xgboost项目实战-保险赔偿额预测与信用卡评分预测001
目录
算法代码
原理
算法流程
xgb.train中的参数介绍
params
min_child_weight
gamma
技巧
算法代码
代码获取方式:链接:https://pan.baidu.com/s/1QV7nMC5ds5wSh-M9kuiwew?pwd=x48l
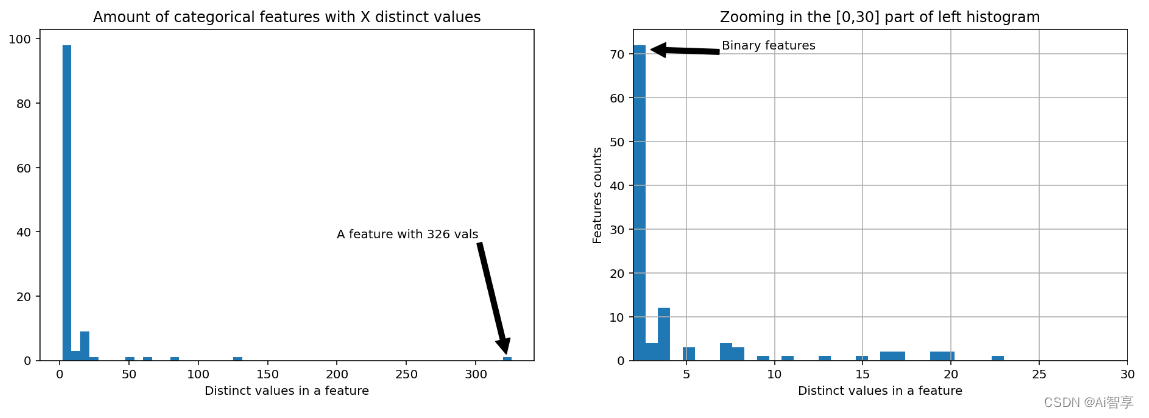
提取码:x48l特征直方图统计:
fig, (ax1, ax2) = plt.subplots(1,2) fig.set_size_inches(16,5) ax1.hist(uniq_values_in_categories.unique_values, bins=50)
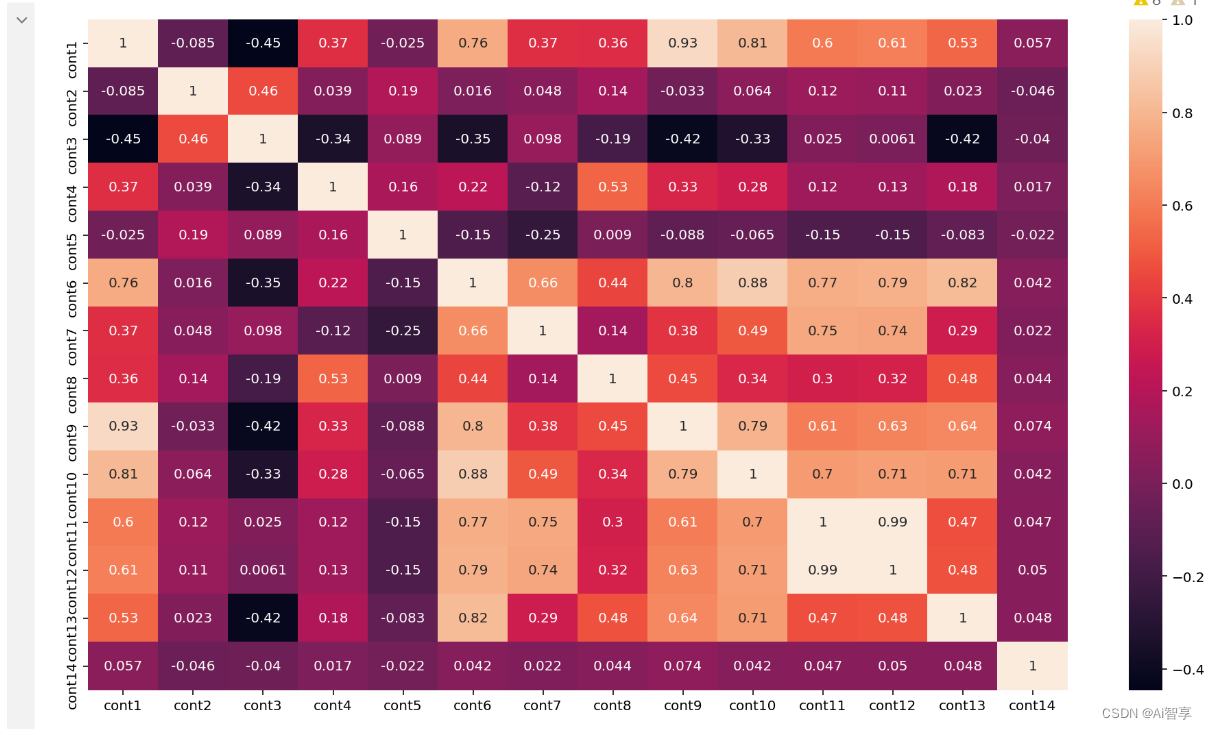
特征相关性分析
plt.subplots(figsize=(16,9)) correlation_mat = train[cont_features].corr() sns.heatmap(correlation_mat, annot=True)
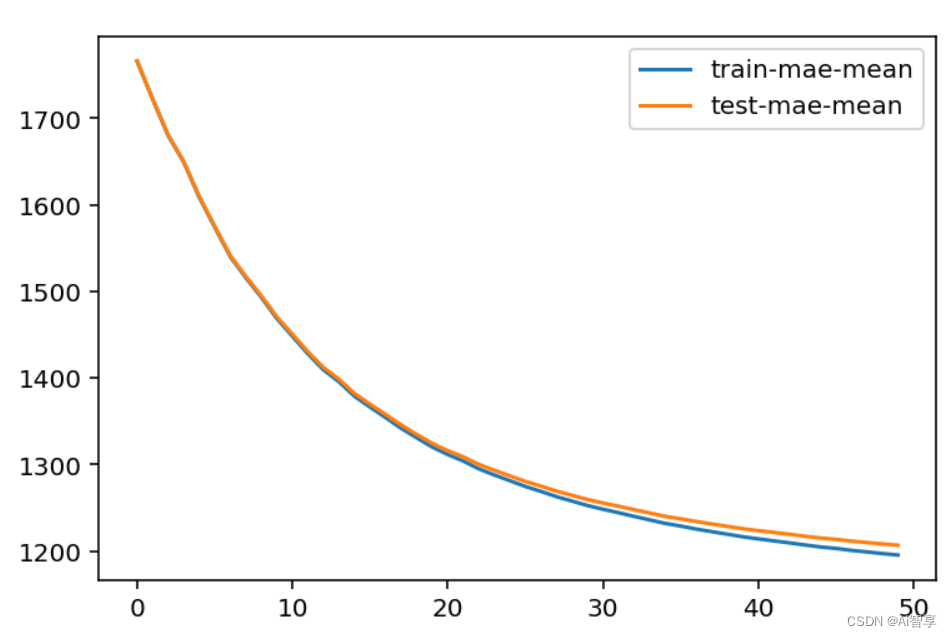
交叉验证调参
plt.figure() bst_cv1[['train-mae-mean', 'test-mae-mean']].plot()
交叉验证获取核心参数
mean_test_score = scores['mean_test_score'] std_test_score = scores['std_test_score'] params = scores['params']_params = [] _params_mae = [] for i in range(len(mean_test_score)):_params.append(params[i])_params_mae.append(mean_test_score[i]) params = np.array(_params) grid_res = np.column_stack((_params,_params_mae)) print(grid_res) print(grid_res.shape) return [grid_res[:,i] for i in range(grid_res.shape[1])]

