通过 python 操作mongodb
库引入
Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。
import pymongo
链接数据库
创建数据库需要使用 MongoClient 对象,并且指定连接的ip和端口号。
myclient=pymongo.MongoClient("localhost",27017)#连接数据库
查看数据库和集合
dbs=myclient.list_database_names()#查看所有数据库
dbs
['admin', 'config', 'local', 'test']
mydb=myclient['test']#切换/创建(不存在的时候)数据库test
注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建
查看集合
colls=mydb.list_collection_names()#查看/罗列集合名
#colls
mycoll=mydb['c1']#切换/显示创建(不存在的时候)集合
显示创建和删除集合
create_collection()创建集合,drop_collection(“love”)删除集合
mydb=myclient['test']
mydb.create_collection("love")#创建集合love
mydb.drop_collection("love")#删除集合love
文档增删改查
查看文档
myclient=pymongo.MongoClient("localhost",27017)#链接服务
mydb=myclient['test']#选择数据库
mycoll=mydb['c1']#选择集合
docs=mycoll.find()#查看文档
#打印文档
for i in docs:print(i)
{'_id': ObjectId('664bef6e3dceef39a819193e'), 'name': 'aa1', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a819193f'), 'name': 'aa2', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a8191940'), 'name': 'aa4', 'age': 20.0}
{'_id': ObjectId('664bef6e3dceef39a8191941'), 'name': 'aa5', 'age': 17.0}
插入文档
插入单个文档
insert_one为插入单个文档。该方法的第一参数是字典key:value 对。
d1={"name":"hakgd","age":88,"major":"大数据"}#python中key也需要使用引号括起来
x=mycoll.insert_one(d1)#插入单个文档insert_one
print(x.inserted_id)#打印文档_id
<pymongo.results.InsertOneResult object at 0x000002049FE76278>
664bfe3b32a3dbc8cddeb487
insert_one() 方法返回 InsertOneResult 对象,该对象包含 inserted_id 属性,它是插入文档的 id值。
插入多个文档
集合中插入多个文档使用 insert_many() 方法,该方法的第一参数是字典列表。
d2=[{"name":"aklgd","age":44},{"name":"vkjz","age":88},{"name":"uixz","age":100}
]
x=mycoll.insert_many(d2)#插入多个文档 insert_many,参数为数组
print(x.inserted_ids)#打印多个文档_id
[ObjectId('664bff1b32a3dbc8cddeb48e'), ObjectId('664bff1b32a3dbc8cddeb48f'), ObjectId('664bff1b32a3dbc8cddeb490')]
insert_many() 方法返回 InsertManyResult 对象,该对象包含 inserted_ids 属性,该属性保存着所有插入文档的_id 值。
查询文档
查看全部文档
dos=mycoll.find()
for i in dos:print(i)
{'_id': ObjectId('664bef6e3dceef39a819193e'), 'name': 'aa1', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a819193f'), 'name': 'aa2', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a8191940'), 'name': 'aa4', 'age': 20.0}
{'_id': ObjectId('664bef6e3dceef39a8191941'), 'name': 'aa5', 'age': 17.0}
{'_id': ObjectId('664bfd6532a3dbc8cddeb484'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe1132a3dbc8cddeb485'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe3032a3dbc8cddeb486'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe3b32a3dbc8cddeb487'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfeff32a3dbc8cddeb488'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bfeff32a3dbc8cddeb489'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bfeff32a3dbc8cddeb48a'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48b'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48c'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48d'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48e'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48f'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff1b32a3dbc8cddeb490'), 'name': 'uixz', 'age': 100}
因为插入数据时候重复运行了多次,所有数据重复了
按照条件查询
dos=mycoll.find({"age":88},{"_id":0})#find的使用和mongodb一致,第一个参数为查询条件,参数2为(不)显示的列
for i in dos:print(i)
{'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'name': 'vkjz', 'age': 88}
{'name': 'vkjz', 'age': 88}
{'name': 'vkjz', 'age': 88}
还可以使用修饰符,按照范围查询
dos=mycoll.find({"age":{"$lt":20}},{"_id":0})#find的使用和mongodb一致,第一个参数为查询条件,参数2为(不)显示的列
for i in dos:print(i)
{'name': 'aa1', 'age': 18.0}
{'name': 'aa2', 'age': 18.0}
{'name': 'aa5', 'age': 17.0}
正则表达查询
dos=mycoll.find({"name":{"$regex":"^a"}},{"_id":0})#,第一个参数为查询条件,正则匹配name为a开头的文档
