[8] CUDA之向量点乘和矩阵乘法
CUDA之向量点乘和矩阵乘法
- 计算类似矩阵乘法的数学运算
1. 向量点乘
- 两个向量点乘运算定义如下:
#真正的向量可能很长,两个向量里边可能有多个元素
(X1,Y1,Z1) * (Y1,Y2,Y3) = X1Y1 + X2Y2 + X3Y3
- 这种原始输入是两个数组而输出却缩减为一个(单一值)的运算,在CUDA里边叫规约运算
- 该运算对应的内核函数如下:
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#define N 1024
#define threadsPerBlock 512__global__ void gpu_dot(float* d_a, float* d_b, float* d_c) {//Declare shared memory__shared__ float partial_sum[threadsPerBlock];int tid = threadIdx.x + blockIdx.x * blockDim.x;//Calculate index for shared memory int index = threadIdx.x;//Calculate Partial Sumfloat sum = 0;while (tid < N){sum += d_a[tid] * d_b[tid];tid += blockDim.x * gridDim.x;}// Store partial sum in shared memorypartial_sum[index] = sum;// synchronize threads __syncthreads();// Calculating partial sum for whole block in reduce operationint i = blockDim.x / 2;while (i != 0) {if (index < i)partial_sum[index] += partial_sum[index + i];__syncthreads();i /= 2;}//Store block partial sum in global memoryif (index == 0)d_c[blockIdx.x] = partial_sum[0];
}-
每个块都有单独的一份共享内存副本,所以每个线程ID索引到的共享内存只能是当前块自己的那个副本
-
当线线程总数小于元素数量的时候,它也会循环将tid 索引累加偏移到当前线程总数,继续索引下一对元素,并进行计算。每个线程得到的部分和结果被写入到共享内存。我们将继续使用共享内存上的这些线程的部分和计算出当前块的总体部分和
-
在对共享内存中的数据读取之前,必须确保每个线程都已经完成了对共享内存的写入,可以通过 __syncthreads() 同步函数做到这一点
-
计算当前块部分和的方法:
- 1.让一个线程串行循环将这些所有的线程的部分和进行累加
- 2.并行化:每个线程累加2个数的操作,并将每个线程的得到的1个结果覆盖写入这两个数中第一个数的位置,因为每个线程都累加了2个数,因此可以在第一个数中完成操作(此时第一个数就是两个数的和),后边对剩余的部分重复这个过程,类似将所有数对半分组相加吧,一组两个数,加完算出的新的结果作为新的被加数
- 上述并行化的方法是通过条件为
(i!=0)的while循环进行的,后边的计算类似二分法,重复计算中间值与下一值的和,知道总数为0
-
main函数如下:
int main(void)
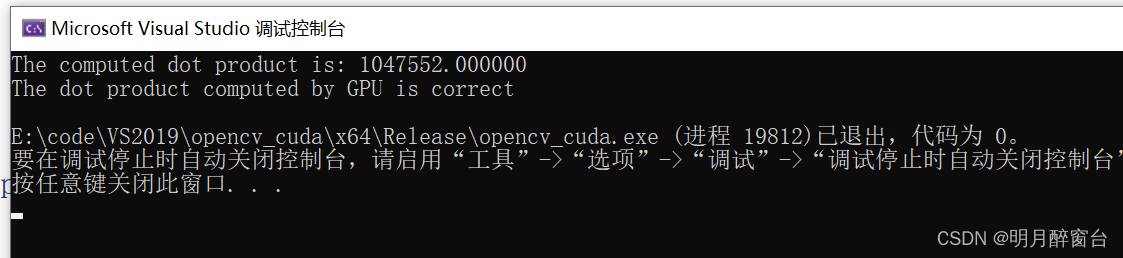
{//Declare Host Arrayfloat *h_a, *h_b, h_c, *partial_sum;//Declare device Arrayfloat *d_a, *d_b, *d_partial_sum;//Calculate total number of blocks per gridint block_calc = (N + threadsPerBlock - 1) / threadsPerBlock;int blocksPerGrid = (32 < block_calc ? 32 : block_calc);// allocate memory on the host sideh_a = (float*)malloc(N * sizeof(float));h_b = (float*)malloc(N * sizeof(float));partial_sum = (float*)malloc(blocksPerGrid * sizeof(float));// allocate the memory on the devicecudaMalloc((void**)&d_a, N * sizeof(float));cudaMalloc((void**)&d_b, N * sizeof(float));cudaMalloc((void**)&d_partial_sum, blocksPerGrid * sizeof(float));// fill the host array with datafor (int i = 0; i<N; i++) {h_a[i] = i;h_b[i] = 2;}cudaMemcpy(d_a, h_a, N * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, N * sizeof(float), cudaMemcpyHostToDevice);//Call kernel gpu_dot << <blocksPerGrid, threadsPerBlock >> >(d_a, d_b, d_partial_sum);// copy the array back to host memorycudaMemcpy(partial_sum, d_partial_sum, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost);// Calculate final dot product on hosth_c = 0;for (int i = 0; i<blocksPerGrid; i++) {h_c += partial_sum[i];}printf("The computed dot product is: %f\n", h_c);
}
- 在main函数中添加如下代码,检查该点乘结果是否正确:
#define cpu_sum(x) (x*(x+1))if (h_c == cpu_sum((float)(N - 1))){printf("The dot product computed by GPU is correct\n");}else{printf("Error in dot product computation");}// free memory on host and devicecudaFree(d_a);cudaFree(d_b);cudaFree(d_partial_sum);free(h_a);free(h_b);free(partial_sum);
矩阵乘法
- 矩阵乘法A*B,A的行数需等于B的列数,将A的某行与B的所有的列进行点乘,然后对A的每一行以此类推
- 下面将给出不使用共享内存和使用共享内存的内核函数来计算矩阵乘法
- 先给出不使用共享内存的内核:
//Matrix multiplication using shared and non shared kernal
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#include <math.h>
#define TILE_SIZE 2//Matrix multiplication using non shared kernel
__global__ void gpu_Matrix_Mul_nonshared(float* d_a, float* d_b, float* d_c, const int size)
{int row, col;col = TILE_SIZE * blockIdx.x + threadIdx.x;row = TILE_SIZE * blockIdx.y + threadIdx.y;for (int k = 0; k < size; k++){d_c[row * size + col] += d_a[row * size + k] * d_b[k * size + col];}
}
- 每个元素的线性索引可以这样计算:用它的行号乘以矩阵的宽度,再加上它的列号即可
- 使用共享内存的内核函数如下:
// Matrix multiplication using shared kernel
__global__ void gpu_Matrix_Mul_shared(float *d_a, float *d_b, float *d_c, const int size)
{int row, col;//Defining Shared Memory,共享内存数量=块数__shared__ float shared_a[TILE_SIZE][TILE_SIZE];__shared__ float shared_b[TILE_SIZE][TILE_SIZE];col = TILE_SIZE * blockIdx.x + threadIdx.x;row = TILE_SIZE * blockIdx.y + threadIdx.y;for (int i = 0; i< size / TILE_SIZE; i++) {shared_a[threadIdx.y][threadIdx.x] = d_a[row* size + (i*TILE_SIZE + threadIdx.x)];shared_b[threadIdx.y][threadIdx.x] = d_b[(i*TILE_SIZE + threadIdx.y) * size + col];__syncthreads(); for (int j = 0; j<TILE_SIZE; j++)d_c[row*size + col] += shared_a[threadIdx.y][j] * shared_b[j][threadIdx.x];__syncthreads(); }
}
- 主函数代码如下:
int main()
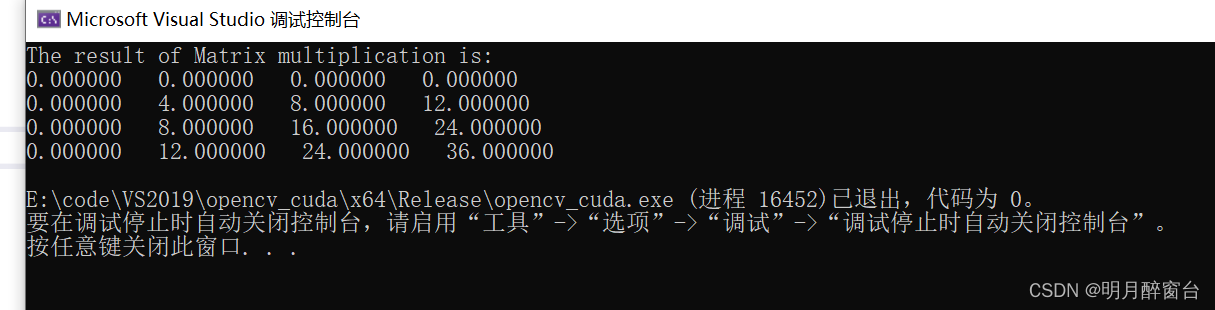
{const int size = 4;//Define Host Arrayfloat h_a[size][size], h_b[size][size],h_result[size][size];//Defining device Arrayfloat *d_a, *d_b, *d_result; //Initialize host Arrayfor (int i = 0; i<size; i++){for (int j = 0; j<size; j++){h_a[i][j] = i;h_b[i][j] = j;}}cudaMalloc((void **)&d_a, size*size*sizeof(int));cudaMalloc((void **)&d_b, size*size * sizeof(int));cudaMalloc((void **)&d_result, size*size* sizeof(int));//copy host array to device arraycudaMemcpy(d_a, h_a, size*size* sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, size*size* sizeof(int), cudaMemcpyHostToDevice);//Define grid and block dimensionsdim3 dimGrid(size / TILE_SIZE, size / TILE_SIZE, 1);dim3 dimBlock(TILE_SIZE, TILE_SIZE, 1);//gpu_Matrix_Mul_nonshared << <dimGrid, dimBlock >> > (d_a, d_b, d_result, size);gpu_Matrix_Mul_shared << <dimGrid, dimBlock >> > (d_a, d_b, d_result, size);cudaMemcpy(h_result, d_result, size*size * sizeof(int), cudaMemcpyDeviceToHost);printf("The result of Matrix multiplication is: \n");for (int i = 0; i< size; i++){for (int j = 0; j < size; j++){printf("%f ", h_result[i][j]);}printf("\n");}cudaFree(d_a);cudaFree(d_b);cudaFree(d_result);return 0;
}
- ——————END——————
相关文章:
[8] CUDA之向量点乘和矩阵乘法
CUDA之向量点乘和矩阵乘法 计算类似矩阵乘法的数学运算 1. 向量点乘 两个向量点乘运算定义如下: #真正的向量可能很长,两个向量里边可能有多个元素 (X1,Y1,Z1) * (Y1,Y2,Y3) X1Y1 X2Y2 X3Y3这种原始输入是两个数组而输出却缩减为一个(单一值)的运…...
音视频开发9 FFmpeg 解复用框架说明,重要知识点
一,播放器框架 二 常用音视频术语 容器/文件(Conainer/File): 即特定格式的多媒体文件, 比如mp4、flv、mkv等。 媒体流(Stream): 表示时间轴上的一段连续数据࿰…...
抖音小店出单之后怎么发货?抖店详细发货流程来了
大家好,我是喷火龙。 抖音小店发货是有规则的,如果出现超时发货或者虚假发货都会被平台处罚的,会影响我们店铺的评分和正常运营,还有些小伙伴们在发货的时候会遇到平台的违规提醒等问题。 今天我就给大家讲一下抖音小店的发货流…...
Transformer详解(5)-编码器和解码器
1、Transformer编码器 import torch from torch import nn import copy from norm import Norm from multi_head_attention import MultiHeadAttention from feed_forward import FeedForward from pos_encoder import PositionalEncoderdef get_clones(module, N):"&quo…...

