Python 全栈体系【四阶】(五十三)
第五章 深度学习
十二、光学字符识别(OCR)
2. 文字检测技术
2.3 DB(2020)
DB全称是Differentiable Binarization(可微分二值化),是近年提出的利用图像分割方法进行文字检测的模型。前文所提到的模型,使用一个水平矩形框或带角度的矩形框对文字进行定位,这种定位方式无法应用于弯曲文字和不规范分布文字的检测。DB模型利用图像分割方法,预测出每个像素的类别(是文字/不是文字),可以用于任意形状的文字检测。如下图所示:

2.3.1 基本流程
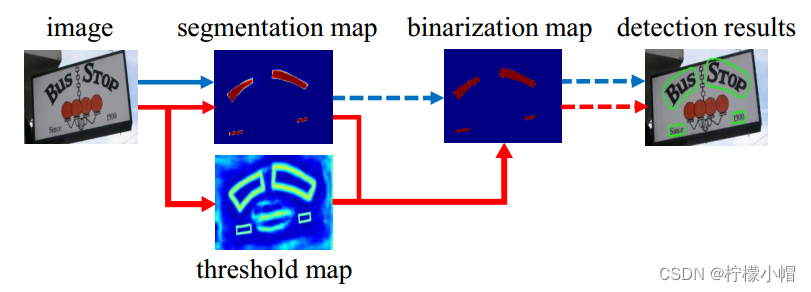
DB之前的一些基于图像分割的文字检测模型,识别原理如上图蓝色箭头所标记流程:
-
第一步,对原图进行分割,预测出每个像素的属于文本/非文本区域的概率;
-
第二步,根据第一步生成的概率,和某个固定阈值进行比较,产生一个二值化图;
-
第三步,采用一些启发式技术(例如像素聚类)将像素分组为文本示例。
DB模型的流程如上图红色箭头所示流程:
-
第一步,对原图进行分割,预测出每个像素的属于文本/非文本区域的概率。同时,预测一个threshold map(阈值图)
-
第二步,采用第一步预测的概率和预测的阈值进行比较(不是直接和阈值比较,而是通过构建一个公式进行计算),根据计算结果,得到二值化图。在计算二值化图过程中,采用了一种二值化的近似函数,称为可微分二值化(Differentiable Binarization),在训练过程中,该函数完全可微分;
-
第三步,根据二值化结果生成分割结果。
2.3.2 标签值生成
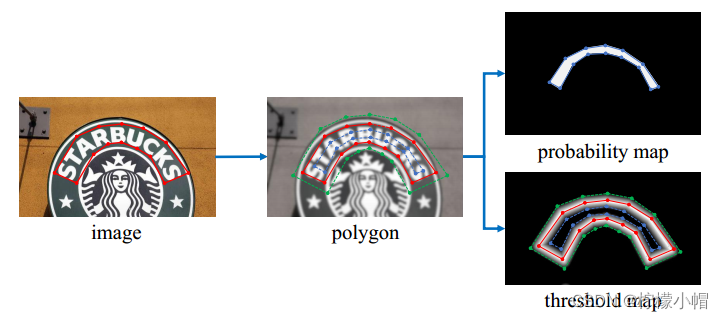
对于每个经过原始标记的样本(上图中第一张图像),采用Vatti clipping algorithm算法(一种用于计算多边形裁剪的算法)对多边形进行缩放,得到缩放后的多边形作为文字边沿(如上图中第二张图像绿色、蓝色多边形所示)。计算公式:
D = A ( 1 − r 2 ) L D = \frac{A(1 - r^2)}{L} D=LA(1−r2)
其中,D是收缩放量,A为多边形面积,L为多边形周长,r是缩放系数,设置为0.4. 根据计算出的偏移量D进行缩小,得到缩小的多边形(第二张图像蓝色边沿所示);根据偏移量D放大,得到放大的多边形(第二张图像绿色边沿所示),两个边沿间的部分就是文字边界。
2.3.3 模型结构
Differentiable Binarization模型结构如下图所示:

模型经过卷积,得到不同降采样比率的特征图,经过特征融合后,产生一组分割概率图、一组阈值预测图,然后微分二值化算法做近似二值化处理,得到预测二值化图。传统的二值化方法一般采用阈值分割法,计算公式为:
B i , j = { 1 , i f P i , j ≥ t 0 , o t h e r w i s e (1) B_{i, j} = \begin{cases} 1,\quad if \ P_{i,j} \ge t \\ 0, \quad otherwise \end{cases} \tag{1} Bi,j={1,if Pi,j≥t0,otherwise(1)
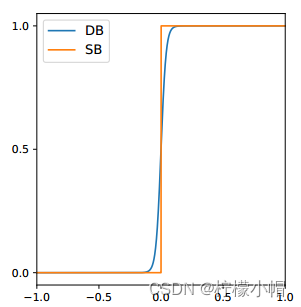
上式描述的二值化方法是不可微分的,导致在训练期间无法与分割网络部分一起优化,为了解决这个问题,DB模型采用了近似阶跃函数的、可微分二值化函数。函数定义如下:
B ^ i , j = 1 1 + e − k ( P i , j − T i , j ) \hat B_{i, j} = \frac{1}{1+e^{-k(P_{i,j} - T_{i, j})}} B^i,j=1+e−k(Pi,j−Ti,j)1
其中, P i , j P_{i,j} Pi,j表示预测概率, T i , j T_{i, j} Ti,j表示阈值,两个值相减后经过系数 K K K放大,当预测概率越大于阈值,则输出值越逼近1。
# 可谓分二值化函数示例
import mathP1 = 0.6 # 预测概率1
P2 = 0.4 # 预测概率2
T = 0.5 # 阈值
K = 50B1 = 1.0 / (1 + pow(math.e, -K * (P1 - T)))
print("B1:", B1) # B1:0.9933 趋近于1B2 = 1.0 / (1 + pow(math.e, -K * (P2 - T)))
print("B2:", B2) # B2:0.00669 趋近于0
2.3.4 损失函数
DB模型损失函数如下所示:
L = L s + α × L b + β × L t L = L_s + \alpha \times L_b + \beta \times L_t L=Ls+α×Lb+β×Lt
其中, L s L_s Ls是预测概率图的loss部分, L b L_b Lb是二值图的loss部分, α \alpha α和 β \beta β值分别设置为1和10. L s L_s Ls和 L b L_b Lb均采用二值交叉熵:
L s = L b = ∑ i ∈ S l y i l o g x i + ( 1 − y i ) l o g ( 1 − x i ) L_s = L_b = \sum_{i \in S_l} y_i log x_i + (1 - y_i) log(1-x_i) Ls=Lb=i∈Sl∑yilogxi+(1−yi)log(1−xi)
上式中 S l S_l Sl是样本集合,正负样本比例为1:3.
L t Lt Lt指经过膨胀后的多边形区域中的像素预测结果和标签值之间的 L 1 L1 L1距离之和:
L t = ∑ i ∈ R d ∣ y i ∗ − x i ∗ ∣ L_t = \sum_{i \in R_d} |y_i ^* - x_i ^*| Lt=i∈Rd∑∣yi∗−xi∗∣
R d R_d Rd值膨胀区域 G d G_d Gd内的像素索引, y i ∗ y_i ^* yi∗是阈值图的标签值。
2.3.5 涉及到的数据集
模型在以下6个数据集下进行了实验:
- SynthText:合成数据集,包含80万张图像,用于模型训练
- MLT-2017:多语言数据集,包含9种语言,7200张训练图像,1800张验证图像及9000张测试图像,用于模型微调
- ICDAR 2015:包含1000幅训练图像和500幅测试图像,分辨率720*1280,提供了单词级别标记
- MSRA-TD500:包含中英文的多语言数据集,300张训练图像及200张测试图像
- CTW1500:专门用于弯曲文本的数据集,1000个训练图像和500个测试图像,文本行级别标记
- Total-Text:包含各种形状的文本,及水平、多方向和弯曲文字,1255个训练图像和300个测试图像,单词级别标记
为了扩充数据量,论文采用了随机旋转(-10°~10°角度内)、随机裁剪、随机翻转等策略进行数据增强。

