Python Beautiful Soup 使用详解

大家好,在网络爬虫和数据抓取的领域中,Beautiful Soup 是一个备受推崇的 Python 库,它提供了强大而灵活的工具,帮助开发者轻松地解析 HTML 和 XML 文档,并从中提取所需的数据。本文将深入探讨 Beautiful Soup 的使用方法和各种功能,希望能给大家带来一些帮助。
一、Beautiful Soup介绍
Beautiful Soup 是一个 Python 库,用于解析 HTML 和 XML 文档,并提供简单而直观的 API 来遍历文档树、搜索元素、提取内容等。它的名字取自于《爱丽丝梦游仙境》中的一段描写:“来吧,让我们到美丽的汤中一起吃面包吧!”正如这句话所暗示的那样,Beautiful Soup 让我们可以轻松地“吃掉”网页中的内容。
应用场景:
-
网络爬虫和数据抓取:Beautiful Soup 可以轻松地解析网页 HTML 或 XML 文档,并从中提取所需的数据,用于构建网络爬虫和进行数据抓取。
-
数据分析和挖掘:通过解析网页中的结构化数据,Beautiful Soup 可以帮助开发者进行数据分析和挖掘,发现数据之间的关系和规律。
-
网页内容提取:Beautiful Soup 可以提取网页中的各种内容,包括文本、链接、图片、表格等,用于构建内容提取系统和网页分析工具。
-
自动化测试:Beautiful Soup 可以用于自动化测试框架中,帮助测试人员解析网页内容、验证数据正确性,进行网页元素抓取等操作。
-
网页数据转换:通过解析网页内容,Beautiful Soup 可以将网页数据转换为其他格式,如 JSON、CSV 等,用于数据导出和数据转换。
优点:
-
简单易用:Beautiful Soup 提供了简单而直观的 API,易于学习和使用,不需要深入了解 HTML 和 XML 的结构。
-
功能丰富:Beautiful Soup 支持解析 HTML 和 XML 文档、文档树遍历、元素搜索、内容提取等功能,满足各种数据抓取和分析需求。
-
解析速度快:使用第三方解析器(如 lxml)可以提高解析速度,适用于大规模数据抓取和分析。
-
灵活性强:Beautiful Soup 支持多种解析器和定制化配置,可以根据具体需求进行灵活选择和调整。
缺点:
-
解析效率低:相比于一些专门的解析库(如 scrapy),Beautiful Soup 的解析效率相对较低,不适合处理大规模的数据抓取任务。
-
不支持异步解析:Beautiful Soup 不支持异步解析,无法充分利用异步编程模型的优势,可能影响程序的性能和并发能力。
-
功能相对有限:虽然 Beautiful Soup 提供了丰富的功能和 API,但相比于一些专门的数据分析工具(如 pandas),其功能相对有限,不适合进行复杂的数据处理和分析。
总的来说,Beautiful Soup 是一个功能强大、简单易用的 HTML 和 XML 解析库,适用于各种数据抓取和数据分析场景,但在处理大规模数据和需要高性能的场景下可能存在一些限制。
二、安装 Beautiful Soup
可以使用 pip 命令来安装 Beautiful Soup:
pip install beautifulsoup4
三、解析器
解析器是 Beautiful Soup 中用于解析 HTML 或 XML 文档的核心组件。Beautiful Soup 支持多种解析器,包括 Python 标准库的解析器以及第三方解析器,如 lxml 和 html5lib。每种解析器都有其特点和适用场景,可以根据自己的需求选择合适的解析器。
1、Python 标准库解析器(html.parser)
Python 标准库中的 html.parser 是一个基于 Python 实现的简单解析器,速度适中,解析速度不如 lxml,但通常足够应付一般的解析任务。它不需要安装额外的库,是 Beautiful Soup 的默认解析器。
from bs4 import BeautifulSoup# 使用 Python 标准库解析器
soup = BeautifulSoup(html_doc, 'html.parser')
2、第三方解析器(lxml)
lxml 是一个非常快速且功能强大的 XML 解析器,它基于 libxml2 和 libxslt 库,支持 XPath 查询和 CSS 选择器,解析速度比 Python 标准库的解析器更快,通常推荐在性能要求较高的场景中使用。
from bs4 import BeautifulSoup# 使用 lxml 解析器
soup = BeautifulSoup(html_doc, 'lxml')
3、第三方解析器(html5lib)
html5lib 是一个基于 HTML5 规范的解析器,它会根据 HTML5 规范解析文档,支持最新的 HTML5 元素和属性,解析结果更加准确和稳定。但是,html5lib 的解析速度比较慢,通常在需要最高准确性和稳定性的情况下使用。
