大数据开发面试题【Flink篇】
148、flink架构
flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算
特点:
高吞吐和低延迟:每秒数百万个事件,毫秒级延迟
结果的准确性:提供了事件时间和处理时间语义,提供结果的一致性
精确一次的状态的一致性保证
jobmanager包含三个组件:
jobmaster:是jobmanager中最核心的组件,负责处理单独的job,jobmaster和具体的job是一一对应的
resourceManager:负责资源的分配和管理,所谓的资源,只要是指taskmanager的任务槽,任务槽就是flink集群中的资源调配单元,包含了机器用来执行计算的一组cpu和内存资源
分发器(Dispatcher):负责提供一个rest接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的jobmanager组件
TaskManager:数据流的具体计算就是它来做的,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。每个taskmanager都包含一个定数据量的任务槽,slot是资源调度的最小单位
flink主要包含TaskManager、JobManager、Client三种角色
- JobManager扮演着集群中的管理者Master的角色,它是整个集群的协调者,负责接收Flink
Job,协调检查点,Failover 故障恢复等,同时管理Flink集群中从节点TaskManager。 - TaskManager是实际负责执行计算的Worker,在其上执行Flink
Job的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
补充:并行度的概念
一个特定算子的子任务的个数被称为并行度,一个流的并行度,指的是其所有算子中最大的并行度
补充:算子链
一个数据流在算子之间传输数据的形式可以是一对一的直通,也可以是打乱的重分区模式
一对一:算子之间不需要重分区,也不需要调整数据的顺序,保证着一对一的关系,类似spark中的窄依赖
重分区:数据流的分区会发生改变,根据数据传输的策略,把数据发送到下游不同的目标任务中,类似spark中的shuffle
合并算子链:并行度一一对应的算子操作,可以连接一起,形成一个大的任务,称为算子链
优点:可以减少线程之间的切换和基于缓存区的数据交换,在减少延时的同时提升吞吐量
客户端在提交任务的时候会优化操作,能进行合并的operator会被合并为一个operator,合并后的operator称为算子链,每个算子链会在taskmanager上独立的线程中执行
补充:任务槽的概念
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。flink将进程的内存进行了划分到多个slot中
任务槽是静态的概念,是指taskmanager的并发执行能力。并行度是动态的概念,是taskmanager运行时候实际使用的并发能力;
槽共享:即使是不同任务的子任务,只要来自同一个作业,一个槽可以保存作业的整个管道,允许插槽共享
优点是:只需要计算job中最高并行度的task slot;资源分配更加公平,可以提高并行度
补充:创建执行环境的方式
getExecutionEnvironment:根据上下文进行创建执行环境,如果是独立运行的,就返回一个本地执行环境,如果是创建了jar包,就返回集群的执行环境
createLocalEnvironment:返回一个本地执行环境,默认并行度就是本地CPU的核心数
createRemoteEnvironment:返回一个集群执行环境,需要指定ip和端口号
补充:flink中支持的数据类型
- java所有的类型包括包装类,再加上void、string、date、BigDecimal和BigInteger。包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)。
- 包括java的元组类型tuple,从tuple0——tuple25
- 包括scala的元组不支持空字段
- POJO类等
149、Flink的窗口了解哪些,都有什么区别,有哪几种?如何定义?
1、按照驱动类型区分:
时间窗口:以时间点来定义窗口的开始和结束,所以截取的就是某一时间段的数据,到达结束时间,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁,定点发车
计数窗口:基于元素的个数来截取数据,到达固定的个数时候就触发计算关闭窗口,人满就发车
2、按照窗口分配数据的规则分类
滚动窗口:由固定的大小,是一种对数据进行均匀切片的划分方式,窗口之间没有重叠,也不会由间隔,首尾相接
-
滑动窗口:窗口之间并不是首尾相连,而是错开的位置
当滑动步长==窗口大小时候,就和滚动窗口一样
当滑动步长<窗口大小时候,窗口就会重叠,出现数据分配到多个窗口的现象出现 -
会话窗口:类似session会话,数据来了就保持会话窗口开启,如果接下来还有数据到来,就一直保持会话,如果一段时间没收到数据,就认为会话超时,窗口自动关闭
-
全局窗口:无界流的数据永无止境,没有结束实际
150、flink中的时间语义
Event time:事件创建的事件,一般是在外部系统事件产生的事件
优势:基于事件时间的处理可以保证结果的准确性;处理具有窗口操作的场景,事件时间可以确保窗口的精确性和一致性;适用于对数据进行实时分析和处理的场景
Ingestion Time:数据进入flink的事件
能够保证摄入数据的顺序性,不会受数据到达顺序的影响
Process time:执行操作算子的本地系统事件,与机器相关
优势:计算成本较低,不需要额外的时间戳和水位线来管理;适用于实时性要求不高的场景
151、flink中的水位线
特性:
- 水位线是插入到数据流中的一个标记
- 水位线的主要内容是一个时间戳,用来表示当前时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增
- 水位线可以通过设置延迟时间,来保证正确的乱序数据
水位线的传递
-
上游多个水位线往下游发送时候,取各个水位线的最小值作为当前水位线
-
watermarks是基于已经收集的消息来估算是否还有消息未到达,watermark相当于一个endline,一旦watermark大于某个window的end_time,就意味windows_end_time和watermark时间相同的窗口就开始执行计算
152、flink中窗口和水位线的关系
flink想要更加高效方便地处理无界流,一种方式就是将无界流数据切割成有限的“数据块”,这就是窗口的概念