2.3.6 效果
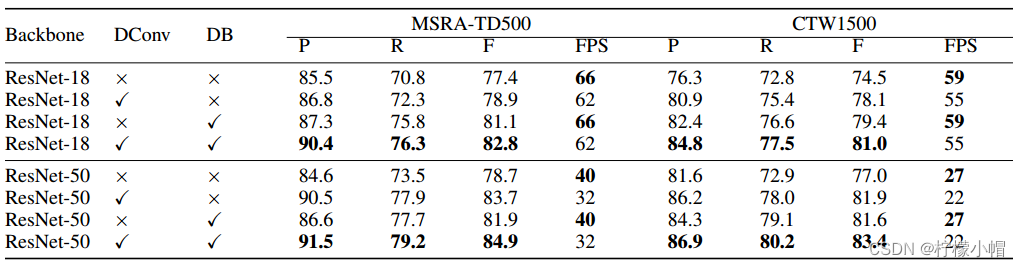
- 不同设置结果比较,“DConv”表示可变形卷积。“P”、“R”和“F”分别表示精度、召回率和F度量。
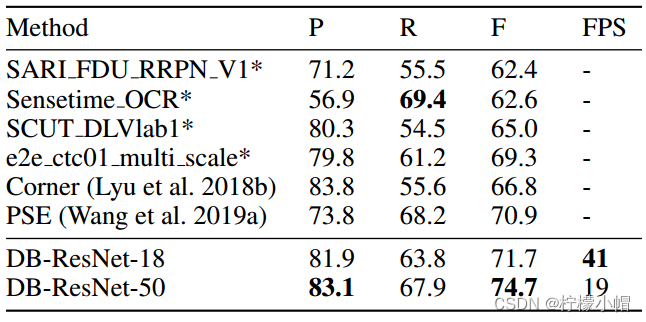
- Total-Text数据集下测试结果,括号中的值表示输入图像的高度,“*”表示使用多尺度进行测试,“MTS”和“PSE”是Mask TextSpotter和PSENet的缩写

- CTW1500数据集下测试结果。括号中的值表示输入图像的高度。
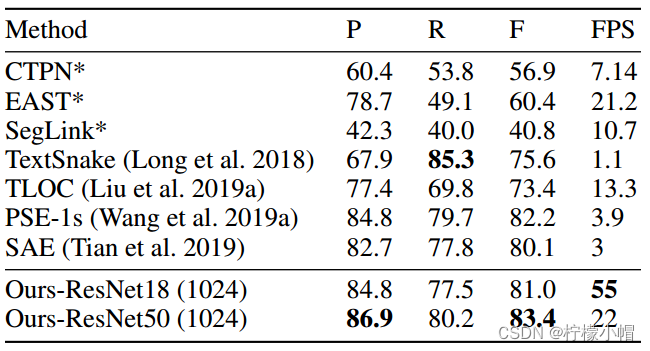
- ICDAR 2015数据集下测试结果。括号中的值表示输入图像的高度,“TB”和“PSE”是TextBoxes++和PSENet的缩写。
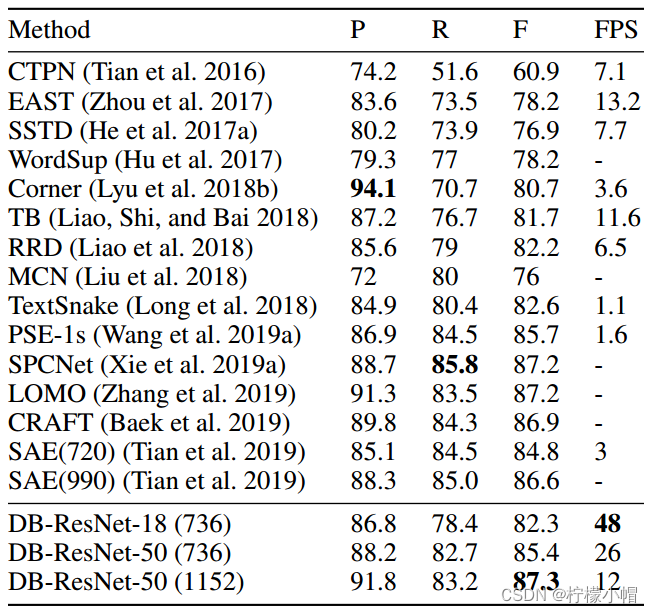
- MSRA-TD500数据集下测试结果。括号中的值表示输入图像的高度。
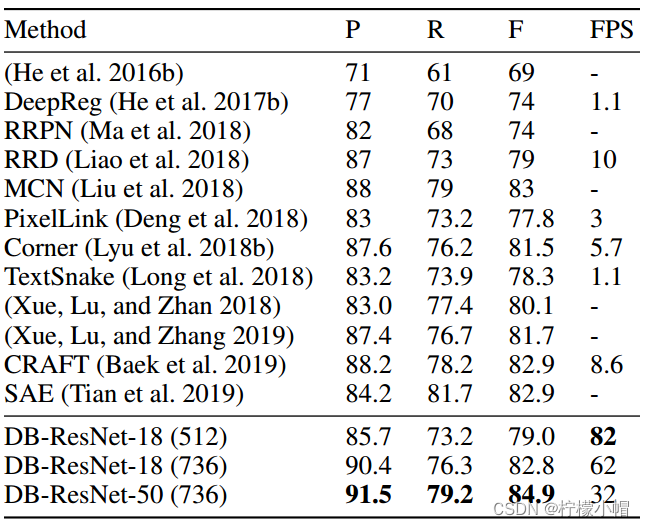
- MLT-2017数据集下测试结果。“PSE”是PSENet的缩写。
2.3.7 结论
- 能有效检测弯曲文本、不规范分布文本
- 具有较好的精度和速度
- 局限:不能处理文本中包含文本的情况
相关文章:
Python 全栈体系【四阶】(五十三)
第五章 深度学习 十二、光学字符识别(OCR) 2. 文字检测技术 2.3 DB(2020) DB全称是Differentiable Binarization(可微分二值化),是近年提出的利用图像分割方法进行文字检测的模型。前文所提…...

