基于长短期记忆网络 LSTM 的送餐时间预测

前言
系列专栏:【深度学习:算法项目实战】✨︎
涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。
对于送餐服务公司来说,预测订单的送达时间是一项极具挑战性的任务。像 Zomato 和 Swiggy 这样的食品外卖服务需要准确显示送达订单所需的时间,以保持对客户的透明度。这些公司使用机器学习算法,根据送餐员过去在相同距离上所花费的时间来预测送餐时间。因此,如果您想了解如何使用机器学习预测食品配送时间,本文就是为您准备的。本文将带你使用 Python 通过机器学习预测送餐时间。
目录
- 1. 相关数据集
- 1.1 导入必要库
- 1.2 加载数据集
- 2. 计算两个经纬度之间的距离
- 3. 探索性分析
- 3.1 送餐距离和送餐时间
- 3.2 送餐时间与送餐员年龄
- 3.3 送餐时间与送餐员评级
- 3.4 食物类型与车辆类型
- 4. 时间预测模型
- 4.1 准备数据
- 4.2 构建模型(LSTM)
- 4.3 模型训练
- 4.4 模型评估
- 5. 总结
1. 相关数据集
要实时预测食品配送时间,我们需要计算餐厅与送餐地点之间的距离。在找到餐厅和送餐地点之间的距离后,我们需要找到送餐员过去在相同距离内送餐所用时间之间的关系。因此,为了完成这项任务,我们需要一个数据集,其中包含送餐员从餐厅到送餐地点的送餐时间数据。
这里提供的数据集是 Gaurav Malik 在 Kaggle 上提交的原始数据集的净化版本。
以下是数据集中的所有特征:🔗
- ID: 订单 ID 编号
- Delivery_person_ID: 送餐员的 ID 编号
- Delivery_person_Age: 送餐员的年龄
- Delivery_person_Ratings(送餐人员评分): 根据以往送餐情况对送餐员的评分
- Restaurant_latitude: 餐厅的纬度
- Restaurant_longitude: 餐厅的经度
- Delivery_location_latitude: 送餐地点的纬度
- Delivery_location_longitude: 送餐地点的经度
- Type_of_order: 顾客订购的餐食类型
- Type_of_vehicle:送餐员所乘坐车辆的类型
- Time_taken(min): 送餐员完成订单所需的时间
1.1 导入必要库
我将通过导入必要的 Python 库和数据集来开始送餐时间预测任务:
import numpy as np
import pandas as pd
import plotly.express as px#splitting data
from sklearn.model_selection import train_test_split# creating the LSTM neural network model
from keras.models import Sequential
from keras.layers import Input, Dense, LSTM
1.2 加载数据集
①使用 pandas 函数 .read_csv() 加载数据集
data = pd.read_csv("deliverytime.txt")
print(data.head())
ID Delivery_person_ID Delivery_person_Age Delivery_person_Ratings \
0 4607 INDORES13DEL02 37 4.9
1 B379 BANGRES18DEL02 34 4.5
2 5D6D BANGRES19DEL01 23 4.4
3 7A6A COIMBRES13DEL02 38 4.7
4 70A2 CHENRES12DEL01 32 4.6 Restaurant_latitude Restaurant_longitude Delivery_location_latitude \
0 22.745049 75.892471 22.765049
1 12.913041 77.683237 13.043041
2 12.914264 77.678400 12.924264
3 11.003669 76.976494 11.053669
4 12.972793 80.249982 13.012793 Delivery_location_longitude Type_of_order Type_of_vehicle Time_taken(min)
0 75.912471 Snack motorcycle 24
1 77.813237 Snack scooter 33
2 77.688400 Drinks motorcycle 26
3 77.026494 Buffet motorcycle 21
4 80.289982 Snack scooter 30
接下来,让我们来看看每一列数据的具体信息
②使用 .info()方法打印有关DataFrame的信息,包括索引dtype和列、非null值以及内存使用情况
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 45593 entries, 0 to 45592
Data columns (total 11 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 ID 45593 non-null object 1 Delivery_person_ID 45593 non-null object 2 Delivery_person_Age 45593 non-null int64 3 Delivery_person_Ratings 45593 non-null float644 Restaurant_latitude 45593 non-null float645 Restaurant_longitude 45593 non-null float646 Delivery_location_latitude 45593 non-null float647 Delivery_location_longitude 45593 non-null float648 Type_of_order 45593 non-null object 9 Type_of_vehicle 45593 non-null object 10 Time_taken(min) 45593 non-null int64