窗口和水位线的提出,使其在一定范围以内可以正确处理数据乱序的现象
一般当水位线时间大于窗口的结束时间,开始触发窗口的计算
window的作用是为了周期性的获取数据
watermark的作用是防止数据出现乱序,事件事件内获取不到指定的全部数据,而做的一种方法
allowlateness是将窗口关闭时间再延长一点
sideoutput是最后的兜底操作,所有过期延期数据,指定窗口已经彻底关闭,就会把数据放到侧输出流
153、Flink的Checkpoint机制
- checkpoint就是flink会在指定时间段上保存状态的机制,如果flink挂了,就可以将上一次的状态信息捞起来,重放还没保存的数据来执行,就中实现exactly
once。状态只持久化一次到最终的存储上。 - 应该在所有任务都恰好处理完一个相同的输入数据的时候,将他们的状态保存下来,在重新恢复时候,只需要让source任务向数据源重新提交偏移量、请求重放数据就可以
- 检查点分界线:专门用来触发检查点保存的时间点,source可以在当前数据流中插入这个结构,之后的任务只要遇到它就开始对状态做持久化快照保存。
补充:Checkpoint 存储位置在哪里
默认情况下,检查点存储在JobManager的堆内存中,也可以存储在本地文件目录或者hdfs上(存储到分布式文件系统、分布式数据库、对象存储服务)
checkpoint的存储格式包括:元数据信息、状态数据、元数据索引
env.enableCheckpointing(6000);
env.getCheckpointConfig().setCheckpointStorage("文件目录");
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
补充:检查点算法
在Flink中,采用了基于Chandy-Lamport算法的分布式快照算法
检查点分界线Barrier:所有任务只要遇到它就开始对状态做持久化快照保存,也代表之前的数据都处理完了,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的“分界线”(Checkpoint Barrier)。
1、分布式快照算法 Barrier对齐精准一次
水位线表示之前的数据全部到齐了,barrier表示之前所有数据的状态更改保存入当前检查点
两个原则:
1、当上游任务向多个并行下游任务发送barrier时,需要广播出去;
2、而当多个上游任务向同一个下游任务传递分界线时,需要在下游任务执行“分界线对齐”操作,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存。
2、 分布式快照算法(Barrier对齐的至少一次)
补充:flink中的SavePoint机制
savepoint:用户手动执行,不会过期,相当于备份
checkpoint:应用定时触发,用户保存状态,会过期
154、并行度和算子链
一个流程序的并行度,可以认为是所有算子中最大的并行度
一个数据流在算子之间传输数据的形式可以说是一对一、可以说是打乱的重分区的,一对一类似于spakr中的窄依赖;重分区类似宽依赖
合并算子链:并行度相同的一对一算子操作,可以直接链接在一起形成一个大的任务,每个task被称为一算子链
将算子链合并成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少延时的同时提升吞吐量
补充:设置flink算子并行度以及优先级
1、在代码中设置
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
2、提交应用时候设置等价于在webUI上设置并行度
bin/flink run –p 2 –c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
3、配置文件指定
并行度优先级:算子代码>env代码>提交时候指定>配置文件
155、转换算子
1、map
一一映射,消费一个元素就产出一个元素,返回类型还是datastream
2、filter
设置一个布尔过滤,对于流内的元素进行判断,若为true则元素正常输出,若为false则元素被过滤掉
3、flatMap
主要是将数据流中的整体拆分成一个又一个的个体使用,消费一个元素,产生多个元素,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同
4、Aggregation
按键分区keyby
keyby是聚合前必须要用到的一个算子,通过指定键,可以将一条流从逻辑上划分成不同的分区,
在内部是通过计算key的哈希值,对分区进行取模运算得到的,keyby得到的记过不再是datastream,而是keyedstream,分区流或者键控流
5、reduce
对已有的数据进行规约处理,把每一个新输入的数据和当前已经规约出来的值,再做一个聚合计算
156、富函数
flink的所有函数都有rich版本,不同于常规函数的是:富函数类可以获取运行时候的上下文,并拥有一些生命周期方法
open()方法:是富函数初始化方法,开启一个算子生命周期,一个算子的实际工作方法map或者filter被调用之前,open方法会首先被调用
close():生命周期中的最后一个调用的方法,
157、物理分区算子
1、随机分区:这是最简单的分区方式,调用datastream.shuffle()将数据随机地分配到下游算子中的并行任务中去
2、轮询分区:按照先后顺序将数据做依次分发,将输入流数据平均地分配到下游的并行任务中去 stream.rebalance()
3、重缩放分区:只会将数据轮询发送到下游并行任务中的一部分去,stream.rescale()
4、广播:数据会在不同的分区逗保留一份,将输入数据复制并分发到下游算子的所有并行任务中去,调用DataStream的broadcast()方法
5、全局分区:调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去
158、分流
将一条数据流拆成两条或者多条独立的流,将符合条件的流拣选出来放入对应的流里
通常使用侧输出流:只需要调用上下文的.output()方法,就可以输出任意类型的数据
OutputTag<WaterSensor> s1 = new OutputTag<>("s1", Types.POJO(WaterSensor.class)){}; 定义侧输出流
OutputTag<WaterSensor> s2 = new OutputTag<>("s2", Types.POJO(WaterSensor.class)){};