民国漫画杂志《时代漫画》第27期.PDF
时代漫画27.PDF: https://url03.ctfile.com/f/1779803-1248635258-b6a842?p9586 (访问密码: 9586) 《时代漫画》的杂志在1934年诞生了,截止1937年6月战争来临被迫停刊共发行了39期。 ps: 资源来源网络!...
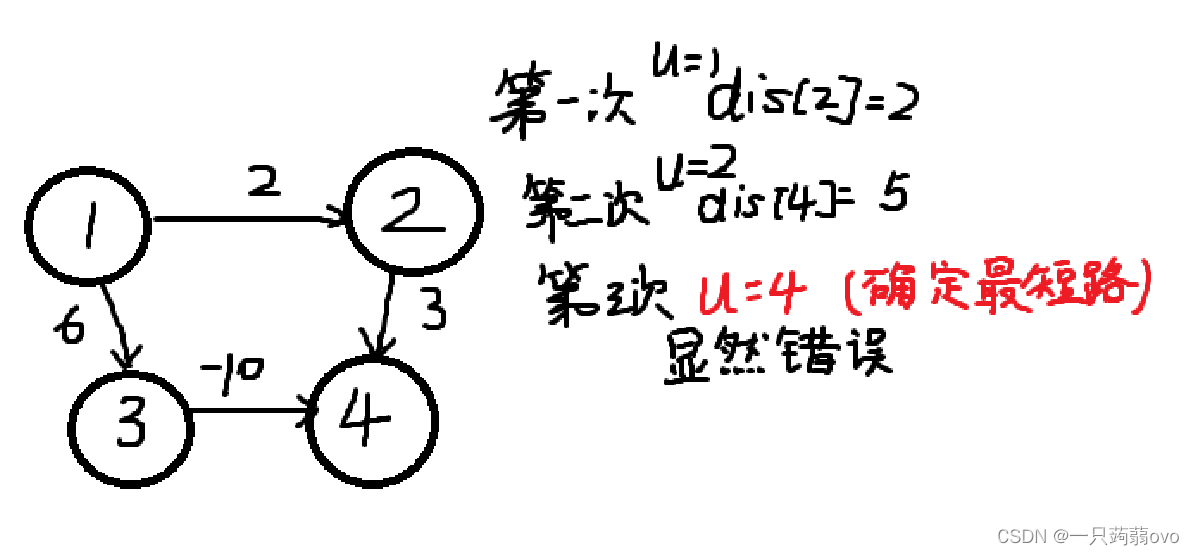
图论(四)—最短路问题(Dijkstra)
一、最短路 概念:从某个点 A 到另一个点B的最短距离(或路径)。从点 A 到 B 可能有多条路线,多种距离,求其中最短的距离和相应路径。 最短路径分类: 单源最短路:图中的一个点到其余各点的最短路径…...
用友NC linkVoucher SQL注入漏洞复现
0x01 产品简介 用友NC是由用友公司开发的一套面向大型企业和集团型企业的管理软件产品系列。这一系列产品基于全球最新的互联网技术、云计算技术和移动应用技术,旨在帮助企业创新管理模式、引领商业变革。 0x02 漏洞概述 用友NC /portal/pt/yercommon/linkVoucher 接口存在…...

