揭开Java序列化的神秘面纱(上)Serializable使用详解
Java序列化(Serialization)作为一项核心技术,在Java应用程序的多个领域都有着广泛的应用。无论是通过网络进行对象传输,还是实现对象的持久化存储,序列化都扮演着关键的角色。然而,这个看似简单的概念蕴含着丰富的原理和用法细节,值得我们一探究竟。
一、序列化的本质
序列化的本质是将对象转换为字节流,以便在网络上传输或存储在磁盘上。经过序列化后,虚拟机中的对象便可以脱离运行环境,转化为平台无关的原始字节流,方便进行传输和持久化。
Serializable序列化的本质可以从以下几个方面来理解:
- 对象状态的保存:序列化允许将对象的状态(即对象的字段值)保存到一个持久化存储中,例如文件或数据库。这意味着即使程序停止运行,对象的状态也可以被保存下来,并在需要时重新加载。
- 对象的传输:在分布式系统中,对象序列化可以用于通过网络传输对象。通过网络发送对象的序列化形式,然后在接收端进行反序列化,从而恢复对象的状态。
- 跨平台:序列化允许Java对象在不同的平台和Java虚拟机之间传输。只要序列化和反序列化的过程遵循相同的协议,对象就可以在不同的系统上保持一致。
- 兼容性:Java的序列化机制保证了对象的兼容性。即使类的实现发生了变化,只要类的序列化版本号(
serialVersionUID)保持不变,旧的序列化对象仍然可以在新的类实现上进行反序列化。 - 简单性:实现序列化非常简单。开发者只需要声明类实现了
Serializable接口,然后Java运行时环境就会自动处理对象的序列化和反序列化。 - 性能考虑:序列化和反序列化的过程可能会涉及到大量的I/O操作,这可能会影响程序的性能。因此,对于性能敏感的应用,需要仔细考虑序列化的使用。
- 安全性:序列化可能会带来安全风险,因为恶意的序列化数据可以被用来执行攻击。因此,需要对序列化的数据进行验证,确保它们是安全和可信的。
- 自定义序列化:Java允许开发者通过实现
ObjectOutputStream和ObjectInputStream的自定义版本来控制序列化和反序列化的过程。这可以用于优化性能或添加额外的序列化逻辑。 - 非静态字段:只有对象的非静态字段会被序列化。静态字段和方法不会被包含在序列化的数据中。
- 序列化代理:Java提供了一种机制,称为序列化代理(
writeReplace和readResolve方法),允许开发者控制序列化和反序列化过程中对象的替换。
序列化是Java中一个强大的特性,它使得对象可以在不同的环境和平台之间移动,同时也为对象的持久化提供了支持。然而,在使用序列化时也需要考虑到性能、安全性和兼容性等问题。
二、实现Serializable接口
在Java中,实现Serializable接口非常简单,因为这是一个标记接口,它不包含任何方法。要使一个类可序列化,你只需要声明它实现了Serializable接口。
下面是一个简单的Java类实现Serializable接口的示例:
import java.io.Serializable;public class Person implements Serializable {// 定义一个序列化版本号,建议添加,以确保序列化兼容性private static final long serialVersionUID = 1L;// 可以添加一些字段,这些字段将会被序列化private String name;private int age;private transient String password; // transient关键字表示该字段不会被序列化// 构造函数public Person(String name, int age, String password) {this.name = name;this.age = age;this.password = password;}// getter和setter方法public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}// 重写toString方法,方便打印对象信息@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +", password='" + password + '\'' +'}';}// 可以添加其他业务逻辑代码
}
在上面的代码中,`Person`类实现了`Serializable`接口,这意味着`Person`对象可以被序列化和反序列化。
serialVersionUID是一个可选的静态字段,用于在反序列化过程中确保发送方和接收方的序列化版本兼容。如果类实现Serializable接口,建议添加这个字段。
transient关键字用于指示某些字段在序列化过程中应该被忽略。在上面的例子中,password字段被标记为transient,这意味着在序列化Person对象时,密码字段不会被包含在序列化的数据中。
这个类还包含了一些基本的getter和setter方法,以及一个重写的toString方法,用于提供类的字符串表示,这在调试和日志记录时非常有用。
三、序列化和反序列化的流程
序列化的核心是通过ObjectOutputStream和ObjectInputStream来完成。
序列化过程:
- 创建一个ObjectOutputStream
- 调用writeObject方法输出可序列化对象
反序列化过程:
- 创建一个ObjectInputStream
- 调用readObject方法从流中读取字节,反序列化为对象
下面是一个简单的示例,演示如何序列化和反序列化Person对象:
import java.io.*;public class SerializationDemo {public static void main(String[] args) {try {// 创建Person对象Person person = new Person("John Doe", 30, "securepassword123");// 序列化FileOutputStream fileOut = new FileOutputStream("person.ser");ObjectOutputStream out = new ObjectOutputStream(fileOut);out.writeObject(person);out.close();fileOut.close();System.out.println("Serialized data is saved in 'person.ser'");// 反序列化FileInputStream fileIn = new FileInputStream("person.ser");ObjectInputStream in = new ObjectInputStream(fileIn);Person deserializedPerson = (Person) in.readObject();in.close();fileIn.close();System.out.println("Deserialized Person: " + deserializedPerson);} catch (IOException i) {i.printStackTrace();} catch (ClassNotFoundException c) {System.out.println("Person class not found");c.printStackTrace();}}
}
这段代码首先创建了一个`Person`对象,然后使用`ObjectOutputStream`将其序列化到一个文件中。之后,使用`ObjectInputStream`从文件中反序列化对象,并打印出来。注意,反序列化时需要处理`ClassNotFoundException`,这可能发生在找不到要反序列化的类定义时。
四、transient关键字
transient关键字在Java中用于控制序列化行为。当一个类实现了Serializable接口,所有的非静态字段(即实例字段)默认都会被序列化。然而,有些字段可能不适合被序列化,或者序列化这些字段没有意义,这时就可以使用transient关键字来标记这些字段。
1、transient关键字详解:
- 字段不序列化:被
transient关键字标记的字段在对象序列化时不会被保存到序列化的数据中。这意味着在反序列化时,这些字段将保持默认值(例如,null对于对象引用,0对于整数类型)。 - 默认值恢复:反序列化后,
transient字段将被自动恢复为该类型的默认值。 - 非静态:
transient关键字只能用于类的非静态字段。 - 非继承:
transient关键字的效果仅限于声明它的类。如果一个子类继承了一个父类,并且父类中的字段被标记为transient,那么在子类的序列化过程中,这些字段仍然不会被序列化。 - 性能优化:对于大对象或者包含大量数据的字段,使用
transient可以减少序列化的数据量,从而提高序列化和反序列化的效率。
2、使用最佳实践
- 安全性:对于敏感信息,如密码或个人信息,使用
transient可以防止这些信息在序列化过程中被泄露。 - 资源管理:对于文件句柄、数据库连接、线程等资源,不应该被序列化,因为它们通常与特定的运行时环境相关联,并且可能在序列化后不再有效。
- 性能考虑:如果一个字段很大,并且不需要在序列化后保留其状态,使用
transient可以减少序列化的数据量,提高性能。 - 临时状态:如果一个字段仅用于临时状态,如缓存或中间计算结果,使用
transient可以避免在序列化过程中包含这些不必要的状态。 - 自定义序列化:对于需要特殊序列化逻辑的字段,可以通过实现
writeObject和readObject方法,并在这些方法中显式处理transient字段。 - 版本控制:在类结构发生变化时,使用
transient可以帮助管理字段的版本,避免因为字段的添加或删除导致序列化版本号的变更。 - 避免不必要的序列化:如果一个字段总是可以通过其他方式重建(例如,基于其他字段的计算),则没有必要序列化它。
- 文档和维护:在使用
transient关键字时,应该在代码中添加适当的注释,说明为什么该字段被标记为transient,以便于其他开发者理解和维护。
通过遵循这些最佳实践,可以有效地利用transient关键字来控制序列化过程,提高应用程序的性能和安全性。
五、自定义序列化逻辑
自定义序列化逻辑允许开发者控制对象序列化和反序列化的详细过程。在Java中,可以通过重写对象类的writeObject和readObject方法来实现自定义序列化。这对于优化性能、处理非可序列化对象、实现版本控制或添加额外的逻辑非常有用。
1、自定义序列化步骤:
第一步,重写writeObject方法:
- 这个方法是在对象序列化时被调用的。
- 可以在这里添加自定义的序列化逻辑,比如只序列化对象的某些字段,或者在序列化之前进行某些计算或检查。
第二步,重写readObject方法:
- 这个方法是在对象反序列化时被调用的。
- 可以在这里添加自定义的反序列化逻辑,比如在反序列化后恢复对象的状态,或者在对象状态被读取之后执行某些操作。
第三步,使用private void readObject(ObjectInputStream in)和private void writeObject(ObjectOutputStream out):
- 这些方法是私有的,只能在类的内部被调用。
- 它们不能被类的外部调用,这保证了序列化和反序列化过程的安全性。
