【机器学习-23】关联规则(Apriori)算法:介绍、应用与实现
在现代数据分析中,经常需要从大规模数据集中挖掘有用的信息。关联规则挖掘是一种强大的技术,可以揭示数据中的隐藏关系和规律。本文将介绍如何使用Python进行关联规则挖掘,以帮助您发现数据中的有趣模式。

一、引言
1. 简要介绍关联规则学习的概念和重要性
关联规则学习是一种数据挖掘技术,旨在发现数据集中项之间的有趣关系。这些关系通常以“如果…那么…”的形式呈现,表示一种条件与结论的关联性。在商业分析中,关联规则学习常用于识别顾客购买行为中的模式,例如哪些商品经常被一起购买。通过发现这些模式,企业可以制定更有效的营销策略,提高销售额和客户满意度。
关联规则学习的重要性在于它能够从大量数据中提取出有价值的信息,帮助企业更好地理解客户行为和市场需求。这些信息不仅可以用于产品推荐、交叉销售等场景,还可以为企业的战略决策提供有力支持。
2. 引入Apriori算法,解释其在关联规则学习中的地位
在关联规则学习领域,Apriori算法是一种广泛应用的算法。它基于两个核心思想:频繁项集生成和剪枝策略。通过逐步生成和评估候选项集,Apriori算法能够有效地找出数据中的频繁项集和关联规则。由于其高效性和实用性,Apriori算法在关联规则学习中占据了重要地位。
Apriori算法的重要性在于它提供了一种有效的手段来发现数据中的关联关系。与其他算法相比,Apriori算法具有较低的计算复杂度和较高的准确性,使得它成为关联规则学习中的首选算法之一。
3. 阐述本文的目的和结构
本文旨在详细介绍Apriori算法及其在关联规则学习中的应用。首先,我们将对关联规则学习进行概述,阐述其基本概念和应用场景。接着,我们将深入介绍Apriori算法的原理和实现过程,包括频繁项集生成、剪枝策略以及算法优化等方面。最后,我们将通过案例研究来展示Apriori算法在实际应用中的效果和价值。
本文的结构如下:引言部分将介绍关联规则学习和Apriori算法的基本概念;关联规则学习概述部分将详细阐述关联规则学习的应用场景和主要挑战;Apriori算法介绍部分将深入探讨算法的原理和实现细节;Apriori算法的应用部分将通过案例研究来展示算法的实际应用效果;最后,总结与展望部分将对全文进行总结,并展望关联规则学习领域的未来发展方向。
二、关联规则学习概述
定义关联规则学习
关联规则学习是一种在大型数据集中寻找有趣关系的方法。这种关系通常表现为项集之间的强关联性,即如果某个项集(集合中的一组项)在数据集中频繁出现,那么另一个项集也很有可能随之出现。关联规则学习的主要目标是找出这样的项集,并生成形如“如果购买了A商品,那么也可能会购买B商品”的规则。
在关联规则学习中,通常使用支持度和置信度这两个指标来量化项集之间的关联性。支持度表示项集在数据集中出现的频率,而置信度则表示在给定一个项集出现的情况下,另一个项集也出现的概率。
关联规则学习的应用场景
-
市场篮子分析:关联规则学习在零售行业中有着广泛的应用,特别是在市场篮子分析方面。通过分析顾客的购买记录,可以发现哪些商品经常被一起购买,从而制定更有效的商品摆放策略、促销活动和交叉销售策略。
-
推荐系统:关联规则学习也被广泛应用于推荐系统中。通过分析用户的历史行为和偏好,可以找出用户可能感兴趣的物品或服务,并为其推荐相关的内容。这种推荐方式简单直观,且易于理解和实现。
-
网络日志分析:在网络安全和日志分析中,关联规则学习可以帮助发现异常行为和潜在的安全威胁。通过分析网络日志中的事件和模式,可以发现哪些事件之间存在关联,从而识别出可能的攻击行为或安全漏洞。
-
疾病诊断:在医疗领域,关联规则学习可以帮助医生发现疾病之间的关联性和潜在风险因素。通过分析病人的病历和诊断记录,可以发现哪些症状或疾病经常同时出现,从而为疾病的诊断和治疗提供有价值的参考。
关联规则学习的主要挑战
-
数据稀疏性:在大型数据集中,许多项集可能只出现一次或几次,导致支持度和置信度的计算变得不准确。此外,数据中的噪声和异常值也可能对关联规则的学习产生负面影响。
-
计算复杂性:关联规则学习需要计算所有可能项集的支持度和置信度,这可能导致计算量非常大。特别是在项集数量较多时,计算时间可能呈指数级增长。
-
规则解释性:生成的关联规则需要具有可解释性,以便用户能够理解和应用这些规则。然而,在某些情况下,生成的规则可能过于复杂或难以理解,这会影响其在实际应用中的效果。
-
规则冗余性:在生成的关联规则中,可能存在大量的冗余规则。这些规则在内容上相似或重复,但可能具有不同的支持度和置信度。如何有效地去除冗余规则并保留最有价值的规则是一个挑战。
三、关联规则中的一些概念
| 序号 | 牛奶 | 啤酒 | 面包 | 花生酱 | 果冻 |
|---|---|---|---|---|---|
| T1 | 1 | 0 | 0 | 1 | 1 |
| T2 | 0 | 0 | 1 | 0 | 1 |
| T3 | 0 | 1 | 0 | 0 | 1 |
| T4 | 1 | 0 | 1 | 0 | 1 |
| T5 | 1 | 1 | 0 | 0 | 0 |
