Python操作MySQL数据库的工具--sqlalchemy
文章目录
- 一、pymysql和sqlalchemy的区别
- 二、sqlalchemy的详细使用
- 1.安装库
- 2.核心思想
- 3.整体思路
- 4.sqlalchemy需要连接数据库
- 5.使用步骤
- 1.手动提前创建数据库
- 2.使用代码创建数据表
- 3.用代码操作数据表
- 3.1 增加数据
- 3.2 查询数据
- 3.3 删除数据
- 3.4 修改数据
一、pymysql和sqlalchemy的区别
pymysql和sqlalchemy都是Python用来操作数据库的工具,两者的区别如下:
- pymysql库在学校用的较多,也称学者库;sqlalchemy基本都是在企业应用,也称企业库;
- pymysql库使用sql语句操作数据库,所以非常繁琐,要求程序员要记忆大量sql语法;而sqlalchemy是采用操作对象的方式来操作数据库,对程序员很友好,不必记忆较多sql语句用法;
综上所述,推荐大家日后在实际开发中使用sqlalchemy库。
二、sqlalchemy的详细使用
1.安装库
安装命令:pip install sqlalchemy
2.核心思想
用操作对象的方式去操作数据库。
3.整体思路
借用sqlalchemy的基本框架
使用和丰富框架 ----- 满足日常需求
4.sqlalchemy需要连接数据库
连接数据库的方法模版如下:
数据库类型+数据库驱动://用户名:密码@电脑IP:mysql端口号/自定义数据库名?charset=utf8
示例如下:
mysql+pymysql://mysql账号:mysql密码@localhost:3306/数据库名?charset=utf8
5.使用步骤
1.手动提前创建数据库
打开Navicat工具,建立好连接之后,右键点击连接名称,在下拉列表中选择【新建数据库】。

进来新建数据库页面之后,数据库名字自己随便起,注意:字符集要选择utf8mb4,排序规则要选择utf8mb4_general_ci,千万不能有错,完了点击确定即可,数据库就创建好了。

2.使用代码创建数据表
使用代码创建数据表,建议单独建个Python文件,方便一会调用,该文件只用来创建数据表,我就取名叫create_table.py,这里先附上创建数据表全部代码如下:
from sqlalchemy import Column, Integer, String, Enum
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine# 1、找到基本框架 -- 把自定义的类变成数据表 declarative_base--声明基类
Base = declarative_base()# 2、连接数据库
engine = create_engine('mysql+pymysql://root:66666666@localhost:3306/python1?charset=utf8'
)# 3、自定义类 -- 创建表
class User(Base):# 3.1 表名__tablename__ = '员工表'# 3.2 字段信息id = Column(Integer, primary_key=True, autoincrement=True, doc='员工ID')name = Column(String(20), doc='员工名字')age = Column(Integer, doc='员工年龄')sex = Column(Enum('男', '女'), doc='员工性别')phone = Column(String(30), doc='员工电话')# 3.3 字段信息初始化def __init__(self, id, name, age, sex, phone):self.id = idself.name = nameself.age = ageself.sex = sexself.phone = phone# 4、表的生成
Base.metadata.create_all(engine)需要注意的是,代码中第三大部分创建表这里需要自己根据自己的实际需求去写,如下图:
其余的所有部分都是创建数据表的标准模板,可以不做改动。
3.用代码操作数据表
用代码操作数据表,也就是通过代码对数据库中数据表内容进行增删改查等等操作,这里我也再新建一个Python文件,取名叫operation_table.py,先附上固定模版代码部分:
from create_table import User
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 1、连接数据库
engine = create_engine('mysql+pymysql://root:66666666@localhost:3306/python1?charset=utf8'
)# 2、创建一个会话对象 -- 第三者 -- 执行语句
# 2.1 绑定引擎
dbsession = sessionmaker(bind=engine)
# 2.2 实例化
session = dbsession()# 3、数据增删改查# 4、事务提交和关闭
session.commit()
session.close()
代码中第三部分数据的增删改查是根据自身需求实际对数据进行操作,其余所有部分均为固定模版,可以不做改动。
接下来说说第三部分,如何用代码对数据表中的数据做增删改查。
3.1 增加数据
A、增加单个数据:使用add()方法,示例如下所示
user = User(0, '张三', 18, '男', '1001')
session.add(user)
B、增加多个数据:使用add_all(列表)方法,示例如下所示
user1 = User(0, '张三', 20, '男', '1003')
user2 = User(0, '李四', 21, '女', '1004')
user3 = User(0, '王五', 22, '男', '1005')
user4 = User(0, '赵六', 23, '女', '1006')
user5 = User(0, '麻七', 24, '男', '1007')
session.add_all([user1, user2, user3, user4, user5])
3.2 查询数据
A、查询所有员工的信息,示例如下所示
query_obj = session.query(User).all()
for obj in query_obj:print(obj.id, obj.name, obj.age, obj.sex, obj.phone)
B、查询年龄在19-24的员工信息,示例如下所示
query_obj = session.query(User).filter(User.age.between(19, 24)).all()
for obj in query_obj:print(obj.id, obj.name, obj.age, obj.sex, obj.phone, sep=' | ')
C、查询性别为男的员工信息,示例如下所示
query_obj = session.query(User).filter(User.sex == '男').all()
for obj in query_obj:print(obj.id, obj.name, obj.age, obj.sex, obj.phone, sep=' | ')
D、查询性别为男的员工信息,并按年龄大小排序【升序:asc(),降序:desc()】,示例如下所示
query_obj = session.query(User).filter(User.sex == '男').order_by(User.age.asc()).all()
for obj in query_obj:print(obj.id, obj.name, obj.age, obj.sex, obj.phone, sep=' | ')
3.3 删除数据
A、删除员工:姓名=张三,示例如下所示
session.query(User).filter(User.name == '张三').delete()
B、删除员工:电话=1005,示例如下所示
session.query(User).filter(User.phone == 1005).delete()
C、清空员工信息表,示例如下所示
session.query(User).delete()
3.4 修改数据
A、id=18的用户姓名改成小明,示例如下所示
session.query(User).filter(User.id == 18).update({'name': '小明'})
B、id=22的用户姓名改成小红,性别改成女,电话改成0000,示例如下所示
session.query(User).filter(User.id == 22).update({'name': '小红', 'sex': '女', 'phone': '0000'})
相关文章:
Python操作MySQL数据库的工具--sqlalchemy
文章目录 一、pymysql和sqlalchemy的区别二、sqlalchemy的详细使用1.安装库2.核心思想3.整体思路4.sqlalchemy需要连接数据库5.使用步骤1.手动提前创建数据库2.使用代码创建数据表3.用代码操作数据表3.1 增加数据3.2 查询数据3.3 删除数据3.4 修改数据 一、pymysql和sqlalchemy…...