from bs4 import BeautifulSoup# 使用 html5lib 解析器
soup = BeautifulSoup(html_doc, 'html5lib')
4、如何选择解析器
我们在选择解析器时,需要考虑解析速度、内存占用、准确性和稳定性等因素。一般来说,如果对解析速度要求较高,可以选择 lxml 解析器;如果对准确性和稳定性要求较高,可以选择 html5lib 解析器;如果只是进行简单的数据抓取,可以使用 Python 标准库解析器。
四、文档树遍历
文档树遍历是 Beautiful Soup 中常用的操作之一,它允许以树形结构遍历 HTML 或 XML 文档,访问文档中的各个节点、子节点、父节点等。
1、访问节点
文档树中的每个元素都是一个节点,可以通过直接访问节点来获取元素的标签名、属性等信息。
# 获取文档树的根节点
root = soup.html# 获取节点的标签名
print("Tag name:", root.name)# 获取节点的属性
print("Attributes:", root.attrs)
2、遍历子节点
可以使用 .children 属性来遍历节点的子节点,它返回一个生成器,用于逐个访问子节点。
# 遍历子节点
for child in root.children:print(child)
3、遍历子孙节点
可以使用 .descendants 属性来遍历节点的所有子孙节点,包括子节点、子节点的子节点等。
# 遍历子孙节点
for descendant in root.descendants:print(descendant)
4、访问父节点和祖先节点
可以使用 .parent 属性来访问节点的父节点,使用 .parents 属性来遍历节点的所有祖先节点。
# 访问父节点
parent = root.parent# 遍历祖先节点
for ancestor in root.parents:print(ancestor)
5、查找兄弟节点
可以使用 .next_sibling 和 .previous_sibling 属性来访问节点的下一个兄弟节点和上一个兄弟节点。
# 访问下一个兄弟节点
next_sibling = root.next_sibling# 访问上一个兄弟节点
previous_sibling = root.previous_sibling
五、搜索元素
搜索元素是 Beautiful Soup 中非常常用的功能之一,它允许根据特定的条件来查找文档中的元素,并提取所需的内容。
1、使用标签名搜索
可以使用标签名来搜索文档中的元素,通过指定标签名,可以获取所有匹配的元素。
# 使用标签名搜索
soup.find_all('div') # 查找所有 div 元素
2、使用 CSS 类名搜索
可以使用 CSS 类名来搜索文档中的元素,通过指定类名,可以获取所有具有指定类名的元素。
# 使用 CSS 类名搜索
soup.find_all(class_='class-name') # 查找所有具有指定类名的元素
3、使用 id 搜索
可以使用 id 来搜索文档中的元素,通过指定 id,可以获取具有指定 id 的元素。
# 使用 id 搜索
soup.find_all(id='content') # 查找具有指定 id 的元素
4、使用正则表达式搜索
Beautiful Soup 还支持使用正则表达式来搜索文档中的元素,通过指定正则表达式,可以匹配符合条件的元素。
import re# 使用正则表达式搜索
soup.find_all(re.compile('^b')) # 查找所有以 'b' 开头的元素
5、搜索嵌套元素
可以通过在搜索方法中传入多个条件来搜索嵌套元素,这样可以更精确地定位到目标元素。
# 搜索嵌套元素
soup.find_all('div', class_='class-name') # 查找所有 class 为 class-name 的 div 元素
6、限制搜索结果数量
可以通过 limit 参数来限制搜索结果的数量,这样可以节省内存和提高搜索速度。
# 限制搜索结果数量
soup.find_all('a', limit=10) # 查找前 10 个 a 元素
六、提取内容
提取内容是 Beautiful Soup 中的核心功能之一,它允许从 HTML 或 XML 文档中提取出所需的信息和内容。
1、提取文本内容
可以使用 .get_text() 方法来提取元素的文本内容,这将返回元素及其子孙节点中的所有文本内容,并将它们合并为一个字符串。
# 提取文本内容
text_content = soup.get_text()
print(text_content)
2、提取链接
可以使用 .get('href') 方法来提取链接元素(如 <a> 标签)的链接地址。
# 提取链接
for link in soup.find_all('a'):print(link.get('href'))