SingleOutputStreamOperator<WaterSensor> ds1 = ds.process(new ProcessFunction<WaterSensor, WaterSensor>()
{@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception {if ("s1".equals(value.getId())) {ctx.output(s1, value);} else if ("s2".equals(value.getId())) {ctx.output(s2, value);} else {out.collect(value);}}
});
补充:合流union
使用union,就可以对datastream实现流的联合了,得到一个datastream,一次可以连接多条同类型的流,但是类型必须一致
补充:链接connect
使用union虽然简单,但是受类型的限制,灵活性不高,使用connect可以连接任意类型的流,但是一次只能连接两条流
补充:读取kafka
KafkaSource<String> kafkaSource = KafkaSource.<String>builder().setBootstrapServers("hadoop102:9092").setTopics("topic_1").setGroupId("atguigu").setStartingOffsets(OffsetsInitializer.latest()).setValueOnlyDeserializer(new SimpleStringSchema()) .build();
补充:sink写入到kafka
在写入到kafka之前,如果要使用精准一次的话,需要满足以下条件:
1、开启checkpoint(后续介绍)
2、设置事务前缀
3、设置事务超时时间: checkpoint间隔 < 事务超时时间 < max的15分钟
补充:窗口
窗口不是一个框,而是一个桶,窗口可以把流切割成有限个大小的多个存储桶,当窗口达到结束时间以后,就对每个桶中收集的数据进行计算处理
1、窗口分类
按照驱动类型区分:时间窗口(窗口有开始和结束,定点发车)、计数窗口(窗口截取达到对应的个数就出发计算关闭窗口,人齐发车)
按窗口分配数据的规则分类:滚动窗口、滑动窗口(若步长大于窗口大小,则不会有重叠;若步长小于窗口大小,则会有重叠数据;若步长等于窗口大小,则和滚动窗口一样)、会话窗口、全局窗口(这种窗口没有结束的时候,默认不会做出发计算)
2、按键分区和非按键分区
基于keyedstream上的窗口,窗口操作会对每个key进行进行单独处理(每个key都定义了一个窗口,各自独立进行计算)
stream.keyBy(<key selector>).window(<window assigner>).aggregate(<window function>)
.window就是窗口分配器,指定使用窗口的类型
滚动处理时间窗口:
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
滑动处理时间窗口:
.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
滚动事件时间窗口:
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
滑动事件时间窗口:
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
处理时间会话窗口:
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))),
是指创建了静态会话超过`10s会话窗口
事件时间会话窗口:
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
非按键分区窗口,是基于datastream进行操作,不会分成多条六级流,只会在一个task中进行
tream.windowAll(...)
3、窗口函数
对于窗口,只是按照一定的收集方式将数据收集起来,而窗口函数,则是对收集起来的数据做处理(在窗口上进行计算)
reducefunction:它可以解决大多数规约聚合的问题,但接口有限制,聚合的类型、输出结果的类型都必须和输入类型一样
AggregateFunction:AggregateFunction可以看作是ReduceFunction的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型IN就是输入流中元素的数据类型;累加器类型ACC则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
全窗口函数:针对需要计算全部数据,这时候增量计算就没意义,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
处理窗口函数(ProcessWindowFunction):除了可以拿到窗口中的所有数据之外,ProcessWindowFunction还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息
4、触发器
触发器用来控制窗口什么时候触发计算,本质上是执行窗口函数 .trigger
5、移除器
用来移除某些数据的逻辑 .evictor
159、对迟到数据的处理
1、推迟水位线推进:设置一个乱序容忍度,推迟系统时间的推进,保证窗口计算被延迟执行
2、设置窗口延迟关闭:允许迟到数据,当触发了窗口计算后,会计算当前结果,但此时不会关闭窗口;以后每迟到一条数据,就触发这个数据所在的窗口计算,直到水位线超过了窗口结束时间+推迟时间
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
3、使用侧输出流接收迟到的数据
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))).allowedLateness(Time.seconds(3)).sideOutputLateData(lateWS)
160、窗口联结
两条流中相同的key,如果在同一窗口中,就可以匹配起来,并且可以使用三种时间窗口(滚动窗口、滑动窗口、会话窗口)
161、间隔联结
针对地一条流的每个数据,开辟出其时间戳见后的一段时间间隔,看这个期间是否有来自另一条流的数据匹配间隔链接通过一个共同的key链接两个流中的数据,
162、flink中的状态
- 无状态算子只需要观察每个独立事件,根据当时输入的数据直接转换输出结果;
- 有状态算子,除了当前数据以外,还需要一些其他数据来得到计算结果
flink的状态有托管状态和原始状态两种