原理
xgboost可以处理二分类、多分类、回归问题;
Extreme Gradient Boosting。XGBoost(Extreme Gradient Boosting)是一种基于决策树的集成学习算法,它在梯度提升(Gradient Boosting)框架下进行了改进和优化。其基本原理包括以下几个关键步骤:
集成学习
XGBoost采用集成学习的思想,通过结合多个弱学习器(通常是决策树)来构建一个强大的集成模型。每个弱学习器都是针对数据的不同部分进行训练,然后将它们组合起来形成最终的预测模型。
决策树的串行训练与集成
XGBoost通过串行训练决策树来构建集成模型。在每一轮训练中,新的决策树被设计为纠正前一轮模型的残差,以逐步减少训练误差。通过迭代添加树模型,XGBoost构建了一个更强大的整体模型。
正则化
XGBoost引入了正则化技术来控制模型的复杂度,防止过拟合。正则化项包括对树结构的惩罚,以及对叶子节点样本权重的约束,这有助于提高模型的泛化能力。
特征重要性评估
XGBoost提供了对特征重要性的评估,可以帮助用户了解哪些特征对模型的预测贡献最大。这有助于特征选择和模型解释。
高效的工程实现
XGBoost在算法和工程实现上都进行了优化,具有高效的训练速度和内存利用率,使其能够处理大规模数据集。
总的来说,XGBoost通过串行训练决策树、引入正则化和特征重要性评估等技术,构建了一种高效而强大的集成学习模型,适用于各种机器学习任务,特别是在结构化数据和表格数据上表现优异。
算法流程
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升树(Gradient Boosting Tree)的机器学习算法,它在提升树算法的基础上进行了优化和改进,以提高模型的性能和效率。以下是XGBoost算法的基本流程:
- 初始化模型参数:包括树的深度、学习率、树的数量等。
- 构建初始树:用一个简单的回归树或分类树作为初始模型。
- 迭代优化
1.计算损失函数的梯度:根据当前模型对训练数据的预测结果,计算损失函数的梯度。常用的损失函数包括平方损失函数(用于回归问题)和对数损失函数(用于分类问题)。
2.构建新树:基于损失函数的梯度,构建一棵新的回归树或分类树,该树的叶子节点数通常比较少。
3.更新模型:通过将新建的树与之前的模型相加,更新模型的预测结果。为了防止过拟合,通常会乘以一个小于1的学习率。
4.正则化:为了控制模型的复杂度和防止过拟合,可以引入正则化项,如树的深度限制、叶子节点权重的L1和L2正则化。
5. 迭代终止条件:可以设定迭代次数、达到一定的模型性能或损失下降率等作为终止条件。
6.输出最终模型:当满足终止条件时,输出最终的集成模型。
XGBoost通过优化目标函数的梯度提升树模型,采用了一些技术和策略,如加权损失函数、子采样、列抽样、树剪枝等,以提高模型的泛化能力和训练速度。
xgb.train中的参数介绍
xgb.train 函数是用于训练模型的主要函数之一。它允许你手动指定模型的各种参数,以定制化地训练 XGBoost 模型。
params
字典类型,表示要传递给 XGBoost 模型的参数。常见的参数包括:reg:linear 表示 XGBoost 将使用线性回归作为优化目标,即模型的输出是一个连续值,目标是最小化预测值与实际值之间的均方误差(MSE)或其他回归损失函数。
binary:logistic 是 XGBoost 中用于二分类问题的一种优化目标(objective)。使用逻辑回归(Logistic Regression)作为优化目标,用于解决二分类问题。
在二分类任务中目标是将样本分为两个类别,正类和负类。而binary:logistic 的作用是训练一个模型,使得对于给定的输入特征,模型能够输出一个概率值,表示样本属于正类的概率。然后设定一个阈值,将这个概率转换为类别标签,例如大于阈值则预测为正类,小于阈值则预测为负类。
使用 binary:logistic 作为优化目标时,模型的输出会通过逻辑函数(sigmoid 函数)转换为 0 到 1 之间的概率值,表示正类的概率。然后,模型会根据损失函数(通常是对数损失函数)来优化模型参数,以最大化预测的概率与实际标签的一致性。
multi:softmax多分类问题的一种优化目标(objective)设置。具体来说,multi:softmax 表示 XGBoost 将使用 Softmax 函数作为优化目标,用于多类别分类。Softmax 函数可以将模型的原始输出转换为每个类别的概率分布,使得概率之和为 1。在训练过程中,XGBoost 会优化模型参数,以最大化实际类别的概率与预测类别的概率之间的一致性。
XGBoost 将会训练一个多分类模型,该模型会尝试在给定数据集上学习出最佳的分类决策边界,以便能够将样本正确地分到多个类别中去。
对于回归任务(如 reg:linear),常用的评估指标包括均方误差(rmse)、平均绝对误差(mae)等。
对于二分类任务(如 binary:logistic),常用的评估指标包括准确率(error)、AUC(auc)等。
对于多分类任务(如 multi:softmax),常用的评估指标包括准确率(merror)、多分类对数损失(mlogloss)等。
min_child_weight
较大的 min_child_weight 值会导致更加保守的树模型,因为它限制了每个叶子节点的样本权重总和,使得树的生长更加受限制。相反,较小的 min_child_weight 值允许模型更多地考虑每个叶子节点的样本,可能导致模型过拟合。
注意:在决策树的训练过程中,每个样本都会被分配一个权重,这个权重可以用来调节样本对模型的贡献程度。
当训练一棵决策树时,XGBoost 会根据样本的权重来计算叶子节点的样本权重。这个过程涉及到样本在树的每个节点上的传递和累积,最终得到每个叶子节点所包含的样本的权重之和。
通过调节叶子节点的样本权重,我们可以控制模型对不同样本的关注程度,进而影响模型的泛化能力和性能。
选择合适的min_child_weight值通常需要通过交叉验证来进行调整。如果min_child_weight设置得太大,可能会导致模型欠拟合;如果设置得太小,可能会导致模型过拟合。
通过调节 subsample 参数,可以控制每棵树的训练样本的多少,从而影响模型的方差和泛化能力。较小的 subsample 值可以降低模型的方差,因为每棵树使用的样本更少,模型更加稳定,但可能会增加偏差。较大的 subsample 值可以提高模型的拟合能力,但可能导致过拟合。
