大模型提示词Prompt学习
引言
关于chatGPT的Prompt Engineer,大家肯定耳朵都听起茧了。但是它的来由?,怎么能用好?很多人可能并不觉得并不是一个问题,或者说认定是一个很快会过时的概念。但其实也不能说得非常清楚(因为觉得没必要深究)。但我觉得,它毕竟存在过,火过,我们还是必须对它有更深入的理解,所以,我花时间认真了解了一下。
对于提示词的理解,我也是经历过好几个阶段。
最初,我第一次听说什么提示词工程,认为是chatGPT的缺陷所致,也就是GPT不够聪明,提示词是为了让我们迁就它,绕开它的一些不足。但仔细一看,发现不对,大多数提示词的技巧,实际上就是对人与人进行良好沟通的要求,并不过分,不能认为是GPT的缺陷。
于是,我开始关注提示词的细节和原理,但始终是记不住,感觉无非就是要学会说人话,要和人好好沟通,要能理解你想问领域的基础知识,似乎并没啥可学的,也就没关注了。
后来,Agent开始火热,开始了解Agent,才发现,原来提示词在这里有用,因为基于GPT编程,实际上很多时候是在使用提示词。那就不能象在chat里那么随意了,需要固化下来,抽象出模板,而且要关注这里提示词在不同版本的准确度。可以理解,提示词就是在编程序,只是在使用自然语言编程。
讲到这里,容我打一下岔。我们一定要来说说人与计算机如何交互的问题:
人与计算机交互的方式,也就是人给计算机派任务。经历了几个阶段,因为计算机本质是在处理0/1数据,处理计算任务。最早,我们可以认为计算机比较蠢,人自然就要多做一些事情,就像你的邻家小孩很笨沟通起来很困难,你就得牵就他。所以,人需要写晦涩的汇编指令(甚至用过打孔纸带),没办法,谁让它那么笨。但慢慢的,机器变得越来越聪明,人就开始使用C语言,C++语言,然后是 Java语言,到现在,最流行的Python,与计算机的交互变得越来越简单,我们可以理解为计算机变聪明了,对于人的要求,不断在后退,计算机理解能力提升,不断在前进。
直到今天,GPT的出现,人可能再退一步,使用自然语言来和计算机交流。这可是人类倒退的一小步,计算机进步的一大步。我们在使用Prompt的时候,发现使用自然语言就可以让计算机完成任务。所以,你不得不重视提示词,它不仅仅是用来聊天的输入,是未来与AI交流的第一语言(当然,也可能会被工程化,变成GPT的内置功能,但至少目前没有)
我不知道有没有引起大家的好奇。铺垫就说这么多了。
Prompt 的产生
对于大模型的技术,有一种四阶的说法,提示词工程应该属于最上层的,应用层技术,面向的人群是所有终端用户,门槛最低,最易于上手。

我们今天的重点是讲提示词工程,也就是Prompt。
简单来说,Prompt就是我们与大模型之间的沟通话术。
我们以前经常会接触一些职场沟通,销售话术,和大模型一起工作,就象人与人配合工作一样,需要有很好的沟通技巧。好了,言归正传,我们说说Prompt的来源。
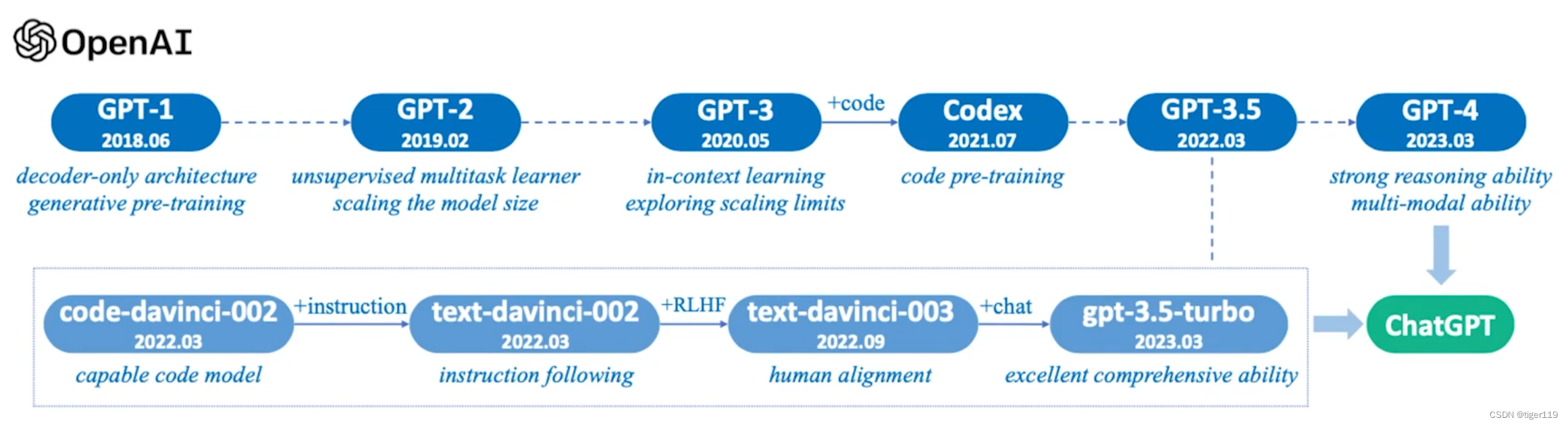
那Promtpt是如何产生的呢?我们必须从GPT的历史说起。
我们来看看GPT的历史:
1.0 时代:在Goolge发明Transformer之后,开始大力发展BERT,OpenAI 的同学觉得Transformer挺好的,把Transformer改了改,用了解码器的生成式架构,改成了可以纯并发的架构,并且采用无监督的方法(省了标注),使用了约50G数据(7000本书),通过预训练 + 专业数据fine-tune的方式,生成一个 1 亿参数的模型,效果还行,在特定的测试集上获得一定的结果。方法嘛 ,那是相当的简单粗暴。但产生一个重要理论范式:PreTrain + Fine-tune 的模式。这个时候,并没有什么人关注GPT。那时是BERT的天下。

