知识融合概述
文章目录
- 知识融合
- 知识融合过程
- 研究现状
- 技术发展趋势
知识融合
知识融合的概念最早出现在1983年发表的文献中,并在20世纪九十年代得到研究者的广泛关注。而另一种知识融合的定义是指对来自多源的不同概念、上下文和不同表达等信息进行融合的过程认为知识融合的目标是产生新的知识,是对松耦合来源中的知识进行集成,构成一个合成的资源,用来补充不完全的知识和获取新知识。在总结众多知识融合概念的基础上认为知识融合是知识组织与信息融合的交叉学科,它面向需求和创新,通过对众多分散、异构资源上知识的获取、匹配、集成、挖掘等处理,获取隐含的或有价值的新知识,同时优化知识的结构和内涵,提供知识服务。
知识融合过程
知识融合是一个不断发展变化的概念,尽管以往研究人员的具体表述不同、所站角度不同、强调的侧重点不同,但这些研究成果中还是存在很多共性,这些共性反应了知识融合的固有特征,可以将知识融合与其他类似或相近的概念区分开来。知识融合是面向知识服务和决策问题,以多源异构数据为基础,在本体库和规则库的支持下,通过知识抽取和转换获得隐藏在数据资源中的知识因子及其关联关系,进而在语义层次上组合、推理、创造出新知识的过程,并且这个过程需要根据数据源的变化和用户反馈进行实时动态调整。从流程角度对知识融合概念进行分解,如下图所示。
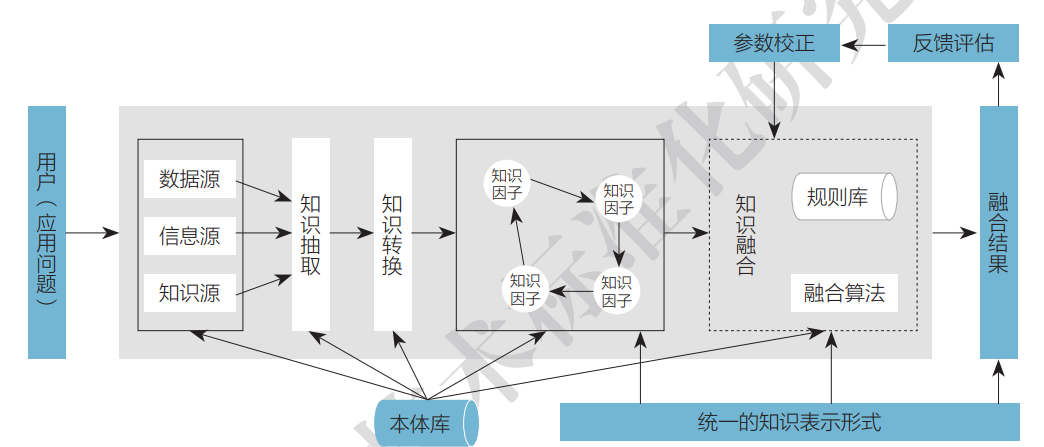
研究现状
知识融合从融合层面划分可以分为数据层知识融合与概念层知识融合,数据层知识融合主要研究实体链接、实体消解,是面向知识图谱实例层的知识融合;概念层知识融合主要研究本体对齐、跨语言融合等技术。
实体链接问题是数据层知识融合研究的主要任务,其核心是构建多类型多模态上下文及知识的统一表示,并建模不同信息、不同证据之间的相互交互,主要的实体链接方法有:基于实体知识的链接方法、基于篇章主题的链接方法和融合实体知识与篇章主题的实体链接方法。
概念层知识融合是对多个知识库或者信息源在概念层进行模式对齐的过程。本体对齐或者本体匹配是概念层知识融合主要研究任务,是指确定本体概念之间映射关系的过程。本体匹配可以分为单语言本体匹配和跨语言本体匹配,单语言本体匹配是指同一自然语言中本体的对齐映射,跨语言本体匹配是指从两个或多个独立的语言本体中建立本体之间映射关系的过程。本体匹配的研究核心就在于如何通过本体概念之间的相似性度量,发现异构本体间的匹配关系,本体匹配基本方法包括基于结构的方法、基于实例的方法、基于语言学的匹配算法、基于文本的匹配算法和基于已知本体实体联结的匹配算法。
在大数据时代背景下,如何将跨语言的知识图谱进行对齐与融合,实现知识的全球共享,为跨语言知识服务提供便利,是知识图谱进一步研究的过程中需要解决的问题。跨语言知识图谱研究的目的是构建一个包含当前重要知识库的大规模跨语言知识库,提高不同语言之间链接数据的国际化以及知识共享全球化,便于跨语言信息检索、机器翻译和跨语言知识问答等跨语言处理任务的研究与应用。构建了一个有42万中英跨语言实体链接的双语言知识图谱(XLORE2),自动化融合了来自维基百科、百度百科和互动百科的信息。
现有的知识融合工具包括:Falcon-AO、YAM++、Dedupe等。以Falcon-AO为例,其是由南京大学计算机软件新技术国家重点实验室开发的一个基于Java的自动本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。Falcon-AO系统采用了相似度组合策略,首先使用PMO进行分而治之,然后使用语言学算法(V-Doc、I-Sub)进行处理,然后使用结构学算法(GMO)接收前两者结果再做处理,最后连通前面两者的输出使用贪心算法进行选取。
技术发展趋势
尽管知识融合已经在学术和工业应用中取得了非常显著的成效,然而随着网络社会数据特征、跨语言融合、知识规模增加等带来挑战越发紧迫,针对短文本及资源缺乏环境下的实体链接方法、融合先验知识的深度学习端到端实体链接方法、大规模本体的高效匹配方法将成为未来研究的重要趋势。
传统的实体链接任务主要是针对长文档,长文档拥有在写的上下文信息能辅助实体的歧义消解并完成链接。而由于日常生活中人们在社交网络中常常会产生大量短文本数据,相比之下,短文本的实体链接存在口语化严重、短文本上下文语境不丰富等巨大挑战,因而面向短文本的实体链接方法研究将会成为未来的研究热点。另外目前绝大部分的实体链接模型依赖于有监督模型,需要大量标签数据集训练来达到实用目的。因此短文本及资源缺乏环境下,基于无监督/半监督和迁移学习的实体链接模型是解决问题的关键。
今年来,基于深度学习模型(如BiLSTM-CRF)在实体链接任务上取得了较大的进展,同时展现出了巨大的应用潜力,然而基于深度学习的算法训练需要大量标注数据集,缺少面向特定领域特点和任务的针对性设计。另一方面当前实体链接方法易受到实体识别等前序过程的误差影响,因此结合先验知识训练端到端深度学习实体链接模型成为未来的一大研究趋势。针对这个问题,一方面,当前许多算法尝试已经证明结合先验知识的思路在实体链接任务中的有效性,如在深度学习模型中增加句法结构、语言学知识、特定领域任务约束、现有知识库知识和特征结构等,如何更好的结合有效利用这些先验知识是提升实体链接算法性能的有效手段。同时设计基于端到端的深度学习模型将有助于降低实体链接过程中的误差传播效应,提高实体链接准确度。
随着当前各类型知识库的出现和知识规模的快速增长,而由于通常本体匹配的计算复杂度与本体规模成正比,因此大规模跨语言本体匹配成为知识库融合的重大挑战,主要面临的挑战有:大规模本体匹配的快速并行计算问题和人机协同匹配问题。针对这个问题主要的思路有:①研究基于分布式处理技术的大规模本体匹配分布式处理算法,如研究利用MapReduce、GPU等技术的并行匹配算法,提高匹配效率;②研究利用现有本体匹配结果实现潜在本体匹配的方法,同时利用启发式相似度计算方法提高计算效率;③通过对实体匹配进行预剪枝,预先过滤不匹配的实体对,避免本体之间一对一的相似度计算。
相关文章:
知识融合概述
文章目录 知识融合知识融合过程研究现状技术发展趋势 知识融合 知识融合的概念最早出现在1983年发表的文献中,并在20世纪九十年代得到研究者的广泛关注。而另一种知识融合的定义是指对来自多源的不同概念、上下文和不同表达等信息进行融合的过程认为知识融合的目标是…...