通过调节 colsample_bytree 参数,可以控制每棵树使用的特征的数量,从而增加模型的多样性,减少过拟合的风险。较小的 colsample_bytree 值可以降低模型的方差,增加模型的泛化能力,但可能会增加模型的偏差。较大的 colsample_bytree 值可以提高模型的拟合能力,但也可能导致过拟合。
- dtrain: 训练数据集(DMatrix 格式),是 XGBoost 特有的数据结构,用于高效存储和处理大型数据集。
- evals: 需要评估的数据集列表,通常包括训练数据集和验证数据集。
- obj: 自定义目标函数(可选)。
- feval: 自定义评估函数(可选)。
- early_stopping_rounds: 当验证指标不再提升时,停止训练的迭代次数。
early_stopping_rounds 参数指定了在多少个迭代轮次内,如果模型的性能在验证集上没有改善,就停止训练。例如如果将 early_stopping_rounds 设置为 10,那么在训练过程中如果连续 10 个迭代轮次内模型的性能都没有提升,训练就会提前终止。
verbose_eval: 控制输出信息的频率。如果设置为一个非负整数,则表示每隔指定的迭代轮次输出一次训练信息。例如,如果 verbose_eval 设置为 100,那么每隔 100 个迭代轮次就会输出一次训练信息。
如果设置为 True,则表示在每个迭代轮次结束后都输出训练信息。
callbacks: 回调函数列表,用于在训练过程中执行自定义操作(如保存模型)。callbacks 参数可以用于指定回调函数,在训练过程中执行特定的操作。常见的用途包括提前停止训练、保存模型、记录训练过程中的指标等。
gamma
`gamma` 参数是一个用于控制模型复杂度的关键参数,它是在构建决策树时用来进行剪枝的。`gamma` 参数的值越大,模型就越保守,倾向于剪枝,这样可以避免过拟合。相反,`gamma` 参数的值越小,模型就越自由,可以生长更多的叶子节点,这可能会导致过拟合。
`gamma` 参数实际上代表了在添加一个新的分裂点时,所需的最小减少的损失。如果一个分裂点不能至少减少 `gamma` 这么多的损失,那么这个分裂点就会被忽略。因此,`gamma` 可以被视为一个正则化项,用于控制模型的复杂度。
在数学上,`gamma` 参数与树的叶子节点的数量和深度直接相关。较大的 `gamma` 值会导致生成较浅的树,因为需要更大的损失减少来创建新的分裂。较小的 `gamma` 值会导致生成较深的树,因为较小的损失减少就足够创建新的分裂。
在实际应用中,调整 `gamma` 参数可以帮助找到模型复杂度和性能之间的最佳平衡点。如果模型的性能在验证集上不佳,可能需要增加 `gamma` 值来减少过拟合。相反,如果模型在训练集上的性能不佳,可能需要减小 `gamma` 值来增加模型的复杂度。
`gamma` 被设置为 0,这意味着默认情况下不会有额外的剪枝。在实际应用中,你可能需要通过交叉验证等方法来调整 `gamma` 的值,以找到最佳的模型配置。
技巧
train.select_dtypes: 选择不同数据类型的特征;
偏度概念
scipy库中,stats.mstats.skew()函数用于计算数据的偏度(skewness)。偏度是描述数据分布不对称性的一个统计量,它是衡量数据分布相对于平均值的偏斜程度。
偏度的计算公式为:
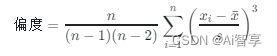
其中:
- ( n ) 是数据点的数量。
- ( x_i ) 是第 ( i ) 个数据点。
- ( bar{x} ) 是数据的平均值。
- ( s ) 是标准差。
- 如果偏度为正数,数据分布是右偏的,即数据点倾向于分布在平均值的右侧。
- 如果偏度为负数,数据分布是左偏的,即数据点倾向于分布在平均值的左侧。
- 如果偏度为零,数据分布是对称的,即数据点均匀分布在平均值两侧。
- 偏度值接近于零,表示数据分布比较对称。
- 偏度值远大于零或远小于零,表示数据分布非常偏斜。 在scipy.stats.mstats.skew()函数中,如果bias参数设置为True,则计算的是无偏估计量,即考虑了数据点的数量对偏度的影响。如果bias参数设置为False,则计算的是未调整偏度的原始估计量,这通常只在理论分析中使用。 例如,使用scipy.stats.mstats.skew()函数计算数据集的偏度:
连续数值特征与分类特征需要分开处理;
使用直方图可视化,统计频率分布;
corr()计算特征之间相关系数;并用sns.heatmap绘制热力图;
保险预测--回归问题;
在Python的pandas库中,astype('category') 方法将pandas的DataFrame或Series列转换为类别类型(categorical type)。这通常用于处理具有有限数量的不同值的列,例如性别、国家代码等。转换为类别类型可以节省内存,并且可以加快某些操作的处理速度。
使用 cat.codes 属性来获取每个类别值的数字编码。这些编码是整数,表示每个唯一类别在类别列表中的位置。例如,如果有一个包含三个不同国家的列,那么这些国家可能会被编码为0、1和2。
GridSearchCV(XGBoostRegressor): 交叉验证获取最佳参数,例如max_depth; min_child_weight;
一般交叉验证调参
Step 1: 选择一组初始参数
Step 2: 改变 max_depth 和 min_child_weight.
Step 3: 调节 gamma 降低模型过拟合风险.
Step 4: 调节 subsample 和 colsample_bytree 改变数据采样策略.
Step 5: 调节学习率 eta.(与数的深度反复调节)
ETA和num_boost_round依赖关系不是线性的,但是有些关联。
相关文章:
xgboost项目实战-保险赔偿额预测与信用卡评分预测001
目录 算法代码 原理 算法流程 xgb.train中的参数介绍 params min_child_weight gamma 技巧 算法代码 代码获取方式:链接:https://pan.baidu.com/s/1QV7nMC5ds5wSh-M9kuiwew?pwdx48l 提取码:x48l 特征直方图统计: fig, …...