【算法】排序
排序算法在信息学非常常用。Hello!大家好,我是学霸小羊,今天讲几个排序算法。 1.“打擂台”排序 思路:a[ i ]和a[ j ]打擂台(i<j)。 这个方法简单易懂,只需要看看需不需要交换。按从大到小…...
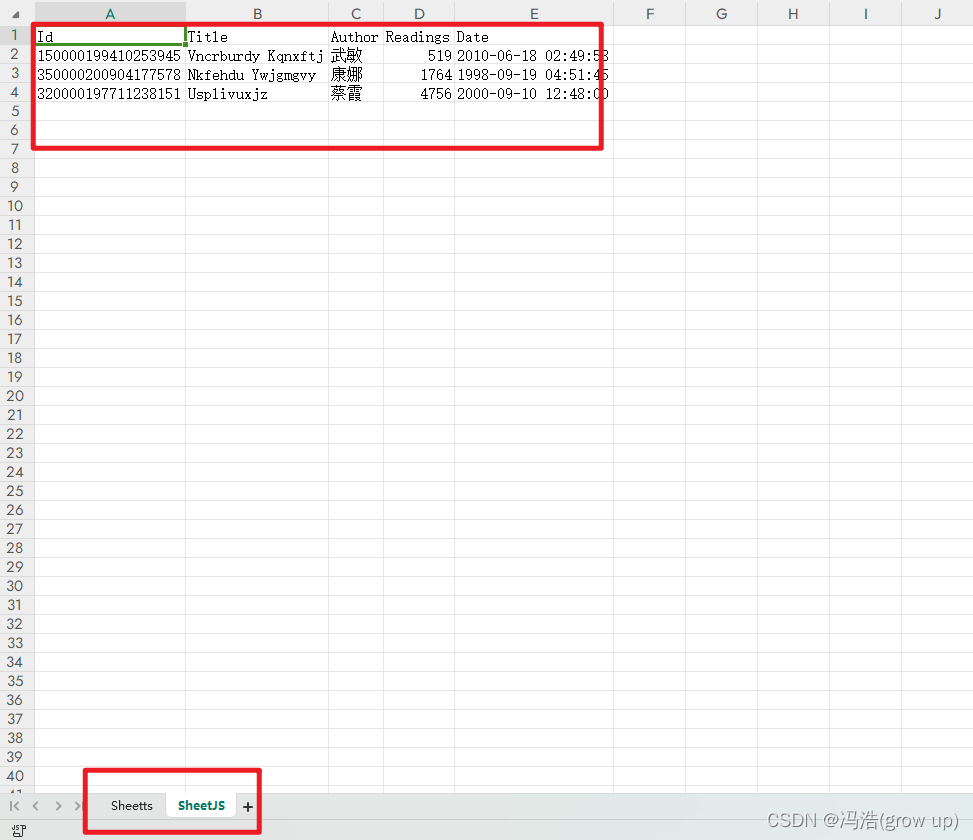
前端开发之xlsx的使用和实例,并导出多个sheet
前端开发之xlsx的使用和实例 前言效果图1、安装2、在页面中引用3、封装工具类(excel.js)4、在vue中使用 前言 在实现业务功能中导出是必不可少的功能,接下来为大家演示在导出xlsx的时候的操作 效果图 1、安装 npm install xlsx -S npm inst…...