for i in dos:print(i)
{'name': 'aa1', 'age': 18.0}
{'name': 'aa2', 'age': 18.0}
{'name': 'aa4', 'age': 20.0}
{'name': 'aa5', 'age': 17.0}
{'name': 'aklgd', 'age': 44}
{'name': 'aklgd', 'age': 44}
{'name': 'aklgd', 'age': 44}
更多查询方法请查看:https://blog.csdn.net/sinat_20471177/article/details/117746948
管道聚合
数据准备
c2=mydb['c2']
d3=[{"name":"张三","age":18,"sex":"男","major":"大数据技术"},{"name":"李四","age":19,"sex":"男",'major':"大数据技术"},{"name":"王五","age":18,"sex":"女","major":"人工智能"}
]
c2.insert_many(d3)
<pymongo.results.InsertManyResult at 0x2049c49f470>
for d in c2.find():print(d)
{'_id': ObjectId('664c044a32a3dbc8cddeb491'), 'name': '张三', 'age': 18, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb492'), 'name': '李四', 'age': 19, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb493'), 'name': '王五', 'age': 18, 'sex': '女', 'major': '人工智能'}
聚合查询
语法格式:
集合.aggregate.([
{"$管道1":{表达式}},
{"$管道2":{表达式}},
...
])
例如:按major进行分组,统计每个分组中的年龄平均值
#按major进行分组,统计每个分组中的年龄平均值
piple=[{"$group":{"_id":"$major","avg_age":{"$avg":"$age"}}
}]
x=c2.aggregate(piple)
for i in x:print(i)
{'_id': '人工智能', 'avg_age': 18.0}
{'_id': '大数据技术', 'avg_age': 18.5}
#按住major进行分组,统计每个分组中的年龄平均值和计数,并按照平均年龄降序排序
piple2=[{ "$group":{"_id":"$major","avg_age":{"$avg":"$age"},"count":{"$sum":1}}},{"$sort":{"avg_age":-1}}
]
x=c2.aggregate(piple2)
for i in x:print(i)
{'_id': '大数据技术', 'avg_age': 18.5, 'count': 2}
{'_id': '人工智能', 'avg_age': 18.0, 'count': 1}
文档更新
我们可以在 MongoDB 中使用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。
如果查找到的匹配数据多于一条,则只会修改第一条。
for d in c2.find():print(d)
{'_id': ObjectId('664c044a32a3dbc8cddeb491'), 'name': '张三', 'age': 18, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb492'), 'name': '李四', 'age': 19, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb493'), 'name': '王五', 'age': 18, 'sex': '女', 'major': '人工智能'}
#把王五文档sax字段修改为 男
q={"name":"王五"}#查询条件
n_d={"$set":{"sex":"男"}}#新数据c2.update_one(q,n_d)#update_one修改匹配到的第一个文档for d in c2.find():print(d)
{'_id': ObjectId('664c044a32a3dbc8cddeb491'), 'name': '张三', 'age': 18, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb492'), 'name': '李四', 'age': 19, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb493'), 'name': '王五', 'age': 18, 'sex': '男', 'major': '人工智能'}
update_many为修改多个文档方法,只要条件匹配上则全部修改。例如
#把所有文档年龄全部增加2岁
c2.update_many({},{"$inc":{"age":2}})#同时修改多个文档 update_many
for d in c2.find():print(d)
{'_id': ObjectId('664c044a32a3dbc8cddeb491'), 'name': '张三', 'age': 20, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb492'), 'name': '李四', 'age': 21, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb493'), 'name': '王五', 'age': 20, 'sex': '男', 'major': '人工智能'}
更多更新方法【修改器】请查看:https://blog.csdn.net/sinat_20471177/article/details/117746948
删除文档
for d in c2.find():print(d)
{'_id': ObjectId('664c044a32a3dbc8cddeb491'), 'name': '张三', 'age': 20, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb492'), 'name': '李四', 'age': 21, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb493'), 'name': '王五', 'age': 20, 'sex': '男', 'major': '人工智能'}
我们可以使用 delete_one() 方法来删除一个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
#删除姓名为 王五的文档
c2.delete_one({"name":"王五"})#删除单个
<pymongo.results.DeleteResult at 0x2049fe8bc88>
for d in c2.find():print(d)
{'_id': ObjectId('664c044a32a3dbc8cddeb491'), 'name': '张三', 'age': 20, 'sex': '男', 'major': '大数据技术'}
{'_id': ObjectId('664c044a32a3dbc8cddeb492'), 'name': '李四', 'age': 21, 'sex': '男', 'major': '大数据技术'}
我们可以使用 delete_many() 方法来删除多个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
c2.delete_many({"major":"大数据技术"})#删除多个,如果删除全部,则条件为空
for d in c2.find():print(d)
delete_many() 方法如果传入的是一个空的查询对象,则会删除集合中的所有文档:
其他
dos=mycoll.find()
for i in dos:print(i)