3、提取图片链接
可以使用 .get('src') 方法来提取图片元素(如 <img> 标签)的链接地址。
# 提取图片链接
for img in soup.find_all('img'):print(img.get('src'))
4、提取属性值
可以使用 .get() 方法来提取元素的任意属性值,包括标签的 class、id 等属性。
# 提取属性值
for element in soup.find_all('div'):print(element.get('class'))
5、提取特定标签的内容
可以通过搜索特定的标签来提取其内容,例如提取所有 <p> 标签的文本内容。
# 提取特定标签的内容
for paragraph in soup.find_all('p'):print(paragraph.get_text())
6、提取表格内容
可以通过搜索 <table> 标签并遍历其中的 <tr> 和 <td> 标签来提取表格中的内容。
# 提取表格内容
for table in soup.find_all('table'):for row in table.find_all('tr'):for cell in row.find_all('td'):print(cell.get_text())
七、修改文档
修改文档是 Beautiful Soup 中的重要功能之一,它允许对解析后的文档树进行各种修改操作,包括添加、删除、修改元素和属性等。
1、添加元素
可以使用 .new_tag() 方法创建一个新的元素,然后使用 .append() 方法将其添加到文档中。
# 创建新的元素
new_tag = soup.new_tag('div')
new_tag.string = 'New content'# 将新元素添加到文档中
soup.body.append(new_tag)
2、删除元素
可以使用 .decompose() 方法来删除文档中的元素,将其从文档树中移除。
# 查找需要删除的元素
tag_to_delete = soup.find(id='content')# 删除元素
tag_to_delete.decompose()
3、修改属性
可以通过修改元素的属性来改变元素的外观和行为,例如修改元素的 class、id 等属性。
# 查找需要修改属性的元素
tag_to_modify = soup.find('a')# 修改属性
tag_to_modify['href'] = 'http://www.example.com'
4、替换元素
可以使用 .replace_with() 方法来替换文档中的元素,将一个元素替换为另一个元素。
# 创建新的元素
new_tag = soup.new_tag('span')
new_tag.string = 'Replacement content'# 查找需要替换的元素
tag_to_replace = soup.find(id='old-content')# 替换元素
tag_to_replace.replace_with(new_tag)
5、插入元素
可以使用 .insert() 方法在文档中插入元素,将新元素插入到指定位置。
# 创建新的元素
new_tag = soup.new_tag('div')
new_tag.string = 'Inserted content'# 查找需要插入元素的位置
target_tag = soup.find(class_='container')# 插入元素
target_tag.insert(0, new_tag) # 在指定位置插入元素
八、示例
from bs4 import BeautifulSoup# HTML 文档内容
html_doc = """
<html>
<head><title>Example HTML Page</title>
</head>
<body><h1 class="heading">Beautiful Soup Example</h1><p>Welcome to <strong>Beautiful Soup</strong>!</p><a href="http://www.example.com">Example Link</a><a href="http://www.example.com/page1">Page 1</a><a href="http://www.example.com/page2">Page 2</a><div id="content"><p>This is some content.</p></div>
</body>
</html>
"""# 创建 Beautiful Soup 对象并指定解析器
soup = BeautifulSoup(html_doc, 'html.parser')# 1. 解析器
print("解析器:", soup.builder.NAME)# 2. 文档树遍历
print("\n文档树遍历:")