子网划分,交换机原理与配置
子网划分 IP地址 IPv4由32位二进制数组成,一般用点分十进制来表示 IPv4是由32位二进制数组成,分成四组,第组八位。例如:11000000.10101000.00000000.00000010 为了便于配置通常表示成点分十进制形式例如:192.168.0.2 255.255.255.0 IPv6由128位组成&…...
记mapboxGL实现鼠标经过高亮时的一个问题
概述 mapboxGL实现鼠标经过高亮可通过注册图层的mousemove和moveout事件来实现,在mousemove事件中可以拿到当前经过的要素,但是当使用该要素时,发现在某个地图级别下会有线和面数据展示不全的情况。究其原因,发现是mapboxGL在绘图…...

AI重塑了我的工作流
阅读内容 Inhai: Agentic Workflow:AI 重塑了我的工作流 4 种主要的 Agentic Workflow 设计模式 Reflection(反思):让 Agent 审视和修正自己生成的输出。 举例:如果有两个 Agent:一个负责 Coding&#…...
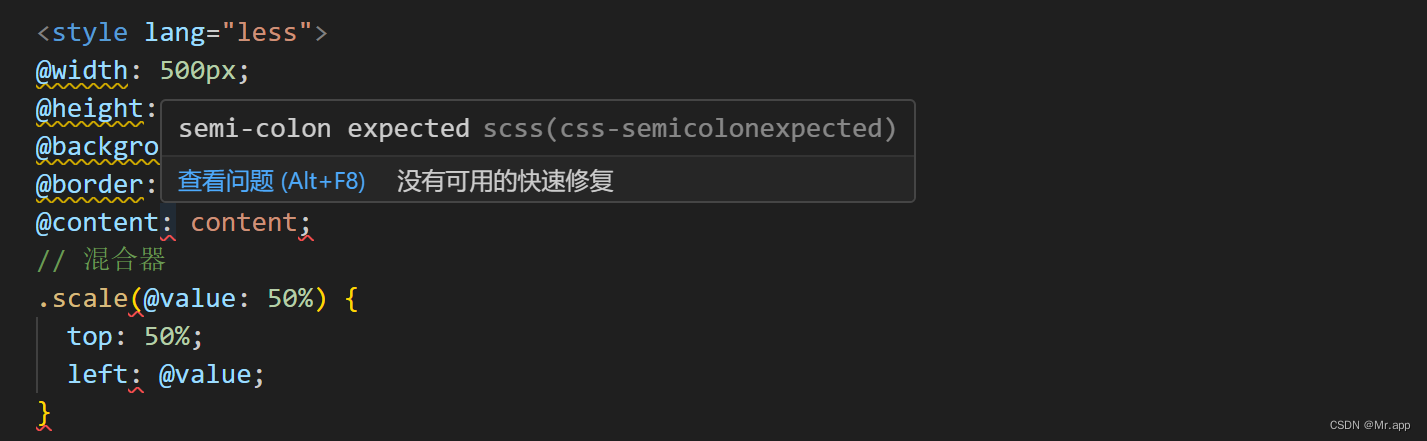
vue使用Less报错semi-colon expectedcss(css-semicolonexpected)的解决方法
1、将 styleint 依赖项添加到项目中 npm install --save-dev stylelint stylelint-config-standard2、在根目录中添加stylelint.config.js文件(与package.json同级) module.exports {extends: ["stylelint-config-standard"],rules: {"…...

