flinkcdc 3.0 源码学习之客户端flink-cdc-cli模块
注意 : 本文章是基于flinkcdc 3.0 版本写的
我们在前面的文章已经提到过,flinkcdc3.0版本分为4层,API接口层,Connect链接层,Composer同步任务构建层,Runtime运行时层,这篇文章会对API接口层进行一个探索.探索一下flink-cdc-cli模块,看看是如何将一个yaml配置文件转换成一个任务实体类,并且启动任务的.
概述
flink-cdc-cli 模块目录结构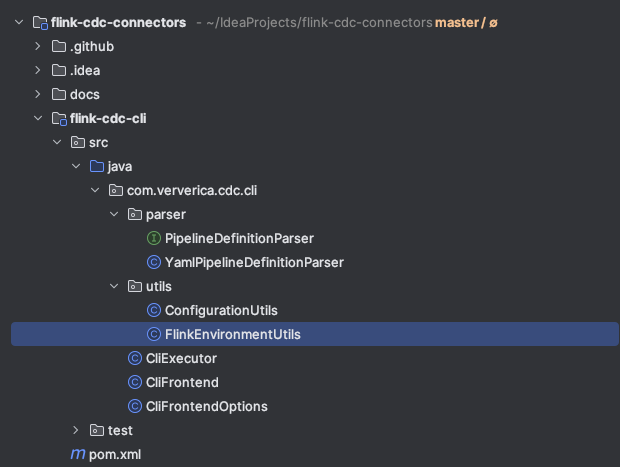
可以看到一共有6个类,1个接口,其中在上一篇文章探索flink-cdc.sh脚本的时候我们知道入口类是CliFrontend,所以接下来会从这个类来一步一步探索这一模块.
入口类 CliFrontend
main方法
public static void main(String[] args) throws Exception {Options cliOptions = CliFrontendOptions.initializeOptions();CommandLineParser parser = new DefaultParser();CommandLine commandLine = parser.parse(cliOptions, args);// Help messageif (args.length == 0 || commandLine.hasOption(CliFrontendOptions.HELP)) {HelpFormatter formatter = new HelpFormatter();formatter.setLeftPadding(4);formatter.setWidth(80);formatter.printHelp(" ", cliOptions);return;}// Create executor and execute the pipelinePipelineExecution.ExecutionInfo result = createExecutor(commandLine).run();// Print execution resultprintExecutionInfo(result);}
这里首先是初始化了一下选项,这里用到了Apache Commons CLI 这个工具类,可以很方便的处理命令行参数
大概的步骤有3步
1.定义阶段 : 定义要解析的命令选项,对应的每个选项就是一个Option类,Options类是Option类的一个集合
2.解析阶段 : 通过CommandLineParser的parser方法将main方法的args参数解析,获得一个CommandLine对象
3.查询阶段 : 就是具体使用解析后的结果,可以通过hasOption来判断是否有该选项,getOptionValue来获取选项对应的值
具体可以参考我的另外一系列文章,有详细介绍这个工具的用法
超强命令行解析工具 Apache Commons CLI
超强命令行解析工具 Apache Commons CLI 各个模块阅读
解析了入参后就判断入参args是否是空或者是否包含-h或者–help这个选项,如果是的话就打印一下帮助信息
接着通过CommandLine对象创建执行器并且执行任务
最后在打印一下结果信息
这个类中最核心的一行就是创建执行器并且执行任务
// Create executor and execute the pipeline
PipelineExecution.ExecutionInfo result = createExecutor(commandLine).run();static CliExecutor createExecutor(CommandLine commandLine) throws Exception {// The pipeline definition file would remain unparsedList<String> unparsedArgs = commandLine.getArgList();if (unparsedArgs.isEmpty()) {throw new IllegalArgumentException("Missing pipeline definition file path in arguments. ");}// Take the first unparsed argument as the pipeline definition filePath pipelineDefPath = Paths.get(unparsedArgs.get(0));if (!Files.exists(pipelineDefPath)) {throw new FileNotFoundException(String.format("Cannot find pipeline definition file \"%s\"", pipelineDefPath));}// Global pipeline configurationConfiguration globalPipelineConfig = getGlobalConfig(commandLine);// Load Flink environmentPath flinkHome = getFlinkHome(commandLine);Configuration flinkConfig = FlinkEnvironmentUtils.loadFlinkConfiguration(flinkHome);// Additional JARsList<Path> additionalJars =Arrays.stream(Optional.ofNullable(commandLine.getOptionValues(CliFrontendOptions.JAR)).orElse(new String[0])).map(Paths::get).collect(Collectors.toList());// Build executorreturn new CliExecutor(pipelineDefPath,flinkConfig,globalPipelineConfig,commandLine.hasOption(CliFrontendOptions.USE_MINI_CLUSTER),additionalJars);}
可以看到最后是构建了一个CliExecutor类,并执行了它的run方法.
选项类 CliFrontendOptions
这个类主要是用来定义命令行选项的,使用的是Apache Commons CLI这个类库,代码比较简单
这里主要细看一下各个选项都有什么作用
package org.apache.flink.cdc.cli;import org.apache.commons.cli.Option;
import org.apache.commons.cli.Options;/** Command line argument options for {@link CliFrontend}. */
public class CliFrontendOptions {public static final Option FLINK_HOME =Option.builder().longOpt("flink-home").hasArg().desc("Path of Flink home directory").build();public static final Option HELP =Option.builder("h").longOpt("help").desc("Display help message").build();public static final Option GLOBAL_CONFIG =Option.builder().longOpt("global-config").hasArg().desc("Path of the global configuration file for Flink CDC pipelines").build();public static final Option JAR =Option.builder().longOpt("jar").hasArgs().desc("JARs to be submitted together with the pipeline").build();public static final Option USE_MINI_CLUSTER =Option.builder().longOpt("use-mini-cluster").hasArg(false).desc("Use Flink MiniCluster to run the pipeline").build();public static Options initializeOptions() {return new Options().addOption(HELP).addOption(JAR).addOption(FLINK_HOME).addOption(GLOBAL_CONFIG).addOption(USE_MINI_CLUSTER);}