| T6 | 0 | 1 | 0 | 0 | 1 |
| T7 | 1 | 1 | 0 | 0 | 0 |
| T8 | 1 | 1 | 0 | 1 | 1 |
| T9 | 1 | 1 | 0 | 0 | 1 |
- 一个样本称为一个“事务” ;上面的T1称为一个“事务”
- 每个事务由多个属性来确定,这里的属性称为“项” ,这里的 牛奶、啤酒、面包、花生酱、果冻 都“项”
- 多个项组成的集合称为“项集”
由k个项构成的集合
- {牛奶}、{啤酒}都是1-项集;
- {牛奶,果冻}是2-项集;
- {啤酒,面包,牛奶}是3-项集
X==>Y含义:
- X和Y是项集
- X称为规则前项(antecedent)
- Y称为规则后项(consequent)
事务仅包含其涉及到的项目,而不包含项目的具体信息。
- 在超级市场的关联规则挖掘问题中事务是顾客一次购物所购买的商品,但事务中并不包含这些商品的具体信息,如商品的数量、价格等。
支持度(support):一个项集或者规则在所有事务中出现的频率,σ(X):表示项集X的支持度计数
- 项集X的支持度:s(X)=σ(X)/N
- 规则X==>Y表示物品集X对物品集Y的支持度,也就是物品集X和物品集Y同时出现的概率
- 某天共有100个顾客到商场购买物品,其中有30个顾客同时购买了啤酒和尿布,那么上述的关联规则的支持度就是30%
置信度(confidence):确定Y在包含X的事务中出现的频繁程度。c(X → Y) = σ(X∪Y)/σ(X)
- p(Y│X)=p(XY)/p(X)。
- 置信度反应了关联规则的可信度—购买了项目集X中的商品的顾客同时也购买了Y中商品的可能性有多大
- 购买薯片的顾客中有50%的人购买了可乐,则置信度为50%
(X , Y)==>Z :
| 交易ID | 购买的商品 |
|---|---|
| 1 | A,B,C |
| 2 | A,C |
| 3 | A,D |
| 4 | B,E,F |
-
支持度:交易中包含{X 、 Y 、 Z}的可能性
-
置信度:包含{X 、 Y}的交易中也包含Z的条件概率
设最小支持度为50%, 最小可信度为 50%, 则可得到 :
- A==>C (50%, 66.6%)
- C==>A (50%, 100%)
若关联规则X->Y的支持度和置信度分别大于或等于用户指定的最小支持率minsupport和最小置信度minconfidence,则称关联规则X->Y为强关联规则,否则称关联规则X->Y为弱关联规则。
提升度(lift):物品集A的出现对物品集B的出现概率发生了多大的变化
- lift(A==>B)=confidence(A==>B)/support(B)=p(B|A)/p(B)
- 现在有** 1000 ** 个消费者,有** 500** 人购买了茶叶,其中有** 450人同时** 购买了咖啡,另** 50人** 没有。由于** confidence(茶叶=>咖啡)=450/500=90%** ,由此可能会认为喜欢喝茶的人往往喜欢喝咖啡。但如果另外没有购买茶叶的** 500人** ,其中同样有** 450人** 购买了咖啡,同样是很高的** 置信度90%** ,由此,得到不爱喝茶的也爱喝咖啡。这样看来,其实是否购买咖啡,与有没有购买茶叶并没有关联,两者是相互独立的,其** 提升度90%/[(450+450)/1000]=1** 。
由此可见,lift正是弥补了confidence的这一缺陷,if lift=1,X与Y独立,X对Y出现的可能性没有提升作用,其值越大(lift>1),则表明X对Y的提升程度越大,也表明关联性越强。
 #### Leverage 与 Conviction的作用和lift类似,都是值越大代表越关联
#### Leverage 与 Conviction的作用和lift类似,都是值越大代表越关联
- Leverage 😛(A,B)-P(A)P(B)
- Conviction:P(A)P(!B)/P(A,!B)
四、使用mlxtend工具包得出频繁项集与规则
- pip install mlxtend
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
自定义一份购物数据集
data = {'ID':[1,2,3,4,5,6],'Onion':[1,0,0,1,1,1],'Potato':[1,1,0,1,1,1],'Burger':[1,1,0,0,1,1],'Milk':[0,1,1,1,0,1],'Beer':[0,0,1,0,1,0]}
df = pd.DataFrame(data)
df = df[['ID', 'Onion', 'Potato', 'Burger', 'Milk', 'Beer' ]]dfID Onion Potato Burger Milk Beer
0 1 1 1 1 0 0
1 2 0 1 1 1 0
2 3 0 0 0 1 1
3 4 1 1 0 1 0
4 5 1 1 1 0 1
5 6 1 1 1 1 0
设置支持度 (support) 来选择频繁项集.