创建数据库数据插入、更新与删除
创建数据库和创建表 一、实验目的 (1)熟悉和掌握数据库的创建和连接方法; (2)熟悉和掌握数据库表的建立、修改和删除; (3)加深对表的实体完整性、参照完整性和用户自定义完整性的…...

【CTF Web】CTFShow web3 Writeup(SQL注入+PHP+UNION注入)
web3 1 管理员被狠狠的教育了,所以决定好好修复一番。这次没问题了。 解法 注意到: <!-- flag in id 1000 -->但是拦截很多种字符。 if(preg_match("/or|\-|\\|\*|\<|\>|\!|x|hex|\/i",$id)){die("id error"); }使用…...
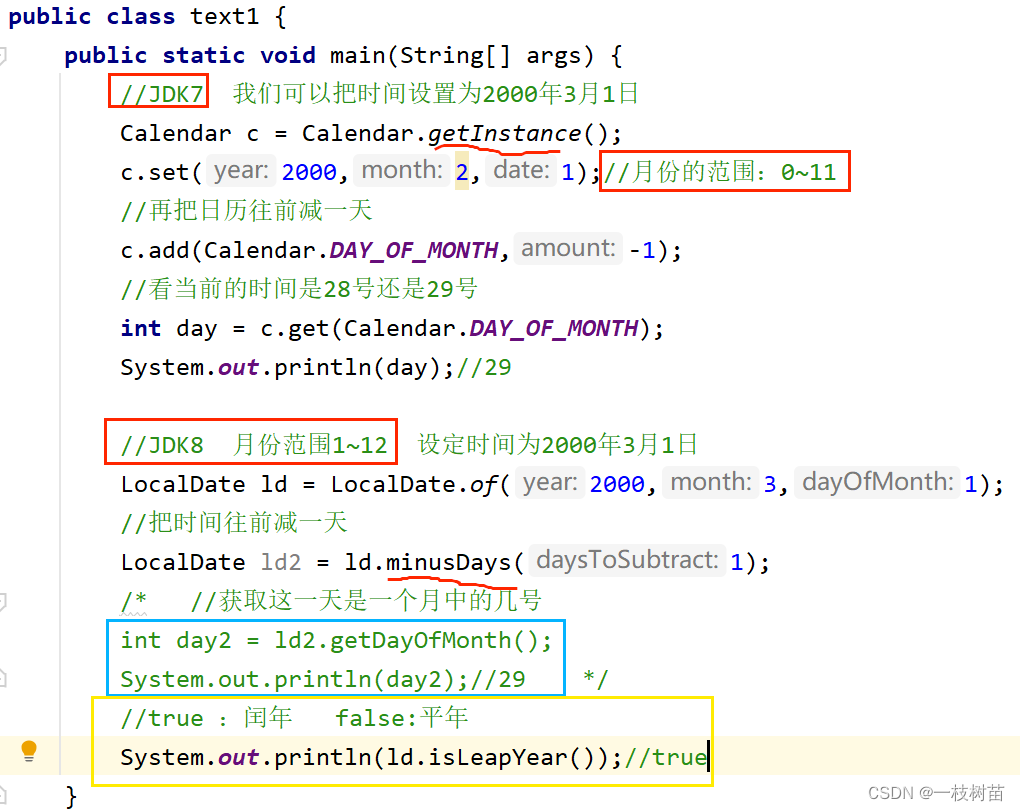
常见API(JDK7时间、JDK8时间、包装类、综合练习)
一、JDK7时间——Date 1、事件相关知识点 2、Date时间类 Data类是一个JDK写好的Javabean类,用来描述时间,精确到毫秒。 利用空参构造创建的对象,默认表示系统当前时间。 利用有参构造创建的对象,表示指定的时间。 练习——时间计…...
)
Docker数据卷(volume)
数据卷 数据卷是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。(容器内目录与宿主机目录对应的桥梁,修改宿主机对应的目录,docker会映射到容器内部,相当于修改了容器内的,反之也一样)数…...

30.哀家要长脑子了!---栈与队列
1.388. 文件的最长绝对路径 - 力扣(LeetCode) 其实看懂了就还好 用一个栈来保存所遍历过最大的文件的绝对路径的长度,栈顶元素是文件的长度,栈中元素的个数是该文件目录的深度,非栈顶元素就是当时目录的长度 检查此…...
多重继承引起的二义性问题和虚基类
多重继承容易引起的问题就是因为继承的成员同名而产生的二义性问题。 例:类A和类B中都有成员函数display和数据成员a,类C是类A和类B的直接派生类 情况一: class A {public:int a;void display(); }; class B {public:int a;void display; }; class C:…...