LIO-EKF: High Frequency LiDAR-Inertial Odometry using Extended Kalman Filters
一、论文摘要 里程计估计是每个需要在未知环境中导航的自主系统的关键要素。在现代移动机器人中,3D LiDAR 惯性系统通常用于执行此任务。通过融合 LiDAR 扫描和 IMU 测量,这些系统可以减少因顺序注册各个 LiDAR 扫描而引起的累积漂移,并提供稳…...
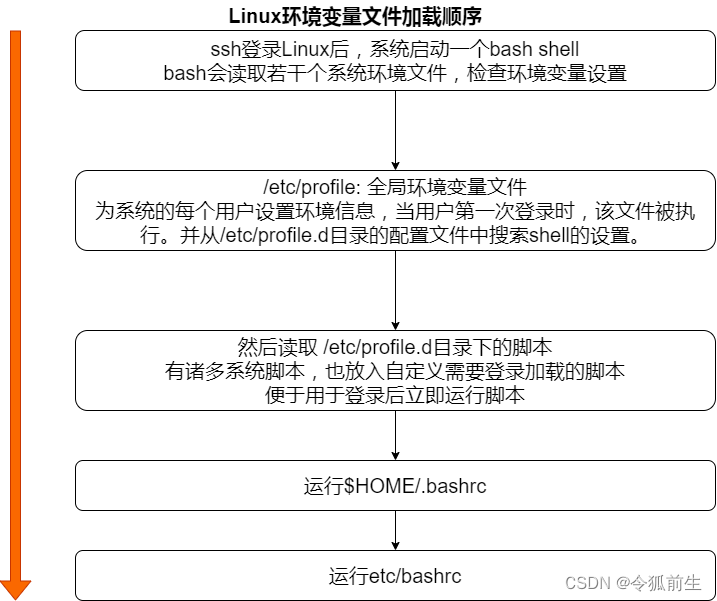
Shell脚本学习笔记(更新中...)
一、什么是shell shell的作用是: 解释执行用户输入的命令程序等。 用户输入一条命令,shell就解释一条。 键盘输入命令,LInux给与响应的方式,称之为交互式。 shell是一块包裹着系统核心的壳,处于操作系统的最外层&a…...