- 托管状态就是由flink统一管理,状态的存储访问和故障恢复都是由flink实现的。
- 原始状态是自定义的,开辟了一块新的内存,需要我们自己管理,实现状态的序列化和故障恢复 通常我们采用Flink托管状态来实现需求。
托管状态又可以分为算子状态和按键分区状态
算子状态作用范围限定为当前算子任务的实列相关联的状态,与特定的并行算子实例相关联,对于一个并行任务,占据一个分区,它所处理的所有数据都会访问到相同的状态;算子状态通常用于存储算子的全局状态或配置信息
按键分区状态是与特定键相关联的状态,即与特定键值对相关联;按键分区状态通常用于在有状态的算子中存储中间计算结果,以便后续的操作能在同一键上继续处理响应的数据
按键分区状态又分为:值状态、列表状态、map状态、规约状态(需要对添加进来的所有数据进行规约处理)、聚合状态(来保存添加进来的所有数据的聚合结果)
flink中状态:计算中间结果如何存储,这叫状态、
补充、算子状态
列表状态:将状态表示为一组数据的列表,与keyedstate的列表状态的区别是,在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。
联合列表状态(unionliststate):算子并行度进行缩放调整时对于状态的分配方式不同
广播状态(broadcaststate):分区的所有数据都会访问到同一个状态
状态是用于在流处理和批处理中持久化保存数据的机制,可以存储和访问计算过程中中间结果和维护状态
补充、TTL
存在原因:很多状态随着时间的推移逐渐增长,不限制就会耗尽存储空间,TTL就是状态的生存时间,当状态在内存中超过这个值,就将该状态清除;
补充:状态后端
状态的存储、访问和维护;主要负责管理本地状态的存储方式和位置
1、哈希状态后端hashmapstatebackend
把状态放在内存里,哈希表状态后端会在内部直接把状态当作对象,保存在taskmanager的jvm堆上
2、内嵌RocksDB状态后端(EmbeddedRocksDBStateBackend)
RocksDB是一种内嵌的key-value存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend后,会将处理中的数据全部放入RocksDB数据库中,RocksDB默认存储在TaskManager的本地数据目录里
对比:两者最大的区别就是本地状态存放在哪里;前者是内存计算,读写速度快,状态大小会受到集群可用内存的限制;后者是硬盘存储,非常适合海量状态的存储,每个状态都需要反序列化和序列化,直接读取磁盘,性能不高。
163、flink和spark的异同
1、编程模型方面:spark基于批处理模型,将连续的数据流划分成一系列的微批次处理,在每个微批次处理中执行rdd操作,允许使用java、scala、python进行编程;flink基于数据流模型,数据以流的形式输入和输出,支持连续数据处理和有限数据处理
2、数据处理模型方面:spark将数据流划分成微批次处理,并在每个微批次处理中执行一组操作,延迟是秒级;flink是一个基于事件事件的引擎,支持流式处理和批处理,根据事件时间对数据进行有序的处理,延迟是毫秒级
3、架构方面:spark streaming在运行过程中角色包括master、worker、driver、executor。flink运行时主要有jobmanager、taskmanager和slot
4、任务调度:spark构建有向无环图;flink生成streamgraph
5、时间机制:spark streaming只支持处理时间;flink支持处理时间、事件时间和注入时间(事件发生时候的时间、时间被处理时候的时间,时间到达flink的时间)
6、容错机制:spark设置checkpoint;flink使用两阶段提交协议来保证exactly once。
7、数据方面:flink的世界观中,一切都是由流组成的,离线数据是有限的流,实时数据是无界限的流;在spark中,一切都是由批次组成的,离线数据只一个大批次,实时数据是很多的无限的小批次组成
8、应用场景:flink适合对实时流数据处理和时间驱动应用,专门对流式数据设计;spark非常适合大规模的数据集批处理操作
164、barrier对齐的精准一次
watermark指的是之前的胡数据全部到齐了,barrier指的是之前所有数据的状态更改保存入当前检查点;
当多个上游任务向同一个下游任务传递分界线点时候,需要在下游任务执行分界线对齐,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存
165、保存点 savepoint
也是一个分盘的备份,它的原理和算法与检查点完全相同,只是额外多了一些元数据,并且是用户手动执行,而checkpoint由程序自动执行
166、状态一致性
通过检查点的保存来保证状态恢复后结果的正确
状态一致性的三种状态:最多一次、至少一次、精确一次
所谓的端到端的状态一致性,就是source端、flink内部、sink端,
端到端的一致性的关键点,就在于输入的数据源端和输出的外部存储端
补充:端到端精准一次
flink内部可以保证精准一次,关键点就是source端和sink端
source端保证精准一次:数据源可重放数据,或者说可重置读取数据偏移量,加上Flink的Source算子将偏移量作为状态保存进检查点,就可以保证数据不丢。——kafka
sink端保证精准一次:
输出端保证:
幂等写入,一个操作可以重复执行很多次,但是只是导致了一次结果的更改,后面再重复执行就不会对结果起作用;
事务写入:所有操作必须成功完成,否则在每个操作中所作的更改都会被撤销,原子性、一致性、隔离性和持久性(ACID)
事务写入:分为预写日志WAL和两阶段提交2PC
WAL:当外部系统不支持事务的时候,使用WAL实现;先把结果数据作为log状态保存,进行检查点保存的时候,会将结果数据一并做持久化存储,在收到检查点完成的通知的时候,将所有结果一次性写入外部系统,成功写入所有数据后,在内部再次确认响应的检查点,才代表全部完成
两阶段提交2PC:先做预提交,等检查点完成以后再正式提交,外部系统需要支持事务;第一条数据到来时候,或者收到检查点的分界线时候,sink任务都会启动一个事务,接下来收到的所有数据,都通过这个事务写入外部系统,此时事务没有提交,数据写入外部系统,但不可用。这是预提交的状态,当sink任务收到jobmanager发来的检查点完成的通知的时候,正式提交事务,这是第二阶段的提交。
167、Flink如何保证一致性?
- flink使用一种检查点的特性,在出现故障时候系统重置回正确的状态。检查点可以保证flink使用精准一次,不需要牺牲性能
- 在将状态内容传送到输出存储系统的过程中,如何保证 exactly-once
