图解 BERT 模型
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:《大模型面试宝典》(2024版) 发布!
《Attention is All You Need》发表于 2017 年,2018 年 Google AI Language 团队发表了论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,提出了 Bert(Bidirectional Encoder Representations from Transformers)架构。
BERT 实际基于 Transformer 的编码器部分,如若大家理解了前述 Transformer 系列文章,那么再学习 BERT 会很容易理解。
这次依然尝试使用图解的方式介绍 BERT。文章一部分及配图参考了 Rahul Agarwal 在 Medium 上的文章及原始论文,建议收藏、关注、点赞,无论实战还是面试都是常考热点。
一、BERT 概览
简单来说,BERT 是一种可用于问题解答、分类、NER 等大量 NLP 下游任务的架构。可将预训练后的 BERT 视为一个黑盒。
BERT 有两个主要版本:
-
BERT Base:12层 Transformer 编码器,隐藏层大小为768,12个自注意头,总参数量约为1.1亿。
-
BERT Large:24层 Transformer 编码器,隐藏层大小为1024,16个自注意头,总参数量约为3.4亿。
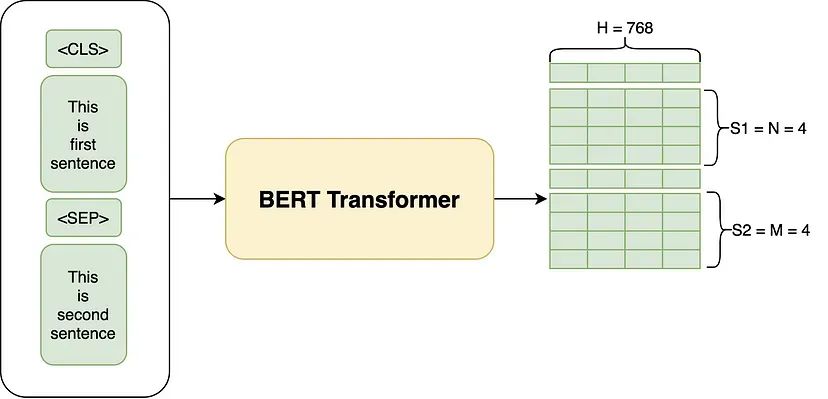
以 BERT Base 版本的 BERT 为例,它能将输入中的每个 Token 转化为一个 H = 768 的向量。与 Transformer 相同,BERT 的输入序列可以是一个单独的句子,也可以是一对由分隔符 [SEP] 标记分隔,以开始符 [CLS] 标记开始的句子。
二、BERT 解决什么问题
如果各位小伙伴对 Imagenet 有所了解,那么也会很容易理解 BERT 的预训练过程。
ImageNet 是一个大型图像数据库,包含了数百万个带标签的图像。CV 模型在这个数据集上进行预训练,以学习图像特征;预训练完成后,对于具体图像任务,可以通过在较小的数据集上,微调模型最后几层来适应特定任务。前几年流行的 ResNet 和 VGG 等深度学习模型最初都是在 ImageNet 数据集上进行预训练的。
BERT 模型工作原理与使用 Imagenet 进行训练的大多数 CV 模型类似。首先,在大型语料库上训练 BERT 模型,然后通过在最后添加一些额外的层,针对具体的 NLP 任务(如分类、问题解答、NER 等)对模型进行微调。
例如,先在维基百科这样的语料库上训练 BERT(屏蔽 LM 任务),然后再用特定的数据对模型进行微调,以完成分类任务,诸如通过添加一些额外的层,将评论分为负面、正面或中性等方式。实际上,我们只是使用 [CLS] 标记的输出来完成分类任务。
如下图所示的微调过程,通过添加线性层和 Softmax 层,对 [cls] Token 进行分类输出。
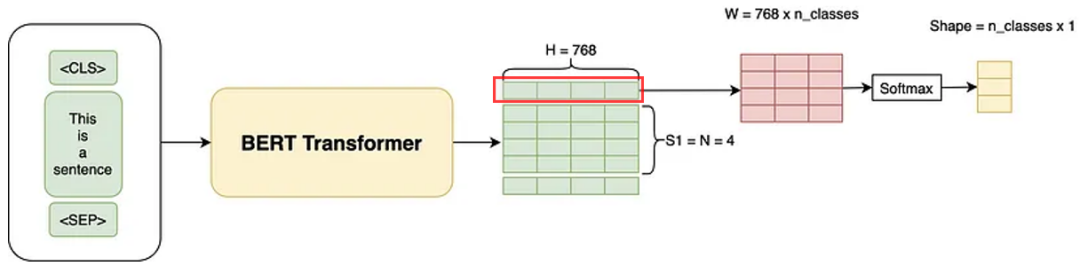
具体来说, 对 BERT 输出的 [cls] Token 使用矩阵乘法作变换。假设我们的分类数是 3,那么 [cls] Token 向量的维度是(1×768),引入的 W 矩阵的形状为( H × num_classes = 768 × 3), [cls] Token 代表的矩阵与 W 矩阵相乘,得到一个(1×3)的矩阵,这个矩阵再通过 Softmax 得到每个类别的概率,然后计算交叉熵损失。
当然,也可以通过在最后一层获取句子特征,然后再输出到 Softmax;或者可以取所有输出的平均值,然后再通过 Softmax。方式有多种,哪种最有效取决于任务的数据。
三、从嵌入的角度看 BERT
从嵌入的角度来看,BERT 的预训练为我们提供了上下文双向嵌入。
1. 上下文 Contextual:
词的嵌入不是固定的,它们依赖于周围的词语。在前序《图解 Transformer》序列文章就详细介绍过这个概念。比如,在“one bird was flying below another bird”这句话中,“bird”这个词的两个嵌入会有所不同。
2. 双向 Bi-Directional:
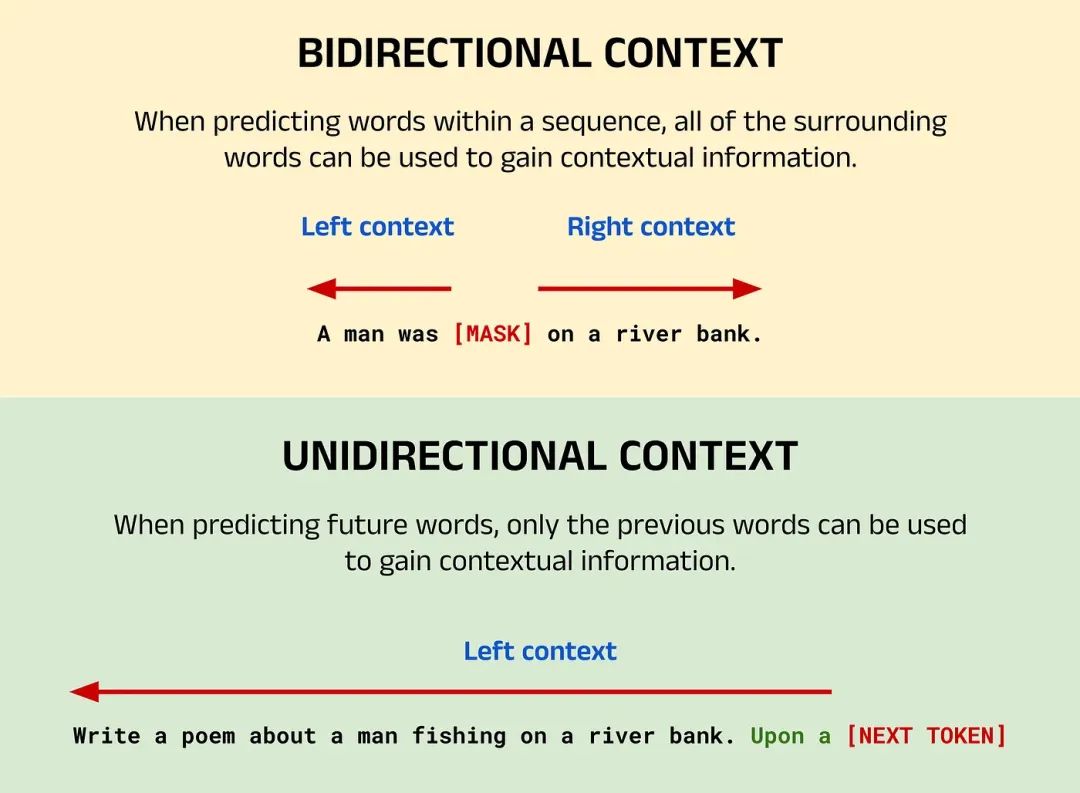
LSTM 按顺序读取文本输入(从左到右或从右到左),而 Transformer 的编码器则是一次性读取整个单词序列,因此被认为是双向的(注意,Transformer 模型的解码器部分通常是单向的)。因此,对于“BERT model is awesome.”这样的句子,“model”这个词的嵌入会包含“BERT”、“awesome”和“is”所有词的上下文。
四、BERT 工作的具体流程
接下来从“架构-Architecture 、输入-Input、训练-Training”三个部分介绍 BERT 的具体工作流程。
1. Architecture
如果你对 Transformers 已经有所了解,那么 BERT 的架构非常容易理解。BERT 基本上是由我们非常熟悉的Transformers 中的编码器堆栈(Encoder Stacks)组成的。
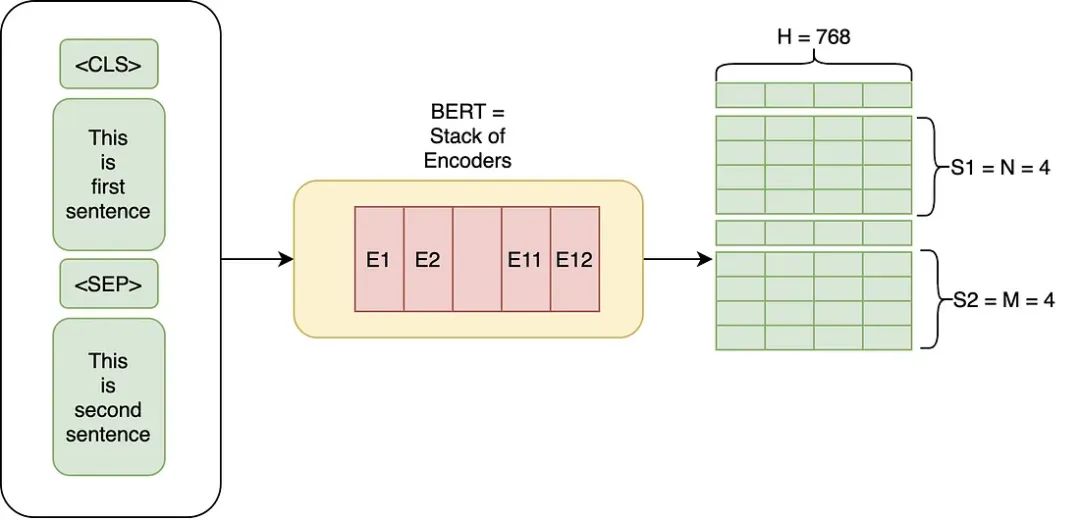
原始论文中,作者实验了两种模型,即我们在开头也提到过的 BERT Base 与 BERT Large 两种架构。
2. Training Input
我们使用下图中的输入结构向 BERT 提供输入。输入由(两个句子+两个特殊的 Token)构成。两个特殊的 token是 [CLS]和[SEP] token。
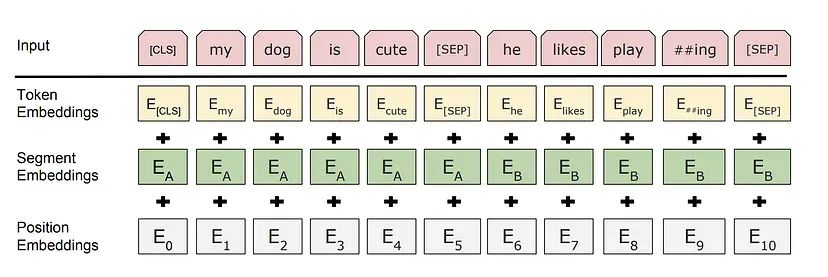
例如,对于两个句子“my dog is cute”和“he likes playing”,BERT 首先使用 WordPiece 分词将序列转换为Token,并在开头添加[CLS] Token,在第二个句子的开头和结尾添加[SEP] Token,因此输入是:

在 BERT 中使用的 WordPiece 分词方法会将单词如 playing 分解成“play”和“##ing”。对于为什么使用 WordPiece 这种方式,我们后面再详细介绍。
BERT 的每个 token 的嵌入由 Token Embeddings、Position Embeddings、Segment Embeddings 三种嵌入向量进行表示:
Token Embedding(词嵌入): 通过在一个大小为 30000x768(H) 的词表矩阵中查找,来获取 Token 嵌入。这里,30000 是WordPiece 分词后的词汇表长度。这个矩阵所代表的权重将在训练过程中学习。
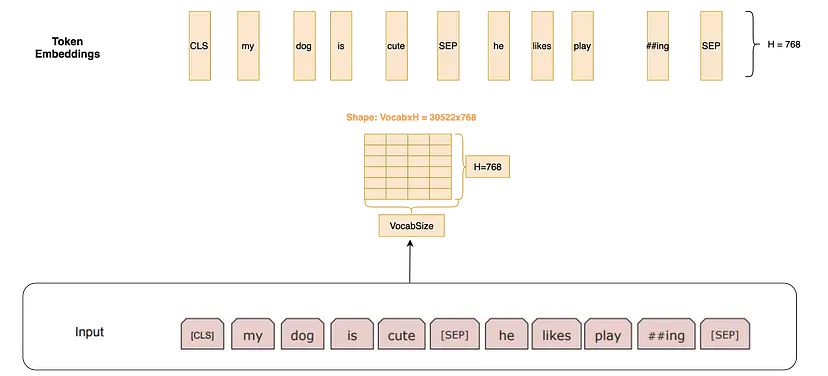
Segment Embedding(段落嵌入): 对于知识问答等任务,我们需要指定这个句子是来自哪个段落。如果嵌入来自第一个句子,这些嵌入是长度为H的全0向量;如果嵌入来自第二个句子,则为全1向量。
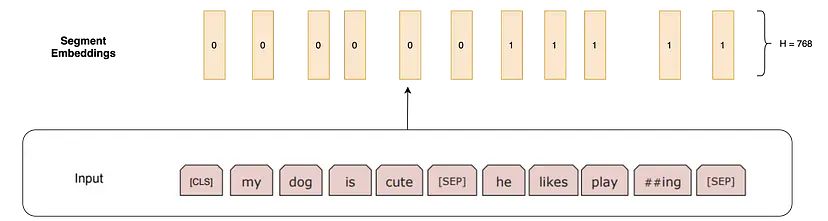
位置嵌入(位置嵌入):这些嵌入用于指定单词在序列中的位置,和 Transformer 中所做的一样。位置矩阵的列数为768,矩阵的第一行是[CLS] Token的嵌入,第二行是单词“my”的嵌入,第三行是单词“dog”的嵌入,以此类推。
给BERT的最终输入是 Token Embeddings、Segment Embeddings、Position Embeddings的叠加(Token Embeddings + Segment Embeddings + Position Embeddings)。
3. 训练遮蔽语言模型(Masked LM)
这部分是 BERT 最有趣的地方。我们将通过各种架构尝试并发现每种尝试的缺陷,以此来解释这些概念,并形成 BERT的最终架构。
尝试1:例如,如果我们按如下方法设置 BERT 训练,即预测输入序列的每个单词。