}–flink-home
指定flink-home的地址,有了这个参数我们就可以不使用系统环境自带的FLINK_HOME,可以使用指定的flink版本
–global-config
flink cdc pipelines 的全局配置文件 也就是 flink conf目录下的那个 flink-cdc.yaml文件,这里面的参数很少,我看只有配置一个并发度,其他的配置没看到,这块有感兴趣的老铁可以再仔细看看
–jar
和任务一起提交的依赖jar包
–use-mini-cluster
使用mini-cluster模式启动,mini-cluster相当于就是本地local模式启动,会用多个现成模拟JobManager,TaskManager,ResourceManager,Dispatcher等组件,一般用于测试
-h 或者 --help
打印帮助信息
执行类 CliExecutor
package com.ververica.cdc.cli;import com.ververica.cdc.cli.parser.PipelineDefinitionParser;
import com.ververica.cdc.cli.parser.YamlPipelineDefinitionParser;
import com.ververica.cdc.cli.utils.FlinkEnvironmentUtils;
import com.ververica.cdc.common.annotation.VisibleForTesting;
import com.ververica.cdc.common.configuration.Configuration;
import com.ververica.cdc.composer.PipelineComposer;
import com.ververica.cdc.composer.PipelineExecution;
import com.ververica.cdc.composer.definition.PipelineDef;import java.nio.file.Path;
import java.util.List;/** Executor for doing the composing and submitting logic for {@link CliFrontend}. */
public class CliExecutor {private final Path pipelineDefPath;private final Configuration flinkConfig;private final Configuration globalPipelineConfig;private final boolean useMiniCluster;private final List<Path> additionalJars;private PipelineComposer composer = null;public CliExecutor(Path pipelineDefPath,Configuration flinkConfig,Configuration globalPipelineConfig,boolean useMiniCluster,List<Path> additionalJars) {this.pipelineDefPath = pipelineDefPath;this.flinkConfig = flinkConfig;this.globalPipelineConfig = globalPipelineConfig;this.useMiniCluster = useMiniCluster;this.additionalJars = additionalJars;}public PipelineExecution.ExecutionInfo run() throws Exception {// Parse pipeline definition filePipelineDefinitionParser pipelineDefinitionParser = new YamlPipelineDefinitionParser();PipelineDef pipelineDef =pipelineDefinitionParser.parse(pipelineDefPath, globalPipelineConfig);// Create composerPipelineComposer composer = getComposer(flinkConfig);// Compose pipelinePipelineExecution execution = composer.compose(pipelineDef);// Execute the pipelinereturn execution.execute();}private PipelineComposer getComposer(Configuration flinkConfig) {if (composer == null) {return FlinkEnvironmentUtils.createComposer(useMiniCluster, flinkConfig, additionalJars);}return composer;}@VisibleForTestingvoid setComposer(PipelineComposer composer) {this.composer = composer;}@VisibleForTestingpublic Configuration getFlinkConfig() {return flinkConfig;}@VisibleForTestingpublic Configuration getGlobalPipelineConfig() {return globalPipelineConfig;}@VisibleForTestingpublic List<Path> getAdditionalJars() {return additionalJars;}
}这个类的核心就是run 方法
首先是构建了一个yaml解析器用于解析yaml配置文件
然后调用parser 方法 获得一个PipelineDef类,这相当与将yaml配置文件转换成了一个配置实体Bean,方便之后操作
接下来获取到PipelineComposer对象,然后调用compose 方法传入刚刚的配置实体BeanPiplineDef对象,就获得了一个PiplineExecution对象
最后调用execute方法启动任务(这个方法底层就是调用了flink 的 StreamExecutionEnvironment.executeAsync方法)
配置文件解析类 YamlPipelineDefinitionParser
看这个类之前先看一下官网给的任务构建的demo yaml
################################################################################
# Description: Sync MySQL all tables to Doris
################################################################################