-
选择最小支持度为50%
-
apriori(df, min_support=0.5, use_colnames=True)
frequent_itemsets = apriori(df[['Onion', 'Potato', 'Burger', 'Milk', 'Beer' ]], min_support=0.50, use_colnames=True)frequent_itemsetssupport itemsets
0 0.666667 (Onion)
1 0.833333 (Potato)
2 0.666667 (Burger)
3 0.666667 (Milk)
4 0.666667 (Potato, Onion)
5 0.500000 (Burger, Onion)
6 0.666667 (Burger, Potato)
7 0.500000 (Milk, Potato)
8 0.500000 (Burger, Potato, Onion)
返回的3种项集均是支持度>=50%
计算规则
association_rules(df, metric='lift', min_threshold=1)- 可以指定不同的衡量标准与最小阈值
rules = association_rules(frequent_itemsets, metric='lift', min_threshold=1)rulesantecedents consequents antecedent support consequent support support confidence lift leverage conviction
0 (Potato) (Onion) 0.833333 0.666667 0.666667 0.80 1.200 0.111111 1.666667
1 (Onion) (Potato) 0.666667 0.833333 0.666667 1.00 1.200 0.111111 inf
2 (Burger) (Onion) 0.666667 0.666667 0.500000 0.75 1.125 0.055556 1.333333
3 (Onion) (Burger) 0.666667 0.666667 0.500000 0.75 1.125 0.055556 1.333333
4 (Burger) (Potato) 0.666667 0.833333 0.666667 1.00 1.200 0.111111 inf
5 (Potato) (Burger) 0.833333 0.666667 0.666667 0.80 1.200 0.111111 1.666667
6 (Burger, Potato) (Onion) 0.666667 0.666667 0.500000 0.75 1.125 0.055556 1.333333
7 (Burger, Onion) (Potato) 0.500000 0.833333 0.500000 1.00 1.200 0.083333 inf
8 (Potato, Onion) (Burger) 0.666667 0.666667 0.500000 0.75 1.125 0.055556 1.333333
9 (Burger) (Potato, Onion) 0.666667 0.666667 0.500000 0.75 1.125 0.055556 1.333333
10 (Potato) (Burger, Onion) 0.833333 0.500000 0.500000 0.60 1.200 0.083333 1.250000
11 (Onion) (Burger, Potato) 0.666667 0.666667 0.500000 0.75 1.125 0.055556 1.333333
返回的是各个的指标的数值,可以按照感兴趣的指标排序观察,但具体解释还得参考实际数据的含义。
rules [ (rules['lift'] >1.125) & (rules['confidence']> 0.8) ]antecedents consequents antecedent support consequent support support confidence lift leverage conviction
1 (Onion) (Potato) 0.666667 0.833333 0.666667 1.0 1.2 0.111111 inf
4 (Burger) (Potato) 0.666667 0.833333 0.666667 1.0 1.2 0.111111 inf
7 (Burger, Onion) (Potato) 0.500000 0.833333 0.500000 1.0 1.2 0.083333 inf
这几条结果就比较有价值了:
- (洋葱和马铃薯)(汉堡和马铃薯)可以搭配着来卖
- 如果洋葱和汉堡都在购物篮中, 顾客买马铃薯的可能性也比较高,如果他篮子里面没有,可以推荐一下.
