随机森林算法实现分类
随机森林算法实现对编码后二进制数据的识别
1.直接先上代码!
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from joblib import dump, load
# 读取数据
data = pd.read_excel('/root/分类数据集.xlsx', sheet_name=0)# 提取特征和标签
binary_strings = data["编码后数据"].values
y = data["类型"]max_length = max(len(s) for s in binary_strings)
X = np.array([list(map(int, s.zfill(max_length))) for s in binary_strings])# 样本标签数值化处理
target_map = {"ldpc": 0, "han": 1, "conv": 2}
target = y.map(target_map)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, target, test_size=0.2, random_state=42)# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 创建随机森林分类器实例
rf = RandomForestClassifier(random_state=42)# 定义超参数搜索空间
param_grid = {'n_estimators': [100, 200], # 决策树的数量'max_depth': [None, 10, 20], # 树的最大深度'min_samples_split': [2, 5], # 分裂内部节点所需的最小样本数'min_samples_leaf': [1, 2], # 叶节点所需的最小样本数'bootstrap': [True, False] # 是否使用bootstrap样本
}# 创建GridSearchCV实例
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='accuracy', n_jobs=-1)# # 用GridSearchCV在给定的超参数网格上进行搜索
grid_search.fit(X_train_scaled, y_train)
# 使用找到的最佳参数的模型进行预测
best_rf = grid_search.best_estimator_
# 保存模型到文件
model_filename = 'best_random_forest64.joblib'
dump(best_rf, model_filename)
# 保存 StandardScaler
scaler_filename = 'scaler64.joblib'
dump(scaler, scaler_filename)
# 假设 max_length 已经在您的代码中计算出来了
max_length_filename = 'max_length64.joblib'
dump(max_length, max_length_filename)
y_pred = best_rf.predict(X_test_scaled)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy on test set with best parameters: {accuracy:.2f}")
2.代码解读
这是一个典型的机器学习流程,用于构建和评估一个随机森林分类器。
- 导入必要的库:
numpy和pandas用于数据处理。train_test_split和GridSearchCV来自sklearn.model_selection,用于划分数据集和超参数优化。RandomForestClassifier来自sklearn.ensemble,是用于分类的随机森林模型。accuracy_score来自sklearn.metrics,用于计算模型准确度。StandardScaler来自sklearn.preprocessing,用于特征缩放。dump和load来自joblib,用于模型和数据的保存和加载。
- 数据加载:
- 使用
pandas的read_excel函数从 Excel 文件中加载数据。
- 使用
- 特征和标签提取:
- 将数据集中的“编码后数据”列转换为数值列表,并将“类型”列作为标签。
- 数据预处理:
- 确定最大长度以保证所有样本长度一致。
- 使用
map方法将标签转换为数值。
- 数据划分:
- 使用
train_test_split将数据集划分为训练集和测试集。
- 使用
- 特征缩放:
- 使用
StandardScaler对训练集和测试集进行特征缩放。
- 使用
- 模型初始化:
- 创建
RandomForestClassifier实例。
- 创建
- 超参数搜索:
- 定义一个超参数网格,包括决策树数量、树的最大深度等。
- 使用
GridSearchCV进行交叉验证和超参数搜索。
- 模型训练:
- 使用训练集数据训练模型,并找到最佳参数。
- 模型保存:
- 将最佳模型、标量器和最大长度保存到文件中。
- 模型评估:
- 使用测试集评估模型的准确度,并打印结果
通过这个过程,我们不仅展示了如何构建一个分类模型,还介绍了如何通过超参数优化来提高模型的性能。
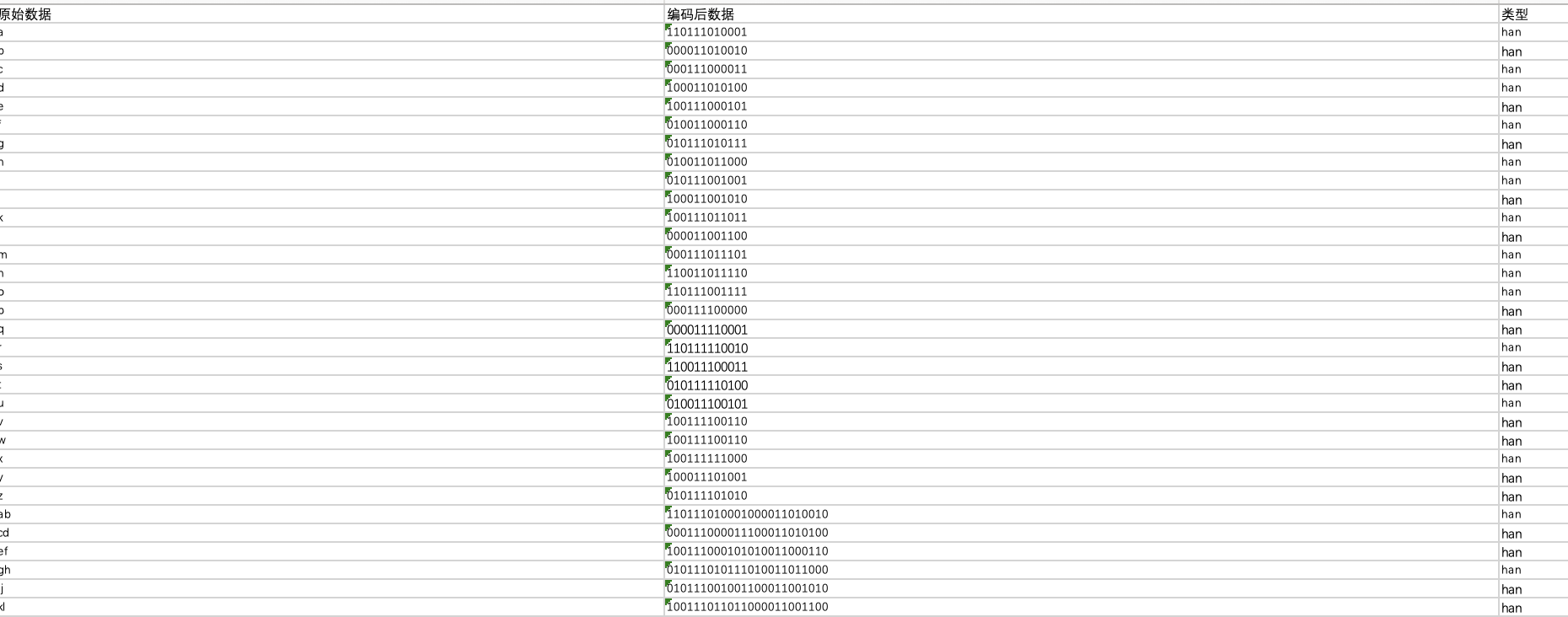
3.数据集部分截图
就介绍到这里啦~~
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
相关文章:
随机森林算法实现分类
随机森林算法实现对编码后二进制数据的识别 1.直接先上代码! import numpy as np import pandas as pd from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import …...