这种方法的问题在于学习任务过于简单。网络提前就知道它要预测什么,因此可以轻松地学习权重以达到100%的分类准确率。
注意:这里的“预测-Predict”与 Transformer 解码器中基于已经生成的单词,预测下一个单词的“预测”的含义略微不同。这里的“预测-Predict”是“生成-Generation”的意思。这里使用“Predict”这个词,是表达在 Masked LM 模型中,模型根据上下文信息推断被掩蔽 token 的过程。虽然“生成”也可以理解为一种预测,但在NLP术语中,“生成”通常指的是更广泛的内容创建,而不是特定位置 token 的推断。下面几种方法中提到的“预测”一词也是这样的含义。
尝试2:遮蔽语言模型(Masked LM)。原论文中尝试使用此方法克服上述问题。在每个训练输入序列中随机遮蔽15%的单词,并仅预测这些单词的输出。
此种方式计算损失时只针对屏蔽的单词。模型学会了预测它未见过的单词,同时还能看到这些单词周围的上下文。(注意,图中屏蔽了 3 个单词,实际上应该只屏蔽 1 个单词,因为这个示例中,8 个单词的 15% 就是 1 个单词。)
但这种方式的造成了模型在“预训练-微调”两个过程的不匹配问题。
具体来说,在预训练阶段,模型需要根据上下文预测被遮蔽的 token,因此模型会更多地依赖上下文信息来填补空白。但在微调阶段,模型直接处理完整的句子,输入方式不同可能会导致模型的预测行为与预训练阶段存在偏差。另外,在预训练时模型通过预测被掩蔽的token来学习语言的结构和语义,但在微调阶段,模型的目标通常是根据完整输入直接进行分类或预测,这种目标上的差异可能导致模型在微调时需要重新调整。
尝试3:使用随机单词的遮蔽语言模型:
在这个尝试中,仍然会遮蔽15%的位置。但会用随机单词替换那些被遮蔽标记中的20%。这样做是为了让模型知道,即使单词不是[MASK]标记,我们仍然需要输出一些结果。因此,如果我们有一个长度为500的序列,我们将遮蔽75个标记(500的15%),在这75个标记中,有15个标记(75的20%)将被随机单词替换。示意图如下:
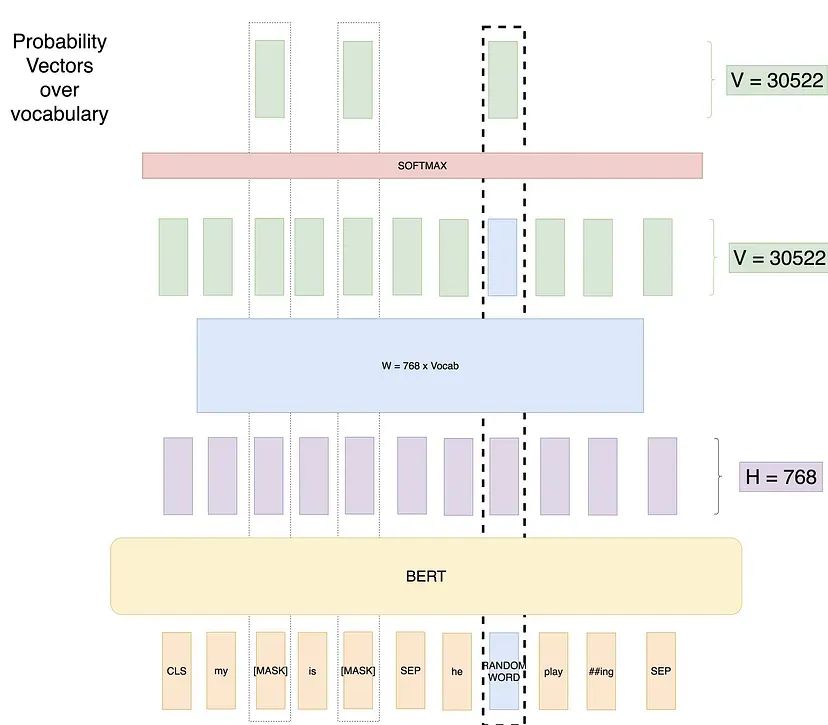
这种方式的优点在于,网络仍然可以处理任何单词。
但其问题在于,模型会学到一种错误模式,即看到随机替换的单词时,这些单词永远不会是正确的输出。比如对于我们的例子,将“likes”随机替换为“eats”,而我们在这个位置需要的输出为“likes”,模型会学习到“eats”的输出永远不会是“eats”。而在不同的上下文中,比如输入“he eats bread”,需要的输出中包含“eats”。
尝试4:使用随机单词和未遮蔽单词的遮蔽语言模型
为了解决这个问题,作者提出了以下训练设置。
在训练数据中随机选择 15% 的 token 位置进行预测。这些随机选择的 token 中,80%替换为[MASK]标记,10%随机替换为词汇表中的其他 token,10% 保持不变。
如果我们有一个长度为 500 的序列,我们将遮蔽75个 token(500的15%),在这75个 token中,7个 token(75的10%)将被随机 token 替换,7个 token(75的10%)保持不变。示意如下:
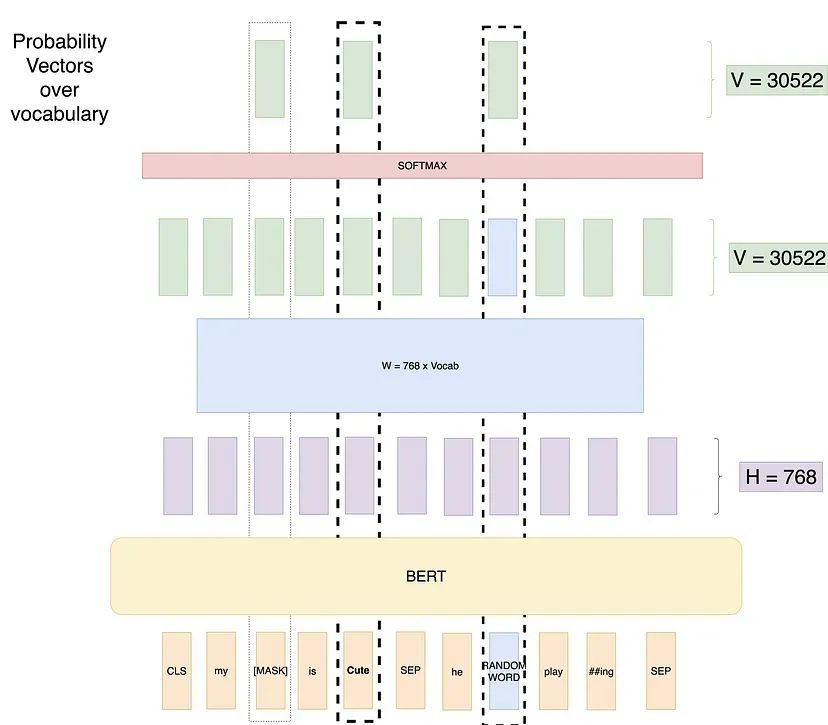
这样就有了最佳设置,模型不会学习到不良模式。
4. 训练附加的下一句预测任务(NSP)
BERT 模型在训练过程中还有另一个并行的于 Masked LM 的训练任务,这个任务称为下一句预测(Next Sentence Prediction, NSP)。在创建训练数据时,我们为每个训练样本选择句子A和B,其中50%的情况下B是实际紧跟在A后的句子(标记为IsNext),而另外50%的情况下B是语料库中的一个随机句子(标记为NotNext)。然后我们使用[CLS]标记的输出来计算损失,这个损失也会通过网络反向传播来调整权重。
摘自 BERT 论文原文:许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都基于两个句子之间的关系,而这种关系不是通过语言模型直接捕捉到的。为了训练一个能够理解句子关系的模型,我们进行了一种二元化的下一句预测任务(binarized next sentence prediction task)的预训练,这个任务可以从任何单语语料库中轻松生成。
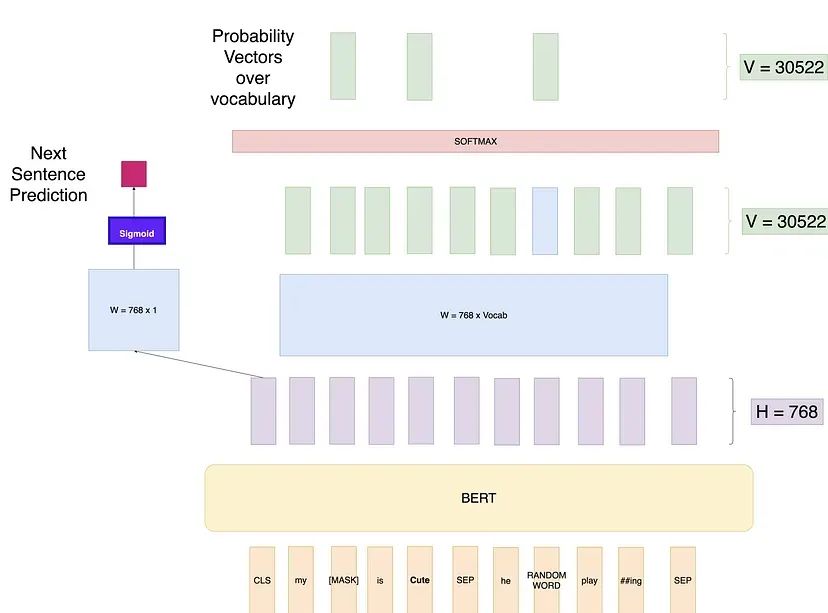
现在我们有了预训练的BERT模型,它可以为我们提供上下文嵌入。那么如何将它用于各种任务呢?
五、针对具体任务进行微调
如前所述,我们可以在 [CLS] 输出上添加几层并微调权重,然后使用BERT进行分类任务。
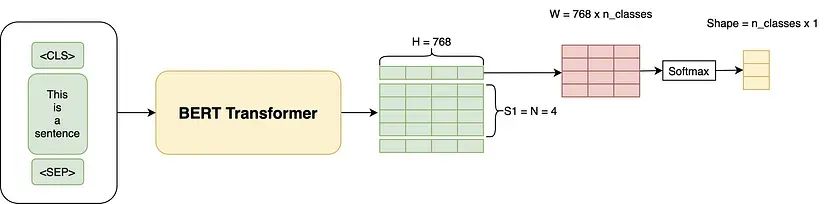
以下是论文中介绍的 BERT 用于其他任务的方法:
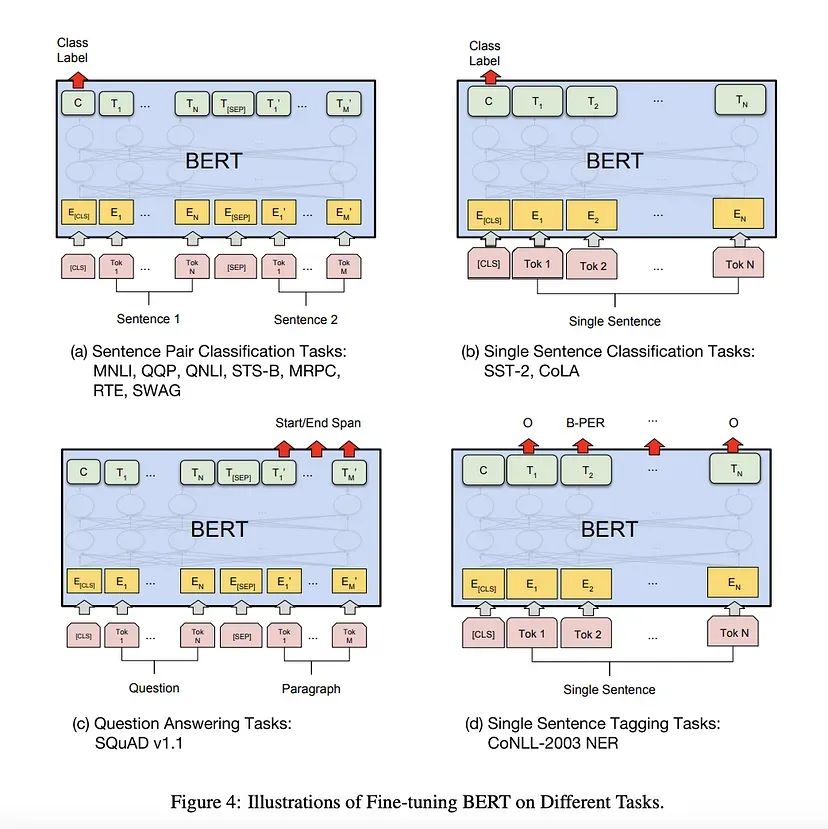
让我们逐一浏览这些任务:
1. 句子对分类任务:这与分类任务非常相似。即在大小为768的[CLS]输出上添加一个线性层和一个Softmax层(Linear + Softmax)。
2. 单句分类任务:与句子对分类任务相同。
4. 单句标注任务:与训练 BERT 时的设置非常相似,只是我们需要为单句中的每个 Token 进行标注。如对于词性标注任务(如预测名词、动词或形容词),我们只需添加一个大小为(768 x n_outputs)的线性层,并在上面添加一个Softmax层进行预测。
3. 问答任务——这个任务中,我们给出一个问题和一个包含答案的段落:目标是确定答案在段落中的起始和结束位置。
六、问答任务详细工作流程
BERT 执行问答任务的原理与 GPT 等以自回归生成答案的模型不同。以下是关于 BERT 在执行问答任务时的详细流程:
1. 输入序列
输入序列由问题和段落拼接而成,并添加特殊标记:
[CLS] 问题 [SEP] 段落 [SEP]
2. BERT模型输出