### 2、示例代码:
import java.io.*;class MyObject implements Serializable {private int value;private transient int transientValue;public MyObject(int value) {this.value = value;this.transientValue = 0;}// 自定义序列化逻辑private void writeObject(ObjectOutputStream out) throws IOException {out.defaultWriteObject(); // 序列化非transient字段// 可以添加额外的序列化逻辑out.writeInt(transientValue + 100); // 示例:修改transient字段的值}// 自定义反序列化逻辑private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {in.defaultReadObject(); // 反序列化非transient字段// 可以添加额外的反序列化逻辑transientValue = in.readInt() - 100; // 示例:根据序列化逻辑恢复transient字段的值}// 其他业务逻辑...
}
3、自定义序列化的最佳实践:
(1)、使用defaultWriteObject和defaultReadObject:
- 在
writeObject和readObject方法中,首先调用defaultWriteObject()和defaultReadObject()方法,以确保非transient字段被正确序列化和反序列化。
(2)、处理transient字段:
- 如果类中有
transient字段,需要在writeObject和readObject方法中显式处理这些字段的序列化和反序列化。
(3)、异常处理:
- 在自定义序列化方法中,适当处理可能发生的异常,如
IOException。
(4)、版本控制:
- 当类的字段发生变化时,通过在
readObject方法中添加逻辑来处理旧版本的序列化对象。
(5)、安全性:
- 由于
writeObject和readObject方法是私有的,确保它们不会被外部调用,避免安全风险。
(6)、性能优化:
- 优化自定义序列化逻辑,以减少不必要的I/O操作,提高性能。
(7)、测试:
- 彻底测试自定义序列化逻辑,确保序列化和反序列化过程的正确性和稳定性。
通过实现自定义序列化逻辑,开发者可以更细致地控制对象的序列化过程,满足特定的需求,如安全性、性能优化或复杂的状态管理。
六、版本控制serialVersionUID
在Java序列化机制中,serialVersionUID是一个非常重要的概念,它用于在序列化和反序列化过程中确保类的版本兼容性。以下是关于serialVersionUID的详细说明:
### 1、什么是`serialVersionUID`?
serialVersionUID是一个唯一的版本标识符,用于区分序列化的对象属于哪个类的不同版本。当一个对象被序列化时,它的类定义中的serialVersionUID会被包含在序列化数据中。在反序列化时,Java运行时环境会检查序列化数据中的serialVersionUID与类定义中的serialVersionUID是否匹配。
2、为什么需要serialVersionUID?
(1)、版本控制:当类的实现发生变化时(例如,添加或删除字段),serialVersionUID帮助确保类的序列化版本是否兼容。
(2)、反序列化兼容性:如果序列化对象的类定义与反序列化时的类定义不匹配,Java运行时环境会根据serialVersionUID来判断是否可以安全地进行反序列化。
(3)、避免序列化错误:如果没有显式声明serialVersionUID,Java运行时环境会基于类的细节自动生成一个。如果类的实现发生变化,自动生成的serialVersionUID也会变化,这可能导致反序列化时出现InvalidClassException错误。
3、如何使用serialVersionUID?
(1)、声明serialVersionUID:
private static final long serialVersionUID = 1L;
这个声明应该放在类的第一行,作为一个静态常量。
(2)、选择serialVersionUID的值:
- 通常,
serialVersionUID是一个长整型(long)值。 - 可以手动指定一个固定的值,或者使用工具(如
serialver工具)来生成。
(3)、更新serialVersionUID:
- 当类的序列化状态发生变化时(例如,添加、删除或修改字段),应该更新
serialVersionUID。 - 如果希望保持与旧版本的兼容性,可以选择不更新
serialVersionUID。
4、最佳实践:
(1)、显式声明:即使类的实现没有变化,也建议显式声明serialVersionUID,以避免自动生成的值在未来发生变化。
(2)、版本管理:在类文档中记录serialVersionUID的更改,以及每次更改的原因。
(3)、兼容性考虑:在设计可序列化的类时,考虑未来可能的变更,并评估这些变更对序列化兼容性的影响。
(4)、使用工具:可以使用serialver工具来帮助生成serialVersionUID。
(5)、测试:在更改类的实现后,彻底测试序列化和反序列化过程,确保serialVersionUID的更改不会破坏现有功能。
(6)、文档化:在类文档中清楚地说明serialVersionUID的使用和任何相关的版本兼容性问题。
通过正确使用serialVersionUID,可以有效地管理类的序列化版本,确保序列化和反序列化过程的兼容性和稳定性。这对于维护大型系统和长期运行的应用程序尤为重要。
总之,Java序列化封装了对象转字节流的细节,提供了简洁的API,但同时也需要我们对其原理和用法有更深入的理解,才能在实践中发挥其最大价值。
期待在未来的技术进化中,序列化会变得更加易于使用和扩展,为分布式系统、大数据处理等领域贡献新的引擎。让我们拭目以待吧!
相关文章:
Serializable使用详解)
揭开Java序列化的神秘面纱(上)Serializable使用详解
Java序列化(Serialization)作为一项核心技术,在Java应用程序的多个领域都有着广泛的应用。无论是通过网络进行对象传输,还是实现对象的持久化存储,序列化都扮演着关键的角色。然而,这个看似简单的概念蕴含着丰富的原理和用法细节&…...