部署Prometheus + Grafana实现监控数据指标
1.1 Prometheus安装部署 Prometheus监控服务 主机名IP地址系统配置作用Prometheus192.168.110.27/24CentOS 7.94颗CPU 8G内存 100G硬盘Prometheus服务器grafana192.168.110.28/24CentOS 7.94颗CPU 8G内存 100G硬盘grafana服务器 监控机器 主机名IP地址系统配置k8s-master-0…...
GEE27:遥感数据可用数据源计算及条带号制作
1.写在前面 🌍✨今天读了一篇关于遥感数据可用数据源计算及条带号制作的文章,结合着自己的理解,添加了一些内容。 2.GEE代码 📚📚这段代码的主要作用是利用Google Earth Engine平台,通过分析Landsat 8影…...

FURNet问题
1. 为什么选择使用弱监督学习? 弱监督学习减少了对精确标注数据的依赖,这在医学图像处理中尤为重要,因为高质量标注数据通常需要大量专业知识和时间。弱监督学习通过利用少量标注数据或粗略标注数据来训练模型,降低了数据准备的成…...
抖音小店怎么对接达人合作?达人带货的细节分享,附邀约达人话术
大家好,我是电商花花 人有多大胆,地就有多大产,做抖店想要出单,爆单,那必须要对接大量的达人来帮我们带货,抖音小店就是直播电商,帮我们对接的达人越多,出单就越多。 所以做抖店如…...
迈向未来:Web3 技术开发的无限可能
在当今的数字时代,互联网技术日新月异,推动着各行各业的变革与发展。从Web1.0的信息发布,到Web2.0的社交互动,互联网的每一次进化都为人们的生活带来了深远的影响。如今,Web3的到来正在开启一个全新的时代,…...
)
Python应用开发——30天学习Streamlit Python包进行APP的构建(2)
🗓️ 天 14 Streamlit 组件s Streamlit 组件s 是第三方的 Python 模块,对 Streamlit 进行拓展 [1]. 有哪些可用的 Streamlit 组件s? 好几十个精选 Streamlit 组件s 罗列在 Streamlit 的网站上 [2]. Fanilo(一位 Streamlit 创作者)在 wiki 帖子中组织了一个很棒的 St…...

Leecode热题100---46:全排列(递归)
题目: 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 思路: 元素交换函数递归: 通过交换元素来实现全排列。即对于[x, nums.size()]中的元素,for循环遍历每个元素分别成…...

Android 多语言
0. Locale方法 Locale locale Locale.forLanguageTag("zh-Hans-CN"); 执行如下方法返回字符串如下: 方法 英文下执行 中文下执行 备注 getLanguage()zhzhgetCountry()CNCNgetDisplayLanguage()zh中文getDisplayCountry()CN中国getDisplayName()zh (…...