source:type: mysqlhostname: localhostport: 3306username: rootpassword: 12345678tables: doris_sync.\.*server-id: 5400-5404server-time-zone: Asia/Shanghaisink:type: dorisfenodes: 127.0.0.1:8031username: rootpassword: ""table.create.properties.light_schema_change: truetable.create.properties.replication_num: 1route:- source-table: doris_sync.a_\.*sink-table: ods.ods_a- source-table: doris_sync.abcsink-table: ods.ods_abc- source-table: doris_sync.table_\.*sink-table: ods.ods_tablepipeline:name: Sync MySQL Database to Dorisparallelism: 2
这个类的主要目标就是要将这个yaml文件解析成一个实体类PipelineDef方便之后的操作
代码解释就直接写到注释中了
package com.ververica.cdc.cli.parser;import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.type.TypeReference;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.JsonNode;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.yaml.YAMLFactory;import com.ververica.cdc.common.configuration.Configuration;
import com.ververica.cdc.composer.definition.PipelineDef;
import com.ververica.cdc.composer.definition.RouteDef;
import com.ververica.cdc.composer.definition.SinkDef;
import com.ververica.cdc.composer.definition.SourceDef;import java.nio.file.Path;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Optional;import static com.ververica.cdc.common.utils.Preconditions.checkNotNull;/** Parser for converting YAML formatted pipeline definition to {@link PipelineDef}. */
public class YamlPipelineDefinitionParser implements PipelineDefinitionParser {// Parent node keysprivate static final String SOURCE_KEY = "source";private static final String SINK_KEY = "sink";private static final String ROUTE_KEY = "route";private static final String PIPELINE_KEY = "pipeline";// Source / sink keysprivate static final String TYPE_KEY = "type";private static final String NAME_KEY = "name";// Route keysprivate static final String ROUTE_SOURCE_TABLE_KEY = "source-table";private static final String ROUTE_SINK_TABLE_KEY = "sink-table";private static final String ROUTE_DESCRIPTION_KEY = "description";// 这个是 解析的核心工具方法,可以获取yaml文件中的值,或者将其中的值转换成java实体类private final ObjectMapper mapper = new ObjectMapper(new YAMLFactory());/** Parse the specified pipeline definition file. */@Overridepublic PipelineDef parse(Path pipelineDefPath, Configuration globalPipelineConfig)throws Exception {// 首先将 pipelineDefPath (就是传入的mysql-to-doris.yaml文件) 通过readTree 转换成 一个JsonNode 对象,方便之后解析JsonNode root = mapper.readTree(pipelineDefPath.toFile());// Source is requiredSourceDef sourceDef =toSourceDef(checkNotNull(root.get(SOURCE_KEY), // 获取 source 这个json对象"Missing required field \"%s\" in pipeline definition",SOURCE_KEY));// 这个和source 同理,不解释了// Sink is requiredSinkDef sinkDef =toSinkDef(checkNotNull(root.get(SINK_KEY), // 获取 sink json对象"Missing required field \"%s\" in pipeline definition",SINK_KEY));// 这里是路由配置,是个数组,而且是个可选项,所以这里优雅的使用了Optional对root.get(ROUTE_KEY) 做了一层包装// 然后调用ifPresent方法来判断,如果参数存在的时候才会执行的逻辑,就是遍历数组然后加到 routeDefs 中// Routes are optionalList<RouteDef> routeDefs = new ArrayList<>();Optional.ofNullable(root.get(ROUTE_KEY)).ifPresent(node -> node.forEach(route -> routeDefs.add(toRouteDef(route))));// Pipeline configs are optional// pipeline 参数,是可选项,这个如果不指定,配置就是用的flink-cdc中的配置Configuration userPipelineConfig = toPipelineConfig(root.get(PIPELINE_KEY));// Merge user config into global config// 合并用户配置和全局配置// 这里可以看到是先addAll 全局配置,后addAll 用户配置,这的addAll实际上就是HashMap的putAll,新值会把旧值覆盖,所以用户的配置优先级大于全局配置Configuration pipelineConfig = new Configuration();pipelineConfig.addAll(globalPipelineConfig);pipelineConfig.addAll(userPipelineConfig);// 返回 任务的实体类return new