【C语言】数据指针地址的取值、赋值、自增操作避坑
【C语言】数据指针的取值、赋值、自增操作避坑
文章目录
- 指针地址
- 指针自增
- 指针取值、赋值
- 附录:压缩字符串、大小端格式转换
- 压缩字符串
- 浮点数
- 压缩Packed-ASCII字符串
- 大小端转换
- 什么是大端和小端
- 数据传输中的大小端
- 总结
- 大小端转换函数
指针地址
请看下列代码:
#include<stdio.h>
#include<stdint.h>
#include<string.h>
#include <stdio.h>
#include <string.h>
uint8_t buf[10]={0x3F,0xaa,0x3E,0xbb,0xAA,0x3F,0xaa,0x3E,0xbb,0xAA};int main()
{void * p=&buf[0];uint8_t* p0=p;uint16_t* p1=p;uint32_t* p2=p;float * p3 =p;uint8_t i=0;for(i=0;i<10;i++){printf("%u ",&buf[i]);}printf("\n");printf("p:%u p0:%u p1:%u p2:%u p3:%u \n",p,p0,p1,p2,p3);p++;p0++;p1++;p2++;p3++;printf("p:%u p0:%u p1:%u p2:%u p3:%u \n",p,p0,p1,p2,p3);printf("%x\n",(uint16_t)*p0);printf("%x\n",*(uint16_t*)p0);return 0;
}先不看答案 先思考:
已知buf的地址为4206608
那么这几个printf的输出分别是哪些数
默认为小端格式
如果你能完全搞懂 那么就没必要继续往下看了
如果不明白指针是什么意思 那么请先去学指针
输出结果是:
4206608 4206609 4206610 4206611 4206612 4206613 4206614 4206615 4206616 4206617
p:4206608 p0:4206608 p1:4206608 p2:4206608 p3:4206608
p:4206609 p0:4206609 p1:4206610 p2:4206612 p3:4206612
aa
3eaa
指针自增
除了void类型 其他的指针地址都有自己的类型 而不同的类型对应的数据结构 大小也不一样
void指针可以单纯表示地址 其自增时地址+1
uint8_t类型大小也是1字节 所以自增地址+1
uint16_t类型大小 2字节 所以自增地址+2
uint32_t类型大小4字节 自增地址+4
float类型大小4字节 自增地址+4
所以得到:
自增前后的地址为:
p:4206608 p0:4206608 p1:4206608 p2:4206608 p3:4206608
p:4206609 p0:4206609 p1:4206610 p2:4206612 p3:4206612
指针取值、赋值
经过上一次的自增p0的地址为4206609
在buf中对应的是0xaa
对于取值(uint16_t)*p0其逻辑为先取值 再转为uint16_t
所以是先得到uint8_t类型的0xaa 然后再做赋值操作 得到uint16_t类型的0x00aa
对于取值*(uint16_t*)p0 其逻辑为先转为uint16_t*类型的指针地址 再取值
在转为uint16_t*类型的指针地址后 其地址对应的数为uint16_t类型的0x3eaa 取值后自然就是0x3eaa
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}压缩Packed-ASCII字符串
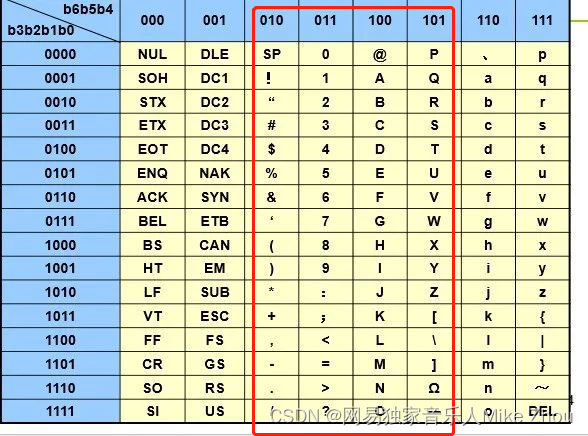
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(buf,0,str_len/4*3); for(i=0;i<str_len;i++){if(str[i]==0x00){str[i]=0x20;}}for(i=0;i<str_len/4;i++){buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);}return 1;
}//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(str,0,str_len);for(i=0;i<str_len/4;i++){str[4*i]=(buf[3*i]>>2)&0x3F;str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);str[4*i+3]=buf[3*i+2]&0x3F;}return 1;
}大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};memcpy(&dat,buf,4);float f=0.0f;f=*((float*)&dat); //地址强转printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40}; float f=0.0f;memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&dat); //大小端转换f=*((float*)&dat); //地址强转printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&f); //大小端转换printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};float f=0.0f;dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{uint16_t *ptr=p;uint16_t x = *ptr;x = (x << 8) | (x >> 8);*ptr=x;
}void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}void swap64(void * p)
{uint64_t *ptr=p;uint64_t x = *ptr;x = (x << 32) | (x >> 32);x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);*ptr=x;
}
相关文章:
【C语言】数据指针地址的取值、赋值、自增操作避坑
【C语言】数据指针的取值、赋值、自增操作避坑 文章目录 指针地址指针自增指针取值、赋值附录:压缩字符串、大小端格式转换压缩字符串浮点数压缩Packed-ASCII字符串 大小端转换什么是大端和小端数据传输中的大小端总结大小端转换函数 指针地址 请看下列代码&#…...

