【数据分析】Numpy和Pandas库基本用法及实例--基于Japyter notebook实现

 个人主页:在线OJ的阿川
个人主页:在线OJ的阿川
大佬的支持和鼓励,将是我成长路上最大的动力 
阿川水平有限,如有错误,欢迎大佬指正 


承接上篇的博客
数据分析—技术栈和开发环境搭建
Python初阶
Python–语言基础与由来介绍
Python–注意事项
Python–语句与众所周知
目录
- Numpy
- 数组类
- 具体操作
- Pandas
- 基本类
- Series类
- 具体操作
- DataFrame类
数据分析最常用的两个库为Numpy和Pandas
用的编辑器为Jupyter notebook
接下来的代码将基于该编辑器中实现
Numpy
- 首先先在cmd(命令提示符)当中安装该库

- 要使用该库,还要在jupyter notebook导入该库
数组类
- .array()方法 创建数组
- .ndim 方法 查看数组维数
- .shape 方法 以元组的形式查看数组几维几元素
- .size 方法 查看数组元素总个数
- .dtype 方法 查看数组元素类型
- .zeros(n) 方法 创建n个为0的数组
- .ones(n)方法 创建n个为1的数组
- n为任意数字
- 数组元素类型为浮点型
- .arange( n,n , n)方法 创建以n到n,左闭右开,步长为n的数组
- .concatenate()方法 将多个数组连接一起,并不改变各个数组
- .sort()方法 对数组进行排序
- [索引 ] 数组可以通过索引进行查找
- [ n:n ] 数组可以通过切片进行查找
- n表示任意数字
- 数组 + 数组 数组相加,表示拼接数组
- 数组 * n 表示利用数组的广播机制,对数组每个元素都乘以n
- 广播机制

- .max()方法 表示数组的最大元素
- .min()方法 表示数组的最小元素
- .sum()方法 表示数组元素总和
- .mean()方法 表示数组元素的平均值
- 数组[ () I或者& ()] 表示数组中加条件
具体操作
具体操作的图:


如果你想练习以上方法,这里有些题:


答案是
import numpy as np
arr1 =np.array([6, 2, -7, 2, 8, -2, 1])
arr1
arr2 = np.array([[1, 3, 5], [2, 4, 6]])
arr2
print(arr1.ndim)
print(arr2.ndim)
print(arr1.shape)
print(arr2.shape)
print(arr1.size)
print(arr2.size)
print(arr1.dtype)
print(arr2.dtype)
arr3 = np.zeros(6)
arr3
arr4 = np.ones(5)
arr4
arr5 = np.arange(10, 21, 2)
arr5
import numpy as np
arr1 = np.array([1, 3, 2, 4, 9])
arr1
arr2 = np.ones(5)
arr2
arr3 = np.zeros(5)
arr3
arr_sum = np.concatenate([arr1, arr2, arr3])
arr_sum
arr1.sort()
arr1
print(arr1[2])
print(arr1[-3])
print(arr1[1:4])
arr1 + arr2
arr1 * 5
print(arr1.max())
print(arr1.min())
print(arr1.sum())
print(arr1.mean())
arr1[(arr1 < 1) | (arr1 > 3)]
Pandas
Pandas库中有两个最重要的方法
- .Series()
- .DataFrame()
基本类
- .iloc[ ] 以位置索引查找数组元素,位置索引从零开始,可以与切片搭配使用
- .loc[ ]以标签索引查找数组元素,可以与切片搭配使用
- [()|或者d ()] 条件选择数组元素
- .add()方法 将两个数组相加,且参数中可以加缺失值
- 若不写缺失值 则两个数组默认相同索引相加 如果没有相同索引则会报错
- .describe()方法 打印统计信息
- 元素数量count
- 元素平均值mean
- 元素标准差std
- 元素前1/4(25%)
- 元素前2/4(50%)
- 元素前3/4(75%)
- 元素最大值max
- 元素类型dtype
- .apply Python中的高阶函数 可以包含其他函数
- .index 展示索引
- .columns 展示维度
- .T 表示对数组转置
- .head(n)表示展示数组中的前面n行
- .drop([“标签索引” ],axis=0或者1) 表示删除针对于某行或者某列的该标签索引的数据
- axis=0 表示行(实际操作是列)
- axis=1 表示列(实际操作是行)