ciscn
ciscn Crypto部分复现 古典密码 先是埃特巴什密码(这个需要进行多次测试),然后base64,再栅栏即可 答案:flag{b2bb0873-8cae-4977-a6de-0e298f0744c3} _hash 题目: #!/usr/bin/python2 # Python 2.7 (6…...
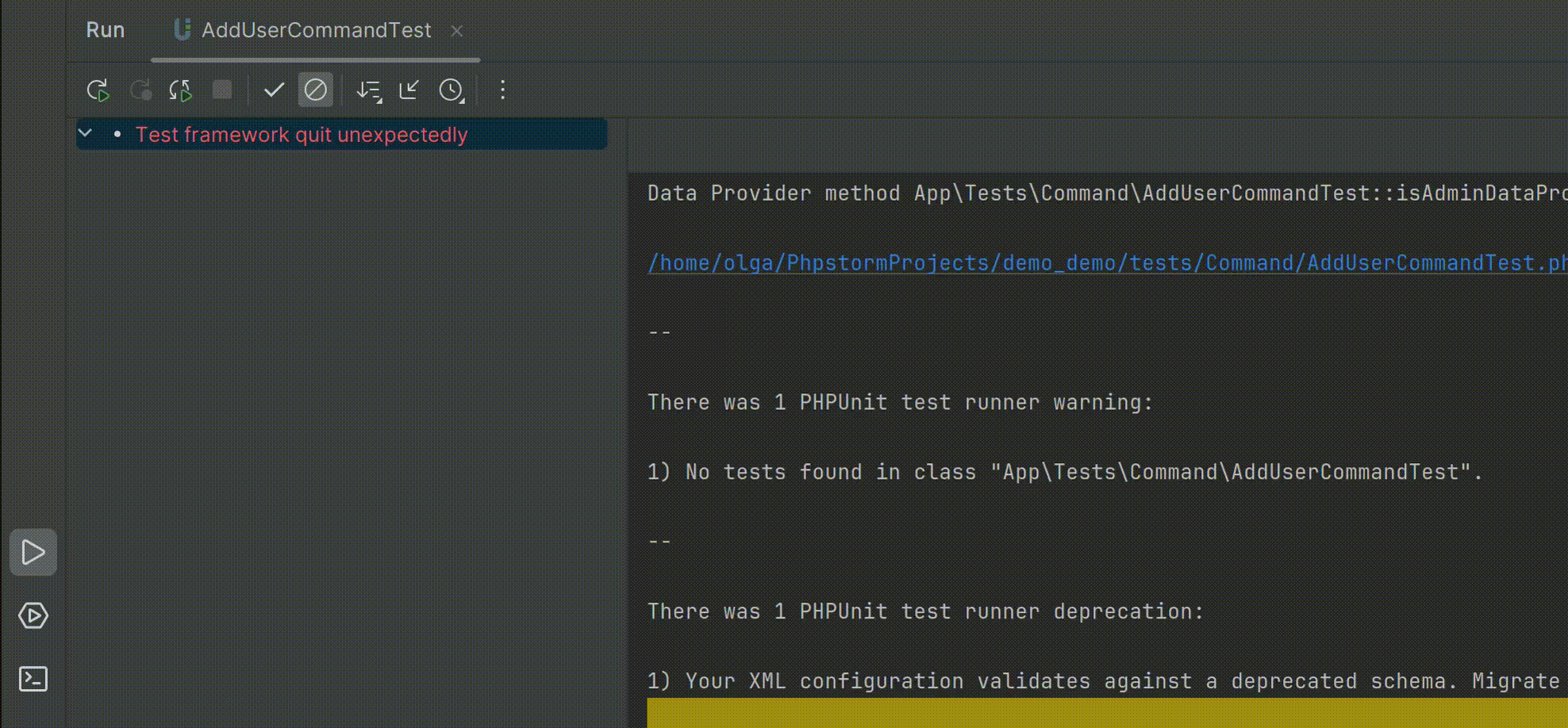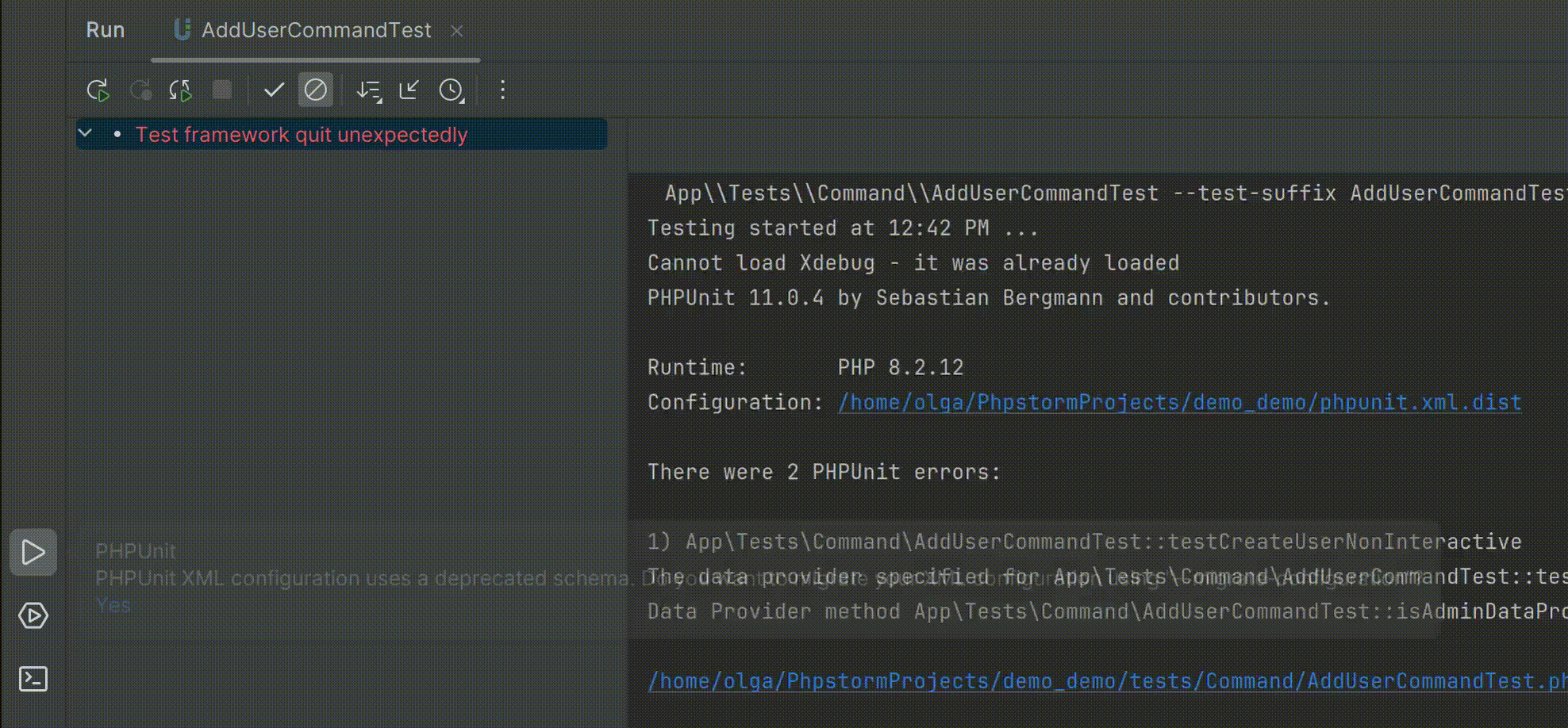