Java进阶-SpringCloud使用BeanUtil工具类简化对象之间的属性复制和操作
在Java编程中,BeanUtil工具类是一种强大且便捷的工具,用于简化对象之间的属性复制和操作。本文将介绍BeanUtil的基本功能,通过详细的代码示例展示其应用,并与其他类似工具进行对比。本文还将探讨BeanUtil在实际开发中的优势和使用…...

【ES6】ECMAS6新特性概览(一):变量声明let与const、箭头函数、模板字面量全面解析
🔥 个人主页:空白诗 🔥 热门专栏:【JavaScript】 文章目录 🌿 引言一、 let 和 const - 变量声明的新方式 🌟📌 var的问题回顾📌 let的革新📌 const的不变之美 二、 Arro…...
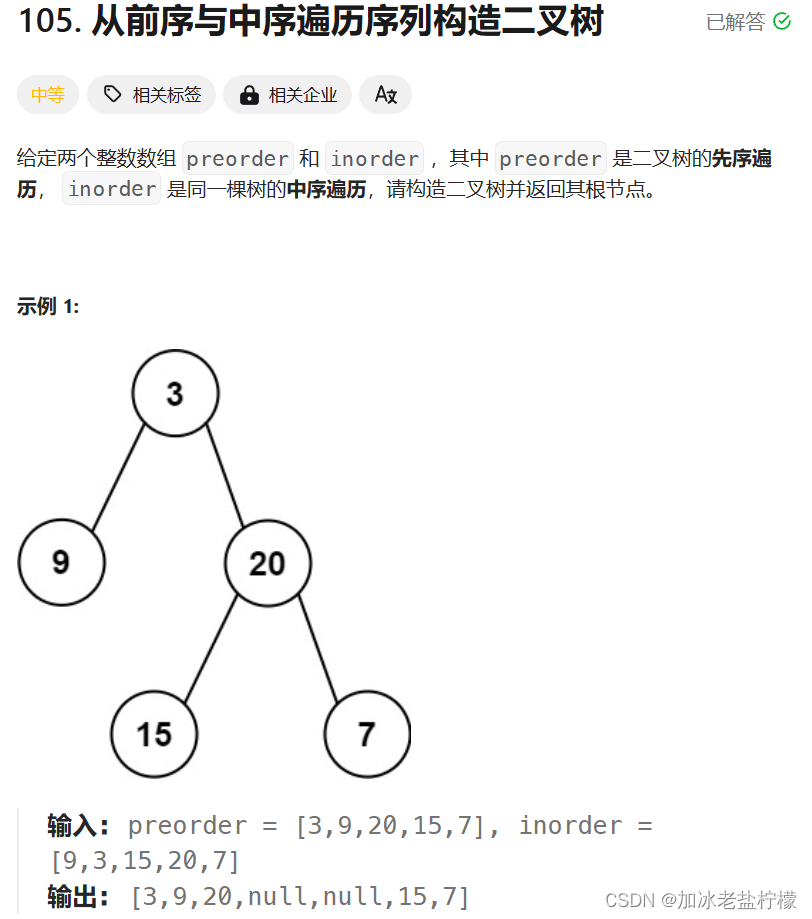
刷题之从前序遍历与中序遍历序列构造二叉树(leetcode)