输入序列通过 BERT 模型处理,生成每个 token 的上下文表示。假设输入序列长度为 𝐿,隐藏层维度为 𝐷,则BERT 的输出表示为一个矩阵 𝐻,其形状为 𝐿×𝐷。
3. 定义向量 𝑆 和 𝐸
向量 𝑆 和 𝐸 是在微调过程中学习的参数,用于分别预测起始位置和结束位置的分数。若隐藏层维度 𝐷=768,则 𝑆 和 𝐸的形状均为 1×768。
4. 计算分数
对于每个 token 的表示向量 ℎ𝑖(BERT的输出),计算其作为答案起始位置和结束位置的分数。具体计算方式向量每个 ℎ𝑖 分别与 𝑆 和 𝐸 向量的装置进行点积(内积),其结果为一个标量:
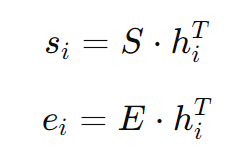
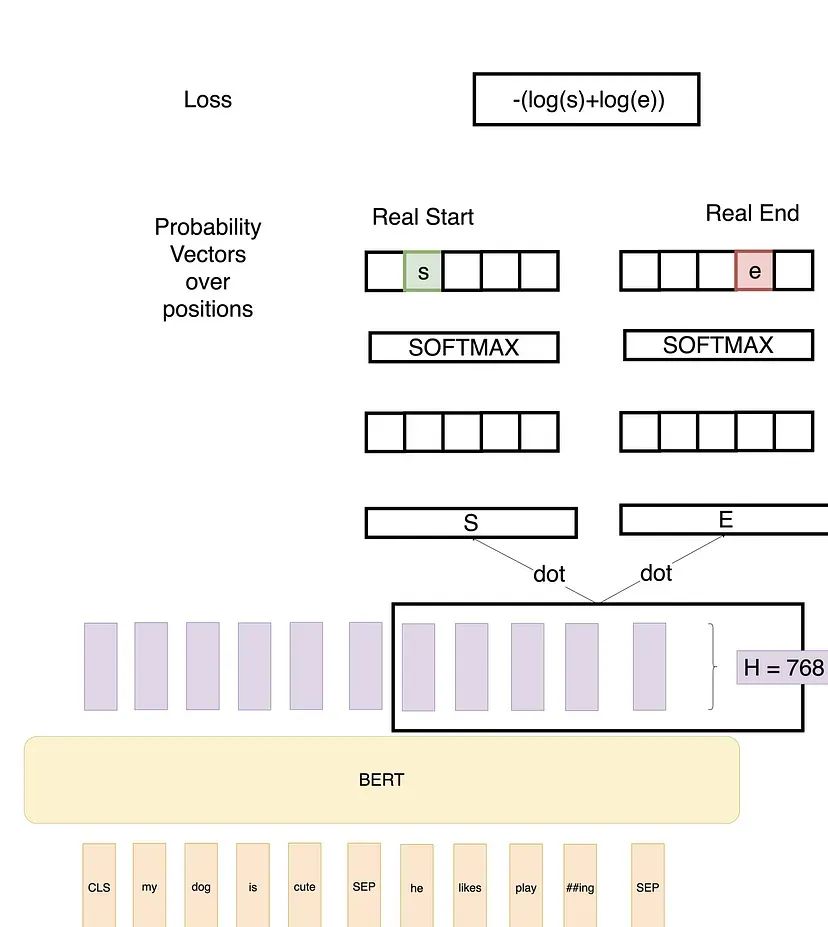
5. 将分数通过 Softmax 函数转换为概率分布
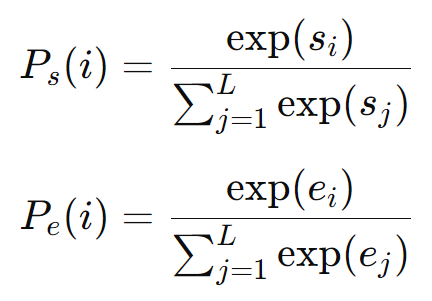
6. 选择最可能的起始和结束位置
- 确定起始和结束位置:根据计算出的起始位置概率分布 𝑃𝑠 和结束位置概率分布 𝑃𝑒,选择概率最高的token 作为答案的起始和结束位置。具体做法是找到使 𝑃𝑠 和 𝑃𝑒 最大的索引位置:
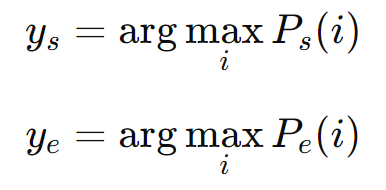
- 确定答案范围:确保起始位置 𝑦𝑠在结束位置 𝑦𝑒 之前,即 𝑦𝑠≤𝑦𝑒。如果需要,可以在推理过程中应用额外的逻辑来处理不合逻辑的预测结果(例如,设置一个最大答案长度)。
7. 提取答案
根据确定的起始和结束位置,从输入序列中的段落部分提取对应的token序列,拼接成最终答案。
8. 训练时的损失计算
问答任务训练的目标是最大化正确起始位置和结束位置的对数似然之和。假设真实的起始位置和结束位置分别为 𝑦𝑠 和 𝑦𝑒,则损失函数(负对数似然)为:
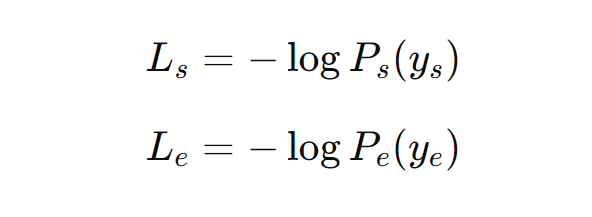
总损失函数为:
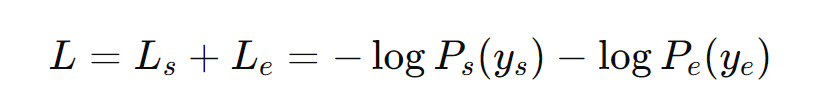
对比 BERT,GPT 在处理问答型任务时,使用自回归方式生成答案,即逐步预测每个 token,基于前面的token生成下一个token,直到生成结束标记或达到预设的最大长度。
七、WordPiece 技术与词嵌入方法的差异
前边我们遗留了一个问题,即 WordPiece 和词嵌入技术方面的差异。以下是二者差异的详细介绍:
1. 原始 Transformer 模型的词嵌入
词汇表:原始的 Transformer 模型通常使用一个固定的词汇表,词汇表中的每个单词都被映射到一个固定长度的向量(词嵌入)。
词嵌入矩阵:在 Transformer 模型中,有一个词嵌入矩阵,用于将输入单词转换为对应的向量表示。
完整单词表示:原始 Transformer 模型中的词嵌入通常是基于完整单词的,也就是说,每个单词在词汇表中都有一个对应的向量。
2. BERT 的 tokenization 技术
词片(WordPiece)嵌入:BERT使用的是一种称为 WordPiece 的子词级别的 tokenization方法。这种方法将单词拆分成更小的子词单元(词片),这些子词单元构成了模型的词汇表。
更小的词汇表:由于使用了子词级别的 tokenization,BERT 的词汇表比基于完整单词的词汇表要小得多。这种方法可以有效处理词汇量大的问题,减少OOV(out-of-vocabulary,词表外词)的情况。
处理未知单词:对于不在词汇表中的单词,BERT 可以通过拆分成已知的子词单元来表示,从而更好地处理未知单词和新词。
词嵌入矩阵:与原始 Transformer 类似,BERT 也有一个词嵌入矩阵,但它是基于子词单元的。每个子词单元都有一个对应的向量表示,这些向量组合在一起构成单词的表示。
3. 示例对比:
输入句子:“Playing football is enjoyable.”
原始 Transformer 模型:
Tokenization结果:
[“Playing”, “football”, “is”, “enjoyable”]
词嵌入向量:
embedding(“Playing”),embedding(“football”),embedding(“is”),embedding(“enjoyable”),每个单词直接作为一个token处理,模型依赖于词汇表中存在的完整单词。
BERT 模型:
Tokenization结果:
[“Play”, “##ing”, “foot”, “##ball”, “is”, “enjoy”, “##able”]
词嵌入向****量:
embedding(“Play”),embedding(“##ing”),embedding(“foot”),embedding(“##ball”),embedding(“is”),embedding(“enjoy”),embedding(“##able”)
八、总结
用最简单的话语概括 BERT 的重要思想
自己总结的:
1.BERT 模型架构利用 Transformer 编码器堆栈结构,是一种能进行文本双向嵌入的语言模型。
2.BERT的 tokenization 采用的是 WordPiece 的方式,Embedding 是 Token Embeddings、Segment Embeddings、Position Embeddings 三者的叠加。
3.BERT 使用“预训练+微调”的方式用于分类、问答、NER 等 NLP 下游任务;预训练采用的是 “MLM+NSP”双任务并行的方式,使用 MLM、NSP 损失的加权和作为总损失进行反向传播;微调时仅需在预训练后的 BERT 模型上增加一个输出层,对此输出层进行微调。
chatgpt-4o总结的:
1. 模型架构
-
Transformer编码器:BERT使用多层的 Transformer 编码器堆栈,每层包含多头自注意力机制和前馈神经网络。这个架构使得 BERT 能够有效地捕捉输入序列中的复杂依赖关系。
-
双向性:BERT是双向的(Bidirectional),这意味着它在训练时能够同时从左到右和从右到左看待上下文。与传统的单向语言模型不同,这种双向性使得BERT能够更好地理解句子的上下文。