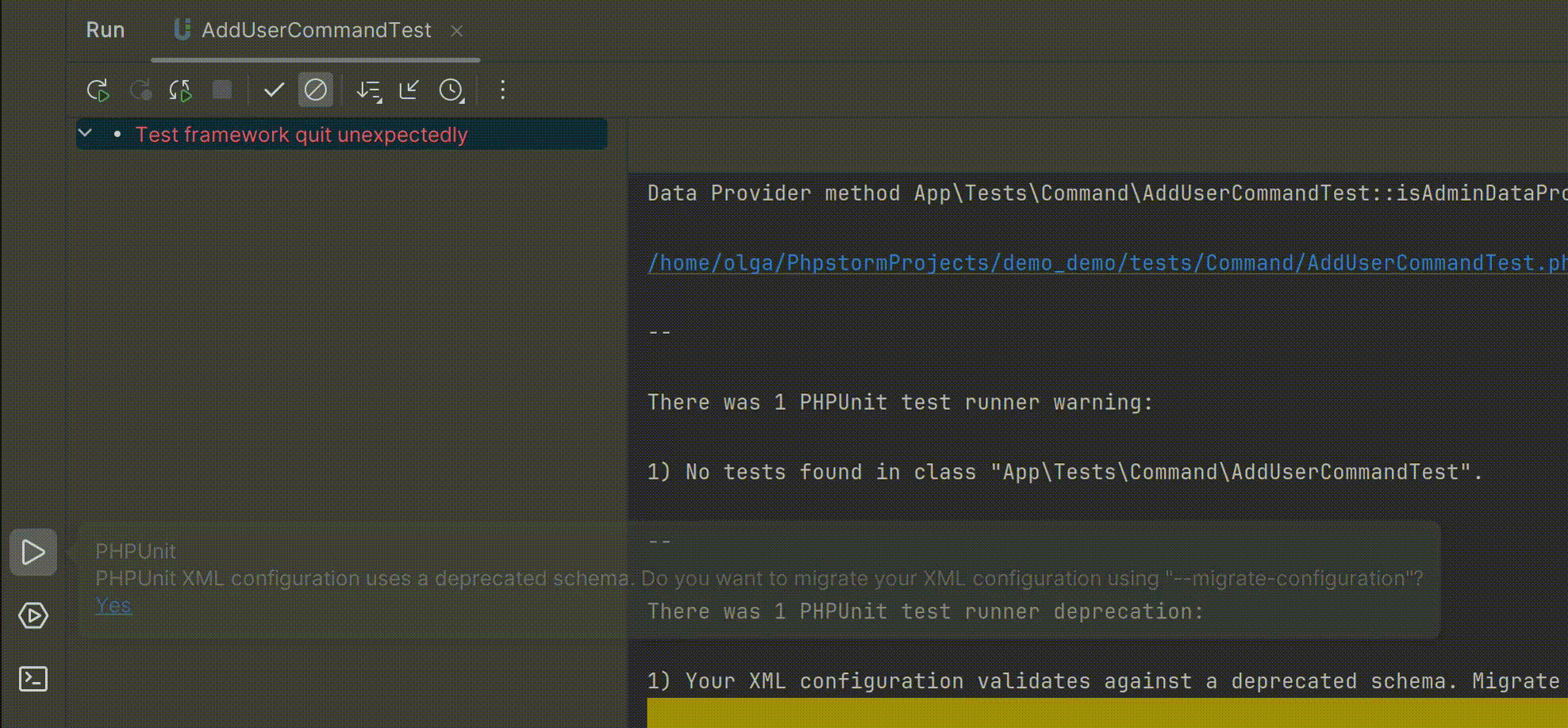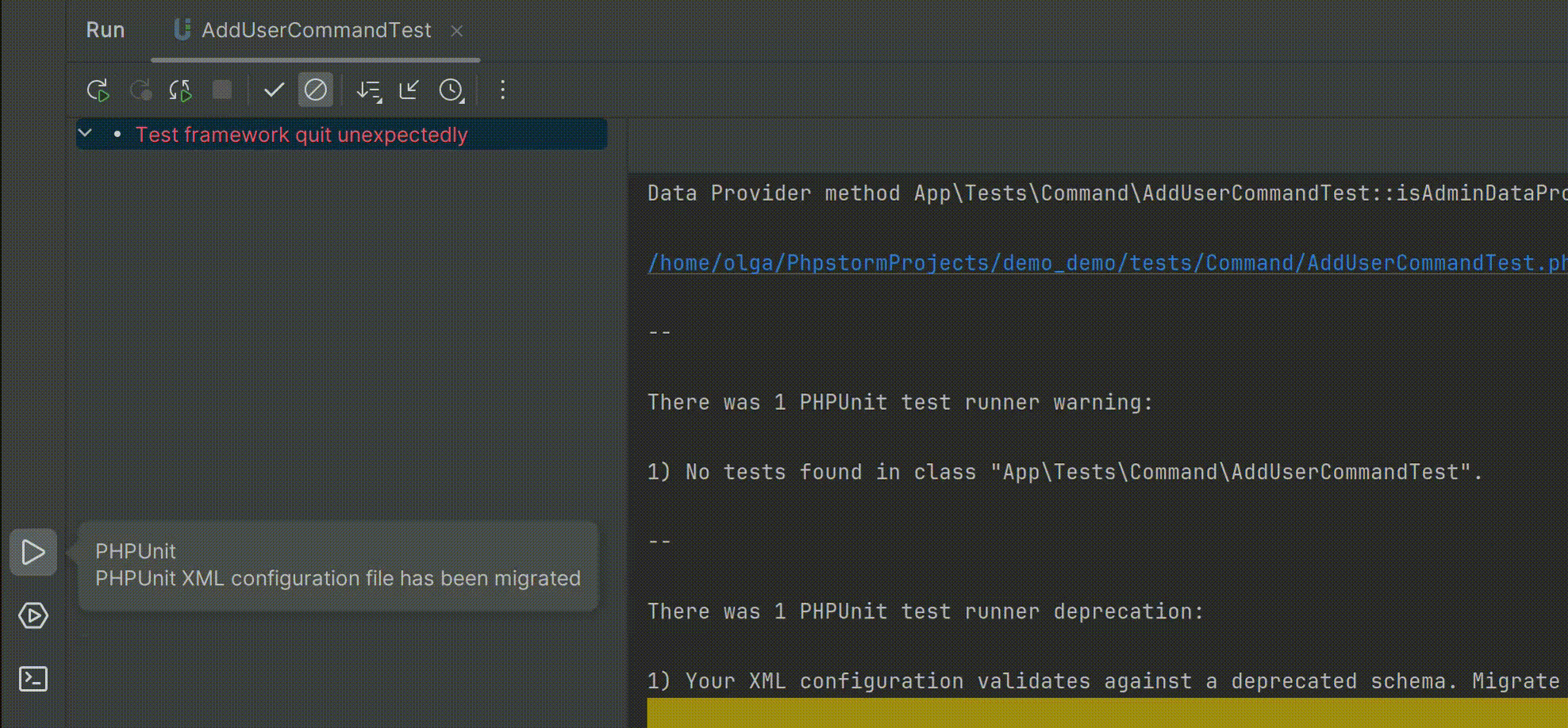
智能的PHP开发工具PhpStorm v2024.1全新发布——支持PHPUnit 11.0
PhpStorm是一个轻量级且便捷的PHP IDE,其旨在提高用户效率,可深刻理解用户的编码,提供智能代码补全,快速导航以及即时错误检查。可随时帮助用户对其编码进行调整,运行单元测试或者提供可视化debug功能。 立即获取PhpS…...