Ubuntu卸载软件
在删除这些目录之前,你必须确定一个非常重要的事情:确认没有任何服务正在使用这些版本的 PHP。如果你删除了正在使用的 PHP 版本的扩展目录,那么依赖于这个版本的 PHP 的网站或服务可能会停止工作。 如果你确定某个版本的 PHP 没有在使用中&…...

网络工程师:网络可靠性技术
一、可靠性 平均故障间隔时间MTBF(Mean Time Between Failure)和平均修复时间MTTR(Mean Time to Repair)这两个指标来评价系统的可靠性。 1、平均故障间隔时间MTBF MTBF是指一个系统无故障运行平均时间,通常以小时为单位。MTBF越大可靠性越高。 2、平均修复时间MTTR…...

科技引领未来:高速公路可视化
高速公路可视化监控系统利用实时视频、传感器数据和大数据分析,通过图扑 HT 可视化展示交通流量、车速、事故和路况信息。交通管理人员可以实时监控、快速响应突发事件,并优化交通信号和指挥方案。这一系统不仅提高了道路安全性和车辆通行效率࿰…...

Golang发送POST请求并传递JSON数据
客户端 package mainimport ("c02_get_param/common""fmt""zdpgo_resty" )func main() {// Create a Resty Clientclient : zdpgo_resty.New()// 设置字符串resp, err : client.R().SetHeader("Content-Type", "application/jso…...

C++实现生产者消费者模型
生产者-消费者模型是一种典型的多线程并发模式,常用于在一个共享缓冲区中协调生产者和消费者之间的数据传递。在C中,我们可以使用标准库中的线程、互斥量和条件变量来实现该模型。以下是一个简单的生产者-消费者模型的实现示例: #include &l…...