- lambda关键词 这是Python当中的关键词与apply()搭配使用,可以实现具体的函数
- applymap(普通函数) 表示将数组中的每个元素放入普通函数中
Series类
- .Series([ ]) 创建一维表格且索引默认为零开始
- .Series([ ],index = [ ])创建表格且指定索引
- .Series({ })创建字典类型表格
具体操作
具体操作的图


如果你想练习以上方法,这里有些题:


答案是:
import pandas as pd
s1 = pd.Series([-1.2, 3.7, 2.5, -8.2, 6.3])
s1
s2 = pd.Series([1, 2, 3, 4, 5], index=[5, 4, 3, 2, 1])
s2
print(s2.iloc[1])
s2.loc[5:3]
s3 = pd.Series({"小李":82, "小陈":93, "小张":91, "小曾":78, "小邓":68})
s3
s3.loc["小张"] = 95
s3
s3[(s3 > 80) & (s3 < 90)]
import pandas as pd
s1 = pd.Series([92, 67, 70, 88, 76], index = ["小明", "小红", "小杰", "小丽", "小华"])
s1
s2 = pd.Series([95, 85, 60, 79, 76], index = ["小明", "小杰", "小宇", "小娟", "小彤"])
s2
s1.add(s2, fill_value = 0)
s1.describe()
s1 = s1 + 5
s1
def get_grade_from_score(score):if score > 90:return "A"elif score > 80:return "B"elif score > 70:return "C"elif score > 60:return "D"else:return "不及格"
s1.apply(get_grade_from_score)DataFrame类
- .DataFrame()创建二维表格,默认标签为列标签
- 这里的二维是指两个维度
- 分别为列维度和行维度
- 是列标签和行标签
- 分别为列维度和行维度
- 这里的二维是指两个维度
- .DataFrame[" 列标签"] 表示以该列标签索引查找表格元素
- .DataFrame[“列标签”:“列标签”] 表示以多个该列标签索引搜索数据
- DataFrame.loc[ “行标签”,“列标签”] 表示以该行标签和列标签索引搜索数据
- Series+DataFrame 可以相加,但要注意标签索引要相对应
- DataFrame +n 表示当中元素数据+n
- n表示任意数字



如果你想练习以上方法,这里有些题:



答案是
import pandas as pd
name = pd.Series(["小陈", "小李", "小王", "小张", "小赵", "小周"], index=[1, 2, 3, 4, 5, 6])
gender = pd.Series(["女", "女", "男", "男", "女", "男"], index=[6, 5, 4, 3, 2, 1])
height = pd.Series([172.5, 168.0, 178.2, 181.3, 161.7], index=[1, 2, 3, 4, 5])
students = pd.DataFrame({"姓名":name, "性别":gender, "身高":height})
students
print(students.index)
print(students.columns)
students.T
students["身高"]
students[["性别", "身高"]]
students.loc["3":"5"]
students.loc["3":"5", "姓名":"身高"]
students.loc["3":"5", : ]
students[(students["身高"] > 165) & (students["性别"] == "女")]
students.head(5)
import pandas as pd
students = {"1":{"姓名" :"小陈", "考试1":85, "考试2":95, "考试3":92}, "2":{"姓名":"小李", "考试1":91, "考试2":92, "考试3":94}, "3":{"姓名":"小王", "考试1":86, "考试2":81, "考试3":89}, "4":{"姓名":"小张", "考试1":79, "考试2":89, "考试3":95}, "5":{"姓名":"小赵", "考试1":96, "考试2":91, "考试3":91}, "6":{"姓名":"小周", "考试1":81, "考试2":89, "考试3":92}}
students = pd.DataFrame(students).T
students
students["考试4"] = [72, 69, 79, 83, 82, 76]
students
students.loc["7"] = {"姓名":"小杨", "考试1":79, "考试2":82, "考试3":81, "考试4":69}
students
students.drop(["6", "7"], axis = 0)
students.drop(["考试2", "考试4"], axis = 1)
bonus = pd.Series({"考试1":2, "考试2":3, "考试3":2, "考试4":5})
bonus
bonus + students[["考试1", "考试2", "考试3", "考试4"]]
students["考试4"] = students["考试4"] + 10
students
import pandas as pd
import numpy as np
students = {"1":{"姓名" :"小陈", "考试1":85, "考试2":95, "考试3":92}, "2":{"姓名":"小李", "考试1":91, "考试2":92, "考试3":94}, "3":{"姓名":"小王", "考试1":86, "考试2":81, "考试3":89}, "4":{"姓名":"小张", "考试1":79, "考试2":89, "考试3":95}, "5":{"姓名":"小赵", "考试1":96, "考试2":91, "考试3":91}, "6":{"姓名":"小周", "考试1":81, "考试2":89, "考试3":92}}
students = pd.DataFrame(students).T
students
score_average = students.loc[ : , "考试1":"考试3"].mean(axis = 1)
name = students["姓名"]students_average = pd.DataFrame({"姓名":name, "平均分":score_average})
students_average
students.loc[ : , "考试1":"考试3"].apply(lambda x: np.sort(x)[-2])
def grade_from_score(score):if score >= 95:return "A+"elif score >= 90:return "A"elif score >= 85:return "B+"elif score >= 80:return "B"elif score >= 75:return "C+"else:return "C"
students.loc[ : , "考试1":"考试3"].applymap(grade_from_score)
students["考试1"] = students["考试1"].astype("int")
students["考试2"] = students["考试2"].astype("int")
students["考试3"] = students["考试3"].astype("int")
students.describe()
请踏实的走好每一步路,一定会变得更强
好的,到此为止啦,祝您变得更强