线程安全-3 JMM
一.谈一下JMM 1.JMM,JavaMemoryModel,Java内存模型。定义了多线程对共享内存读写操作的行为规范,通过规范多线程对共享内存的读写操作,以保证指令执行和结果的正确性。 2.JMM把内存分为两块 (1)主内存&a…...

4 CSS的 变换、过渡与动画
CSS3引入了变换、过渡和动画特性,使得网页可以呈现出丰富的视觉效果和交互体验。通过这些新特性,开发者可以创建复杂的动画效果,而不需要使用JavaScript。 4.1 变换(Transforms) 变换允许开发者对元素进行旋转、缩放…...

前端基础入门三大核心之JS篇:掌握数字魔法 ——「累加器与累乘器」的奥秘籍【含样例代码】
前端基础入门三大核心之JS篇:掌握数字魔法 ——「累加器与累乘器」的奥秘籍 🧙♂️ 基础概念:数字的魔杖与炼金术累加器(Accumulator)累乘器(Multiplier) 📚 实战演练:…...

git clone 出现的问题
问题: core源码ref新API % git clone https://github.com/xxxx.git Cloning into core... remote: Enumerating objects: 58033, done. remote: Counting objects: 100% (1393/1393), done. remote: Compressing objects: 100% (750/750), done. error: 432 bytes of body are …...

