python数据分析-CO2排放分析
导入所需要的package
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号数据清洗和读取数据
df = pd.read_csv("energy.csv")
df.shape
###展示数据前6行
df.head(6)# 删除特定的列 在数据中体现为 Unnamed: 0
df = df.drop(['Unnamed: 0'], axis=1)
df.head(6)
 ###重新命名列名称 即简化名称
###重新命名列名称 即简化名称
df.rename(columns={'Energy_type' : 'e_type', 'Energy_consumption' : 'e_con', 'Energy_production' : 'e_prod', 'Energy_intensity_per_capita' : 'ei_capita', 'Energy_intensity_by_GDP' : 'ei_gdp'}, inplace=True)df['e_type'] = df['e_type'].astype('category')df['e_type'] = df['e_type'].cat.rename_categories({'all_energy_types': 'all', 'natural_gas': 'nat_gas','petroleum_n_other_liquids': 'pet/oth','renewables_n_other': 'ren/oth'})df['e_type'] = df['e_type'].astype('object')df.info() ###对所以特征进行统计性描述
###对所以特征进行统计性描述
df.describe(include='all') ##得出每一种变量的总数
##得出每一种变量的总数
for var in df:print(f'{var}: {df[var].nunique()}')
###缺失值的处理
#先查看缺失值
for var in df:print(f'{var}: {df[var].isnull().sum()}')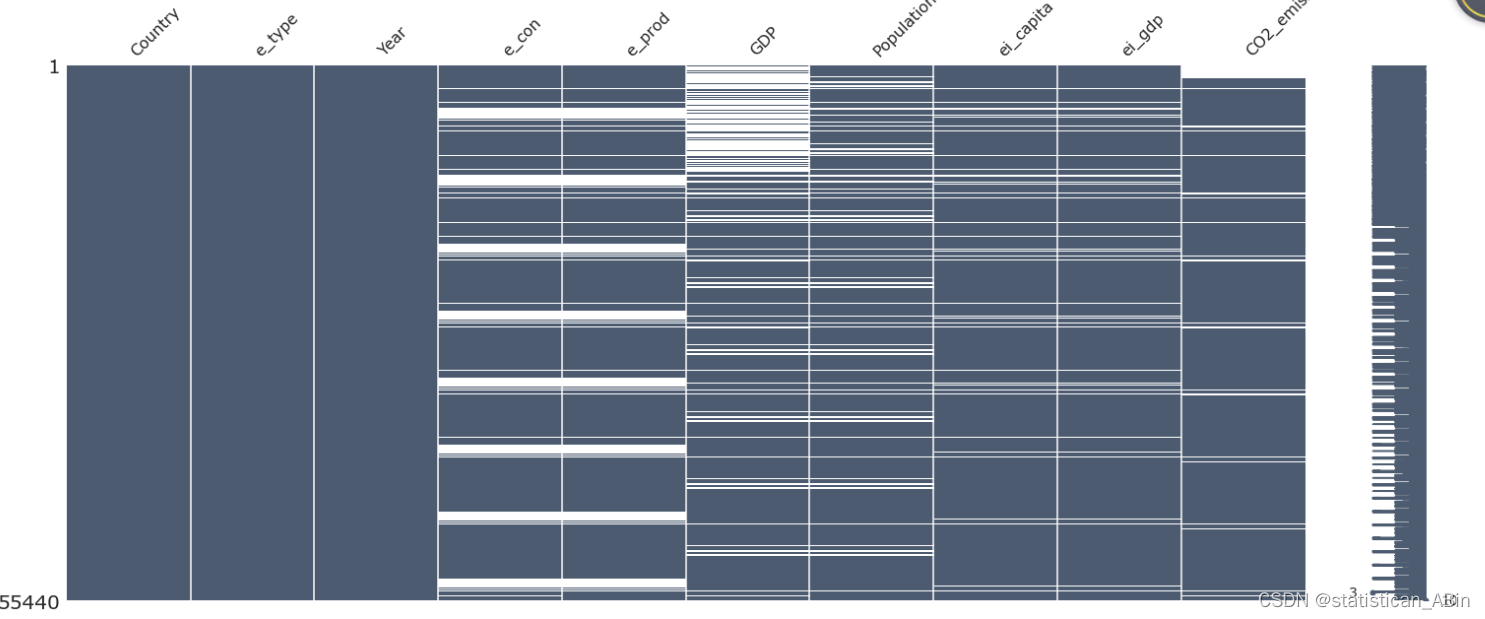 从上面可以看到有的特征变量有很多缺失值
从上面可以看到有的特征变量有很多缺失值
 由于大多数国家不消费或生产核能,因此缺少e_con和e_prod的许多价值,因此他们将其保留为Nan。我将添加 0 来代替这些
由于大多数国家不消费或生产核能,因此缺少e_con和e_prod的许多价值,因此他们将其保留为Nan。我将添加 0 来代替这些
nuclear = df[df['e_type']=='nuclear']temp_ecp = df[df['e_type']!='nuclear']# Replacing all Nan values of e_con and e_prod of e_type nuclear to 0
nuclear[['e_con', 'e_prod']] = nuclear[['e_con', 'e_prod']].replace(np.nan, 0)# Joining them back up
df = pd.concat([nuclear, temp_ecp]).sort_index()处理完之后再看,没有缺失值了
 现在可以开始查看数据了,可视化
现在可以开始查看数据了,可视化
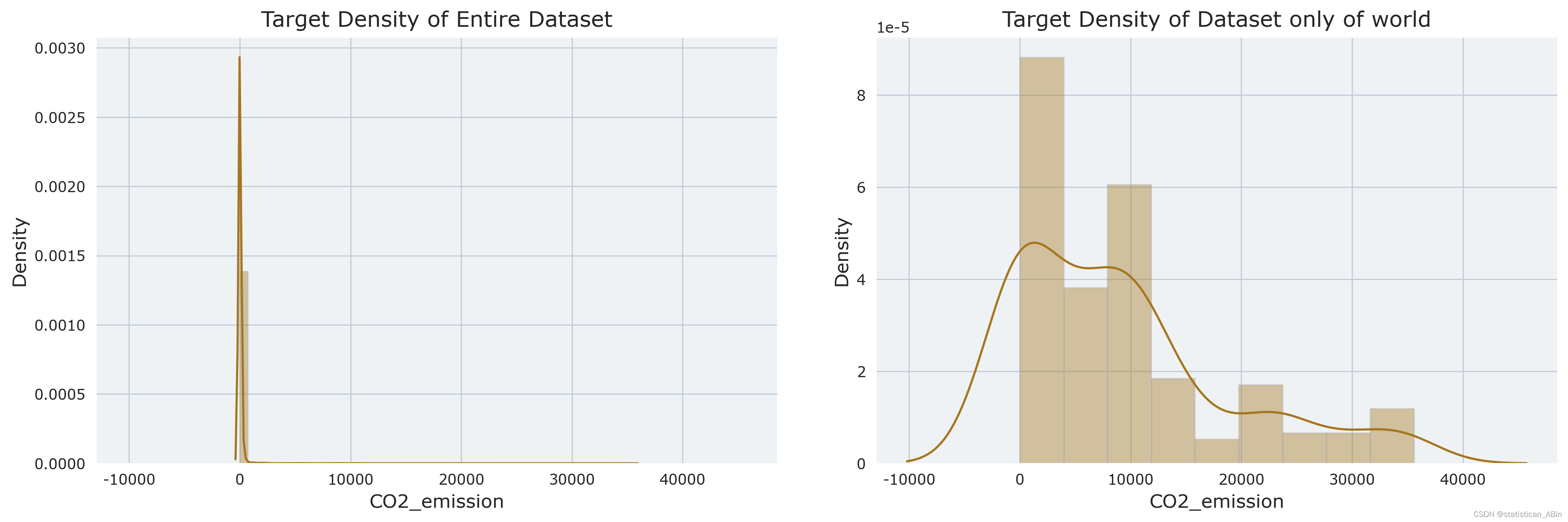

