PSN ),并选举出一台 DIS ( Designa…...

random和range
含义: random(1,10) 不包含10,用于生成随机数。它可以生成浮点数或整数,取决于具体的使用方式。 range(0,1) 不包含1,用于生成一个整数序列。它可以生成一个指定范围内的连续整数序列。 区别在于&#x…...

研二学妹面试字节,竟倒在了ThreadLocal上,这是不要应届生还是不要女生啊?
一、写在开头 今天和一个之前研二的学妹聊天,聊及她上周面试字节的情况,着实感受到了Java后端现在找工作的压力啊,记得在18,19年的时候,研究生计算机专业的学生,背背八股文找个Java开发工作毫无问题&#x…...
实现)
Golang:gammazero/deque是一个快速环形缓冲区deque(双端队列)实现
gammazero/deque是一个快速环形缓冲区deque(双端队列)实现。 文档 https://github.com/gammazero/deque 安装 go get github.com/gammazero/deque代码示例 先入先出队列 package mainimport ("fmt""github.com/gammazero/deque&quo…...

C++ 时间处理-统计函数运行时间
1. 关键词2. 问题3. 解决思路4. 代码实现 4.1. timecount.h4.2. timecount.cpp 5. 测试代码6. 运行结果7. 源码地址 1. 关键词 C 时间处理 统计函数运行时间 跨平台 2. 问题 C如何简单便捷地实现“函数运行时间的统计”功能? 3. 解决思路 类的构造函数&#x…...
)
JAVA面试题大全(十五)
1、Zookeeper 是什么? zookper是一个分布式的,开放源码的分布式应用程序协调服务。是 google chubby 的开源实现,是 hadoop 和 hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护…...

使用python对指定文件夹下的pdf文件进行合并
使用python对指定文件夹下的pdf文件进行合并 介绍效果代码 介绍 对指定文件夹下的所有pdf文件进行合并成一个pdf文件。 效果 要合并的pdf文件,共计16个1页的pdf文件。 合并成功的pdf文件:一个16页的pdf文件。 代码 import os from PyPDF2 import …...

Day50 | 309.最佳买卖股票时机含冷冻期 714.买卖股票的最佳时机含手续费 总结
代码随想录算法训练营Day50 | 309.最佳买卖股票时机含冷冻期 714.买卖股票的最佳时机含手续费 总结 LeetCode 309.最佳买卖股票时机含冷冻期 题目链接:LeetCode 309.最佳买卖股票时机含冷冻期 思路: 四个状态。 保持持有股票,保持卖出股票…...

Steam在连接至服务器发生错误/连接服务器遇到问题解决办法
Steam作为全球最大的数字游戏分发平台,构建了一个活跃的玩家社区,用户可以创建个人资料,添加好友,组建群组,参与讨论,甚至直播自己的游戏过程。通过创意工坊,玩家还能分享自制的游戏模组、地图、…...

kafka 工作流程文件存储
爬虫组件分析 目录概述需求: 设计思路实现思路分析1.kafka 工作流程2.kafka 文件存储 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for…...

贪心算法4(c++)
过河的最短时间 题目描述 输入 在漆黑的夜里,N位旅行者来到了一座狭窄而且没有护栏的桥边。如果不借助手电筒的话,大家是无论如何也不敢过桥去的。不幸的是,N个人一共只带了一只手电筒,而桥窄得只够让两个人同时过,如果…...

【无标题】yoloV8目标检测与实例分割--目标检测onnx模型部署
1. 模型转换 ONNX Runtime 是一个开源的高性能推理引擎,用于部署和运行机器学习模型,其设计的目标是优化执行open neural network exchange (onnx)格式定义各模型,onnx是一种用于表示机器学习模型的开放标准。ONNX Ru…...
深入理解与防御跨站脚本攻击(XSS):从搭建实验环境到实战演练的全面教程
跨站脚本攻击(XSS)是一种常见的网络攻击手段,它允许攻击者在受害者的浏览器中执行恶意脚本。以下是一个XSS攻击的实操教程,包括搭建实验环境、编写测试程序代码、挖掘和攻击XSS漏洞的步骤。 搭建实验环境 1. 安装DVWAÿ…...
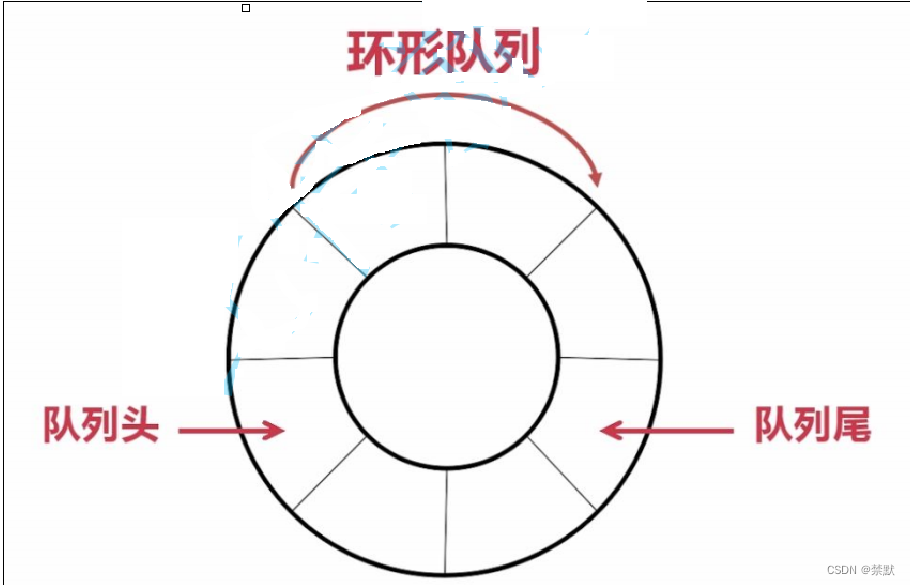
初步认识栈和队列
Hello,everyone,今天小编讲解栈和队列的知识!!! 1.栈 1.1栈的概念及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。 进行数据插入和删除操作的一端 称为栈顶&…...
插件:NGUI
一、版本 安装完毕后重启一下即可,否则可能创建的UI元素不生效 二、使用 Label文字 1、创建Canvs 2、只有根节点的这些脚本全部展开才能鼠标右键创建UI元素 3、选择字体 Label添加打字效果 Sprite图片 1、选择图集 2、选择图集中的精灵 InvisibleWidget容器 用来…...

网络爬虫原理及其应用
你是否想知道Google 和 Bing 等搜索引擎如何收集搜索结果中显示的所有数据。这是因为搜索引擎对其档案中的所有页面建立索引,以便它们可以根据查询返回最相关的结果。网络爬虫使搜索引擎能够处理这个过程。 本文重点介绍了网络爬虫的重要方面、网络爬虫为何重要、其…...

串口中断原理及实现
一、串口的原理 SM0、SM1——串行口工作模式 SM0SM1模式特点00模式0移位寄存器方式,用于I/O口扩展01模式18位UART,波特率可变10模式29位UART,波特率为时钟频率/32或/6411模式39位UART,波特率可变 TI、RI——发送、接收中断标志位 TITI0 允许发送>TI1 发送完成后…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...