2.0 时代:继续扩大参数,扩到15亿(12倍相对于GPT-1),预训练使用了更多的数据。将Fine-tune的量减少,争取一次搞定预训练和微调,变成一个阶段。PreTrain做更多的事情。无监督学习,增加掩码语言模型(增强自监督)。这仍然是一个暴力美学,但效果确实得到很大增强,相应的范式发生变化,PreTrain做了更多的事情,基础模型的能力大大增强。
In-context learning的产生
到了3.0:增加更多的数据(4100亿tokens),模型参数量更大(1700亿参数,相对于GPT-2大了100倍),这时就有问题了,如果要传统的fine-tune,成本会太高。因此,这时候出现了 In-Context learning ,让模型能够在上下文中学习,其实就是把问题前移,要求提问的人把问题问得更清楚,并且给出一些解答问题的示例 。这样,可以让大模型针对上下文进行推理,做到在不改变预训练模型的情况下,通过增强输入,达到最好的结果。
这和提示词有啥关系?当然有关系,这实际上就是提示词一个原理,就是提示词的前身,这是一个很简单的道理,一点不深奥,仍然是敌退我进的方法,邻家傻儿子能力不强,咋办呢,我把问题讲清楚一点。它减少了对fine-tune的依赖,支持对上下文的推理,但要求对方把上下文给清楚,甚至给出示例 ,然后根据模型的常识能力,直接获得答案。对于in-context learning有三类:
1:Zero shot 不给示例 ,给明确的指示
2: One-shot 给一个示例
3: Few-shot 给小于10个以内的多个案例