dtypes: float64(5), int64(2), object(4)
memory usage: 3.8+ MB
③现在我们来看看这个数据集是否包含任何空值:
data.isnull().sum()
ID 0
Delivery_person_ID 0
Delivery_person_Age 0
Delivery_person_Ratings 0
Restaurant_latitude 0
Restaurant_longitude 0
Delivery_location_latitude 0
Delivery_location_longitude 0
Type_of_order 0
Type_of_vehicle 0
Time_taken(min) 0
dtype: int64
数据集没有任何空值。让我们继续!
2. 计算两个经纬度之间的距离
数据集没有任何特征可以显示餐厅和送餐地点之间的差异。我们只有餐厅和送餐地点的经纬度点。我们可以使用哈弗辛公式,根据两个地点的经纬度计算它们之间的距离。
下面是我们如何根据餐厅和外卖地点的经纬度,利用哈弗辛公式求出它们之间的距离:
# Set the earth's radius (in kilometers)
R = 6371# Convert degrees to radians
def deg_to_rad(degrees):return degrees * (np.pi/180)# Function to calculate the distance between two points using the haversine formula
def distcalculate(lat1, lon1, lat2, lon2):d_lat = deg_to_rad(lat2-lat1)d_lon = deg_to_rad(lon2-lon1)a = np.sin(d_lat/2)**2 + np.cos(deg_to_rad(lat1)) * np.cos(deg_to_rad(lat2)) * np.sin(d_lon/2)**2c = 2 * np.arctan2(np.sqrt(a), np.sqrt(1-a))return R * c# Calculate the distance between each pair of points
data['distance'] = np.nanfor i in range(len(data)):data.loc[i, 'distance'] = distcalculate(data.loc[i, 'Restaurant_latitude'], data.loc[i, 'Restaurant_longitude'], data.loc[i, 'Delivery_location_latitude'], data.loc[i, 'Delivery_location_longitude'])
现在,我们已经计算出餐厅与送餐地点之间的距离。我们还在数据集中添加了一个新特征,即距离。让我们再次查看数据集:
print(data.head())
ID Delivery_person_ID Delivery_person_Age Delivery_person_Ratings \
0 4607 INDORES13DEL02 37 4.9
1 B379 BANGRES18DEL02 34 4.5
2 5D6D BANGRES19DEL01 23 4.4
3 7A6A COIMBRES13DEL02 38 4.7
4 70A2 CHENRES12DEL01 32 4.6 Restaurant_latitude Restaurant_longitude Delivery_location_latitude \
0 22.745049 75.892471 22.765049
1 12.913041 77.683237 13.043041
2 12.914264 77.678400 12.924264
3 11.003669 76.976494 11.053669
4 12.972793 80.249982 13.012793 Delivery_location_longitude Type_of_order Type_of_vehicle Time_taken(min) \
0 75.912471 Snack motorcycle 24
1 77.813237 Snack scooter 33
2 77.688400 Drinks motorcycle 26
3 77.026494 Buffet motorcycle 21
4 80.289982 Snack scooter 30 distance
0 3.025149
1 20.183530
2 1.552758
3 7.790401
4 6.210138
3. 探索性分析
3.1 送餐距离和送餐时间
现在,让我们探索数据,找出特征之间的关系。我先来看看送餐距离和送餐时间之间的关系:
figure = px.scatter(data_frame = data, x="distance",y="Time_taken(min)", size="Time_taken(min)", trendline="ols", title = "Relationship Between Distance and Time Taken")
figure.show()