从上图可以看出分布高度右偏。
接下来查看能源类型分布
###画出其环形图 看其分布和占比情况
percent = temp_dist['CO2_emission']
labels= temp_dist['e_type']my_pie,_,_ = plt.pie(percent, radius = 2.2, labels=labels, autopct="%.1f%%")
plt.setp(my_pie, width=0.6, edgecolor='white')
plt.show()
从上图可以看出,所有能源都分布较为均匀
计算相关系数并画出其热力图

不同可视化分析
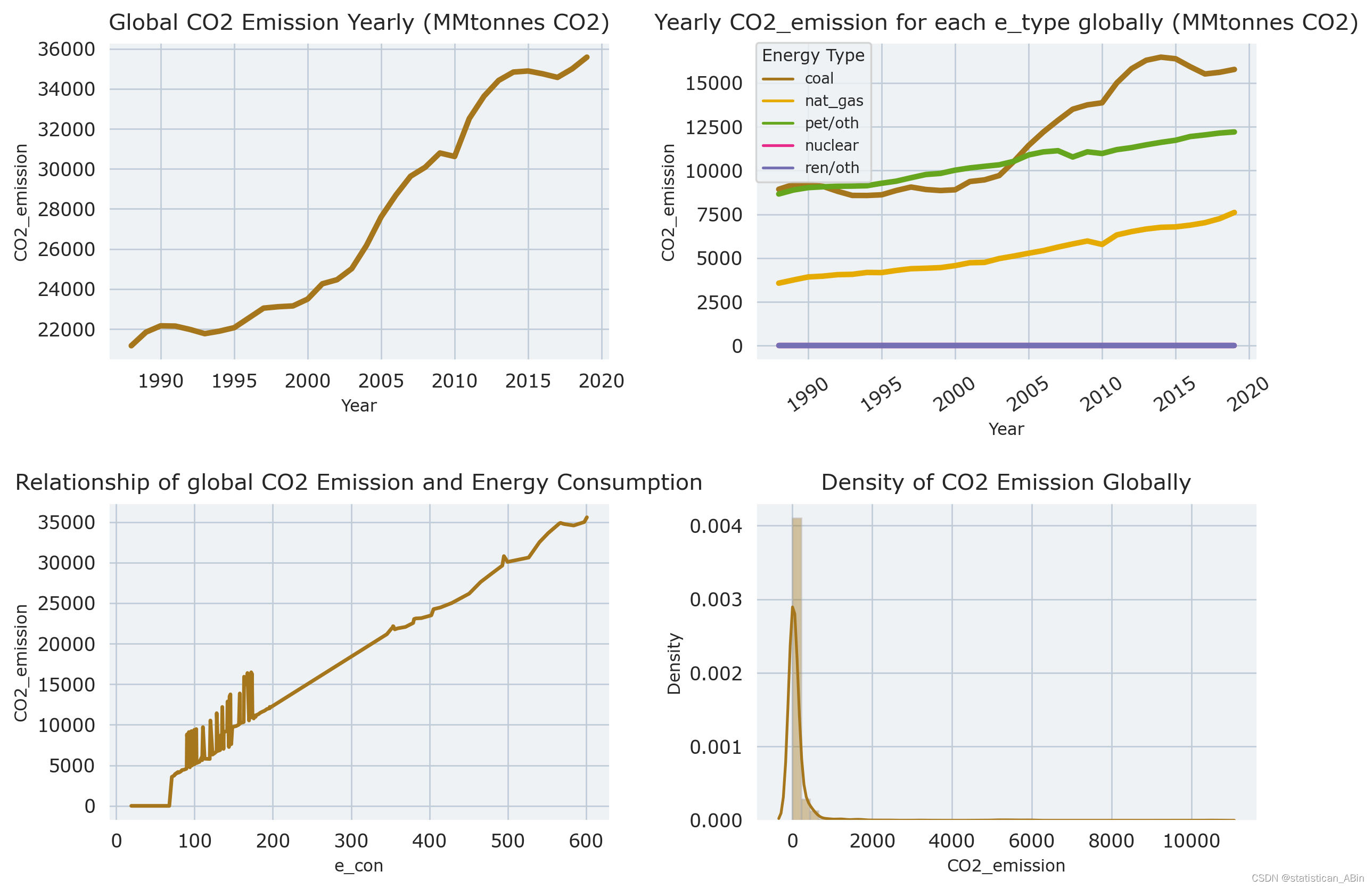
with plt.rc_context(rc = {'figure.dpi': 250, 'axes.labelsize': 9,'xtick.labelsize': 10, 'ytick.labelsize': 10,'legend.title_fontsize': 7, 'axes.titlesize': 12,'axes.titlepad': 7}):# Data with only the 'World' valuescd = df[df['Country']=='World']fig, ax = plt.subplots(2, 2, figsize = (10, 7), # constrained_layout = True,gridspec_kw = {'width_ratios': [3, 3], 'height_ratios': [3, 3]})ax_flat = ax.flatten()### 1st graphsns.lineplot(ax=ax_flat[0], data=cd[cd['e_type']=='all'],x='Year', y='CO2_emission', lw=3).set_title('Global CO2 Emission Yearly (MMtonnes CO2)')### 2nd graphsns.lineplot(ax=ax_flat[1], data=cd[cd['e_type']!='all'],x='Year',y='CO2_emission',hue='e_type',lw=3,).set_title('Yearly CO2_emission for each e_type globally (MMtonnes CO2)')ax_flat[1].legend(fontsize=8, title='Energy Type', title_fontsize=9, loc='upper left', borderaxespad=0)ax_flat[1].tick_params(axis='x', rotation=35)### 3rd graphsns.lineplot(ax=ax_flat[2], data=cd,x='e_con', y='CO2_emission', lw=2).set_title('Relationship of global CO2 Emission and Energy Consumption')### 4th graphfor_dist = df[df['Country']!='World'][df['e_type']=='all']sns.distplot(for_dist['CO2_emission'], ax=ax_flat[3]).set_title('Density of CO2 Emission Globally')plt.tight_layout(pad = 1)plt.show()# 前 6 个国家/地区的年度二氧化碳排放量
fig, ax = plt.subplots(2, 3, figsize = (20, 10))# Top 6 Countries
countries = temp_cd['Country'].head(6)# Average CO2 Emission each year for top 6 emiters