深度学习——自己的训练集——图像分类(CNN)
图像分类 1.导入必要的库2.指定图像和标签文件夹路径3.获取文件夹内的所有图像文件名4.获取classes.txt文件中的所有标签5.初始化一个字典来存储图片名和对应的标签6.遍历每个图片名的.txt文件7.随机选择一张图片进行展示8.构建图像的完整路径9.加载图像10.检查图像是否为空 随…...

goimghdr,一个有趣的 Python 库!
更多Python学习内容:ipengtao.com 大家好,今天为大家分享一个有趣的 Python 库 - goimghdr。 Github地址:https://github.com/corona10/goimghdr 在图像处理和分析过程中,识别图像文件的类型是一个常见的需求。Python自带的imghdr…...

每小时电量的计算sql
计算思路,把每小时的电表最大记录取出来,然后用当前小时的最大值减去上个小时的最大值即可。 使用了MYSQL8窗口函数进行计算。 SELECT b.*,b.epimp - b.lastEmimp ecValue FROM ( SELECT a.deviceId,a.ctime,a.epimp, lag(epimp) over (ORDER BY a.dev…...
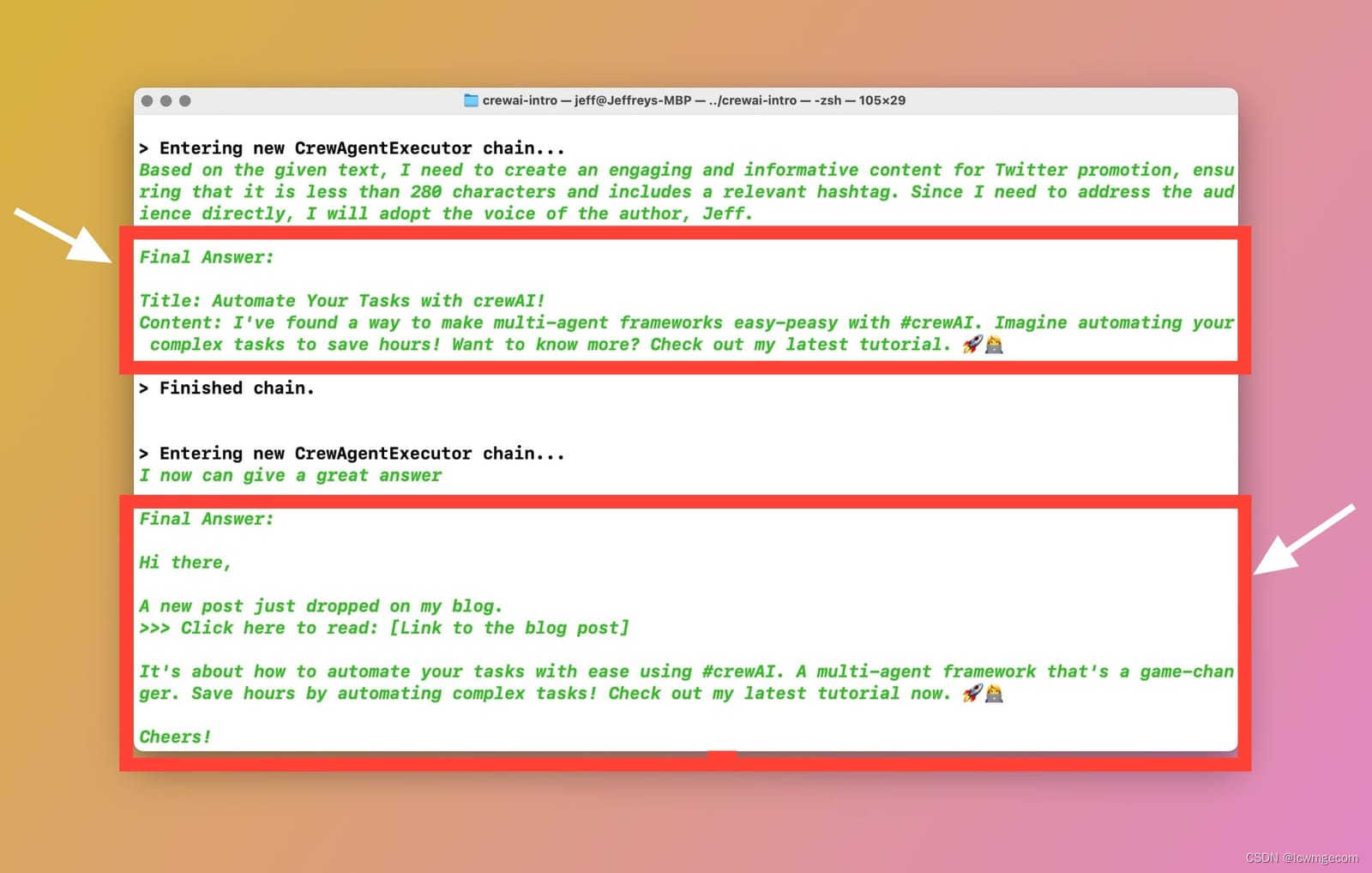
自动化您的任务——crewAI 初学者教程
今天,我写这篇文章是为了分享您开始使用一个非常流行的多智能体框架所需了解的所有信息:crewAI。 我将在这里或那里跳过一些内容,使本教程成为一个精炼的教程,概述帮助您入门的关键概念和要点 今天,我写这篇文章是为了…...
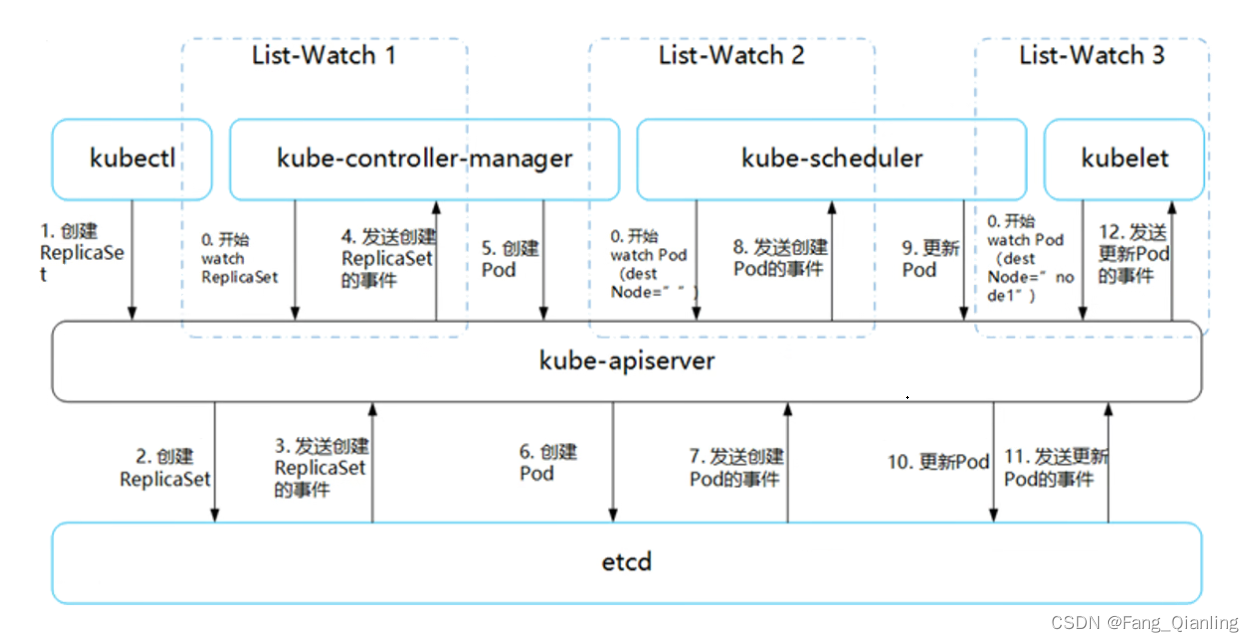
K8s集群中的Pod调度约束亲和性与反亲和性
前言 在 K8s 集群管理中,Pod 的调度约束——亲和性(Affinity)与反亲和性(Anti-Affinity)这两种机制允许管理员精细控制 Pod 在集群内的分布方式,以适应多样化的业务需求和运维策略。本篇将介绍 K8s 集群中…...