五、 性能优化
在关联规则学习中,Apriori算法虽然强大且广泛应用,但在处理大型数据集时可能会遇到性能瓶颈。因此,研究者们提出了一系列优化方法来提升Apriori算法及其同类算法的性能。以下是几种常见的性能优化方法,以及它们如何影响算法性能的评估。
1. FP-Growth算法
FP-Growth(Frequent Pattern Growth)算法是Apriori算法的一个有效替代方案,尤其在处理大型数据集时表现出色。FP-Growth算法使用一种称为FP树(Frequent Pattern Tree)的数据结构来存储频繁项集的信息,并基于这个数据结构进行频繁项集和关联规则的挖掘。FP树通过共享前缀来减少存储空间,并允许在不生成候选项集的情况下直接生成频繁项集,从而显著提高了算法的效率。
评估FP-Growth算法的性能时,通常会关注其在处理大型数据集时的运行时间、内存消耗以及生成的关联规则的质量。与Apriori算法相比,FP-Growth算法通常能够在更短的时间内处理更多的数据,并生成更准确和有用的关联规则。
2. 并行化
并行化是另一种提高关联规则学习算法性能的有效方法。通过将算法的计算任务分配给多个处理器或计算机节点,可以显著减少算法的运行时间。对于Apriori算法和FP-Growth算法等关联规则学习算法,并行化可以通过多种方式实现,例如将数据集划分为多个子集并在不同处理器上独立处理、在多个节点上并行生成和评估候选项集等。
评估并行化算法的性能时,除了关注运行时间和内存消耗外,还需要考虑并行化过程中的通信开销和负载均衡等因素。良好的并行化策略应该能够确保各个处理器或节点之间的负载均衡,并减少不必要的通信开销,从而最大化算法的性能提升。
3. 其他优化方法
除了FP-Growth算法和并行化之外,还有一些其他方法也可以用于优化关联规则学习算法的性能。例如,可以通过改进算法的数据结构、减少候选项集的数量、利用数据挖掘中的采样技术等来降低算法的计算复杂度。此外,还可以结合其他机器学习算法和技术来进一步提高关联规则学习的准确性和效率。
在评估优化后的算法性能时,需要采用合适的评估指标和方法。常见的评估指标包括运行时间、内存消耗、生成的关联规则的数量和质量等。为了获得准确的评估结果,可以使用基准数据集进行测试,并将优化后的算法与原始算法以及其他相关算法进行比较。此外,还可以根据实际应用场景的需求和约束条件来定制评估指标和方法。
六、总结与展望
6.1 总结Apriori算法的优点和局限性
Apriori算法作为关联规则学习的经典算法,具有其独特的优点。首先,它通过逐步生成和评估候选项集,有效地找出了数据中的频繁项集和关联规则。其次,Apriori算法的计算过程简单直观,易于理解和实现。此外,Apriori算法还具有良好的可解释性,生成的关联规则可以直接用于实际应用中。
然而,Apriori算法也存在一些局限性。首先,在处理大型数据集时,Apriori算法的计算量可能会非常大,导致运行时间较长。其次,Apriori算法对候选项集的生成和评估采用了较为简单的方式,可能会产生大量的冗余计算和冗余规则。最后,Apriori算法对数据的稀疏性和噪声较为敏感,可能会影响其性能和准确性。
6.2 讨论关联规则学习领域的未来发展方向
关联规则学习领域在未来将继续发展,并呈现出以下几个方向:
- 算法优化:针对Apriori算法等现有算法的局限性,研究者们将继续探索新的优化方法和技术,以提高算法的性能和准确性。例如,可以进一步改进FP-Growth算法、利用并行化技术加速计算过程等。
- 深度学习在关联规则学习中的应用:随着深度学习技术的不断发展,将深度学习应用于关联规则学习中将是一个新的研究方向。深度学习可以自动学习数据中的复杂模式,有望进一步提高关联规则学习的性能。
- 跨领域融合:关联规则学习可以与其他数据挖掘和机器学习技术相结合,形成跨领域的融合方法。例如,可以将关联规则学习与推荐系统、社交网络分析等领域相结合,以发现更多有趣和有价值的信息。
- 实时关联规则学习:随着实时数据的不断增长,实时关联规则学习将成为一个重要的研究方向。研究者们将探索如何在数据流中实时发现关联规则,并将其应用于实时推荐、异常检测等场景中。
6.3 提出可能的改进方案和研究建议
针对Apriori算法和关联规则学习领域的发展方向,我们提出以下可能的改进方案和研究建议:
- 优化候选项集生成和评估策略:通过改进候选项集的生成和评估策略,减少冗余计算和冗余规则的产生,提高算法的效率。
- 结合深度学习技术:将深度学习技术应用于关联规则学习中,自动学习数据中的复杂模式,提高算法的准确性。
- 探索跨领域融合方法:将关联规则学习与其他数据挖掘和机器学习技术相结合,形成跨领域的融合方法,以发现更多有趣和有价值的信息。
- 研究实时关联规则学习算法:针对实时数据的特点,研究如何在数据流中实时发现关联规则,并将其应用于实时应用中。
七、参考文献
以下是本文引用的主要学术文献和资料,这些文献和资料为本文提供了理论基础、算法细节和应用实例等方面的支持。
-
Agrawal, R., & Srikant, R. (1994). Fast algorithms for mining association rules in large databases. In Proc. 20th int. conf. very large data bases, VLDB (pp. 487-499). This seminal paper introduced the Apriori algorithm for mining association rules in large databases. It discusses the basic principles and implementation of the algorithm.