从前序遍历与中序遍历序列构造二叉树 前序遍历:中左右 中序遍历:左中右 前序遍历的第一个数必定为根节点,再到中序遍历中找到该数,数的左边是左子树,右边是右子树,进行递归即可。 #include<vector>…...
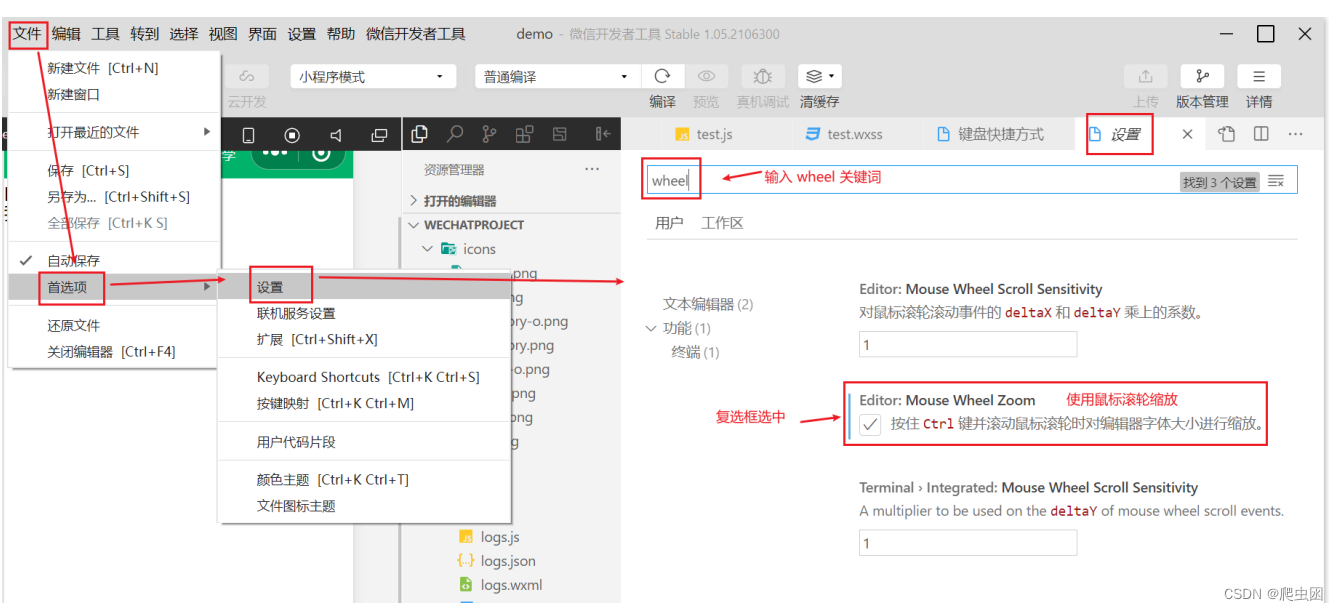
微信小程序--微信开发者工具使用小技巧(3)
一、微信开发者工具使用小技巧 1、快速创建小程序页面 在app.json中的pages配置项,把需要创建的页面填写上去 2、快捷键使用 进入方式 1: 文件–>首选项–> keyboard shortcuts 进入快捷键查看与设置 进入方式 2: 设置–>快捷键…...

JDBC的 PreparedStatement 的用法和解释
文章目录 前言1、封装数据库连接和关闭操作数据库配置文件 config.properties 2、批量添加操作3、查询操作4、修改和删除操作总结 前言 PreparedStatement是预编译的,对于批量处理可以大大提高效率. 也叫JDBC存储过程 1、封装数据库连接和关闭操作 package org.springblade.m…...