kafka之consumer参数auto.offset.reset
Kafka的auto.offset.reset 参数是用于指定消费者在启动时如何处理偏移量(offset)的。这个参数有三个主要的取值:earliest、latest和none。 earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;…...
回答篇二:测试开发高频面试题目
引用之前文章:测试开发高频面试题目 本篇文章是回答篇(持续更新中) 1. 在测试开发中使用哪些自动化测试工具和框架?介绍一下你对其中一个工具或框架的经验。 a. 测试中经常是用的自动化测试工具和框架有Selenium、Pytest、Postman…...
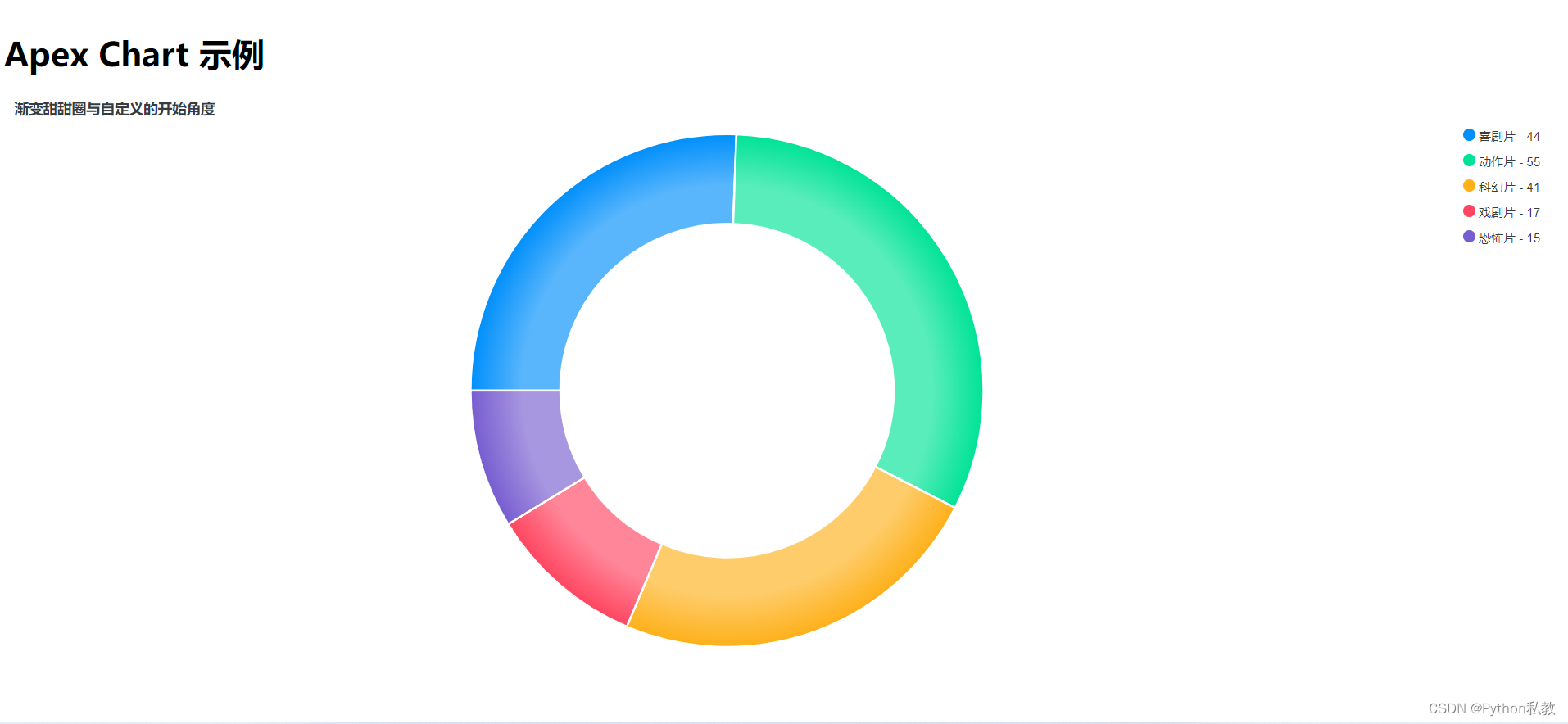
React18 apexcharts数据可视化之甜甜圈图
03 甜甜圈图 apexcharts数据可视化之甜甜圈图。 有完整配套的Python后端代码。 本教程主要会介绍如下图形绘制方式: 基本甜甜圈图个性图案的甜甜圈图渐变色的甜甜圈图 面包圈 import ApexChart from react-apexcharts;export function DonutUpdate() {// 数据…...

如何通过OpenHarmony的音频模块实现录音变速功能?
简介 OpenAtom OpenHarmony(以下简称“OpenHarmony”)是由开放原子开源基金会孵化及运营的开源项目,是面向全场景、全连接、全智能时代的智能物联网操作系统。 多媒体子系统是OpenHarmony系统中的核心子系统,为系统提供了相机、…...

探索 Rust 语言的精髓:深入 Rust 标准库
探索 Rust 语言的精髓:深入 Rust 标准库 Rust,这门现代编程语言以其内存安全、并发性和性能优势而闻名。它不仅在系统编程领域展现出强大的能力,也越来越多地被应用于WebAssembly、嵌入式系统、分布式服务等众多领域。Rust 的成功࿰…...
Log360:护航安全,远离暗网风险
暗网有时候就像是一个神秘的地下世界,是互联网的隐蔽角落,没有任何规则。这是一个被盗数据交易、网络犯罪分子策划下一步攻击的地方。但仅仅因为它黑暗,不意味着你要对潜在的威胁视而不见。 暗网 这就是ManageEngine Log360的用武之地&…...

react使用antd警告:Warning: findDOMNode is deprecated in StrictMode.
警告信息: Warning: findDOMNode is deprecated in StrictMode. findDOMNode was passed an instance of DOMWrap which is inside StrictMode. Instead, add a ref directly to the element you want to reference. Learn more about using refs safely here: htt…...