上图可以看出,参考示例越多,效果越好。模型越大,效果越好。
再回顾一下,GPT的发展过程如下:
即然 In-Context learning的效果这么好,那我们提问者是不是可以更进一步呢?
Prompt 实际上是在In-context learning的基础上更进一步
In-Context Learing:提供参考示例的学习方式。
Prompt-Learning 是在 in-context learning的基础上更进一步,利用好上下文来影响模型的输出。
两者的区别是:Prompt Learning 是设计好的提示来引导更好的输出。而 in-context learning则关注的是如何利用输入序列的上下文信息来影响模型输出。其实,我觉得大概都是一回事。
Prompt的理论
在学习如何写好提示词之前,我们先看看理论,虽然理论实际上我觉得有点扯。
其实就是三篇论文
1:Chain-of-Throught (思维链)
论文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
原理:作为用户,把需求描述更清楚(更适合对方的理解),具体的方法如下
* 大问题分解成小问题。职场OKR的做法。逐步思考,按问题解决的步骤。让LLM多步骤思考。会消耗额外资源,但会多次思考。
* 多步骤输出如何解决。让LLM给出中间结果。就象高中生数学考试,不给过程,要扣分滴。这样更容易发现错误(可以从错误的步聚重新开始)
* 对于数学应用题,一定要用步骤,逐步解决问题。
* 只能在大模型上,用少量样本包含思路。才有用。小模型没啥效果。原因是什么?越是复杂的问题,越有效。类似 Few-Shot
举例 :
提问中给出推理过程,帮助大模型在上下文中学习知识。然后举一反三,答对问题:有点相当于老师把饭给你喂到嘴边,先告诉你大概的解题思路。
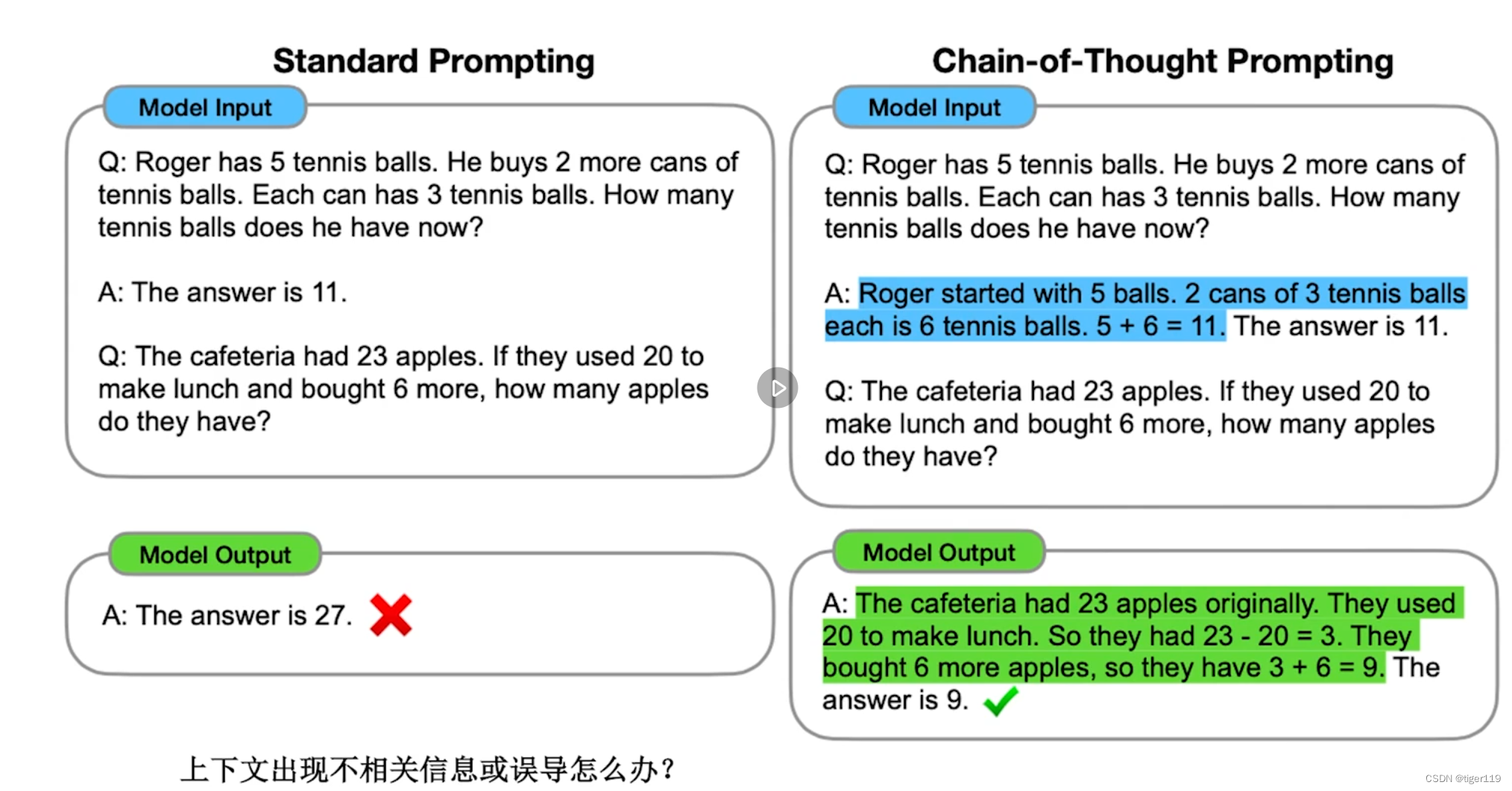
说实话,这个有点扯,一般我们并不会为了问第二个问题,去构造那么复杂的例子一。这实际上是有一定复杂度的。
我的理解就是为了让大模型具备某一些能力,可以找到解决该类问题的多步骤解决的方法。把它当成上下文给到模型,然后模型可以学会按上下文的解法,来分步骤解决新问题。
对于ChatGPT的高版本,可能已经内置了相应的提示词模板,会自动带上模板,提升准确率,当然,因为是分步骤执行,可能会导致消耗更多的算力。对于GPT API,你需要自行按CoT的思想去构造提示词。
除了添加按步骤示例的方法以外,还有一个小技巧:
在问题的后面追加说明:Think step-by-step (请按步骤思考和回答这个问题)
在某些情况,会获得更好的答案。
2: 自洽性(多路径推理)
论文:self-consistency improve Chain of Throught Reasoning in Language Models
原理:多路径推理,如何提升思维链的能力。三个臭皮匠顶个诸葛亮,多回答几次,投票选择最优解。
初一看到这个,觉得挺好笑,为啥这也是重要的论文之一,这顶维期刊的论文,也太显而易见了吧?
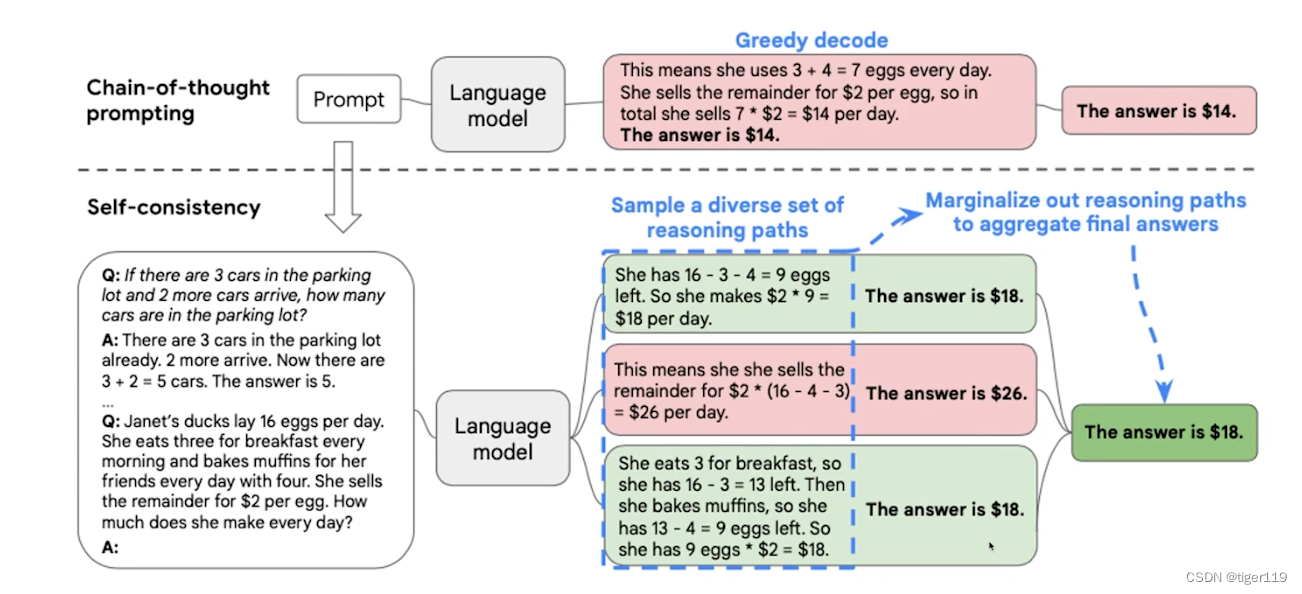
如上图所示,可以根据多个路径形成多解,然后投票获取答案。
非常可惜的是,目前大模型在计算方面的能力不强,另外,对于人脑具德的有意识的行为,大模型基本上是做不到的。我们通过CoT 其实可以看出,大模型并没有带来意识,展开来看,它仍然是一种复读机式的鹦鹉学舌式的智能。

