【CUDA】Nsight profile驱动的CUDA优化
前置准备
- 安装NVIDIA Nsight Compute。 安装好后选择使用管理员权限启动
- 下载官方 Demo 代码
- 官方博客
- Shuffle warp
1. 任务介绍及CPU版本
1.1 任务介绍
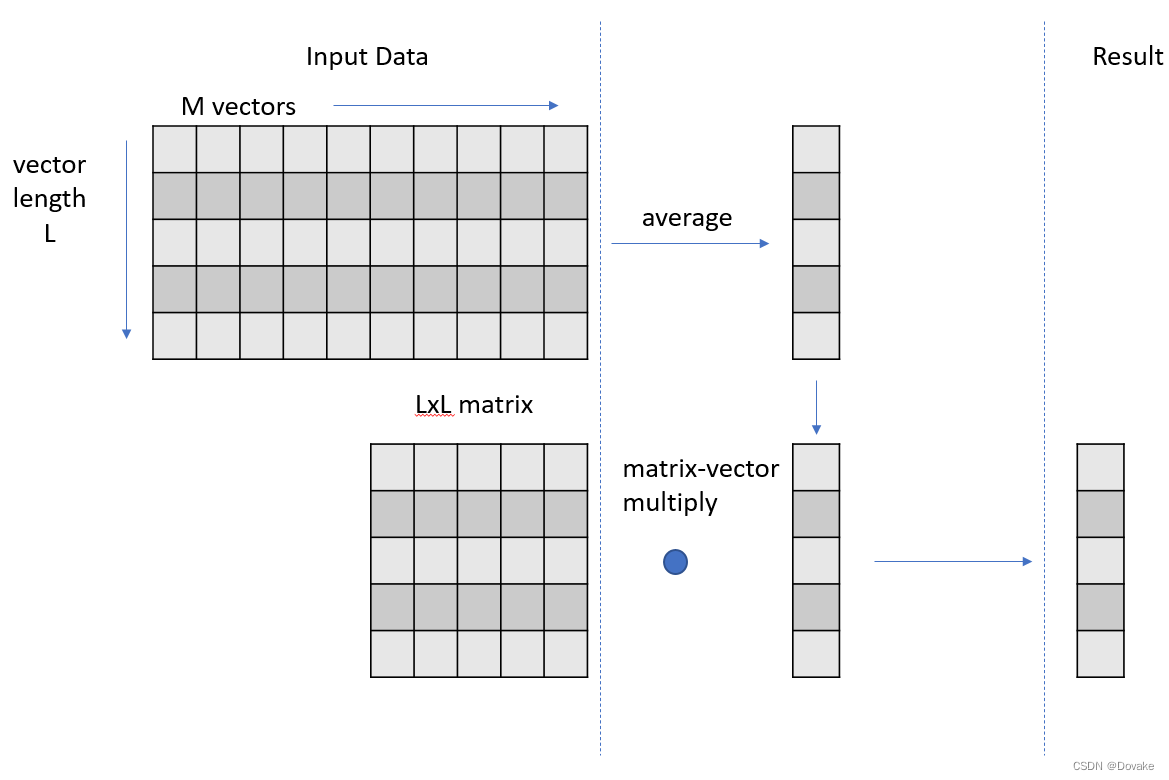
任务理解:
- 有一个 L x M 的矩阵 M 1 M_1 M1 对其每行取平均值 得到 V 1 ∈ R L × 1 V_1 \in \mathbb{R}^{L \times 1} V1∈RL×1 的列向量
- 有一个 L x L 的矩阵 M 2 M_2 M2 与 V 1 V_1 V1做矩阵乘法,最后得到 V 2 ∈ R L × 1 V_2 \in \mathbb{R}^{L \times 1} V2∈RL×1 的列向量
1.2 CPU版本实现
/**input: input 矩阵,维度为(N, L, M) N为Batchoutput: ouput 矩阵,维度为(N, L)matrix: matrix 维度为(L, L)
*/
template <typename T>
void cpu_version1(T *input, T *output, T *matrix, int L, int M, int N){
#pragma omp parallel forfor (int k = 0; k < N; k++){ // repeat the following, N timesstd::vector<T> v1(L); // vector length of Lfor (int i = 0; i < M; i++) // compute average vector over M input vectorsfor (int j = 0; j < L; j++)v1[j] += input[k*M*L+j*M+i];for (int j = 0; j < L; j++)v1[j] /= M;for (int i = 0; i < L; i++) // matrix-vector multiplyfor (int j = 0; j < L; j++)output[i*N+k] += matrix[i*L+j]*v1[j];}
}
1.3 计时逻辑
#include <time.h>
#ifdef __linux__
#define USECPSEC 1000000ULL
#include <sys/time.h>
unsigned long long dtime_usec(unsigned long long start){timeval tv;gettimeofday(&tv, 0);return ((tv.tv_sec*USECPSEC)+tv.tv_usec)-start;
}
#elif defined(WIN32)
#include <windows.h>