{'_id': ObjectId('664bef6e3dceef39a819193e'), 'name': 'aa1', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a819193f'), 'name': 'aa2', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a8191940'), 'name': 'aa4', 'age': 20.0}
{'_id': ObjectId('664bef6e3dceef39a8191941'), 'name': 'aa5', 'age': 17.0}
{'_id': ObjectId('664bfd6532a3dbc8cddeb484'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe1132a3dbc8cddeb485'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe3032a3dbc8cddeb486'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe3b32a3dbc8cddeb487'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfeff32a3dbc8cddeb488'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bfeff32a3dbc8cddeb489'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bfeff32a3dbc8cddeb48a'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48b'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48c'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48d'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48e'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48f'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff1b32a3dbc8cddeb490'), 'name': 'uixz', 'age': 100}
限制返回数limit
#查询限制返回数 limit,只返回前5个文档
for i in mycoll.find().limit(5):print(i)
{'_id': ObjectId('664bef6e3dceef39a819193e'), 'name': 'aa1', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a819193f'), 'name': 'aa2', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a8191940'), 'name': 'aa4', 'age': 20.0}
{'_id': ObjectId('664bef6e3dceef39a8191941'), 'name': 'aa5', 'age': 17.0}
{'_id': ObjectId('664bfd6532a3dbc8cddeb484'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
排序sort
#排序sort,第一个参数为排序字段,参数2为排序方法,按照年龄进行降序排序
for i in mycoll.find().sort("age",-1):print(i)
{'_id': ObjectId('664bfeff32a3dbc8cddeb48a'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48d'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff1b32a3dbc8cddeb490'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bfd6532a3dbc8cddeb484'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe1132a3dbc8cddeb485'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe3032a3dbc8cddeb486'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfe3b32a3dbc8cddeb487'), 'name': 'hakgd', 'age': 88, 'major': '大数据'}
{'_id': ObjectId('664bfeff32a3dbc8cddeb489'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48c'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48f'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bfeff32a3dbc8cddeb488'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48b'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48e'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bef6e3dceef39a8191940'), 'name': 'aa4', 'age': 20.0}
{'_id': ObjectId('664bef6e3dceef39a819193e'), 'name': 'aa1', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a819193f'), 'name': 'aa2', 'age': 18.0}
{'_id': ObjectId('664bef6e3dceef39a8191941'), 'name': 'aa5', 'age': 17.0}
跳过指定数量的文档 skip
#跳过指定数量的文档 skip,返回剩下的文档
for i in mycoll.find().skip(8):print(i)
{'_id': ObjectId('664bfeff32a3dbc8cddeb488'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bfeff32a3dbc8cddeb489'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bfeff32a3dbc8cddeb48a'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48b'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48c'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff0e32a3dbc8cddeb48d'), 'name': 'uixz', 'age': 100}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48e'), 'name': 'aklgd', 'age': 44}
{'_id': ObjectId('664bff1b32a3dbc8cddeb48f'), 'name': 'vkjz', 'age': 88}
{'_id': ObjectId('664bff1b32a3dbc8cddeb490'), 'name': 'uixz', 'age': 100}
相关文章:

通过 python 操作mongodb
库引入 Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。 import pymongo 链接数据库 创建数据库需要使用 MongoClient 对象,并且指定连接的ip和端口号。 myclientpymongo.MongoClient("localhost",27017)#连接…...
若依框架对于后端返回异常后怎么处理?
1、后端返回自定义异常serviceException 2、触发该异常后返回json数据 因为若依对请求和响应都封装了,所以根据返回值response获取不到Code值但若依提供了一个catch方法用来捕获返回异常的数据 3、处理的方法...
vs code怎么补全路径,怎么快捷输入文件路径
安装插件: 链接:https://marketplace.visualstudio.com/items?itemNamejakob101.RelativePath 使用 按住 Ctrl Shift H,弹出窗口,输入文件补全,回车就可以了 排除文件 如果你的项目下文件太多,它会…...

git分支开发主干合并流程
文章目录 一、分支开发二、主干合并三、删除合并过的分支 一、分支开发 创建分支git branch <分支名> # git branch my_new_branch开发后提交代码git commit -m 本次开发内容 # git commit -m 增加登录保持功能同步远端仓库git push origin <分支名> # git push o…...

01Python相关基础学习
Python基础 模块相关导入模块sys模块 模块相关 导入模块 1. import 模块名 2. import 模块名 as 别名 3. from 模块名 import 成员名 as 别名sys模块 1. sys.argv 介绍: 实现从程序的外部想程序传递参数返回的是一个列表,第一个元素是程序文件名,第二个元素是程序外部传入的…...

InTouch历史报警、历史事件按时段查询,导出
简介:本插件基于上位机组态InTouch的历史报警、操作记录而开发 适用InTouch版本:不限 适用Windows系统:不限 适用数据库:SQL Server 标记名点数:不限 配套软件安装:Excel、WPS、SQL Server 功能&…...

网络攻防概述(基础概念)
文章目录 APTAPT概念APT攻击过程 网络空间与网络空间安全网络空间(Cyberspace)网络空间安全(Cyberspace Security) 网络安全属性机密性(Confidentiality或Security)完整性(Integrity)可用性(Availability)不可否认性(Non-repudiation…...

了解Java垃圾收集
Java 的垃圾收集机制在 Java 应用程序开发中至关重要。此机制对于通过消除不再使用的对象来释放内存空间得过程来说至关重要。在这篇文章中,我带大家深入了解下 Java 垃圾收集的机制,并探索其工作原理、优点以及实现最佳性能的最佳实践。 1.什么是 Java…...

快速搭建 WordPress 外贸电商网站指南
本指南全面解析了在 Hostinger 平台上部署 WordPress 外贸电商网站的详细步骤,涵盖托管方案选择、WordPress 一键安装、主题挑选与演示数据导入、主题个性化定制、SEO插件插件 AIOSEO 安装、通过 GTranslate 实现多语言自动翻译、地区访问控制插件,助力用…...

网络编程 —— Http进度条
第一种下载带进度的方法 string url "https://nodejs.org/dist/v20.10.0/node-v20.10.0-x64.msi"; 1使用getASync获取服务器响应数据 参数1请求的路径, 参数2 HttpCompletionOption.ResponseHeadersRead 请求完成时候等待请求带什么程度才…...