好消息是:通过规模提升,带来智能拥现。好像有智能了。坏肖息是,看起来还是鹦鹉学䇢,还是很弱智,并非产生了意识。对于意识:是脑科学范畴,人类自已也没有弄明白,人到底是怎么回事,人类的本质是复读机吗?
今天看到腾讯小马哥提出:人工智能的技术必须是可知的,也就是可以掌握,可以解释的。其实有一定到底,否则到时可能控制不住,会出大问题。目前深度学习比较黑盒,不知是好事还是坏事。
3: 思维树(Tree of Throughts)
论文:Tree of thought:Deliberate Problem Solving with Large Language Models
原理:能不能打破从左到右的有局限性的问题解决顺序。类似BIRT的做法。
如下图,类似搜索算法,可以进行遍历解空间,找到全局最优解。

从理论上,可以看看ToT的思路,正如人是如何解决复杂问题的?
那就是不断发掘,如何做:
Step 1:利用CoT,把问按多步骤拆解,思维分解。
Step 2:思维生成器——给出K个侯选项,进行抽样,提供多样性。
Step 3:选择,进行价值评估。对每个状态进行独立评估。或者进行投票。
或者让大语言模型自已来评估。
注意:在寻找答案时,需要搜索。可以使用广度或者深度。
说实话,并没有弄明白,我们如何使用ToT?至少感觉在ChatGPT中简单利用提示词很难,如果是编程,在做AutoGPT或者Agent时,好像可以按此思路来解决问题。但这和大模型本身的关系不大,确实又是一个工程方法。
提示词如何写?
好了,我们终于写到重点了(以下都是网上截抄的,但我自已实验过)
原则,把大模型当成你的同事,一个小伙伴。

