huggingface 笔记:查看GPU占用情况
0 准备部分
0.1 创建虚拟数据
import numpy as npfrom datasets import Datasetseq_len, dataset_size = 512, 512
dummy_data = {"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),"labels": np.random.randint(0, 1, (dataset_size)),
}
dummy_data
'''
使用 np.random.randint 函数生成一个形状为 (dataset_size, seq_len),即 512x512 的数组。
数组中的每个元素是一个随机整数,范围从 100 到 30000。使用 np.random.randint 函数生成一个形状为 (dataset_size,) 的数组,其中的元素是 0 或 1
表示每个样本的标签
'''
'''
{'input_ids': array([[11687, 1246, 6661, ..., 20173, 3772, 29152],[ 720, 25945, 11963, ..., 11675, 27842, 3553],[22100, 26587, 19452, ..., 1836, 24395, 22849],...,[11610, 24425, 1026, ..., 6237, 28503, 2775],[10266, 22622, 14079, ..., 24491, 26029, 17796],[11500, 7688, 13780, ..., 4839, 13967, 18493]]),'labels': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0])}
'''ds = Dataset.from_dict(dummy_data)
ds.set_format("pt")
#将它们存储在一个带有PyTorch格式的数据集中
ds
'''
Dataset({features: ['input_ids', 'labels'],num_rows: 512
})
'''0.2 辅助函数
为了打印GPU利用率和使用Trainer进行训练运行的摘要统计信息,定义了两个辅助函数
0.2.1 打印GPU内存使用情况
from pynvml import *def print_gpu_utilization(device_id=1):nvmlInit()#初始化 NVML 库handle = nvmlDeviceGetHandleByIndex(device_id)#获取索引为 device_id 的 GPU 设备的句柄。info = nvmlDeviceGetMemoryInfo(handle)'''使用前面获取的句柄,查询该 GPU 的内存信息。返回的对象包含了 GPU 内存的总量、已使用的量和空闲的量。'''print(f"GPU内存占用:{info.used // 1024 ** 2} MB。")'''打印 GPU 当前已使用的内存量,单位为 MB。这里通过将字节单位的值除以 1024 的平方来转换为 MBprint_gpu_utilization()
#GPU内存占用:270 MB。0.2.2 打印训练过程的信息
def print_summary(result):print(f"时间:{result.metrics['train_runtime']:.2f}")'''打印训练过程的运行时间从 result 对象中的 metrics 字典获取 'train_runtime' 键的值格式化为两位小数。'''print(f"样本/秒:{result.metrics['train_samples_per_second']:.2f}")'''打印训练速度,即每秒处理的样本数从 result 对象中的 metrics 字典获取 'train_samples_per_second' 键的值格式化为两位小数。'''print_gpu_utilization()#调用 print_gpu_utilization() 函数来打印 GPU 的内存使用情况1 加载模型,查看GPU空间占用情况
print_gpu_utilization(1)
#print_gpu_utilization(1)from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-large-uncased").to("cuda:1")
print_gpu_utilization(1)
#GPU内存占用:1866 MB。2 训练模型时的GPU占用情况
default_args = {"output_dir": "tmp","eval_strategy": "steps","num_train_epochs": 1,"log_level": "error","report_to": "none",
}
'''
output_dir: 指定输出目录,这里设置为 "tmp"。
eval_strategy: 设置评估策略为 "steps",意味着在训练过程中会按照步骤进行模型评估。
num_train_epochs: 设置训练周期为 1,即整个训练集只会被训练一遍。
log_level: 设置日志级别为 "error",这样只有错误信息会被记录。
report_to: 设置报告输出目标为 "none",这表示不将训练进度报告输出到任何外部服务或控制台。
'''
from transformers import TrainingArguments, Trainer, logginglogging.set_verbosity_error()
#让 transformers 库只输出错误级别的日志。training_args = TrainingArguments(per_device_train_batch_size=1,**default_args)
'''
TrainingArguments: 创建一个训练参数对象,设置每个设备的训练批量大小为 1
并将前面定义的默认参数集成进来。
'''
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
#Trainer: 初始化训练器,传入模型、训练参数和训练数据集。
result = trainer.train()
#使用 trainer.train() 启动训练过程,并将结果存储在 result 变量中
print_summary(result)
在我这边的GPU上跑不起来:可能是不同版本的cuda、pytorch导致的(不确定)
相关文章:
huggingface 笔记:查看GPU占用情况
0 准备部分 0.1 创建虚拟数据 import numpy as npfrom datasets import Datasetseq_len, dataset_size 512, 512 dummy_data {"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),"labels": np.random.randint(0, 1, (dataset_size…...