# 遍历子节点
for child in soup.body.children:print(child)
# 遍历子孙节点
for descendant in soup.body.descendants:print(descendant)# 3. 搜索元素
print("\n搜索元素:")
# 使用标签名搜索
heading = soup.find('h1')
print("标签名:", heading.name)
# 使用 CSS 类名搜索
heading = soup.find(class_='heading')
print("CSS 类名:", heading.name)
# 使用 id 搜索
content_div = soup.find(id='content')
print("id:", content_div.name)
# 使用正则表达式搜索
for tag in soup.find_all(re.compile('^a')):print("正则表达式:", tag.name)# 4. 提取内容
print("\n提取内容:")
# 提取文本内容
text_content = soup.get_text()
print("文本内容:", text_content)
# 提取链接
for link in soup.find_all('a'):print("链接:", link.get_text(), link.get('href'))
# 提取图片链接
for img in soup.find_all('img'):print("图片链接:", img.get('src'))# 5. 修改文档
print("\n修改文档:")
# 添加元素
new_tag = soup.new_tag('div')
new_tag.string = 'New content'
soup.body.append(new_tag)
print("添加元素后的文档:", soup)
# 删除元素
tag_to_delete = soup.find(id='content')
tag_to_delete.decompose()
print("删除元素后的文档:", soup)
# 修改属性
heading = soup.find('h1')
heading['class'] = 'header'
print("修改属性后的文档:", soup)
# 替换元素
new_tag = soup.new_tag('span')
new_tag.string = 'Replacement content'
tag_to_replace = soup.find(id='old-content')
tag_to_replace.replace_with(new_tag)
print("替换元素后的文档:", soup)
# 插入元素
new_tag = soup.new_tag('div')
new_tag.string = 'Inserted content'
target_tag = soup.find(class_='container')
target_tag.insert(0, new_tag)
print("插入元素后的文档:", soup)
这个示例代码涵盖了 Beautiful Soup 的解析、搜索、提取、修改等功能,包括了解析器的选择、文档树的遍历、搜索元素、提取内容和修改文档等方面。大家可以根据需要修改示例代码,并尝试在实际项目中应用 Beautiful Soup 进行数据抓取和分析。
相关文章:
Python Beautiful Soup 使用详解
大家好,在网络爬虫和数据抓取的领域中,Beautiful Soup 是一个备受推崇的 Python 库,它提供了强大而灵活的工具,帮助开发者轻松地解析 HTML 和 XML 文档,并从中提取所需的数据。本文将深入探讨 Beautiful Soup 的使用方…...
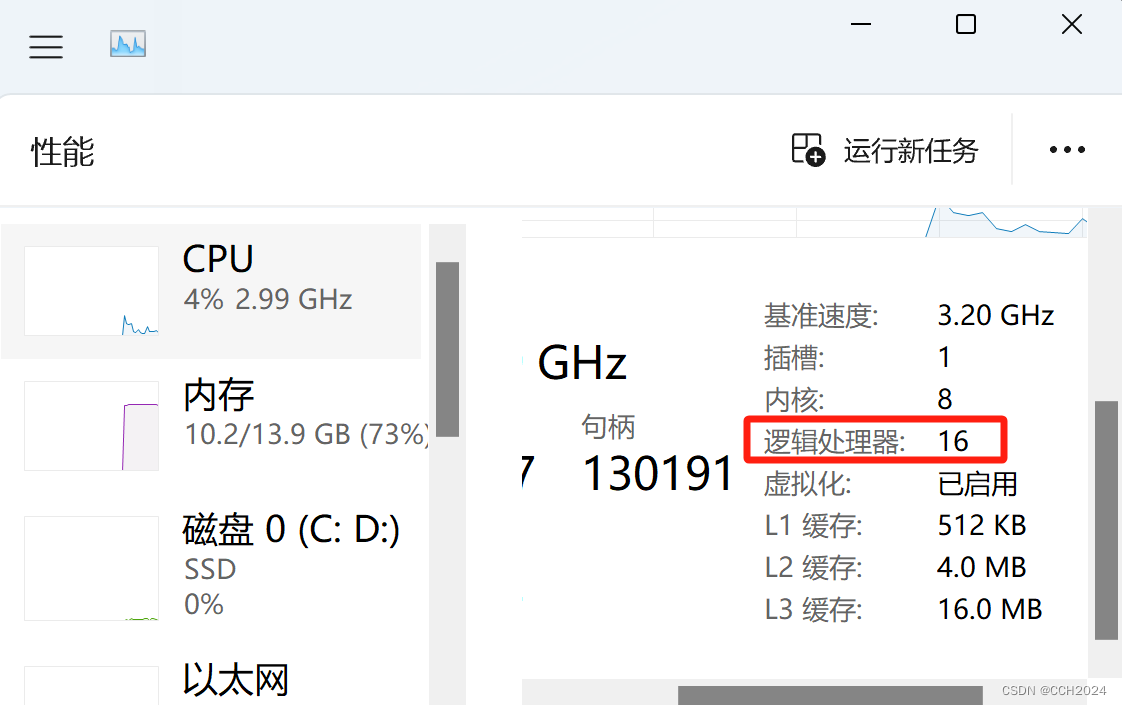
Java进阶学习笔记29——Math、System、Runtime
Math: 代表的是数学,是一个工具类,里面提供的都是对数据进行操作的一些静态方法。 示例代码: package cn.ensourced1_math;public class MathTest {public static void main(String[] args) {// 目标:了解Math类提供…...
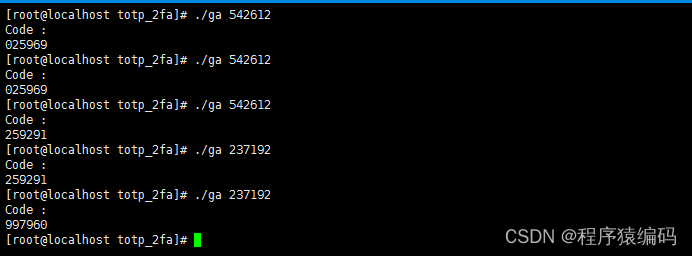
TOTP 算法实现:双因素认证的基石(C/C++代码实现)
双因素认证(Two-Factor Authentication, 2FA)扮演着至关重要的角色。它像是一道额外的防线,确保即便密码被窃取,不法分子也难以轻易突破。在众多双因素认证技术中,基于时间的一次性密码(Time-Based One-Tim…...