送餐时间与送餐距离之间存在一致的关系。也就是说,无论距离远近,大多数送餐员都能在 25-30 分钟内送达食物。
3.2 送餐时间与送餐员年龄
现在我们来看看送餐时间与送餐员年龄之间的关系:
figure = px.scatter(data_frame = data, x="Delivery_person_Age",y="Time_taken(min)", size="Time_taken(min)", color = "distance",trendline="ols", title = "Relationship Between Time Taken and Age")
figure.show()

送餐时间与送餐员的年龄呈线性关系。这意味着年轻的送餐员比年长的送餐员用时更短。
3.3 送餐时间与送餐员评级
现在让我们来看看送餐时间与送餐员评级之间的关系:
figure = px.scatter(data_frame = data, x="Delivery_person_Ratings",y="Time_taken(min)", size="Time_taken(min)", color = "distance",trendline="ols", title = "Relationship Between Time Taken and Ratings")
figure.show()

送餐时间与送餐员的评分之间存在反向线性关系。也就是说,与评分低的送餐员相比,评分高的送餐员送餐时间更短。
3.4 食物类型与车辆类型
现在我们来看看顾客订购的食物类型和送餐员使用的车辆类型是否会影响送餐时间:
fig = px.box(data, x="Type_of_vehicle",y="Time_taken(min)", color="Type_of_order")
fig.show()

因此,送餐员所花费的时间并不会因为他们所驾驶的车辆和所运送的食品类型而有太大差异。
因此,根据我们的分析,对送餐时间影响最大的特征是:
- 送餐员的年龄
- 送餐员的评级
- 餐厅与送餐地点之间的距离
4. 时间预测模型
4.1 准备数据
将数据拆分为训练集和测试集
#splitting data
from sklearn.model_selection import train_test_split
x = np.array(data[["Delivery_person_Age", "Delivery_person_Ratings", "distance"]])
y = np.array(data[["Time_taken(min)"]])
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.10, random_state=42)
4.2 构建模型(LSTM)
现在,让我们使用 LSTM 神经网络模型来训练一个机器学习模型,以完成送餐时间预测任务:
# creating the LSTM neural network model
from keras.models import Sequential
from keras.layers import Input, Dense, LSTMmodel = Sequential([Input(shape=(xtrain.shape[1], 1)),LSTM(128, return_sequences=True),LSTM(64, return_sequences=False),Dense(25),Dense(1)
])model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ lstm (LSTM) │ (None, 3, 128) │ 66,560 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_1 (LSTM) │ (None, 64) │ 49,408 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 25) │ 1,625 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_1 (Dense) │ (None, 1) │ 26 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘Total params: 117,619 (459.45 KB)Trainable params: 117,619 (459.45 KB)Non-trainable params: 0 (0.00 B)
4.3 模型训练
model.fit(xtrain, ytrain, batch_size=1, epochs=9)
Epoch 1/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 65s 2ms/step - loss: 78.0635
Epoch 2/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 63s 2ms/step - loss: 65.2568
Epoch 3/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 62s 2ms/step - loss: 61.7881
Epoch 4/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 62s 2ms/step - loss: 60.5413
Epoch 5/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 63s 2ms/step - loss: 60.2824
Epoch 6/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 63s 2ms/step - loss: 59.3861
Epoch 7/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 62s 2ms/step - loss: 59.8831
Epoch 8/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 62s 2ms/step - loss: 59.0806
Epoch 9/9
41033/41033 ━━━━━━━━━━━━━━━━━━━━ 63s 2ms/step - loss: 59.7611
4.4 模型评估
现在,让我们通过输入来预测送餐时间,从而测试模型的性能:
print("Food Delivery Time Prediction")
a = int(input("Age of Delivery Partner: "))
b = float(input("Ratings of Previous Deliveries: "))
c = int(input("Total Distance: "))features = np.array([[a, b, c]])
print("Predicted Delivery Time in Minutes = ", model.predict(features))
Food Delivery Time Prediction
Age of Delivery Partner: 29
Ratings of Previous Deliveries: 2.9
Total Distance: 6
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 155ms/step
Predicted Delivery Time in Minutes = [[35.726112]]
5. 总结
要实时预测食品配送时间,需要计算食品准备点与食品消费点之间的距离。在找到餐厅和送餐地点之间的距离后,您需要找到送餐员过去在相同距离内的送餐时间之间的关系。希望您喜欢这篇关于使用 Python 进行机器学习预测送餐时间的文章。
相关文章:
基于长短期记忆网络 LSTM 的送餐时间预测
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...