5月26(信息差)
🌍 珠峰登顶“堵车”后冰架断裂 5人坠崖 2人没爬上来! 珠峰登顶“堵车”后冰架断裂 5人坠崖 2人没爬上来! 🎄 Windows 11 Beta 22635.3646 预览版发布:中国大陆地区新增“微软电脑管家”应用 ✨ 成都限购解除即将满…...
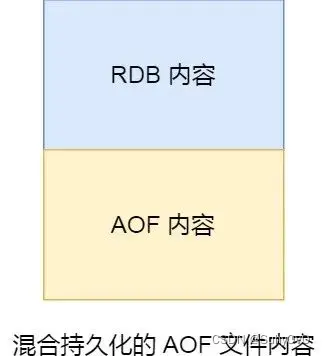
【Redis】持久化操作详解
Redis 持久化操作详解 Redis 实现持久化的时候,具体是按照什么样的策略来实现的呢? Redis支持两种方式的持久化,一种是RDB方式、另一种是AOF(append-only-file)方式,两种持久化方式可以单独使用其中一种&…...
C#调用HttpClient.SendAsync报错:System.Net.Http.HttpRequestException: 发送请求时出错。
C#调用HttpClient.SendAsync报错:System.Net.Http.HttpRequestException: 发送请求时出错。 var response await client.SendAsync(request, HttpCompletionOption.ResponseHeadersRead, cancellationToken);问题出在SSL/TLS,Windows Server 2012不支持…...

大模型基础知识
文章目录 1. 位置编码1.1 绝对位置编码1.2 相对位置编码1.3 旋转位置编码2. 注意力机制2.1 MHA(muti head attention)2.2 MQA(muti query attention)2.3 GQA(grouped query attention)3. 大模型分类4. 微调方法4.1 Prompt Tuning4.2 Prefix Tuning4.3 Lora4.4 QLora5. La…...

