Pytorch深度学习实践笔记10(b站刘二大人)
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:pytorch深度学习
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
目录
1 卷积神经网络
2 拆解卷积
3 特征提取+分类
1 卷积神经网络
CNN,用于特征提取,但是计算量大,卷积算子是一个计算密集型算子,工业界优化卷积算子是一个重大的任务。有LeNet、AlexNet、VGG系列、ResNet、很多深度学习框架都提供了丰富的CNN模型实现个训练的接口。
- ResNet深度残差网络:
Resnet50(深度残差网络),图像分类网络,2015年何凯明提出。残差是在正常的神经网络中加了一个short cut 分支结构,也称为高速公路。这样网络就不是单纯卷积的输出F(x),而是卷积的输出和前面输入的叠加F(x)+X,可以很好的解决训练过程中的梯度消失问题。被证明具有很强的图像特征提取能力,一般作为一种特征提取器来使用。常用来作为back bone,即骨干网络。也被用来测试AI芯片的性能指标。
- 为什么重要?
(1)常被用来做back bone,例如 YoLo-v3 ,被用来作为特征提取器,特斯拉的占用网络
(2)性能标杆

- ResNet包含的算法:
(1)卷积算法
卷积是CNN网络的核心,对图片或者特征图进行进一步的特征提取,从而实现在不同尺度下的特征提取或者特征融合。
(2)激活(relu)
卷积是乘加运算,属于线性运算,使用激活函数是为了引入非线性因素,提高泛化能力,将一部分神经元激活,而将另一部分神经元关闭。
(3)池化
池化层主要是为了降维,减少运算量,同时可以保证输出特征图中的关键特征
(4)加法
残差结构,解决梯度消失问题
(5)全连接
全连接层,称为Linear层或者FC层,将所有学习到的特征进一步融合,并映射到样本空间的特征上,输出与样本对应。全连接层之后会加一个Softmax,完成多分类。
2 拆解卷积
- 卷积为什么重要
(1)通过卷积核局部感知图像,感受野(有点像人眼盯着某一个地方看)
(2)滑动以获取全局特征(有点像人眼左看右看物体)
(3)权重矩阵(记忆)
- 特征图(Feature Map)
卷积操作从输入图像提取的特征图,即卷积算法的输出结果,包含了输入图像的抽象特征。

- 感受野
卷积核在输入图像上的滑动扫描过程,表示一个输出像素“看到”的输入图像中区域的大小,注意是从输出来看。如果将卷积比作窗户,那么感受野就是一个输出像素透过这个窗户可以看到的输入图片的范围。
感受野影响神经网络对于图像的理解和图像特征的提取。大的感受野可以使得神经网络理解图像的全局信息,从而提取全局特征。小的感受野只能捕捉图像的局部特征。
- 2个3x3卷积替代5x5卷积的意义?
首先可以替代是因为从输出元素看,2个3x3卷积和1个5x5卷积,具有相同的感受野。
优势:
(1)2个3x3卷积的卷积核参数量为3x3+3x3=18,而1个5x5=25
(2)一个卷积变成两个卷积,加深了神经网络的层数,从而在卷积后面引入更多的非线性层,增加了非线性能力。
- 卷积公式
输出通道就是卷积核的个数
![]()
- Padding参数
指的是在输入图像的周围添加的额外的像素值,用来扩大输入图像的尺寸,这些额外填充的像素值通常设置为0,卷积在这个填充后的图像上进行。
Padding主要是为了防止边缘信息的损失,保持输出大小与输入大小一致。
需要填充的场景:
(1)相同卷积(输入和输出尺寸一致)
(2)处理小物体,边缘像素卷积运算较少,多次卷积容易丢失在边缘的小物体,Padding可以提高
(3)网络设计灵活
- Stride 参数
卷积核在活动过程中每次跳过的像素的数量,可以减少计算量、控制Feature Map输出的大小,一定程度上防止过拟合,这是通过降低模型的复杂度来实现的。
Dilation 参数和空洞卷积
dilation指的是卷积核元素之间的间距,决定卷积核在输入数据上的覆盖范围。增大dilation,增大感受野,由此引入了空洞卷积。
空洞卷积扩大了卷积核的感受野,但却不增加卷积核的尺寸,减少运算量;可以解决大尺寸输入图像的问题;可以处理遥远像素之间的关系。
- 卷积长、宽推导