leetcode 210.课程表II
思路:拓补排序 其实就是对于第一个题的问题变了一个问法,上一个题本质上是求有没有环,这道题本质上就是让你求出来符合没有环的路径输出而已,本质上没有什么区别。 不同就在于这里需要你额外开一个数组用来存储你遍历这个有向图…...

SpringBootTest测试框架五
示例 package com.xxx;import com.xxx.ut.AbstractBasicTest; import com.xxx.ut.uttool.TestModel; import...

赛事|基于SprinBoot+vue的CSGO赛事管理系统(源码+数据库+文档)
CSGO赛事管理系统 目录 基于SprinBootvue的CSGO赛事管理系统 一、前言 二、系统设计 三、系统功能设计 1系统功能模块 2管理员功能模块 3参赛战队功能模块 4合作方功能模块 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取&…...

线性化技巧:绝对值变量的线性化
文章目录 1. 问题2. 线性化3. 缺少 x i x i − 0 x_i^ \times x_i^- 0 xixi−0 有什么问题4. 延伸思考5. 参考文献 1. 问题 以方述诚老师课件中的案例为例: m a x 3 x 1 − 2 x 2 − 4 ∣ x 3 ∣ s . t . − x 1 2 x 2 ≤ − 5 3 x 2 − x 3 ≥ 6 2 x 1 …...

List基本使用(C++)
目录 1.list的介绍 2.list的使用 list的构造 list的size() 和 max_size() list遍历操作 list元素修改操作 assign()函数 push_front(),push_back 头插,尾插 pop_front() pop_back 头删尾删 insert()函数 swap()函数 resize()函数 clear()函数 list类数…...

ELK 日志监控平台(一)- 快速搭建
文章目录 ELK 日志监控平台(一)- 快速搭建1.ELK 简介2.Elasticsearch安装部署3.Logstash安装部署4.Kibana安装部署5.日志收集DEMO5.1.创建SpringBoot应用依赖导入日志配置文件 logback.xml启动类目录结构启动项目 5.2.创建Logstash配置文件5.3.重新启动L…...