aws eks理解和使用podidentity为pod授权
参考链接 https://www.amazonaws.cn/new/2024/amazon-eks-introduces-eks-pod-identity/https://aws.amazon.com/cn/blogs/aws/amazon-eks-pod-identity-simplifies-iam-permissions-for-applications-on-amazon-eks-clusters/ 先决条件 集群版本需要符合要求,如果…...
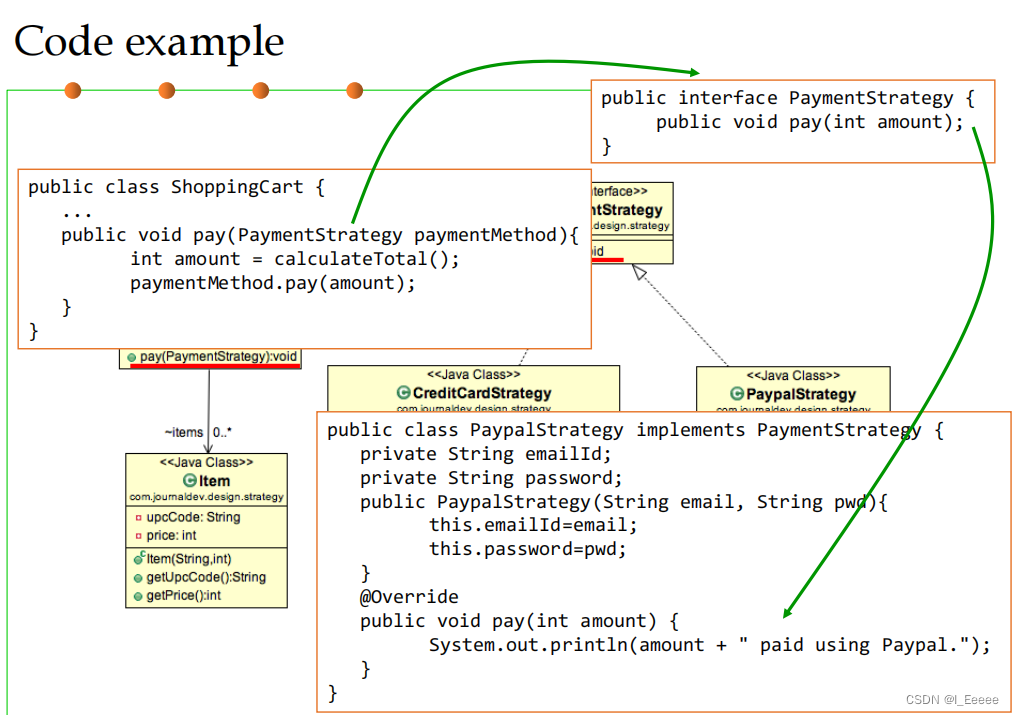
面向可复用性和可维护性的设计模式 课程学习总结
什么是设计模式 设计模式:在软件设计中给定上下文中常见问题的通用的、可重用的解决方案。 设计模式分类 1. 创建型模式——Creational patterns 关注对象创建的过程 1.1 工厂方法模式 定义用于创建对象的接口,但让子类决定要实例化哪个类。工厂方…...

