【Python】特征编码
特征编码
- 1. 独热编码(离散变量编码) sklearn.preprocessing.OneHotEncoder
- 1.1 原理 & 过程
- 1.2 封装函数
- 2. 连续变量分箱(连续变量编码) sklearn.preprocessing.KBinsDiscretizer
- 2.1 原理
- 2.2 等宽分箱 KBinsDiscretizer(strategy='uniform')
- 2.3 等频分箱 KBinsDiscretizer(strategy='quantile')
- 2.4 聚类分箱 KBinsDiscretizer(strategy='kmeans')
1. 独热编码(离散变量编码) sklearn.preprocessing.OneHotEncoder
- 【sklearn】数据预处理 独热编码
1.1 原理 & 过程
- 原理
'''
二分类离散变量,转换后知到一列取值已知则另一列取值也确定
OneHotEncoder(drop='if_binary') 跳过二分类,只对多分类离散变量进行转化
ID Gender ID Gender_F Gender_M
1 F 1 1 0
2 M >>> 2 0 1
3 M 3 0 1
4 F 4 1 0
ID Gender Income ID Gender Income_High Income_medium Income_Low
1 F High 1 0 1 0 0
2 M Medium >>> 2 1 0 1 0
3 M High 3 1 1 0 0
4 F Low 4 0 0 0 1
'''
- 数据
X = pd.DataFrame({'Gender': ['F', 'M', 'M', 'F'],'Income': ['High', 'Medium', 'High', 'Low']})
X
| Gender | Income | |
|---|---|---|
| 0 | F | High |
| 1 | M | Medium |
| 2 | M | High |
| 3 | F | Low |
- 代码
from sklearn.preprocessing import OneHotEncoderenc = OneHotEncoder(drop='if_binary')
enc.fit_transform(X).toarray()
'''array([[0., 1., 0., 0.],[1., 0., 0., 1.],[1., 1., 0., 0.],[0., 0., 1., 0.]])
'''
# 转换规则
'''
二分类 F >>> 0,M >>> 1
多分类 第一列High,第二列Low,第三列Medium
'''
enc.categories_
'''[array(['F', 'M'], dtype=object),array(['High', 'Low', 'Medium'], dtype=object)]
'''
# 编码后命名列 原列名_字段取值
# 原始列名
cate_cols = X.columns.tolist()
cate_cols
'''['Gender', 'Income']
'''
# 新编码字段名称存储
cate_cols_new = []
# 提取独热编码后所有特征的名称
for idx, colname in enumerate(cate_cols):# 二分类离散变量if len(enc.categories_[idx]) == 2:cate_cols_new.append(colname)# 多分类离散变量else:for f in enc.categories_[idx]:feature_name = colname + '_' + fcate_cols_new.append(feature_name)
cate_cols_new
'''['Gender', 'Income_High', 'Income_Low', 'Income_Medium']
'''
# 组合成新DataFrame
pd.DataFrame(enc.fit_transform(X).toarray(),columns=cate_cols_new)
| Gender | Income_High | Income_Low | Income_Medium | |
|---|---|---|---|---|
| 0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 1.0 | 0.0 | 0.0 | 1.0 |
| 2 | 1.0 | 1.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 1.0 | 0.0 |
1.2 封装函数
def cate_colName(Transformer, category_cols, drop='if_binary'):"""离散字段独热编码后字段名创建函数:param Transformer: 独热编码转化器:param category_cols: 原始列名:param drop: 独热编码转化器的drop参数"""# 新编码字段名称存储cate_cols_new = []col_value = Transformer.categories_# 提取独热编码后所有特征的名称for idx, colname in enumerate(cate_cols):# 二分类离散变量if (len(col_value[idx]) == 2) & (drop == 'if_binary'):cate_cols_new.append(colname)# 多分类离散变量else:for f in col_value[idx]:feature_name = colname + '_' + fcate_cols_new.append(feature_name)return (cate_cols_new)