Docker Swarm - 删除 worker 节点
1、前提:集群环境已经运行 在manager节点上执行: # 查看节点信息 >>> docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION jr06s8pbrclkrxt7jpy7wae8t * iZ2ze78653g2…...
AI视频智能分析技术赋能营业厅:智慧化管理与效率新突破
一、方案背景 随着信息技术的快速发展,图像和视频分析技术已广泛应用于各行各业,特别是在营业厅场景中,该技术能够有效提升服务质量、优化客户体验,并提高安全保障水平。TSINGSEE青犀智慧营业厅视频管理方案旨在探讨视频监控和视…...
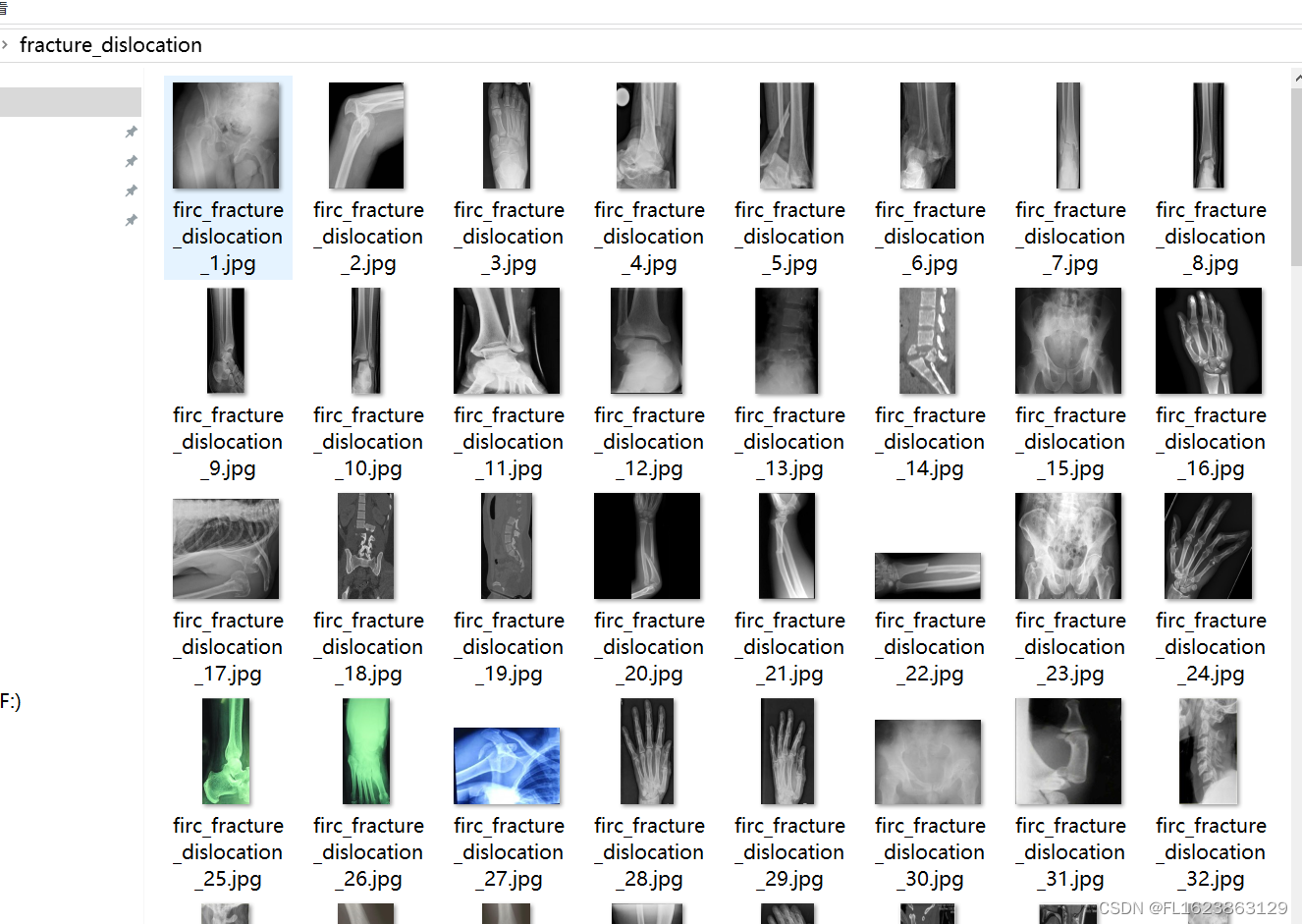
骨折分类数据集1129张10类别
数据集类型:图像分类用,不可用于目标检测无标注文件 数据集格式:仅仅包含jpg图片,每个类别文件夹下面存放着对应图片 图片数量(jpg文件个数):1129 分类类别数:10 类别名称:["avulsion_fracture",…...