| 道阻且长 行则将至 |
|---|
个人主页:在线OJ的阿川大佬的支持和鼓励,将是我成长路上最大的动力 
相关文章:
【数据分析】Numpy和Pandas库基本用法及实例--基于Japyter notebook实现
各位大佬好 ,这里是阿川的博客 , 祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 承接上篇的博客 数据分析—技术栈和开发环境搭…...
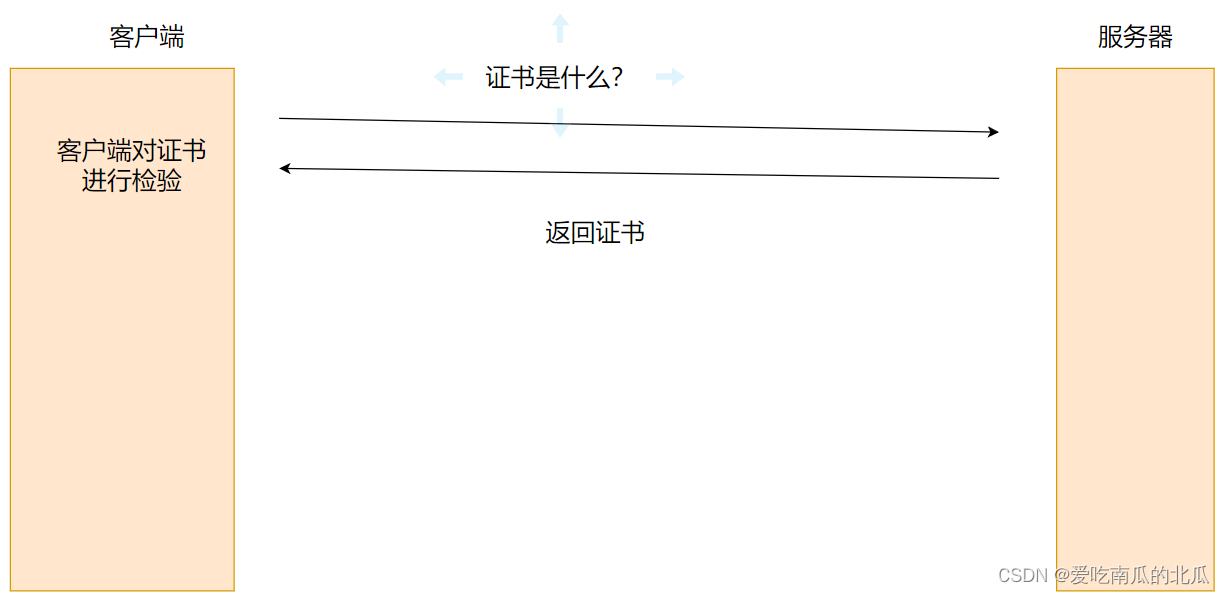
【网络协议】应用层协议HTTPS
文章目录 为什么引入HTTPS?基本概念加密的基本过程对称加密非对称加密中间人攻击证书 为什么引入HTTPS? 由于HTTP协议在网络传输中是明文传输的,那么当传输一些机密的文件或着对钱的操作时,就会有泄密的风险,从而引入…...
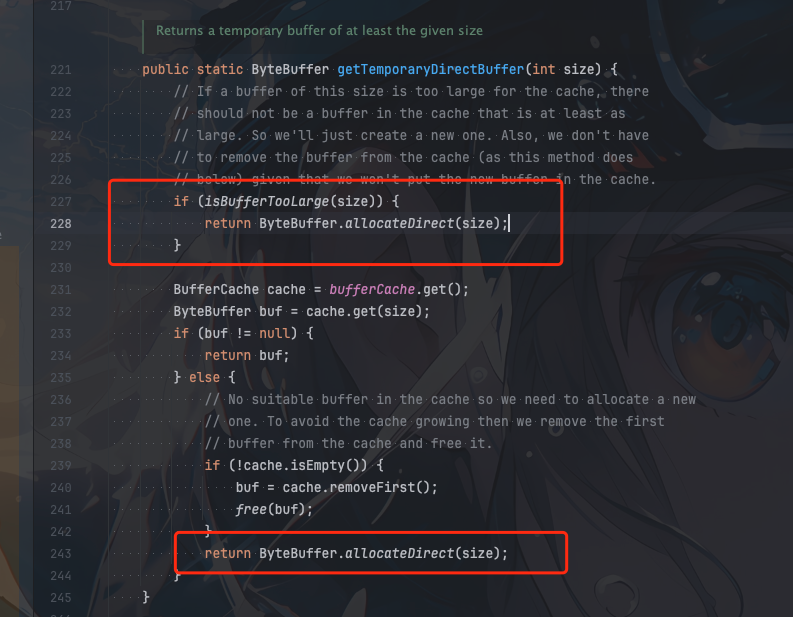
java nio FileChannel堆内堆外数据读写全流程分析及使用(附详细流程图)