JavaSE 学习记录
1. Java 内存 2. this VS super this和super是两个关键字,用于引用当前对象和其父类对象 this 关键字: this 关键字用于引用当前对象,即调用该关键字的方法所属的对象。 主要用途包括: 在类的实例方法中,通过 this …...
HTML与CSS的学习
什么是HTML,CSS? HTML(HyperText Markup Language):超文本标记语言。 超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等 标记语言:由标签构成的语言 >HTML标签都是预定义好的。例如:使用<a>…...
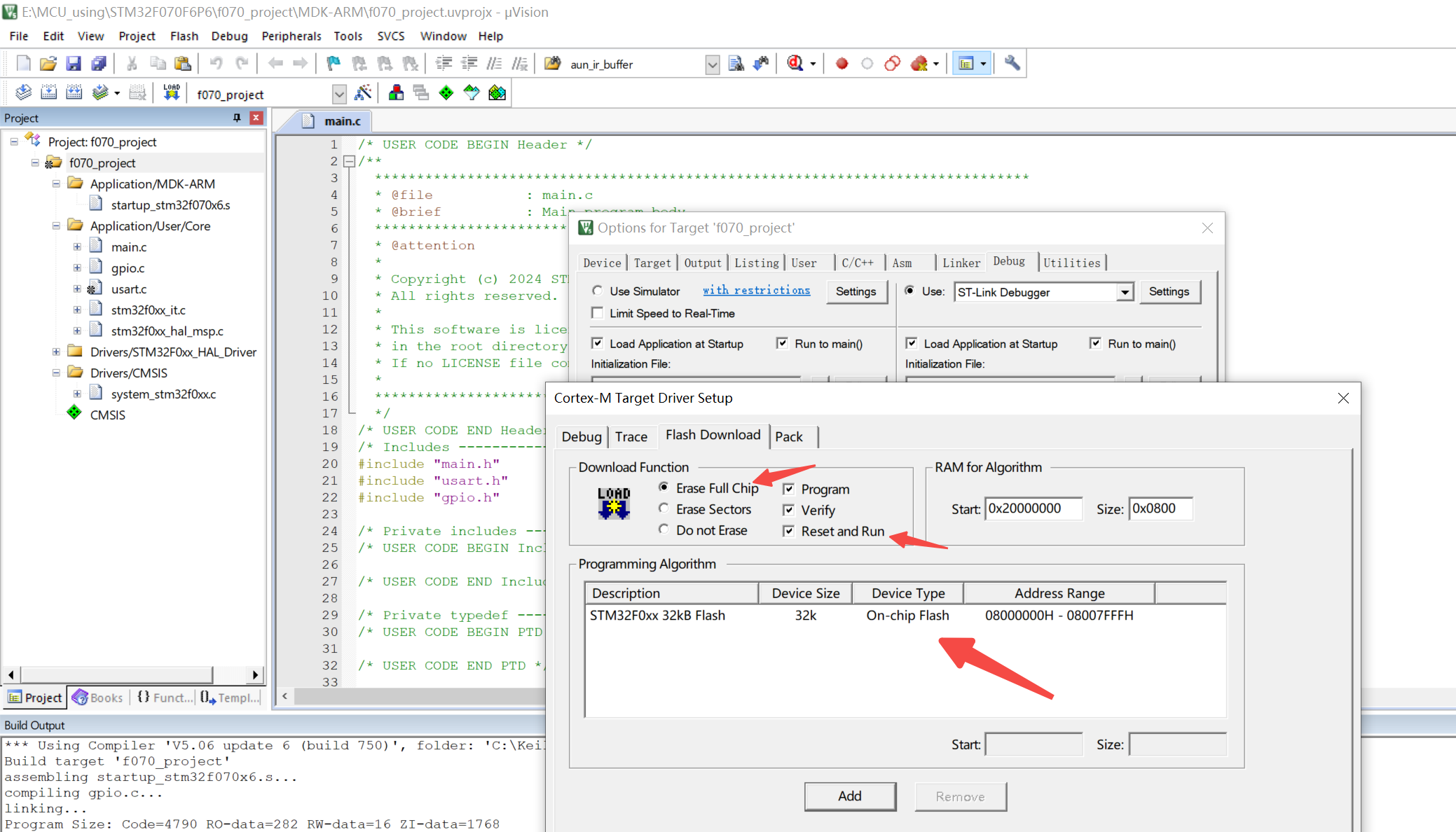
【单片机】STM32F070F6P6 开发指南(一)STM32建立HAL工程
文章目录 一、基础入门二、工程初步建立三、HSE 和 LSE 时钟源设置四、时钟系统(时钟树)配置五、GPIO 功能引脚配置六、配置 Debug 选项七、生成工程源码八、生成工程源码九、用户程序下载 一、基础入门 f0 pack下载: https://www.keil.arm…...
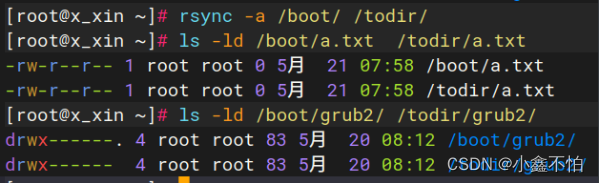
源码编译安装Rsync数据同步
源码编译安装 RPM软件包:rpm -ivh 或者 yum -y install 需要开发编译工具gcc、gcc-c、make等... 源码包----开发工具gcc与make----》可以执行的程序-----》运行安装 •主要优点 –获得软件的最新版,及时修复bug –软件功能可按需选择/定制ÿ…...
SQL Server2019安装步骤教程(图文)_最新教程
一、下载SQL Server2019 1.到微软官网下载SQL Server Developer版本,官网当前的2019版本下载需要注册账号。 不想注册的朋友,可以选择从网盘下载:点击此处直接下载 2.下载之后先解压,解压后执行exe安装程序。打开之后的界面如下…...