Thingsboard规则链:Message Type Filter节点详解
一、Message Type Filter节点概述 二、具体作用 三、使用教程 四、源码浅析 五、应用场景与案例 智能家居自动化 工业设备监控 智慧城市基础设施管理 六、结语 在物联网(IoT)领域,数据处理与自动化流程的实现是构建智能系统的关键。作…...
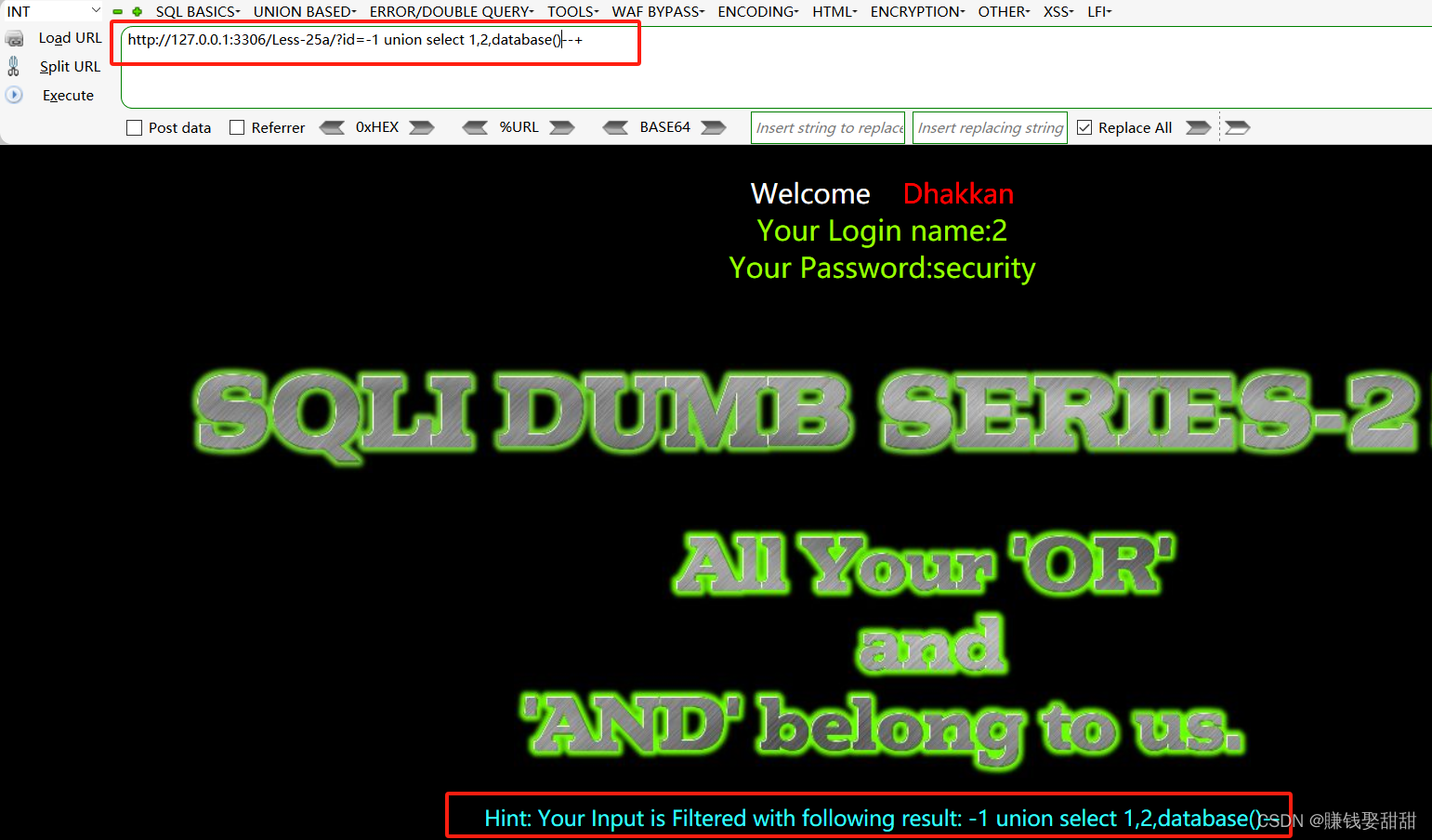
SQLI-labs-第二十五关和第二十五a关
目录 第二十五关 1、判断注入点 2、判断数据库 3、判断表名 4、判断字段名 5、获取数据库的数据 第二十五a关 1、判断注入点 2、判断数据库 第二十五关 知识点:绕过and、or过滤 思路: 通过分析源码和页面,我们可以知道对and和or 进…...