这里是小奏,觉得文章不错可以关注公众号小奏技术 背景 java nio中文件读写不管是普通文件读写,还是基于mmap实现零拷贝,都离不开FileChannel这个类。 随便打开RocketMQ 源码搜索FileChannel 就可以看到使用频率 kafka也是 所以在java中文件读写FileCh…...
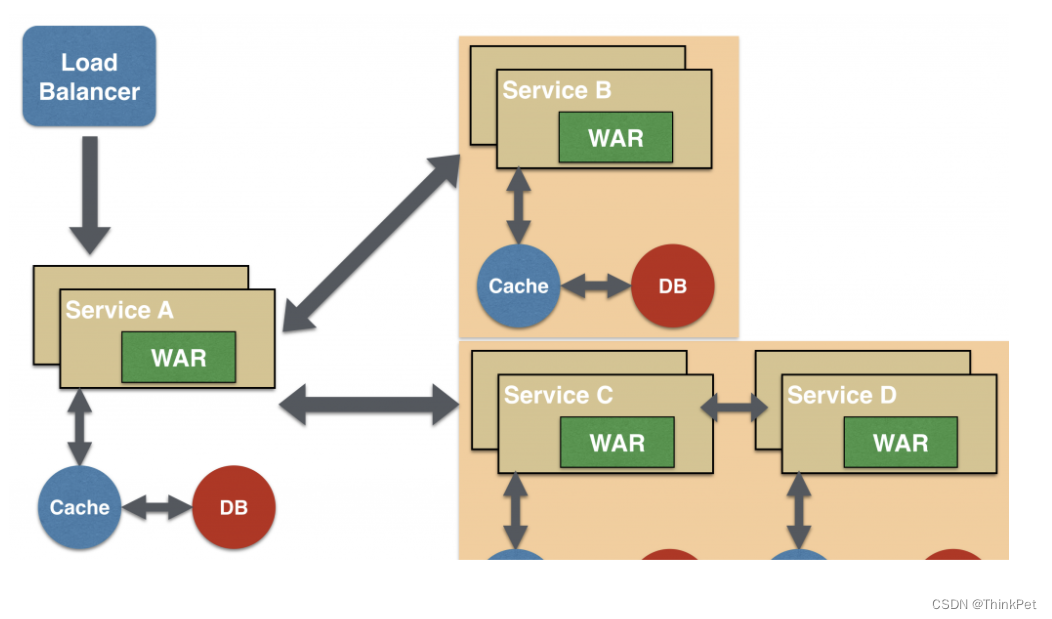
微服务架构-分支微服务设计模式
微服务架构-分支微服务设计模式 这种模式是聚合器模式的扩展,允许同时调用两个微服务链 分支微服务设计模式是一种用于构建大型系统的微服务架构模式,其核心思想是 将复杂的业务逻辑拆解为多个小的、相互独立的子系统,每个子系统由一个或多…...
)
关于Vue本地图片转file传到后端服务器(不通过组件上传)
一、代码 // 核心代码 const getMyFileFromLocalPath (localPath, filename) > {return fetch(localPath).then((response) > response.blob()).then((blob) > new File([blob], filename, { type: "image/png" })); // 假设是PNG格式// 获取真正的流文件…...