LeetCode 面试150
最近准备面试,我以前不愿意面对的 现在保持一颗本心,就是专注于算法思想,语言基础的磨炼; 不为速成,不急功近利的想要比赛,或者为了面试。 单纯的本心,体验算法带来的快乐,是一件非常…...

xmake+xrepo自建仓库添加交叉编译工具链
xmakexrepo自建仓库添加交叉编译工具链 最近想将交叉编译工具链放到xrepo自建仓库中,在xmake中引用,方便多个电脑快速实现交叉编译。 xmake官方文档感觉不够详细,折腾了好久,这里做个记录。 基本步骤如下: 添加自建…...

论文阅读》学习了解自己:一个粗略到精细的个性化对话生成的人物感知训练框架 AAAI 2023
《论文阅读》学习了解自己:一个粗略到精细的个性化对话生成的人物感知训练框架 AAAI 2023 前言 简介研究现状任务定义模型架构Learning to know myselfLearning to avoid Misidentification损失函数实验结果消融实验 前言 亲身阅读感受分享,细节画图解释…...

[Java EE] 网络编程与通信原理(三):网络编程Socket套接字(TCP协议)
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏:🍕 Collection与数据结构 (92平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm1001.2014.3001.5482 🧀Java …...
)
MyBatis懒加载数据(大批量数据处理)
使用范例 Cursor约定使用Iterator去懒加载数据,以时间换空间,非常适合处理通常无法容纳在内存中的数百万个项目查询。如果在 resultMap 中使用集合,则必须使用 resultMap 的 id 列对游标 SQL 查询进行排序(resultOrdered“true”)。 //为了避…...