这里提供的思路,并不是实际的例子,对于不同应用的例子,可以在网上搜索,或者选择提示词工具和插件。
角色设定:减少范围,有点相当于直接选了MoE
下面的示例中,System就是系统级的设定,如果在ChatGPT中,可以先单独开一条消息,提前做一下说明,后续就不用再重复了。
指令注入:强调本次上下文一直要注意的信息

问题拆解:帮计算机拆解一下问题,不要太为难它

这个例子不太好,大概的意思就是把问题的步骤帮助做一下拆解。
分层设计:这个知道答案是分层的,那就按层来提问


编程思维:注意,大模型是可以支持自然语言编程的

问题实际上就是一段程序,可以有逻辑判断,可以有输出定义。
Few-Shot:给例子,给例子,给例子。
对于打样,给例子,上面已经给出例子。
另外,网上提供的一个比较好的例子:生成标注数据,挺好用。

这个例子也很有用,在分析BUG时可以参考。

提示词工程是啥?
随着ChatGPT的工程能力越来越强,可能写好提示词的价值会越来越小。你可能在使用chatGPT过程中会发现,之前的一些提示词黑魔法,在高版ChatGPT会变得没必要了。因为相应的提示词会在ChatGPT中自动引用。但目前而言,GPT API是没有开放相应的能力的,还需要我们通过程序来进行封装。
我们需要将手工变成自动,把手工的Prompt变成程序自动生成(实际上是抽象变量)。这样变成一个固定的做法。变成一个工程问题。可以通过抽象模板来完成。
比如:我要将{文字}翻译成{中文} 这实际上就是一个翻译工具
比如:我要创作一个{}的文案。
定义模板,抽取参数,它就变成一个自动化的工具。
将Prompt当作编程语言,把多个prompt串在一起,就可以完成复杂的任务。
作为提示词工程师,会按照一定的规则去写提示词。
使用LangChane时,可以很好的使用Prompt,因为它有一个Promt Templates:
1:PromtTemplate.from_template(""),可以添加变量,使用时传入。输出格式也可以规范。
可以检查传参。无变量也是可以的。
2:使用构造函数生成PromptTemplate。和1没啥区别。只是更严格,确定参数
这个有点怪,但你可以认为实际上就是将自然语言封装了变量。
ChatPromptTemplate 与之类似。
可以在System中添加变量。要以在user_input中定义变量。
使用fromatf进行参数传入
FewShotPromptTemplate——给参考示例。
给示例集,解包,定义字典,模板还可以嵌套。
注意:SematicSimilarityExampleSelector 可以查找相近的语义词。这个很有用噢。
如下是一个简单的示例图,只要学过一点点编程,很容易理解这个。

对于复杂的情况,我们还可以生成思维链,完成复杂的流程,也就是类似上面讲到的ToT了。我觉得ToT的落地,就在这里了。
比如:我需要提供一个工具,有大模型来生成戏剧,另外,针对生成的戏剧在理解后进行评论,使用另一个大模型。对于此类的问题,就需要比较复杂的对待了。
(如下使用的框架是开源的LangChain框架)

好了,大概写这么多,提示词大家确实没必要太关注,我也觉得它是一个过渡的技术。
它的起因是为了给基础大模型减压(模型能力问题)
它的发展是因为低版本的ChatGPT的工程能力弱(没有对提示词封装),API没有提供相应的模板支持,但是,很可能后续很快会被补上。
当然,了解一下原理,并没有什么坏处。
但没有必要满世界去学习提示词模板,在需要的时候,去搜一下就好了。
但是要注意,提示词模板并不是通用的,要看具体的大模型和大模型的版本。
相关文章:
大模型提示词Prompt学习
引言 关于chatGPT的Prompt Engineer,大家肯定耳朵都听起茧了。但是它的来由?,怎么能用好?很多人可能并不觉得并不是一个问题,或者说认定是一个很快会过时的概念。但其实也不能说得非常清楚(因为觉得没必要深…...