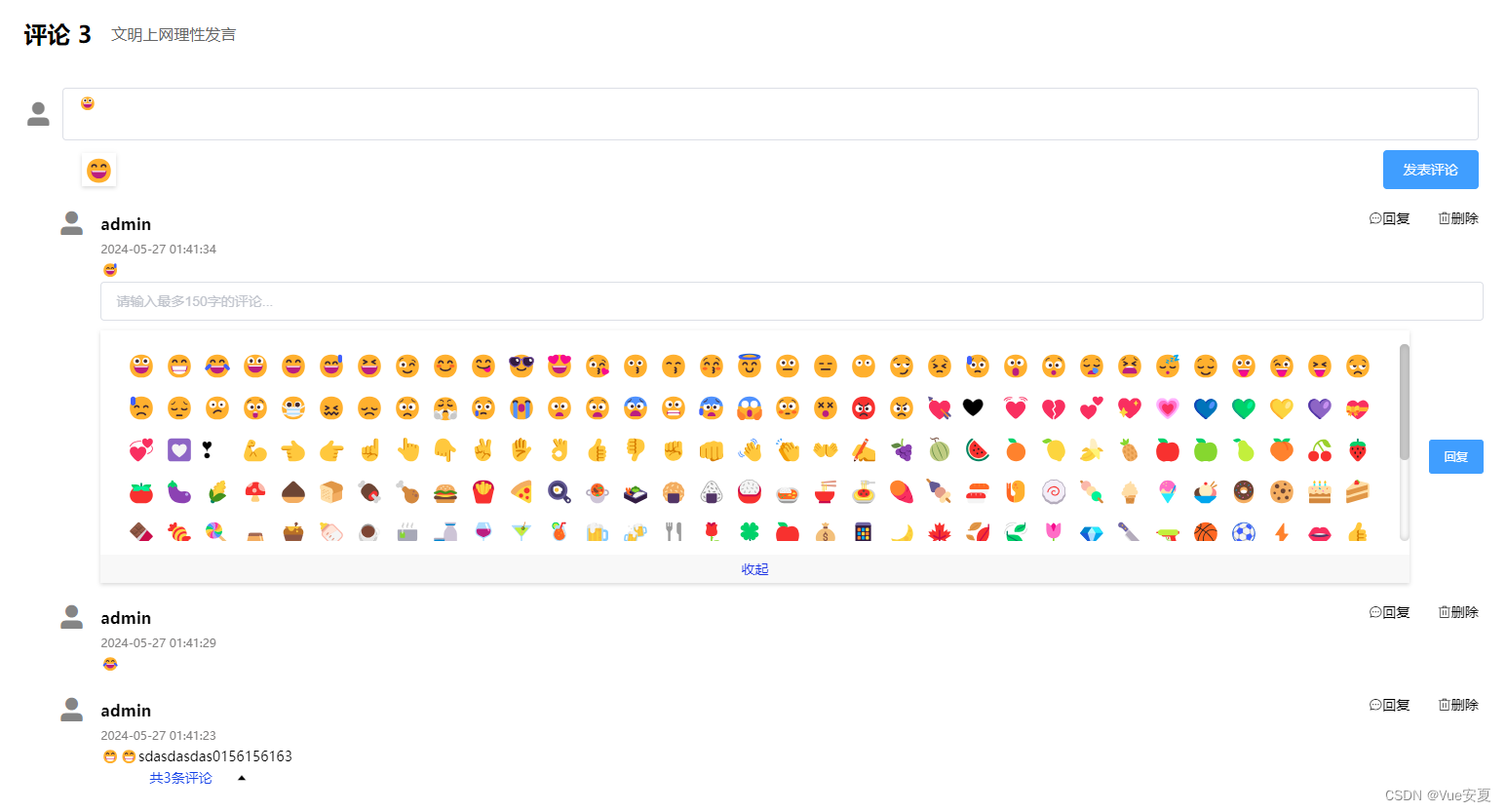
Vue2+Element 封装评论+表情功能
有需要的小伙伴直接拿代码即可,不需要下载依赖,目前是初始版本,后期会进行代码的优化。 评论组件如下: 创建 comment.vue 文件。 表情组件 VueEmoji.vue 在评论组件中使用。 <template><div class"comment"…...