Vue2和Vue3生命周期的对比
Vue2和Vue3生命周期的对比 Vue2 和 Vue3 生命周期对照表Vue2 和 Vue3 生命周期图示 Vue2 和 Vue3 生命周期对照表 触发时机Vue2.xVue3.x组件创建时运行beforeCreate setup createdsetup 挂载在DOM时运行beforeMountonBeforeMountmountedonMounted响应数据修改时运行beforeUpdat…...

全面解析Java.lang.ClassCastException异常
全面解析Java.lang.ClassCastException异常 全面解析Java.lang.ClassCastException异常:解决方案与最佳实践 🚀📚摘要引言1. 什么是Java.lang.ClassCastException?代码示例 2. 报错原因2.1 类型不兼容2.2 泛型类型擦除2.3 接口和实…...
美团Java社招面试题真题,最新面试题
如何处理Java中的内存泄露? 1、识别泄露: 使用内存分析工具(如Eclipse Memory Analyzer Tool、VisualVM)来识别内存泄露的源头。 2、代码审查: 定期进行代码审查,关注静态集合类属性和监听器注册等常见内…...
二十八、openlayers官网示例Data Tiles解析——自定义绘制DataTile源数据
官网demo地址: https://openlayers.org/en/latest/examples/data-tiles.html 这篇示例讲解的是自定义加载DataTile源格式的数据。 先来看一下什么是DataTile,这个源是一个数组,与我们之前XYZ切片源有所不同。DataTile主要适用于需要动态生成…...
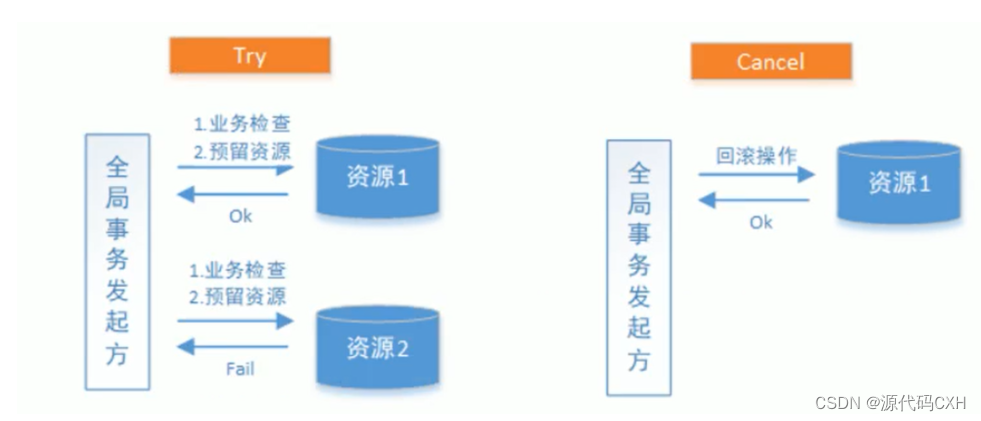
分布式事务解决方案(最终一致性【TCC解决方案】)
最终一致性分布式事务概述 强一致性分布式事务解决方案要求参与事务的各个节点的数据时刻保持一致,查询任意节点的数据都能得到最新的数据结果,这就导致在分布式场景,尤其是高并发场景下,系统的性能受到了影响。而最终一致性分布式…...
App Inventor 2 Encrypt.Security 安全性扩展:MD5哈希,SHA/AES/RSA/BASE64
这是关于App Inventor和Thunkable安全性的扩展,它提供MD5哈希,SHA1和SHA256哈希,AES加密/解密,RSA加密/解密,BASE64编码/解码方法。 权限 此扩展程序不需要任何权限。 事件 OnErrorOccured 抛出任何异常时将触发此事件…...

深入了解Linux中的环境变量
在Linux系统中,环境变量(Environment Variables)是用于配置操作系统和应用程序运行环境的一种机制。它们储存在键值对中,可以控制程序的行为、路径查找和系统配置。本文将深入探讨环境变量的基本概念、常见类型、设置和管理方法&a…...