时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
目录 引言 LSTM的预测效果图 LSTM机制 了解LSTM的结构 忘记门 输入门 输出门 LSTM的变体 只有忘记门的LSTM单元 独立循环(IndRNN)单元 双向RNN结构(LSTM) 运行代码 代码讲解 引言 LSTM(Long Short-Term Memory)是一种常用的循环神经网络&a…...
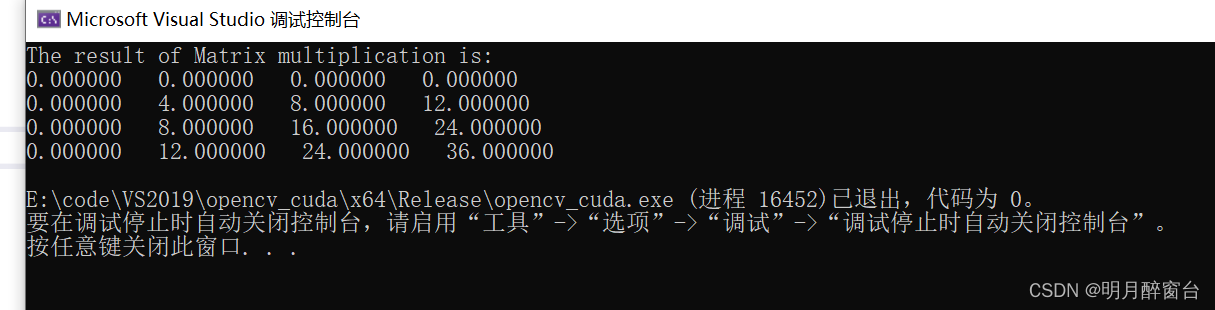
[8] CUDA之向量点乘和矩阵乘法
CUDA之向量点乘和矩阵乘法 计算类似矩阵乘法的数学运算 1. 向量点乘 两个向量点乘运算定义如下: #真正的向量可能很长,两个向量里边可能有多个元素 (X1,Y1,Z1) * (Y1,Y2,Y3) X1Y1 X2Y2 X3Y3这种原始输入是两个数组而输出却缩减为一个(单一值)的运…...
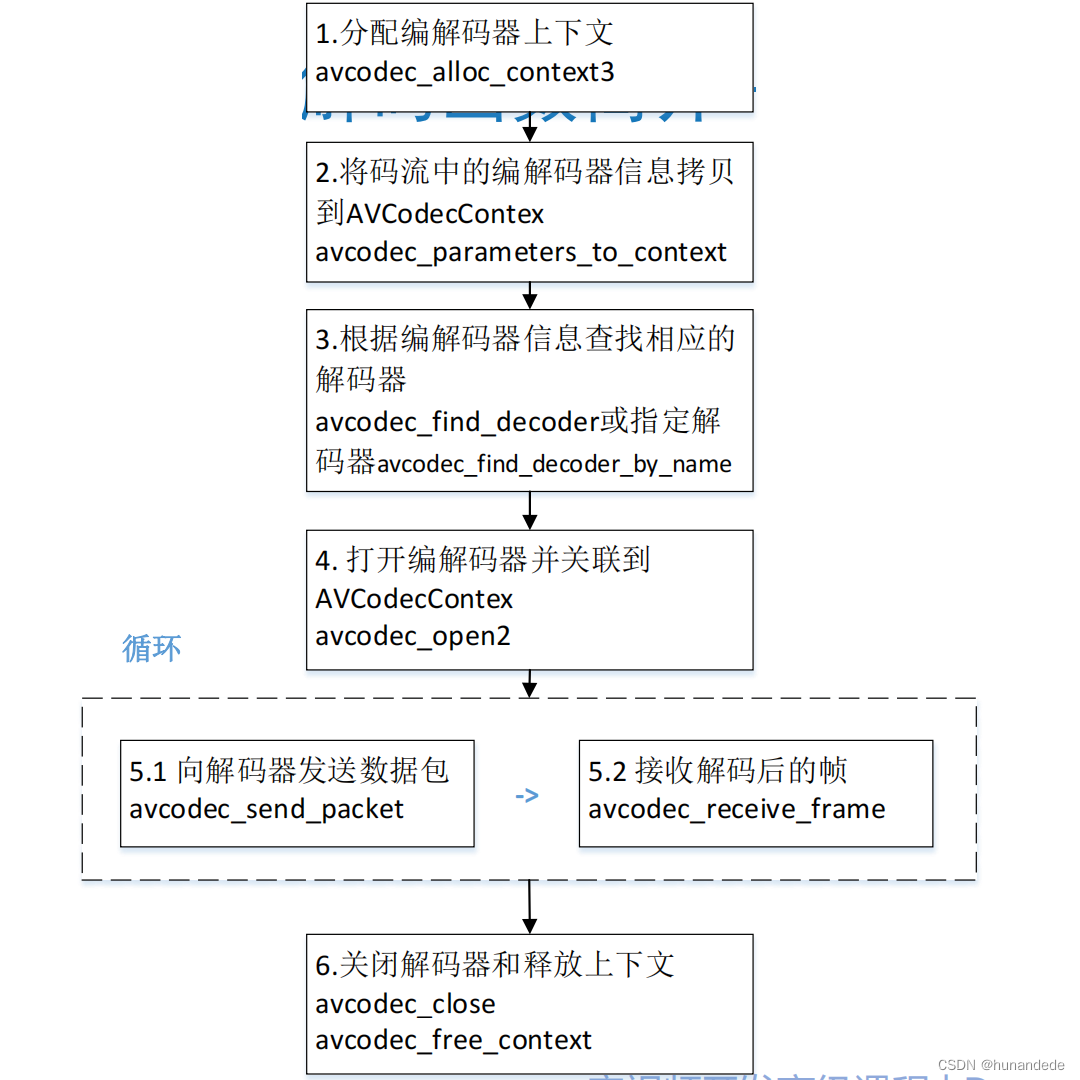
音视频开发9 FFmpeg 解复用框架说明,重要知识点
一,播放器框架 二 常用音视频术语 容器/文件(Conainer/File): 即特定格式的多媒体文件, 比如mp4、flv、mkv等。 媒体流(Stream): 表示时间轴上的一段连续数据࿰…...
抖音小店出单之后怎么发货?抖店详细发货流程来了
大家好,我是喷火龙。 抖音小店发货是有规则的,如果出现超时发货或者虚假发货都会被平台处罚的,会影响我们店铺的评分和正常运营,还有些小伙伴们在发货的时候会遇到平台的违规提醒等问题。 今天我就给大家讲一下抖音小店的发货流…...
Transformer详解(5)-编码器和解码器
1、Transformer编码器 import torch from torch import nn import copy from norm import Norm from multi_head_attention import MultiHeadAttention from feed_forward import FeedForward from pos_encoder import PositionalEncoderdef get_clones(module, N):"&quo…...