【SpringBoot】SpringBoot中防止接口重复提交(单机环境和分布式环境)
📝个人主页:哈__ 期待您的关注 目录 🌼前言 🔒单机环境下防止接口重复提交 📕导入依赖 📂项目结构 🚀创建自定义注解 ✈创建AOP切面 🚗创建Conotroller 💻分布…...
)
零基础学Java(全170集)
课程概述 本课程旨在全面深化对 Java 语言的核心技术理解,并提升编程实践能力。课程内容涵盖以下关键领域: 掌握Java核心语法,为后续学习打下扎实的基础。熟练运用Java常用的类库与开发工具,提高开发效率与质量。解决面向对象编…...

摄像头应用测试
作者简介: 一个平凡而乐于分享的小比特,中南民族大学通信工程专业研究生在读,研究方向无线联邦学习 擅长领域:驱动开发,嵌入式软件开发,BSP开发 作者主页:一个平凡而乐于分享的小比特的个人主页…...

Golang框架HTTP客户端框架zdpgo_resty发送表单请求
核心代码 这里通过字典传递了一个简单的表单数据。 发送的是POST请求。 resp, err : client.R().SetFormData(map[string]string{"username": "jeeva","password": "mypass",}).Post("http://127.0.0.1:3333/login")fmt.P…...
【机器学习300问】99、多通道卷积神经网络在卷积操作时有哪些注意事项?
一、多通道卷积神经网络示例 还是以图像处理为例,如果你的目标不仅是分析灰度图像特性,还打算捕捉RGB彩色图像的特征。如下图,当面对一张66像素的彩色图像时,提及的“3”实际上是指红、绿、蓝三种颜色通道,形象地说&am…...

Rust之函数、单元测试
1、函数 类似于C函数。 1.1、普通函数 在Rust中,函数的定义使用fn关键字,后跟函数名、参数列表、返回类型和函数体。函数体由一系列语句组成,用于执行特定的操作和计算。 函数定义: 使用fn关键字定义函数,函数由函数…...

Linux环境下TensorFlow安装教程
TensorFlow是学习深度学习时常用的Python神经网络框 下面以Mask R-CNN 的环境配置为例: 首先进入官网:www.tensorflow.org TensorFlow安装的总界面: 新建anaconda虚拟环境: conda create -n envtf2 python3.8 (Pyth…...