MySQL--联合索引应用细节应用规范
目录 一、索引覆盖 1.完全覆盖 2.部分覆盖 3.不覆盖索引-where条件不包含联合索引的最左则不覆盖 二、MySQL8.0在索引中的新特性 1.不可见索引 2.倒序索引 三、索引自优化--索引的索引 四、Change Buffer 五、优化器算法 1.查询优化器算法 2.设置算法 3.索引下推 …...
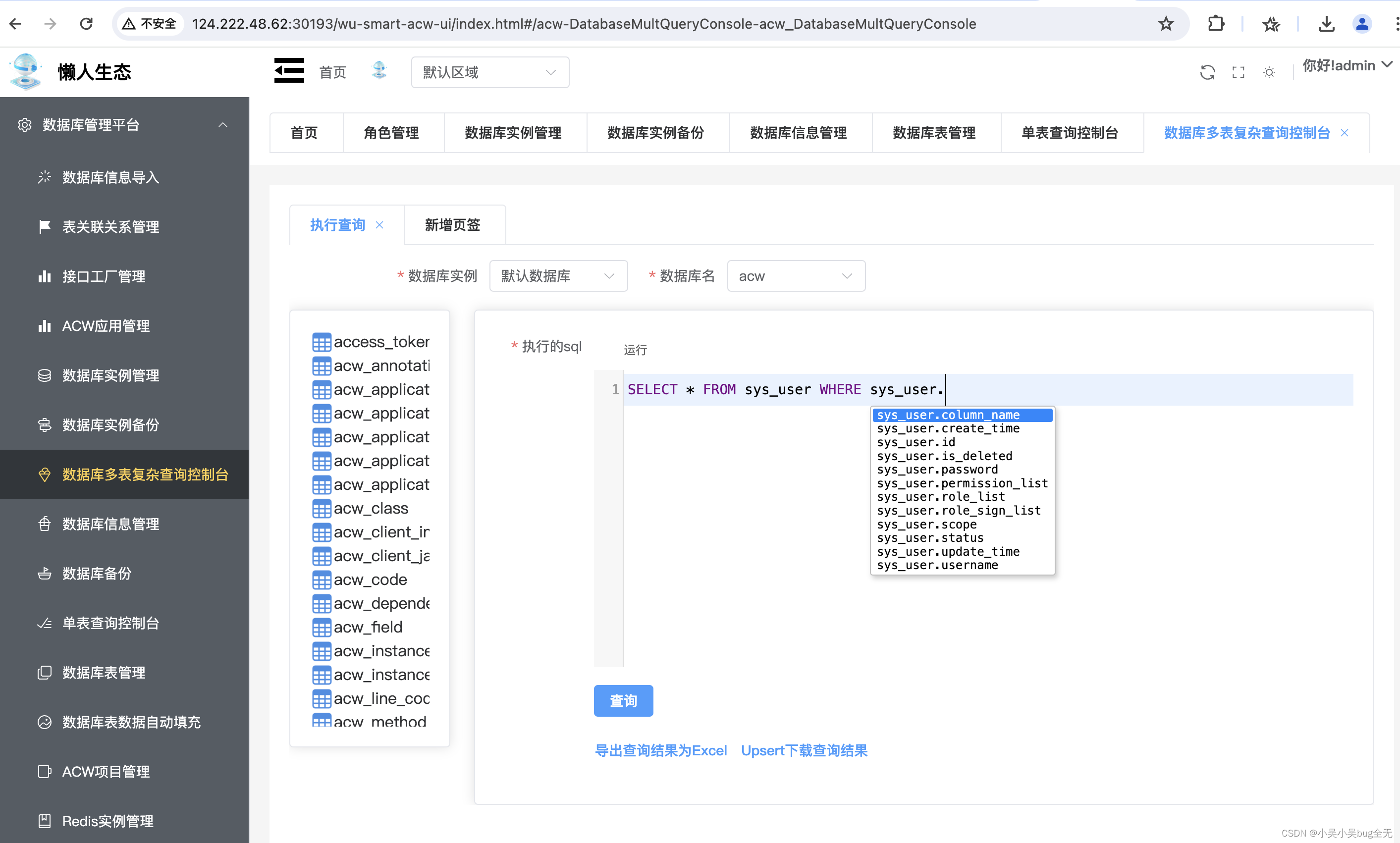
【spring boot+Lazy ORM+mysql】开发一个数据库管理系统实现对应数据库数据查看和修改
【spring bootLazy ORMmysql】开发一个数据库管理系统实现对应数据库数据查看和修改 演示项目地址:http://124.222.48.62:30193/wu-smart-acw-ui/index.html#/login (admin/admin) 功能 用户登录注册新增、编辑数实例新增、编辑数据库信息…...
知识分享:隔多久查询一次网贷大数据信用报告比较好?
随着互联网金融的快速发展,越来越多的人开始接触和使用网络贷款。而在这个过程中,网贷大数据信用报告成为了评估借款人信用状况的重要依据。那么,隔多久查询一次网贷大数据信用报告比较好呢?接下来随小易大数据平台小编去看看吧。 首先&…...

【Day8:JAVA字符串的学习】
目录 1、常用API2、String类2.1 String类的特点2.2 String类的常见构造方法2.3 String类的常见面试题:2.3.1 面试题一:2.3.2 面试题二:2.3.3 面试题三:2.3.4 面试题四: 2.4 String类字符串用于比较的方法2.5 String类字…...

jetcache缓存
1 介绍 是阿里的双极缓存,jvm-->redis-->数据库 文档:jetcache/docs/CN at master alibaba/jetcache GitHub 2 注意事项 使用的实体类一定实现序列化接口定时刷新注解,慎用 它会为每一个key创建一个定时器 :场景为&…...

SQLSyntaxErrorException: FUNCTION dbname.to_timestamp does not exist
由于MySQL数据库高版本(如8.x)中有to_timestamp()函数,低版本中(如5.7.x)没有这个函数,服务运行报错。 自己创建函数实现功能,创建语句如下; DELIMITER // CREATE FUN…...

Borel-Cantelli 引理
翻译自大佬 https://huarui1998.com/Notes/math/borel-cantelli.html 1. 集序列的 lim inf \lim\inf liminf 和 lim sup \lim\sup limsup 类似于定义实数序列 { a k } \{a_k\} {ak} 的 lim inf \lim\inf liminf 和 lim sup \lim\sup limsup, …...