PipelineDef(sourceDef, sinkDef, routeDefs, null, pipelineConfig);}private SourceDef toSourceDef(JsonNode sourceNode) {// 将sourceNode 转换成一个 Map类型Map<String, String> sourceMap =mapper.convertValue(sourceNode, new TypeReference<Map<String, String>>() {});// "type" field is requiredString type =checkNotNull(sourceMap.remove(TYPE_KEY), // 将type 字段移除取出"Missing required field \"%s\" in source configuration",TYPE_KEY);// "name" field is optionalString name = sourceMap.remove(NAME_KEY); // 将 name 字段移除取出// 构建SourceDef对象return new SourceDef(type, name, Configuration.fromMap(sourceMap));}private SinkDef toSinkDef(JsonNode sinkNode) {Map<String, String> sinkMap =mapper.convertValue(sinkNode, new TypeReference<Map<String, String>>() {});// "type" field is requiredString type =checkNotNull(sinkMap.remove(TYPE_KEY),"Missing required field \"%s\" in sink configuration",TYPE_KEY);// "name" field is optionalString name = sinkMap.remove(NAME_KEY);return new SinkDef(type, name, Configuration.fromMap(sinkMap));}private RouteDef toRouteDef(JsonNode routeNode) {String sourceTable =checkNotNull(routeNode.get(ROUTE_SOURCE_TABLE_KEY),"Missing required field \"%s\" in route configuration",ROUTE_SOURCE_TABLE_KEY).asText(); // 从JsonNode 获取String类型的值String sinkTable =checkNotNull(routeNode.get(ROUTE_SINK_TABLE_KEY),"Missing required field \"%s\" in route configuration",ROUTE_SINK_TABLE_KEY).asText();String description =Optional.ofNullable(routeNode.get(ROUTE_DESCRIPTION_KEY)).map(JsonNode::asText).orElse(null);return new RouteDef(sourceTable, sinkTable, description);}private Configuration toPipelineConfig(JsonNode pipelineConfigNode) {if (pipelineConfigNode == null || pipelineConfigNode.isNull()) {return new Configuration();}Map<String, String> pipelineConfigMap =mapper.convertValue(pipelineConfigNode, new TypeReference<Map<String, String>>() {});return Configuration.fromMap(pipelineConfigMap);}
}配置信息工具类 ConfigurationUtils
package com.ververica.cdc.cli.utils;import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.type.TypeReference;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.yaml.YAMLFactory;import com.ververica.cdc.common.configuration.Configuration;import java.io.FileNotFoundException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Map;/** Utilities for handling {@link Configuration}. */
public class ConfigurationUtils {public static Configuration loadMapFormattedConfig(Path configPath) throws Exception {if (!Files.exists(configPath)) {throw new FileNotFoundException(String.format("Cannot find configuration file at \"%s\"", configPath));}ObjectMapper mapper = new ObjectMapper(new YAMLFactory());try {Map<String, String> configMap =mapper.readValue(configPath.toFile(), new TypeReference<Map<String, String>>() {});return Configuration.fromMap(configMap);} catch (Exception e) {throw new IllegalStateException(String.format("Failed to load config file \"%s\" to key-value pairs", configPath),e);}}
}这个类就一个方法,主要的作用就是将一个配置文件转换成 Configuration对象
来看一下具体的实现细节吧
首先是 Files.exists 判断了一下文件是否存在,不存在就直接抛异常
ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
这行代码主要是用了Jackson库中的两个核心类,ObjectMapper和YAMLFactory
ObjectMapper 是 Jackson 库中用于序列化(将对象转换为字节流或其他格式)和反序列化(将字节流或其他格式转换为对象)的核心类。它提供了各种方法来处理 JSON、YAML 等格式的数据。
YAMLFactory 是 Jackson 库中专门用于处理 YAML 格式的工厂类。在这里,我们通过 new YAMLFactory() 创建了一个 YAML 格式的工厂实例,用于处理 YAML 数据。
new ObjectMapper(new YAMLFactory()):这部分代码创建了一个 ObjectMapper 实例,并使用指定的 YAMLFactory 来配置它,这样 ObjectMapper 就能够处理 YAML 格式的数据了。
Map<String, String> configMap =mapper.readValue(configPath.toFile(), new TypeReference<Map<String, String>>() {});
这行的意思就是传入yaml配置文件,容纳后将其转换成一个Map类型,kv都是String