for idx, (country, axes) in enumerate(zip(countries, ax.flatten())):cd3 = df[df['Country']==country][df['e_type']=='all']temp_data = cd3.groupby(['Year'])['CO2_emission'].sum().reset_index().sort_values(by='CO2_emission',ascending=False)plot_ = sns.barplot(ax=axes, data=temp_data, x='Year', y='CO2_emission', palette="Reds_d")# Titleaxes.set_title(country)# Reducing Density of X-ticksfor ind, label in enumerate(plot_.get_xticklabels()):if ind % 4 == 0: # every 10th label is keptlabel.set_visible(True)else:label.set_visible(False)# Rotating X axisfor tick in axes.get_xticklabels():tick.set_rotation(45)### Removing empty figures
else:[axes.set_visible(False) for axes in ax.flatten()[idx + 1:]]plt.tight_layout(pad=0.4, w_pad=2, h_pad=2)
plt.show()
 # 在此期间,中国和印度的排放量增加了很多。
# 在此期间,中国和印度的排放量增加了很多。
#从这一时期开始到结束,二氧化碳排放量增加/减少幅度最大的国家
# 然后绘图
# Countries with biggest increase in CO2 emission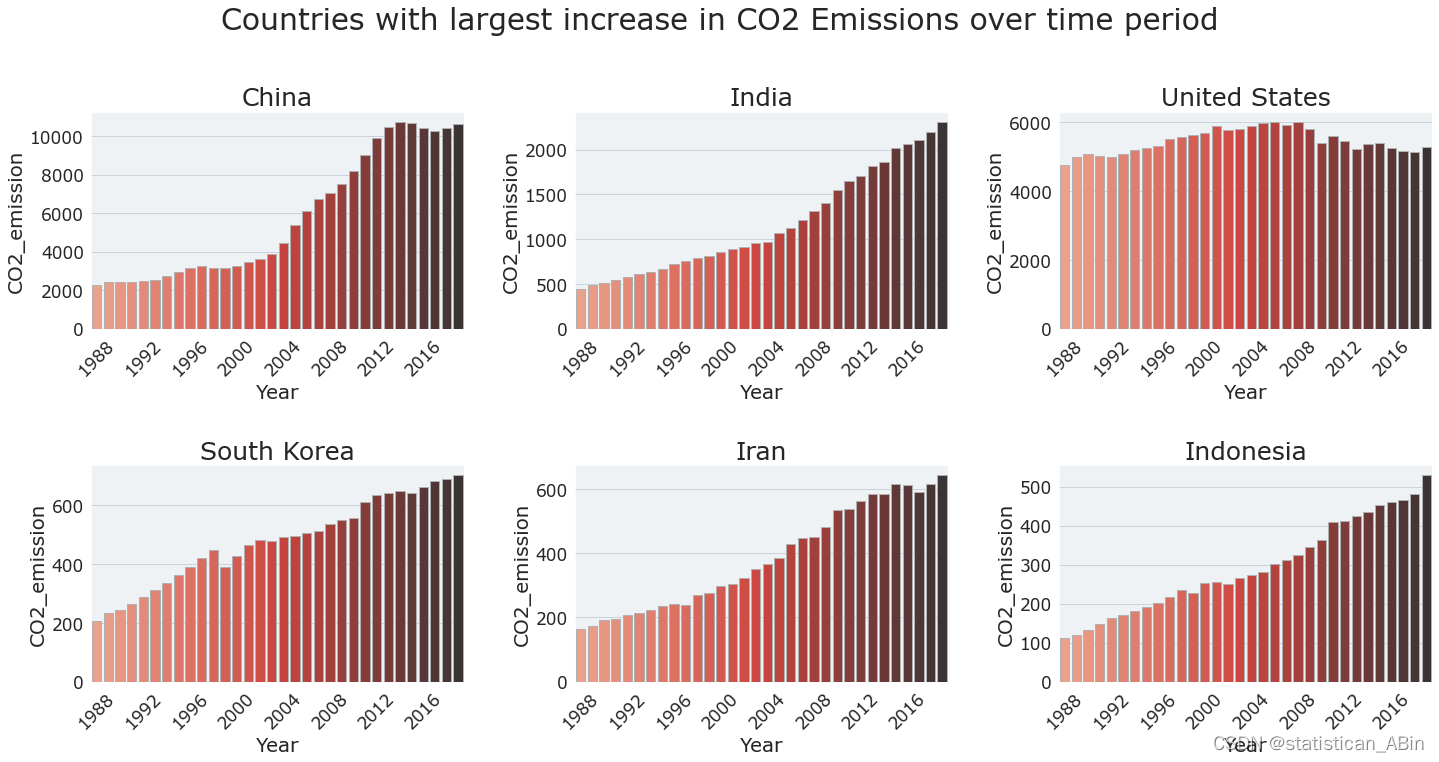
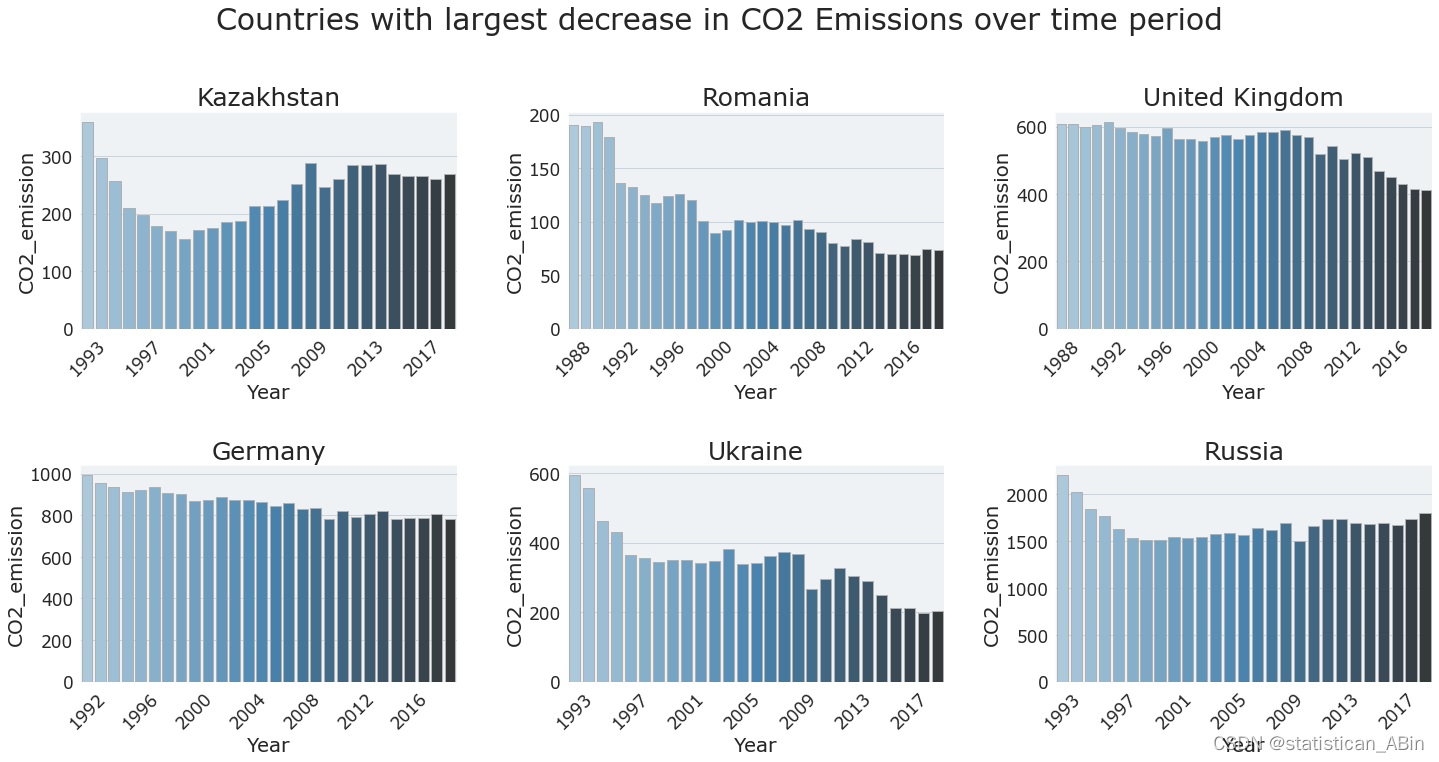
Countries with biggest decrease in CO2 emission
结论
关于CO2排放量的结论
1.在此期间,二氧化碳排放量一直在增加。
2.煤炭和石油/其他液体一直是这一时期的主要能源。
3.二氧化碳排放量平均每年增长1.71%,整个时期整体增长68.14%。
4.截至2019年,当年平均二氧化碳排放量为10.98(百万吨二氧化碳)。
5.在整个时期,二氧化碳排放量最大的国家是中国和美国,这两个国家的二氧化碳排放量几乎是其他国家的4倍或更多。
6.在此期间,中国和印度的二氧化碳排放量增加是其他所有国家中最多的。
7.在此期间,前苏联加盟共和国的二氧化碳排放量下降幅度最大,英国和德国的排放量也略有下降。
8.一般来说,人口越多,该国排放的二氧化碳就越多。
9.GDP越大,该国二氧化碳排放量越大。
10.一个国家的能源消耗越大,二氧化碳排放量就越大。
11.按人均能源强度的GDP计算的高或低能源强度并不一定能预测大量的二氧化碳排放量,但一般来说,它越低越好(节约的能量越多意味着二氧化碳排放量越少)。
代码和数据
创作不易,希望大家多多点赞收藏和评论!
相关文章:
python数据分析-CO2排放分析
导入所需要的package import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import datetime %matplotlib inline plt.rcParams[font.sans-serif] [KaiTi] #中文 plt.rcParams[axes.unicode_minus] False #负号 数据清洗…...