如何使用golang自带工具对代码进行覆盖率测试
在 Go 语言中,测试代码覆盖率通常使用 go test 命令结合 -cover 和 -coverprofile 1. 基本代码覆盖率报告 在项目目录下运行以下命令 go test -cover这将在控制台输出一个代码覆盖率的百分比。但是,这种方式不会保存覆盖率数据(可以指定目…...
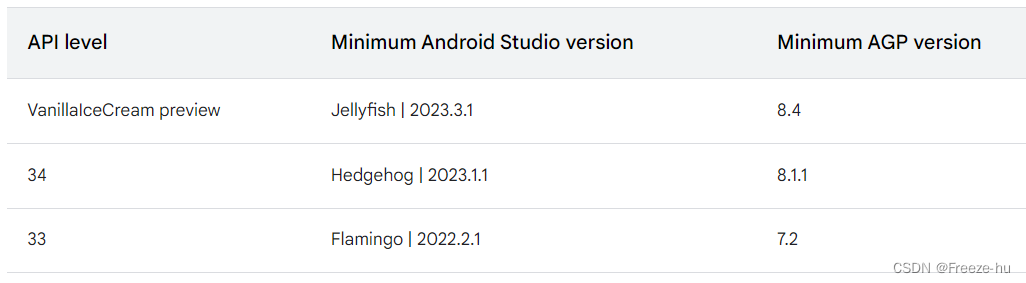
Android studio版本和Android gradle plugin版本对应表
1.Android studio 版本的升级,一个方面上看主要是升级对AGP最高版本的支持 2.那为什么AGP要出高版本呢,主要支持高版本的API,真是一环扣一环...