【k8s】存储 pvc 参数列表
相关文章: 【K8s】初识PV和PVC 【k8s】存储 pv 参数列表 【k8s】存储 pvc 参数列表 1. pv概述 2. 参数列表 [rootpaas-controller-3:/home/ubuntu]$ kubectl explain pvc.spec KIND: PersistentVolumeClaim VERSION: v1RESOURCE: spec <Object>DESCRI…...

数据集007:垃圾分类数据集(含数据集下载链接)
数据集简介 本数据拥有 训练集:43685张; 验证集:5363张; 测试集:5363张; 总类别数:158类。 部分代码: 定义数据集 class MyDataset(Dataset):def __init__(self, modetrain, …...
Spring常用注解(超全面)
官网:核心技术SPRINGDOC.CN 提供 Spring 官方文档的翻译服务,可以方便您快速阅读中文版官方文档。https://springdoc.cn/spring/core.html#beans-standard-annotations 1,包扫描组件标注注解 Component:泛指各种组件 Controller、…...

HQL面试题练习 —— 合并活动日期
目录 1 题目2 建表语句3 题解 1 题目 已知有表记录了每个大厅的活动开始日期和结束日期,每个大厅可以有多个活动。请编写一个SQL查询合并在同一个大厅举行的所有重叠的活动,如果两个活动至少有一天相同,那他们就是重叠的,请将他们…...