2024宝藏工具EasyRecovery数据恢复软件免费版本下载
在这个数字化的时代,数据已经成为我们生活中的重中之重。无论是工作中的重要文件,还是手机中珍贵的照片,我们都依赖着这些数据。然而,数据丢失的情况时有发生,可能是误删,可能是设备故障,更可能…...

【EventSource错误解决方案】设置Proxy后SSE发送的数据只在最后接收到一次,并且数据被合并
【EventSource错误解决方案】设置Proxy后SSE发送的数据只在最后接收到一次,并且数据被合并 出错描述 出错原因与解决方案 出错描述 SSE前后端一切正常,但是fetchEventSource 的onmessage回调函数只在所有流都发送完毕后,才会执行一次。 前…...
执行ipynb 文件。可以不依赖jupyter)
如何在linux命令行(终端)执行ipynb 文件。可以不依赖jupyter
1.安装 runipy pip install runipy 2.终端运行 runipy <YourNotebookName>.ipynb 在终端命令行执行shell脚本,(也可以在crontab 中执行): (base) [recommendapp-0-5-B-006 script]$ cat run1.sh #!/bin/bashcd /home/recom…...
基于YOLOv8的车牌检测与识别(CCPD2020数据集)
前言 本篇博客主要记录在autodl服务器中基于yolov8实现车牌检测与识别,以下记录实现全过程~ yolov8源码:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite 一、环境配置 …...
驱动开发之新字符设备驱动开发
1.前言 register_chrdev 和 unregister_chrdev 这两个函数是老版本驱动使用的函数,现在新的 字符设备驱动已经不再使用这两个函数,而是使用 Linux 内核推荐的新字符设备驱动 API 函数。 旧版本的接口使用,感兴趣可以看下面这个博客&#…...

【JMU】21编译原理期末笔记
本拖延症晚期患者不知不觉已经有半年没写博客了,天天不知道在忙什么。 乘着期末周前赶紧先把编译原理上传了,我记得我这科是86分,有点小遗憾没上90,但是总体不错。 链接:https://pan.baidu.com/s/1gO8pT7paHv1lkM_ZpkI…...