Windows、Linux添加路由
目录 一、Windows添加路由 1. 查看路由规则 2. 添加路由规则 3. 添加默认路由 4. 删除路由规则 二、Linux添加路由 1. 查看路由 2. 添加路由 3. 删除路由 4. 修改路由 5. 临时路由 6. 默认网关设置 一、Windows添加路由 1. 查看路由规则 route print 2. 添加…...

Swift 初学者交心:在 Array 和 Set 之间我们该如何抉择?
概述 初学 Swift 且头发茂密的小码农们在日常开发中必定会在数组(Array)和集合(Set)两种类型之间的选择中“摇摆不定”,这也是人之常情。 Array 和 Set 在某些方面“亲如兄弟”,但实际上它们之间却有着“云…...

C++ 类模板 函数模板
类模板 #include <bits/stdc.h> using namespace std; //多少变量就写多少个 template<typename T1, typename T2> class Cat { public:Cat(){}Cat(T1 name, T2 age){this->age age;this->name name;}void print(){cout << this->name << …...

OTP8脚-全自动擦鞋机WTN6020-低成本语音方案
一,产品开发背景 首先,随着人们生活质量的提升,对鞋子的保养需求也日益增加。鞋子作为人们日常穿着的重要组成部分,其清洁度和外观状态直接影响到个人形象和舒适度。因此,一种能够自动清洁和擦亮鞋子的设备应运而生&am…...
GpuMall智算云:meta-llama/llama3/Llama3-8B-Instruct-WebUI
LLaMA 模型的第三代,是 LLaMA 2 的一个更大和更强的版本。LLaMA 3 拥有 35 亿个参数,训练在更大的文本数据集上GpuMall智算云 | 省钱、好用、弹性。租GPU就上GpuMall,面向AI开发者的GPU云平台 Llama 3 的推出标志着 Meta 基于 Llama 2 架构推出了四个新…...
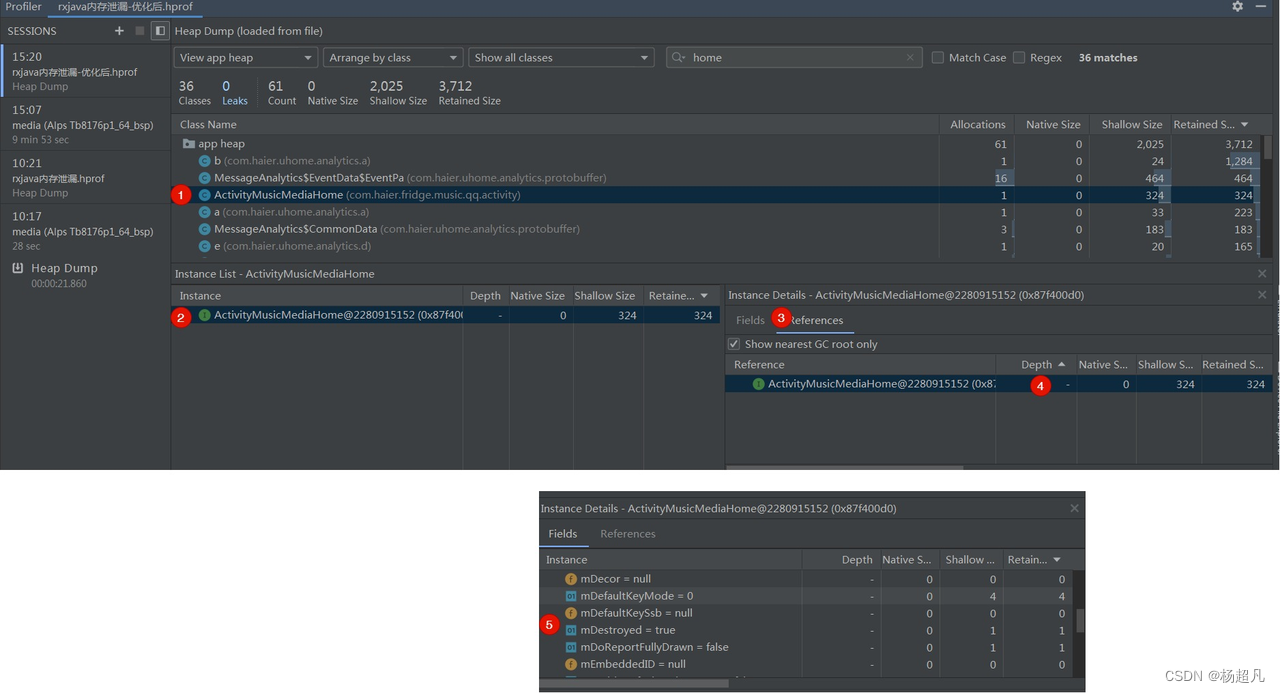
内存泄漏案例分享4-异步任务流内存泄漏
案例4——异步任务内存泄漏 异步任务,代指起子线程异步完成一些数据操作、网络接口请求等,通常会使用以下API: Runnbale,Thread,线程池RxJavaHandlerThread 而这些异步任务很有可能操作内存泄漏,下面我们以Rxjava为…...