JavaRedis-主从集群-分片-数据结构-回收处理-缓存问题
一、主从集群 1.主从集群 主从集群读写分离,主能读能写,从只能读,读的数据是同步主的 docker搭建: docker-compose 这里设置网络模式为model,就直接暴露在了宿主机中,就不用映射端口了 不改就是默认的桥…...

Java原生JDBC概览
Java原生JDBC概览 一、是什么? JDBC是Java DataBase Connectivity的缩写,它是Java程序访问数据库的标准接口。 Java代码并不是直接通过TCP连接去访问数据库,而是通过JDBC接口来访问,而JDBC接口则通过JDBC驱动来实现对数据库的访…...

C# 跨线程访问UI组件,serialPort1串口接收数据
在Windows应用程序(例如WinForms或WPF)中,UI组件(如按钮、文本框等)都在主线程(也称为UI线程)上运行。当你在一个非UI线程(例如,一个后台线程或者网络请求线程࿰…...
D - New Friends(AtCoder Beginner Contest 350)
题目链接: D - New Friends (atcoder.jp) 题目大意: 题目解析: 题目的大致意思: 假如A和B是朋友 B和C也是朋友 那么当A和C不是朋友的时候 可以通过B让A和C也成为朋友 问你增加了多少对的朋友关系 题目分析: 咱们可以从图论去考虑 当这一群是一个连通块 那么这一群点(人) 都…...
)
【FAQ】HarmonyOS SDK 闭源开放能力 —Account Kit(2)
1.问题描述: 怎么判断登录的华为帐号有变动? 解决方案: 华为帐号登录成功后会返回唯一标识OpenID和UnionID,如果切换不同的华为帐号登录,这个唯一标识会变。 OpenID是华为帐号用户在不同类型的产品的身份ID&#x…...
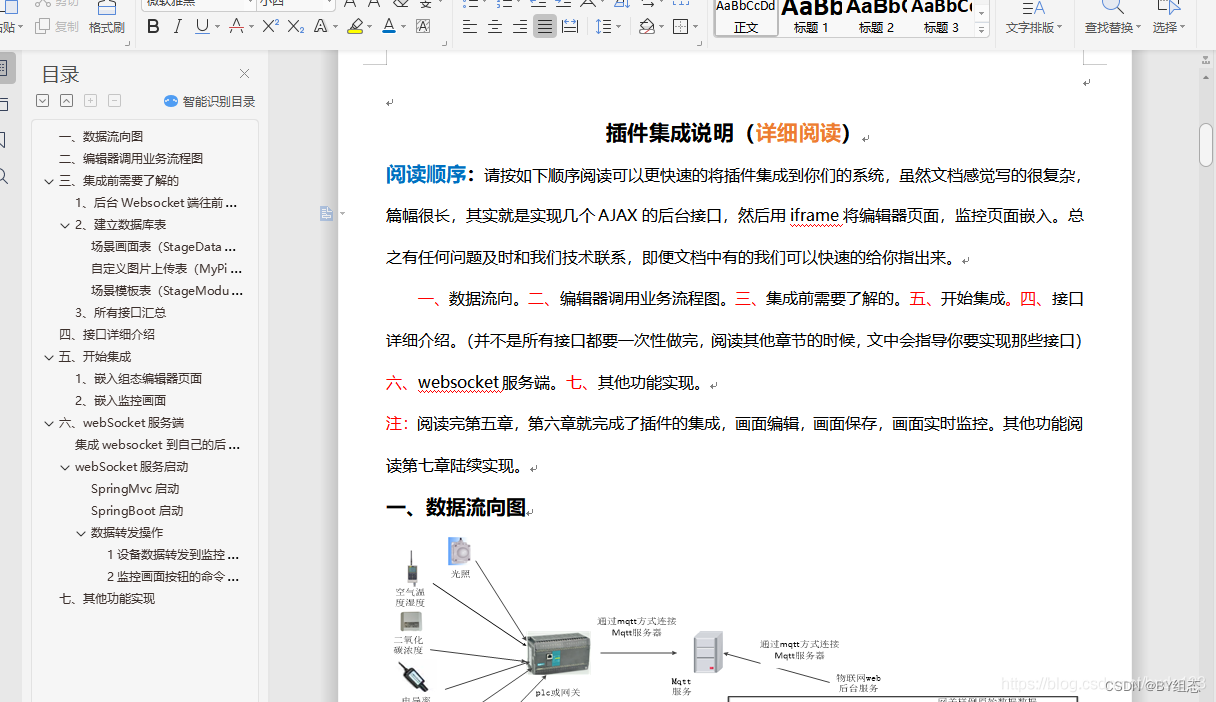
Web组态可视化编辑器 快速绘制组态图
演示地址:by组态[web组态插件] 随着工业智能制造的发展,工业企业对设备可视化、远程运维的需求日趋强烈,传统的单机版组态软件已经不能满足越来越复杂的控制需求,那么实现Web组态可视化界面成为了主要的技术路径。 行业痛点 对于…...