就业信息|基于SprinBoot+vue的就业信息管理系统(源码+数据库+文档)
就业信息管理系统 目录 基于SprinBootvue的就业信息管理系统 一、前言 二、系统设计 三、系统功能设计 1前台功能模块 2后台功能模块 4.2.1管理员功能 4.2.2学生功能 4.2.3企业功能 4.2.4导师功能 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设…...
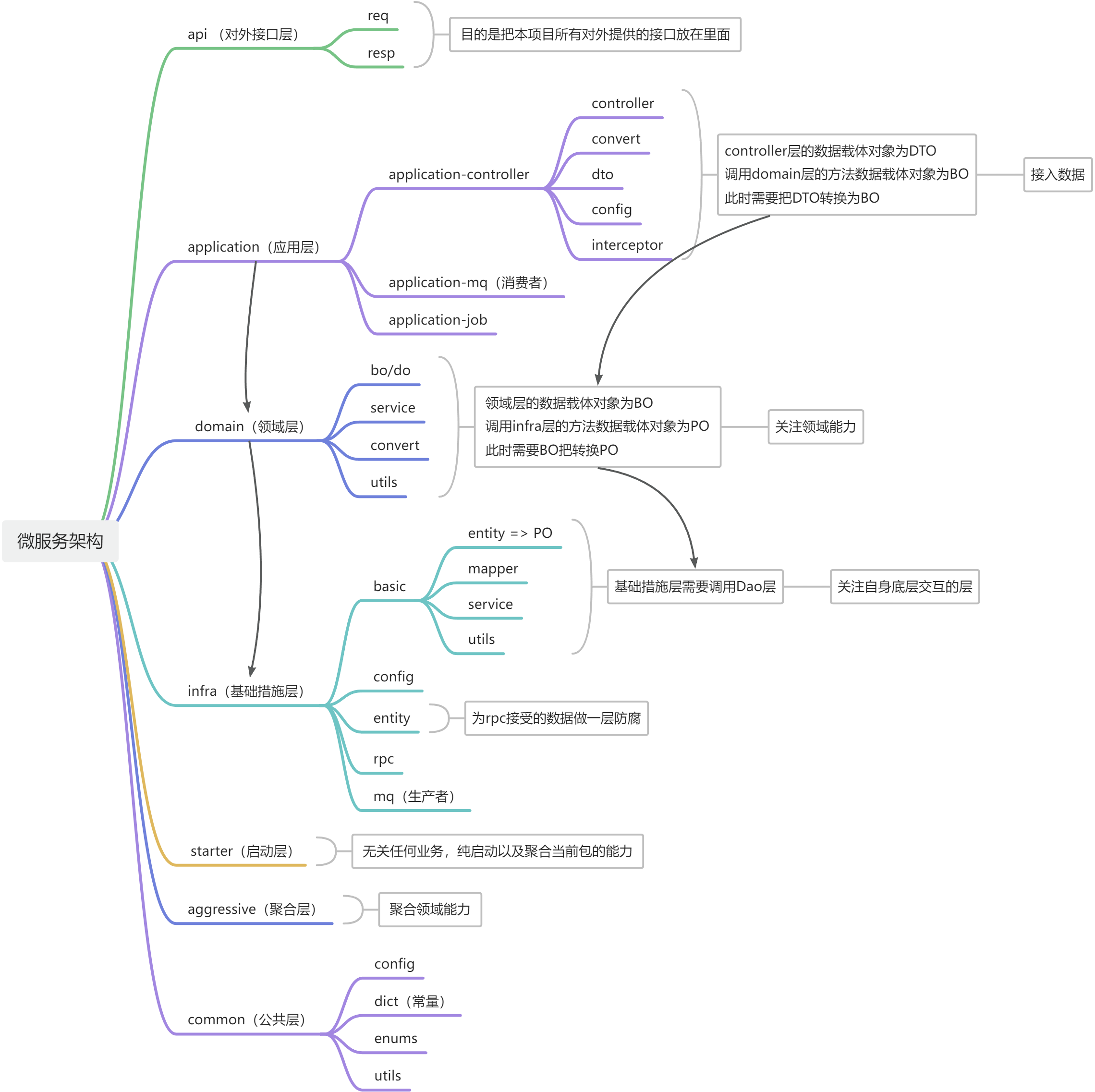
一.架构设计
架构采用 ddd 架构,不同于传统简单的三层的架构,其分层的思想对于大家日后都是很有好处的,会给大家的思想层级,提高很多。 传统的项目 现有的架构 采取ddd架构,给大家在复杂基础上简化保留精髓,一步步进行…...
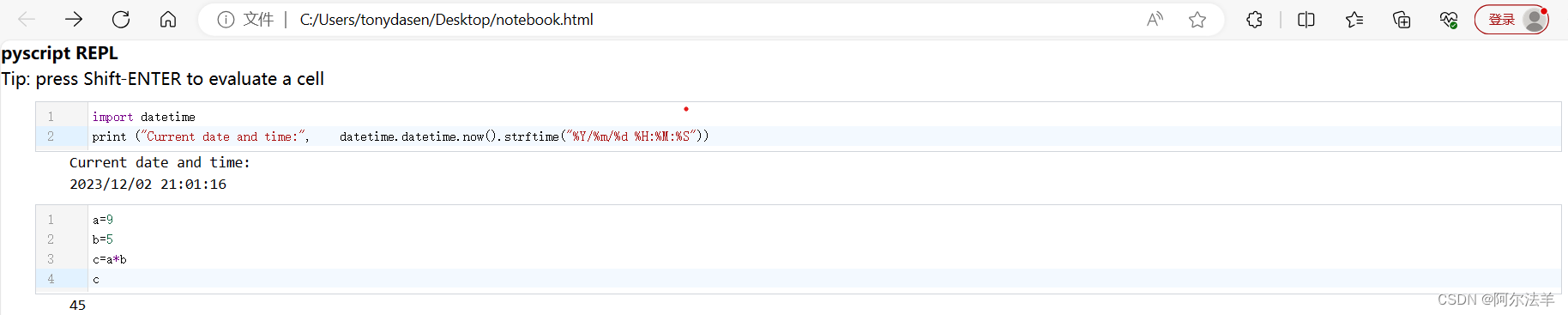
<学习笔记>从零开始自学Python-之-实用库篇(一)-pyscript
由Anaconda创建的PyScript是一项实验性的但很有前途的新技术,它使python运转时在支撑WebAssembly的浏览器中作为一种脚本言语运用。 每个现代常用的浏览器现在都支撑WebAssembly,这是许多言语(如C、C和Rust)能够编译的高速运转时…...