龙芯3A5000工业主板实战:从硬件部署到软件生态的国产化替代指南
1. 项目概述:一颗“中国芯”的工业级落地 最近,圈子里关于国产自主平台的消息又热闹了起来。这次的主角,是集特智能新推出的一款工业主板,核心搭载了龙芯3A5000处理器和7A2000桥片。对于长期深耕工业控制、边缘计算、网络安全这些…...

WarcraftHelper:三步搞定魔兽争霸3兼容性难题的终极解决方案
WarcraftHelper:三步搞定魔兽争霸3兼容性难题的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争霸3在现…...

Rust异步编程深度实战
Rust异步编程深度实战:从async/await到Tokio运行时原理 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言:为什么Rust异步编程让人又爱又恨? 写了两年Rust异步代码,我最大的感受是:Rust的异步编程模型是所有语言中最"较真"的。它不允许你偷懒…...

在Node.js服务中集成Taotoken实现智能问答与内容生成功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现智能问答与内容生成功能 对于Node.js后端开发者而言,为应用添加智能问答或内容生成能…...

3步掌握Sabaki围棋软件:从新手到高手的完整指南
3步掌握Sabaki围棋软件:从新手到高手的完整指南 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki 在围棋的智慧世界里,一款优秀的软件能让您的学习和…...

别再手动刷新了!用HomePage v0.8.2+Docker Compose,一键监控所有容器和网站状态
别再手动刷新了!用HomePage v0.8.2Docker Compose,一键监控所有容器和网站状态 每次登录服务器都要挨个检查容器是否运行正常?网站挂了却要等用户反馈才知道?这种被动式运维早该淘汰了。今天介绍的这套方案,能让你的H…...

回归模型评估实战指南:从指标选择到业务决策
1. 这不是“背公式”手册,而是回归模型评估的实战决策地图 你训练完一个房价预测模型,R0.87,MAE2.3万,RMSE3.8万——然后呢?是立刻上线?还是再调参?还是换数据?还是干脆换算法&#…...

Axios内存泄漏:云原生Node.js服务的静默雪崩
1. 这不是漏洞公告,而是一次云原生环境下的“静默雪崩”你有没有遇到过这样的情况:服务在本地跑得好好的,一上Kubernetes就隔三差五OOM,Pod反复重启,监控里内存曲线像心电图一样剧烈波动,但代码里没写大对象…...

Monocle投票系统实现原理:构建高效的帖子排名算法
Monocle投票系统实现原理:构建高效的帖子排名算法 【免费下载链接】monocle Link and news sharing 项目地址: https://gitcode.com/gh_mirrors/mon/monocle Monocle是一个功能强大的链接和新闻聚合平台,其核心功能之一就是智能投票排名系统。这篇…...

如何用Blender3mfFormat插件完美处理3MF文件:终极3D打印工作流指南
如何用Blender3mfFormat插件完美处理3MF文件:终极3D打印工作流指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否曾经在Blender中为3D打印工作流而烦…...