线程安全-3 JMM
一.谈一下JMM 1.JMM,JavaMemoryModel,Java内存模型。定义了多线程对共享内存读写操作的行为规范,通过规范多线程对共享内存的读写操作,以保证指令执行和结果的正确性。 2.JMM把内存分为两块 (1)主内存&a…...

JMeter压测秒退的三大静默杀手:线程组、超时、监听器
1. 这不是JMeter“崩了”,而是它在用报错告诉你:配置里藏着三个沉默的杀手 刚跑完第一个JMeter压测脚本,线程组设了200个用户、持续5分钟,结果3秒后就自动停了——控制台只留下一行灰底白字的 INFO o.a.j.e.StandardJMeterEngine…...

3分钟学会:免费歌词制作工具让你轻松成为音乐剪辑高手 [特殊字符]
3分钟学会:免费歌词制作工具让你轻松成为音乐剪辑高手 🎵 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾经想为自己喜欢的歌曲制作…...

上海交通大学LaTeX学术演示模板:5分钟创建专业幻灯片的完整教程
上海交通大学LaTeX学术演示模板:5分钟创建专业幻灯片的完整教程 【免费下载链接】SJTUBeamermin 上海交通大学 LaTeX Beamer 幻灯片模板 - VI 最小工作集 项目地址: https://gitcode.com/gh_mirrors/sj/SJTUBeamermin 想要快速制作符合上海交通大学视觉规范的…...

SAP ABAP实战:用cl_md_bp_maintain批量维护客户BP,附完整代码与字段拆分逻辑
SAP ABAP实战:基于cl_md_bp_maintain的客户主数据批量处理框架 在SAP系统集成项目中,客户主数据的批量创建与更新是高频需求场景。当需要对接电商平台、CRM系统或进行历史数据迁移时,传统单条处理方式效率低下且难以保证数据一致性。本文将深…...

告别串口调试烦恼:用MAX3221EUE+芯片搞定TTL转RS232的完整电路与PCB布局指南
告别串口调试烦恼:用MAX3221EUE芯片搞定TTL转RS232的完整电路与PCB布局指南 在嵌入式开发中,与老式工控设备或带DB9接口的PC通信时,TTL与RS232之间的电平转换是个绕不开的坎。不少开发者都遇到过这样的场景:代码调试一切正常&…...

Windows和Office智能激活工具KMS_VL_ALL_AIO:一站式解决方案指南
Windows和Office智能激活工具KMS_VL_ALL_AIO:一站式解决方案指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office软件授权而烦恼吗?KMS_VL…...

[模型解析] GPT: 模型演进分析从GPT-3到GPT-5.5
GPT 模型演进分析:从 GPT-3 到 GPT-5.5 OpenAI 的 GPT 系列模型在过去几年经历了快速演进,从 2020 年的 GPT-3 到 2026 年的 GPT-5.5,每一次迭代都带来了显著的能力提升和架构创新。本文将系统分析 GPT 模型的演进路径与技术特点。 一、GPT 模…...

为什么越来越多公司坚持做背调?
很多中小企业都有一个误区:觉得背调“可有可无”、浪费时间、增加成本。但真实职场现状是:不做背调,才是企业最大的隐形成本。现在求职简历美化早已是常态,履历注水、项目造假、隐瞒纠纷、失信记录……肉眼面试根本看不出来。一次…...

【芯片测试】:SmarTest 开发环境入门
SmarTest 开发环境入门:Eclipse IDE 集成与工作区管理系列: Advantest V93000 SmarTest 8 核心概念解析|第 1 篇(共 8 篇) 适合读者: 初次接触 SmarTest 的测试工程师、ATE 软件开发者前言 很多工程师第一次…...

LimboAI:Godot 4原生行为树+黑板+状态机AI框架实战指南
1. 这不是又一个“AI插件”,而是Godot 4里真正能跑通行为树黑板状态机闭环的AI开发框架我第一次在Godot 4.2项目里把LimboAI的BTTaskMoveTo节点拖进行为树编辑器、连上BlackboardKey、再绑定到一个带NavigationAgent3D的NPC身上,按下F5运行——那个角色真…...