cate_colName(enc, cate_cols)
'''['Gender', 'Income_High', 'Income_Low', 'Income_Medium']
'''
2. 连续变量分箱(连续变量编码) sklearn.preprocessing.KBinsDiscretizer
2.1 原理
'''
字段 连续型 >>> 离散型
减少异常值影响,消除特征量纲影响
对于线性模型来说引入非线性因素,提升模型表现
对于树模型来说损失连续变量信息,影响模型效果[0,30)->0 [30,60)->1 [60,inf)->2
ID Income ID Income_Level
1 0 1 0
2 10 2 0
3 180 >>> 3 2
4 30 4 1
5 55 5 1
'''
'''
等宽分箱 uniforme 一定程度受异常值影响
等频分箱 quantile 完全忽略异常值影响
聚类分箱 kmeans 兼顾变量原始数值分布,优先考虑
'''
2.2 等宽分箱 KBinsDiscretizer(strategy=‘uniform’)
# 等宽分箱
# 根据连续变量的取值范围,划分宽度相等的区间
income = np.array([0, 10, 180, 30, 55, 35, 25, 75, 80, 10]).reshape(-1, 1)
income
'''array([[ 0],[ 10],[180],[ 30],[ 55],[ 35],[ 25],[ 75],[ 80],[ 10]])
'''
from sklearn.preprocessing import KBinsDiscretizer
'''
KBinsDiscretizer转化器 (discrete离散的)n_bins 分箱个数strategy 分箱方式'uniforme' 等宽分箱'quantile' 等频分箱'kmeans' 聚类分箱encode 分箱后的离散字段进一步编码方式'ordinal' 二分类-自然数编码'onehot' 多分类-独热编码
'''dis = KBinsDiscretizer(n_bins=3, strategy='uniform', encode='ordinal')
dis.fit_transform(income)
'''array([[0.],[0.],[2.],[0.],[0.],[0.],[0.],[1.],[1.],[0.]])
'''
# 查看分箱边界
dis.bin_edges_
'''array([array([ 0., 60., 120., 180.])], dtype=object)
'''
2.3 等频分箱 KBinsDiscretizer(strategy=‘quantile’)
'''
根据分箱数和连续变量数,划分样本数量相等的区间
若样本数无法整除箱数,最后一个箱子包含余数样本(10/3 -> 3/3/4).
'''
np.sort(income.flatten(), axis=0) # 分两个箱的话会以32.5划分
'''array([ 0, 10, 10, 25, 30, 35, 55, 75, 80, 180])
'''
dis = KBinsDiscretizer(n_bins=3, strategy='quantile', encode='ordinal')
dis.fit_transform(income)
'''array([[0.],[0.],[2.],[1.],[1.],[1.],[0.],[2.],[2.],[0.]])
'''
# 查看分箱边界
dis.bin_edges_
'''array([array([ 0., 25., 55., 180.])], dtype=object)
'''
2.4 聚类分箱 KBinsDiscretizer(strategy=‘kmeans’)
# 对连续变量进行聚类(多KMeans聚类),按样本所属类别作为标记代替原始值
from sklearn import clusterkmeans = cluster.KMeans(n_clusters=3)
kmeans.fit(income)
kmeans.labels_
'''array([0, 0, 1, 0, 2, 0, 0, 2, 2, 0], dtype=int32)
'''
dis = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans')
dis.fit_transform(income) # 分类结果和上面相同但更合理,小数字更能体现收入水平低
'''array([[0.],[0.],[2.],[0.],[1.],[0.],[0.],[1.],[1.],[0.]])
'''
dis.bin_edges_
'''array([array([ 0. , 44.16666667, 125. , 180. ])],dtype=object)
'''
相关文章:

【Python】特征编码
特征编码1. 独热编码(离散变量编码) sklearn.preprocessing.OneHotEncoder1.1 原理 & 过程1.2 封装函数2. 连续变量分箱(连续变量编码) sklearn.preprocessing.KBinsDiscretizer2.1 原理2.2 等宽分箱 KBinsDiscretizer(strategyuniform)2.3 等频分箱 KBinsDiscretizer(stra…...
前端开发者必备的Nginx知识
nginx在应用程序中的作用 解决跨域请求过滤配置gzip负载均衡静态资源服务器…nginx是一个高性能的HTTP和反向代理服务器,也是一个通用的TCP/UDP代理服务器,最初由俄罗斯人Igor Sysoev编写。 nginx现在几乎是众多大型网站的必用技术,大多数情…...
在 KubeSphere 中开启新一代云原生数仓 Databend
作者:尚卓燃(https://github.com/PsiACE),Databend 研发工程师,Apache OpenDAL (Incubating) PPMC。 前言 Databend 是一款完全面向云对象存储的新一代云原生数据仓库,专为弹性和高效设计,为您…...
【独家】)
华为OD机试 - 最优资源分配(C 语言解题)【独家】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 使用说明本期题目:最优资源…...

求数组的中心索引
给你一个整数数组 nums ,请计算数组的 中心下标 。 数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。 如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点…...
Ubuntu 搭建NextCloud私有云盘【内网穿透远程访问】
文章目录1.前言2.本地软件安装2.1 nextcloud安装2.2 cpolar安装3.本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置4.公网访问测试5. 结语1.前言 对于爱好折腾的电脑爱好者来说,Linux是绕不开的、必须认识的系统(大部分服务器都是采用Linux操作系统&a…...
如何使用vue创建一个完整的前端项目
搭建Vue项目的完整流程可以分为以下几个步骤:安装Node.js和npm:Vue.js是基于Node.js开发的,因此在开始搭建Vue项目之前,需要先安装Node.js和npm(Node.js的包管理器)。可以从官网下载Node.js安装包并安装。安…...
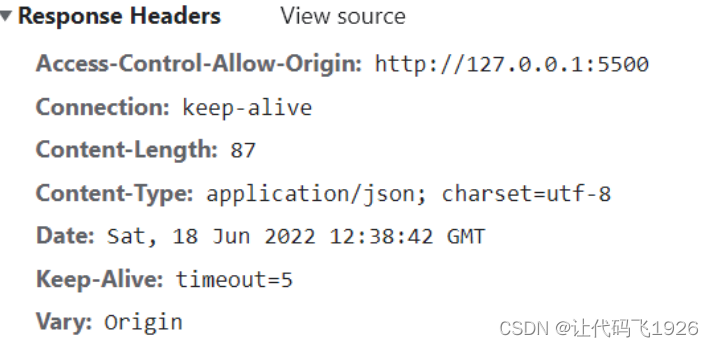
http组成及状态及参数传递
http组成及状态及参数传递 早期的网页都是通过后端渲染来完成的:服务器端渲染(SSR,server side render): 客户端发出请求 -> 服务端接收请求并返回相应HTML文档 -> 页面刷新,客户端加载新的HTML文档&…...

USART_GetITStatus与 USART_GetFlagStatus的区别
文章目录共同点不同点USART_GetITStatus函数详解USART_GetFlagStatus函数共同点 都能访问串口的SR寄存器 不同点 USART_GetFlagStatus(USART_TypeDef USARTx, uint16_t USART_FLAG):* 该函数只判断标志位(访问串口的SR寄存器)。在没有使能…...
Java 系列之 Springboot
系列文章目录 文章目录系列文章目录前言一、Springboot 简介?1.1 什么是启动器?1.2 Springboot 优点1.3 Springboot 核心二、搭建方式2.1 搭建方式一2.2 搭建方式二2.3 搭建方式三三、启动原理3.1 初始化SrpingApplication对象3.2 执行run()方法1. 加载监…...

乐山持点科技:抖客推广准入及准出管理规则
抖音小店平台新增《抖客推广准入及准出管理规则》,本次抖音规则具体如下:第一章 概述1.1 目的及依据为维护精选联盟平台经营秩序,保障精选联盟抖客、商家、消费者等各方的合法权益;根据《巨量百应平台服务协议》、《“精选联盟”服务协议(推广…...