呢?这叫作端到端的一致性。本质上有两种实现方法,用哪一种方法则取决于输出存储系统的类型,以及应用程序的需求: - 第一种方法是在sink环节缓冲所有输出,并在sink收到检查点记录时候,将数据原子提交到存储系统,不会出现重复数据
168、Flink支持JobMaster的HA啊?原理是怎么样的?
独立集群的jobmanager的机制是,一个leader jobmanager和多个stanby jobmanage,当leader崩溃后,多个stanby选举后产生新的leader,两者没区别,任何jobmanager都可以承担leader或者stanby角色
167、如何确定Flink任务的合理并行度?
压测合理并行度的方法:或者高峰期的qps,消费该高峰期的数据,达到反压状态查看每秒处理的数据量,就是但并行度的处理上限;
168、反压机制
反压现象:下游消费速度跟不上上游产生数据的速度,这就是反压,出现反压时,限制上游生产者的速度,使得下游的速度跟的上上游的速度。
反压会导致流处理作业数据延迟的增加,同时还会影响checkpoint,但是由于flink的checkpoint机制还需要进行barrier对齐,如果此时出现了反压,barrier流动的速度就会变慢,导致checkpoint整体时间变长;严重的会导致checkpoint超时;
长期或者频繁出现反压才需要处理,若只是网络波动或者垃圾回收机制出现的反压就不用考虑
反压就是缓冲区不够用,内存空间不够,task暂时性的堵塞
反压存在两种情况:
1、当前task发送的速度跟不上它产生数据的速度,导致当前task发送电源申请不到内存
2、当前task处理数据的速度比较慢,如果每条数据都要进行算法调用时,上游task处理数据较快,导致下游发送端申请不到内存
反压的解决方式
部分情况是由于用户代码执行效率不高的问题,可以增加并发度或者其他资源的方式在缓解反压。若是数据倾斜引起的,可以对数据进行一次keyby之类的操作来解决;
flink不需要一个特殊的机制来处理反压,flink的数据传输机制已经提供了反压机制
169、flink对迟到数据的处理
第一时间想到是水位线的解决机制,但是水位线不能完全解决数据延迟的问题,通常延迟数据的处理方式有三种:直接丢弃、把迟到的部分单独开在一个window处理、把数据符合要求的部分,导入到窗口中
一般会设置延迟水位线的处理,但是只能在一定程上解决数据乱序问题,某些极端问题会比较严重,即使延长水位线,也无法全部进入窗口中;在默认情况下,flink会将严重迟到的数据丢弃,还可以设置侧输出流,处理迟到的数据
补充:处理函数
ProcessFunction:必须实现两个抽象方法,一个是processElement,另一个是ontimer
processElement:流中的每一个元素都会调用一次,参数包括三个:输入数据值value,上下文ctx,以及“收集器”(Collector)out;
ontimer:只有在注册好的定时器触发的时候才会调用,定时器是通过timerservice来注册的,timer就是设置一个闹钟,ontime就是闹钟响了需要做的事情
1、按键分区处理函数KeyedProcessFunction
只有在KeyedStream中才支持使用TimerService设置定时器的操作
2、窗口处理函数ProcessWindowFunction和ProcessAllWindowFunction
补充:FlinkSQL
flinksql中的表是动态表,根据数据流的源源不断进行更新;持续查询就是针对动态表的sql结果也在时刻发生变化
补充:flink和sparkstreming的区别
- flink基于流的概念,采用数据流模型,可以对有界和无界数据流进行有状态的处理计算
- sparkstreaming通过微批次的处理方式来实现对数据的实时处理,将数据流切成很小的批数据,基于RDD表达逻辑
- Flink是基于流的真正运行时,Spark Streaming是基于微批的流处理。
- Flink用 Operator Chains 来实现流计算,Spark Streaming将流任务转换为批作业RDD。
- Flink有更低的延迟,可以做到毫秒级,Spark Streaming批间隔一般500毫秒以上。
- Flink检查点机制实现Exactly-once语义,Spark Streaming有At-least-once语义。
- Flink支持事件时间处理,可以处理乱序事件,Spark Streaming基于批次时间。
- Flink具有更好的容错能力和重启能力,Spark Streaming重启后需要重新计算。
- Flink提供了更丰富的流处理功能,如循环流、流Join等,Spark Streaming继承自Spark批设计。
- Flink需要单独部署和运维,Spark Streaming可以直接基于Spark集群运行。
- Flink更适合低延迟、高精度的连续流处理,Spark Streaming更偏向间断性数据流。
- Flink提供了丰富的窗口操作支持,滚动、滑动、会话等,Spark Streaming只支持滚动和滑动窗口
补充:公司怎么提交的实时任务,有多少Job Manager?
使用yarn-session模式,每提交一次就会创建一个新的集群,为每个jon提供资源,任务之间相互独立,互不影响,方便管理,任务执行完成汲取随之消失
集群模式默认只有个jobmanager
补充:Flink的并行度了解吗?Flink的并行度设置是怎样的?
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:map.set…算子层面>env.set…环境层面>客户端层面>系统层面。
补充:checkpoint、statebackend、savepiont的区别?
- checkpoint:检查点用来实现容错和状态的一致性机制;检查点包含了当前任务的状态信息、如果某个任务失败,则可利用检查点来进行恢复;
- statebackend:是用来存储和检索状态的地方,状态可以是键值对、列表、映射等数据结构;状态是用于在流处理和批处理中持久化保存数据的机制,可以存储和访问计算过程中中间结果和维护状态。
- 检查点和状态后端不是一个东西,但紧密相关
- 检查点的状态就是数据,隔一段时间就保存一次状态数据
- 状态后端更像是所有状态数据的存储
- statebackend定义了状态的存储位置和方式,checkpoint是周期性持久化状态的机制,savepoint则是手动创建的用于保存状态和位置信息的检查点
- savepoint面向用户,完全根据用户的需要触发与清理。checkpoint面向flink本身,由flink的各个taskmanager定时触发快照并自动清理
相关文章:

大数据开发面试题【Flink篇】
148、flink架构 flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算 特点: 高吞吐和低延迟:每秒数百万个事件,毫秒级延迟 结果的准确性:提供了事件时间和处理时间语义,提供结果的一致…...
)
Java技术深度解析:高级面试问题与精粹答案(二)
Java 面试问题及答案 1. 什么是Java的垃圾回收机制?它是如何工作的? 答案: Java的垃圾回收机制(Garbage Collection,GC)是Java运行时环境(JRE)中的一个功能,用于自动管…...

算数运算符
算术运算符是用于数值类型变量计算的运算符。 它的返回结果是数值。 赋值符号 关键知识点:先看右侧,再看左侧,把右侧的值赋值给左侧的变量。 附上代码: string myName "唐唐"; int myAge 18; float myHeight 177.5…...

闲话 .NET(3):.NET Framework 的缺点
前言 2016 年,微软正式推出 .NET Core 1.0,并在 2019 年全面停止 .NET Framework 的更新。 .NET Core 并不是 .NET Framework 的升级版,而是一个从头开始开发的全新平台,一个跟 .NET Framework 截然不同的开源技术框架。 微软为…...

WPF实现简单的3D图形
简述 Windows 演示基础 (WPF) 提供了一种功能,用于根据应用程序要求绘制、转换 3D 图形并为其添加动画效果。它不支持完整的3D游戏开发,但在某种程度上,您可以创建3D图形。 通过组合 2D 和 3D 图形,您还可以…...