除了以上的三个tensor,还有计算卷积的三个参数,Padding、stride、dilation,这样才构成一个完整的卷积运算。
无参数推导:
![]()
加padding推导:
![]()
加上stride推导:
![]()
加上dilation推导:
![]()

3 特征提取+分类

输入->卷积->输出

一个简单的神经网络:

一些代码说明:
代码说明:
1、torch.nn.Conv2d(1,10,kernel_size=3,stride=2,bias=False)
1是指输入的Channel,灰色图像是1维的;10是指输出的Channel,也可以说第一个卷积层需要10个卷积核;kernel_size=3,卷积核大小是3x3;stride=2进行卷积运算时的步长,默认为1;bias=False卷积运算是否需要偏置bias,默认为False。padding = 0,卷积操作是否补0。
2、self.fc = torch.nn.Linear(320, 10),这个320获取的方式,可以通过x = x.view(batch_size, -1) # print(x.shape)可得到(64,320),64指的是batch,320就是指要进行全连接操作时,输入的特征维度。
CPU代码:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此处自动算出的是320x = self.fc(x)return xmodel = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100*correct/total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()
GPU代码:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此处自动算出的是320# print("x.shape",x.shape)x = self.fc(x)return xmodel = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = datainputs, target = inputs.to(device), target.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100*correct/total))return correct/totalif __name__ == '__main__':epoch_list = []acc_list = []for epoch in range(10):train(epoch)acc = test()epoch_list.append(epoch)acc_list.append(acc)plt.plot(epoch_list,acc_list)plt.ylabel('accuracy')plt.xlabel('epoch')# plt.show()plt.savefig('./data/pytorch9.png')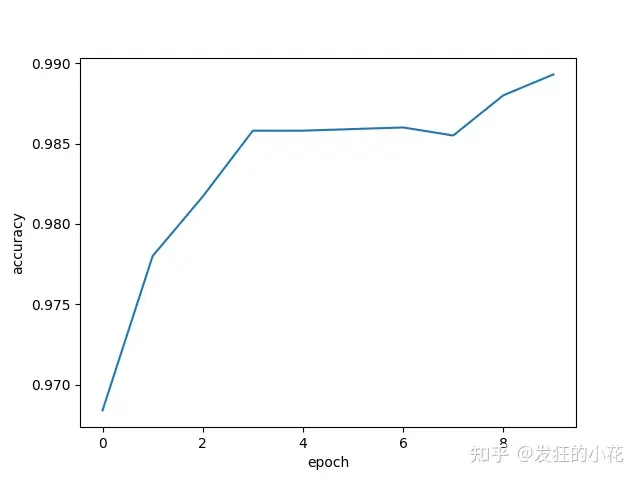
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!
相关文章:
Pytorch深度学习实践笔记10(b站刘二大人)
🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:pytorch深度学习 🎀CSDN主页 发狂的小花 🌄人生秘诀:学习的本质就是极致重复! 《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibi…...
QT5.15.2及以上版本安装
更新时间:2024-05-20 安装qt5.15以上版本 系统:ubuntu20.04.06 本文安装:linux-5.15.2 下载安装 # 安装编译套件g sudo apt-get install build-essential #安装OpenGL sudo apt-get install libgl1-mesa-dev# 下载qt安装器 https://downl…...
5月27日
思维导图 #include <iostream>using namespace std; namespace st_open {string a1;string retval(string a1);} using namespace st_open; int main() {getline(cin,a1);cout << "逆置前的字符串:" << a1 << endl;a1rerval(a1);…...