double dtime_usec(double start) {LARGE_INTEGER frequency; // ticks per secondLARGE_INTEGER t1; // ticksdouble elapsedTime;// get ticks per secondQueryPerformanceFrequency(&frequency);// get current timeQueryPerformanceCounter(&t1);// compute the elapsed time in micro-second resolution(毫秒)elapsedTime = (t1.QuadPart - start) * 1000000.0 / frequency.QuadPart;return elapsedTime;
}
#endif
1.4 main函数
typedef double ft;int main(){ft *d_input, *h_input, *d_output, *h_outputc, *h_outputg, *d_matrix, *h_matrix;int L = my_L; int M = my_M; int N = my_N;// host allocationsh_input = new ft[N*L*M];h_matrix = new ft[L*L];h_outputg = new ft[N*L];h_outputc = new ft[N*L];// data initializationfor (int i = 0; i < N*L*M; i++) h_input[i] = (rand()&1)+1; // 1 or 2for (int i = 0; i < L*L; i++) h_matrix[i] = (rand()&1)+1; // 1 or 2// create result to test for correctnessLARGE_INTEGER st;double dt;QueryPerformanceCounter(&st); // 获取起始时间点cpu_version1(h_input, h_outputc, h_matrix, L, M, N);dt = dtime_usec(st.QuadPart);std::cout << "CPU execution time: \t" << dt / 1000.0f << "ms" << std::endl;// device allocationscudaMalloc(&d_input, N*L*M*sizeof(ft));cudaMalloc(&d_output, N*L*sizeof(ft));cudaMalloc(&d_matrix, L*L*sizeof(ft));cudaCheckErrors("cudaMalloc failure");// copy input data from host to devicecudaMemcpy(d_input, h_input, N*L*M*sizeof(ft), cudaMemcpyHostToDevice);cudaMemcpy(d_matrix, h_matrix, L*L*sizeof(ft), cudaMemcpyHostToDevice);cudaMemset(d_output, 