基于SVm和随机森林算法模型的中国黄金价格预测分析与研究
摘要 本研究基于回归模型,运用支持向量机(SVM)、决策树和随机森林算法,对中国黄金价格进行预测分析。通过历史黄金价格数据的分析和特征工程,建立了相应的预测模型,并利用SVM、决策树和随机森林算法进行训…...

Host头攻击-使用反向代理服务器或负载均衡器来传递路由信息
反向代理服务器的作用 安全性:反向代理服务器位于Web服务器之前,可以隐藏实际Web服务器的身份和地址,从而增加安全性。它还可以对客户端请求进行过滤和检查,以防止潜在的攻击。负载均衡:反向代理服务器可以将客户端请…...

AWS容器之Amazon ECS
Amazon Elastic Container Service(Amazon ECS)是亚马逊提供的一种完全托管的容器编排服务,用于在云中运行、扩展和管理Docker容器化的应用程序。可以理解为Docker在云中对应的服务就是ECS。...
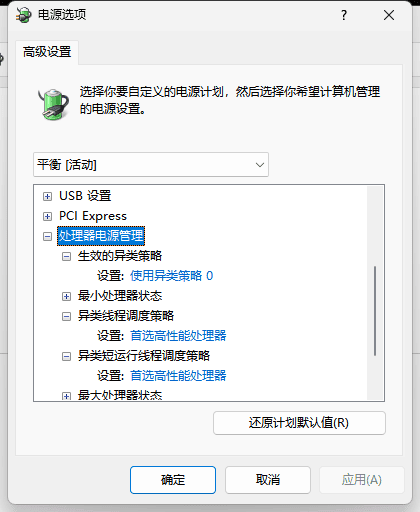
win10/win11 优先调用大核的电源计划性能设置
前言 大小核,即Intel 12代开始的P-core(性能核,一般叫大核)和E-core(能效核,一般叫小核)异核架构。说下个人理解,就是英特尔为了增加cpu性能,但是又因为架构和功耗的限制…...

5分钟上手京东自动抢购工具:Python脚本让限量商品轻松到手
5分钟上手京东自动抢购工具:Python脚本让限量商品轻松到手 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为抢不到心仪商品而烦恼吗?Autobuy-JD京东自动抢购工具为…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成流程详解
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成流程详解。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

代码优化的10个技巧:让你的代码既高效又优雅
对于软件测试从业者而言,编写高质量的测试代码是保障测试效率、提升测试可靠性的核心基础。无论是自动化测试脚本、测试工具开发还是测试框架搭建,臃肿、低效、可读性差的代码不仅会拖慢测试执行速度,还会增加缺陷排查的难度,提升…...

爆仓价格系数推导
多仓 爆仓条件:账户权益 < 维持保证金 即: Equity Maintenance Margin对于一个仓位: 多仓 权益: 权益 初始权益 (当前价 - 开仓价) 数量因为: 价格上涨赚钱。 空仓 权益: 权益 初始权益 (开仓价 -…...

C++面试考点 头文件与实现文件形式
为什么C标准头文件没有所谓的.h后缀? 在一个源文件中,函数模板的声明与定义分离是可以的,即使把函数模板的实现放在调用 之下也是ok的,与普通函数一致。//函数模板的声明 template <class T> T add(T t1, T t2);…...

基于 ComfyUI 本地部署 的「图像 + 音频 → 口型匹配 + 自动运镜」MV 全流程指南
基于 ComfyUI 本地部署 的「图像 + 音频 → 口型匹配 + 自动运镜」MV 全流程指南 适用人群:有一定电脑(Windows / macOS / Linux)操作经验、显卡(GPU)支持 CUDA/ROCm、能自行安装 Python 第三方库的技术爱好者。 目标:输入一张人像图片 + 一段伴奏/人声音频,自动生…...
)
今日算法(二叉搜索树)
题目描述给定一棵二叉搜索树(BST)的根节点 root,树中节点值各不相同。要求将其转换为累加树(Greater Sum Tree),规则如下:每个节点的新值 原节点值 所有比它大的节点值的总和二叉搜索树的性质…...

Jetpack Compose 动画使用指南
Jetpack Compose 动画使用指南 ⚡ 快速上手 Compose 动画,6 大核心 API 结合项目:仓库地址 目录 animate*AsState — 最基础的动画AnimatedVisibility — 显示/隐藏动画updateTransition — 多值协同过渡Crossfade — 页面/内容切换AnimatedContent —…...

NotebookLM时间线功能深度解锁:5个被90%用户忽略的高阶技巧,今天必须掌握
更多请点击: https://codechina.net 第一章:NotebookLM时间线功能概览与核心价值 NotebookLM 的时间线(Timeline)功能是其区别于传统笔记工具的关键创新,它以可视化、可交互的方式呈现文档内容的演进脉络与语义关联。…...

独立开发者如何一站式管理多个AI项目的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何一站式管理多个AI项目的API密钥 对于独立开发者而言,同时维护多个AI应用项目是常态。每个项目可能对接不…...