修复谷歌 AdSense 的 Ads.Txt 无效的有收益损失风险提示
明月的 AdSense 账号后台一直都有“有收益损失风险 - 您需要纠正 ads.txt 文件存在的一些问题,以免严重影响您的收入。”的提示长达一年多了,这次重新开始投放谷歌 AdSense 广告后感觉需要解决掉这个问题了,因为已经全站使用了 CloudFlare&am…...

使用向量叉乘,来计算一个点到一条线的距离
1. 使用向量叉乘,来计算一个点到一条线的距离 如果说一条线段的两个端点坐标分别是,A,B点,到线段外一点P的距离。 我们可以把,这三个点连接起来,得到一个三角形,此时的步骤就是这样的 计算这个…...

学习笔记——交通安全分析02
目录 前言 当天学习笔记整理 绪论 结束语 前言 #随着上一轮SPSS学习完成之后,本人又开始了新教材《交通安全分析》的学习 #整理过程不易,喜欢UP就点个免费的关注趴 当天学习笔记整理 绪论 美国在道路设施安全改善过程中,形成了数据基…...

pytest-sugar插件:对自动化测试用例加入进度条
摘要 在自动化测试过程中,测试进度的可视化对于开发者和测试工程师来说非常重要。本文将介绍如何使用pytest-sugar插件来为pytest测试用例添加进度条,从而提升测试的可读性和用户体验。 1. 引言 自动化测试是软件开发过程中不可或缺的一部分ÿ…...
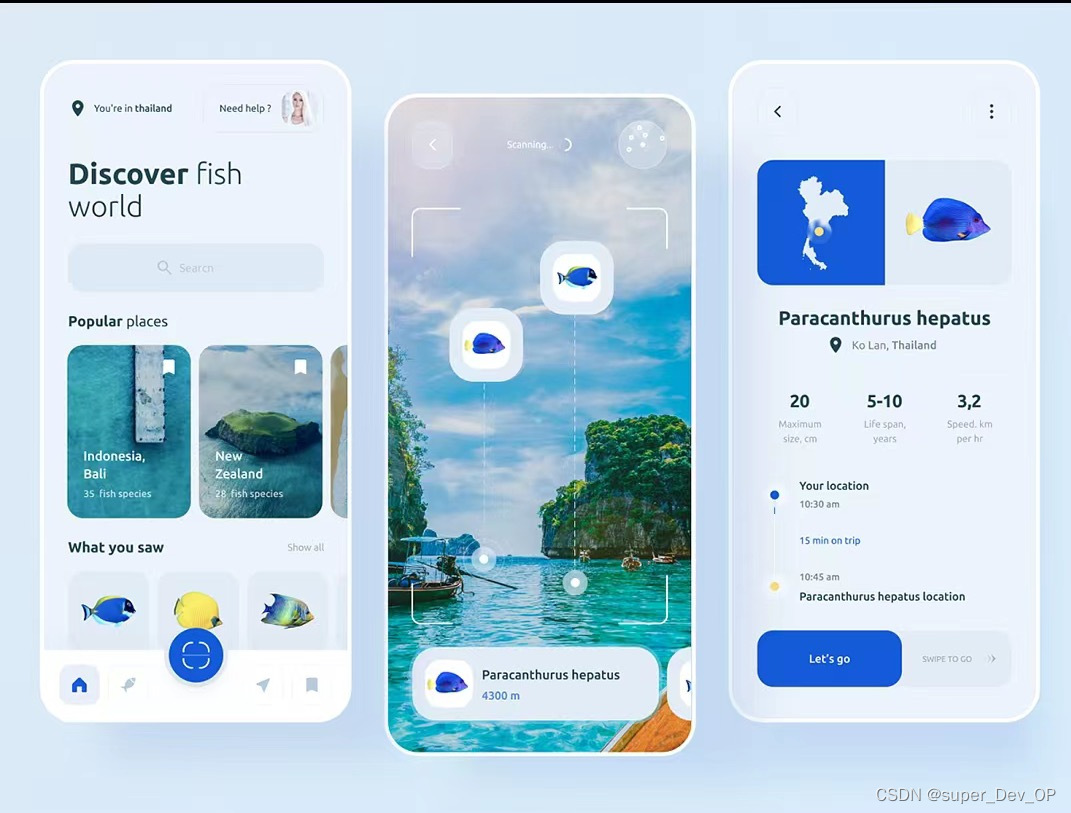
AI大模型的口语练习APP
开发一个使用第三方大模型的口语练习APP涉及多个步骤,从需求分析到部署上线。以下是详细的开发流程和关键步骤,通过系统化的流程和合适的技术选型,可以有效地开发出一个功能丰富、用户体验良好的口语练习APP。北京木奇移动技术有限公司&#…...