因为这个类的主要用途是解析global-conf的,也就是conf目录下的flink-cdc.yaml,这个文件仅只有kv类型的,所以要转换成map
flink-cdc.yaml
# Parallelism of the pipeline
parallelism: 4# Behavior for handling schema change events from source
schema.change.behavior: EVOLVE
这里再简单看一下mapper的readValue方法
Jackson ObjectMapper的readValue方法主要用途就是将配置文件转换成java实体,主要可以三个重载
public <T> T readValue(File src, Class<T> valueType); // 将配置转换成一个实体类
public <T> T readValue(File src, TypeReference<T> valueTypeRef); // 针对一些Map,List,数组类型可以用这个
public <T> T readValue(File src, JavaType valueType); // 这个一般不常用
最后这行就是将一个map转换成Configuration对象
return Configuration.fromMap(configMap);
这里的Configuration就是将HashMap做了一个封装,方便操作
FLink环境工具类 FlinkEnvironmentUtils
package com.ververica.cdc.cli.utils;import com.ververica.cdc.common.configuration.Configuration;
import com.ververica.cdc.composer.flink.FlinkPipelineComposer;import java.nio.file.Path;
import java.util.List;/** Utilities for handling Flink configuration and environment. */
public class FlinkEnvironmentUtils {private static final String FLINK_CONF_DIR = "conf";private static final String FLINK_CONF_FILENAME = "flink-conf.yaml";public static Configuration loadFlinkConfiguration(Path flinkHome) throws Exception {Path flinkConfPath = flinkHome.resolve(FLINK_CONF_DIR).resolve(FLINK_CONF_FILENAME);return ConfigurationUtils.loadMapFormattedConfig(flinkConfPath);}public static FlinkPipelineComposer createComposer(boolean useMiniCluster, Configuration flinkConfig, List<Path> additionalJars) {if (useMiniCluster) {return FlinkPipelineComposer.ofMiniCluster();}return FlinkPipelineComposer.ofRemoteCluster(org.apache.flink.configuration.Configuration.fromMap(flinkConfig.toMap()),additionalJars);}
}public static Configuration loadFlinkConfiguration(Path flinkHome) throws Exception {Path flinkConfPath = flinkHome.resolve(FLINK_CONF_DIR).resolve(FLINK_CONF_FILENAME);return ConfigurationUtils.loadMapFormattedConfig(flinkConfPath);}
这个方法的主要目的就是通过找到FLINK_HOME/conf/flink-conf.yaml文件,然后将这个文件转换成一个Configuration对象,转换的方法在上一节中介绍过了
这里还用到了Path 的 resolve 方法,就是用于拼接两个Path然后形成一个新Path的方法
public static FlinkPipelineComposer createComposer(boolean useMiniCluster, Configuration flinkConfig, List<Path> additionalJars) {if (useMiniCluster) {return FlinkPipelineComposer.ofMiniCluster();}return FlinkPipelineComposer.ofRemoteCluster(org.apache.flink.configuration.Configuration.fromMap(flinkConfig.toMap()),additionalJars);}
这个是通过一些参数来初始化Composer,Composer就是将用户的任务翻译成一个Pipeline作业的核心类
这里首先是判断了一下是否使用miniCluster,如果是的话就用minicluster ,这个可以在启动的时候用–use-mini-cluster 来指定,具体在上文中介绍过.
如果不是那么就用remoteCluster,这里就不多介绍了,之后的文章会介绍
总结
上面几个类写的比较多,这里做一个总结,简单的来总结一下这个模块
flink-cdc-cli 模块的主要作用
1.解析任务配置yaml文件,转换成一个PipelineDef任务实体类
2.通过FLINK_HOME获取flink的相关配置信息,然后构建出一个PipelineComposer 对象
3.调用composer的comoose方法,传入任务实体类获取PipelineExecution任务执行对象,然后启动任务
再简单的概述一下 : 解析配置文件生成任务实体类,然后启动任务
通过阅读这模块的源码的收获 :
1.学习使用了Apache Commons CLI 工具,之后如果自己写命令行工具的话也可以用这个
2.学习了 Jackson 解析yaml文件
3.加深了对Optional类判断null值的印象,之后对于null值判断有个一个更优雅的写法
4.对flink-cdc-cli模块有了个全面的认识,但是具体还有些细节需要需要深入到其他模块再去了解
总之阅读大佬们写的代码真是收获很大~
参考
[mini-cluster介绍] : https://www.cnblogs.com/wangwei0721/p/14052016.html
[Jackson ObjectMapper#readValue 使用] : https://www.cnblogs.com/del88/p/13098678.html
相关文章:
flinkcdc 3.0 源码学习之客户端flink-cdc-cli模块
注意 : 本文章是基于flinkcdc 3.0 版本写的 我们在前面的文章已经提到过,flinkcdc3.0版本分为4层,API接口层,Connect链接层,Composer同步任务构建层,Runtime运行时层,这篇文章会对API接口层进行一个探索.探索一下flink-cdc-cli模块,看看是如何将一个yaml配置文件转换成一个任务…...
香橙派 AIpro开发体验:使用YOLOV8对USB摄像头画面进行目标检测
香橙派 AIpro开发体验:使用YOLOV8对USB摄像头画面进行目标检测 前言一、香橙派AIpro硬件准备二、连接香橙派AIpro1. 通过网线连接路由器和香橙派AIpro2. 通过wifi连接香橙派AIpro3. 使用vscode 通过ssh连接香橙派AIpro 三、USB摄像头测试1. 配置ipynb远程开发环境1.…...