工作中写单片机代码,与学校里有什么不同?
来聊聊我的经历,提供几个提升方向,亲测有效,希望能让你少走几年弯路。 10几年前,还没参加工作的时候,主要是玩玩开发板,也接触不到实际产品的代码,很好奇那些产品级的代码是怎样的。 第一份工作…...
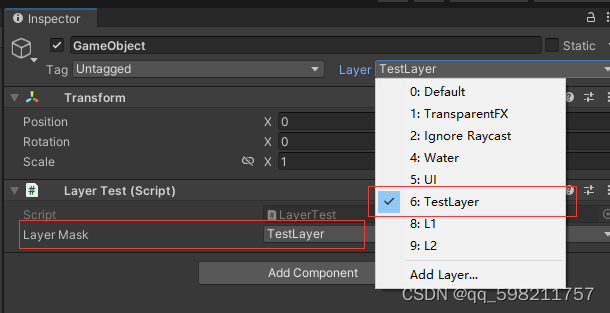
Unity LayerMask避坑笔记
今天使用Physics2D.OverlapAreaNonAlloc进行物理检测时候,通过LayerMask.NameToLayer传入了int值的LayerMask,结果一直识别不到,经过Debug才找到问题,竟是LayerMask的“值”传输有问题,记录一下。 直接贴代码输出结果&…...

(原创)从右到左排列RecycleView的数据
问题的提出 当我们写一个Recycleview时,默认的效果大概是这样的: 当然,我们也可以用表格布局管理器GridLayoutManager做成这样: 可以看到,默认的绘制方向是: 从左到右,从上到下 那么问题来了…...
【C语言】数据指针地址的取值、赋值、自增操作避坑
【C语言】数据指针的取值、赋值、自增操作避坑 文章目录 指针地址指针自增指针取值、赋值附录:压缩字符串、大小端格式转换压缩字符串浮点数压缩Packed-ASCII字符串 大小端转换什么是大端和小端数据传输中的大小端总结大小端转换函数 指针地址 请看下列代码&#…...

Java进阶-SpringCloud使用BeanUtil工具类简化对象之间的属性复制和操作
在Java编程中,BeanUtil工具类是一种强大且便捷的工具,用于简化对象之间的属性复制和操作。本文将介绍BeanUtil的基本功能,通过详细的代码示例展示其应用,并与其他类似工具进行对比。本文还将探讨BeanUtil在实际开发中的优势和使用…...