【Mac】MWeb Pro(好用的markdown编辑器) v4.5.9中文版安装教程
软件介绍 MWeb Pro for Mac是一款Mac上的Markdown编辑器软件,它支持实时预览,语法高亮,自动保存和备份等功能,并且有多种主题和样式可供选择。此外,MWeb还支持多种导出格式,包括HTML、PDF、Word、ePub等&a…...

C++ | Leetcode C++题解之第118题杨辉三角
题目: 题解: class Solution { public:vector<vector<int>> generate(int numRows) {vector<vector<int>> ret(numRows);for (int i 0; i < numRows; i) {ret[i].resize(i 1);ret[i][0] ret[i][i] 1;for (int j 1; j &…...

3D透视图转的时候模型闪动怎么解决?---模大狮模型网
在3D建模与渲染的世界中,透视图是我们观察和操作模型的重要窗口。然而,有时候在旋转透视图时,模型会出现闪动的现象,这不仅影响了我们的工作效率,还可能对最终的渲染效果产生负面影响。本文将探讨这一问题的成因&#…...
如何创建一个vue项目?详细教程,如何创建第一个vue项目?
已经安装node.js在自己找的到的地方新建一个文件夹用于存放项目,记住文件夹的存放路径,以我为例,我的文件夹路径为D:\tydic 打开cmd命令窗口,进入刚刚的新建文件夹 切换硬盘: D: 进入文件夹:cd tydic 使…...

AWS迁移与传输之Migration Hub
AWS Migration Hub是一种集中化的迁移管理服务,可帮助企业规划、跟踪和管理在亚马逊云中进行的各种迁移活动。包括应用程序迁移、数据库迁移、服务器迁移等。 AWS Migration Hub (Migration Hub) 提供一个位置来跟踪使用多个 AWS 工具和合作伙伴解决方案的迁移任务…...

网络渗透思考
1. windows登录的明文密码,存储过程是怎么样的,密文存在哪个文件下,该文件是否可以打开,并且查看到密文 windows的明文密码:是通过LSA(Local Security Authority)进行存储加密的 存储过程:当用户输入密码之…...

2.8万字总结:金融核心系统数据库升级路径与场景实践
OceanBase CEO 杨冰 谈及数字化转型,如果说过去还只是头部金融机构带动效应下的“选择题”。那么现在,我相信数字化转型已经成为不论大、中、小型金融机构的“必答题”。 本文为OceanBase最新发布的《万字总结:金融核心系统数据库升级路径…...
Linux:进程控制(二.详细讲解进程程序替换)
上次讲了:Linux:进程地址空间、进程控制(一.进程创建、进程终止、进程等待) 文章目录 1.进程程序替换1.1概念1.2原理1.3使用一个exec 系列函数execl()函数结论与细节 2.多进程时的程序替换3.其他几个exec系…...
Elasticsearch8.13.4版本的Docker启动关闭HTTPS
博主环境是: 开发环境:SpringbootElasticSearch客户端对应的starter 2.6.3版本 maven配置 <!-- ElasticSearch --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elas…...
- ION简化版本)
linux 之dma_buf (8)- ION简化版本
一、前言 我们学习了如何使用 alloc_page() 方式来分配内存,但是该驱动只能分配1个PAGE_SIZE。本篇我们将在上一篇的基础上,实现一个简化版的ION驱动,以此来实现任意 size 大小的内存分配。 二、准备 为了和 kernel 标准 ion 驱动兼容&…...

⌈ 传知代码 ⌋ 高速公路车辆速度检测软件
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...

scrapy 整合 mitm
1.mitm 是什么 MITMproxy 是一个开源的中间人代理,常用于网络流量的拦截、查看和修改。 2.scrapy 整合 mitm步骤 2.1 安装mitm PS F:\studyScrapy\itcastScrapy> pip install mitmproxy2.2 在settings 中配置下载器中间件 # settings.pyDOWNLOADER_MIDDLEWARES…...

linux大文件切割
在一些小众的场景下出现的大文件无法一次性传输 当然我遇到了 ,work中6G镜像文件无法一次性刻盘到4.7G大小的盘 split split -b 3G 源大文件 目标文件 #安静等待会生成目标文件名a、b、c......-b <大小>:指定每个输出文件的大小,单位为…...