Python中正则表达式详解
Python中正则表达式详解 引言 正则表达式是一种用于字符串搜索和操作的强大工具。它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在Python中,正则表达式通过内置的re模块来实现,使得文本处理变得简洁而高效。 正则表达式基础 在深入…...

vue使用EventBus进行跨组件通信
Vue中的EventBus,又称为事件总线,是一种常用的通信模式,它允许在Vue应用程序的不同组件之间进行松耦合的通信,尤其是对于那些没有直接父子关系的组件间的通信非常有用。EventBus基于Vue的自定义事件系统实现,工作原理遵…...

boot项目中定时任务quartz
最近换项目组,发现项目中定时任务使用的是quartz框架,上一篇文章[springboot定时任务]也是使用的quartz,只不过实现方式不同,于是整理下 定时任务常用方法有Quartz,Spring自带的Schedule框架 Quartz基础知识 quartz…...

使用阿里云OSS实现视频上传功能
目录 前言 视频上传 前言 阿里云对象存储服务(OSS)作为一种高可用、高扩展性的云端存储服务,为开发者提供了便捷、安全的对象存储解决方案。本文将介绍如何利用阿里云OSS实现视频上传功能。 视频上传 前期准备请看阿里云OSS文件上传和下载…...

LOTO示波器软件新增导览功能
新版本的大部分型号LOTO示波器的上位机软件我们改成了导航工具条方式。原来的方式是把所有功能都显示在不同的标签页中,这样的优点是非常快捷方便,基本上用鼠标一两次点击就能直达想要的功能设置。但是缺点是不熟练的客户可能记不住各种功能的标签位置在…...