0, N*L*sizeof(ft));cudaCheckErrors("cudaMemcpy/Memset failure");// run on device and measure execution timeQueryPerformanceCounter(&st); // 获取起始时间点gpu_version1<<<1, L>>>(d_input, d_output, d_matrix, L, M, N);cudaCheckErrors("kernel launch failure");cudaDeviceSynchronize();cudaCheckErrors("kernel execution failure");dt = dtime_usec(st.QuadPart);cudaMemcpy(h_outputg, d_output, N*L*sizeof(ft), cudaMemcpyDeviceToHost);cudaCheckErrors("cudaMemcpy failure");for (int i = 0; i < N*L; i++) if (h_outputg[i] != h_outputc[i]) {std::cout << "Mismatch at " << i << " was: " << h_outputg[i] << " should be: " << h_outputc[i] << std::endl; return 0;}std::cout << "Kernel execution time: \t" << dt / 1000.0f << "ms" << std::endl;return 0;
}
2. GPU version1
2.1 实现
template<typename T>
__global__ void gpu_version1(const T * __restrict__ input, T * __restrict__ output, const T * __restrict__ matrix,const int L,const int M, const int N
)
{___shared__ T smem[L];int idx = threadIdx.x;// 以此处理N个Batchfor(int k = 0; k < N; i++){T v = 0;for(int i = 0; i < M; ++i){v += input[K * M * L + M * idx + i]}v /= M;for(int row = 0; row < L; ++row) {smem[idx] = v * M[idx * L + row];// 对矩阵乘法求和for(int s = blockDim.x >> 1; s > 0; s >>=1){__syncthreads();if (idx < s) smem[threadIdx.x] += smem[threadIdx.x + s];}if (!threadIdx.x) ouput[i*N + row] = smem[0];}}
}const int L = 512; // maximum 1024