)
Vue项目中npm run build 卡住不执行的几种情况(实战版)
方法一 一:比较常见是镜像导致的原因 我们可以找到build/check-versions文件 将这段代码注释,重新运行就可以解决这个问题 if (shell.which(npm)) {versionRequirements.push({name: npm,currentVersion: exec(npm --version),versionRequirement: packageConfig.en…...
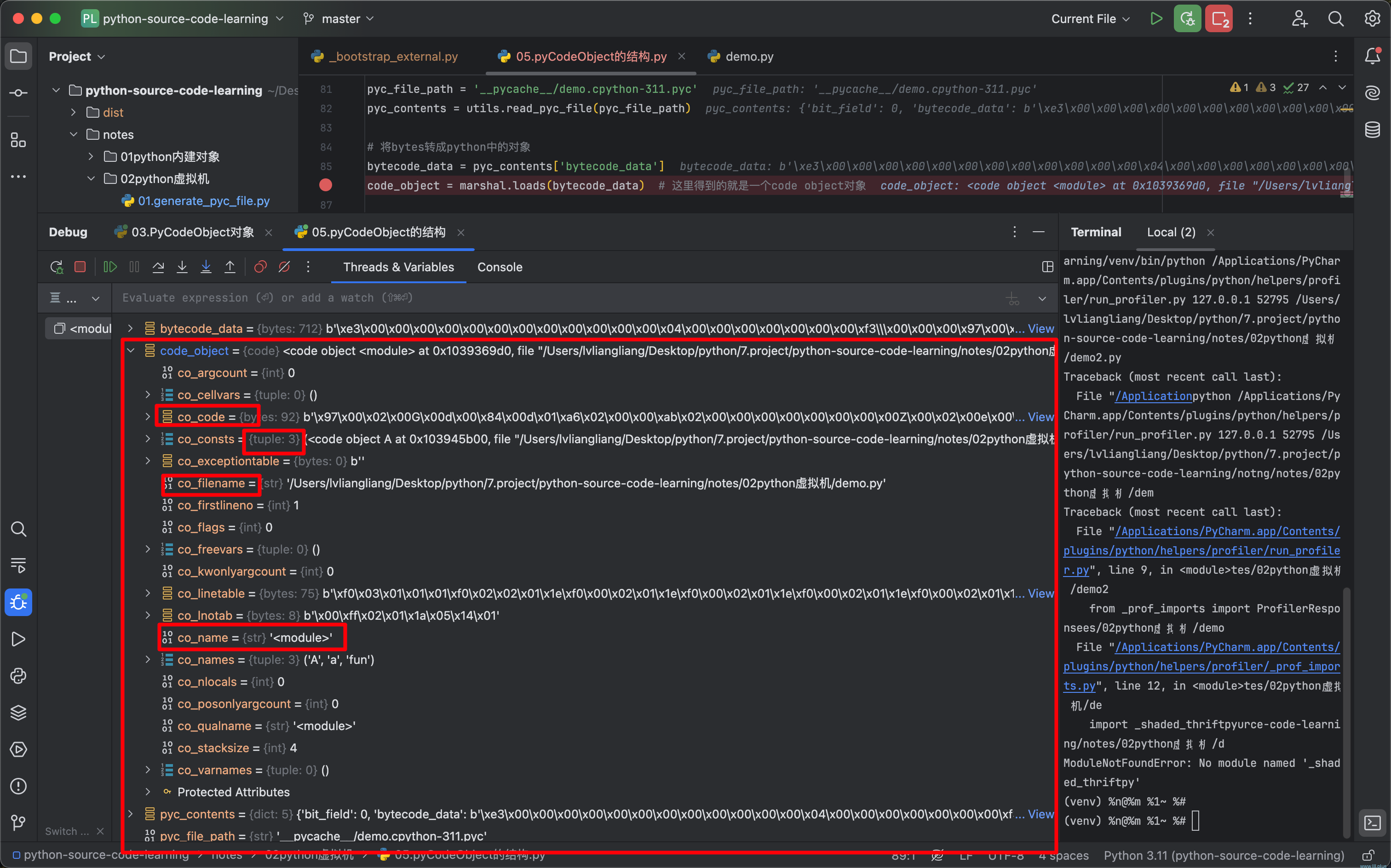
《Python源码剖析》之pyc文件
前言 前面我们主要围绕pyObject和pyTypeObject聊完了python的内建对象部分,现在我们将开启新的篇章—python虚拟机,将聚焦在python的执行部分,搞懂从“代码”到“执行”的过程。开启新的篇章之前,你也许会有一个疑惑:我…...
Python零基础-中【详细】
接上篇继续: Python零基础-上【详细】-CSDN博客 目录 十、函数式编程 1、匿名函数lambda表达式 (1)匿名函数理解 (2)lambda表达式的基本格式 (3)lambda表达式的使用场景 (4&…...