2. Tokenization 和 Embeddings
-
WordPiece Tokenization:BERT 使用 WordPiece 分词方法,将单词拆分为更小的子词或字符片段,以处理未见过的词和稀有词。这样可以更好地覆盖语言中的各种词汇。
-
三种嵌入:Token Embeddings,将每个 token 映射到一个固定维度的向量;Position Embeddings,添加位置嵌入,以表示每个token在序列中的位置,从而保留顺序信息;Segment Embeddings,用于区分不同的句子,特别是在句子对任务中,通过添加句子A和句子B的嵌入来区分它们。
3. 预训练任务
-
掩蔽语言模型(Masked Language Model, MLM):在输入序列中随机掩蔽15%的token,然后让模型预测这些被掩蔽的token。这种方法使模型能够在双向上下文中学习每个token的表示。
-
下一句预测(Next Sentence Prediction, NSP):训练模型判断两个句子是否在原始文本中是连续的句子。输入由两个句子组成,50%的情况下它们是连续的,50%的情况下它们是随机选择的不连续句子。这有助于模型理解句子间的关系。
4. 预训练和微调策略
-
预训练:在大规模无标签文本数据上进行预训练,使用 MLM 和 NSP 任务进行训练。预训练使模型学习到通用的语言表示,包括词汇、语法和句子间的关系。
-
微调:在特定的下游任务数据集上进行微调。通过在预训练的BERT模型顶部添加一个任务特定的输出层(例如分类层或序列标注层),对整个模型进行微调。这使得 BERT 可以适应各种特定任务,如文本分类、问答、命名实体识别等。
5. 应用场景
-
文本分类:使用[CLS] token的表示,通过一个线性分类层进行分类任务。适用于情感分析、主题分类等任务。
-
问答系统:输入包括问题和段落,通过预测答案在段落中的起始和结束位置来回答问题。适用于SQuAD等问答数据集。
-
命名实体识别(NER):在每个token的表示上添加一个标注层,预测每个token的实体类别。适用于识别文本中的人名、地名、组织名等。
-
句子对任务:判断两个句子之间的关系,如自然语言推理(NLI)任务,通过在[CLS] token的表示上添加分类层进行预测。适用于MNLI、SNLI等数据集。
综上, BERT(Bidirectional Encoder Representations from Transformers)是一种基于双向Transformer编码器的预训练语言模型,通过双向的上下文嵌入和大规模预训练,提供了强大的语言表示能力。其核心包括WordPiece tokenization、Token/Position/Segment Embeddings、MLM和NSP预训练任务,以及预训练+微调的应用方式。BERT在文本分类、问答系统、命名实体识别等NLP任务中表现优异,广泛应用于各种自然语言处理场景。
用通俗易懂方式讲解系列
-
《大模型面试宝典》(2024版) 正式发布!
-
《大模型实战宝典》(2024版)正式发布!
-
用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
-
用通俗易懂的方式讲解:1.6万字全面掌握 BERT
-
用通俗易懂的方式讲解:NLP 这样学习才是正确路线
-
用通俗易懂的方式讲解:28张图全解深度学习知识!
-
用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
-
用通俗易懂的方式讲解:实体关系抽取入门教程
-
用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
-
用通俗易懂的方式讲解:图解 Transformer 架构
-
用通俗易懂的方式讲解:大模型算法面经指南(附答案)
-
用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
-
用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
-
用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
-
用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
-
用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
-
用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
-
用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
-
用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
-
用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
-
用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
-
用通俗易懂的方式讲解:面试字节大模型算法岗(实习)
-
用通俗易懂的方式讲解:大模型算法岗(含实习)最走心的总结
-
用通俗易懂的方式讲解:大模型微调方法汇总
参考
1-Rahul Agarwa 博客链接:https://thealgorithmicminds.com/explaining-bert-simply-using-sketches-ba30f6f0c8cb
2-BERT 论文:https://arxiv.org/abs/1810.04805
相关文章:
图解 BERT 模型
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学. 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总合集&…...