const int M = 512;
const int N = 1024;
// 调用核函数
gpu_version1<<<1, L>>>(d_input, d_output, d_matrix, L, M, N);
2.2 时间对比
CPU execution time: 2764.96ms
Kernel execution time: 1508.34ms
2.3 Nsight 分析
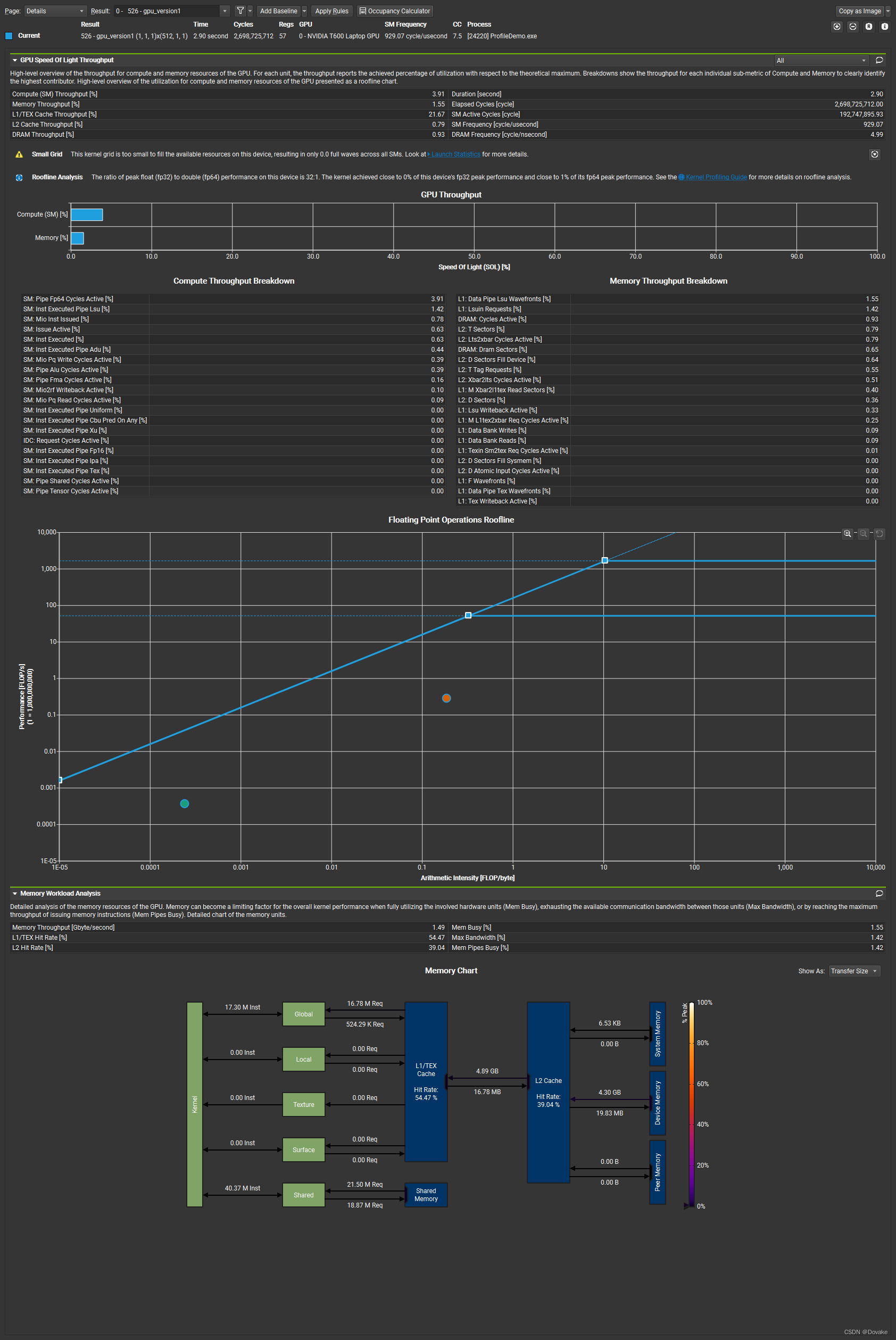
可以看到,这里This kernel grid is too small to fill the available resources on this device, resulting in only 0.0 full waves across all SMs.这里说我们的 grid size 设置得太小了,没有充分利用SM。下一版我们增大 Graid size
3. 增加GridSize
3.1 实现
分析上一个核函数调用:
gpu_version1<<<1, L>>>(d_input, d_output, d_matrix, L, M, N);
这里grid size是1,这里可以考虑把这个设置为 Batch size 即 N
gpu_version1<<<N, L>>>(d_input, d_output, d_matrix, L, M, N);
对应得核函数修改, 其实就是 把k 替换成了 blockIdx.x
template <typename T>
__global__ void gpu_version2(const T* __restrict__ input, T* __restrict__ output, const T* __restrict__ matrix, const int L, const int M, const int N) {// parallelize threadIdx.x over vector length, and blockIdx.x across k (N)__shared__ T smem[my_L];int idx = threadIdx.x;int k = blockIdx.x;T v1 = 0;for (int i = 0; i < M; i++)v1 += input[k * M * L + idx * M + i];v1 /= M;for (int i = 0; i < L; i++) {__syncthreads();smem[threadIdx.x] = v1 * matrix[i * L + idx];for (int s = blockDim.x >> 1; s > 0; s >>= 1) {__syncthreads();if (threadIdx.x < s) smem[threadIdx.x] += smem[threadIdx.x + s];}if (!threadIdx.x) output[k + i * N] = smem[0];}
}
3.2 时间对比
CPU execution time: 3219.04ms