Steam流
Steam流 Stream 流是什么,为什么要用它? Stream是 Java8 新引入的一个包( java.util.stream),它让我们能用声明式的方式处理数据(集合、数组等)。Stream流式处理相较于传统方法简洁高效&#…...
Nuxt实战教程基础-Day01
Nuxt实战教程基础-Day01Nuxt是什么?Nuxt.js框架是如何运作的?Nuxt特性流程图服务端渲染(通过 SSR)单页应用程序 (SPA)静态化 (预渲染)Nuxt优缺点优点缺点安装运行项目总结前言:本教程基于Nuxt2,作为教程的第一天,我们先…...
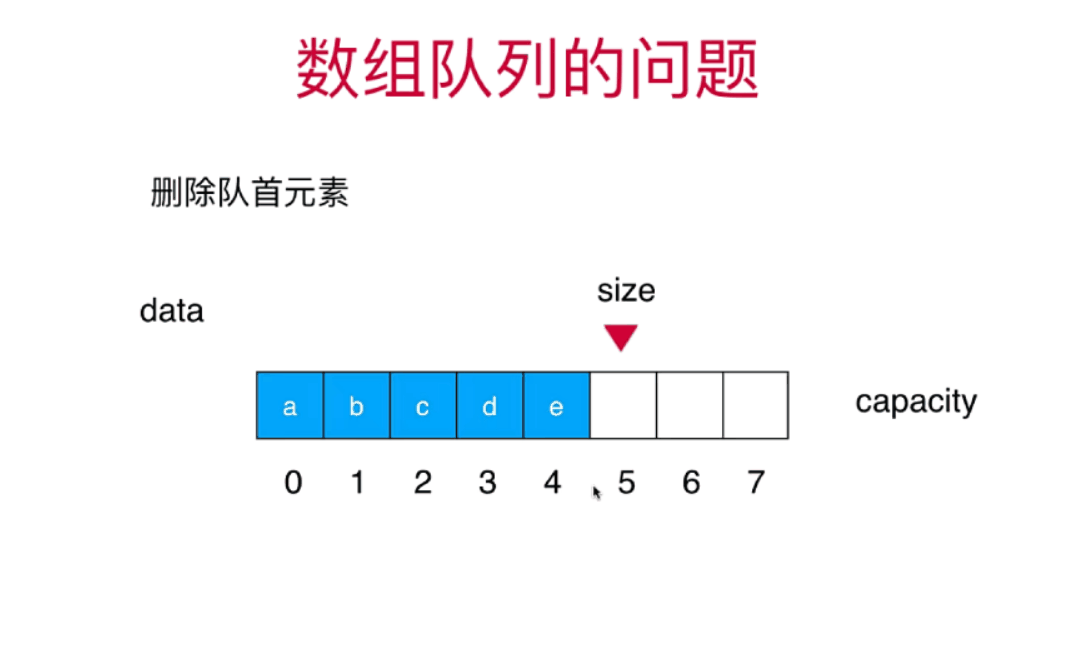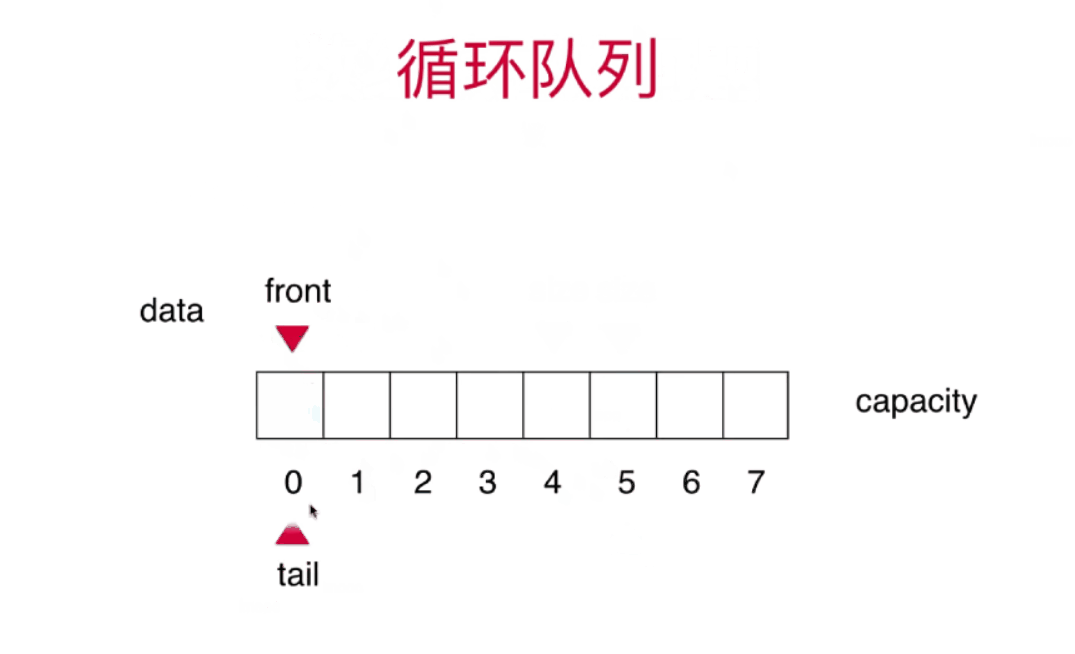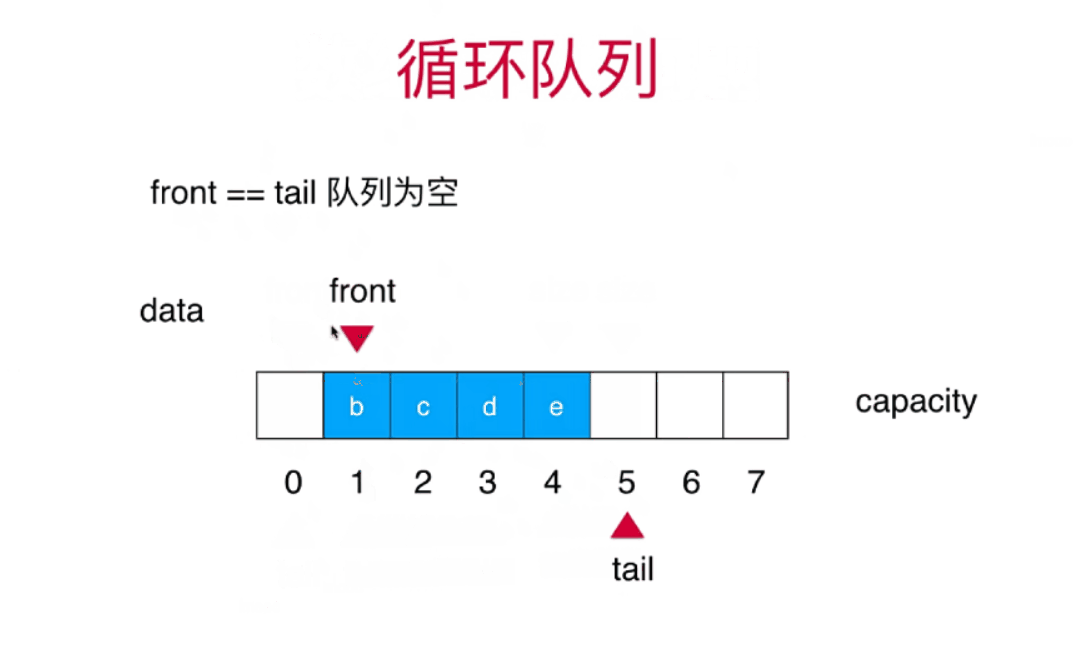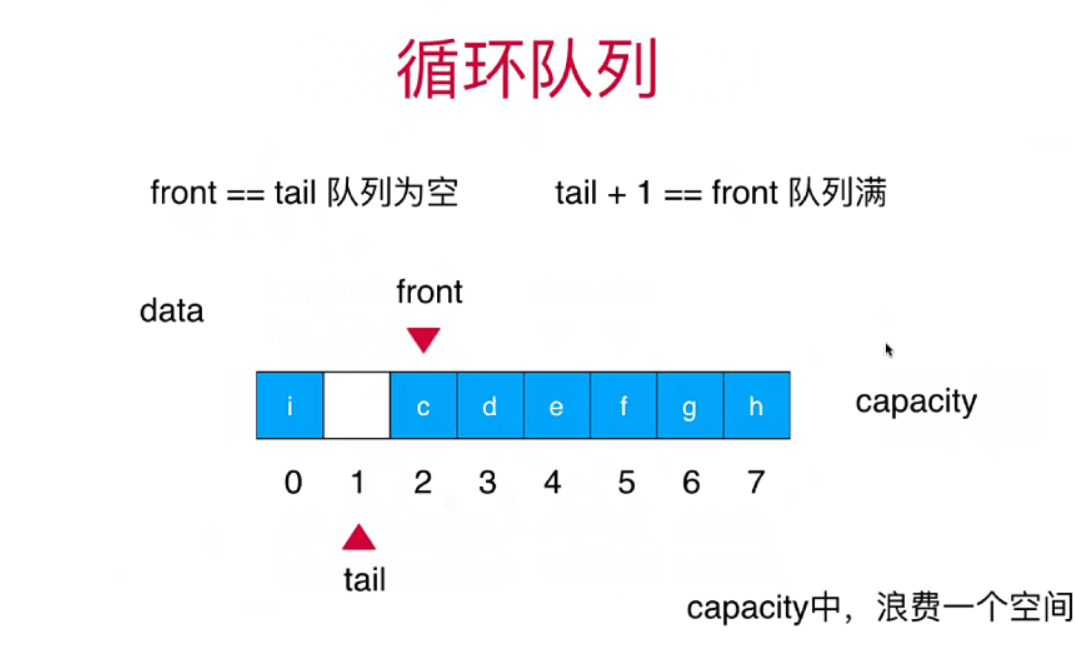