基于Open3D的点云处理19-模拟生成点云
如果没有设备,怎么得到点云进行学习研究呢,一般通过以下方法: 模型采样+增加噪声:简单方便,但结果比较理想与真实扫描不一致;光线投射:简单方便,可以模仿传感器的一个扫描视角Blensor点云仿真:能够模仿传感器本身的一些噪声,适合激光雷达和tof相机的仿真,传感器较少…...
安全分析[1]之网络协议脆弱性分析
文章目录 威胁网络安全的主要因素计算机网络概述网络体系结构 网络体系结构脆弱性分组交换认证与可追踪性尽力而为匿名与隐私对全球网络基础实施的依赖无尺度网络互联网的级联特性中间盒子 典型网络协议脆弱性IP协议安全性分析IPSec(IP Security)IPv6问题 ICMP协议安…...
)
数据湖对比(hudi,iceberg,paimon,Delta)
Delta 数据湖 Delta 更新原理 update/delete/merge 实现均基于spark的join功能。 定位 做基于spark做流批一体的数据处理 缺点 本质为批处理。强绑定spark引擎。整体性能相较其他数据湖比较差 hudi 数据湖 hudi 更新原理 通过hudi自定义的主键索引hoodiekey 布隆过…...
基于ssm的蛋糕商城系统java项目jsp项目javaweb
文章目录 蛋糕商城系统一、项目演示二、项目介绍三、系统部分功能截图四、部分代码展示五、底部获取项目源码(9.9¥带走) 蛋糕商城系统 一、项目演示 蛋糕商城管理系统 二、项目介绍 系统角色 : 管理员、用户 一,管理员 管理员有…...

vue3父组件使用ref获取子组件的属性和方法
在vue3中父组件访问子组件中的属性和方法是需要借助于ref: 1.<script setup> 中定义响应式变量 例如: const demo1 ref(null) 2.在引入的子组件标签上绑定ref属性的值与定义的响应式变量同名( <demo1 ref"demo1"/>)。 父组件代码如下&…...

加入MongoDB AI创新者计划,携手MongoDB共同开创AI新纪元
加入MongoDB AI创新者计划! MongoDB对AI创新和初创企业的支持既全面又广泛!无论您是领先的AI初创企业还是刚刚起步,MongoDB Atlas都是支持您愿景的最佳平台。 AI 初创者计划The AI Startup Track AI初创者计划为早期初创企业提供专属福利&…...

3. CSS的色彩与背景
3.1 CSS3中的色彩 CSS3扩展了颜色的定义方式,使得开发者能够使用更多样化和灵活的颜色表达方式。这包括RGB、RGBA、HSL、HSLA等格式,以及支持透明度和渐变的特性。 3.1.1 颜色格式 十六进制颜色 十六进制颜色是最常用的颜色表示法,以#开头…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南
掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源…...

Video2X专业级AI视频增强实战指南:GPU加速无损放大的深度技术解析
Video2X专业级AI视频增强实战指南:GPU加速无损放大的深度技术解析 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trendi…...

KMS智能激活工具:如何一键永久激活Windows和Office的完整指南
KMS智能激活工具:如何一键永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题而烦恼吗?每次系统重装后都要…...

3步解锁网盘全速下载:LinkSwift开源助手深度使用指南
3步解锁网盘全速下载:LinkSwift开源助手深度使用指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

SISSO符号回归算法:革命性可解释AI模型的3大技术突破
SISSO符号回归算法:革命性可解释AI模型的3大技术突破 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO 在…...

知其雄,守其雌,为天下谿,在 SAP Fiori Elements 开发里修一条能承载业务之水的溪谷
老子《道德经》第二十八章说,知其雄,守其雌,为天下谿。完整语境里,这句话后面还接着,为天下谿,常德不离,复归于婴儿。中国哲学书电子化计划收录的《道德经》第二十八章文本,也把这组句子放在知其白、守其黑,知其荣、守其辱这一连串对照之中,可见老子并不是简单赞美柔…...
)
Windows 10/11 保姆级教程:手把手教你安装配置人大金仓KingbaseES V8R6(附授权文件处理)
Windows 10/11 深度实战:人大金仓KingbaseES V8R6全流程配置指南 在国产数据库生态快速发展的今天,人大金仓KingbaseES作为一款成熟稳定的关系型数据库,正获得越来越多开发者的青睐。不同于简单的安装说明,本文将带你深入理解每个…...