python给三维点上色,并添加颜色柱
python的matplotlib库给三维点上色,并添加颜色柱 import numpy as np from pathlib import Path import matplotlib.cm as cm import matplotlib.pyplot as plt# 可视化3d点迹 def Show3D_complete(points3D_result, color_list, save_path):# 指定起止点start_poin…...
Ubuntu22.04之解决:忘记登录密码(二百三十二)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
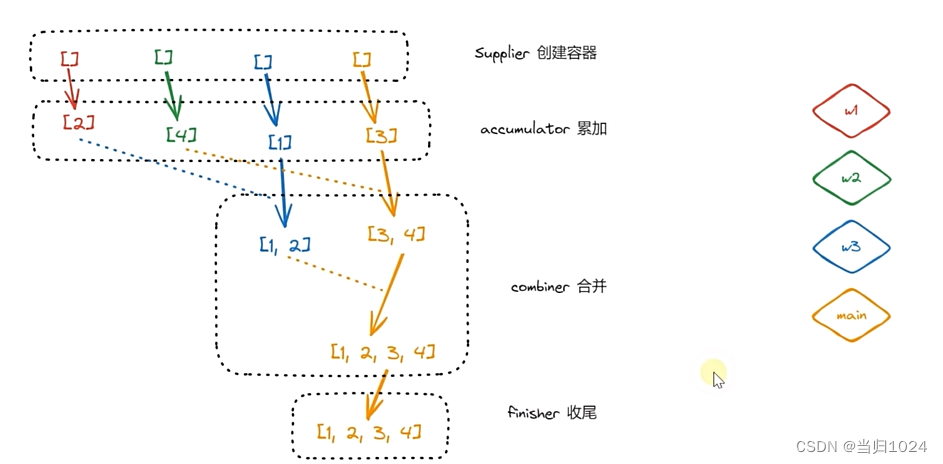
stream-并行流
定义 常规的流都是串行的流并行流就是并发的处理数据,一般要求被处理的数据互相不影响优点:数据多的时候速度更快,缺点:浪费系统资源,数据少的时候开启线程更耗费时间 模版 Stream<Integer> stream1 Stream.of…...
插件“猫抓”使用方法 - 浏览器下载m3u8视频 - 合并 - 视频检测下载 - 网课下载神器
前言 浏览器下载m3u8视频 - 合并 - 网课下载神器 chrome插件-猫抓 https://chrome.zzzmh.cn/info/jfedfbgedapdagkghmgibemcoggfppbb 步骤: P.s. 推荐大佬的学习视频! 《WEB前端大师课》超级棒! https://ke.qq.com/course/5892689#term_id…...
【quarkus系列】构建可执行文件native image
目录 序言为什么选择 Quarkus Native Image?性能优势便捷的云原生部署 搭建项目构建可执行文件方式一:配置GraalVM方式二:容器运行错误示例构建过程分析 创建docker镜像基于可执行文件命令式构建基于dockerfile构建方式一:构建mic…...
常用的代理设置)
linux(ubuntu)常用的代理设置
1. git代理设置与取消 # 设置 git config --global http.proxy socks5://127.0.0.1:1234 git config --global https.proxy socks5://127.0.0.1:1234 # 取消 git config --global --unset http.proxy git config --global --unset https.proxy2. conda代理设置与取消 在.cond…...

红队攻防渗透技术实战流程:红队目标上线之Webshell免杀对抗
红队攻防免杀实战 1. 红队目标上线-Webshell免杀-基础准备2. 红队目标上线-Webshell免杀-基础内容3.红队目标上线-Webshell免杀-建立认知3.红队目标上线-Webshell免杀-测试实验3.1 查杀对象-Webshell&C2后门&工具&钓鱼3.2 免杀对象-Webshell&表面代码&行为…...

Habicht定理中有关子结式命题3.4.6的证明
个人认为红色区域有问题,因为 deg ( ϕ ( S j ) ) r \deg{\left( \phi\left( S_{j} \right) \right) r} deg(ϕ(Sj))r,当 i ≥ r i \geq r i≥r时, s u b r e s i ( ϕ ( S j 1 ) , ϕ ( S j ) ) subres_{i}\left( \phi(S_{j 1}),\p…...

【Unity AR开发插件】如何快速地开发可热更的AR应用
预告 本专栏将介绍如何使用这个支持热更的AR开发插件,快速地开发AR应用。 Unity AR开发插件使用教程 更新 二、使用插件一键安装HybridCLR和ARCore 三、配置带HybridCLR的ARCore开发环境 四、制作热更数据-AR图片识别场景...
)
Divisibility Part1(整除理论1)
Divisibility Part1 学习本节的基础:任意个整数之间进行加、减、乘的混合运算之后的结果仍然是整数。之后将不申明地承认这句话的正确性并加以运用。 用一个不为 0 0 0的数去除另一个数所得的商却不一定是整数( a a a除 b b b,写作 b a \frac…...