K-means聚类算法详细介绍
目录 🍉简介 🍈K-means聚类模型详解 🍈K-means聚类的基本原理 🍈K-means聚类的算法步骤 🍈K-means聚类的优缺点 🍍优点 🍍缺点 🍈K-means聚类的应用场景 🍈K-mea…...
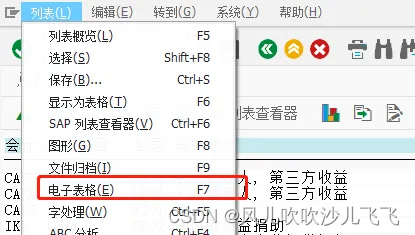
SAP FS00如何导出会计总账科目表
输入T-code : S_ALR_87012333 根据‘FS00’中找到的总账科目,进行筛选执行 点击左上角的列表菜单,选择‘电子表格’导出即可...

ROS参数服务器
一、介绍 参数服务器是用于存储和检索参数的分布式多机器人配置系统,它允许节点动态地获取参数值。 在ROS中,参数服务器是一种用于存储和检索参数的分布式多机器人配置系统。它允许节点动态地获取参数值,并提供了一种方便的方式来管理和共享配…...

QCC---DFU升级变更设备名和地址
QCC---DFU升级变更设备名和地址 这个很多人碰到这个疑问,升级了改不了设备名和地址 /******************************************************************************* Copyright (c) 2018 Qualcomm Technologies International, Ltd. FILE NAME sink_dfu_ps.c DESCRIPT…...

[力扣题解] 695. 岛屿的最大面积
题目:695. 岛屿的最大面积 思路 代码 深度优先搜索 // 深度搜索 class Solution { private:int area_max 0;int dir[4][2] {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};void dfs(vector<vector<int>>& grid, vector<vector<bool>>& …...

AI模型发展路径探析:开源与闭源,何者更胜一筹?
AI模型发展路径探析:开源与闭源,何者更胜一筹? 在当今快速发展的人工智能领域,AI模型成为推动技术创新和应用落地的关键。而评价一个AI模型“好不好”“有没有发展”,往往会引向一个重要话题:开源与闭源这…...

concurrency 并行编程
Goroutine go语言的魅力所在,高并发。 线程是操作系统调度的一种执行路径,用于在处理器执行我们在函数中编写的代码。一个进程从一个线程开始,即主线程,当该线程终止时,进程终止。这是因为主线程是应用程序的原点。然后…...

JavaScript如何让一个按钮的点击事件在完成之前禁用
在JavaScript中,要禁用一个按钮的点击事件直到某个操作完成,你可以将其点击事件用匿名函数的方式书写。 你可以将其在点击函数内设置为null来禁用按钮。 <button id"butto_n">点击抽奖</button><script>butto_n.onclick bu…...

透视App投放效果,Xinstall助力精准分析,让每一分投入都物超所值!
在移动互联网时代,App的推广与投放成为了每一个开发者和广告主必须面对的问题。然而,如何精准地掌握投放效果,让每一分投入都物超所值,却是一个令人头疼的难题。今天,我们就来谈谈如何通过Xinstall这个专业的App全渠道…...