栈和队列详细讲解+算法动画
栈和队列 栈stack 栈也是一种线性结构相比数组,栈对应的操作数数组的子集只能从一端添加元素,也只能从一端取出元素这一端称为栈顶 栈是一种后进先出的数据结构Last in Firt out(LIFO)在计算机的世界里,栈拥有者不可思议的作用 栈的应用 …...
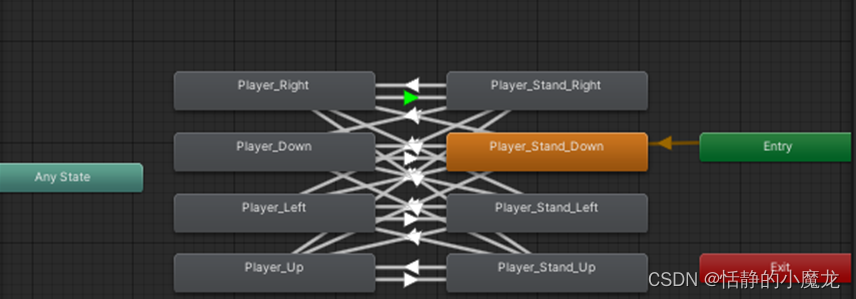
【Unity3D小技巧】Unity3D中判断Animation以及Animator动画播放结束,以及动画播放结束之后执行函数
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 在日常开发中,可能会遇到要判断Animation或者Anima…...