回溯 leetcode
22. 括号生成 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:["((()))","(()())","(())()","()(())"…...

Android firebase消息推送集成 FCM消息处理
FirebaseMessagingService 是 Firebase Cloud Messaging (FCM) 提供的一个服务,用于处理来自 Firebase 服务器的消息。它有几个关键的方法,你提到的 onMessageReceived、doRemoteMessage 和 handleIntent 各有不同的用途。下面逐一解释这些方法的作用和用…...

react中怎么为props设置默认值
在React中,你可以使用ES6的类属性(class properties)或者函数组件中的默认参数(default parameters)来定义props的默认值。 1.类组件中定义默认props 对于类组件,你可以在组件内部使用defaultProps属性来…...
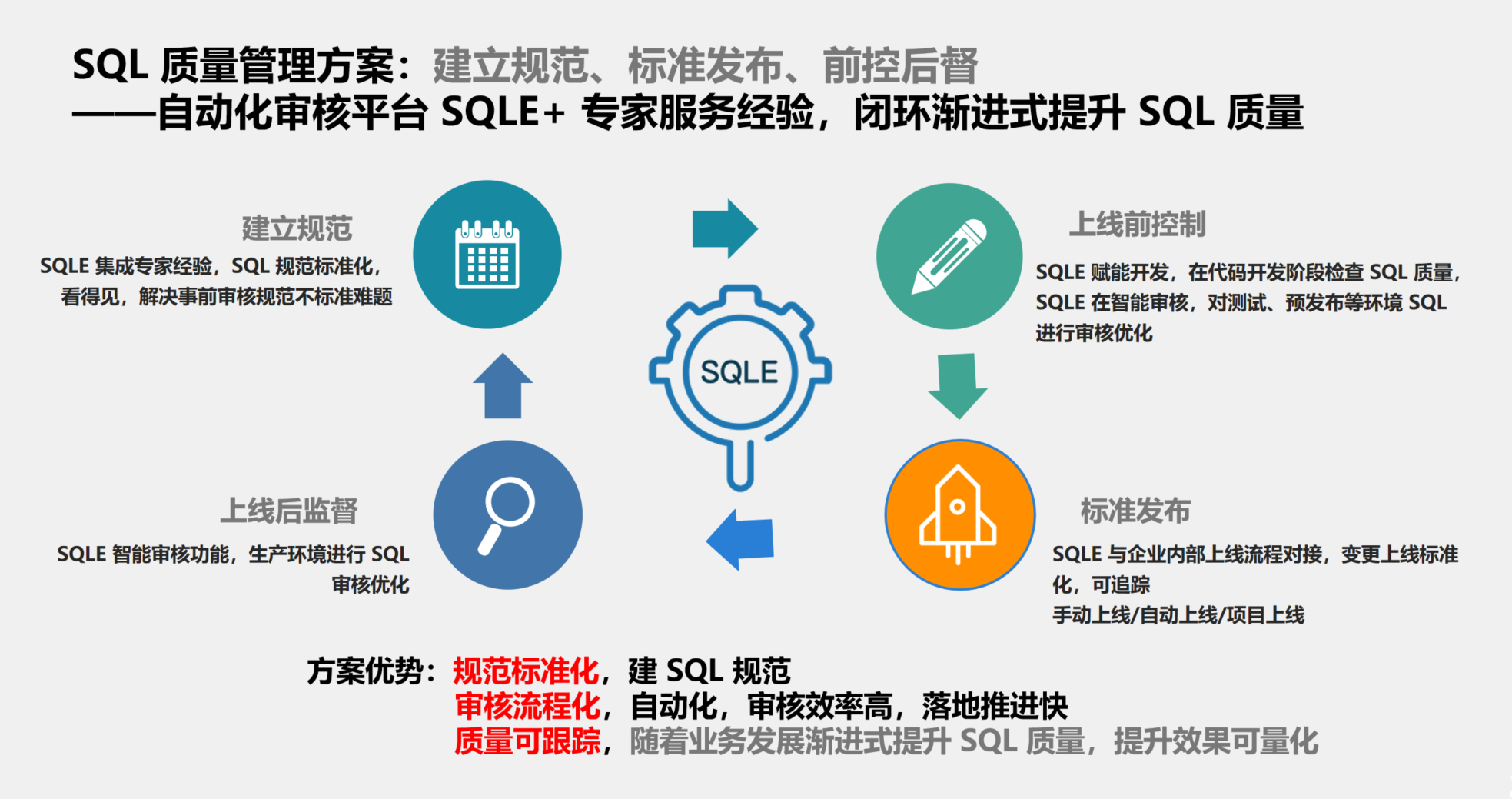
企业如何做好 SQL 质量管理?
研发人员写 SQL 操作数据库想必一定是一类基础且常见的工作内容。如何避免 “问题” SQL 流转到生产环境,保证数据质量?这值得被研发/DBA/运维所重视。 什么是 SQL 问题? 对于研发人员来说,在日常工作中,大部分都需要…...