关于软件设计模式的理解
系列文章 关于时间复杂度o(1), o(n), o(logn), o(nlogn)的理解 关于HashMap的哈希碰撞、拉链法和key的哈希函数设计 关于JVM内存模型和堆内存模型的理解 关于代理模式的理解 关于Mysql基本概念的理解 关于软件设计模式的理解 文章目录 前言一、软件设计模式遵循的六大原则…...

Java开发官方文档
Spring中文网 Spring Cloud中文网 Hutool工具类 Ant Design官方文档 遇见狂神说学习文档 若依后台管理系统测试环境 FineBI官方文档 vscode教程 新一代微服务全家桶AlibabaCloudSpringCloud实战 分布式任务调度平台XXL-JOB...

AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
系列篇章💥 AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研 AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研 AI大模型探索之路-实战篇6:掌握Function Calling的详细流程 AI大模型探索之路-实战篇7…...
 集成paimon0.9)
本地spark3.5(不整合hive) 集成paimon0.9
spark官网下载集成hadoop的spark包: spark-3.5.1-bin-hadoop3.... 解压后 环境变量配置 SPARK_HOME spark-defaults.conf 中增加一行配置(避免启动spark-sql报错hive元数据连不上): spark.sql.catalogImplementationhive 打开paimon官网: https://paimon.apache.org/docs/mas…...
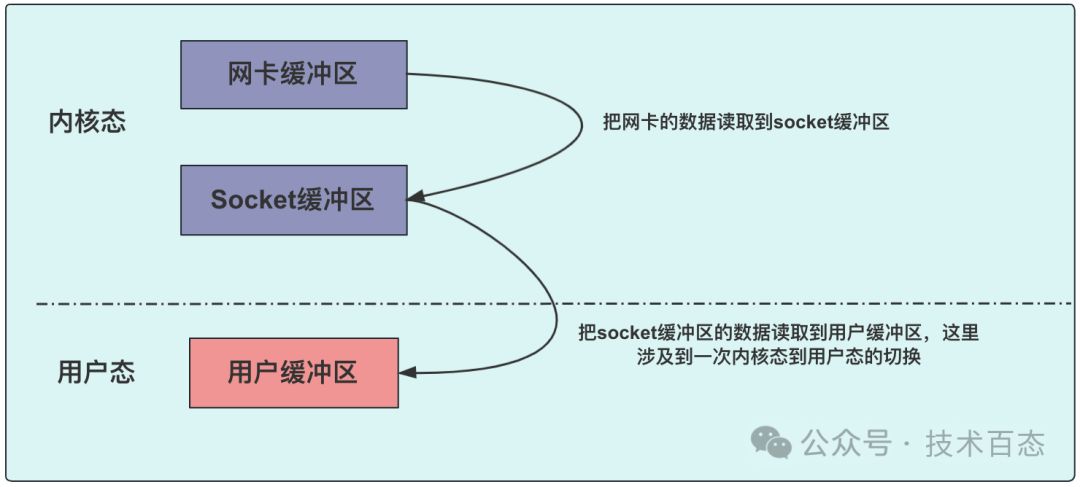
Linux IO模型深度解析与实战应用
linux的5种IO模型 一、这里IO是什么 操作系统设有用户态与内核态,确保系统安全。应用程序默认在用户态运行,而执行如IO操作等底层任务时,需切换至内核态以高效执行。 服务器从网络接收的大致流程如下: 1、数据通过计算机网络来到了网卡 2、把网卡的数据读取到 socket 缓…...