蓝桥杯python组备赛指南
文章目录 前言刷题网站idle操作常用标准库mathdatetime 常见Q&A 前言 最近结束了比赛,我对比赛的过程进行了详细的复盘,并计划撰写一篇文章。这篇文章旨在为准备参加蓝桥杯的学弟学妹们提供帮助,我希望我的文章和笔记能对你们有所裨益。…...
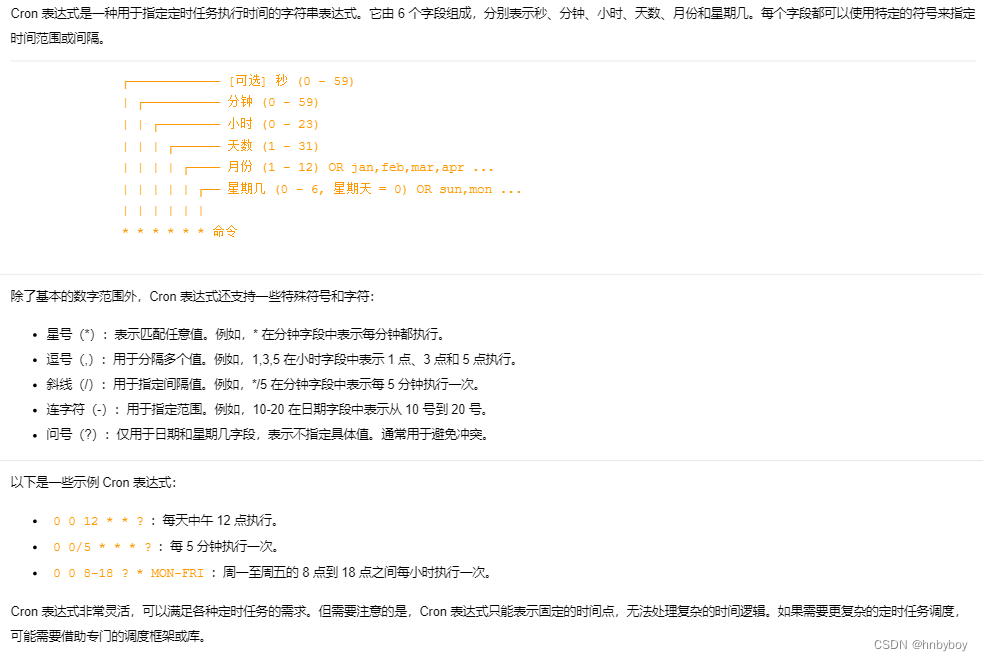
架构师系列-定时任务解决方案
定时任务概述 在很多应用中我们都是需要执行一些定时任务的,比如定时发送短信,定时统计数据,在实际使用中我们使用什么定时任务框架来实现我们的业务,定时任务使用中会遇到哪些坑,如何最大化的提高定时任务的性能。 我…...

新计划,不断变更!做自己,接受不美好!猪肝移植——早读(逆天打工人爬取热门微信文章解读)
时间不等人 引言Python 代码第一篇 做自己,没有很好也没关系第二篇结尾 引言 新计划: 早上一次性发几个视频不现实 所以更改一下 待后面有比较稳定的框架再优化 每天早上更新 早到8点 晚到10点 你刚刚好上班或者上课 然后偷瞄的看两眼 学习一下 补充知…...

【数据结构】二叉树-堆(上)
个人主页~ 二叉树-堆 一、树的概念及结构1、概念2、相关概念3、树的表示4、树的实际应用 二、二叉树的概念和结构1、概念2、特殊二叉树3、二叉树的性质4、二叉树的存储结构(1)顺序存储(2)链式存储 三、二叉树的顺序结构以及实现1、…...

【Spring Boot】在项目中使用Spring AI
Spring AI是Spring框架中用于集成和使用人工智能和机器学习功能的组件。它提供了一种简化的方式来与AI模型进行交互。下面是一个简单的示例,展示了如何在Spring Boot项目中使用Spring AI。 步骤 1: 添加依赖 首先,在pom.xml文件中添加Spring AI的依赖&…...

【java程序设计期末复习】chapter3 运算符、表达式和语句
运算符、表达式和语句 Java提供了丰富的运算符,如算术运算符、关系运算符、逻辑运算符、位运算符等。 Java语言中的绝大多数运算符和C语言相同,基本语句,如条件分支语句、循环语句等也和C语言类似,因此,本章就主要知识…...

【建议收藏】30个较难Python脚本,纯干货分享
本篇较难,建议优先学习上篇 ;20个硬核Python脚本-CSDN博客 接上篇文章,对于Pyhon的学习,上篇学习的结束相信大家对于Pyhon有了一定的理解和经验,学习完上篇文章之后再研究研究剩下的30个脚本你将会有所成就&…...

01-05.Vue自定义过滤器
目录 前言过滤器的概念过滤器的基本使用给过滤器添加多个参数 前言 我们接着上一篇文章01-04.Vue的使用示例:列表功能 来讲。 下一篇文章 02-Vue实例的生命周期函数 过滤器的概念 概念:Vue.js 允许我们自定义过滤器,可被用作一些常见的文本…...

C++系列-static成员
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 概念 声明为static的类成员称为类的静态成员,用static修饰的成员变量,称之为静态成员变量,用static修饰的成员函数,称之为静态成…...