CCF20240302——相似度计算
CCF20240302——相似度计算 代码如下: #include <stdio.h> #include <string.h> #include <ctype.h>#define MAX_WORD_LEN 100 #define MAX_WORDS 10000int main() {int n, m;scanf("%d %d", &n, &m);char words1[MAX_WORDS][…...

C++的第一道门坎:类与对象(二)
一.类中生成的默认成员函数详解 0.类的6个默认成员函数 编译器会给类生成六个默认成员函数,在类中即使我们什么都不做,也会自动生成。 默认成员函数:用户没有显式实现,编译器会自动生成的成员函数称为默认成员函数。 下面我们逐…...

C语言与内存息息相关的重要概念有哪些?
一、问题 C语⾔、C语⾔和C#语⾔,这三门语⾔,⼀个⽐⼀个加号()多,C语⾔没有加号,C有两个加号,C#有四个加号。随着语⾔的发展,⼀个⽐⼀个简单,很多问题系统都给做了&#x…...
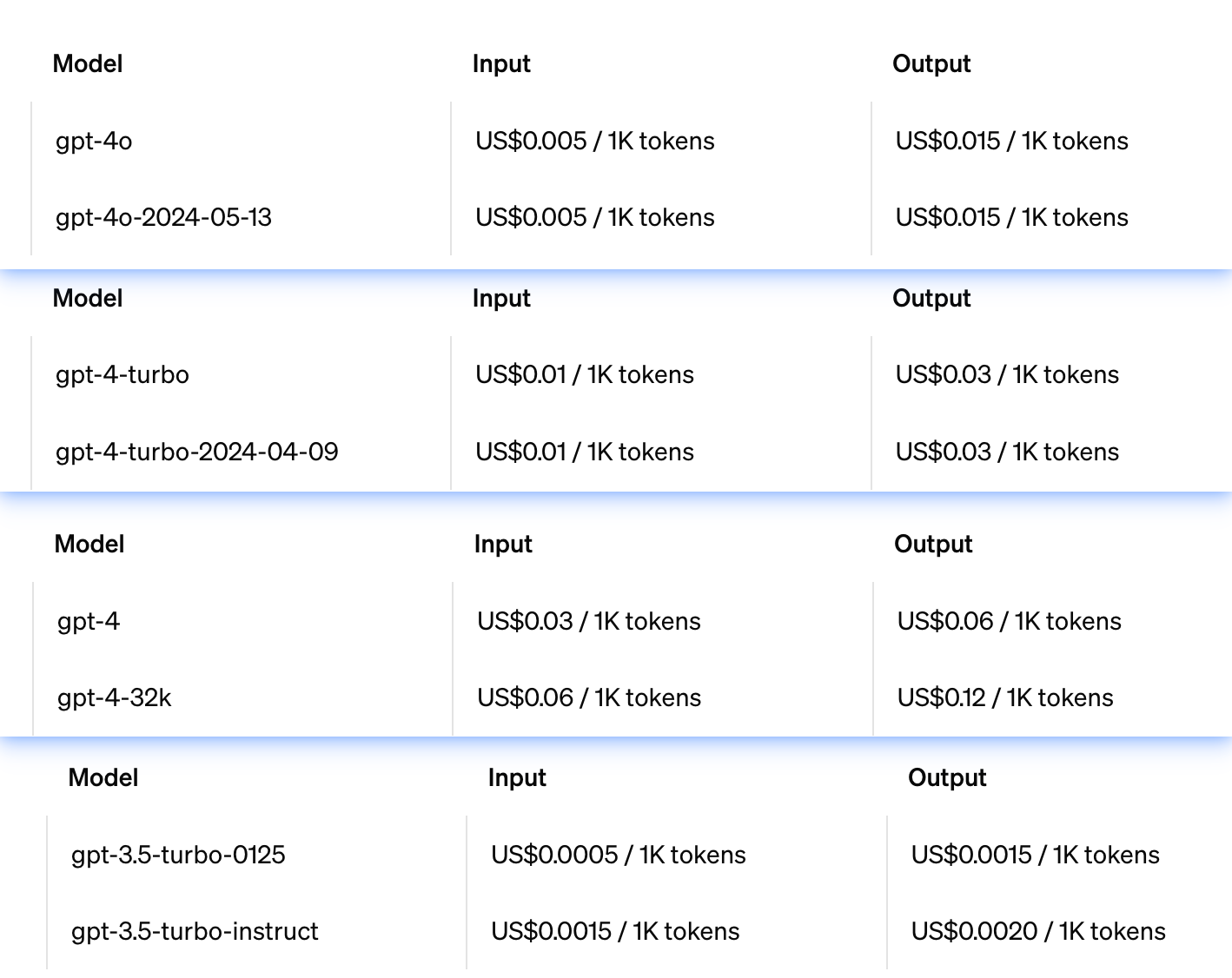
【chagpt】广泛使用API之前:考虑成本和数据隐私
文章目录 一. 定价和标记限制二. 安全和隐私 在广泛使用API之前,应该考虑两个重要因素:成本和数据隐私。 一. 定价和标记限制 OpenAI在Pricing页面上列出了模型的定价。请注意,OpenAI不一定及时更新该页面上的定价信息,因此实际…...