Kernel execution timev1: 1508.34ms
Kernel execution timev2: 91.4291ms
可以看到相对v1 提高了15倍 +
3.3 Nsight 分析
3.3.1 概览
相比上一个版本,SM和memory的利用率明显提高了。
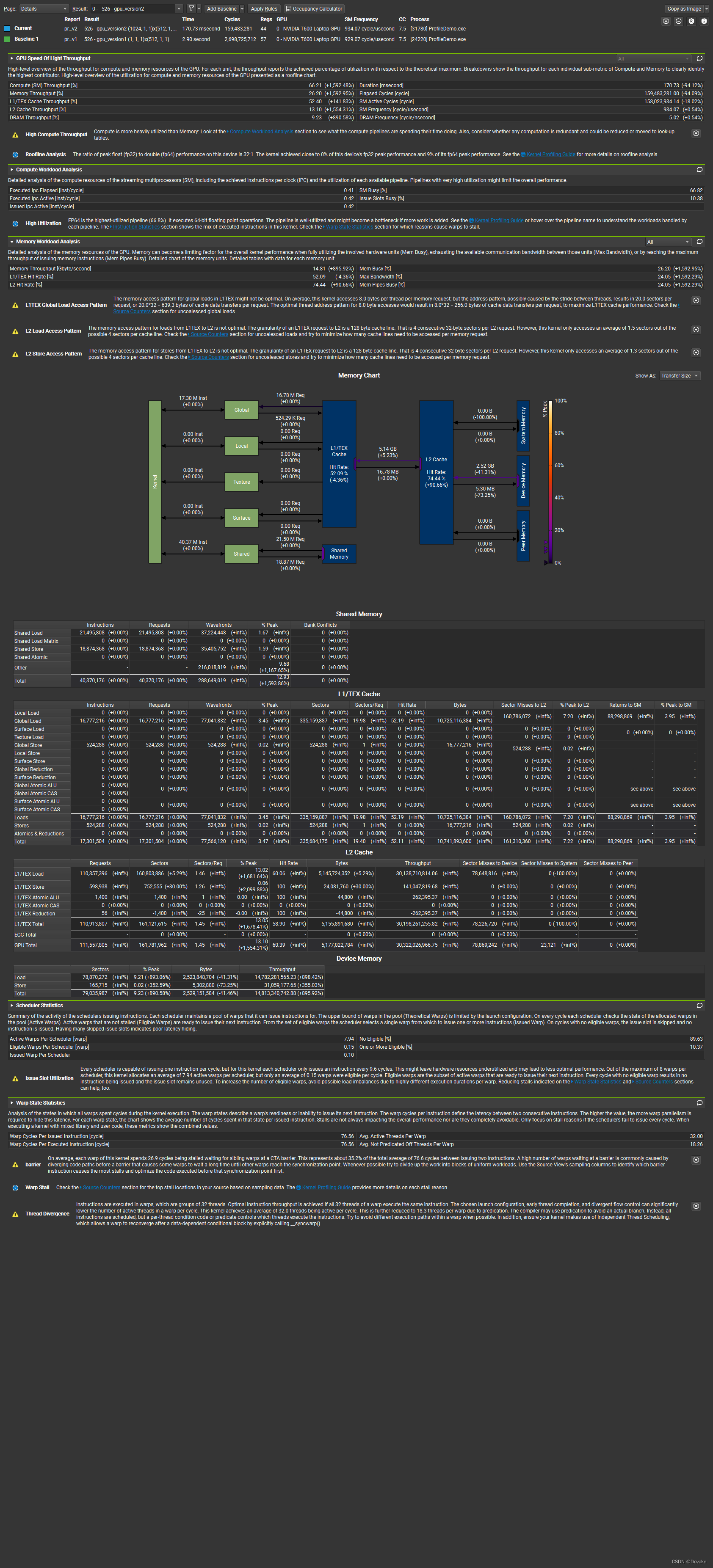
3.3.2 Memoy Workload Analysis
The memory access pattern for global loads in L1TEX might not be optimal. On average, this kernel accesses 8.0 bytes per thread per memory request; but the address pattern, possibly caused by the stride between threads, results in 20.0 sectors per request, or 20.032 = 639.3 bytes of cache data transfers per request. The optimal thread address pattern for 8.0 byte accesses would result in 8.032 = 256.0 bytes of cache data transfers per request, to maximize L1TEX cache performance. Check the Source Counters section for uncoalesced global loads.
在 L1TEX中,全局加载的内存访问模式可能不是最优的。平均来说,这个kernel 每个线程每次内存请内存会访问8 字节,但是当前的地址模式,可能由于线程之间的跨度导致每次请求了20个 sectors, 每次请求的缓存传输为 20 * 32 = 649.3 字节。对于8字节的访问,最优的线程地址模式使用的缓存传输数据为 8 * 32 = 256字节,为了最大化L1TEX缓存性能,检查没有 coalesed (合并)访问的全局加载。
为什么会导致这么高 ? 可以通过 source页面
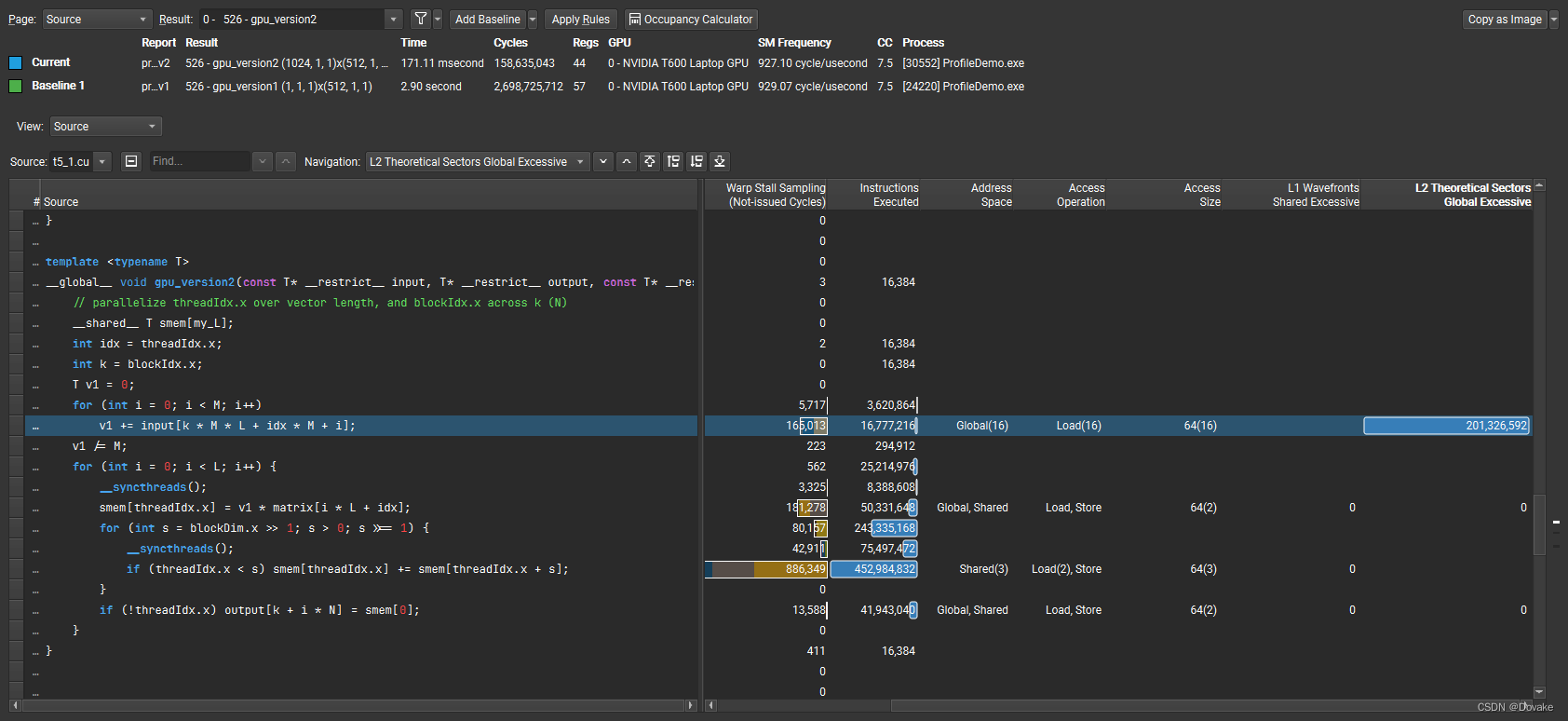
可以发现高亮的这一句进行了大量的L2 Cache访问操作,为什么这一句会导致访问不合并呢?
是因为每次for循环都隔了 idx * M 个数据,导致缓存失效,如何解决这个问题呢?看下一节
相关文章:
【CUDA】Nsight profile驱动的CUDA优化
前置准备 安装NVIDIA Nsight Compute。 安装好后选择使用管理员权限启动下载官方 Demo 代码官方博客Shuffle warp 1. 任务介绍及CPU版本 1.1 任务介绍 任务理解: 有一个 L x M 的矩阵 M 1 M_1 M1 对其每行取平均值 得到 V 1 ∈ R L 1 V_1 \in \mathbb{R}^{…...