Git | 创建和管理Pull Request总结
如是我闻: 在使用 GitHub 进行项目协作时,掌握如何创建、更新和合并(squash)pull request 是非常有帮助的。本文将详细介绍这些操作,帮助我们更好地管理项目代码,并解释每个操作的原因和解决的问题。 1. 什…...

电机控制系列模块解析(23)—— 同步机初始位置辨识
一、两个常见问题 为什么感应电机(异步机)不需要初始位置辨识?(因此感应电机转子磁场在定子侧进行励磁,其初始位置可以始终人为定义为0) 为什么同步磁阻电机需要初始位置辨识?(因为…...
【数据库基础-mysql详解之索引的魅力(N叉树)】
索引的魅力目录 🌈索引的概念🌈使用场景🌈索引的使用🌞🌞🌞查看MySQL中的默认索引🌞🌞🌞创建索引🌞🌞🌞删除索引 站在索引背后的那个男…...
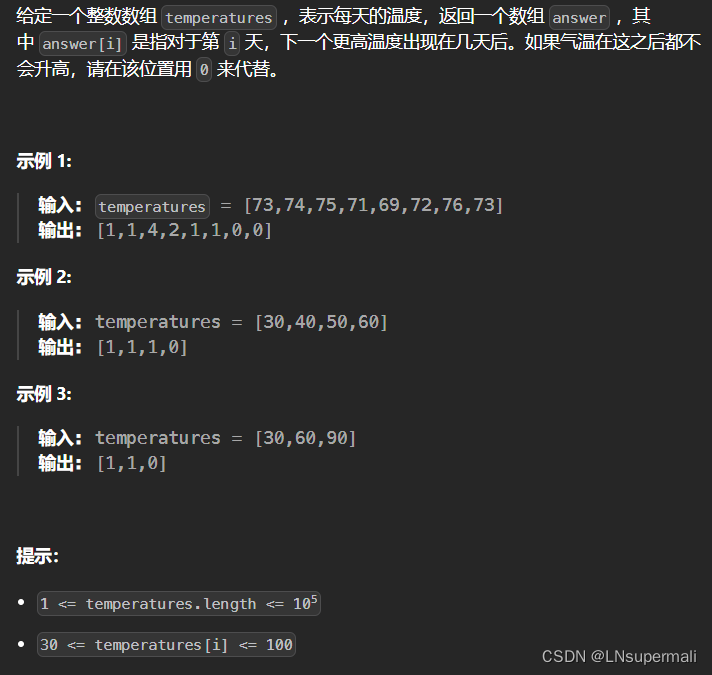
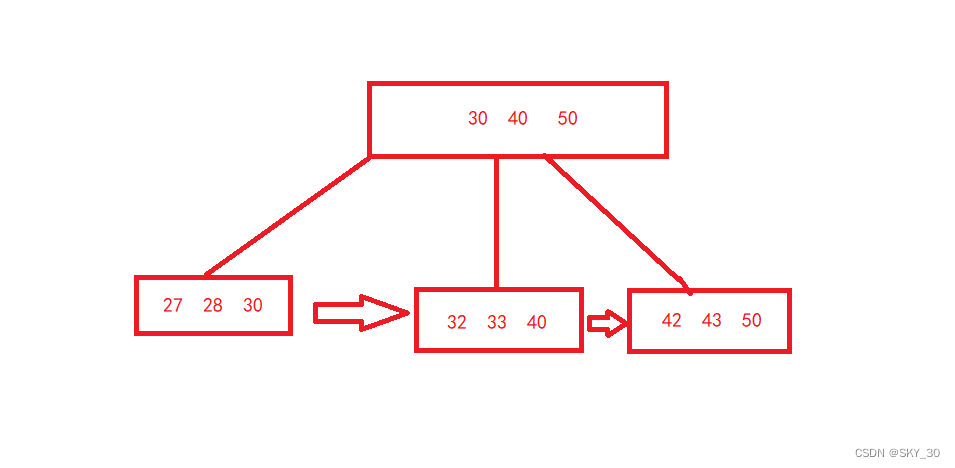
力扣739. 每日温度
Problem: 739. 每日温度 文章目录 题目描述思路复杂度Code 题目描述 思路 若本题目使用暴力法则会超时,故而使用单调栈解决: 1.创建结果数组res,和单调栈stack; 2.循环遍历数组temperatures: 2.1.若当stack不为空同时…...

KDE6桌面于2024年2月发布
原文:KDE MegaRelease 6 - KDE 社区 1. **Plasma 6 桌面环境**:KDE Plasma 是一个现代化、功能丰富的 Linux 操作系统桌面环境,以其时尚设计、可定制界面和广泛的应用程序而闻名。Plasma 6 带来了两项重大技术升级:过渡到最新的应…...