-
Han, J., & Kamber, M. (2006). Data mining: concepts and techniques. Morgan Kaufmann. This book provides a comprehensive overview of data mining techniques, including association rule learning. It discusses the Apriori algorithm and its extensions in detail.
-
Li, H., Han, J., & Pei, J. (2001). FP-growth: frequent pattern growth in transactional databases. In Proc. 17th int. conf. data engineering (pp. 315-324). This paper proposes the FP-Growth algorithm as an efficient alternative to the Apriori algorithm for mining frequent itemsets and association rules.
-
Liu, B., Hsu, W., & Ma, Y. (2002). Integrating classification and association rule mining. In Proc. 8th ACM SIGKDD int. conf. knowledge discovery and data mining (pp. 80-89). This paper discusses how association rule mining can be integrated with classification tasks to improve prediction performance.
-
Zaki, M. J. (2000). Scalable algorithms for association mining. IEEE transactions on knowledge and data engineering, 12(3), 372-390. This paper discusses scalable algorithms for mining association rules in large datasets, including techniques for reducing the number of candidate itemsets.
八、附录
额外数据集
- GroceryStoreDataset.csv:一个包含超市购物篮数据的数据集,用于演示Apriori算法在市场篮子分析中的应用。
相关文章:
【机器学习-23】关联规则(Apriori)算法:介绍、应用与实现
在现代数据分析中,经常需要从大规模数据集中挖掘有用的信息。关联规则挖掘是一种强大的技术,可以揭示数据中的隐藏关系和规律。本文将介绍如何使用Python进行关联规则挖掘,以帮助您发现数据中的有趣模式。 一、引言 1. 简要介绍关联规则学习…...

Gradle筑基——Gradle Maven仓库管理
基础概念: 1.POM pom:全名Project Object Model 项目对象模型,用来描述当前maven项目发布模块的基础信息 pom主要节点信息如下: 配置描述举例(com.android.tools.build:gradle:4.1.1)groupId组织 / 公司的名称com.…...

c++11:智能指针的种类以及使用场景
指针管理困境 内存释放,指针没有置空;内存泄漏;资源重复释放 怎样解决? RAII 智能指针种类 shared_ptr 实现原理:多个指针指向同一资源,引用计数清零,再调用析构函数释放内存。 使用场景…...