怎样在网上赚点零花钱?推荐十个正规的赚钱兼职平台
今天要和大家探讨一个激动人心的话题——网络赚钱。在这个互联网日新月异的时代,网络赚钱已经变成了触手可及的现实。如果你正打算在网上赚取一些额外收入,那么这篇文章绝对值得一读! 在这个信息泛滥的时代,网络赚钱的机遇随处可…...

手动操作很麻烦?试试这个自动加好友神器吧!
你是不是也觉得手动逐一输入号码或是微信号,再搜索添加很麻烦?试试这个自动加好友神器——个微管理系统,帮助你省去繁琐的手工操作,节省时间和精力。 首先,在系统上登录微信号,无论你有多少个微信号&#…...

金额转大写
金额转大写 /*** 金额转大写* param n* returns {string}*/ export const moneyUppercase (n) > {let fraction [角, 分];let digit [零, 壹, 贰, 叁, 肆,伍, 陆, 柒, 捌, 玖];let unit [[圆, 万, 亿],[, 拾, 佰, 仟]];let head n < 0 ? 欠 : ;n Math.abs(n);let…...

vue的axios配置超时时间;单个接口配置响应时间
vue项目中axios请求统一配置了超时时间,单独接口请求时重设超时时间 根据官网推荐:axios中文文档 1.配置的优先顺序 配置会以一个优先顺序进行合并。这个顺序是:在 lib/defaults.js 找到的库的默认值,然后是实例的 defaults 属性&…...
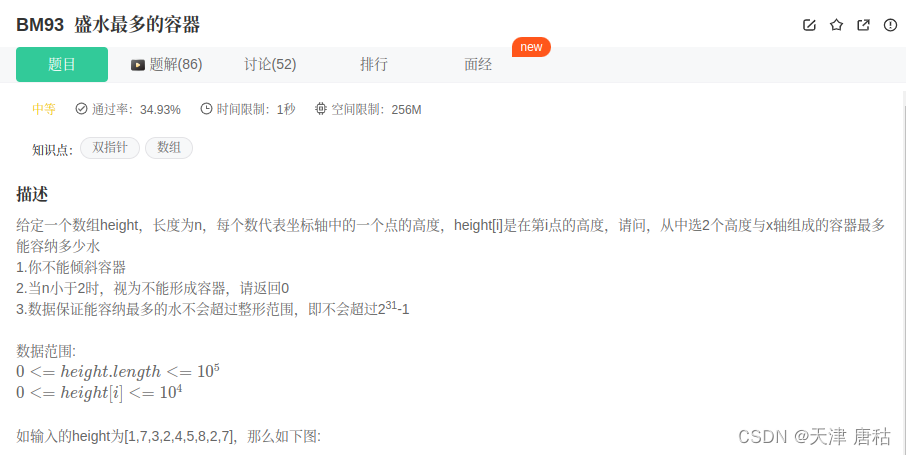
leetcode-盛水最多的容器-109
题目要求 思路 1.正常用双循环外循环i从0开始,内循环从height.size()-1开始去计算每一个值是可以的,但是因为数据量太大,会超时。 2.考虑到超时,需要优化一些,比如第一个选下标1,第二个选下标3和第一个选下…...
VMware ESXi中安装Proxmox VE
0、巴拉巴拉 前几天某行业HW,闲暇的时候几个技术人员聊天,臭味相投的聊到自己玩的东西。有个玩家说家里用工作站安装Proxmox VE,然后在上面安装软路由、安装NAS。我以前一直想玩玩,没有付诸行动,所以也想弄个集中的方案…...