六月后考研如何备考看这一篇就够了
以下是考研六月后可以参考的规划: 6 月至 8 月(强化阶段): 英语:继续背单词,开始刷历年真题中的阅读部分,仔细分析错题原因,总结解题技巧。数学:完成基础阶段的复习后&am…...

Linux主机连接腾讯云服务器详细配置
硬件条件 当然你要先有一个云服务器,腾讯云比阿里云便宜一点,所以就用腾讯云了 问了师兄买这个98的就行,选择CentOS,不要选Ubuntu,因为 嗯,大概就是这样 编程测试 云服务器当然是作为服务端 server.cpp…...

数字化工厂怎么收集,处理数据?
数字化工厂的数据收集与处理 数字化工厂是现代化工厂,利用数字技术和数据分析提高效率和优化流程。数据分析作为数字化工厂的核心技术,对数据的获取与处理至关重要。在数字化工厂中,数据的来源包括企业内部信息系统、物联网信息以及外部信息&…...

OOM不会导致JVM退出
问题来源 一次生产事故,由于一次性从数据库查询过多数据导致线程 OOM:Java heap space 异常(千万级表,JVM堆内存2G),但是在线程OOM发生时,java进程却没有立即挂掉。 ##OOM与异常 说到底OutOfM…...
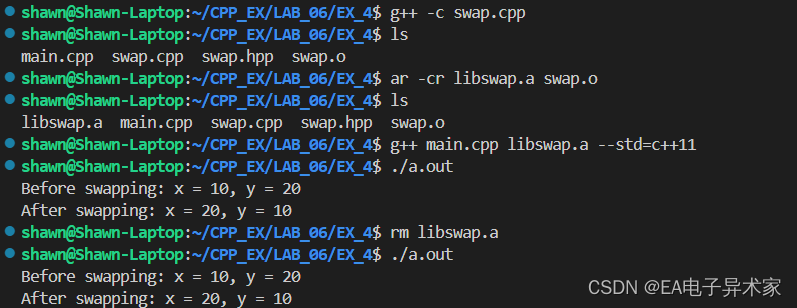
C++学习日记 | LAB 6 static library 静态库
资料来源:南科大 余仕琪 C/C Program Design LINK:CPP/week06 at main ShiqiYu/CPP GitHub 一、本节内容 本节主要介绍静态库和动态库。 1.1 静态库和动态库的概念 静态链接和静态库(也称为存档)是链接器将所有使用的库函数复制到可执行文件的结果。静…...

他用AI,抄袭了我的AI作品
《大话西游》里面有一句经典台词:每个人都有一个妈,但是“你妈就一定是你妈吗?” 用AI创作的艺术作品,也走进类似的困境:如何证明你用AI生成的作品,就是你的作品? 近日,腾讯科技独…...

力扣刷题--2956. 找到两个数组中的公共元素【简单】
题目描述 给你两个下标从 0 开始的整数数组 nums1 和 nums2 ,它们分别含有 n 和 m 个元素。 请你计算以下两个数值: 统计 0 < i < n 中的下标 i ,满足 nums1[i] 在 nums2 中 至少 出现了一次。 统计 0 < i < m 中的下标 i &am…...

海信集团携纷享销客启动LTC数字化落地 推动ToB业务再升级
日前,海信集团携手连接型CRM纷享销客正式启动LTC(Leads to Cash)数字化平台实施落地项目。作为海信集团数字化的重要里程碑,该项目将通过统一规划、统一投资、统一平台、资源共享和数据赋能,构建ToB业务数字化经营管理…...

【Go语言入门学习笔记】Part5.函数
一、前言 这里的还是跟C有区别的,大家熟悉了其他语言后,还得注意一下这里的内容。Go的函数非常灵活。 二、学习代码 package mainimport "fmt"// ZhengXing 类似typedef的方法 type ZhengXing int// 函数名有说法,首字母大写是pu…...