图像分割模型LViT-- (Language meets Vision Transformer)
参考:LViT:语言与视觉Transformer在医学图像分割-CSDN博客 背景 标注成本过高而无法获得足够高质量标记数据医学文本注释被纳入以弥补图像数据的质量缺陷半监督学习:引导生成质量提高的伪标签医学图像中不同区域之间的边界往往是模糊的&…...

OpenSpec 介绍与使用:让 AI 编程从“聊天驱动”变成“规格驱动”
一、为什么需要 OpenSpec? AI 编程工具越来越强,但很多人在使用 AI 写代码时会遇到一个问题:需求都在聊天记录里,代码越写越快,但上下文越来越乱,最终很难判断 AI 实现的到底是不是最初想要的东西。 OpenSp…...

【实用程序】基于 Java 的简易HTTP 反向代理
本站内的程序及源代码下载地址。 第一章 概述 本项目是一个基于 Java 的简易 HTTP 反向代理实现。反向代理(Reverse Proxy)的核心职责是代表客户端向目标服务器发起请求,并将目标服务器的响应透明地返回给客户端。客户端感知不到后端真实服务的存在,所有交互都通过代理层…...

NoSQL数据库原理与应用
NoSQL数据库原理与应用 1. 技术分析 1.1 NoSQL概述 NoSQL数据库是对传统关系型数据库的补充: NoSQL类型文档型: MongoDB键值型: Redis列族型: Cassandra图数据库: Neo4jNoSQL特点:非关系型分布式水平扩展1.2 NoSQL vs 关系型 对比维度数据模型: 灵活vs结构化一致性:…...
)
从零到一:用Air724UG 4G模块和Python,手把手教你搭建一个物联网数据上报系统(含完整代码)
从零构建物联网数据上报系统:Air724UG与Python实战指南 在万物互联的时代,物联网技术正悄然改变着我们的生活和工作方式。想象一下,您只需轻点手机,就能实时查看千里之外温湿度数据;或是远程监控设备运行状态ÿ…...
)
保姆级教程:用Python脚本一键搞定OPIXray/HIXray数据集转YOLO格式(附避坑指南)
Python实战:OPIXray/HIXray数据集高效转YOLO格式全流程解析 在目标检测领域,数据格式转换往往是项目落地的第一道门槛。当我第一次拿到OPIXray和HIXray这两个专业X光安检数据集时,面对原始标注格式与YOLO训练需求的不匹配,也经历过…...

HNU 计算机系统 bomblab:从GDB断点到链表重构的逆向实战
1. 逆向工程实战:从零开始拆解二进制炸弹 第一次接触bomblab时,我盯着终端里那个名为"bomb"的可执行文件发呆了十分钟。这个看似普通的Linux程序就像个黑盒子,里面藏着六个需要密码才能解除的"炸弹"。作为计算机系统课程…...
)
KUKA机器人FSoE安全地址丢了别慌!手把手教你用WorkVisual 6.0找回(附KRC4标准柜地址表)
KUKA机器人FSoE安全地址丢失应急修复指南:WorkVisual 6.0实战全解析 当产线突然报警停机,示教器闪烁"FSoE安全地址丢失"的红色警告时,经验丰富的维护工程师都知道——这往往是EtherCAT网络拓扑结构异常引发的紧急故障。尤其在采用K…...
)
别只傻等候补了!用Bypass分流抢票监控12306“捡漏”全攻略(含微信通知设置)
别只傻等候补了!用Bypass分流抢票监控12306"捡漏"全攻略(含微信通知设置) 春节临近,当你在12306官网上看到心仪车次显示"候补"或"无票"时,是否已经放弃希望?其实,…...

向量:一篇文章带你看清数学中最有“方向感“的概念
一、先讲一个让我"开窍"的故事 高中时第一次接触向量,老师在黑板上画了一个箭头,说:“这就是向量。” 我看着那个箭头,心想:这有什么稀奇的?不就是带方向的线段吗? 然后老师开始讲向量…...
:解锁摄像头与雷达融合的3D感知新范式)
跨域空间匹配(CDSM):解锁摄像头与雷达融合的3D感知新范式
1. 为什么自动驾驶需要跨域空间匹配技术 当你坐在一辆自动驾驶汽车里,最不希望看到的就是系统把前方停着的卡车误判成广告牌。这种错误在单一传感器系统中其实很常见——摄像头可能因为逆光看不清物体轮廓,雷达又难以识别物体的具体形状。这就是为什么我…...