【ES6】ECMAS6新特性概览(一):变量声明let与const、箭头函数、模板字面量全面解析
🔥 个人主页:空白诗 🔥 热门专栏:【JavaScript】 文章目录 🌿 引言一、 let 和 const - 变量声明的新方式 🌟📌 var的问题回顾📌 let的革新📌 const的不变之美 二、 Arro…...
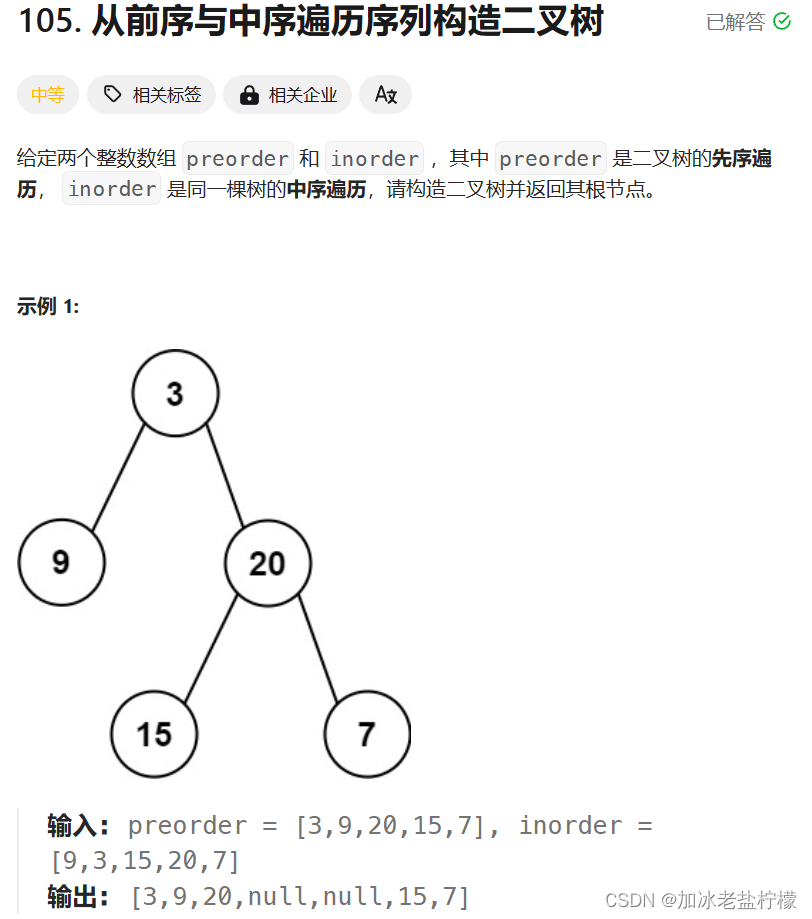
刷题之从前序遍历与中序遍历序列构造二叉树(leetcode)
从前序遍历与中序遍历序列构造二叉树 前序遍历:中左右 中序遍历:左中右 前序遍历的第一个数必定为根节点,再到中序遍历中找到该数,数的左边是左子树,右边是右子树,进行递归即可。 #include<vector>…...
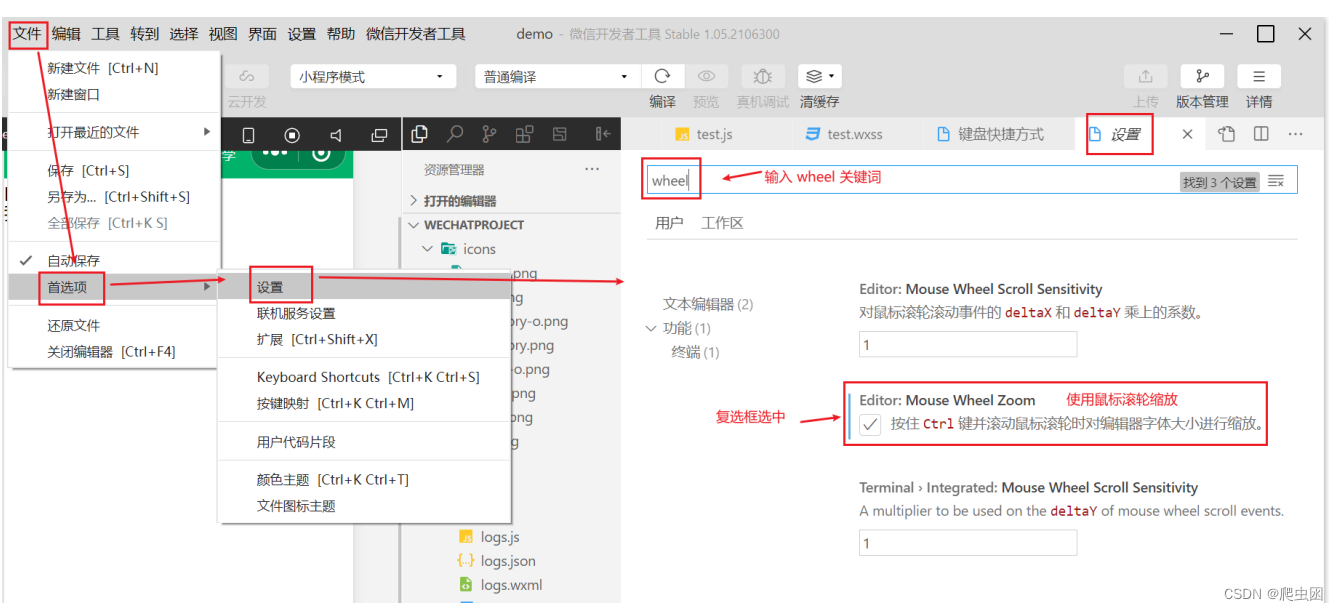
微信小程序--微信开发者工具使用小技巧(3)
一、微信开发者工具使用小技巧 1、快速创建小程序页面 在app.json中的pages配置项,把需要创建的页面填写上去 2、快捷键使用 进入方式 1: 文件–>首选项–> keyboard shortcuts 进入快捷键查看与设置 进入方式 2: 设置–>快捷键…...