磁珠笔记汇总
磁珠笔记汇总 磁珠是和电感很相似的器件。 电感磁珠单位亨(H)欧姆(Ω)是否储能存储能量消耗高频能量应用场景通常用于开关电源吸收高频,EMC保护如何看待损耗使用电感时希望损耗越小越好使用磁珠时是利用其损耗来消耗不需要的高频分量 一、磁珠的工作原理 磁珠与…...

【css3】02-css3新特性之选择器篇
目录 1 属性选择器 2 结构伪类选择器 3 其他选择器 :target和::selection ::first-line和::first-letter 4 伪类和伪元素的区别 伪类(Pseudo-classes) 伪元素(Pseudo-elements) 伪类和伪元素的区别 1 属性选择器 ☞ 属性选…...
)
别再让ROS2节点间通信拖慢你的机器人:手把手配置Fast DDS共享内存传输(附XML配置文件)
ROS2高性能通信实战:Fast DDS共享内存传输深度优化指南 当机器人系统需要处理高频率的激光雷达点云或4K摄像头图像时,传统网络传输方式可能成为性能瓶颈。我曾在一个工业分拣机器人项目中发现,仅图像传输就占用了30%的CPU资源,这促…...

关联查询,左连接,inner join笔记,BNL,NLJ
文章目录left join的最大值和最小值3个表的inner join关联查询时的is_del处理cross join(full join)NLJ 性能高BNL 性能低blj会导致什么问题?left join的最大值和最小值 假设左表m条,右表n条 最小值是m: 当一条也匹配不到右表时,或者右表中…...

终极指南:如何在5分钟内让魔兽争霸3在现代电脑上完美运行
终极指南:如何在5分钟内让魔兽争霸3在现代电脑上完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争霸3在现代W…...

词达人自动化助手终极指南:如何让英语学习效率提升10倍
词达人自动化助手终极指南:如何让英语学习效率提升10倍 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否曾经面对堆积如山的英语词汇任务感到力不…...

5分钟极速上手:B站视频转文字工具bili2text完整指南
5分钟极速上手:B站视频转文字工具bili2text完整指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为整理B站视频内容而烦恼吗?每…...

Gemini 3.5 Flash 实测报告:快4倍、编程跑分超自家Pro,这6类场景到底该不该换?
Gemini 3.5 Flash 实测报告:快4倍、编程跑分超自家Pro,这6类场景到底该不该换? 问题背景 Google 在 2026 年 5 月发布了 Gemini 3.5 Flash,主打"前沿性能 Flash 价位"。从基准测试数据看,这款模型在编程跑分…...
)
独家披露:Perplexity未公开的政治新闻过滤白名单(含6国政府通报接口绕过逻辑与合规使用边界)
更多请点击: https://kaifayun.com 第一章:Perplexity政治新闻查询的底层机制与合规边界 Perplexity 在处理政治新闻类查询时,并非直接抓取或缓存原始新闻页面,而是依托其混合检索架构——融合实时网络搜索(通过 Bing…...

XInputTest:精准测量游戏手柄轮询率与延迟的专业工具
XInputTest:精准测量游戏手柄轮询率与延迟的专业工具 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest 在竞技游戏和模拟飞行等高精度操作场景中,游戏手…...
)
A/B测试还在用t检验?DeepSeek团队淘汰传统方法的4个关键转折点(含贝叶斯动态决策引擎实测对比)
更多请点击: https://intelliparadigm.com 第一章:A/B测试范式迁移的必然性 传统A/B测试长期依赖静态流量分配、固定实验周期与人工决策闭环,在现代高并发、多场景、实时反馈的业务系统中正面临三重结构性失配:实验吞吐量低、决策…...

CANN/asc-devkit float2到half2向上取整转换函数
__float22half2_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitc…...