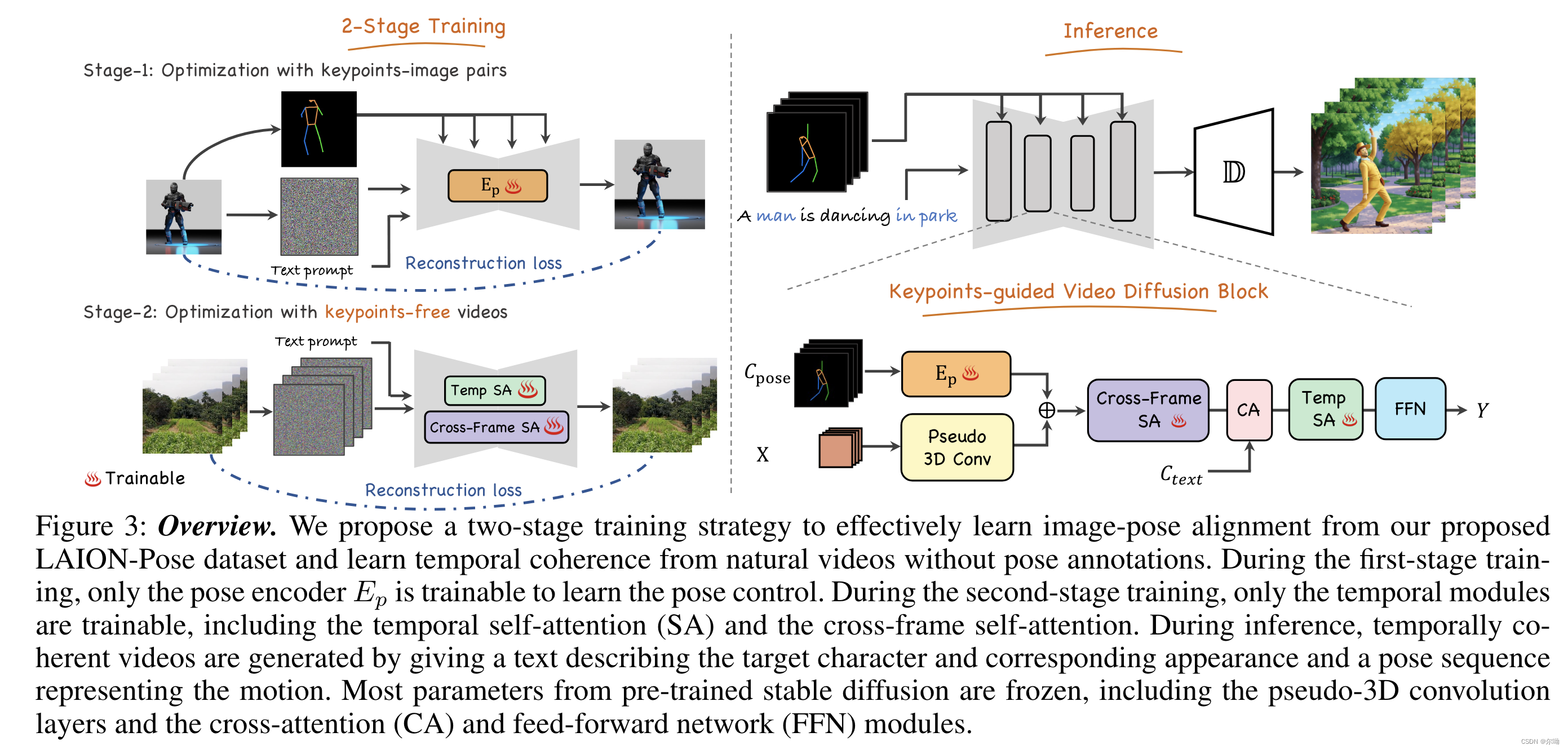
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
清华深&港科&深先进&Tencent AAAI24https://github.com/mayuelala/FollowYourPose 问题引入 本文的任务是根据文本来生成高质量的角色视频,并且可以通过pose来控制任务的姿势;当前缺少video-pose caption数据集,所以提出一个两…...
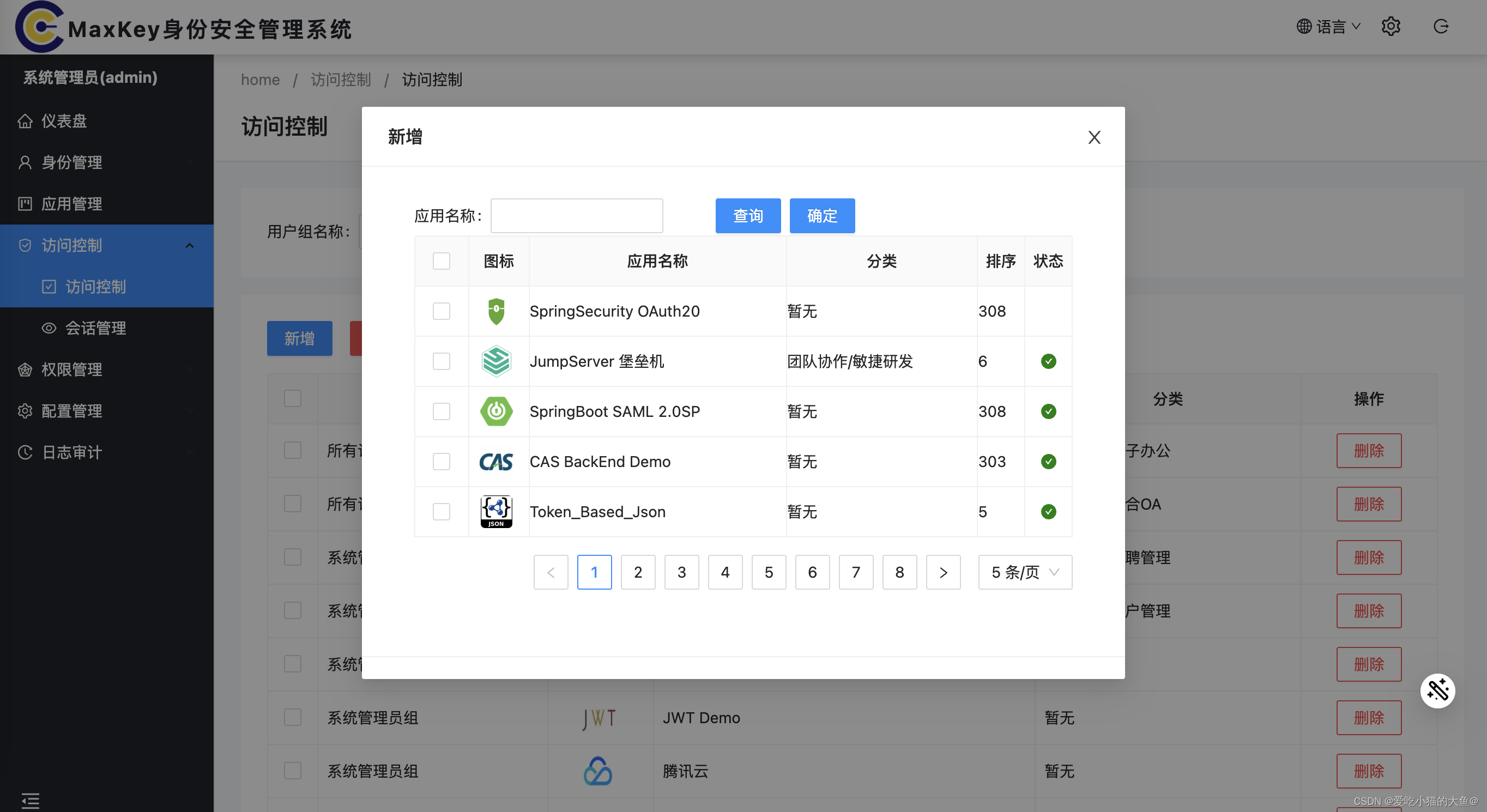
记录一次开源 MaxKey 安装部署
官方文档:https://www.maxkey.top/doc/docs/intro/ 开源代码:https://toscode.mulanos.cn/dromara/MaxKey 发行版:https://toscode.mulanos.cn/dromara/MaxKey/releases 一、准备工作 yum install -y yum-utils yum-config-manager --add-r…...