JDBC的 PreparedStatement 的用法和解释
文章目录 前言1、封装数据库连接和关闭操作数据库配置文件 config.properties 2、批量添加操作3、查询操作4、修改和删除操作总结 前言 PreparedStatement是预编译的,对于批量处理可以大大提高效率. 也叫JDBC存储过程 1、封装数据库连接和关闭操作 package org.springblade.m…...

LeetCode 面试150
最近准备面试,我以前不愿意面对的 现在保持一颗本心,就是专注于算法思想,语言基础的磨炼; 不为速成,不急功近利的想要比赛,或者为了面试。 单纯的本心,体验算法带来的快乐,是一件非常…...

xmake+xrepo自建仓库添加交叉编译工具链
xmakexrepo自建仓库添加交叉编译工具链 最近想将交叉编译工具链放到xrepo自建仓库中,在xmake中引用,方便多个电脑快速实现交叉编译。 xmake官方文档感觉不够详细,折腾了好久,这里做个记录。 基本步骤如下: 添加自建…...

如何构建现代自托管音乐播放器:音乐爱好者的完整使用指南
如何构建现代自托管音乐播放器:音乐爱好者的完整使用指南 【免费下载链接】feishin A modern self-hosted music player. 项目地址: https://gitcode.com/gh_mirrors/fe/feishin 在数字音乐时代,音乐爱好者面临着数据隐私、平台依赖和个性化体验的…...

Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁?
Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁? 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经因为Adobe Crea…...

Meteor-Ionic 模态框和弹出层:创建优雅的用户交互体验
Meteor-Ionic 模态框和弹出层:创建优雅的用户交互体验 【免费下载链接】meteor-ionic Ionic components for Meteor. No Angular! 项目地址: https://gitcode.com/gh_mirrors/me/meteor-ionic Meteor-Ionic 是一个专为 Meteor 框架设计的 Ionic 组件库&#…...

Agent驱动的机器学习 pipeline 全链路拆解,深度解析LLM+ML协同训练的4大范式演进
更多请点击: https://codechina.net 第一章:Agent驱动的机器学习 pipeline 全链路拆解,深度解析LLMML协同训练的4大范式演进 Agent驱动的机器学习 pipeline 正在重构传统ML工程范式——它不再将数据预处理、特征工程、模型训练与部署割裂为静…...

终极指南:如何用BepInEx配置管理器轻松掌控所有游戏模组设置
终极指南:如何用BepInEx配置管理器轻松掌控所有游戏模组设置 【免费下载链接】BepInEx.ConfigurationManager Plugin configuration manager for BepInEx 项目地址: https://gitcode.com/gh_mirrors/be/BepInEx.ConfigurationManager 你是否厌倦了在游戏模组…...

对比按Token计费与传统套餐在项目中的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按Token计费与传统套餐在项目中的成本体感差异 在开发项目中引入大模型能力时,成本控制是团队必须面对的现实问题。…...
)
“AI点单员”真的能替代人工吗?——基于237家门店AB测试的转化率、客单价、复购率三重数据验证(含原始数据集索引)
更多请点击: https://kaifayun.com 第一章:AI Agent餐饮行业应用 AI Agent正以前所未有的深度融入餐饮行业全链路,从智能点餐、后厨协同到供应链优化与顾客情感分析,其核心价值在于将静态规则系统升级为具备感知、推理与自主决策…...

Runtime不是跑kernel的——它是昇腾CANN里的执行层
前言 昇腾NPU上的算子是怎么跑起来的?有人说"runtime就是负责跑kernel的",有人说"runtime管内存分配",还有人说"runtime就是CUDA runtime的对应物"。这些答案都有对的地方,但都没说到根子上。 Ru…...

Super IO:Blender剪贴板导入导出神器,让3D工作流效率翻倍
Super IO:Blender剪贴板导入导出神器,让3D工作流效率翻倍 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 你是否厌倦了在Blender中反复点击文件菜单、浏览文件夹…...

工控行业IO信号Web监控平台原理及技术实现方案
本文从实际使用角度出发,意在解决行业系统中的IO信号监控痛点。一台设备的 IO 信号点动辄成百上千——从简单的门锁状态、急停按钮,到复杂的真空压力模拟量、主轴转速等。这些信号的实时监控直接关系到设备稼动率(OEE)和良品率&am…...