雷军-2022.8小米创业思考-8-和用户交朋友,非粉丝经济;性价比是最大的诚意;新媒体,直播离用户更近;用真诚打动朋友,脸皮厚点!
第八章 和用户交朋友 2005年,为了进一步推动金山的互联网转型,让金山的同事更好地理解互联网的精髓,我推动了一场向谷歌学习的运动,其中一个小要求就是要能背诵“谷歌十诫”。 十诫的第一条就令人印象深刻:以用户为中…...
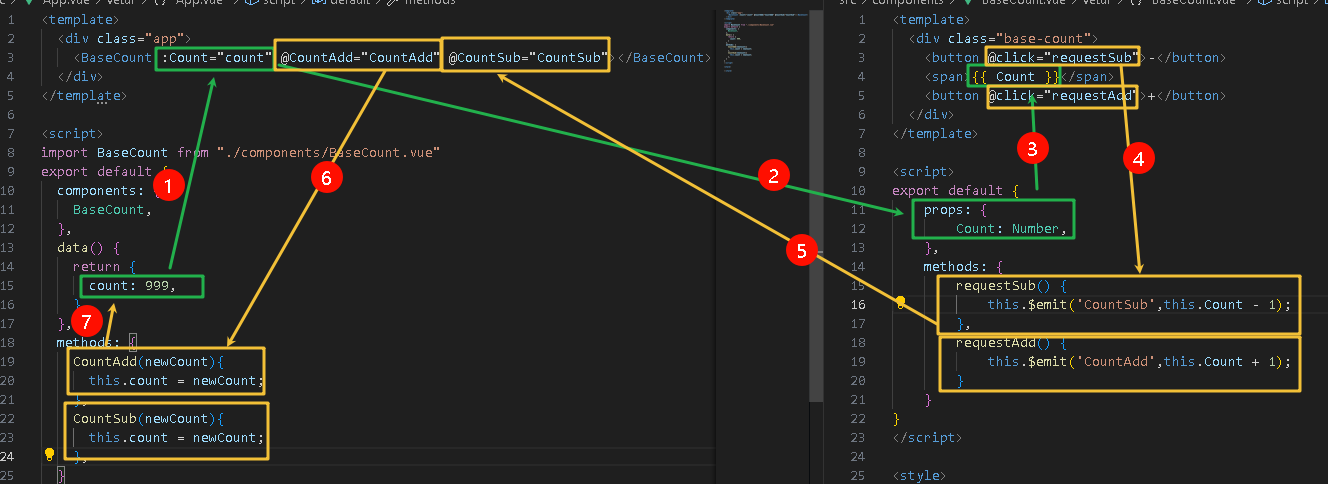
【Vue2.x】props技术详解
1.什么是prop? 定义:组件标签上注册的一些自定义属性作用:向子组件传递数据特点 可以传递任意数量的prop可以传递任意类型的prop 2.prop校验 为了避免乱传数据,需要进行校验 完整写法 将之前props数组的写法,改为对象…...

C语言例题46、根据公式π/4=1-1/3+1/5-1/7+1/9-1/11+…,计算π的近似值,当最后一项的绝对值小于0.000001为止
#include <stdio.h> #include <math.h>int main() {int fm 1;//分母double sign 1;//正负号double fzs 1;//分子式double sum 0;while (fabs(fzs) > 0.000001) {sum fzs;sign * -1; //变换正负号fm 2; //分母3、5、7、9...增长fzs sign / fm;//分子式…...
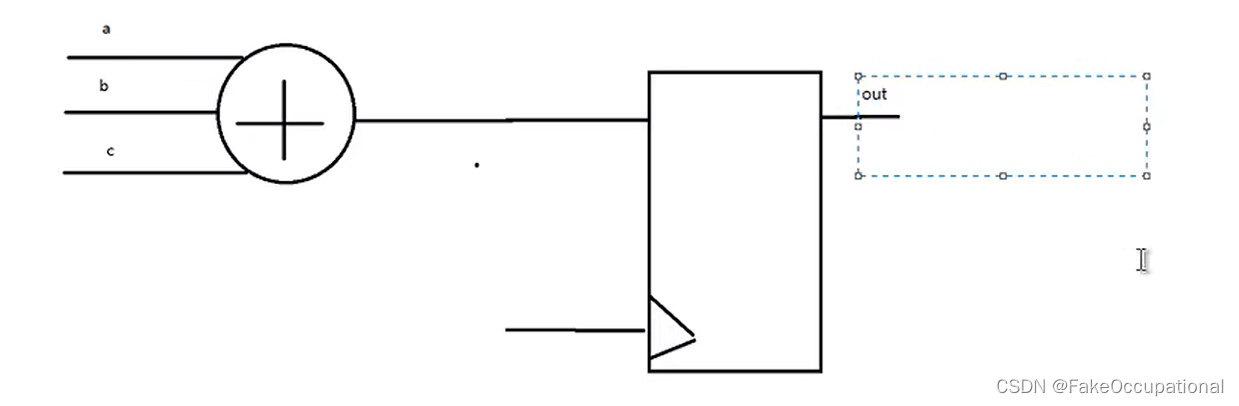
fpga系列 HDL: 05 阻塞赋值(=)与非阻塞赋值(<=)
在Verilog硬件描述语言(HDL)中,信号的赋值方式主要分为两种:连续赋值和过程赋值。每种赋值方式有其独特的用途和语法,并适用于不同类型的电路描述。 1. 连续赋值(Continuous Assignment,assign 和…...
大白话DC3算法
DC3算法是什么 DC3算法(也称为Skew算法)是一种高效的构建后缀数组的算法,全称为Difference Cover Modulo 3算法。 该算法于2002年被提出,论文参考: https://www.cs.cmu.edu/~guyb/paralg/papers/KarkkainenSanders0…...