【Linux杂货铺】进程通信
目录 🌈 前言🌈 📁 通信概念 📁 通信发展阶段 📁 通信方式 📁 管道(匿名管道) 📂 接口 编辑📂 使用fork来共享通道 📂 管道读写规则 &…...
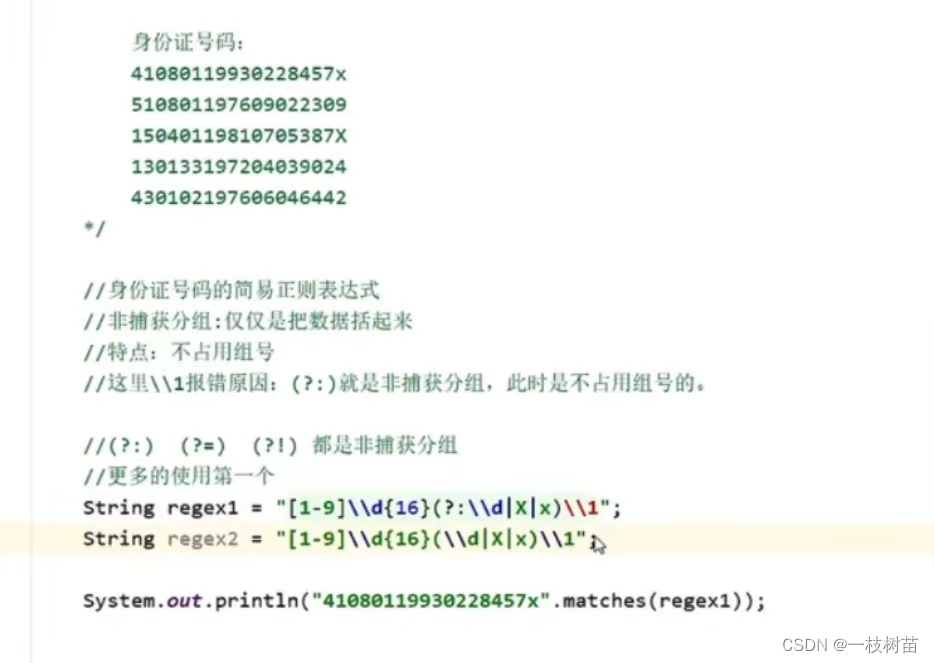
常用API(正则表达式、爬取、捕获分组和非捕获分组 )
1、正则表达式 练习——先爽一下正则表达式 正则表达式可以校验字符串是否满足一定的规则,并用来校验数据格式的合法性。 需求:假如现在要求校验一个qq号码是否正确。 规则:6位及20位之内,0不能在开头,必须全部是数字…...
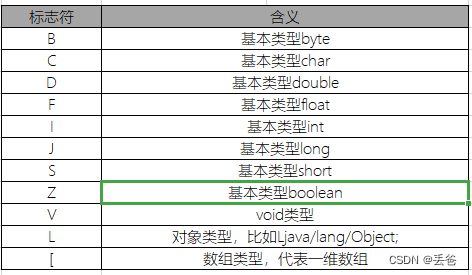
JVM学习-Class文件结构②
访问标识(access_flag) 在常量池后,紧跟着访问标记,标记使用两个字节表示,用于识别一些类或接口层次的访问信息,包括这个Class是类还是接口,是否定义为public类型,是否定义为abstract类型,如果…...

数据库连接项目
MySQL...

MySQL--InnoDB体系结构
目录 一、物理存储结构 二、表空间 1.数据表空间介绍 2.数据表空间迁移 3.共享表空间 4.临时表空间 5.undo表空间 三、InnoDB内存结构 1.innodb_buffer_pool 2.innodb_log_buffer 四、InnoDB 8.0结构图例 五、InnoDB重要参数 1.redo log刷新磁盘策略 2.刷盘方式&…...