算法训练营第四十一天 | LeetCode 509 斐波那契数列、LeetCode 70 爬楼梯、LeetCode 746 使用最小花费爬楼梯
LeetCode 509 斐波那契数列 这题动规五部曲都定义得比较明确。首先是dp数组下标,题目中给定F(0) 0说明从0开始,dp[i]直接表示F(i)的值即可。递推公式也直接给出了,也给了开头两个作为递推基础的数值作为初始化依据。遍历顺序也指明是从前往…...
网络其他重要协议(DNS、ICMP、NAT)
1.DNS DNS是一整套从域名映射到IP的系统 1.1 DNS背景 TCP/IP中使用IP地址和端口号来确定网络上的一台主机的一个程序,但是IP地址不方便记忆,例如我们想访问百度就会在浏览器中输入baidu.com而不是百度的IP地址。于是人们发明了一种叫主机名的东西, 是…...

嘎嘎降AI和率零深度对比:2026年同为低价工具效果差距完整评测报告
嘎嘎降AI和率零深度对比:2026年同为低价工具效果差距完整评测报告 选工具之前做了一周功课,试用了三款,最后定了嘎嘎降AI(www.aigcleaner.com)。 4.8元,知网AI率从61%降到了5.3%,达标率99.26%…...

终极指南:3分钟掌握跨平台网络资源下载神器res-downloader
终极指南:3分钟掌握跨平台网络资源下载神器res-downloader 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在为…...

终极指南:5分钟搭建Rust高性能HTTP文件服务器,告别繁琐配置
终极指南:5分钟搭建Rust高性能HTTP文件服务器,告别繁琐配置 【免费下载链接】simple-http-server Simple http server in Rust (Windows/Mac/Linux) 项目地址: https://gitcode.com/gh_mirrors/si/simple-http-server Simple HTTP Server是一款基…...

line_buffer + window_buffer架构
一、line buffer + win buffer架构说明 1.在图像算法处理中,line buffer + window buffer架构是非常普通使用的架构; 2.本次针对3*3的滤波,给出两种处理架构的设计方案 二、方案一步骤 ap_uint<8> window_buffer[3][3]; ap_uint<8> line_buffer[2][COLS]; …...

黑苹果终极简化方案:OpCore Simplify 让你的OpenCore配置变得前所未有的简单
黑苹果终极简化方案:OpCore Simplify 让你的OpenCore配置变得前所未有的简单 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的…...

VideoDownloadHelper专业视频下载解决方案:技术架构与实战指南
VideoDownloadHelper专业视频下载解决方案:技术架构与实战指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper VideoDownloadHelp…...
)
用正点原子Nano开发板,5分钟搞定RT-Thread Nano的MDK5工程配置(附串口调试技巧)
正点原子Nano开发板极速上手RT-Thread实战指南 1. 开箱即用的开发环境搭建 刚拿到正点原子Nano开发板时,最令人兴奋的莫过于快速验证硬件是否正常工作。这款基于STM32F103RBT6的开发板,以其72MHz主频和丰富的外设资源,成为嵌入式入门学习的…...

在Node.js后端服务中集成Taotoken,调用多模型API完成内容生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken,调用多模型API完成内容生成 将大模型能力集成到后端服务是现代应用开发的常见需求。…...

RK3568播放RTSP摄像头实测:软解1080P直接CPU跑满,降到360P才流畅,硬解到底怎么搞?
RK3568 RTSP摄像头解码实战:从软解瓶颈到硬解优化全解析 最近在调试RK3568开发板的RTSP摄像头播放功能时,遇到了一个典型问题:1080P软解直接让CPU跑满,降到360P才能勉强流畅。这让我开始深入探索瑞芯微平台的硬解方案,…...

5分钟完成Switch注入:TegraRcmGUI终极图形化工具完整指南
5分钟完成Switch注入:TegraRcmGUI终极图形化工具完整指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI Switch注入对于许多Nintendo Switch用户…...