【1】熟悉刷题平台操作
TestBench使用 与quartus中testbench的写法有些许。或者说这是平台特有的特性!! 1 平台使用谨记 (1)必须删除:若设计为组合逻辑,需将自动生成的clk删除 若不删除,会提示运行超时错误。 &#…...
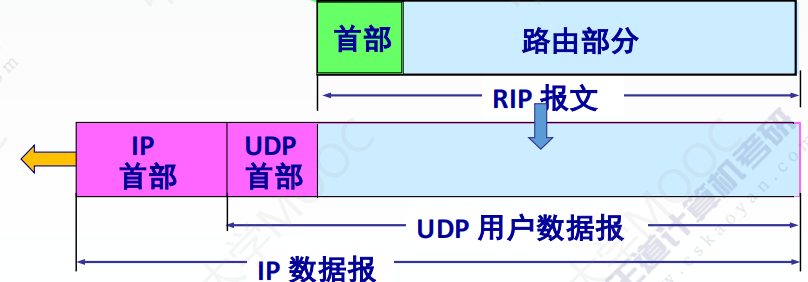
计算机网络:RIP协议以及距离向量算法
RIP协议 RIP是一种分布式的基于适量向量的路由选择协议,最大优点是简单。要求网络中的每一个路由器都要维护从它自己到其他每一个目的网络的唯一最佳(最短)距离记录,最多包含15个路由器,距离为16就表示网络不可达&…...
[数据结构与算法(严蔚敏 C语言第二版)]第1章 绪论(课后习题+答案解析)
1. 简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。 数据 数据是客观事物的符号表示,是所有能输人到计算机中并被计算机程序处理的符号的总称。数据是信息的载体,能够被计算机识别、存储和加工 数据元素…...