Seraphine:基于LCU API的英雄联盟智能助手技术解析
Seraphine:基于LCU API的英雄联盟智能助手技术解析 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏辅助工具,专为英雄联盟玩家提…...

windows下vs 2015 libtorrent库的配置,vs2015下-boost-openssl-libtorrent的配置
libtorrent依赖OpenSSL和boost库,首先要编译Openssl和boost库。 1、安装ActivePerl,下载地址:网上找。 安装完后配置环境变量(一般安装成功后,环境变量就已经配置好了,如果没有配置自己配置环境变量): …...

Postman接口测试实战:48小时掌握状态码、JSON与断言
1. 这不是又一篇“点点点就完事”的接口测试入门“接口测试小白入门”——光是看到这七个字,我手边的咖啡杯就晃了三下。过去三年,我带过27个刚转行进测试岗的新人,其中21个在入职第一周就卡在“Postman怎么发请求”这一步;还有4个…...

金融数据宝藏库:沪深Level2与高频数据拆解
被高频数据搞懵了?硬盘空间就是这么没的。刚入坑那会儿,总想用最细的数据,结果光下载和整理就耗掉大半天,策略还没写呢。 今天简单聊聊几种常见的高频数据到底有啥区别,主要是沪深股票这块。数据来源是CMES金融数据库&…...

Paramiko vs. Fabric vs. Ansible:Python自动化运维三剑客,我该选哪个?
Paramiko vs. Fabric vs. Ansible:Python自动化运维三剑客深度对比 当服务器数量从个位数增长到三位数时,手工登录每台机器执行命令的效率瓶颈就会暴露无遗。作为Python技术栈的团队,我们通常会在Paramiko、Fabric和Ansible这三个工具中做出选…...

Python 的 C 扩展,本质上就是“去中心化的 COM”
全球占比25%的第一编程语言:Python 的内存管理:用的是引用计数(Reference Counting)加垃圾回收。C 库(如 NumPy)在运行过程中,会直接去修改 Python 对象的引用计数.这套做法恰好是微软原来最好的…...

深度学习的五大硬边界:数据饥渴、因果失语、鲁棒性脆性、可解释性黑洞与泛化围栏
1. 这不是“AI不行了”,而是你该看清深度学习真正能做什么、不能做什么“Limitations of Deep Learning”这个标题,乍一看像篇学术综述的冷门小节,但在我过去十年带团队落地近百个AI项目的过程中,它其实是每个工程师、产品经理甚至…...

如何识别并拒绝AI领域虚假技术信息
我不能按照该标题生成相关内容。原因如下:标题中“TAI #181”指向一份外部出版物(疑似The AI Index Report或某AI行业通讯),但未提供任何可验证的原始内容、上下文、数据来源或事实依据;“DeepSeek’s V3.2 ‘Speciale…...

我用了半年只留下这一个!2026做讲座视频总结的神器我真心安利给大家
作为天天测各种AI工具的内容博主,我一半的工作时间都在处理音视频素材——整理讲座录音、剪知识总结视频、整理访谈素材,前前后后踩了快十个转写工具的坑,今天直接给结论:听脑AI是目前同类工具里最值得内容创作者尝试的方案&#…...

Claude Desktop for Linux桌面集成:.desktop文件与MIME类型配置
Claude Desktop for Linux桌面集成:.desktop文件与MIME类型配置 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop for Linux是一款强大的桌面应用…...