软件系统开发标准流程文档(Word原件)
目的:规范系统开发流程,提高系统开发效率。 立项申请需求分析方案设计方案评审开发调整测试阶段系统培训试运行测试验收投入使用 所有文档过去进主页获取。 软件项目相关全套精华资料包获取方式①:点我获取 获取方式②:本文末个人…...
嵌入式进阶——外部中断(EXTI)
🎬 秋野酱:《个人主页》 🔥 个人专栏:《Java专栏》《Python专栏》 ⛺️心若有所向往,何惧道阻且长 文章目录 STC8H中断外部中断外部中断编写配置外部中断调用中断触发函数 外部中断测试测试外部中断0测试外部中断2、3或者4 PCB中断设计 STC8…...
flinkcdc 3.0 源码学习之客户端flink-cdc-cli模块
注意 : 本文章是基于flinkcdc 3.0 版本写的 我们在前面的文章已经提到过,flinkcdc3.0版本分为4层,API接口层,Connect链接层,Composer同步任务构建层,Runtime运行时层,这篇文章会对API接口层进行一个探索.探索一下flink-cdc-cli模块,看看是如何将一个yaml配置文件转换成一个任务…...
香橙派 AIpro开发体验:使用YOLOV8对USB摄像头画面进行目标检测
香橙派 AIpro开发体验:使用YOLOV8对USB摄像头画面进行目标检测 前言一、香橙派AIpro硬件准备二、连接香橙派AIpro1. 通过网线连接路由器和香橙派AIpro2. 通过wifi连接香橙派AIpro3. 使用vscode 通过ssh连接香橙派AIpro 三、USB摄像头测试1. 配置ipynb远程开发环境1.…...