JS_countup.js 的简单使用,数字滚动效果
countup.js countup.js 是一个轻量级,无依赖的JavaScript类,通过简单的设置就可以达到数字滚动的效果 官网:https://inorganik.github.io/countUp.js/ 源码 var CountUpfunction(target,startVal,endVal,decimals,duration,options){var …...

【C++知识点】STL 容器总结
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:C/C知识点 📣专栏定位:整理一下 C 相关的知识点,供大家学习参考~ ❤️如果有收获的话,欢迎点赞👍…...

别再只盯着标定板了!用ROS camera_calibration搞定海康工业相机,这5个细节决定成败
工业相机标定进阶指南:ROS camera_calibration的五个关键优化点 工业相机的标定质量直接决定了机器视觉系统的测量精度。许多开发者虽然能够完成基础标定流程,却常常在参数解读和精度优化环节遇到瓶颈。本文将深入解析ROS camera_calibration工具在实际工…...

从‘Hello World’到视频监控:用QT+海康SDK开发你的第一个安防应用
从‘Hello World’到视频监控:用QT海康SDK开发你的第一个安防应用 第一次看到海康威视摄像头的实时画面在自己的程序里跳出来时,那种成就感比写一百个"Hello World"都来得强烈。作为一位刚接触QT的开发者,你可能已经厌倦了按钮和文…...

Termius vs SecureCRT:为什么这款内置FTP的SSH工具更适合中文用户?
Termius vs SecureCRT:为什么这款内置FTP的SSH工具更适合中文用户? 作为开发者,每天与服务器打交道是家常便饭。选择一款趁手的SSH工具,就像程序员挑选键盘一样重要——不仅要功能强大,更要符合个人使用习惯。对于中文…...
用C++实现信奥题 P6334 [COCI 2007/2008 #1] SREDNJI)
打卡信奥刷题(3016)用C++实现信奥题 P6334 [COCI 2007/2008 #1] SREDNJI
P6334 [COCI 2007/2008 #1] SREDNJI 题目描述 给定一个长度为 nnn 的 1∼n1\sim n1∼n 的排列 a1,…,ana_1,\dots ,a_na1,…,an,请你找出这个排列有多少个长度为奇数的子串的中位数为 BBB。 子串定义:把这个排列从开头(可能无ÿ…...

Cadence IC617实战:VerilogA vs analogLib搭建全差分放大器,哪个更适合你?
Cadence IC617实战:VerilogA与analogLib全差分放大器设计深度对比 在模拟IC设计领域,全差分放大器作为基础构建模块,其实现方式直接影响设计效率和仿真精度。Cadence IC617作为行业标准工具,提供了VerilogA和analogLib两种截然不同…...

汉字拼音转换工具选型与实战指南:用pinyinjs解决多场景字符处理难题
汉字拼音转换工具选型与实战指南:用pinyinjs解决多场景字符处理难题 【免费下载链接】pinyinjs 一个实现汉字与拼音互转的小巧web工具库,演示地址: 项目地址: https://gitcode.com/gh_mirrors/pi/pinyinjs 在数字化产品开发中…...

OpenClaw版本升级:GLM-4.7-Flash环境无缝迁移指南
OpenClaw版本升级:GLM-4.7-Flash环境无缝迁移指南 1. 为什么需要升级? 上周我在本地开发环境遇到一个棘手问题:OpenClaw的旧版本无法正确解析GLM-4.7-Flash模型返回的JSON响应。经过排查发现是框架对数组嵌套结构的处理存在兼容性问题。这促…...

ChatTTS 入门指南:从零开始构建你的第一个语音对话应用
最近在做一个需要语音交互的小项目,选型时发现了 ChatTTS 这个工具,感觉挺有意思的。它不像一些大厂的 TTS 服务那么“重”,更像是一个专为对话场景优化的语音合成工具。如果你是第一次接触,可能会觉得有点无从下手,比…...

3分钟搞定Windows音频捕获:win-capture-audio让你的录音效率翻倍
3分钟搞定Windows音频捕获:win-capture-audio让你的录音效率翻倍 【免费下载链接】win-capture-audio An OBS plugin that allows capture of independant application audio streams on Windows, in a similar fashion to OBSs game capture and Discords applicat…...

学术专著不用愁!AI专著写作工具,为你打造专属学术大作
一、研究者专著写作困境与AI工具的出现 对于很多研究人员来说,写学术专著时面临的最大难题就是“有限的精力”与“无限的需求”之间的矛盾。专著的写作通常需要花费3到5年甚至更久的时间,但研究者们在日常工作中,除了教学和科研项目外&#…...