k8s基础命令
#查看pod kubectl get pod -n 命名空间 或者 kubectl get pod -n 命名控江 -o wide 例如: kubectl get pod -n databank-dev #查看deployment控制器 kubectl get deploy -n 命名空间 kubectl get deploy -n databank-dev #查看命名控制(namespace&am…...

【云原生_K8S系列】认识 Kubernetes
在当今数字化转型的浪潮中,企业对于构建高效、灵活的软件架构有了更高的期望。而在这个迅速变化的环境中,容器化技术如雨后春笋般涌现,为解决传统部署和管理软件所带来的挑战提供了一种全新的解决方案。在众多容器编排工具中,Kube…...

不懂网络也能远程连内网?UU 远程这个新功能,我真的会用
不懂网络也能远程连内网?UU 远程这个新功能,我真的会用 不懂网络也能远程连内网?UU 远程这个新功能,我真的会用 其实我的场景很简单——公司内网有台开发机,上面跑了不少服务,日常在家办公时需要随时能访问…...

element-plus主题换色
提示:本篇暂未完善全,仅仅提供思路 具体的实现可以参考我这篇文章,验证可行:推荐使用该链接方式实现换色 主题方式是通过切换主题的方式实现换色,例如blue、green,不推荐,仅参考逻辑。 原因&a…...

Wannakey终极指南:免费恢复WannaCry加密文件的专业内存密钥恢复工具
Wannakey终极指南:免费恢复WannaCry加密文件的专业内存密钥恢复工具 【免费下载链接】wannakey Wannacry in-memory key recovery 项目地址: https://gitcode.com/gh_mirrors/wa/wannakey Wannakey是一款专为恢复WannaCry勒索软件加密文件而设计的免费开源工…...

5分钟上手:用VMagicMirror打造你的虚拟形象分身
5分钟上手:用VMagicMirror打造你的虚拟形象分身 【免费下载链接】VMagicMirror VRM Software for Windows to move avatar with minimal devices. 项目地址: https://gitcode.com/gh_mirrors/vm/VMagicMirror VMagicMirror是一款专为Windows设计的开源虚拟角…...

如何快速掌握智能电源管理:macOS用户的完整配置指南
如何快速掌握智能电源管理:macOS用户的完整配置指南 【免费下载链接】SleeperX MacBook prevent idle/lid sleep! Hackintosh sleep on low battery capacity. 项目地址: https://gitcode.com/gh_mirrors/sl/SleeperX SleeperX是一款专为macOS用户设计的开源…...

在Node.js服务中集成Taotoken实现多模型智能对话
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现多模型智能对话 应用场景类,描述一个Node.js后端服务需要集成大模型能力的场景&#…...
)
RWKV vs Llama2:在论文审稿任务上,我们为什么第一版选了它?(附长上下文模型选型避坑指南)
RWKV与Llama2在论文审稿任务中的技术选型思考 当面对论文审稿这一知识密集型任务时,模型选型往往成为项目成败的关键。2023年第三季度,我们在构建首个论文审稿GPT系统时,曾在RWKV与Llama2之间面临艰难抉择。本文将深入剖析两种架构的核心差异…...

办公效率翻倍!OpenClaw AI 数字员工实操教程
适配系统:Windows 10 64位(新手专享版) 产品亮点: 零门槛安装:无需命令行操作,免去复杂环境配置即开即用:解压即安装,内置完整运行环境可视化操作:全程图形界面&#x…...

智慧养殖与猪行为实例分割数据集 动物行为分析数据集 生猪进食数据集 生猪睡觉站立姿态识别数据集 yolo格式数据集
猪行为实例分割数据集核心信息 类别 Tags 标签 Instance Segmentation 实例分割 Model 模型Classes (4) 类别(4) Eating 进食 Lying 躺着 Sitting 坐着 Standing 站立数据集关键信息表信息类别具体内容数据集类别猪行为实例分割数据集,聚焦猪…...

Box64终极指南:如何在ARM设备上轻松运行x86程序?三个简单步骤解锁无限可能
Box64终极指南:如何在ARM设备上轻松运行x86程序?三个简单步骤解锁无限可能 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_m…...