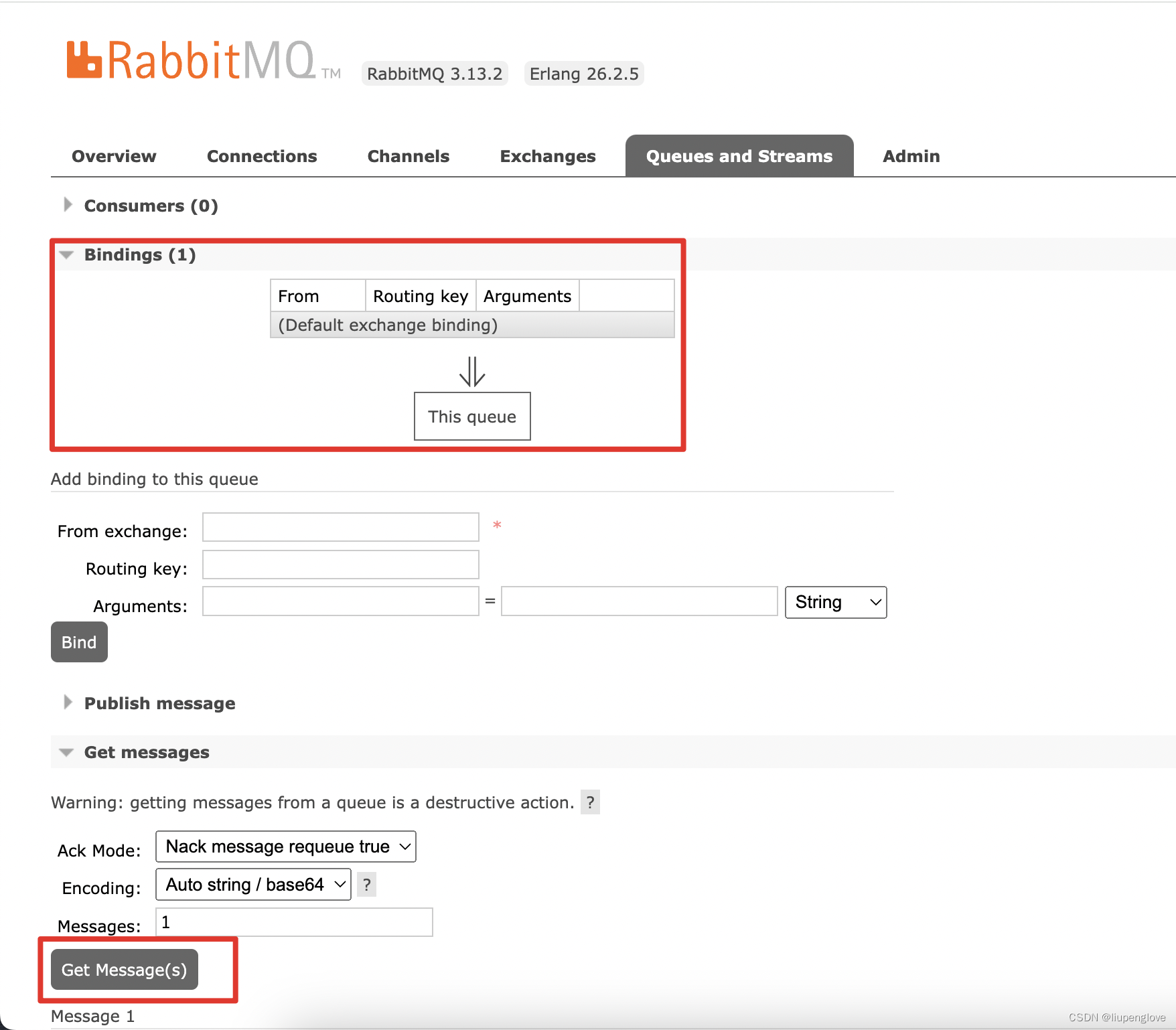
RabbitMQ-默认读、写方式介绍
1、RabbitMQ简介 rabbitmq是一个开源的消息中间件,主要有以下用途,分别是: 应用解耦:通过使用RabbitMQ,不同的应用程序之间可以通过消息进行通信,从而降低应用程序之间的直接依赖性,提高系统的…...

阿里云百炼大模型使用
阿里云百炼大模型使用 由于阿里云百炼大模型有个新用户福利,有免费的4000000 tokens,我开通了相应的服务试试水。 使用 这里使用Android开发了一个简单的demo。 安装SDK implementation group: com.alibaba, name: dashscope-sdk-java, version: 2.…...
)
亲测有效,通过接口实现完美身份证号有效性验证+身份证与姓名匹配查询身份实名认证接口(实时)
最近发现一个限时认证的接口分享给大家,有需要的拿去试下吧. 附上部分密钥f478186edba9854f205a130aa888733d227a8f82f98d84b9【剩余约125450次,无时间限制】 b6131281611f6e1fc86c8662f549bdd683a68517203ba312【剩余约1300次,无时段限制】 …...
试题11 输出什么?
...

对vue3/core源码ref.ts文件API的认识过程
对toRef()API的认识的过程: 最开始认识toRef()是从vue3源码中的ref.ts看见的,右侧GPT已经举了例子 然后根据例子,在控制台输出ref对象是什么样子的: 这就是ref对象了,我们根据对象中有没有__v_isRef来判断是不是一个ref对象,当对象存在且__v_isRef true的时候他就判定为是一个…...

AWS迁移与传输之AWS DMS
AWS Database Migration Service(AWS DMS)是一项托管的服务,用于帮助企业将现有的数据库迁移到AWS云中的各种数据库引擎中,或者在不同数据库引擎之间进行数据迁移和同步。直接在线迁移,将数据复制到云端,不…...