ffplay 使用文档介绍
ffplay ffplay 是一个简单的媒体播放器,它是 FFmpeg 项目的一部分。FFmpeg 是一个广泛使用的多媒体框架,能够解码、编码、转码、复用、解复用、流化、过滤和播放几乎所有类型的媒体文件。 ffplay 主要用于测试和调试,因为它提供了一个命令行界面,可以方便地查看媒体文件的…...
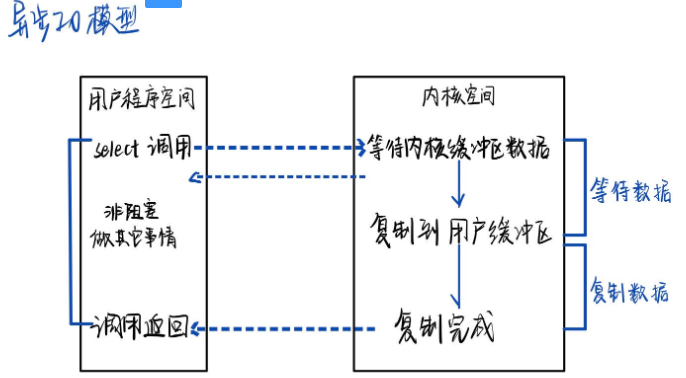
四种网络IO模型
📝个人主页:五敷有你 🔥系列专栏:面经 ⛺️稳中求进,晒太阳 IO的定义 IO是计算机内存与外部设备之间拷贝数据的过程。CPU访问内存的速度远高于外部设备。因此CPU是先把外部设备的数据读取到内存,在…...
Mixed-precision计算原理(FP32+FP16)
原文: https://lightning.ai/pages/community/tutorial/accelerating-large-language-models-with-mixed-precision-techniques/ This approach allows for efficient training while maintaining the accuracy and stability of the neural network. In more det…...
的并发数量)
Go 控制协程(goroutine)的并发数量
在使用协程并发处理某些任务时, 其并发数量往往因为各种因素的限制不能无限的增大. 例如网络请求、数据库查询等等。 从运行效率角度考虑,在相关服务可以负载的前提下(限制最大并发数),尽可能高的并发。 在Go语言中,…...
:web渗透测试之CSRF跨站请求伪造)
web安全渗透测试十大常规项(一):web渗透测试之CSRF跨站请求伪造
渗透测试之CSRF跨站请求伪造 CSRF跨站请求伪造 CSRF跨站请求伪造...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

Godot 4.3随机地图性能优化:避开TileMap与RNG陷阱
1. 为什么刚写完第一版随机地图就崩溃?——从“能跑”到“能用”的真实断层你兴冲冲地照着教程敲完几十行GDScript,RandomNumberGenerator初始化了,for x in range(width)循环也套好了,甚至还在_draw()里用draw_rect()把每个格子都…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...

SafeExamBrowser虚拟机检测绕过实战:双路径技术决策与深度破解
SafeExamBrowser虚拟机检测绕过实战:双路径技术决策与深度破解 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser(…...

代码跑偏白盒补漏:判定节点覆盖全路径测试
位于程序逻辑分叉处,起着关键开通作用的判定节点,意义无比重大。于程序运行进程里,每一条if语句、else语句以及switch语句背后,事实上都暗藏着一条独具特色且彼此独立的执行回路。而测试覆盖的核心使命,就是要把这些回…...
)
UE4插件开发实战:手把手教你为自定义资源创建独立的3D预览窗口(基于SEditorViewport)
UE4插件开发实战:打造自定义资源的3D预览视口在虚幻引擎4的编辑器扩展开发中,为自定义资源提供直观的3D预览功能是提升工具链效率的关键环节。想象一下,当技术美术师调整一把自定义武器的参数时,能够实时看到模型变化,…...
)
PyAutoGUI图像识别踩坑实录:如何让游戏自动化脚本更稳定?(附避坑指南)
PyAutoGUI图像识别稳定性优化实战:从原理到避坑指南游戏自动化脚本开发中,图像识别是最容易翻车的环节。上周我的《原神》自动采集脚本在好友电脑上运行时,连续三次误点了传送锚点而非目标采集物——这让我意识到不同设备环境对locateOnScree…...

告别窗口遮挡:Topit如何让macOS多任务效率提升3倍
告别窗口遮挡:Topit如何让macOS多任务效率提升3倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否曾经因为窗口重叠而频繁切换应用࿱…...

全方位防护矿山开采三维透明化智能安全防控整体方案
依托黎阳之光核心技术矿山开采三维透明化智能安全防控整体方案一、方案前言1.建设背景矿山开采井下巷道错综复杂、采掘工作面地质隐蔽,顶板、透水、瓦斯、边坡失稳、三违作业、设备故障为高发安全风险。传统二维监控、分散监测系统存在场景碎片化、地质不可视、风险…...