设计模式之创建型模式---原型模式(ProtoType)
文章目录 概述类图原型模式优缺点优点缺点 代码实现 概述 在有些系统中,往往会存在大量相同或者是相似的对象,比如一个围棋或者象棋程序中的旗子,这些旗子外形都差不多,只是演示或者是上面刻的内容不一样,若此时使用传…...

git命令新建远程仓库
今天记录一下使用git命令新建远程分支的操作,因为公司的代码管理仓库界面没找到新建分支的操作界面,无奈只能通过git命令来新建分支。 1、新建本地分支 首先,你的至少应该已经有了一个master分支,然后你再master分支下面执行下面…...
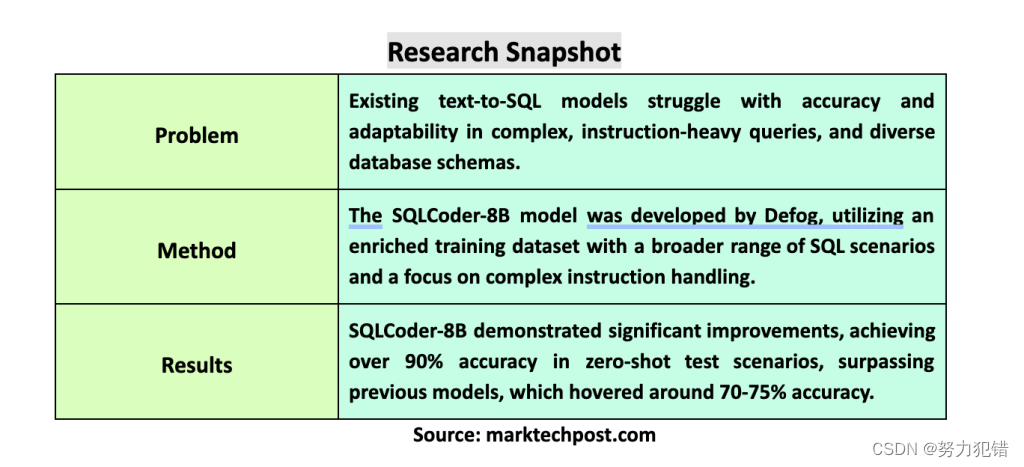
Defog发布Llama-3-SQLCoder-8B,文本转SQL模型,性能比肩GPT-4,准确率超90%,消费级硬件可运行
前言 在计算语言学领域,将自然语言转化为可执行的SQL查询是一个重要的研究方向。这对于让那些没有编程或SQL语法知识的用户也能轻松访问数据库信息至关重要。Defog团队近日发布了基于Llama-3的SQLCoder-8B模型,它在文本转SQL模型领域取得了显著突破&…...

防刷发送短信验证码接口的五种简单好用方法绝对够用
防刷发送短信验证码接口的五种简单好用方法,绝对够用 前端增加图形验证码,点击发送按钮后增加60s倒计时,60s后才可以再次点击 后端对接口次数校验,60s内同一电话号码只能发送一次 // 生成基于电话号码的重试锁定键 String repeat…...
ubuntu中idea创建spark项目步骤
1.前置条件 ubuntu中已经安装idea,jdk,scala,spark 2.打开idea,新建,选择Maven项目 3.在IDEA中,File-Setting-Plugin,下载Scala插件 4.File-project structure,导入插件 4.1在全局库中,选择导入刚才的sca…...
回文链表(快慢指针解法之在推进过程中反转)
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍 收藏⭐ 留言📝抱怨深处黑暗,不如提灯前行…...

深度剖析:为什么 Spring 和 IDEA 都不推荐使用 @Autowired 注解
目录 依赖注入简介 Autowired 注解的优缺点 Spring 和 IDEA 不推荐使用 Autowired 的原因 构造器注入的优势 Autowired 注解的局限性 可读性和可测试性的问题 推荐的替代方案 构造器注入 Setter 注入 Java Config Bean 注解 项目示例:Autowired vs 构造器…...

【接口自动化_05课_Pytest接口自动化简单封装与Logging应用】
一、关键字驱动--设计框架的常用的思路 封装的作用:在编程中,封装一个方法(函数)主要有以下几个作用:1. **代码重用**:通过封装重复使用的代码到一个方法中,你可以在多个地方调用这个方法而不是…...
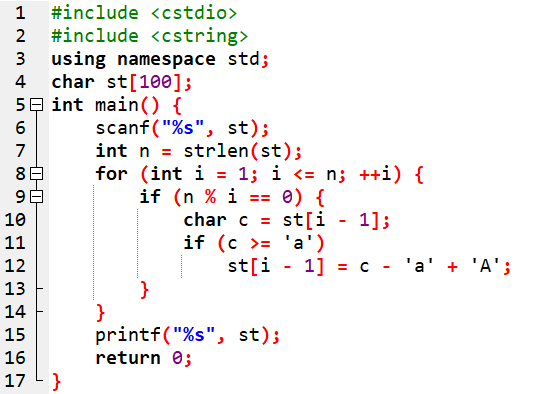
信息学奥赛初赛天天练-14-阅读程序-字符数组、唯一分解定理应用
更多资源请关注纽扣编程微信公众号 1 2019 CSP-J 阅读程序1 (程序输入不超过数组或字符串定义的范围;判断题正确填√,错误填;除特殊说明外,判断题1.5分,选择题3分,共计40分) 1 输入的字符串只能由小写字母或大写字母组…...
K210 数字识别 笔记
一、烧写固件 连接k210开发板,点开烧录固件工具,选中固件,并下载 二、模型训练 网站:MaixHub 1、上传文件 2、开始标记数据 添加9个标签,命名为1~9,按键盘w开始标记,键盘D可以下一张图片&…...
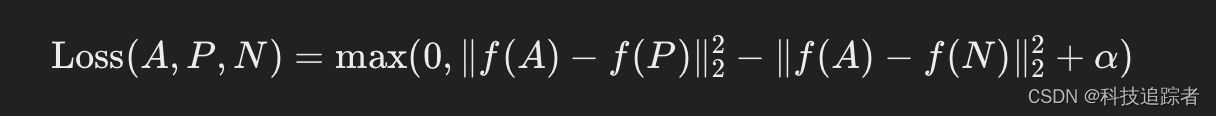
人脸检测--FaceNet(四)
FaceNet 是一个由 Google 研究团队开发的人脸识别系统,它基于深度学习技术,可以实现高精度的人脸识别、验证和聚类任务。FaceNet 通过学习直接从图像像素到人脸嵌入的映射,使得它在各种人脸识别任务中表现出色。下面是对 FaceNet 的详细介绍&…...
Android性能优化方案
1.启动优化: application中不要做大量耗时操作,如果必须的话,建议异步做耗时操作2.布局优化:使用合理的控件选择,少嵌套。(合理使用include,merge,viewStub等使用)3.apk优化(资源文件优化&#…...
视频监控平台AS-V1000 的场景管理,一键查看多画面视频的场景配置、调用、管理(一键浏览多路视频)
目录 一、场景管理的定义 二、场景管理的功能和特点 1、功能 (1)场景配置 (2)实时监控 (3)权限管理 2、特点 三、AS-V1000的场景配置和调用 1、场景配置 (1)实时视频预览 …...
微服务架构五大设计模式详解,助你领跑行业
微服务架构设计模式详解(5种主流模式) 微服务架构 微服务,一种革命性的架构模式,主张将大型应用分解为若干小服务,通过轻量级通信机制互联。每个服务专注特定业务,具备独立部署能力,轻松融入生产环境,为系…...
【problem】解决EasyExcel导出日期数据显示为#####问题
前言 在使用EasyExcel进行数据导出时,你可能遇到日期或其他数据在Excel中显示为“#######”的情况,这通常是因为列宽不足以展示单元格内的全部内容。本文将指导你如何通过简单的步骤解决这一问题,并确保导出的Excel文件自动调整列宽或直接指…...