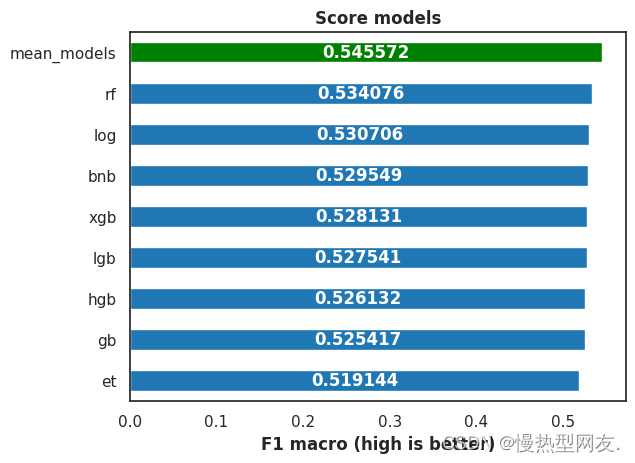
【ML Olympiad】预测地震破坏——根据建筑物位置和施工情况预测地震对建筑物造成的破坏程度
文章目录 Overview 概述Goal 目标Evaluation 评估标准 Dataset Description 数据集说明Dataset Source 数据集来源Dataset Fields 数据集字段 Data Analysis and Visualization 数据分析与可视化Correlation 相关性Hierarchial Clustering 分层聚类Adversarial Validation 对抗…...

kafka监控配置和告警配置
Kafka的监控配置和告警配置是确保Kafka集群稳定运行的关键部分。以下是一些关于Kafka监控配置和告警配置的建议: 一、Kafka监控配置 集群级别参数监控: log.retention.hours:用于控制消息在日志中保留的时间。监控此参数的值,确…...

关于智慧校园安全用电监测系统的设计
人生人身安全是大家关注的话题,2019年12月中国消防统计近五年发生在全国学生宿舍的火灾2314起(中国消防2019.12.应急管理部消防救援局官方微博),违规电器是引发火灾的主因。如果在各寝室安装智能用电监测器实时监督线路参数&#…...

Flutter 中的 FormField 小部件:全面指南
Flutter 中的 FormField 小部件:全面指南 在Flutter的世界里,表单是用户输入数据的基本方式之一。FormField是一个强大的小部件,它将表单字段的创建、验证和管理集成到了一个易于使用的抽象中。本文将为您提供一个全面的指南,帮助…...
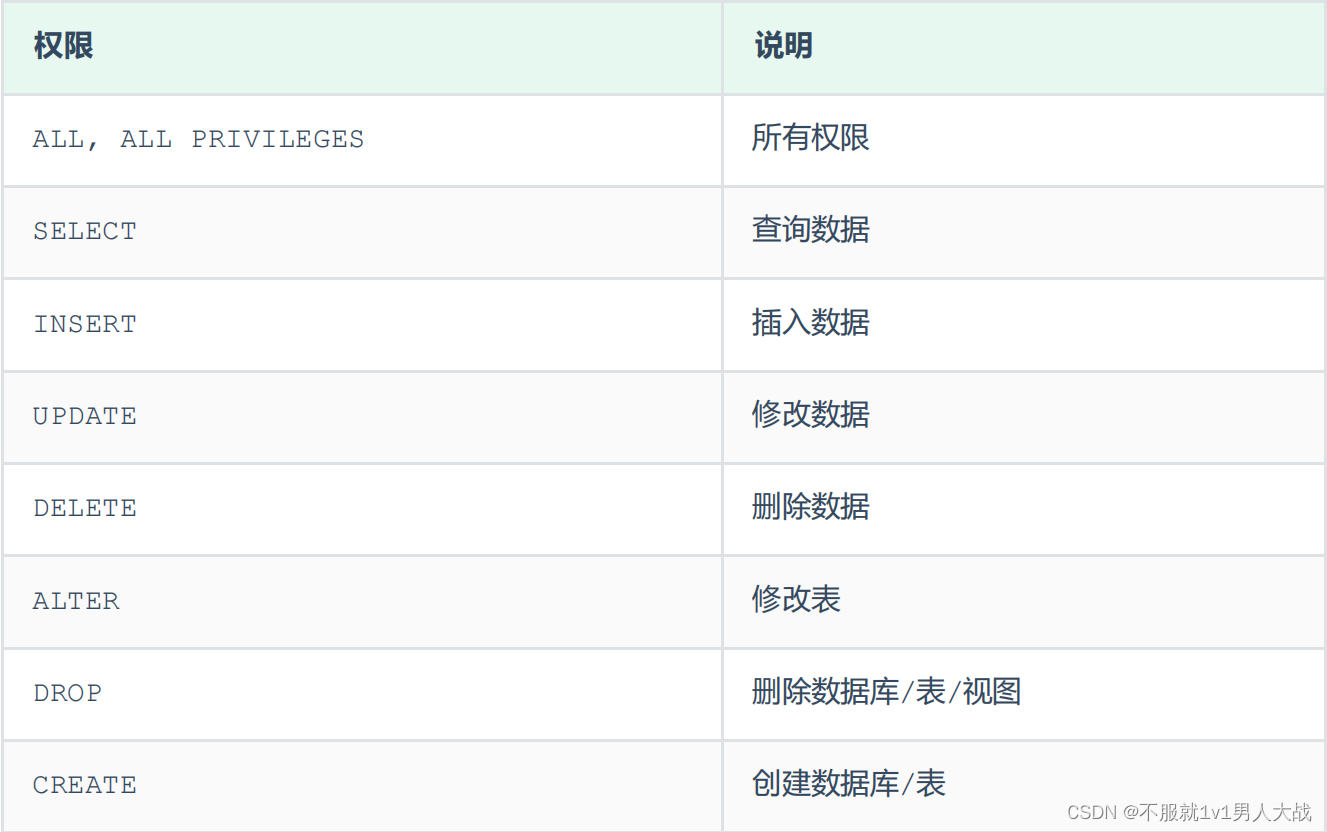
数据库DCL语句
数据库DCL语句 介绍: DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访 问权限。 管理用户: 查询用户: select * from mysql.user;创建用户: create user 用户名主机名 identified by 密码;修改用…...

mysql-日志管理-error.log
日志管理 默认的数据库日志 vim /etc/my.cnf //错误日志 log-error/usr/local/mysql/mysql.log查看数据库日志 tail -f /usr/local/mysql/mysql.log1 错误日志 :启动,停止,关闭失败报错。rpm安装日志位置 /var/log/mysqld.log #默认开启 2 …...