Java(其十二)--集合·初级
ArrayList集合 集合有很多种,ArrayList 是最常用的一种,集合的作用相当于C中的STL 最显著的特点就是:自动扩容。 一般定义式 ArrayList list new ArrayList(); //该 list 是可以储存各种类型的数据的,要想约束储存的数据&#x…...

3分钟快速完成Windows 11系统优化:开源神器Win11Debloat完全指南
3分钟快速完成Windows 11系统优化:开源神器Win11Debloat完全指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declut…...

使用Taotoken的OpenAI兼容协议与PythonSDK三分钟完成大模型接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken的OpenAI兼容协议与Python SDK三分钟完成大模型接入 本文面向刚开始接触大模型API的开发者,旨在提供一个清…...

基于VSCode与CMake的G32R501 MCU现代化开发环境搭建实战
1. 项目概述:为什么选择这套组合拳? 最近在折腾极海半导体的G32R501这款MCU,发现身边不少朋友在搭建开发环境时,要么被臃肿的IDE拖慢速度,要么在构建配置上反复踩坑。我自己的习惯是,能用轻量化工具链搞定的…...

Ubuntu 20.04服务器静态网络配置:从Netplan配置到MobaXterm远程连接一条龙
Ubuntu 20.04服务器静态网络配置全流程实战指南 在本地开发环境中搭建Ubuntu服务器时,稳定的网络连接是后续所有操作的基础。不同于桌面版Ubuntu的图形化网络配置,服务器版需要通过配置文件精确控制网络参数。本文将带你从虚拟机网络规划开始࿰…...

HACS极速版终极指南:告别智能家居插件下载龟速的完整解决方案
HACS极速版终极指南:告别智能家居插件下载龟速的完整解决方案 【免费下载链接】integration 🇨🇳 HACS 极速版,无需登陆Github 项目地址: https://gitcode.com/gh_mirrors/int/integration 你是否曾经为了给Home Assistant…...

AI科技日报-2026年5月22日
AI科技日报 日期:2026年5月22日人工智能正在从“会生成”向“会规划、会行动”进化,2026年成为全球AI发展的关键之年。以下为今日重要资讯。 一、大模型竞赛持续升级 OpenAI、谷歌、深度求索等顶尖AI企业正在发布规模更大或效率更高的最新版本大模型。斯…...

Unity风格化山脉系统:程序化生成与运行时自然逻辑
1. 这不是“又一个山地素材包”,而是一套可工业化复用的风格化自然系统你有没有在Unity项目里,拖进一个山体模型,调完材质发现它和场景里其他植被、岩石、雾效完全不搭?或者好不容易调出理想中的晨雾山色,换到另一个光…...

从零到一:打造属于你的智能语音助手完整方案
从零到一:打造属于你的智能语音助手完整方案 【免费下载链接】xiaozhi-esp32-server 本项目为xiaozhi-esp32提供后端服务,帮助您快速搭建ESP32设备控制服务器。Backend service for xiaozhi-esp32, helps you quickly build an ESP32 device control ser…...

对比按量计费与套餐计划在长期项目中的成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与套餐计划在长期项目中的成本差异 在长期技术项目的规划中,成本管理是一个需要持续关注的环节。对于依赖…...

ISME | 中科院动物所金坚石组-呼吁标准化且无批次效应的技术以促进微生物组研究的全球协作
标准化且无批次效应的技术促进微生物组研究的全球协作● 期刊:The ISME Journal [IF 10.0]● DOI:10.1093/ismejo/wrag122● 原文链接:https://doi.org/10.1093/ismejo/wrag122● 第一作者:Muzi Ge (葛沐子)● 通讯作者:Jianshi J…...