【StructueEngineering】SYMBOL SCHEDULE
文章目录 标记表列SYMBOL SCHEDULELINES线条COLUMN REFERENCE SYMBOL柱参考标记SECTION REFERENCE SYMBOLS剖面参考标记DETAILREFERENCE SYMBOLS详图参考标记GENERALELEVATIONSYMBOLS一般立面图标记MISCELLANEOUS SYMBOLS杂项标记 STEEL FRAMING SYMBOLS钢结构平面图标记COLUMN…...

简化跨网文件传输摆渡过程,降低IT人员工作量
在当今数字化时代,IT企业面临着日益增长的数据交换需求。随着网络安全威胁的不断演变,网关隔离成为了保护企业内部网络不受外部威胁的重要手段。然而,隔离的同时,企业也需要在不同网络间安全、高效地传输文件,这就催生…...

关于python中屏蔽输出
python中屏蔽输出包含屏蔽标准输出(比如打印出来的内容)、屏蔽标准错误(错误信息)还有屏蔽logging信息等。 屏蔽标准输出 import contextlib import oswith open(os.devnull, "w") as devnull:with contextlib.redire…...
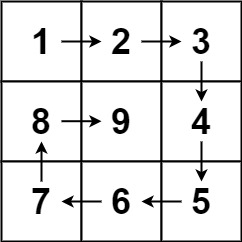
螺旋矩阵(算法题)
文章目录 螺旋矩阵解题思路 螺旋矩阵 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]解题思路 模…...

ffmpeg-webrtc(metartc)给ffmpeg添加webrtc协议
这个是使用metrtc的库为ffmpeg添加webrtc传输协议,目前国内还有一个这样的开源项目,是杨成立大佬,大师兄他们在做,不过wili页面维护的不好,新手不知道如何使用,我专门对它做过介绍,另一篇博文&a…...

C语言知识大纲
一、基础 (一)变量定义和使用 (二)数据类型的字节数 (三)变量转换 (四)程序主要结构 (五)if和else判断 (六)switch判断 (七)while循环 (八)do while循环 (九)for循环 (十)基本输入输出 (十一)数组定义和使用 (十二)函数定义和使用 (十三)指针 (十四)多级指针 (十…...

【必会面试题】synchronized锁升级的过程
目录 Java中的synchronized关键字用于实现同步控制,以保护共享资源免受并发访问的影响。为了提高性能,特别是针对多线程环境中的锁机制,Java引入了锁升级的概念。锁升级的过程主要是为了减少锁操作的开销,根据竞争情况动态地调整锁…...

设计模式——工厂三兄弟之简单工厂
1.业务需求 大家好,我是菠菜。在介绍这期简单工厂设计模式前,我们先来看看这样的需求:制作一个简单的计算器,能够实现控制台输入俩个数以及运算符完成运算。 2.初步实现 实现第一版思路: 创建计算器类&…...

如何使用ChatGPT撰写短视频爆款文案
在这个快速发展的数字时代,短视频已经成为最受欢迎的娱乐和信息获取方式之一。对于内容创作者来说,如何制作出爆款短视频,吸引更多观众的注意力,是他们面临的一大挑战。文案,作为视频内容的灵魂,起着至关重…...

申办风景园林设计乙级资质如何整理技术人员的专业培训证明
整理技术人员的专业培训证明是申办风景园林设计乙级资质的重要环节,它直接关系到证明技术人员持续学习和专业能力提升的情况。以下是整理专业培训证明的一些建议步骤: 收集培训记录:首先,向所有参与设计工作的技术人员收集他们参加…...
类别型特征
#机器学习 #深度学习 #基础知识 #特征工程 #数据编码 背景 在现实生活中,我们面对的数据类型有很多,其中有的数据天然为数值类型具备数值意义,那么可以很自然地和算法结合,但是大部分数据他没有天然的数值意义,那么将他们送入到算法前,就需要对数据进行编码处理,将其转换为数…...

java医院管理系统源码(springboot+vue+mysql)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的医院管理系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 医院管理系统的主要使用者分…...

vue2 面试题
一、.vue的性能优化怎么做? 1.编码优化: 不要把所有的数据都放在data中;v-for时给每个元素绑定事件用事件代理;keep-alive缓存组件;尽可能拆分组件,提高复用性、维护性;key值要保证唯一&#…...