半年不在csdn写博客,总结一下这半年的学习经历,coderfun的一些碎碎念.
前言 自从自己建站一来,就不在csdn写博客了,但是后来自己的网站因为资金问题不能继续维护下去,所以便放弃了自建博客网站来写博客,等到以后找到稳定,打算满意的工作再来做自己的博客网站。此篇博客用来记录自己在csdn…...

c++中的命名空间与缺省参数
一、命名空间 1、概念:在C/C中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存 在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或…...
SpringBoot整合WebSocket实现聊天室
1.简单的实现了聊天室功能,注意页面刷新后聊天记录不会保存,后端没有做消息的持久化 2.后端用户的识别只简单使用Session用户的身份 0.依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-…...

别再乱删了!一文理清Unity工程里Assets、Library等6个核心文件夹的作用与关系
Unity工程目录深度解析:从Assets到UserSettings的完整指南在Unity开发过程中,工程目录结构就像一座精心设计的建筑,每个文件夹都有其特定的功能和存在意义。对于刚接触Unity的开发者来说,理解这些文件夹的作用和相互关系ÿ…...

LLM应用开发之向量数据库详解
摘要随着大语言模型(LLM)应用的快速发展,向量数据库作为AI时代的关键基础设施,正在成为RAG(检索增强生成)、语义搜索、智能推荐等场景的核心组件。本文将从向量嵌入的原理出发,深入讲解向量相似…...
)
别再只会用cp了!用dd命令给硬盘做‘全身体检’和‘克隆手术’(附实战命令)
别再只会用cp了!用dd命令给硬盘做‘全身体检’和‘克隆手术’(附实战命令)在Linux系统管理中,文件复制是最基础的操作之一。大多数用户习惯使用cp命令完成日常的文件复制任务,但当面对磁盘级操作时,cp就显得…...

2026电工杯数学建模竞赛A题论文、代码、数据
2026年电工杯数学建模竞赛A题完整论文 摘要 随着” 双碳” 战略深入推进,新能源消纳难的问题日益凸显,绿电直连型电氢氨园区成为解决新能源就近消纳和化工行业深度脱碳的重要路径。本文针对绿电直连型电氢氨园区的优化运行问题,基于风电 40MW…...

2026年杭州靠谱的GEO优化公司,杭州这里通网络科技值得选择吗?
在数字化时代,企业越来越重视线上推广,GEO优化服务能有效提升企业在AI平台上的曝光和流量,因此很多企业关注靠谱的GEO优化公司。杭州这里通网络科技就是一家值得了解的企业。 ### 选择标准 技术能力:靠谱的GEO优化公司应具备强大…...

2026保姆级免费在线去水印教程:想保存无水印视频?用这些方法就够了
你是不是也遇到过这样的尴尬:刷到一个特别喜欢的视频想保存下来做素材,结果画面中间杵着大大的水印;或者朋友发来一张好图,角落的Logo怎么都去不掉?自己研究半天,又是下软件又是找教程,结果要么…...

紧急更新!OpenAI API v4.5对脑筋急转弯类输出新增隐式过滤机制——立即启用这7个绕过策略,保住你的创意产能
更多请点击: https://codechina.net 第一章:OpenAI API v4.5脑筋急转弯过滤机制的底层原理与影响评估 OpenAI API v4.5 引入的脑筋急转弯过滤机制并非独立模块,而是深度集成于请求预处理与响应后置校验双阶段的语义安全策略。其核心依赖于轻…...

DeepSeek LeetCode 2617. 网格图中最少访问的格子数 Java实现
以下是 LeetCode 2617「网格图中最少访问的格子数」的 Java 实现,采用 BFS TreeSet 优化,保证每个格子只被访问一次,时间复杂度 O(mn log(mn))。java class Solution {public int minimumVisitedCells(int[][] grid) {int m grid.length, n…...

3步掌握Android虚拟定位:FakeLocation完全使用指南
3步掌握Android虚拟定位:FakeLocation完全使用指南 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation FakeLocation是一款基于Xposed框架的Android虚拟定位工具ÿ…...

在自动化客服系统中集成多模型 API 以提升响应稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服系统中集成多模型 API 以提升响应稳定性 对于构建自动化客服系统的团队而言,服务的连续性与稳定性是核心诉…...