字符串的拼接
字符串拼接方式1 之前的算术运算符,只是用来数值类型进行数学运算的,而string不存在算术运算符不能计算,但是可以通过号来进行字符串拼接。 string str "123"; //用进行拼接 str str "456"; Console.WriteLine(str)…...
HIVE3.1.3+ZK+Kerberos+Ranger2.4.0高可用集群部署
目录 一、集群规划 二、介质下载 三、基础环境准备 1、解压文件 2、配置环境变量 四、配置zookeeper 1、创建主体 2、修改zoo.cfg 3、新增jaas.conf 4、新增java.env 5、重启ZK 6、验证ZK 五、配置元数据库 六、安装HIVE 1、创建Hiver的kerberso主体 2…...
Android ANR Trace日志阅读分析技巧
什么是Trace日志 Trace日志是指ANR目录下的一份txt文件 adb pull /data/anr/traces.txt Trace日志有什么用 分析应用ANR无响应的问题, Trace怎么用 Cmd line: com.xx ABI: arm Build type: optimized Zygote loaded classes3682 post zygote classes3750 Intern…...

前端Ajax、Axios和Fetch的用法和区别笔记
前端 JavaScript 开发中,进行 HTTP 请求的三种主要方式是 Ajax、Axios 和 Fetch。这三种方式各有优缺点,并且适用于不同的场景。在合适的业务场景下使用,以下是它们的区别和使用举例。 1. Ajax Ajax(Asynchronous JavaScript an…...
)
Android的Framework(TODO)
(TODO)...