「TypeScript系列」TypeScript 对象及对象的使用场景
文章目录 一、TypeScript 对象1. 对象字面量2. 类实例化3. 使用接口定义对象形状4. 使用类型别名定义对象类型5. 使用工厂函数创建对象 二、TypeScript 对象属性及方法1. 对象属性2. 对象方法3. 访问器和修改器(Getters 和 Setters) 三、TypeScript 对象…...
shell正则匹配~=)
shell从入门到精通(22)shell正则匹配~=
文章目录 1. 基本用法2. 正则表达式捕获组(catch group)3. 匹配结果提取1. 基本用法 在 Shell 脚本中,可以使用正则表达式进行文本匹配和提取。Bash shell 支持使用 [[ … =~ … ]] 结构进行正则表达式匹配,同时还能提取匹配结果。 以下是一个简单的例子,展示了如何在 Bas…...

【Spring】使用Spring常用导入依赖介绍
当使用Spring框架时,以下是常用导入的依赖的详细介绍,按照不同的功能和类别进行分点表示和归纳: 1、核心依赖 Spring Core (spring-core) 功能:提供了Spring框架的基础功能,包括IoC(控制反转)…...

PC端应用订阅SDK接入攻略
本文档介绍了联想应用联运sdk接入操作指南,您可在了解文档内容后,自行接入应用联运sdk。 1. 接入前准备 1. 请先与联想商务达成合作意向。 2. 联系联想运营,提供应用和公司信息,并获取商户id、app id、key(公私钥、…...

WebService的wsdl详解
webservice服务的wsdl内容详解,以及如何根据其内容编写调用代码 wsdl示例 展示一个webservice的wsdl,及调用这个接口的Axis客户端 wsdl This XML file does not appear to have any style information associated with it. The document tree is shown…...

如何在Mac上免费运行Windows游戏与应用:Whisky完整指南
如何在Mac上免费运行Windows游戏与应用:Whisky完整指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 还在为Mac无法运行Windows专属软件而烦恼吗?Whisky为你…...

线段树入门:算法分析
算法分析线段树采用了分而治之的策略,其点更新、区间更新、区间查询都可以在 时间内完成。树状数组和线段树都用于解决频繁修改和查询的问题,树状数组比线段树更节省空间、代码简单易懂,但是先单数用途更广、更加灵活,凡是可以使用…...
)
94、【Agent】【OpenCode】edit 工具提示词(参数内容)
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除 背景 上篇 blog 【Agent】【OpenCode】edit 工…...

【DeepSeek数据隐私保护终极指南】:20年安全专家亲授5大合规落地实践与3大避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek数据隐私保护的核心理念与演进脉络 DeepSeek自诞生以来,将“数据主权归用户、模型能力不以隐私让渡为前提”确立为不可妥协的底层信条。其隐私保护理念并非静态规范,而是随技术…...

机器学习数据安全新视角:高价值样本的脆弱性与差异化防御策略
1. 项目概述与核心问题在机器学习的实际部署中,我们常常面临一个看似矛盾的局面:那些对模型性能提升贡献最大的“高价值”数据,是否也恰恰是系统中最脆弱的环节?这个问题在过去几年里一直萦绕在我的心头。无论是构建一个图像分类器…...

BabelDOC:如何用结构化中间语言实现PDF格式无损翻译?
BabelDOC:如何用结构化中间语言实现PDF格式无损翻译? 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 在学术研究和跨国协作中,PDF文档翻译一直是一个技术难题…...

自己用 ai 写了个链接 mysql 数据库的 mcp 工具
概要背景是这样的,之前用 ai 帮我生成 entity 都要我自己导出表结构,然后粘贴给它分析生成对应的 entity ,感觉好麻烦,而且还不能实时查看我的表和 entity 字段是否对应了, 问了 ai 建议我写个本地针对性的脚本或者用 …...

观察Taotoken在多模型间自动路由与容灾切换的实际响应情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型间自动路由与容灾切换的实际响应情况 在构建依赖大模型服务的应用时,服务的连续性与稳定性是开发…...

MinIO集群敏感信息泄露漏洞CVE-2023-28432深度解析
1. 这个漏洞不是“配置没关好”,而是MinIO架构里埋着的定时炸弹MinIO集群模式下的敏感信息泄露漏洞(CVE-2023-28432)——光看标题,很多人第一反应是:“哦,又一个管理员忘了关调试接口?”我最初也…...

AWVS深度配置与实战避坑指南:从安装校准到漏洞验证
1. 为什么AWVS不是“点开就扫”的玩具,而是渗透测试中真正能扛事的扫描器很多人第一次听说Acunetix Web Vulnerability Scanner(AWVS),是在某篇标题写着“三分钟上手”的教程里。点开安装包、一路下一步、填个URL、点“开始扫描”…...