面试必问:AI 医疗平台怎么设计?这次彻底讲透
AI 医疗平台怎么设计?一次讲清医生辅助、知识库、问答系统与安全边界 大家好,我是一名有 4 年工作经验的 Java 后端开发。 AI 和医疗结合这个方向这两年非常热,但也正因为它太敏感,所以最怕两种极端:一种是把它吹成“万…...

IS6201A多相PWM控制器:从架构解析到PCB布局的电源设计实战
1. 项目概述:为什么我们需要关注IS6201A?在电源设计领域,尤其是面对高性能计算、数据中心服务器、高端显卡以及工业自动化设备时,工程师们常常面临一个核心挑战:如何为那些“电老虎”级别的核心芯片(比如CP…...

手把手教你用UE5 C++为角色添加动态攀爬:支持移动平台与高度自适应
手把手实现UE5动态攀爬系统:移动平台与高度自适应全解析 在当代3A级动作游戏中,角色与环境的动态交互已成为沉浸感的核心要素。想象一个场景:玩家在摇晃的空中浮岛上追逐目标,需要连续攀爬移动中的平台;或是潜入敌方基…...

Fast-GitHub:智能网络优化架构解析与分布式加速方案
Fast-GitHub:智能网络优化架构解析与分布式加速方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 在国内开发者面临G…...

北京理工大学:数据中心节能降碳之算电协同——背景、技术、实践和展望 2026
这份由北京理工大学 2026 年初发布的《数据中心节能降碳之算电协同:背景、技术、实践和展望》报告,围绕算电协同,从背景、技术、实践、展望四方面系统分析,核心是推动算力与电力、热力深度融合,助力数据中心节能降碳、…...

【2026】记录在windows编译llama.cpp步骤,AMD CPU本地部署千问3.5本地大模型,内存占用低
前言 我的电脑是AMD的32G内存,没有GPU,偏要玩一玩千问3.5本地大语言模型,github上下载的llama安装包,无法使用,只有自己编译试试了。注意我是编译CPU版本的,你有GPU这篇别看了。 以下是我的CPU型号: 1.…...

C++ vector动态数组:从原理到实战的完整指南
1. 项目概述:为什么我们需要动态数组?在C的世界里,如果你是从C语言转过来的,或者刚开始接触系统级的编程,第一个让你感到“束手束脚”的,很可能就是数组。C风格的数组,大小必须在编译时确定&…...
)
用LAMMPS做材料分析?手把手教你用Ovito绘制应力、温度、速度云图(附完整脚本)
从LAMMPS到Ovito:材料模拟数据可视化的全流程实战指南 在计算材料科学领域,分子动力学模拟产生的海量数据如何转化为直观、可发表的科学图表,一直是研究者面临的挑战。本文将系统介绍从LAMMPS模拟到Ovito可视化的完整工作流,重点解…...

NoSQL数据库原理与应用
NoSQL数据库原理与应用 1. 技术分析 1.1 NoSQL概述 NoSQL数据库是对传统关系型数据库的补充: NoSQL类型文档型: MongoDB键值型: Redis列族型: Cassandra图数据库: Neo4jNoSQL特点:非关系型分布式水平扩展1.2 NoSQL vs 关系型 对比维度数据模型: 灵活vs结构化一致性:…...

别再只盯着AB相了!三引脚EC35编码器在智能面板上的应用与防误触设计
三引脚EC35编码器在智能面板设计中的创新应用与抗干扰实践 旋钮交互在智能家居和工业HMI领域从未失去它的魅力——当用户手指触碰到那个精致的金属环时,物理反馈带来的确定感是纯触控界面无法替代的。但传统AB相编码器的误触发问题长期困扰着产品设计师:…...