牛客小白月赛94 EF题解
题目描述 注:此版本为本题的hard(困难版),与easy(简单版)唯一的不同之处只有数据范围。 小苯有一个容量为 k 的背包,现在有 n 个物品,每个物品有一个体积 v 和价值 w࿰…...

大数据开发面试题【Flink篇】
148、flink架构 flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算 特点: 高吞吐和低延迟:每秒数百万个事件,毫秒级延迟 结果的准确性:提供了事件时间和处理时间语义,提供结果的一致…...
)
Java技术深度解析:高级面试问题与精粹答案(二)
Java 面试问题及答案 1. 什么是Java的垃圾回收机制?它是如何工作的? 答案: Java的垃圾回收机制(Garbage Collection,GC)是Java运行时环境(JRE)中的一个功能,用于自动管…...

算数运算符
算术运算符是用于数值类型变量计算的运算符。 它的返回结果是数值。 赋值符号 关键知识点:先看右侧,再看左侧,把右侧的值赋值给左侧的变量。 附上代码: string myName "唐唐"; int myAge 18; float myHeight 177.5…...

闲话 .NET(3):.NET Framework 的缺点
前言 2016 年,微软正式推出 .NET Core 1.0,并在 2019 年全面停止 .NET Framework 的更新。 .NET Core 并不是 .NET Framework 的升级版,而是一个从头开始开发的全新平台,一个跟 .NET Framework 截然不同的开源技术框架。 微软为…...

WPF实现简单的3D图形
简述 Windows 演示基础 (WPF) 提供了一种功能,用于根据应用程序要求绘制、转换 3D 图形并为其添加动画效果。它不支持完整的3D游戏开发,但在某种程度上,您可以创建3D图形。 通过组合 2D 和 3D 图形,您还可以…...

设计模式之创建型模式---原型模式(ProtoType)
文章目录 概述类图原型模式优缺点优点缺点 代码实现 概述 在有些系统中,往往会存在大量相同或者是相似的对象,比如一个围棋或者象棋程序中的旗子,这些旗子外形都差不多,只是演示或者是上面刻的内容不一样,若此时使用传…...

git命令新建远程仓库
今天记录一下使用git命令新建远程分支的操作,因为公司的代码管理仓库界面没找到新建分支的操作界面,无奈只能通过git命令来新建分支。 1、新建本地分支 首先,你的至少应该已经有了一个master分支,然后你再master分支下面执行下面…...
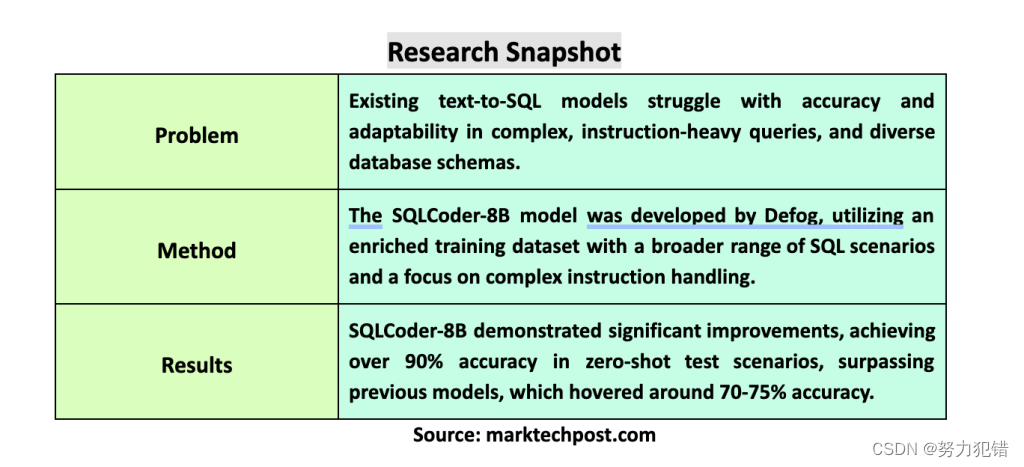
Defog发布Llama-3-SQLCoder-8B,文本转SQL模型,性能比肩GPT-4,准确率超90%,消费级硬件可运行
前言 在计算语言学领域,将自然语言转化为可执行的SQL查询是一个重要的研究方向。这对于让那些没有编程或SQL语法知识的用户也能轻松访问数据库信息至关重要。Defog团队近日发布了基于Llama-3的SQLCoder-8B模型,它在文本转SQL模型领域取得了显著突破&…...

防刷发送短信验证码接口的五种简单好用方法绝对够用
防刷发送短信验证码接口的五种简单好用方法,绝对够用 前端增加图形验证码,点击发送按钮后增加60s倒计时,60s后才可以再次点击 后端对接口次数校验,60s内同一电话号码只能发送一次 // 生成基于电话号码的重试锁定键 String repeat…...
ubuntu中idea创建spark项目步骤
1.前置条件 ubuntu中已经安装idea,jdk,scala,spark 2.打开idea,新建,选择Maven项目 3.在IDEA中,File-Setting-Plugin,下载Scala插件 4.File-project structure,导入插件 4.1在全局库中,选择导入刚才的sca…...
回文链表(快慢指针解法之在推进过程中反转)
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍 收藏⭐ 留言📝抱怨深处黑暗,不如提灯前行…...