代码随想录算法训练营第三十七天 | 860.柠檬水找零、406.根据身高重建队列、452.用最少数量的箭引爆气球
目录 860.柠檬水找零 思路 代码 406.根据身高重建队列 思路 代码 452. 用最少数量的箭引爆气球 思路 代码 860.柠檬水找零 本题看上好像挺难,其实挺简单的,大家先尝试自己做一做。 代码随想录 思路 这题还有什么难不难的,这道题不是非…...

GolangFoundation
GolangFoundation 一. Hello World1.1 SDK1.2 环境1.3 hello world1.4 语法规则二. 程序结构2.1 循环2.2 概述2.3 完整写法2.4 类似while2.5 死循环2.6 特殊循环三. 变量3.1 命名3.2 声明2.3 变量...
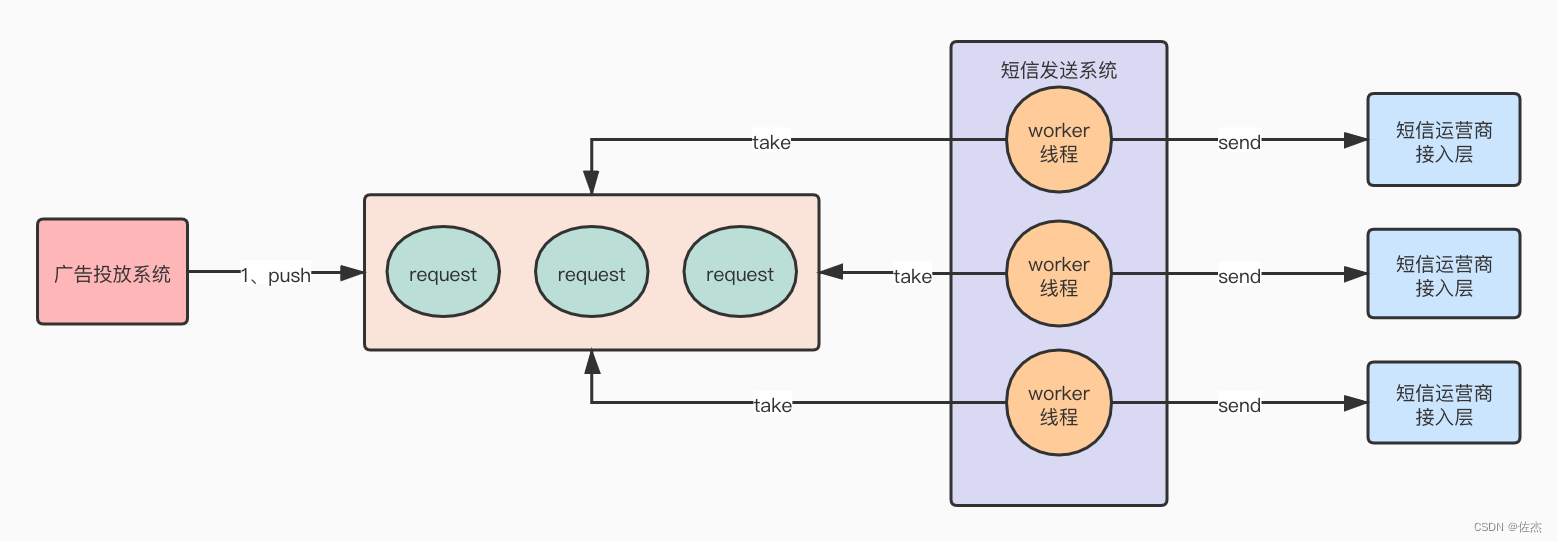
如果任务过多,队列积压怎么处理?
如果任务过多,队列积压怎么处理? 1、内存队列满了应该怎么办2、问题要治本——发短信导致吞吐量降低的问题不能忽略!!3、多路复用IO模型的核心组件简介1、内存队列满了应该怎么办 如图: 大家可以看到,虽然现在发短信和广告投递,彼此之间的执行效率不受彼此影响,但是请…...

FTP协议——BFTPD基本操作(Ubuntu+Win)
1、描述 本机(Win10)与虚拟机(Ubuntu22.04.4)上的BFTPD服务器建立FTP连接,执行一些基本操作。BFTPD安装教程:FTP协议——BFTPD安装(Linux)-CSDN博客 2、 步骤 启动BFTPD。启动文件…...