Python中正则表达式详解
Python中正则表达式详解 引言 正则表达式是一种用于字符串搜索和操作的强大工具。它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在Python中,正则表达式通过内置的re模块来实现,使得文本处理变得简洁而高效。 正则表达式基础 在深入…...

vue使用EventBus进行跨组件通信
Vue中的EventBus,又称为事件总线,是一种常用的通信模式,它允许在Vue应用程序的不同组件之间进行松耦合的通信,尤其是对于那些没有直接父子关系的组件间的通信非常有用。EventBus基于Vue的自定义事件系统实现,工作原理遵…...

boot项目中定时任务quartz
最近换项目组,发现项目中定时任务使用的是quartz框架,上一篇文章[springboot定时任务]也是使用的quartz,只不过实现方式不同,于是整理下 定时任务常用方法有Quartz,Spring自带的Schedule框架 Quartz基础知识 quartz…...

使用阿里云OSS实现视频上传功能
目录 前言 视频上传 前言 阿里云对象存储服务(OSS)作为一种高可用、高扩展性的云端存储服务,为开发者提供了便捷、安全的对象存储解决方案。本文将介绍如何利用阿里云OSS实现视频上传功能。 视频上传 前期准备请看阿里云OSS文件上传和下载…...

LOTO示波器软件新增导览功能
新版本的大部分型号LOTO示波器的上位机软件我们改成了导航工具条方式。原来的方式是把所有功能都显示在不同的标签页中,这样的优点是非常快捷方便,基本上用鼠标一两次点击就能直达想要的功能设置。但是缺点是不熟练的客户可能记不住各种功能的标签位置在…...

【StructueEngineering】SYMBOL SCHEDULE
文章目录 标记表列SYMBOL SCHEDULELINES线条COLUMN REFERENCE SYMBOL柱参考标记SECTION REFERENCE SYMBOLS剖面参考标记DETAILREFERENCE SYMBOLS详图参考标记GENERALELEVATIONSYMBOLS一般立面图标记MISCELLANEOUS SYMBOLS杂项标记 STEEL FRAMING SYMBOLS钢结构平面图标记COLUMN…...

简化跨网文件传输摆渡过程,降低IT人员工作量
在当今数字化时代,IT企业面临着日益增长的数据交换需求。随着网络安全威胁的不断演变,网关隔离成为了保护企业内部网络不受外部威胁的重要手段。然而,隔离的同时,企业也需要在不同网络间安全、高效地传输文件,这就催生…...

关于python中屏蔽输出
python中屏蔽输出包含屏蔽标准输出(比如打印出来的内容)、屏蔽标准错误(错误信息)还有屏蔽logging信息等。 屏蔽标准输出 import contextlib import oswith open(os.devnull, "w") as devnull:with contextlib.redire…...
螺旋矩阵(算法题)
文章目录 螺旋矩阵解题思路 螺旋矩阵 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]解题思路 模…...

ffmpeg-webrtc(metartc)给ffmpeg添加webrtc协议
这个是使用metrtc的库为ffmpeg添加webrtc传输协议,目前国内还有一个这样的开源项目,是杨成立大佬,大师兄他们在做,不过wili页面维护的不好,新手不知道如何使用,我专门对它做过介绍,另一篇博文&a…...
)
告别C盘爆满!手把手教你将VS2010旗舰版安装到其他盘(附完整配置流程)
告别C盘爆满!手把手教你将VS2010旗舰版安装到其他盘(附完整配置流程) 对于开发者而言,Visual Studio 2010(VS2010)作为经典的开发环境,至今仍被许多项目所依赖。然而,随着系统盘空间…...

实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本
实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg logitech-pubg是一个针对《绝…...

从拉灯呼叫到闭环处理:安灯管理软件操作流程能解决哪些场景痛点?一套安灯管理软件操作流程实战
在制造工厂的生产现场,异常就像不速之客,总在最忙的时候敲门。设备突然停机、物料没送到位、质量出现批量不良……这些异常发生后,最让人头疼的往往不是问题本身,而是处理问题的过程。工人发现设备停了,扯着嗓子喊班长…...

ARM嵌入式开发板OpenSSH移植全攻略:从交叉编译到部署实战
1. 项目概述与核心价值给嵌入式开发板移植OpenSSH,这几乎是每一个从单片机转向Linux嵌入式开发的工程师都会遇到的“成人礼”。你可能已经习惯了用串口调试终端,一根线连着,虽然稳定,但也被束缚在工位前。当你的设备需要部署到某个…...

全志T113-S3开发板网络配置实战:从DHCP到静态IP与故障排查
1. 项目概述:从零上手T113-S3的网络配置刚拿到一块新的全志T113-S3开发板,比如眺望电子的EVM-T113-S3,第一件事你会做什么?我的习惯是,先把它“连上网”。这听起来简单,但却是后续所有高级操作——无论是通…...

透明化智慧港口码头•装载·存储·集散全流程透明化管控方案
一、方案前言本方案依托黎阳之光镜像孪生、时空AI拓扑、无感全域定位、视频实景融合、边缘实时算力五大核心技术,聚焦港口码头货物装载、堆场存储、集疏运集散三大核心业务,打造实景可视、数字镜像、智能调度、全程透明、风险可控、全程可溯的智慧管控体…...

【教程】全流程基于最新导则下的生态环境影响评价技术方法及图件制作与案例实践技术应用
专题一:生态环境影响评价框架及流程 以某既包含陆域、又包含水域的项目为主要案例,兼顾其它类型项目,主要内容包括: 1、生态环境影响评价基本思路与要求:工作程序、报告编制技术要求与规范 2、资料收集与初步踏勘&a…...

影刀RPA跨境店群运营架构:TikTok Shop矩阵多节点高并发调度与Python环境隔离实战
大家好,我是林焱。 太有意思了,刚刷朋友圈,看到一个在跨境圈子里被疯狂转发的消息。 有几个当年和我一样,在职业技术学院念工程出身的 00 后学弟,最近跑回母校干了件特别硬核的事。 他们没有像传统的成功校友那样&a…...

2026企业网盘选型对比:坚果云领衔,5款主流产品优劣与场景建议
随着企业数字化办公不断加深,企业网盘已从“文件存储工具”演变为“组织级协作平台”。到2026年,各厂商在同步机制、协作效率、权限体系与安全合规方面差距进一步拉大。本文对5款主流企业网盘做横向对比,帮助管理者按业务场景选到更合适的方案…...

技术突破:如何让ARM设备突破x86架构的束缚?
技术突破:如何让ARM设备突破x86架构的束缚? 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾…...