深度剖析:为什么 Spring 和 IDEA 都不推荐使用 @Autowired 注解
目录 依赖注入简介 Autowired 注解的优缺点 Spring 和 IDEA 不推荐使用 Autowired 的原因 构造器注入的优势 Autowired 注解的局限性 可读性和可测试性的问题 推荐的替代方案 构造器注入 Setter 注入 Java Config Bean 注解 项目示例:Autowired vs 构造器…...

【接口自动化_05课_Pytest接口自动化简单封装与Logging应用】
一、关键字驱动--设计框架的常用的思路 封装的作用:在编程中,封装一个方法(函数)主要有以下几个作用:1. **代码重用**:通过封装重复使用的代码到一个方法中,你可以在多个地方调用这个方法而不是…...

终极虚拟定位指南:FakeLocation让你的Android设备位置自由
终极虚拟定位指南:FakeLocation让你的Android设备位置自由 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否厌倦了应用的位置限制?想要在社交软件中保…...

如何快速实现Android Studio中文界面:终极完整汉化指南
如何快速实现Android Studio中文界面:终极完整汉化指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android…...

法律文书分析系统接入 A-MEM 长程记忆
项目实训 | Vue3 FastAPI | NeurIPS 2025 A-MEM 复现与工程落地一、背景与动机 在法律文书智能分析系统的开发过程中,我们发现了一个核心痛点:AI助手没有"记忆"。 用户在第一轮对话里详细描述了案件事实——“我是原告张三,2024年…...
)
MATLAB数据处理小技巧:用reshape函数把一维数组变成你想要的任意形状(附图像处理实例)
MATLAB数据处理实战:reshape函数的高效应用与图像处理案例 当你面对一堆杂乱无章的一维数据时,是否曾为如何将其整理成适合分析的格式而头疼?在MATLAB中,reshape函数就像一位魔术师,能够在不改变数据本质的情况下&…...
)
KUKA机器人FSoE安全地址丢了别慌!手把手教你用WorkVisual 6.0找回(附KRC4标准柜地址表)
KUKA机器人FSoE安全地址丢失应急修复指南:WorkVisual 6.0实战全解析 当产线突然报警停机,示教器闪烁"FSoE安全地址丢失"的红色警告时,经验丰富的维护工程师都知道——这往往是EtherCAT网络拓扑结构异常引发的紧急故障。尤其在采用K…...

别再手动刷纹理了!用Blender 3.6的镂版映射,5分钟给苹果模型贴上真实贴图
别再手动刷纹理了!Blender 3.6镂版映射实战指南 在数字艺术创作中,给3D模型添加纹理是赋予物体真实感的关键步骤。许多Blender初学者在掌握了基础UV展开后,往往会陷入手动绘制纹理的低效循环——用笔刷一点一点"涂抹"贴图ÿ…...

量子门合成技术GULPS:异构硬件下的高效量子电路编译
1. 量子门合成基础与GULPS创新点 量子计算的核心操作单元是量子门,其中双量子位门(如CNOT、iSWAP等)在构建量子算法中扮演着关键角色。传统量子门合成方法主要围绕CNOT门展开,这种单一视角在面对现代量子硬件日益丰富的异构指令集…...

Kubernetes集群能耗监测:RAPL与Prometheus方案对比
1. 项目概述在Kubernetes集群中实现精确的能耗监测一直是系统优化领域的难点问题。作为一名长期从事分布式系统性能调优的工程师,我最近完成了一项关于RAPL与Prometheus在Kubernetes集群能耗监测中的对比研究。这项研究源于我们在实际工作中遇到的一个具体问题&…...

Ubuntu 下 P106-100 矿卡 `nvidia-smi No devices were found` 问题解决全过程
Ubuntu 下 P106-100 矿卡 nvidia-smi No devices were found 问题解决全过程 最近折腾一张老矿卡 P106-100,在 Ubuntu 下遇到一个非常经典的问题: nvidia-smi No devices were found但是: lspci | grep -i nvidia却能看到显卡: 01:00.0 3D controller: NVIDIA Corporat…...

【致91岁的双胞胎】堡垒复习:3步搭建理科“作战地图”,告别零散刷题效率翻倍
很多学生长期陷入理科复习瓶颈:花费大量时间刷题、背书,成绩却始终原地踏步。核心根源只有一个:照搬文科的复习方式学理科。 文科复习侧重知识点记忆、框架梳理、素材积累,通用的A4纸整理法完全适用;但理科的核心是逻辑闭环、体系串联、题型落地、抗遗忘复盘,死记硬背、…...