京东自动抢购工具:5分钟快速上手指南,轻松抢购心仪商品
京东自动抢购工具:5分钟快速上手指南,轻松抢购心仪商品 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为心仪商品秒杀时手速不够快而烦恼吗?Autobuy-JD…...

完全自由操作系统的构建秘密:从可验证构建到信任链转移
1. 项目概述:探寻“完全自由”操作系统的内核秘密最近在技术社区里,一个话题反复被提起:“一套完全自由的操作系统都有这个秘密”。这听起来像是一个谜语,又像是一个宣言。作为一个在系统软件领域摸爬滚打了十几年的老手ÿ…...

2026年度AI接入方案复盘:六大主流API中转/API聚合平台深度测评与选型建议
2026年度AI接入方案复盘:六大主流API中转平台深度测评与选型建议 站在2026年的技术节点回望,企业在构建大模型应用时,早已告别了单纯追求低价的阶段。经过一整年的行业沉淀,我们发现真正影响生产效率的并非单一Token的成本&#…...

1分钟带你认识分辨率 帧率, 码率 HDR 的作用
日常刷视频,刷到关于剪辑的只是,就会老是听到一些分辨率,帧率 码率 HDR 这个名字,那你一定很好奇,这些是什么,有什么作用,今天小编就用最简单直白的话,一分钟带你搞懂四大核心参数的…...

别只懂SARA归档删除!SAP数据生命周期管理实战:归档、查询与长期保留指南
SAP数据生命周期管理实战:从归档策略到长期可查询架构 在数字化转型浪潮中,企业数据量呈现指数级增长。某跨国制造企业的SAP系统仅物料凭证表每年就新增超过200万条记录,导致月结操作耗时从2小时延长至8小时。这不仅是存储空间的问题——系统…...

DCGAN原理解析:用卷积结构根治GAN模式坍缩
1. 项目概述:从手写数字到逼真猫脸,DCGAN如何让生成模型真正“看见”图像结构你有没有试过训练一个最基础的GAN,结果生成器输出的全是模糊的、像打了马赛克的灰扑扑色块?或者更糟——所有生成的图片都长得一模一样,只是…...

如何快速掌握Prism-Samples-Wpf交互性编程:InvokeCommandAction事件驱动开发终极指南
如何快速掌握Prism-Samples-Wpf交互性编程:InvokeCommandAction事件驱动开发终极指南 【免费下载链接】Prism-Samples-Wpf Samples that demonstrate how to use various Prism features with WPF 项目地址: https://gitcode.com/gh_mirrors/pr/Prism-Samples-Wpf…...
 面向中小学数学教学的自动出题工具,覆盖从小学一年级到高中三年级共 7 个学段、33 种题型)
[工具] 数学题库生成器(小学,初中,高中全包括) 面向中小学数学教学的自动出题工具,覆盖从小学一年级到高中三年级共 7 个学段、33 种题型
数学题库生成器(小学,初中,高中全包括) 基本覆盖各个年级的重点题型生成,并导出为word,可以显示解题步骤。# 数学题库生成器 MathMaster 数学题库生成器(MathMaster)是一款面向中小学…...

kafka安装与可视化工具offset explore连接操作说明
1.1 环境前置要求 本地部署 Kafka 4.0 极简,无复杂依赖,只需满足 1 个核心条件: 本地已安装 JDK 17 及以上版本(推荐 JDK 17),并配置好 Java 环境变量(能在命令行执行 java -version 和 javac -…...

【习题05】求n的阶乘
题目: 分别利用递归和非递归的方法求n的阶乘 1、题目分析 规定:0的阶乘为1。 非递归: 我们先列举几个求阶乘的案例,从中找寻规律。 0! 11! 12! 1 * 23! 1 * 2 * 3 从上述几个例子可…...