为什么需要分布式 ID?
目录 为什么需要分布式 ID 分布式 ID 的生成方法 分布式 ID 的应用场景 小结 在现代软件架构中,分布式系统架构变得越来越流行。在这些系统中,由于组件分散在不同的服务器、数据中心甚至不同的地理位置,因此要构建高性能、可扩展的应用系…...

MIT6.828 Lab2-3 Sysinfo
目录 一、实验内容二、实验过程2.1 已有的代码2.2 需补充内容/kernel/kalloc.c修改(剩余内存计算的函数)/kernel/proc.c修改(统计进程数量的函数)/kernel/defs.h修改添加/kernel/sysinfo.c文件/kernel/syscall.h修改/kernel/sysca…...

形态学操作:腐蚀、膨胀、开闭运算、顶帽底帽变换、形态学梯度区别与联系
一、总述相关概念 二、相关问题 1.形态学操作中的腐蚀和膨胀对图像有哪些影响? 形态学操作中的腐蚀和膨胀是两种常见的图像处理技术,它们通过对图像进行局部区域的像素值替换来实现对图像形状的修改。 腐蚀操作通常用于去除图像中的噪声和细小的细节&a…...

2026浏览器侧信道指纹检测技术研究与防护方案落地
一、引言常规浏览器指纹检测依托页面脚本读取显性设备参数,这类识别方式早已被各类虚拟浏览工具针对性规避。近两年各大互联网平台开始大规模部署侧信道指纹检测体系,跳出表层参数读取的局限,借助硬件运行损耗、指令执行耗时、内存调度特征、…...

Ftrace事件跟踪配置与性能分析实战指南
1. events-ftrace.xml文件属性详解events-ftrace.xml是Arm Development Studio和DS-5 Development Studio中用于配置ftrace事件跟踪的关键配置文件。这个文件定义了如何捕获、解析和显示内核跟踪事件。理解其中各个属性的作用对于性能分析和系统调试至关重要。1.1 核心属性解析…...

9大网盘直链解析:免费高效的完整下载解决方案
9大网盘直链解析:免费高效的完整下载解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

原神抽卡数据分析神器:告别盲目抽卡,用数据掌控你的欧皇之路
原神抽卡数据分析神器:告别盲目抽卡,用数据掌控你的欧皇之路 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 你是否曾在原神抽卡时…...

python旅游分享点评网系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈扩展功能建议项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python旅游分…...

Go Web中间件机制深度剖析与实战
Go Web中间件机制深度剖析与实战 引言 中间件(Middleware)是Web开发中的核心概念,它在请求处理链路中扮演着至关重要的角色。本文将深入探讨Go语言中中间件的实现机制,并通过实战案例展示如何构建可复用的中间件系统。 一、中间件…...

Spek音频频谱分析器:如何免费快速可视化音频频率的秘密世界
Spek音频频谱分析器:如何免费快速可视化音频频率的秘密世界 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek Spek是一款功能强大的开源音频频谱分析工具,能够将复杂的音频信号转换为直观的彩…...

Pyroscope实战:持续性能剖析与火焰图在微服务中的深度应用
1. 项目概述:为什么我们需要持续性能剖析?作为一线开发者,我们都有过这样的经历:线上服务突然变慢,CPU或内存使用率异常飙升,用户投诉接踵而至。这时候,常规的日志排查往往像大海捞针࿰…...

Cursor AI斜杠命令系统全解析
Cursor AI代码编辑器 的 斜杠命令系统简介 目录 Cursor AI代码编辑器 的 斜杠命令系统简介 一、Skills(技能)类命令 1. `/create-skill` 2. `/babysit` 3. `/canvas` 二、Commands(内置命令)类 1. `/explain` 2. `/read-branch` 3. `/review` 三、使用建议 ,分为Skills(…...

TCP三次握手与四次挥手——连接管理的“仪式感“
**导读:**如果说HTTP是互联网世界的"通用语言",那么TCP就是支撑这一切的"地下管道"。但这条管道不是想通就通的——它有一套严格的"礼仪规范",也就是我们常说的三次握手和四次挥手。今天,我们就来聊…...