Elasticsearch 详细介绍和经典应用
Elasticsearch是一个开源的分布式搜索和分析引擎,它建立在Apache Lucene搜索引擎库之上,提供了一个分布式、多租户的全文搜索引擎,能够实时地存储、检索和分析大规模的数据。以下是关于Elasticsearch的详细介绍和经典应用: 详细介…...

GEC210编译环境搭建
一、下载编译工具链 下载:点击跳转 二、解压到 /usr/local/arm 目录 sudo mv gec210.zip /usr/local/arm cd /usr/local/arm sudo unzip gec210.zip 三、添加到环境变量 PATH/usr/local/arm/arm-cortex_a8-linux-gnueabi-4.7.3/bin:$PATH 四、测试验证 在终端…...
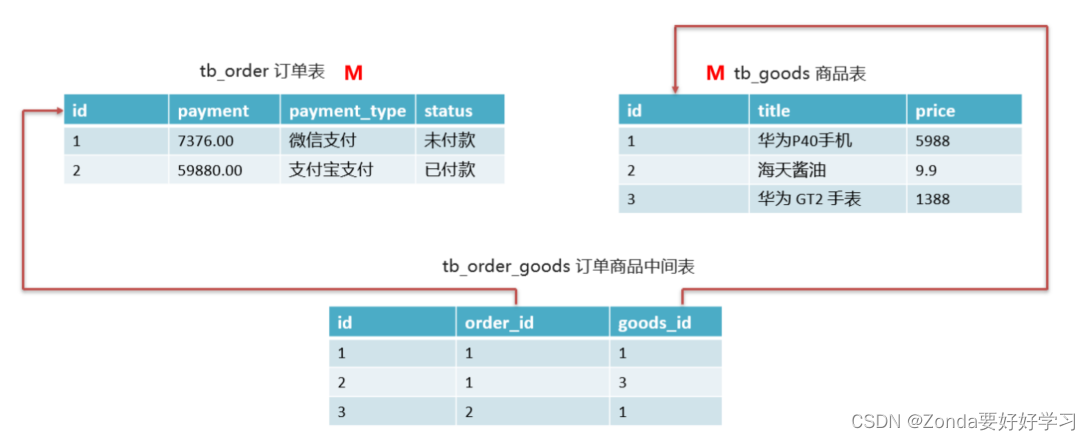
Mysql中表之间的关系
表之间的关系 一对一、多对一(其实就是主从关系,在从表中设置一个外键关联上主表)、多对多关系(需要一个中间表,设置两个外键,分别关联到两个表的主键) 比如订单和商品之间:一个订单…...