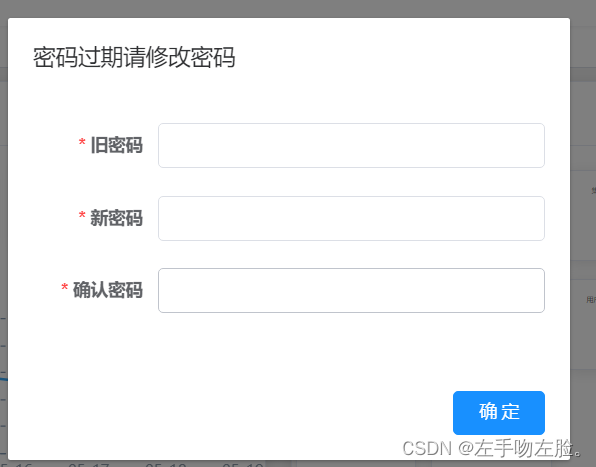
弱密码系统登录之后强制修改密码
在你登录的时候,获取到弱密码,然后将他存到vuex里面,在登录进去之后,index页面再去取,思路是这样的 一、vuex里面定义密码字段 我是直接在user.js里面写的 import { login, logout, getInfo } from /api/login impo…...

解释Python中的多线程和多进程编程
在Python中,多线程(Multithreading)和多进程(Multiprocessing)是两种常见的并发编程技术,用于同时执行多个任务。然而,由于Python的全局解释器锁(GIL,Global Interpreter…...

【LeetCode】【1】两数之和(1141字)
文章目录 [toc]题目描述样例输入输出与解释样例1样例2样例3 提示进阶Python实现哈希表 个人主页:丷从心 系列专栏:LeetCode 刷题指南:LeetCode刷题指南 题目描述 给定一个整数数组nums和一个整数目标值target,请在该数组中找出…...

【论文速读】|探索ChatGPT在软件安全应用中的局限性
本次分享论文:Exploring the Limits of ChatGPT in Software Security Applications 基本信息 原文作者:Fangzhou Wu, Qingzhao Zhang, Ati Priya Bajaj, Tiffany Bao, Ning Zhang, Ruoyu "Fish" Wang, Chaowei Xiao 作者单位:威…...

部门来了个测试开发,听说是00后,上来一顿操作给我看蒙了...
公司新来了个同事,听说大学是学的广告专业,因为喜欢IT行业就找了个培训班,后来在一家小公司实习半年,现在跳槽来我们公司。来了之后把现有项目的性能优化了一遍,服务器缩减一半,性能反而提升4倍!…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用
qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,追求极致音质的音…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...