文心智能体大赛:百度文心智能体平台初体验
写在前面 博文内容涉及:文心智能体大赛:文心智能体初体验理解不足小伙伴帮忙指正 😃,生活加油 我徒然忘记了热闹,却来不及悟透真正的清冷(《四喜忧国》) 前言 徒然忘记了热闹,却来不及悟透真正的清冷(《四喜忧国》),在…...
AI数据面临枯竭
Alexandr Wang:前沿研究领域需要大量当前不存在的数据,未来会受到这个限制 Alexandr Wang 强调了 AI 领域面临的数据问题。 他指出,前沿研究领域(如多模态、多语言、专家链式思维和企业工作流)需要大量当前不存在的数…...

2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(中):订阅智能体OSS实现
传送门: 《2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(上):MetaGPT安装、单智能体开发》《2024.5组队学习——MetaGPT(0.8.1)智能体理论与实战(下)&…...

LoadBalancer
一、手写随机负载均衡 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId> </dependency><!--引入nacos discovery--> <dependency><groupId>com…...

【栈】Leetcode 71. 简化路径【中等】
简化路径 给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/’ 开头),请你将其转化为更加简洁的规范路径。 在 Unix 风格的文件系统中,一个点(.)表示当前目录本身&am…...

简单操作一单利润500+,最新快手缺货赔付玩法,【找店教程+详细教程】
在如今快速变化的时代,寻找充满创新的收入来源已经成为了一种趋势。这不仅是为了实现财务的自由,更是为了在生活中拥有更多的选择权。一项革新的实践——利用手机进行快手缺货赔付单号的操作,已经成为许多人稳定“下车”的一个新途径。 据了…...

【软件设计师】先导
一、考试科目: 上午:计算机与软件工程知识,考试时间150min,75空单选题(不一定一题一空) 下午:软件设计,考试时间150分钟,问答题,6道只做5大题(前四…...

完整解决方案:PL2303 Windows 10驱动快速安装指南
完整解决方案:PL2303 Windows 10驱动快速安装指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 如果你正在Windows 10系统上使用PL-2303HXA或PL-2303XA芯…...

深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构
深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构 【免费下载链接】zenodo_get Zenodo_get: Downloader for Zenodo records 项目地址: https://gitcode.com/gh_mirrors/ze/zenodo_get 在科研数据管理领域,高效的数据下载工具…...

C语言--day19
第十章 内存管理当./a.out 运行起来后,系统会给a.out分配一段内存区域1、code ,存放编写好的c语言代码。 只读特性,在运行期间不能修改2、data 数据段。 存储全局变量,和被static 修改的变量细分:data 数据段ÿ…...

终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签
终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 还在为满屏混乱的Chrome书…...

收藏|2026 新版大模型入行指南!风口红利期程序员小白均可入局
2026年人工智能行业发展势头迅猛,已然迈入全民争相布局的高速发展阶段。多模态技术持续更新升级,大模型各类商业化项目不断落地投产,市场专业人才缺口不断拉大,对应岗位薪酬待遇也迎来大幅上涨。 不管是毫无技术基础、打算从零起步…...

Python调用WebAssembly破解APP签名算法实战
1. 这不是“调用JS”,而是把WebAssembly当真实CPU来调试你有没有遇到过这样的情况:抓包看到某资讯APP的请求里,sign参数像雪花一样每秒变一个,长度固定32位,全是小写字母加数字;Fiddler里点开响应ÿ…...

SISSO符号回归算法:革命性可解释AI模型的3大技术突破
SISSO符号回归算法:革命性可解释AI模型的3大技术突破 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO 在…...

ComfyUI-Manager终极指南:如何快速安装和管理ComfyUI自定义节点
ComfyUI-Manager终极指南:如何快速安装和管理ComfyUI自定义节点 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

中文分词与词频统计全流程实战 | 全网独家复现,Python零基础落地篇 引入jieba分词优化+多策略词频统计,助力文本挖掘、舆情分析、学术研究高效落地
目录 一、核心前言(明确价值,避开踩坑) 1.1 实战意义 1.2 技术选型说明 1.3 前置准备(零基础必看) 二、核心原理(极简理解,无需深入) 2.1 中文分词原理 2.2 词频统计原理 三、全流程代码实现(零基础可复制,全程注释) 3.1 工程化目录结构(必看,避免路径错…...

终极魔兽争霸III优化指南:如何使用WarcraftHelper提升游戏体验
终极魔兽争霸III优化指南:如何使用WarcraftHelper提升游戏体验 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专门为…...